Training-free多模态大模型选题指南(非常详细),适合学生的研究方向从入门到精通,收藏这一篇就够了!
开始之前,说说自己对training-free一类工作的看法。虽然说training-free一直都是大家争议比较多的一类工作,但是个人觉得training-free不是不能做,事实上好的training-free工作是有很多的(diffusion model这边的classifier guidance、一众editing工作)。
一、前言
开始之前,说说自己对training-free一类工作的看法。
虽然说training-free一直都是大家争议比较多的一类工作,但是个人觉得training-free不是不能做,事实上好的training-free工作是有很多的(diffusion model这边的classifier guidance、一众editing工作)。
而且training-free类的工作限制比training-based会更多,其实并不是简单的魔改、调参就能做好的一件事。
如果你能做training,你就能用额外的model parameters、额外的data pairs去建模原生模型没有的映射关系,甚至在benchmark上的一些performance gain,也可以通过堆积参数量、调超参、调数据等多种方式获取,毕竟deep learning是data-driven的学科,有新的数据就意味着能够带来新的东西;
如果你做training-based,前面的这些额外的映射关系必须要能从原生模型上获取,比方说LLM通过prompt engineering获取一些额外的输出、diffusion model通过inversion从特定的image中获取一些能够控制采样过程的特征,等等。
——不管是什么这都需要你对于原生模型的机制有非常深刻的理解和认识,而并非能通过「力大砖飞」的方式暴力调参。
当然training-free的好处也非常直接,无需训练,实验代价被极大程度降低了,可以说跑一次inference就是一次实验,确实非常适合高校、缺少算力资源的研究者去做。
在「多模态大模型」的语境下,training-free可以是MLLM,也可以是text-to-image diffusion models,下面就围绕这两种主流的研究课题,针对一些我自己关注的training-free工作做一个简单的分享。
二、MLLM中的Training-Free工作有哪些值得Follow?
MLLM中的training-free研究主要对logits分布、KV-Cache这些和LLM高度相关的机制上,针对特定的任务再去做优化。
这一类工作的核心逻辑在于:训练好的LLM已经具备了world knowledge,只是在推理时容易被language prior带偏(MLLM hallucination的动机)或者存在计算量冗余的问题(LLM acceleration一类工作的动机)。
所以training-free技术在这个过程中的作用,主要还是在LLM的基础范式上进一步调优。
(一)MLLM Hallucination
最为经典的training-free工作就是做MLLM hallucination,也就是通过inference-time optimization来解决多模态模型中的幻觉问题,让模型真正关注到visual embedding中存在的信息,而并非因为language prior输出存在幻觉的内容。
目前的套路主要分三类:contrastive decoding、self-correction和attention intervention。
第一类是contrastive decoding。
其核心假设在于:幻觉往往来源于语言模型的language prior,而真实视觉感知应该是实实在在的aptialgrounding。
这类工作的代表作有VCD(visual contrastive decoding) 和DCD,它们的套路是在推理时构造一个「坏样本」分布(比如把原图mask掉、或者加噪声),得到logits ,然后用正常生成的logits 减去它,公式上近似为。这样就把那些带有幻觉先验给抑制了。
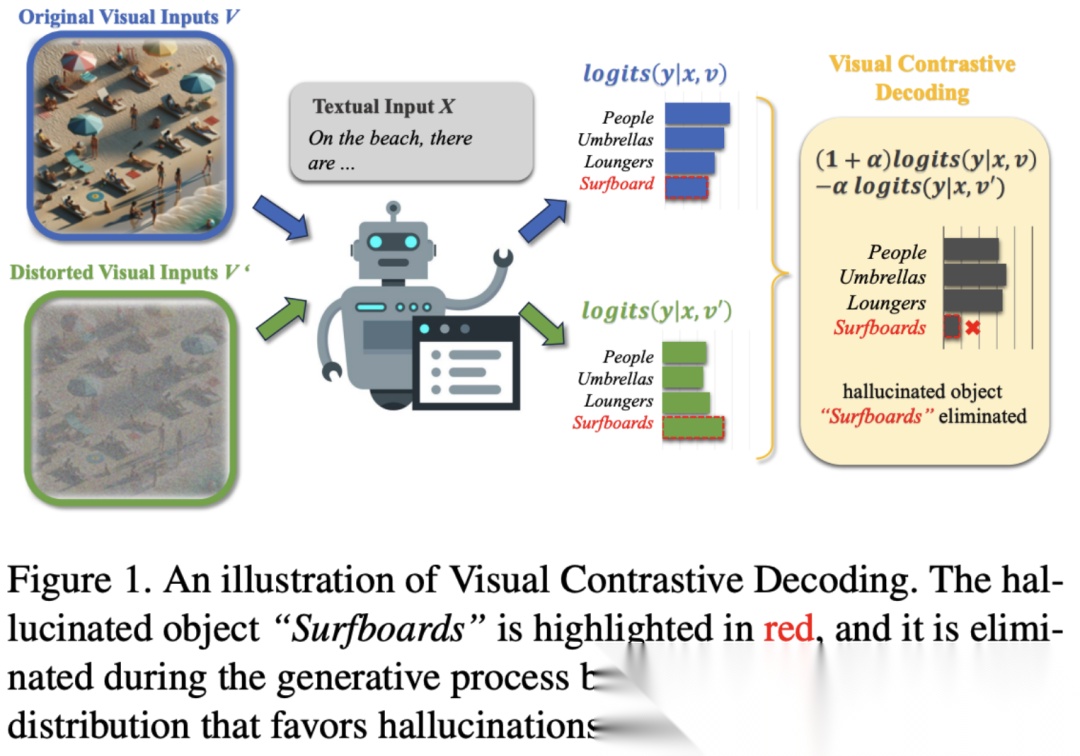
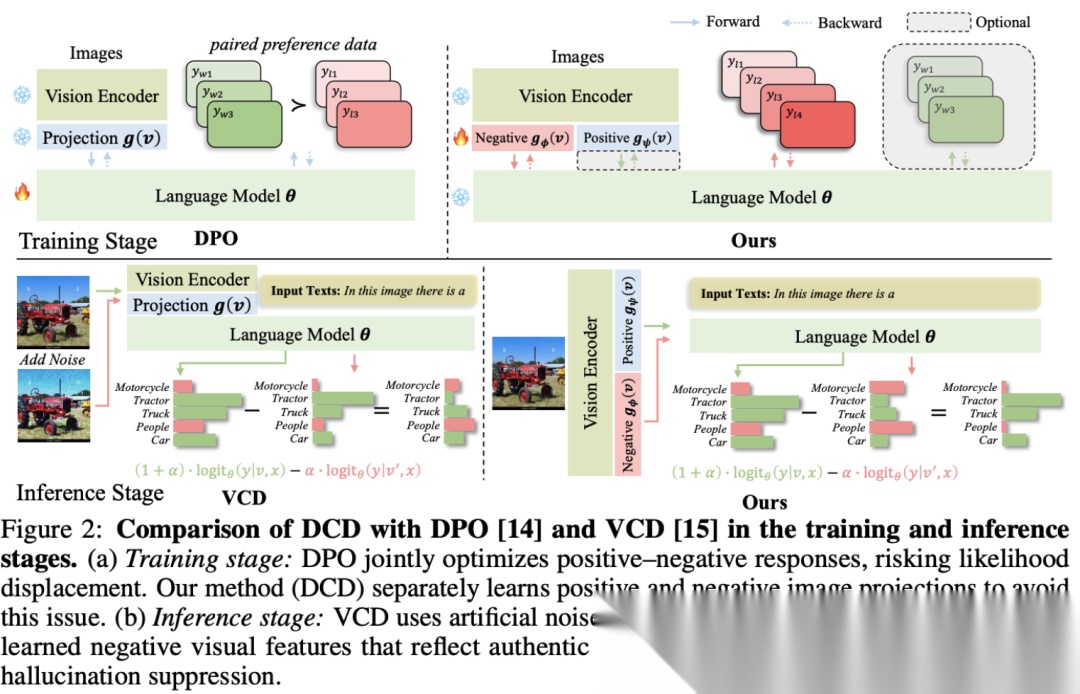
第二类是self-correction比较直观。
比如CODE,它让模型先生成一个description,再基于这个description去回答问题。这利用了类似于CoT(chain-of-thought)的思想,强制模型在做推理前先align视觉信息。
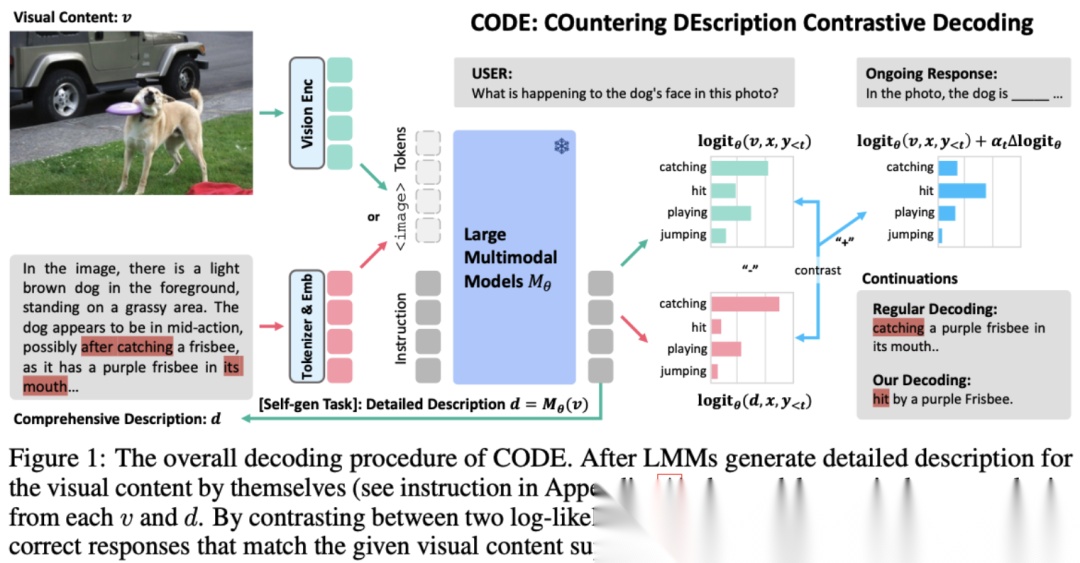
第三类是attention intervention,主要围绕LLM中attention的机制做文章。
比如iTaD,它通过分析attention map发现,当模型出现幻觉时,对image token的注意力会显著下降。于是它的做法是:直接在inference阶段强行把attention权重拉回来。
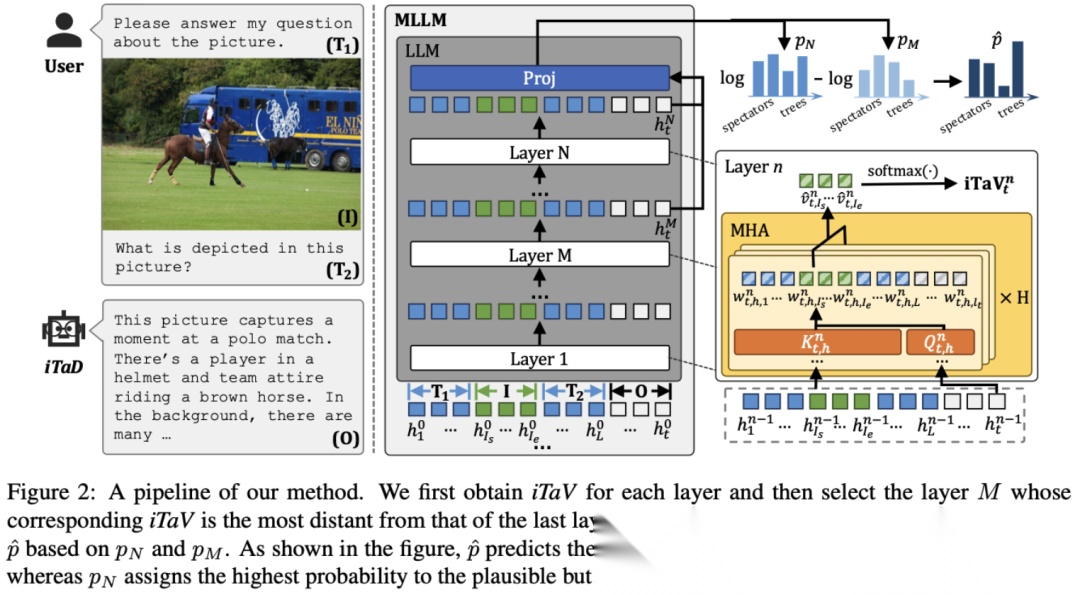
(二)LLM Acceleration
针对LLM acceleration,核心战场是visual token pruning。
由于ViT会产生大量visual tokens(例如LLaVA-1.5有576个,有的甚至几千个),但LLM处理文本只需要很少的tokens。
所以这类visual token pruning的套路通常是设计一个scorer,保留高分token,抛弃或融合低分token,从而实现加速的目的。
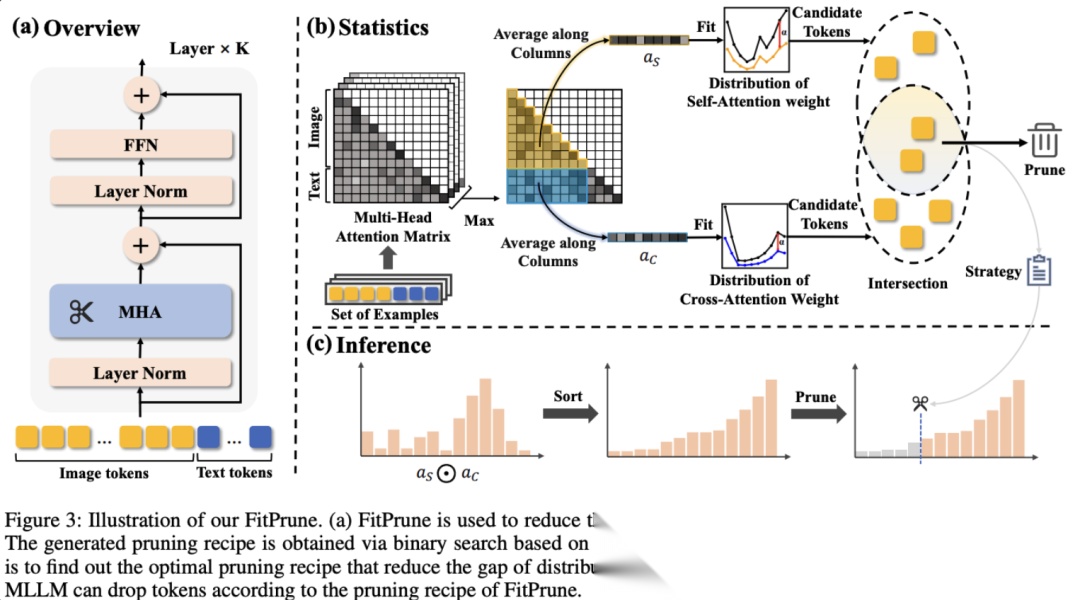
代表工作如FastV、FiTPrune。
FastV发现很多visual tokens在深层layer的attention权重极低,属于冗余计算,直接把它去掉并不影响性能。

FitPrune则引入了统计学方法,用少量样本拟合出剪枝策略。这里的一个gap是,剪枝往往会导致幻觉上升,如何平衡efficiency和hallucination是个关键的设计问题。
三、Text-to-Image Diffusion Models中的Training-Free有哪些值得Follow?
文生图的training-free研究其实也很多,无非围绕U-Net的几个关键机制:attention机制(self-和cross-attention机制的侧重都有所不同)、inversion、noise prediction(diffusion guidance类方法),等等。
下面也围绕几个主流方向的training-free工作进行展开:
- • image editing
- • controllable image generation
- • personalized image generation
- • video generation acceleration
- • video-to-video editing
(一)Image Editing
Image editing这个任务是text-to-image generation中training-free工作最集中的地方,也是最卷的地方,主要范式也氛围attention injection和inversion-based两种。
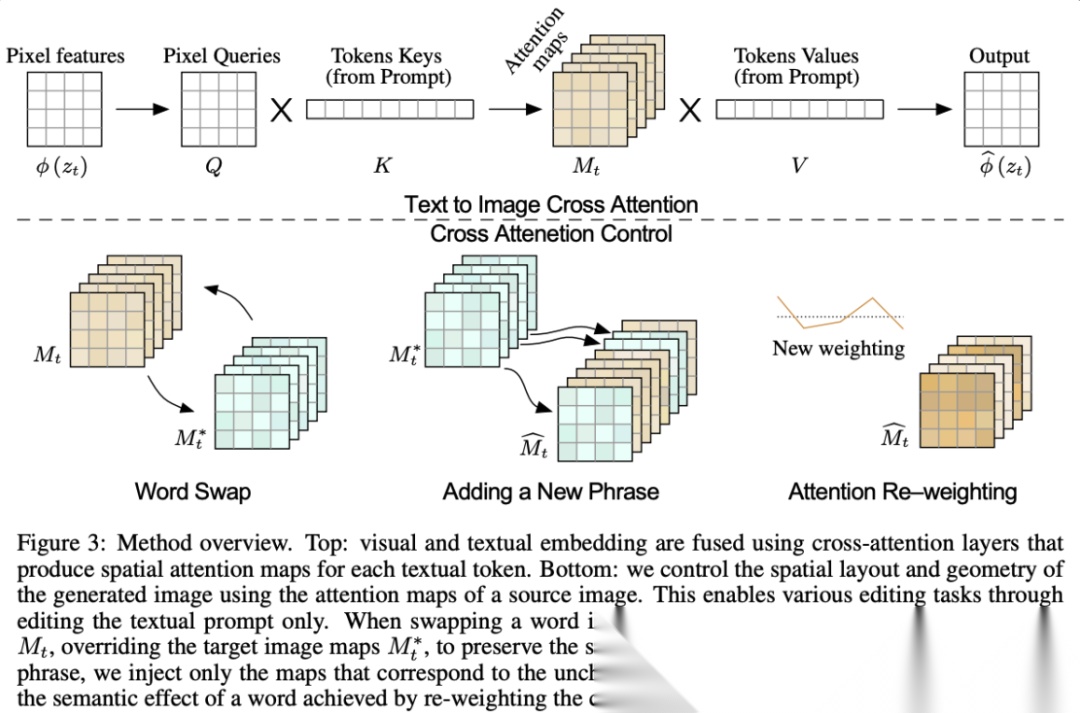
attention injection的代表作是Prompt-to-Prompt,这个也是diffusion-based image editing的开山之作之一了。
它的逻辑非常直观:如果你想把「猫骑自行车」改成「猫骑摩托车」,你应该保留原图的空间布局的同时,从text prompt的视角去替换对应的semantic。
具体做法是在生成新图时,Prompt-to-Prompt会强制把前几个step的cross-attention map替换成原图的attention map。这样spatial layout就在sampling中给强行enforce了,随后再通过交换「自行车」和「摩托车」的cross-attention map,来实现改变语义的目的。
inversion-based的代表是Null-text Inversion。
对于真实图片的编辑,你必须先求出它对应的latent noise trajectory(即inversion)。但常规DDIM inversion很难完美重建,Null-text巧妙地优化unconditional embedding(即null-text),在不改动模型权重的情况下实现了高保真的editing。

(二)Controllable Image Generation
针对可控生成(controllable generation),主要范式有diffusion guidance。
diffusion guidance比如BoxDiff,不需要像ControlNet那样训练,而是直接在inference阶段计算loss,然后通过更新每个step预测的noisy latents,来实现引导整个sampling trajectory的目的。
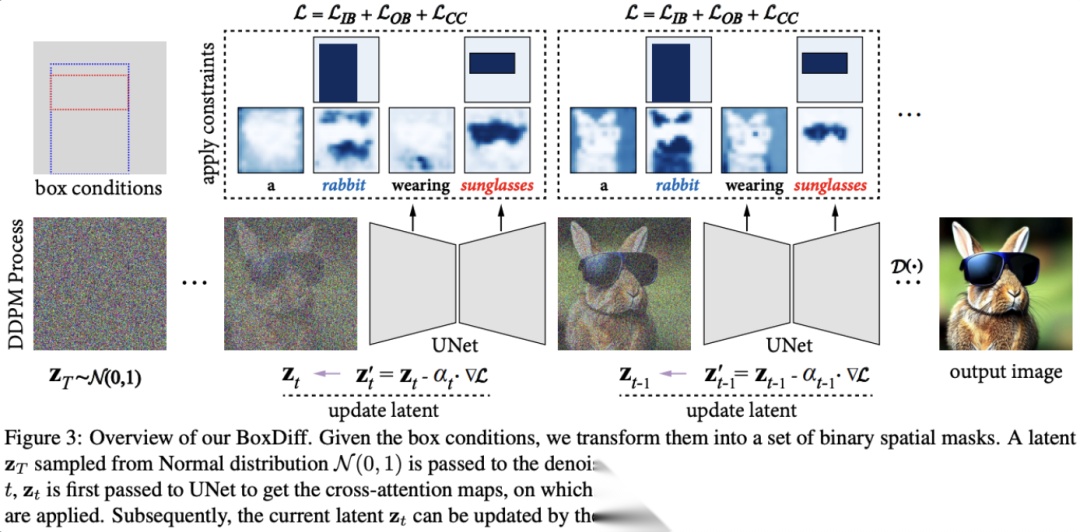
给定一个bounding box,我们计算对应object token的attention map在box区域内的能量,如果能量溢出,就通过gradient descent更新latent,把物体引导回框里。
更多的training-free的controllable generation工作在我的往期专栏文章中有更详细的介绍,感兴趣的朋友欢迎移步。
(三)Personalized Image Generation
针对定制化生成(personalization),更多的还是inversion-based和attention-based的方法。
inversion-based的方法主要想将reference image的主体信息通过inversion,反演到sampling trajectory的不同step中,然后在采样的时候去enforce这些信息;
attention-based的方法则是利用attention机制中query、key、value通常控制不同特性的特点,通过显式替换变量来引入guidance。
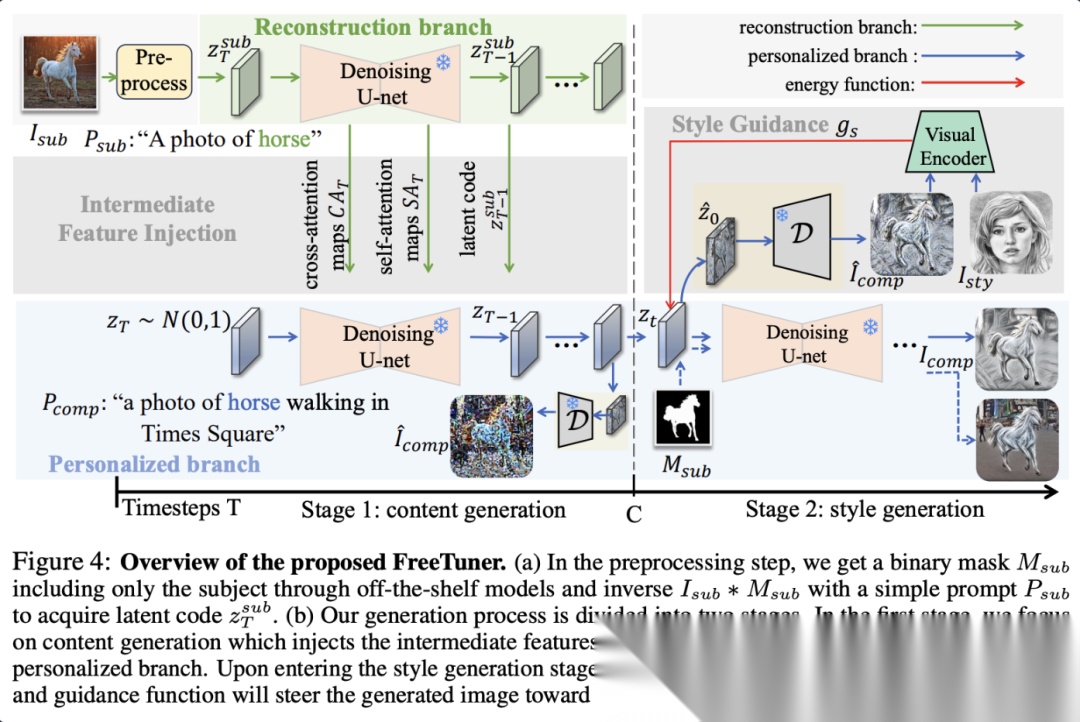
代表工作比如FreeTuner。它们不需要DreamBooth那样的fine-tuning,而是利用model内部的deep feature具有很强的语义对应关系来实现personalization。
在生成主体时,把reference image的self-attention key或value注入到生成过程中。
(四)Video Generation Acceleration
针对视频加速,核心思路还是如何剔除sampling过程中的冗余,并在尽可能小地损失性能的前提下,复用更多的特征来实现加速。
核心逻辑是:视频相邻帧之间(spatial redundancy)以及diffusion相邻step之间(temporal redundancy)变化通常很小,加速就是通过精简这些redundancy来实现的。
具体来说,DeepCache指出U-Net的深层feature变化缓慢,可以隔几步计算一次,所以中间步直接复用cache。
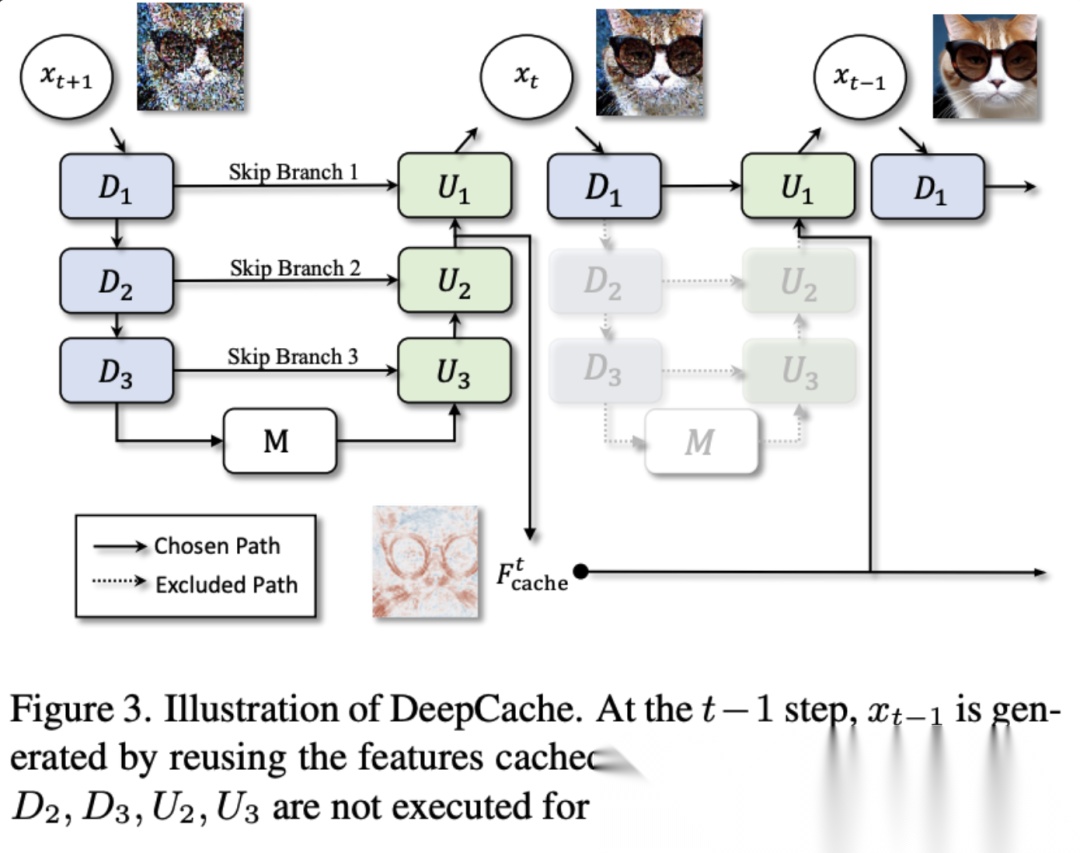
MagCache这类工作更进一步,基于magnitude analysis动态决定哪些step可以跳过或者retrieve cache。实测这能带来2x-5x的加速,且几乎无损画质。
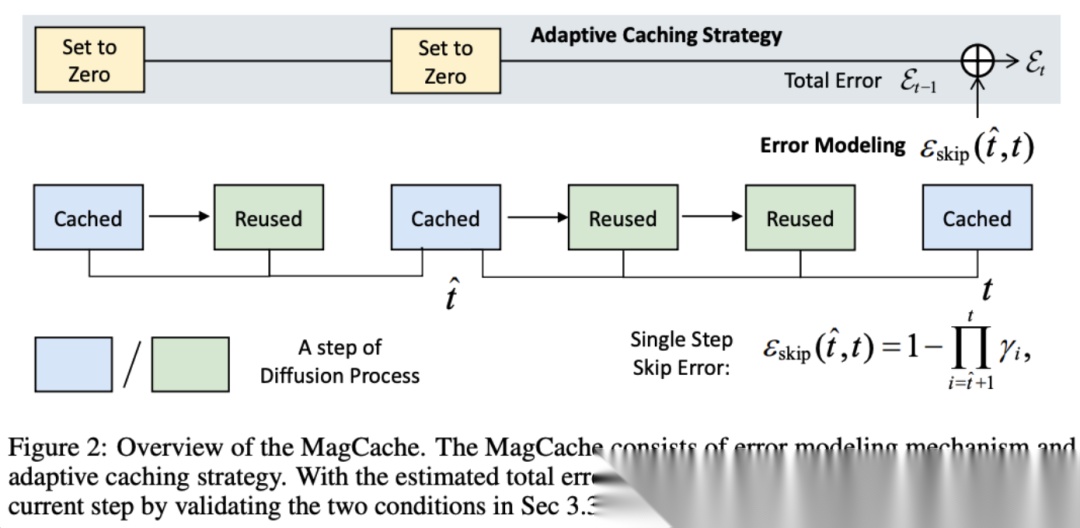
这里非常适合高校去做,因为你只需要改forward pass代码,不需要训练。但是可想而知,也会和image editing一样是人最多、最卷、最需要拼手速的方向,技术更迭、淘汰速度肯定相对都会快很多。
(五)Video-to-Video Editing
视频编辑这个任务的核心在于和source video sequence保持一致的运动信息,然后让模型在sampling的时候通过修改text prompt达到editing的目的,任务本身可以理解为是一个image editing的高级版,只是video相比于image多了一个temporal dimension,所以会更难。
早期工作有TokenFlow。它的套路是:既然key frames编辑好了,非关键帧就不应该重新生成,而是应该根据content correspondence直接把feature搬运过去。通过强制所有帧共享key-value features,从而通过这种方式来enforce采样过程中的temporal consistency。
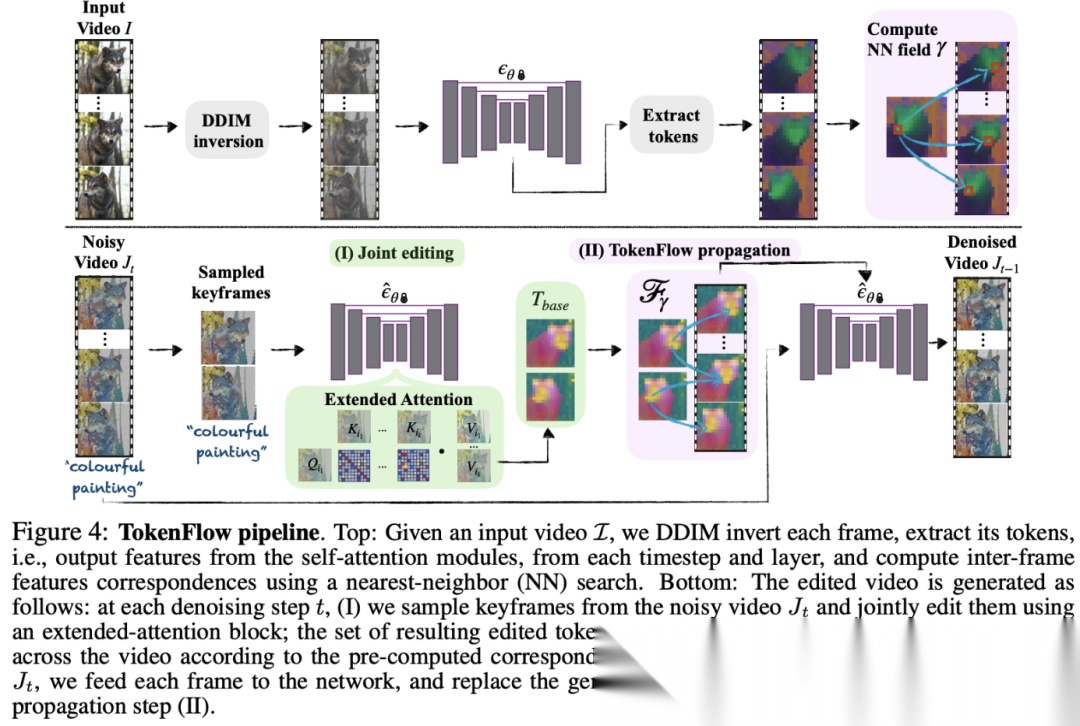
2025年之后大家的研究方向还是逐渐开始转向flow matching和DiT-based架构下的video editing了,和最新的生态变化逐渐接轨,所以inversion-based的方法逐渐开始退出历史舞台,flow-based和attention-based的方法开始成为主流。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献658条内容
已为社区贡献658条内容

所有评论(0)