AI助理-搭建个人的AI助手-先本地的
AI助手
基于之前的流程,我想到需要做一个对他人或者对自己更有意义的,用途更广的应用,基于目前自己的岗位角色,首先想到的就是AI助理。
目前这类的还是比较多的,像很多团队的知识问答库等等,但是对于我个人来讲,我可能更关注他能把我日常的比如发版计划,发包计划,问题处理,需求处理结果,日程安排等实时更新进去,我的上下游可以直接搜索就可以找到这些问题的解决方法或者答案,省去我去到处搜索给他们回答。本质上还是想做一个问答+任务助手的应用。
🛠️ 第一步:环境准备 (Windows)
-
检查 Python:
打开 PowerShell 或 CMD,输入python --version。- 如果有版本号 (如
Python 3.9.x),继续。 - 如果没有,去 python.org 下载并安装(重要:安装时勾选 "Add Python to PATH")。
- 如果有版本号 (如
-
创建项目文件夹:
在桌面新建一个文件夹,命名为my_ai_assistant。 -
安装依赖库:
在该文件夹内,按住Shift+右键,选择“在此处打开 PowerShell 窗口”或“在终端中打开”,然后运行:pip install dashscope langchain langchain-community chromadb apscheduler streamlit python-dotenv dateparser(解释:
dashscope是阿里云SDK,chromadb是本地向量库,apscheduler是做闹钟的,streamlit是快速写网页的,dateparser能听懂“今天下午3点”这种自然语言) -
获取 API Key:
- 去 阿里云百炼控制台 注册/登录。
- 创建一个 API Key (通常送免费额度,够你测试很久)。
- 复制这个 Key,备用。
📂 第二步:准备项目文件
在你的 my_ai_assistant 文件夹里,创建以下 4 个文件:
1. .env (存放密钥,不要泄露)
新建文本文件,重命名为 .env (注意前面有个点),内容如下:
DASHSCOPE_API_KEY=sk-你的真实API密钥在这里2. docs 文件夹 (存放知识)
新建一个文件夹叫 docs。
在里面随便建一个测试文件,比如 test_knowledge.md,写入一些内容:
# 交易系统常见错误
## 错误码 503
当出现 503 Service Unavailable 时,通常是因为撮合引擎过载。
解决方案:请等待 30 秒后重试,或检查本地网络连接。
## 错误码 403
权限不足。请检查你的 API Key 是否有交易权限,且 IP 白名单已配置。3. scheduler.py (私人助理核心:闹钟 + 提醒)
新建文件 scheduler.py,粘贴以下代码:
import os
import sqlite3
import time
import requests
from datetime import datetime, timedelta
from apscheduler.schedulers.background import BackgroundScheduler
from dotenv import load_dotenv
import dateparser
# 加载环境变量
load_dotenv()
SEND_KEY = os.getenv("SERVERCHAN_SEND_KEY", "") # 可选:填ServerChan的Key实现微信推送
# --- 数据库初始化 ---
def init_db():
conn = sqlite3.connect('assistant.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS tasks
(id INTEGER PRIMARY KEY, content TEXT, trigger_time_str TEXT,
is_recurring BOOLEAN, interval_minutes INT, notified BOOLEAN)''')
conn.commit()
conn.close()
# --- 添加任务 (支持自然语言时间) ---
def add_task_natural(content, time_text, is_recurring=False, interval=0):
# 解析自然语言时间 (如 "今天下午3点", "10分钟后")
parsed_time = dateparser.parse(time_text, settings={'RETURN_AS_TIMEZONE_AWARE': False})
if not parsed_time:
return f"❌ 无法识别时间:{time_text},请尝试'下午3点'或'10分钟后'"
trigger_time_str = parsed_time.strftime("%Y-%m-%d %H:%M:%S")
conn = sqlite3.connect('assistant.db')
c = conn.cursor()
c.execute("INSERT INTO tasks (content, trigger_time_str, is_recurring, interval_minutes, notified) VALUES (?, ?, ?, ?, ?)",
(content, trigger_time_str, is_recurring, interval, False))
conn.commit()
conn.close()
return f"✅ 已设定:{content} -> {trigger_time_str}"
# --- 发送通知 (控制台打印 + 可选微信) ---
def send_notification(title, content):
print(f"\n🔔 [{title}] {content}")
if SEND_KEY:
try:
url = f"https://sctapi.ftqq.com/{SEND_KEY}.send"
requests.post(url, data={"title": title, "desp": content})
except:
pass
# --- 定时检查任务 ---
def check_tasks():
conn = sqlite3.connect('assistant.db')
c = conn.cursor()
now = datetime.now()
now_str = now.strftime("%Y-%m-%d %H:%M:%S")
c.execute("SELECT * FROM tasks WHERE trigger_time_str <= ? AND notified = False", (now_str,))
tasks = c.fetchall()
for task in tasks:
task_id, content, t_str, is_recurring, interval, _ = task
send_notification("💼 私人助理提醒", f"时间到了!\n事项:{content}")
# 标记已通知
c.execute("UPDATE tasks SET notified = True WHERE id = ?", (task_id,))
# 处理循环任务
if is_recurring and interval > 0:
next_time = now + timedelta(minutes=interval)
next_str = next_time.strftime("%Y-%m-%d %H:%M:%S")
c.execute("INSERT INTO tasks (content, trigger_time_str, is_recurring, interval_minutes, notified) VALUES (?, ?, ?, ?, ?)",
(content, next_str, True, interval, False))
print(f"🔄 下次提醒已设:{content} -> {next_str}")
conn.commit()
conn.close()
if __name__ == "__main__":
init_db()
scheduler = BackgroundScheduler()
scheduler.add_job(check_tasks, 'interval', seconds=10) # 每10秒检查一次(本地测试用,生产环境改60秒)
scheduler.start()
print("🤖 私人助理后台已启动... (按 Ctrl+C 停止)")
# 保持主线程运行
try:
while True:
time.sleep(1)
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()4. app.py (知识库问答 + 交互界面)
新建文件 app.py,粘贴以下代码:
import os
import streamlit as st
from dotenv import load_dotenv
import dashscope
from dashscope import Generation
import pickle # 用于保存 FAISS 索引
# ✅ 只引入最稳定的库
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS # <--- 换成 FAISS
from langchain_core.documents import Document
# 配置
load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY")
st.set_page_config(page_title="小智(FAISS 版)", layout="wide")
st.title("UFT一问通")
# --- 侧边栏:添加待办 ---
with st.sidebar:
st.header("⏰ 添加待办/提醒")
task_content = st.text_input("要做的事")
task_time = st.text_input("时间 (如:今天下午3点)")
is_loop = st.checkbox("循环提醒")
loop_min = st.number_input("间隔 (分钟)", min_value=1, value=60) if is_loop else 0
if st.button("添加提醒"):
if task_content and task_time:
import sqlite3, dateparser
from datetime import datetime
parsed = dateparser.parse(task_time)
if parsed:
conn = sqlite3.connect('assistant.db')
c = conn.cursor()
c.execute("INSERT INTO tasks (content, trigger_time_str, is_recurring, interval_minutes, notified) VALUES (?, ?, ?, ?, ?)",
(task_content, parsed.strftime("%Y-%m-%d %H:%M:%S"), is_loop, loop_min if is_loop else 0, False))
conn.commit()
conn.close()
st.success(f"✅ 已添加:{task_content}")
else:
st.error("❌ 时间格式无法识别")
# --- 主界面:知识库问答 ---
st.markdown("### 📚 知识库问答")
INDEX_FILE = "faiss_index.pkl"
@st.cache_resource
def load_and_process_docs():
docs_folder = "docs"
if not os.path.exists(docs_folder):
os.makedirs(docs_folder)
return None, "请先在 'docs' 文件夹放入 .md 或 .txt 文件。"
docs = []
# ✅ 只读取 md 和 txt,彻底避开 unstructured
file_list = [f for f in os.listdir(docs_folder) if f.endswith(('.md', '.txt'))]
if not file_list:
return None, "docs 文件夹为空。"
progress_bar = st.progress(0)
status_text = st.empty()
try:
# 1. 读取文件
for i, filename in enumerate(file_list):
status_text.text(f"正在读取:{filename}...")
file_path = os.path.join(docs_folder, filename)
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
docs.append(Document(page_content=content, metadata={"source": filename}))
except UnicodeDecodeError:
with open(file_path, 'r', encoding='gbk') as f:
content = f.read()
docs.append(Document(page_content=content, metadata={"source": filename}))
progress_bar.progress((i + 1) / len(file_list) * 0.5)
if not docs:
return None, "未找到有效文档。"
# 2. 切片
status_text.text("正在切片...")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
splits = splitter.split_documents(docs)
# 3. 向量化 (使用 FAISS)
status_text.text("正在调用阿里云 API 进行向量化 (首次较慢)...")
if not api_key:
return None, "❌ 缺少 API Key。"
embeddings = DashScopeEmbeddings(model="text-embedding-v2")
# ✅ 创建 FAISS 索引 (不依赖系统 DLL,自带所有依赖)
db = FAISS.from_documents(documents=splits, embedding=embeddings)
# 4. 本地保存 (使用 pickle 序列化,简单稳定)
db.save_local(INDEX_FILE)
progress_bar.progress(1.0)
status_text.empty()
st.success(f"✅ 成功!加载 {len(docs)} 个文件,构建 FAISS 索引完成。")
return db, "OK"
except Exception as e:
st.error(f"发生错误:{e}")
import traceback
st.code(traceback.format_exc())
return None, str(e)
# 尝试加载现有索引,如果没有则重新构建
def get_db():
if os.path.exists(INDEX_FILE):
try:
embeddings = DashScopeEmbeddings(model="text-embedding-v2")
db = FAISS.load_local(INDEX_FILE, embeddings, allow_dangerous_deserialization=True)
return db, "OK (从缓存加载)"
except:
pass # 加载失败则重新构建
return load_and_process_docs()
db, status_msg = get_db()
# --- 核心问答逻辑 ---
def get_answer(question, vector_db):
docs = vector_db.similarity_search(question, k=3)
if not docs:
return "未找到相关文档内容。"
context_text = "\n\n---\n\n".join([d.page_content for d in docs])
prompt = f"""基于以下已知信息回答。如果不知道,就说“知识库暂无记录”。
已知信息:
{context_text}
用户问题:{question}
专业回答:"""
try:
response = Generation.call(model='qwen-max', prompt=prompt, temperature=0.3, max_tokens=1000)
if response.status_code == 200:
return response.output.text
else:
return f"❌ API 错误:{response.code}"
except Exception as e:
return f"❌ 调用失败:{str(e)}"
# 显示界面
if db:
user_query = st.chat_input("问问小智知识库...")
if user_query:
with st.spinner("正在思考..."):
answer = get_answer(user_query, db)
st.write(answer)
else:
st.info(f"👈 {status_msg}")
st.markdown("---")
st.caption("💡 提示:此版本使用 FAISS 引擎,无需安装系统级 C++ 库,稳定性极高。")🚀 第三步:运行与测试
你需要打开两个终端窗口(PowerShell 或 CMD):
窗口 1:启动“闹钟管家”
在文件夹路径下运行:
python scheduler.py- 现象:看到
🤖 私人助理后台已启动...,表示它正在每分钟检查有没有要提醒的事。 - 测试:你可以在侧边栏(见下一步)添加一个“1 分钟后喝水”的任务,等 1 分钟后看这个窗口有没有打印提醒。
窗口 2:启动“网站界面”
新开一个终端窗口,运行:
streamlit run app.py- 现象:会自动打开浏览器,显示你的网站。
- 功能测试:
- 左侧:输入“审核代码”,时间填“1 分钟后”,点击添加。
- 中间:提问“503 错误怎么处理?”,看它是否读取了
docs/test_knowledge.md的内容并回答。 - 观察:1 分钟后,切回 窗口 1,看是否输出了提醒信息。
✅ 成功标志
如果你能看到:
- 网页能正常回答问题(基于你放的文档)。
- 另一个窗口能准时打印出提醒文字。
那么恭喜你!核心逻辑已经跑通了!
**问题复盘**
1.总是遇到库报错
重新编写app.py

2、加载起来后依旧报错
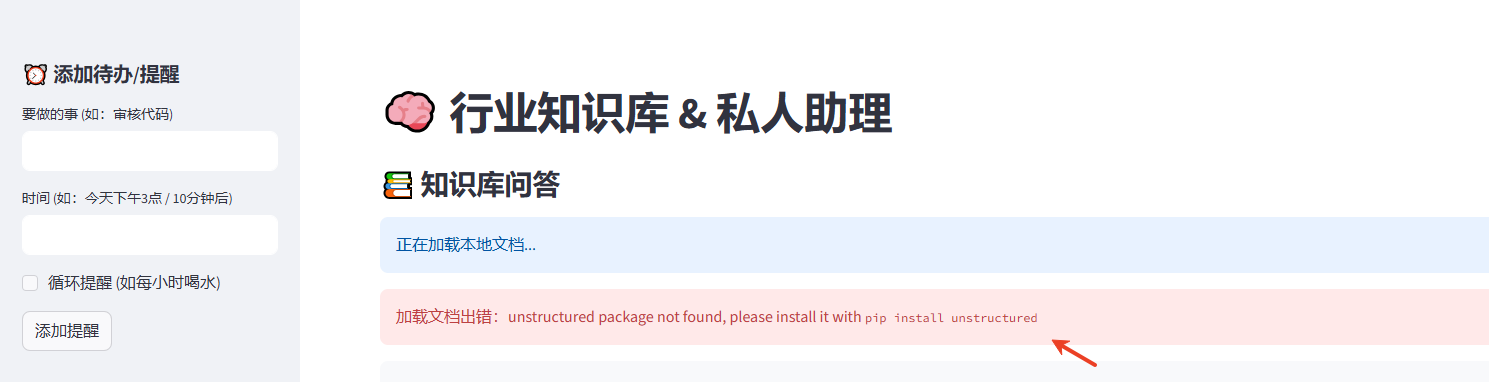 需要安装依赖的库:pip install unstructured
需要安装依赖的库:pip install unstructured
3、依赖库报错

需要下载到本地,然后安装:
复制这个链接(这是经过加速处理的 GitHub 下载链接):https://ghproxy.net/https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.8.0/en_core_web_sm-3.8.0-py3-none-any.whl
cmd下运行:pip install en_core_web_sm-3.8.0-py3-none-any.whl
4、文件加载一直不行,需要调试
通过分析windows的时间监视器,发现是因为依赖系统库版本不对。最后采用还是原始的方式解析md文件,暂不支持高级的doc解析。如果需要解决依赖库问题,需要升级系统库,因为我的环境要用来做开发,所以系统库暂不能升级。
最后顺利完成问答了:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)