FARS全自动科研系统技术深度解析:从多智能体架构到工业化科研范式
FARS全自动科研系统通过四智能体流水线架构实现AI自主科研,包括构思、规划、实验和写作智能体,采用极简的共享文件系统进行异步协作。该系统在228小时内产出100篇论文,展示了AI驱动科研的工业化潜力。关键创新在于:1)基于文件系统的透明协作机制;2)短论文形式提升科研吞吐量;3)状态机设计实现高容错性。这一范式突破了传统人工科研的局限性,为科学发现提供了可扩展的新路径。

前言
2026年2月12日至2月22日,一场持续228小时33分钟的直播在全球AI社区引发了持续震荡。屏幕另一端,一个名为FARS(Fully Automated Research System)的全自动研究系统,在没有人类干预的情况下,自主完成了从文献调研到论文撰写的完整科研流程,最终产出100篇学术论文,总消耗114亿Token,成本10.4万美元。
这场实验的意义远不止于“AI写论文”的简单升级。它向世界展示了科学发现的根本范式正在发生转移——从依赖人类灵感的“手工作坊”,转向由AI驱动的“工业化流水线”。本文将从最底层的技术细节出发,逐层拆解FARS的系统架构、智能体协作机制、资源调度策略、成本控制模型,以及与竞品的技术对比,为读者呈现一个完整的全自动科研系统技术图谱。
第一章 系统总体架构:四智能体流水线设计
1.1 核心设计理念:研究系统的第一性原理
FARS的设计并非简单地模仿人类科研流程,而是基于团队对“研究系统”本质的重新思考。创始团队提出,一个理想的研究系统应遵循两条基本原则:
- 高效拓展知识边界:系统的吞吐量应成为核心评估指标,而非单篇论文的完美程度
- 可靠的假设验证:只要假设合理,验证结果无论正负都构成有意义的知识
基于这一理念,FARS抛弃了传统学术论文的篇幅和结构约束,采用“短论文”形式——每篇聚焦一个边界清晰的研究贡献,鼓励报告失败结果。这种设计使得系统能够以“生产线”模式连续运转,而不是像人类研究者那样陷入对单篇论文的过度打磨。
1.2 四智能体分工架构
FARS的核心架构由四个专业化智能体构成,它们在一个共享文件系统中协作,形成完整的科研流水线:
# FARS系统核心架构示意代码
class FARSSystem:
def __init__(self):
self.agents = {
'ideation': IdeationAgent(), # 构思智能体
'planning': PlanningAgent(), # 规划智能体
'experiment': ExperimentAgent(), # 实验智能体
'writing': WritingAgent() # 写作智能体
}
self.storage = SharedFileSystem() # 共享文件系统
def run_pipeline(self, research_domain):
# 阶段1:构思 -> 生成研究假设
hypotheses = self.agents['ideation'].generate_hypotheses(
research_domain,
self.storage
)
for hypothesis in hypotheses:
# 阶段2:规划 -> 设计实验方案
experiment_plan = self.agents['planning'].design_experiments(
hypothesis,
self.storage
)
# 阶段3:实验 -> 执行代码与数据分析
results = self.agents['experiment'].run_experiments(
experiment_plan,
gpu_cluster_size=160
)
# 阶段4:写作 -> 生成规范论文
paper = self.agents['writing'].generate_paper(
hypothesis,
experiment_plan,
results,
self.storage
)
self.storage.archive_paper(paper)
这种架构设计的核心优势在于关注点分离:每个智能体只需专注于单一职责,通过共享文件系统进行异步通信,避免了复杂的同步协调问题。
1.3 共享文件系统:极简主义的多智能体通信
在大多数多智能体系统中,通信协议的设计往往是最大的技术挑战。FARS采用了一种反直觉的极简方案:基于文件系统的共享状态。
class SharedFileSystem:
def __init__(self, base_path='./fars_workspace'):
self.base_path = base_path
self.create_workspace()
def create_workspace(self):
"""创建结构化工作空间"""
directories = [
'literature', # 文献库
'hypotheses', # 研究假设
'experiment_plans', # 实验方案
'code', # 实验代码
'results', # 实验结果
'papers', # 论文草稿
'final_papers' # 最终论文
]
for dir_name in directories:
os.makedirs(f'{self.base_path}/{dir_name}', exist_ok=True)
def write_hypothesis(self, hypothesis_id, content):
"""写入研究假设"""
file_path = f'{self.base_path}/hypotheses/{hypothesis_id}.json'
with open(file_path, 'w', encoding='utf-8') as f:
json.dump({
'id': hypothesis_id,
'content': content,
'created_at': datetime.now().isoformat(),
'status': 'proposed'
}, f, indent=2)
return file_path
def read_hypotheses(self, status='proposed', limit=10):
"""读取指定状态的研究假设"""
hypotheses_dir = f'{self.base_path}/hypotheses'
hypotheses = []
for file_path in sorted(glob.glob(f'{hypotheses_dir}/*.json'))[:limit]:
with open(file_path, 'r') as f:
hypothesis = json.load(f)
if hypothesis.get('status') == status:
hypotheses.append(hypothesis)
return hypotheses
def update_status(self, file_path, new_status):
"""更新任务状态"""
with open(file_path, 'r+') as f:
data = json.load(f)
data['status'] = new_status
data['updated_at'] = datetime.now().isoformat()
f.seek(0)
json.dump(data, f, indent=2)
f.truncate()
这种设计的优势在于:
- 无需复杂的消息队列:文件系统天然支持持久化和异步处理
- 天然的可观测性:任何人可以随时查看工作空间内容,实现透明科研
- 故障恢复简单:智能体崩溃后重启,只需扫描文件状态即可继续工作
- 版本控制友好:可以直接用Git管理整个科研过程
1.4 智能体间协作的数据流
四个智能体通过共享文件系统形成完整的数据流转链路:
[构思智能体]
↓ 写入 hypotheses/*.json
[规划智能体]
↓ 读取 hypotheses/*.json,写入 experiment_plans/*.json
[实验智能体]
↓ 读取 experiment_plans/*.json,写入 code/*.py 和 results/*.json
[写作智能体]
↓ 读取 results/*.json,写入 papers/*.md 和 final_papers/*.pdf
[归档]
↓ GitHub自动提交
每个智能体都是状态机,持续扫描文件系统,处理待办任务,更新任务状态。这种架构使得系统能够自然地支持并行处理——多个智能体可以同时处理不同任务,只要文件系统支持并发读写。
第二章 构思智能体:从文献海洋到研究假设
2.1 文献调研的自动化实现
构思智能体的首要任务是从海量文献中识别研究空白和潜在突破点。在FARS的9天半运行中,它生成了244个研究假设,覆盖RLVR、模型架构、持续学习等多个前沿方向。
class IdeationAgent:
def __init__(self, literature_db, model_api):
self.literature_db = literature_db # 文献数据库
self.model_api = model_api # LLM API接口
self.research_domains = [
'RLVR (Reinforcement Learning from Verifiable Rewards)',
'small language model post-training',
'LLM automatic evaluation',
'beyond-transformer architectures',
'continual learning',
'diffusion language models',
'AI agent memory mechanisms',
'test-time scaling',
'world models'
]
def generate_hypotheses(self, domain=None, count=10):
"""批量生成研究假设"""
if domain is None:
# 如果没有指定领域,从预设列表中随机选择
domain = random.choice(self.research_domains)
# 1. 检索最新文献
recent_papers = self.literature_db.search(
domain=domain,
time_range='2025-2026',
limit=1000,
sort_by='citations'
)
# 2. 提取研究趋势
trends = self.analyze_trends(recent_papers)
# 3. 识别研究空白
gaps = self.identify_research_gaps(recent_papers, trends)
# 4. 生成假设
hypotheses = []
for gap in gaps[:count]:
hypothesis = self.formulate_hypothesis(domain, gap, trends)
hypotheses.append({
'domain': domain,
'gap': gap,
'hypothesis': hypothesis,
'confidence': self.evaluate_hypothesis(hypothesis),
'timestamp': datetime.now().isoformat()
})
return hypotheses
def analyze_trends(self, papers):
"""分析研究趋势"""
# 提取关键词频率、引用网络、作者合作关系等
keywords = Counter()
for paper in papers:
keywords.update(paper.get('keywords', []))
# 识别热点方向和衰退方向
hot_topics = [k for k, v in keywords.most_common(20)]
return {
'hot_topics': hot_topics,
'emerging_topics': self.detect_emerging_topics(papers),
'citation_clusters': self.cluster_by_citation(papers)
}
def identify_research_gaps(self, papers, trends):
"""识别研究空白"""
prompt = f"""
Based on the following recent papers in {self.current_domain}:
{self.format_papers_for_prompt(papers[:50])}
Research trends:
{json.dumps(trends, indent=2)}
Please identify 5-10 research gaps or unanswered questions that:
1. Are not addressed in the existing literature
2. Can be empirically tested with reasonable computational resources
3. Have potential to advance the field
For each gap, provide:
- A clear statement of the gap
- Why it matters
- A proposed approach to address it
Format as JSON.
"""
response = self.model_api.complete(prompt)
return self.parse_gaps(response)
def formulate_hypothesis(self, domain, gap, trends):
"""将研究空白转化为可验证假设"""
prompt = f"""
Domain: {domain}
Research gap: {gap}
Current trends: {trends['hot_topics'][:5]}
Formulate a specific, testable research hypothesis that addresses this gap.
The hypothesis should:
1. Be falsifiable through experiments
2. Specify the independent and dependent variables
3. Suggest a plausible mechanism
Return as JSON with fields:
- hypothesis: the main hypothesis statement
- independent_variable: what will be manipulated
- dependent_variable: what will be measured
- predicted_outcome: expected result
- rationale: why this hypothesis makes sense
"""
response = self.model_api.complete(prompt)
return self.parse_hypothesis(response)
2.2 假设生成的案例:FA0042论文的诞生

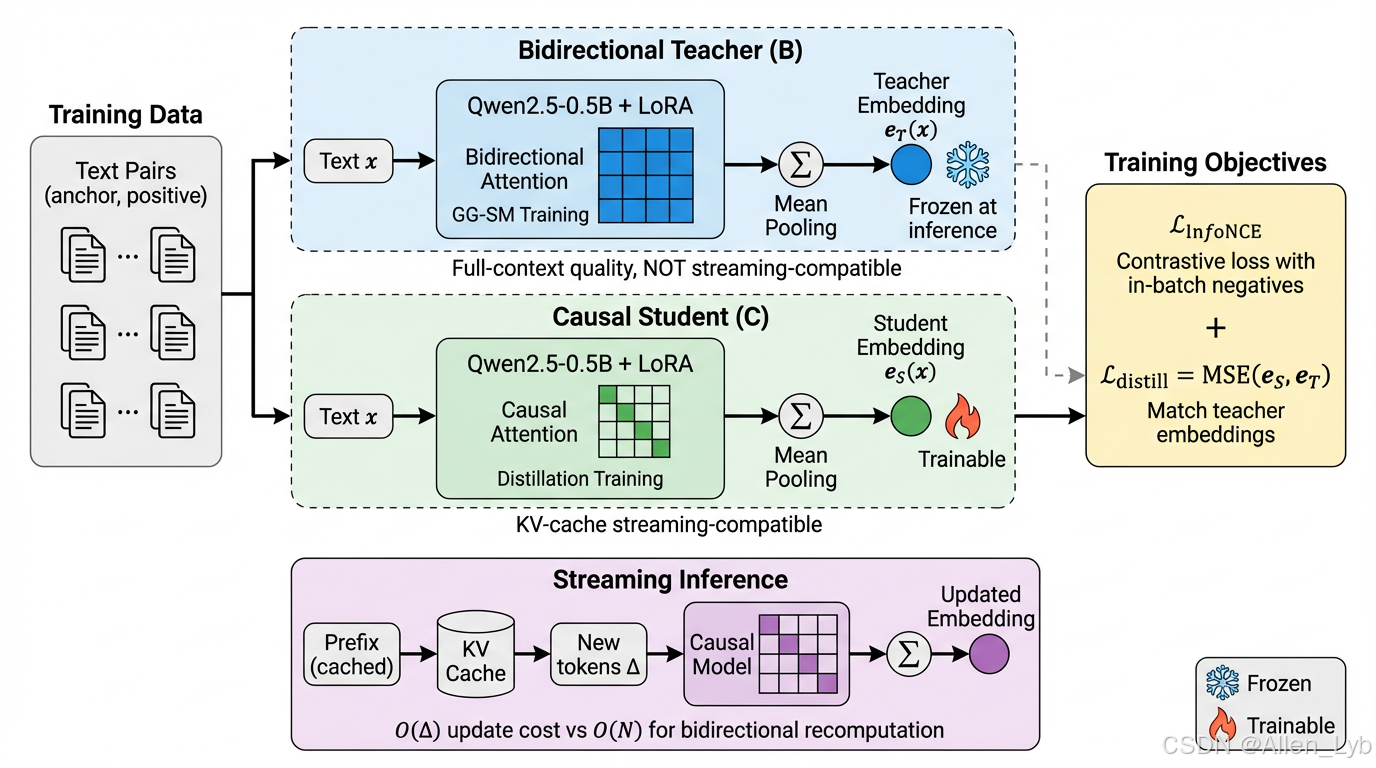
在FARS直播期间,一篇编号为FA0042的论文引起了广泛关注。该论文研究的是文本嵌入领域的注意力机制问题:
研究背景:文本嵌入模型存在一个根本性矛盾——双向注意力(如BERT)质量高但破坏推理效率,因果注意力(如GPT)效率高但质量低。
构思智能体的推理过程(根据公开信息还原):
- 文献调研发现,近期有研究尝试用因果注意力模拟双向注意力
- 但现有方法在长文档检索任务中效果不佳
- 构思智能体提出假设:能否训练一个因果注意力模型,使其在检索任务中达到甚至超过双向注意力模型的性能?
- 具体方案:以双向注意力模型为教师,通过知识蒸馏将能力传递给因果注意力学生模型,同时引入渐进式过渡机制
这一假设最终形成了FA0042论文的核心研究问题。
2.3 假设的自动评估与筛选
并非所有生成的假设都会被送入下一阶段。构思智能体内置了自动评估机制,对每个假设进行多维度评分:
def evaluate_hypothesis(self, hypothesis):
"""评估假设的可行性"""
evaluation_criteria = {
'novelty': self.check_novelty(hypothesis), # 新颖性
'testability': self.assess_testability(hypothesis), # 可测试性
'resource_cost': self.estimate_resource_cost(hypothesis), # 资源成本
'potential_impact': self.estimate_impact(hypothesis), # 潜在影响
'clarity': self.assess_clarity(hypothesis) # 清晰度
}
# 加权综合评分
weights = {
'novelty': 0.25,
'testability': 0.25,
'resource_cost': 0.15,
'potential_impact': 0.25,
'clarity': 0.10
}
total_score = sum(
evaluation_criteria[criterion] * weights[criterion]
for criterion in evaluation_criteria
)
return total_score
只有评分超过阈值(实验中设定为0.7)的假设才会进入下一阶段。这一筛选机制确保了计算资源不会被浪费在低质量假设上。
第三章 规划智能体:从假设到可执行实验方案
3.1 实验方案的形式化描述
规划智能体的任务是将自然语言描述的假设转化为结构化的实验方案。这要求智能体具备实验设计能力和资源预估能力。
class PlanningAgent:
def __init__(self, model_api, resource_manager):
self.model_api = model_api
self.resource_manager = resource_manager # 资源管理器
self.experiment_templates = self.load_templates() # 实验模板库
def design_experiments(self, hypothesis):
"""根据假设设计实验方案"""
# 1. 解析假设的关键要素
parsed = self.parse_hypothesis(hypothesis)
# 2. 选择合适的实验模板
template = self.select_template(parsed)
# 3. 定制化实验设计
experiment_plan = self.customize_template(template, parsed)
# 4. 资源预估
resource_estimate = self.estimate_resources(experiment_plan)
# 5. 验证实验设计的可行性
if self.validate_plan(experiment_plan, resource_estimate):
return {
'hypothesis_id': hypothesis['id'],
'experiment_steps': experiment_plan,
'resource_estimate': resource_estimate,
'estimated_duration': self.estimate_duration(resource_estimate),
'success_criteria': self.define_success_criteria(parsed),
'alternative_approaches': self.generate_alternatives(parsed),
'timestamp': datetime.now().isoformat()
}
else:
return self.revise_plan(hypothesis)
3.2 实验模板库的设计
规划智能体的核心资产是实验模板库——针对常见研究问题类型预定义的实验框架。
class ExperimentTemplate:
def __init__(self):
self.templates = {
'model_comparison': {
'description': 'Compare multiple models on standard benchmarks',
'steps': [
'select_benchmarks',
'setup_models',
'run_inference',
'collect_metrics',
'statistical_tests'
],
'required_resources': ['gpu_hours', 'storage'],
'output_format': 'comparison_table'
},
'ablation_study': {
'description': 'Isolate the effect of specific components',
'steps': [
'define_baseline',
'create_variants',
'run_controlled_experiments',
'analyze_differences'
],
'required_resources': ['gpu_hours', 'code_modification'],
'output_format': 'ablation_matrix'
},
'hyperparameter_search': {
'description': 'Optimize model hyperparameters',
'steps': [
'define_search_space',
'choose_search_algorithm',
'parallel_trials',
'analyze_results'
],
'required_resources': ['gpu_hours', 'parallel_jobs'],
'output_format': 'optimization_curve'
},
'distillation_experiment': {
'description': 'Transfer knowledge from teacher to student',
'steps': [
'load_teacher_model',
'initialize_student',
'prepare_distillation_data',
'train_student',
'evaluate_student'
],
'required_resources': ['gpu_hours', 'teacher_inference'],
'output_format': 'performance_comparison'
}
}
def select_template(self, hypothesis_features):
"""根据假设特征选择最合适的模板"""
# 使用分类模型或规则引擎
if 'compare' in hypothesis_features['action']:
return self.templates['model_comparison']
elif 'component' in hypothesis_features['action']:
return self.templates['ablation_study']
elif 'optimize' in hypothesis_features['action']:
return self.templates['hyperparameter_search']
elif 'distill' in hypothesis_features['action'] or 'transfer' in hypothesis_features['action']:
return self.templates['distillation_experiment']
else:
return self.templates['custom_experiment']
3.3 实验方案验证机制
规划智能体生成的方案并非直接执行,而是经过多重验证:
- 逻辑一致性检查:确保实验步骤能够验证原假设
- 资源可行性检查:预估所需算力是否在当前集群容量内
- 时间可行性检查:预估实验时长是否在可接受范围内
- 依赖完整性检查:确保所有需要的代码库、数据集都已准备
这种验证机制大大减少了实验智能体执行失败的概率。
第四章 实验智能体:代码编写与分布式执行
4.1 从自然语言方案到可执行代码
实验智能体是FARS系统中技术含量最高的模块。它需要将自然语言描述的实验方案,转化为可执行的Python代码,并调度160张GPU集群进行训练和推理。
class ExperimentAgent:
def __init__(self, model_api, gpu_cluster, code_repository):
self.model_api = model_api
self.gpu_cluster = gpu_cluster # 160卡GPU集群
self.code_repository = code_repository # 代码仓库
self.experiment_history = []
def run_experiments(self, experiment_plan):
"""执行实验方案"""
# 1. 生成实验代码
code_files = self.generate_code(experiment_plan)
# 2. 代码验证
validated_code = self.validate_code(code_files)
# 3. 提交到集群执行
job_ids = self.submit_jobs(validated_code, experiment_plan['resource_estimate'])
# 4. 监控执行状态
results = self.monitor_jobs(job_ids)
# 5. 收集和分析结果
analyzed_results = self.analyze_results(results, experiment_plan)
return analyzed_results
def generate_code(self, experiment_plan):
"""从实验方案生成代码"""
code_files = {}
for step in experiment_plan['experiment_steps']:
# 根据步骤类型生成对应代码
if step == 'load_teacher_model':
code = self.generate_model_loading_code(
experiment_plan.get('teacher_model', 'bert-base-uncased')
)
code_files['load_teacher.py'] = code
elif step == 'initialize_student':
code = self.generate_student_initialization(
experiment_plan.get('student_architecture', 'gpt2-small')
)
code_files['init_student.py'] = code
elif step == 'prepare_distillation_data':
code = self.generate_data_preparation_code(
experiment_plan.get('dataset', 'wikitext-103')
)
code_files['prepare_data.py'] = code
elif step == 'train_student':
code = self.generate_training_code(
experiment_plan.get('training_params', {})
)
code_files['train.py'] = code
elif step == 'evaluate_student':
code = self.generate_evaluation_code(
experiment_plan.get('benchmarks', [])
)
code_files['evaluate.py'] = code
# 生成主调度脚本
code_files['run_experiment.sh'] = self.generate_shell_script(
list(code_files.keys())
)
return code_files
4.2 代码生成的智能化实现
代码生成并非简单的模板填充,而是基于对深度学习框架(PyTorch、TensorFlow等)的深度理解:
def generate_training_code(self, training_params):
"""生成训练代码,包含智能化的超参数设置"""
# 根据任务类型自动调整默认参数
task_type = training_params.get('task_type', 'language_modeling')
if task_type == 'language_modeling':
default_params = {
'learning_rate': 5e-5,
'batch_size': 32,
'num_epochs': 3,
'optimizer': 'AdamW',
'scheduler': 'linear_with_warmup',
'warmup_steps': 500,
'weight_decay': 0.01
}
elif task_type == 'classification':
default_params = {
'learning_rate': 2e-5,
'batch_size': 16,
'num_epochs': 5,
'optimizer': 'AdamW',
'scheduler': 'linear',
'warmup_ratio': 0.1,
'weight_decay': 0.01
}
else:
default_params = training_params.get('defaults', {})
# 合并用户参数
params = {**default_params, **training_params.get('override', {})}
# 生成训练代码
code = f'''
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from transformers import AdamW, get_linear_schedule_with_warmup
import wandb
import os
from tqdm import tqdm
def train(model, train_dataset, val_dataset=None):
"""Training function for {task_type} task"""
# 训练参数
learning_rate = {params['learning_rate']}
batch_size = {params['batch_size']}
num_epochs = {params['num_epochs']}
weight_decay = {params['weight_decay']}
# 数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4
)
if val_dataset:
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=4
)
# 优化器
optimizer = AdamW(
model.parameters(),
lr=learning_rate,
weight_decay=weight_decay
)
# 学习率调度器
total_steps = len(train_loader) * num_epochs
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps={params.get('warmup_steps', 500)},
num_training_steps=total_steps
)
# 损失函数
criterion = nn.CrossEntropyLoss()
# 训练循环
model.train()
for epoch in range(num_epochs):
epoch_loss = 0.0
progress_bar = tqdm(train_loader, desc=f"Epoch {{epoch+1}}/{{num_epochs}}")
for batch in progress_bar:
# 将数据移到GPU
batch = {{k: v.cuda() for k, v in batch.items()}}
# 前向传播
outputs = model(**batch)
loss = criterion(outputs.logits, batch['labels'])
# 反向传播
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
epoch_loss += loss.item()
progress_bar.set_postfix({{'loss': loss.item()}})
avg_loss = epoch_loss / len(train_loader)
print(f"Epoch {{epoch+1}} average loss: {{avg_loss:.4f}}")
# 验证
if val_dataset:
val_loss = evaluate(model, val_loader, criterion)
print(f"Validation loss: {{val_loss:.4f}}")
return model
def evaluate(model, val_loader, criterion):
"""评估函数"""
model.eval()
total_loss = 0.0
with torch.no_grad():
for batch in val_loader:
batch = {{k: v.cuda() for k, v in batch.items()}}
outputs = model(**batch)
loss = criterion(outputs.logits, batch['labels'])
total_loss += loss.item()
return total_loss / len(val_loader)
if __name__ == "__main__":
# 从共享文件系统加载数据
import json
with open("/workspace/data/train_config.json", "r") as f:
config = json.load(f)
# 初始化wandb进行实验跟踪
wandb.init(project="fars-experiment", config=config)
# 执行训练
model = train(model, train_dataset, val_dataset)
# 保存模型
torch.save(model.state_dict(), "/workspace/models/final_model.pt")
'''
return code
4.3 分布式集群调度
160张GPU的集群管理是一个复杂的系统工程。FARS将整个集群封装成一个可供智能体调用的工具集:
class GPUCluster:
def __init__(self):
self.gpu_count = 160
self.nodes = self.discover_nodes()
self.job_queue = []
self.running_jobs = {}
def submit_job(self, code_files, resource_request):
"""提交作业到集群"""
# 计算所需资源
gpu_needed = resource_request.get('gpu', 1)
memory_needed = resource_request.get('memory', '16GB')
time_needed = resource_request.get('time', '1h')
# 检查可用资源
available = self.check_available_resources()
if available['gpu'] >= gpu_needed:
# 直接分配
job_id = self.allocate_resources(code_files, gpu_needed, memory_needed)
return job_id
else:
# 加入队列等待
job_id = self.queue_job(code_files, resource_request)
return job_id
def allocate_resources(self, code_files, gpu_needed, memory_needed):
"""分配资源并启动作业"""
# 选择节点
target_nodes = self.select_nodes(gpu_needed, memory_needed)
# 准备作业环境
job_dir = self.prepare_job_environment(code_files)
# 生成分布式训练脚本
if gpu_needed > 1:
launch_script = self.generate_distributed_script(
job_dir,
target_nodes,
gpu_needed
)
else:
launch_script = self.generate_single_gpu_script(job_dir)
# 提交作业
job_id = self.launch_job(launch_script, target_nodes)
return job_id
4.4 实验结果自动分析
实验执行完成后,实验智能体还需要对原始结果进行分析和提炼:
def analyze_results(self, raw_results, experiment_plan):
"""分析实验结果"""
analysis = {}
# 根据实验类型选择分析方法
experiment_type = experiment_plan.get('type', 'unknown')
if experiment_type == 'model_comparison':
analysis = self.analyze_comparison(raw_results)
elif experiment_type == 'ablation_study':
analysis = self.analyze_ablation(raw_results)
elif experiment_type == 'hyperparameter_search':
analysis = self.analyze_optimization(raw_results)
elif experiment_type == 'distillation_experiment':
analysis = self.analyze_distillation(raw_results)
# 添加统计显著性检验
analysis['statistical_tests'] = self.run_statistical_tests(raw_results)
# 生成可视化
analysis['figures'] = self.generate_figures(raw_results, analysis)
# 提炼关键发现
analysis['key_findings'] = self.extract_key_findings(
raw_results,
analysis,
experiment_plan['hypothesis_id']
)
return analysis
在FA0042论文的案例中,实验智能体发现了一个反直觉的结果:学生模型在某些长文档检索任务中的表现反超了教师模型。这一发现被如实记录,并成为论文的核心贡献。
第五章 写作智能体:从数据到学术论文
5.1 论文结构生成
写作智能体负责将实验数据转化为规范的学术论文。在FARS的实验中,它需要在9天半内完成100篇论文的撰写,平均每篇论文的生成时间约2.3小时。
class WritingAgent:
def __init__(self, model_api, citation_manager):
self.model_api = model_api
self.citation_manager = citation_manager
self.paper_templates = self.load_templates()
def generate_paper(self, hypothesis, experiment_plan, results, storage):
"""生成完整论文"""
# 1. 构建论文框架
outline = self.create_outline(hypothesis, experiment_plan, results)
# 2. 逐章节生成
paper_sections = {}
for section in outline['sections']:
if section == 'abstract':
paper_sections['abstract'] = self.write_abstract(
hypothesis, results, outline
)
elif section == 'introduction':
paper_sections['introduction'] = self.write_introduction(
hypothesis, storage
)
elif section == 'related_work':
paper_sections['related_work'] = self.write_related_work(
hypothesis, storage
)
elif section == 'methodology':
paper_sections['methodology'] = self.write_methodology(
experiment_plan
)
elif section == 'experiments':
paper_sections['experiments'] = self.write_experiments(
experiment_plan, results
)
elif section == 'results':
paper_sections['results'] = self.write_results(
results, hypothesis
)
elif section == 'discussion':
paper_sections['discussion'] = self.write_discussion(
results, hypothesis, storage
)
elif section == 'conclusion':
paper_sections['conclusion'] = self.write_conclusion(
hypothesis, results
)
# 3. 生成参考文献
paper_sections['references'] = self.generate_references(
hypothesis, results, storage
)
# 4. 整合为完整论文
full_paper = self.assemble_paper(
outline,
paper_sections,
results.get('figures', [])
)
return full_paper
5.2 拥抱失败的写作哲学
FARS最引人注目的特点之一是鼓励报告失败结果。在传统学术体系中,“阴性结果”往往难以发表,导致大量科研资源的浪费。FARS的设计理念认为,只要假设合理,验证结果无论正负都构成有意义的知识。
def write_discussion(self, results, hypothesis, storage):
"""讨论章节:诚实地分析结果,包括失败"""
# 检查是否支持原假设
hypothesis_supported = self.check_hypothesis_support(results, hypothesis)
if hypothesis_supported:
# 正向结果讨论
discussion = self.write_success_discussion(results, hypothesis)
else:
# 负向结果讨论 - 同样重要
discussion = self.write_failure_discussion(results, hypothesis)
# 分析失败原因
failure_analysis = self.analyze_failure(results, hypothesis)
discussion['failure_analysis'] = failure_analysis
# 提出可能的改进方向
discussion['future_directions'] = self.suggest_improvements(
failure_analysis
)
# 明确说明:即使失败,也为社区提供了有价值的信息
discussion['value_statement'] = (
"While the original hypothesis was not supported, "
"these negative results provide important constraints "
"on the underlying theory and can prevent redundant "
"investigations by other researchers."
)
return discussion
5.3 引文网络的自动化构建
写作智能体需要为论文生成准确的参考文献。这要求它能够从共享文件系统中检索相关文献,并构建合理的引文网络。
class CitationManager:
def __init__(self, literature_db):
self.literature_db = literature_db
self.citation_style = 'iclr' # 默认使用ICLR格式
def generate_references(self, hypothesis, results, storage):
"""生成参考文献列表"""
references = []
# 1. 引用基础文献(领域经典)
foundational_papers = self.literature_db.search(
domain=hypothesis['domain'],
sort_by='citations',
limit=5
)
references.extend(foundational_papers)
# 2. 引用近期相关工作
recent_papers = self.literature_db.search(
domain=hypothesis['domain'],
time_range='2025-2026',
sort_by='date',
limit=10
)
references.extend(recent_papers)
# 3. 引用方法论文(实验中使用的方法)
methods_used = results.get('methods_used', [])
for method in methods_used:
method_papers = self.literature_db.search_by_method(method)
references.extend(method_papers)
# 4. 引用数据集论文
datasets_used = results.get('datasets_used', [])
for dataset in datasets_used:
dataset_papers = self.literature_db.search_by_dataset(dataset)
references.extend(dataset_papers)
# 5. 去重和格式化
unique_refs = self.deduplicate(references)
formatted_refs = self.format_citations(unique_refs, self.citation_style)
return formatted_refs
第六章 技术栈与资源调度深度解析
6.1 完整的FARS技术栈
根据公开信息,FARS系统的完整技术栈如下:
| 层级 | 技术组件 | 说明 |
|---|---|---|
| 模型层 | Claude、GPT-4、Gemini | 闭源模型API调用 |
| 自研后训练模型 | 部分链路使用 | |
| 智能体框架 | 自定义Agent框架 | 基于状态机的多智能体系统 |
| 通信层 | 共享文件系统 | 替代传统消息队列 |
| 计算层 | 160卡GPU集群 | 封装为统一调用接口 |
| PyTorch、TensorFlow | 深度学习框架 | |
| 存储层 | 分布式文件系统 | 存储代码、数据、结果 |
| Git | 版本控制和开源 | |
| 观测层 | 直播系统 | 实时展示系统工作状态 |
| GitHub Pages | 论文和代码发布 |
6.2 资源调度与成本控制
FARS在9天半内消耗了114亿Token,总成本10.4万美元,平均每篇论文成本约1000美元。这一成本控制得益于精密的资源调度策略:
class ResourceManager:
def __init__(self, budget_constraint=104000): # 总预算10.4万美元
self.budget_constraint = budget_constraint
self.spent = 0
self.token_prices = {
'claude': 0.015, # 每千token价格(示例)
'gpt4': 0.03,
'gemini': 0.025,
'internal': 0.005
}
def allocate_resources(self, task):
"""根据任务类型和重要性分配资源"""
task_priority = task.get('priority', 1)
task_type = task.get('type')
# 不同类型的任务使用不同的模型
if task_type == 'literature_review':
# 文献综述需要大量上下文,使用Claude
model = 'claude'
estimated_tokens = task.get('estimated_tokens', 50000)
elif task_type == 'code_generation':
# 代码生成需要高精度,使用GPT-4
model = 'gpt4'
estimated_tokens = task.get('estimated_tokens', 20000)
elif task_type == 'experiment_analysis':
# 实验分析可以使用内部模型
model = 'internal'
estimated_tokens = task.get('estimated_tokens', 10000)
elif task_type == 'paper_writing':
# 论文写作需要平衡质量和成本
if task_priority > 0.8:
model = 'gpt4'
else:
model = 'gemini'
estimated_tokens = task.get('estimated_tokens', 30000)
# 计算预估成本
estimated_cost = estimated_tokens * self.token_prices[model] / 1000
# 检查预算
if self.spent + estimated_cost > self.budget_constraint:
# 预算不足,尝试降级
if model != 'internal' and task_priority < 0.5:
model = 'internal'
estimated_cost = estimated_tokens * self.token_prices[model] / 1000
return {
'model': model,
'estimated_tokens': estimated_tokens,
'estimated_cost': estimated_cost,
'allocated': self.spent + estimated_cost <= self.budget_constraint
}
6.3 并行处理与任务调度
FARS系统能够同时处理多个研究项目。在9天半内生成244个假设、完成100篇论文,意味着系统高度并行化。
class TaskScheduler:
def __init__(self, max_concurrent=10):
self.max_concurrent = max_concurrent
self.active_tasks = []
self.task_queue = PriorityQueue()
self.completed_tasks = []
def submit_hypothesis(self, hypothesis, priority=1):
"""提交研究假设到队列"""
self.task_queue.put((priority, hypothesis))
def run_scheduler(self):
"""主调度循环"""
while not self.task_queue.empty() or self.active_tasks:
# 检查是否有空闲智能体
while len(self.active_tasks) < self.max_concurrent and not self.task_queue.empty():
priority, hypothesis = self.task_queue.get()
task = self.start_task(hypothesis)
self.active_tasks.append(task)
# 轮询活动任务状态
for task in self.active_tasks[:]:
if task.is_complete():
self.active_tasks.remove(task)
self.completed_tasks.append(task)
# 如果任务失败,可能需要重新调度
if not task.success and task.retry_count < 3:
task.retry_count += 1
self.task_queue.put((priority-0.1, task.hypothesis))
# 短暂休眠避免CPU空转
time.sleep(1)
第七章 质量评估体系
7.1 自动化审稿系统
FARS产出的论文经过了斯坦福AI审稿系统(Agentic Reviewer)的评估。该系统按ICLR标准进行盲审,FARS论文平均得分5.05分,高于人类投稿平均水平(4.21分)。
class AgenticReviewer:
"""模拟的AI审稿系统"""
def review_paper(self, paper):
"""对论文进行多维度评审"""
scores = {}
# 维度1:创新性
scores['novelty'] = self.evaluate_novelty(paper)
# 维度2:技术正确性
scores['correctness'] = self.verify_technical_correctness(paper)
# 维度3:实验充分性
scores['experiments'] = self.evaluate_experiments(paper)
# 维度4:写作质量
scores['writing'] = self.evaluate_writing(paper)
# 维度5: reproducibility
scores['reproducibility'] = self.check_reproducibility(paper)
# 综合评分
weights = {
'novelty': 0.25,
'correctness': 0.25,
'experiments': 0.20,
'writing': 0.15,
'reproducibility': 0.15
}
overall = sum(scores[d] * weights[d] for d in scores)
return {
'scores': scores,
'overall': overall,
'comments': self.generate_comments(paper, scores),
'decision': 'accept' if overall >= 5.0 else 'reject'
}
7.2 人工审核门槛
尽管系统自动产出论文,但FARS团队设置了严格的人工审核门槛:每篇论文在上传arXiv之前,需经过至少3位具有5年以上研究经验的团队成员审核,并在首页明确标注为AI生成。
这一机制确保了系统的输出不会污染学术社区,同时为AI科研保留了“人类监督”的安全垫。
第八章 与竞品的技术对比
8.1 同类系统对比表
| 维度 | FARS (Analemma) | AI Scientist (Sakana) | AI-Researcher (HKU) |
|---|---|---|---|
| 发布年份 | 2026.02 | 2024.08 (v1), 2025.04 (v2) | 2025 |
| 智能体数量 | 4个 (Ideation, Planning, Experiment, Writing) | 3个 (Idea, Experiment, Write) | 未明确 |
| 通信机制 | 共享文件系统 | 数据库+消息队列 | 未明确 |
| 算力规模 | 160张GPU | 未明确 | 未明确 |
| 论文产出 | 100篇/9.5天 | 约15美元/篇 | 多领域覆盖 |
| 质量验证 | 斯坦福审稿系统5.05分 | v1被评"本科生水平",v2通过ICLR Workshop | NeurIPS 2025 Spotlight |
| 开源策略 | 代码数据全公开 | 开源 | 产品化版本Novix |
| 特点 | 直播透明运行、鼓励失败报告 | 成本极低 | 覆盖CV/NLP/数据挖掘 |
8.2 核心差异分析
FARS与Sakana AI Scientist的关键差异在于:
-
设计理念:AI Scientist遵循学术出版惯例生产论文,FARS回归研究第一性原理,以可验证假设为单位组织产出
-
透明性:FARS首次实现大规模公开直播,系统工作过程完全透明
-
失败报告:FARS鼓励报告失败结果,并视之为有价值知识
-
领域聚焦:FARS明确聚焦AI4AI,Sakana和HKU覆盖更广领域但深度受限
第九章 未来展望与技术挑战
9.1 从AI4AI到AI4Science
当前FARS聚焦于AI领域的研究(AI4AI),因为AI实验可以完全在计算机上完成,天然适合自动化。但要扩展到其他学科(物理、生物、化学),需要解决以下技术挑战:
- 物理实验接口:需要机器人自动操作实验设备
- 数据采集自动化:需要传感器和自动化测量系统
- 领域知识建模:需要将各学科知识形式化为机器可理解的形式
9.2 人类-AI协作新范式
FARS的出现并非要取代人类研究者,而是重塑人机协作方式:
- 人类:设定研究方向、提供资源、评估产出质量
- FARS:执行具体研究、快速迭代假设、规模化产出
正如团队所言:“科学的下一个时代不仅由更好的灵感塑造,更将由能够推理、实验和迭代的系统定义。”
9.3 伦理与规范挑战
随着AI科研系统的普及,学术社区面临新的伦理规范问题:
- AI生成论文的标识问题:FARS的做法是在首页明确标注
- 学术评价体系的调整:如何评估AI产出的贡献?
- 科研资源分配:拥有大规模算力的机构可能占据绝对优势
结语
FARS系统的9天半直播实验,不仅产出了100篇学术论文,更重要的是向世界展示了科研工业化的可能性。通过四智能体流水线、共享文件系统通信、160卡GPU集群调度、以及114亿Token的高效利用,FARS将科学发现从依赖个人灵感的“手工作坊”模式,转变为可规模化、可复制的“工业生产”模式。
技术细节的背后,是创始团队对“研究系统”本质的深刻理解:高效可靠地拓展知识边界。在这一理念指导下,FARS鼓励报告失败、追求透明运行、强调规模效应,为未来AI科学家的普及完成了关键的概念验证。
当OpenAI将“全自主AI研究员”写入2028年路线图,当智源研究院预测AI for Science正在从Copilot向AI Scientist迁移,FARS的实验结果提醒我们:科学发现的未来,将是人类智慧与机器效率的深度融合。在这个无限问题构成的世界里,我们需要构建的正是这种无限的心智。
附录:核心技术参数汇总
| 参数项 | 数值 | 说明 |
|---|---|---|
| 运行时长 | 228小时33分 | 9天半完成100篇论文 |
| 生成假设 | 244个 | 筛选后执行 |
| 产出论文 | 100篇 | 短论文形式 |
| Token消耗 | 114亿 | 包括推理和生成 |
| 总成本 | 10.4万美元 | 约75万人民币 |
| 单篇成本 | 约1000美元 | 含算力和API费用(单篇约6888人民币) |
| GPU规模 | 160卡 | 封装为统一工具 |
| 质量评分 | 5.05/7 | 斯坦福审稿系统评估 |
| 人类基准 | 4.21/7 | ICLR人类投稿平均 |
| 研究方向 | 9个 | 预设+自由探索 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)