video-subtitle-remover(VSR)-- 开源AI去字幕方案深度解析
VSR(video-subtitle-remover)是一款开源AI视频去字幕工具,支持本地运行,无需上传数据。它融合STTN、LaMa、ProPainter三大前沿修复模型,可智能检测并擦除硬字幕/水印,保持原分辨率与画质。兼容CUDA/DirectML,适配NVIDIA/AMD/Intel显卡,兼顾隐私性、可控性与高性能。
一、从“硬字幕”说起:为什么我们需要 VSR?
在视频剪辑、二创和影视加工场景里,“硬字幕”(内嵌到画面里的字幕)一直是特别棘手的问题:
-
你无法通过关闭字幕轨道来清除;
-
直接裁剪会破坏画面构图;
-
简单模糊/马赛克又会在画面上留下明显的“补丁”。
传统做法要么牺牲画质,要么牺牲效率。而开源项目 video-subtitle-remover(VSR),则直接把问题拉到了“AI 视频修复”的维度:用深度学习模型自动检测字幕区域,再通过图像修复算法把文字“擦掉”,并用背景自然填补。
项目核心信息(来自 README):
-
功能定位:- 去除视频 / 图片中的硬字幕、文本水印
-
无损分辨率输出
-
支持自定义字幕区域,或全视频自动去除所有文本
-
-
技术特点:- 完全本地运行,无需调用第三方 API
-
支持多种 GPU 加速(CUDA / DirectML 等)
-
提供多种修复算法(STTN LaMa ProPainter)
-
项目地址:
GitHub:https://github.com/YaoFANGUK/video-subtitle-remover【turn4fetch0】
(国内镜像可在 GitCode 搜索 video-subtitle-remover)
二、VSR 整体架构:从“检测”到“修复”的闭环
先用一张结构图把整体流程串起来,再逐块拆解。
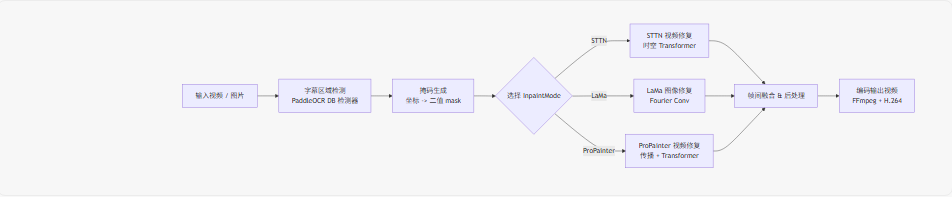
2.1 输入层:视频 / 图片统一抽象
-
视频:通过 OpenCV
cv2.VideoCapture逐帧解码,获取帧号、帧图像,用于后续检测与修复。 -
图片:走同样的检测 + 修复流程,只是“帧数=1”,简化为单帧图像修复。
整个项目的入口是 backend/main.py,核心类包括:
-
SubtitleDetect:负责文本检测与字幕区域定位。 -
后续还有
SubtitleRemover等类负责掩码生成、修复和视频写回(这些在源码中继续向下阅读即可看到)。
2.2 字幕检测:PaddleOCR + DB 检测器
VSR 没有自己造轮子,而是直接集成 PaddleOCR 的文本检测能力github
。
关键点:
-
检测模型选择
-
使用 DB(Differentiable Binarization)文本检测算法,这是 PaddleOCR 默认的检测模型之一medium+1
。 -
模型路径通过
config.DET_MODEL_PATH指定,位于backend/models/V4/ch_det目录。
-
-
检测流程(精简版)
-
对每一帧图像调用
TextDetector:- 输入:原始帧(RGB)。-
输出:文本检测框
dt_boxes(多边形,通常是四边形)。
-
-
将多边形框转换为坐标
(xmin, xmax, ymin, ymax),用于生成掩码。
-
-
区域过滤与统一
-
支持传入
sub_area自定义字幕区域,只保留落在该区域内的文本框。 -
通过
unify_regions等方法,将连续帧中相似位置的文本框统一,避免掩码频繁跳动。
-
从架构上看,这里完全可以替换成其他 OCR/文本检测模型(如 YOLO-based 文本检测),VSR 只是选择了成熟可用的 PaddleOCR。
三、三种修复算法:STTN LaMa ProPainter 的硬核对比
VSR 最大的亮点在于:把前沿的视频/图像修复模型整合到了一个可工程化落地的工具中。
配置文件 backend/config.py 中定义了三种 InpaintMode:
python
class InpaintMode(Enum):
STTN = 'sttn'
LAMA = 'lama'
PROPAINTER = 'propainter'
3.1 STTN:时空 Transformer 做视频修复
-
论文来源:
STTN 来自 ECCV 2020 论文《Learning Joint Spatial-Temporal Transformations for Video Inpainting》arxiv+1
。 -
核心思想:- 将所有待修复帧作为一个整体,输入一个 时空 Transformer 网络。
-
通过多尺度 patch 级别的注意力机制,在“时间维度”和“空间维度”之间建立对应关系,从周围帧中“搬运”纹理来填补当前帧的缺失区域ecva
。
-
-
在 VSR 中的实现:-
STTN_NEIGHBOR_STRIDE:参考帧步长,例如取 5,表示每隔 5 帧采样一帧作为参考。-
STTN_REFERENCE_LENGTH:参考帧数量,决定时间上下文范围。 -
STTN_MAX_LOAD_NUM:单批处理的最大帧数,受显存限制。 -
STTN_SKIP_DETECTION:可以跳过字幕检测,直接对固定区域修复,适合场景固定、字幕位置稳定的视频。
-
特点:
-
适合 真人视频、运动较自然 的场景,如电影、剧集、访谈。
-
速度相对较快,显存占用可控。
-
对字幕位置变化不大、背景相对简单的视频效果很好。
3.2 LaMa:高分辨率图像修复的“大杀器”
-
论文来源:
LaMa 来自 WACV 2022 论文《Resolution-robust Large Mask Inpainting with Fourier Convolutions》arxiv+1
。 -
核心思想:- 引入 快速傅里叶卷积(FFC),使网络具有 图像级感受野,能够一次性利用整张图的信息来修补大面积缺失arxiv
。-
专门针对“大掩码”场景设计,对高分辨率图像和周期性结构(如栏杆、砖墙)效果很好github+1
。
-
-
在 VSR 中的实现:-
MODE = InpaintMode.LAMA-
LAMA_SUPER_FAST = False以保证质量(若为 True 会使用更快的近似推理)。
-
特点:
-
对 动画、卡通、图文排版类视频 效果很好,因为这类内容本身就具有明显的图形和边界。
-
不支持跳过检测,必须先生成掩码,再逐帧修复。
-
在高分辨率图片上表现优异,但视频逐帧处理会略慢于 STTN。
3.3 ProPainter:追求极致效果的“重型方案”
-
论文来源:
ProPainter 来自 ICCV 2023 论文《ProPainter: Improving Propagation and Transformer for Video Inpainting》shangchenzhou+1
。 -
核心思想:- 三大组件:循环流完成(recurrent flow completion) + 双域传播(dual-domain propagation) + 掩码引导的稀疏 Transformershangchenzhou
。-
通过光流传播 + Transformer 注意力,在时间维度上做更精细的纹理传递,适合运动剧烈、镜头频繁切换的视频。
-
-
在 VSR 中的实现:-
PROPAINTER_MAX_LOAD_NUM:控制单批处理帧数,需要根据显存调整:- 720p 视频:80 帧约需 8G 显存,50 帧约需 7G。
1280x720 视频:80 帧约需 25G 显存。
特点:
-
对 运动剧烈、镜头切换频繁 的视频效果最好。
-
显存占用大、速度慢,是“重型武器”,适合对效果要求极高的场景。
3.4 三种算法的横向对比
| 算法 | 类型 | 适用场景 | 显存占用 | 速度 | 能否跳过检测 |
|---|---|---|---|---|---|
| STTN | 视频修复 | 真人电影、剧集、访谈等运动自然的视频 | 中等 | 快 | 可以 |
| LaMa | 图像修复 | 动画、图文排版、高分辨率图片 | 中等 | 中等 | 不可以 |
| ProPainter | 视频修复 | 运动剧烈、镜头切换多的视频 | 高 | 慢 | 不可以 |
实际使用中,建议:
-
先尝试 STTN,兼顾速度和效果;
-
对动画、图文类内容使用 LaMa;
-
对运动剧烈、效果要求极高的场景再上 ProPainter。
四、工程实现细节:从掩码生成到视频输出
4.1 掩码生成:从检测框到二值掩码
在 backend/tools/inpaint_tools.py 中,VSR 提供了 create_mask 等工具函数(从导入可见):
-
将检测到的文本框坐标转换为二值掩码:- 字幕区域 = 1(需要修复)。
-
其余区域 = 0。
-
-
对掩码进行适当的形态学操作(如膨胀),确保字幕边缘被完全覆盖,避免修复后出现文字边缘残留。
4.2 场景切换与帧间一致性
VSR 引入了 场景检测 模块 backend/scenedetect,使用 ContentDetector 检测场景切换点:
-
通过
get_scene_div_frame_no获取发生场景切换的帧号。 -
在这些点重新计算字幕区域,避免不同场景的字幕区域互相“串扰”。
这保证了在镜头切换时,修复不会把前一场景的内容错误地“传播”到下一场景。
4.3 FFmpeg 与视频 I/O
VSR 在 backend/ffmpeg 目录下预置了各平台的 FFmpeg 可执行文件(Windows Linux macOS):
-
用于:- 从原始视频中提取音频轨道;
-
将修复后的帧序列重新编码为视频;
-
合并音频,生成最终的无字幕视频。
-
-
配置中默认开启
USE_H264 = True,以便生成的视频能在安卓手机上正常播放。
4.4 ONNX 与 DirectML:让非 NVIDIA 显卡也能跑
在 config.py 中,VSR 做了一件很工程化的事情:
-
自动检测 ONNX Runtime 可用的执行提供者:- 支持 DirectML(AMD/Intel/通用 GPU)、ROCm、OpenVINO、Metal、CoreML、CUDA 等。
-
如果检测到非 CPU Provider,会将 Paddle 模型自动转换为 ONNX 格式,便于用 ONNX Runtime 推理。
这意味着:
-
NVIDIA 显卡:走 CUDA + PyTorch / Paddle 的 GPU 推理。
-
AMD / Intel 显卡:通过 DirectML + ONNX Runtime 也能跑,兼容性很好。
五、性能调优:参数调优与效果权衡
README 中专门提供了“常见问题”解答,这里把关键点整理成极客向的调优指南。
5.1 速度优先:STTN + 跳过检测
python
MODE = InpaintMode.STTN
STTN_SKIP_DETECTION = True
-
优点:省去整遍字幕检测,大幅缩短处理时间。
-
缺点:- 可能会把本不该处理的帧当作“有字幕”来修复,造成误伤。
-
也可能漏掉一些字幕帧,导致字幕残留。
-
适合:字幕位置非常固定、视频时长较长、对时间敏感的场景。
5.2 效果优先:LaMa / ProPainter + 更大上下文
-
对于 LaMa:-
LAMA_SUPER_FAST = False,关闭快速近似推理,保证修复质量。 -
对于 ProPainter:- 在显存允许的前提下,尽量增大
PROPAINTER_MAX_LOAD_NUM。 -
对于 STTN:- 增大
STTN_REFERENCE_LENGTH和STTN_MAX_LOAD_NUM,可以获得更长的时序上下文,提升修复连贯性。
5.3 检测与掩码调优
config.py 中提供了若干“像素级”参数:
-
THRESHOLD_HEIGHT_WIDTH_DIFFERENCE:过滤高宽比异常的文本框,减少误检。 -
SUBTITLE_AREA_DEVIATION_PIXEL:放大掩码范围,避免文字边缘残留。 -
PIXEL_TOLERANCE_X / PIXEL_TOLERANCE_Y:用于判断两个文本框是否“同一行”,影响连续帧字幕区域统一。
这些参数对最终效果影响很大,需要在实际视频中多调几次。
六、本地开源 vs 在线商用:VSR 与 云端AI 去字幕的对比
在真实业务中,团队往往需要在“本地开源工具”和“在线 SaaS 服务”之间做选择。
这里我们对比 VSR 和在线去字幕服务 550W AI 去字幕(550wai.cn)。
6.1 550W AI 去字幕的产品特点
根据官网介绍:
-
产品定位:- 支持网页端和微信小程序,云端 GPU 加速,1 分钟视频平均处理约 30 秒。
-
核心技术:- 深度学习模型识别多种字幕样式,识别准确率约 98%。
-
内容感知算法进行背景填充,支持多语言(中英日韩等)。
-
-
适用场景:- 短视频创作者(抖音、快手、视频号等)去除原视频字幕,添加自己的文案。
-
B 站 UP 主、YouTube 博主处理影视剪辑素材。
-
教育培训机构和企业营销团队处理课程视频和宣传素材。
-
6.2 VSR vs 550W:适用场景分析
| 维度 | VSR(本地开源) | 550WAI去字幕(在线) |
|---|---|---|
| 部署方式 | 本地 Python / Docker,需要自己配置环境 | 浏览器或小程序,无需安装 |
| 隐私合规 | 数据不上传,适合敏感内容 | 视频需上传到云端,需评估隐私风险 |
| 可定制性 | 可修改源码、更换模型、训练自己的模型 | 模型和流程固定,只能使用平台能力 |
| 成本 | 机器成本 + 人力维护成本 | 按使用量付费,无额外运维成本 |
| 适用规模 | 中小规模、对隐私和可控性要求高的团队 | 大量临时性需求、对快速出片要求高的创作者 |
极客视角:
-
如果你是一个 技术团队,希望:
-
完全掌控数据与模型;
-
根据业务场景训练自己的修复模型;
-
嵌入到现有的视频处理流水线;
那么 VSR 是首选。
-
-
如果你是一个 内容创作者 / 运营团队,更关注:
-
上传 → 处理 → 下载 的极致简化;
-
不想折腾环境、显卡和依赖;
那么像 550W AI 去字幕 这样的在线服务 会更合适。
-
在实际项目中,两者也可以结合:
-
用 VSR 做本地化、高隐私需求的批量处理;
-
用 550W 做移动端、轻量级的临时处理。
七、实操建议:从零到一跑通 VSR
7.1 环境准备(以 CUDA 版本为例)
-
安装 Python 3.12+。
-
创建虚拟环境:
bash
python -m venv videoEnv
source videoEnv/bin/activate # Linux/macOS
或 Windows: videoEnv\Scripts\activate
-
安装依赖:
bash
git clone https://github.com/YaoFANGUK/video-subtitle-remover.git
cd video-subtitle-remover
pip install -r requirements.txt -
安装 PaddlePaddle GPU 版本(CUDA 11.8):
bash
pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/ -
安装 PyTorch(CUDA 11.8):
bash
pip install torch==2.7.0 torchvision==0.22.0 --index-url https://download.pytorch.org/whl/cu118
7.2 运行 GUI / CLI
-
GUI:
bash
python gui.py -
CLI:
bash
python ./backend/main.py
在 GUI 中,你可以:
-
选择输入视频 / 图片;
-
指定字幕区域(或自动检测);
-
选择修复算法(STTN LaMa ProPainter);
-
调整参数(如参考帧长度、跳过检测等)。
八、进阶:如何在自己的业务中“榨干”VSR?
8.1 模型替换与训练
README 中提到,design 目录里提供了训练方法,backend/tools/train 中有训练代码,你可以:
-
用自己的字幕数据训练文本检测模型;
-
针对特定类型的视频(如动画、体育赛事)训练专用的修复模型;
-
将训练好的模型替换
backend/models下的对应模型。
8.2 与现有视频处理流水线集成
由于 VSR 是纯 Python + FFmpeg 的工程,你可以:
-
将其封装为 REST API / gRPC 服务,对外提供“去字幕”能力;
-
与剪辑、转码、审核等流程串联,形成完整的视频处理管道;
-
结合分布式任务队列(如 Celery、Ray)做大规模并发处理。
九、小结:VSR 的价值与局限
价值:
-
把前沿的视频修复论文(STTN、LaMa、ProPainter)工程化,变成可直接使用的工具。
-
完全本地化运行,保护数据隐私,适合企业级落地。
-
支持多种 GPU 平台,兼容性好。
局限:
-
对硬件要求较高,尤其 ProPainter 显存占用大。
-
复杂动态场景、半透明字幕、特效字幕仍可能效果不佳,需要进一步调参或训练模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)