AI并非万能:在疾病预测中,传统统计学为何依然不可替代?
牛津大学研究团队在《柳叶刀·数字健康》发表评论指出,在医学风险预测中,传统统计学方法(如逻辑回归)与机器学习(如XGBoost)各有优势:前者适用于变量少、关系明确的场景(约20个指标),解释性强且不易过拟合;后者则擅长处理高维复杂数据。研究强调,盲目使用复杂AI模型可能导致过拟合,而简单线性模型在特定场景下表现更优。最佳实践是结合两者优势——先用机器学习筛选关键变量,再用统计模型构建可解释的预测
在当今的医疗科技领域,人工智能(AI)和机器学习似乎成了解决一切问题的“银弹”。随着健康数据的爆炸式增长和计算成本的降低,越来越多的研究者倾向于使用复杂的机器学习算法来构建疾病风险预测模型。我们常常默认:越先进的技术,效果一定越好。
然而,事实果真如此吗?来自牛津大学的研究团队近期在顶刊《柳叶刀·数字健康》(The Lancet Digital Health)上发表了一篇颠覆认知的评论文章。他们指出,在医学研究中,盲目追逐复杂的机器学习模型不仅可能徒劳无功,甚至可能带来错误的结论。对于很多临床问题,那些被认为“过时”的传统统计学方法,反而能吊打最先进的AI算法。

这场关于“AI与传统统计学”的争论由来已久,但究竟何时该用AI,何时该坚持传统?本文将为你揭开迷雾,找到最优解。
1. AI vs. 统计学:一场被误解的“新旧之争”
在临床医学中,我们最常做的任务就是“算命”——即预测一个人患某种疾病的风险(分类任务)或者估计某个具体的数值(回归任务)。
为了完成这个任务,我们手头通常有两种武器:
- 传统统计学方法:比如逻辑回归(Logistic Regression)或Cox比例风险模型。它们像是一把精准的手术刀,结构清晰,刀法透明。
- 机器学习方法:比如大名鼎鼎的XGBoost。它们像是一个拥有超级大脑的黑盒,能处理海量杂乱的信息,但你很难看清它内部是如何运作的。
研究指出,这两者并没有绝对的优劣之分,而是各有各的“主场”。
如果你的研究已经有了明确的假设,比如你只想研究“吸烟”和“肺癌”之间的关系,且手头的变量并不多(例如只有20个左右的指标),那么传统统计学方法是绝对的王者。特别是当变量和疾病风险之间呈现简单的线性关系(即A增加,B就按比例增加)时,传统模型的表现往往优于复杂的AI模型。
反之,如果你面对的是海量的数据指标(例如成百上千个基因位点或蛋白质数据),且你根本不知道哪些指标有用,也不知道它们之间有什么复杂的非线性关系(即A增加,B可能先降后升,还受到C的影响),这时候就是机器学习大显身手的时候了。它擅长在没有任何先验知识的情况下,从数据大海中“暴力”挖掘出潜在的规律。
为了让你更直观地理解,我们可以通过下表快速对比两者的适用场景:
|
特征维度 |
传统统计学方法 (如 Cox 回归) |
机器学习方法 (如 XGBoost) |
|
适用场景 |
已有明确假设,验证已知理论 |
探索未知,从海量数据中生成新假设 |
|
变量数量 |
少量 (如约20个) |
大量 (高维数据) |
|
数据关系 |
简单的线性关系 |
复杂的非线性关系,包含未知交互作用 |
|
可解释性 |
高(清晰透明,易于医生理解) |
低(通常是“黑盒”,难以解释原因) |
2. 拒绝“杀鸡用牛刀”:为何越复杂的模型越容易翻车?
很多人认为,既然AI模型更复杂、更“聪明”,那它至少能包含传统模型的功能吧?为什么说简单的反而更好?
这里涉及到一个核心的科学原则——奥卡姆剃刀原理(Occam’s razor):如无必要,勿增实体。简单来说,如果一个简单的方法能解决问题,就不要用复杂的。
复杂且强大的机器学习模型有一个致命的弱点,那就是容易“过拟合”(Overfitting)。这就好比一个学生记性太好,为了应付考试,他死记硬背了练习册里每一道题的答案(训练集),甚至把题目中的错别字(噪声)都背下来了。结果一到正式考试(测试集/未知数据),题目稍微变了一点点,他就彻底懵了,考分一塌糊涂。
相比之下,结构简单的线性回归模型虽然“脑容量”有限,但它学到的是通用的规律,反而能在面对新数据时表现得更稳健。有研究已经证实,当变量间存在直接的线性关系时,最基础的线性回归模型甚至能击败复杂的XGBoost机器。
因此,盲目增加模型复杂度,不仅不能提升预测准确率,反而会因为“想太多”而导致在实际应用中失效。
3. 图解最佳实践:强强联手才是王道
既然AI擅长“广撒网”发现新线索,而传统统计学擅长“精准打击”且解释性强,那为什么不把它们结合起来呢?
最新的研究趋势表明,“混合双打”模式往往能取得最佳效果。这种模式的核心思路是:先让机器学习去处理海量、复杂的数据,筛选出真正重要的变量,然后把这些精华变量交给传统统计学模型来进行最终的风险预测。
如图[1]所示,研究人员展示了一套标准化的分析流水线。首先,在训练数据阶段,利用机器学习模型(如XGBoost)强大的计算能力,从成千上万个潜在指标中进行初步筛选。为了不让AI变成“黑盒”,这里引入了可解释性工具(如SHAP值),它能告诉我们AI究竟看重哪些指标。接下来,将AI筛选出的“Top级”特征与医学上已知的经典预测因子合并,去除重复和高相关性的冗余信息。最后,将这组精选出来的变量输入到经典的Cox统计模型中,构建出一个既包含新发现、又具备传统模型稳健性的“增强版”预测模型。
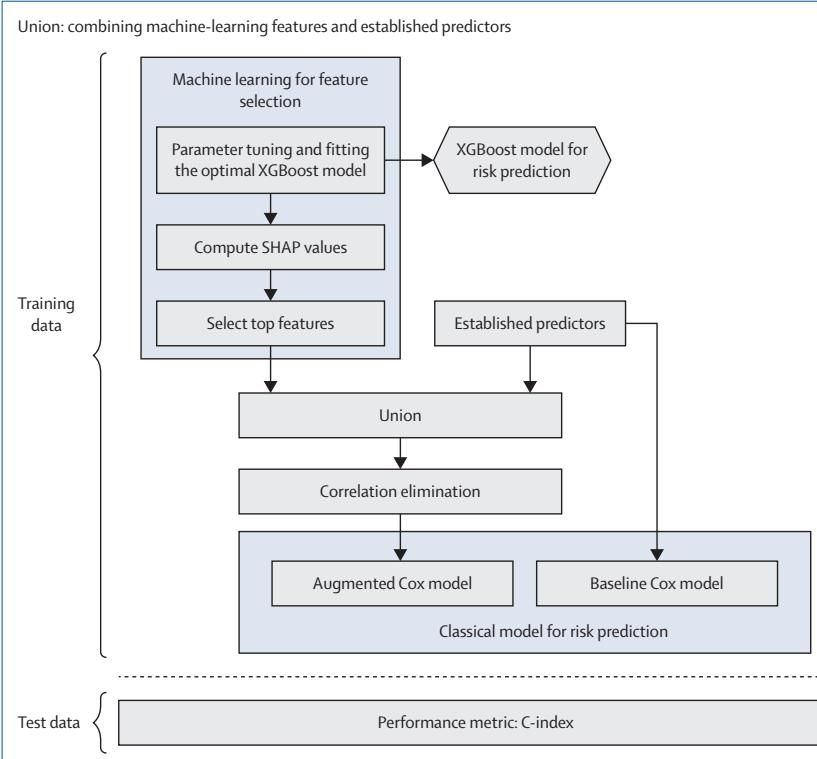
这种策略完美地平衡了二者的优缺点:利用机器学习解决了传统方法处理不了的高维数据挖掘问题,同时又保留了统计学模型清晰、可解释、不易过拟合的特性。在预测骨髓瘤的研究案例中,研究团队正是利用这套流程,从数千种蛋白质中精准锁定了最关键的十种,构建出了高效的预测模型。
4. 给未来的实战启示:不仅要“算得准”,更要“看得懂”
对于医疗健康领域的从业者和关注者来说,这项研究带来了几个至关重要的启示:
4.1 拒绝“垃圾进,垃圾出”
很多AI鼓吹者声称可以把所有原始数据一股脑丢给模型,让它自己去学习。但这在医学上是行不通的。研究团队在使用英国生物样本库(UK Biobank)的数据时,并没有直接使用原始的7000多个变量,而是经过人工精心筛选和清洗,保留了约1700个有意义的变量。如果不了解数据的医学背景,AI很可能会抓取到错误的“噪音”——比如它可能错误地认为“做过某种扫描”本身就是患病的标志,而忽略了真正的病理原因。
4.2 解释性是信任的基石
一个预测模型如果要真正应用到临床,医生和患者必须能“看得懂”。如果AI只是冷冰冰地给出一个风险数值,却说不出依据,医生是不敢轻易采纳的。这也是为什么传统统计学模型依然屹立不倒的原因——它的每一个参数都有明确的医学含义。未来的方向,一定是让AI变得更透明(如利用SHAP值),或者让AI回归辅助角色,服务于可解释的统计模型。
4.3 必须经过外部验证
无论模型吹得多么天花乱坠,如果在独立的新数据集(外部验证)上表现拉胯,那都是空谈。所有的模型,无论是AI还是传统统计学,都必须接受陌生数据的严苛检验,以排除因特定数据偏差导致的“假高分”。
结语
在这个算法统治的时代,我们依然不能丢掉对科学原理的敬畏。AI确实为医学研究打开了通往未知的大门,帮我们在海量数据中“淘金”,但它并不是万能的“神谕”。
最好的未来,或许不是AI彻底取代统计学,而是两者握手言和。当AI的探索能力遇上统计学的严谨逻辑,我们才能在复杂的生命迷宫中,找到那条通往健康的最近路径。对于下一次体检报告上的风险预测,你是不是也希望能看到一个既精准又“说人话”的解释呢?
本文申明:本文使用“超能文献”(suppr.wilddata.cn)进行文献的搜集、文献翻译以及文献总结,。
论文信息
- 标题:When to and when not to use machine learning in risk prediction models.
- 论文链接:https://doi.org/10.1016/j.landig.2025.100954
- 发表时间:2026-2-12
- 期刊/会议:The Lancet. Digital health
- 作者:Lei Clifton, John Powell, David A Clifton, Aziz Sheikh

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献292条内容
已为社区贡献292条内容

所有评论(0)