LLM模型开发教程(十七)MCP/A2A/Memory一篇搞定(文末附源码)
MCP(Model Context Protocol)是一个开源标准协议,旨在标准化AI模型(Agent)与外部系统之间的连接。它采用类似USB接口的统一标准,解决传统集成中的碎片化问题,降低开发维护成本。MCP基于JSON-RPC 2.0协议,支持多种传输方式(HTTP/HTTPS、IPC等),实现Client(客户端)与Server(服务端)的安全高效通信。其核心价值包括即插即用、安全隔离和促
MCP
🔌 MCP (Model Context Protocol) 深度解析:Agent 互联的“通用插座”
导读:随着 Agent 应用爆发,如何标准化地连接各种外部系统成为痛点。MCP 应运而生,它就像 USB 接口一样,统一了 AI 模型与外部数据/工具的连接标准。本文档将解读其核心定义、协议架构及工程价值。
🟢 第一部分:什么是 MCP?
💡 一句话定义:
MCP (Model Context Protocol) 是一个开源标准协议,用于将 Agent (客户端) 访问 外部系统 (服务端) 的过程标准化。
- 以前:每个工具都要写一套独特的对接代码(像老式电器各有各的插头)。
- 现在:所有工具都遵循 MCP 标准(像 USB-C 接口),Agent 只要支持 MCP,就能即插即用任何兼容的工具。
⚙️ 核心架构要素:
- 角色分工:
- Client (客户端):通常是 LLM Agent 或宿主应用(如 IDE、聊天机器人)。它发起请求。
- Server (服务端):提供具体能力的外部系统(如数据库、文件系统、API 网关)。它响应请求。
- 通信协议:
- 应用层:基于 JSON-RPC 2.0。这是一种轻量级的远程过程调用协议,使用 JSON 格式发送请求和接收响应,结构清晰,易于解析。
- 传输层:灵活多样。底层可以是 HTTP/HTTPS (网络传输)、IPC (进程间通信,如 Stdio)、甚至 WebSocket。这意味着 MCP 既可以在云端运行,也可以在本地离线运行。
🔵 第二部分:为什么需要 MCP?(核心价值)
🎯 解决的核心痛点:
- 碎片化严重:在没有 MCP 之前,连接 Notion、Google Drive、本地数据库需要编写完全不同的适配代码。
- 维护成本高:每增加一个新工具,就要重新开发、测试一套集成逻辑。
- 安全性难控:缺乏统一的权限管理和数据隔离标准。
✅ MCP 带来的优势:
- 🔌 即插即用:开发者只需编写一次 MCP Server,所有支持 MCP 的 Client (如 Claude Desktop, LangChain Agents) 都能直接连接。
- 🛡️ 安全隔离:MCP 设计了明确的权限边界。Client 只能访问 Server 明确暴露的资源,无法随意窥探服务器其他部分。
- 🚀 生态繁荣:类似于 App Store 模式。未来会出现大量现成的 “MCP Servers” (如 “GitHub MCP”, “Postgres MCP”),开发者可以直接拿来用,无需重复造轮子。
🟣 第三部分:工程落地与实操思路
如何在项目中引入 MCP?
🛠️ 场景 A:作为使用者 (Client 端)
- 目标:让你的 Agent 能调用现有的 MCP 工具。
- 步骤:
- 选择 SDK:使用官方提供的 MCP Client SDK (Python/TypeScript)。
- 配置连接:在配置文件中声明要连接的 MCP Server 地址(如
stdio: command="mcp-server-git"或http: url="...")。 - 自动发现:Client 启动后会自动向 Server 询问:“你有哪些工具 (Tools)、资源 (Resources) 和 提示词 (Prompts)?”
- 动态调用:将这些工具动态注册到你的 Agent 框架中,即可像调用本地函数一样使用它们。
🏗️ 场景 B:作为提供者 (Server 端)
- 目标:把你公司的内部系统(如 ERP、CRM)封装成 MCP 服务供 AI 调用。
- 步骤:
-
定义能力:确定你要暴露哪些 API(例如:
get_order_status,create_user)。 -
实现 Server:使用 MCP Server SDK 编写代码,实现标准的 JSON-RPC 接口。
# 伪代码:一个简单的 MCP Server @server.call_tool() async def get_weather(name: str) -> list[TextContent]: # 这里写真实的业务逻辑 temp = fetch_from_internal_db(name) return [TextContent(text=f"{name} 的温度是 {temp}")] -
部署运行:将 Server 部署为独立进程或容器。
-
开放连接:告知 Client 端连接地址,完成对接。
-
📊 总结对比:传统集成 vs MCP 集成
| 维度 | 传统点对点集成 | MCP 标准化集成 |
|---|---|---|
| 开发模式 | 定制化开发,每个工具写一套代码 | 标准化开发,一次编写,到处连接 |
| 耦合度 | 高耦合,Agent 强依赖特定工具实现 | 低耦合,通过协议解耦 |
| 扩展性 | 差,新增工具成本高 | 优,新增工具只需启动新 Server |
| 安全性 | 参差不齐,依赖各自实现 | 统一标准,权限控制更严谨 |
| 适用场景 | 临时脚本、单一功能 demo | 企业级应用、复杂 Agent 系统、生态构建 |
💡 专家建议:
不齐,依赖各自实现 | 统一标准,权限控制更严谨 |
| 适用场景 | 临时脚本、单一功能 demo | 企业级应用、复杂 Agent 系统、生态构建 |
💡 专家建议:
- 新项目首选 MCP:如果你正在构建一个需要连接多个外部系统的 Agent 应用,直接采用 MCP 架构,避免未来的技术债务。
- 旧系统改造:对于已有的内部系统,可以逐步将其核心功能封装为 MCP Server,让 AI 能够安全、规范地访问。
- 关注生态:密切关注 Anthropic 及社区推出的现成 MCP Servers,很多常用功能(文件读取、数据库查询、网页抓取)可能已经有现成方案了。
✅ 终极总结:
MCP 是 AI 时代的 USB 协议。它通过 JSON-RPC 2.0 标准化了通信,屏蔽了底层传输差异,让 Agent (Client) 和 外部系统 (Server) 的连接变得简单、安全、可复用。掌握 MCP,就是掌握了构建可扩展 AI 应用的关键钥匙。
MCP的核心成员
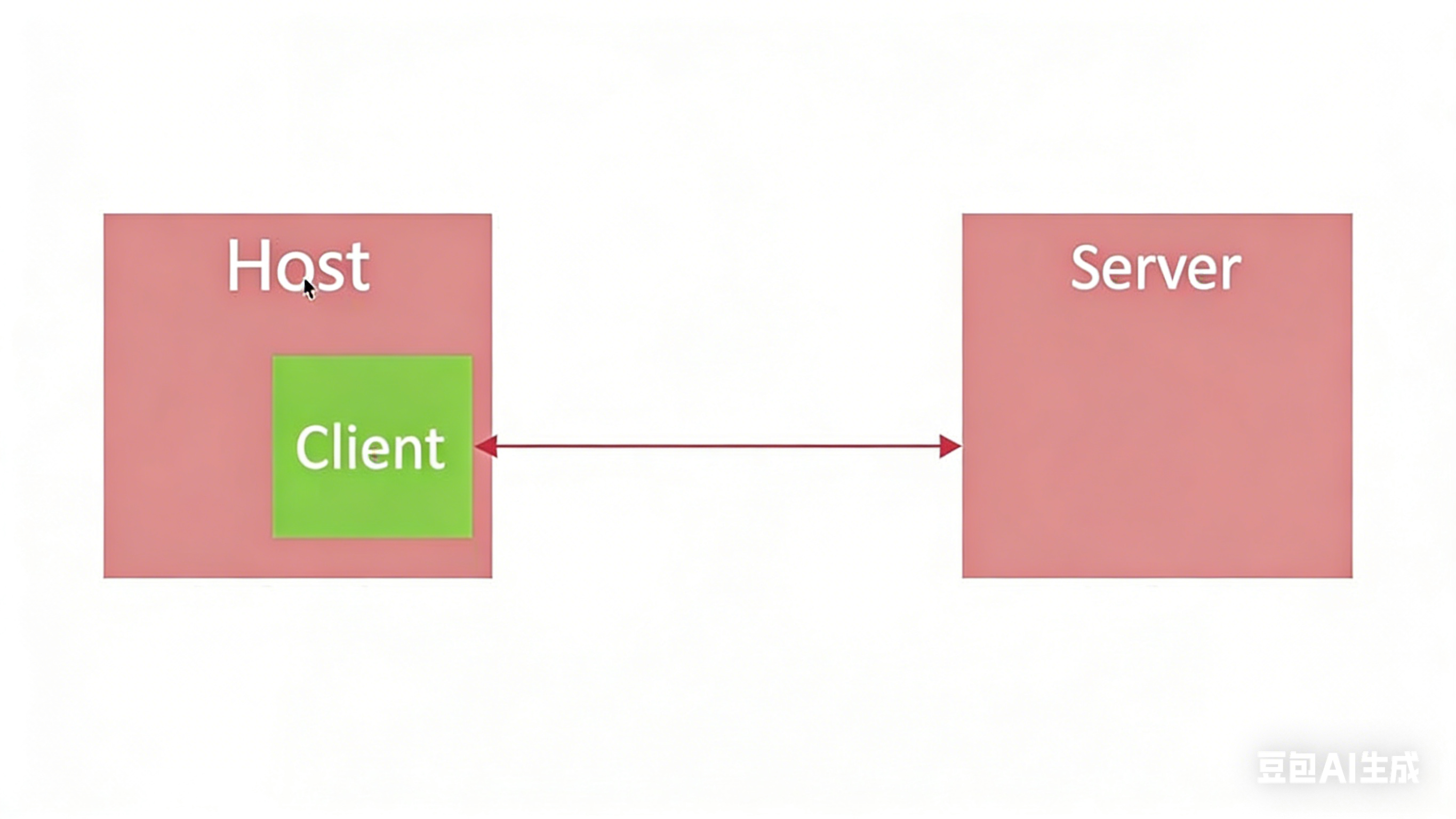
导读:理解 MCP 架构的关键在于厘清三个核心角色的职责与交互关系。本文档将结合图片内容,用工程化视角拆解 Host、MCP Client 和 MCP Server 的定义、职责及协作流程,助你构建清晰的架构认知。
🟢 第一部分:三大核心角色定义
💡 一句话总览:
MCP 架构由 Host (宿主)、Client (客户端) 和 Server (服务端) 组成。简单来说:Host 是大脑,Client 是嘴巴,Server 是手脚。
🏠 1. Host (宿主)
- 📝 定义:一般指的是 Agent 或承载 Agent 的应用程序(如 IDE、聊天机器人、自动化工作流平台)。
- 🧠 职责:
- 决策中心:负责理解用户意图,决定是否需要调用外部工具。
- 集成环境:它是 MCP Client 的“容器”,为 Client 提供运行环境和上下文。
- 最终执行者:接收 Server 返回的结果,整合后生成最终回复给用户。
- 🌰 例子:Claude Desktop 应用、LangChain 构建的 Agent、自定义的 AI 助手后端。
🗣️ 2. MCP Client (客户端)
- 📝 定义:用于与 MCP Server 进行通讯的组件,通常集成在 Host 内部。
- ⚙️ 职责:
- 协议翻译:将 Host 的内部指令转换为标准的 JSON-RPC 2.0 消息发送给 Server。
- 连接管理:负责建立和维护与一个或多个 MCP Server 的连接(通过 Stdio, HTTP, etc.)。
- 服务发现:启动时自动询问 Server:“你支持哪些工具 (Tools) 和资源 (Resources)?”并汇报给 Host。
- 🔍 关键点:Client 本身不包含业务逻辑,它只是一个通信代理 (Proxy)。
🛠️ 3. MCP Server (服务端)
- 📝 定义:一个独立运行的服务,提供具体的工具、资源或提示词能力。
- 🦾 职责:
- 能力暴露:将内部功能(如查数据库、读文件、调 API)封装成符合 MCP 标准的接口。
- 请求处理:监听来自 Client 的 JSON-RPC 请求,执行业务逻辑,返回结果。
- 安全边界:控制访问权限,确保只暴露被允许的数据和操作。
- 🌰 例子:一个专门读取本地文件的
mcp-server-filesystem进程,或一个连接 GitHub API 的mcp-server-github服务。
🔵 第二部分:三者如何协作?(工作流详解)
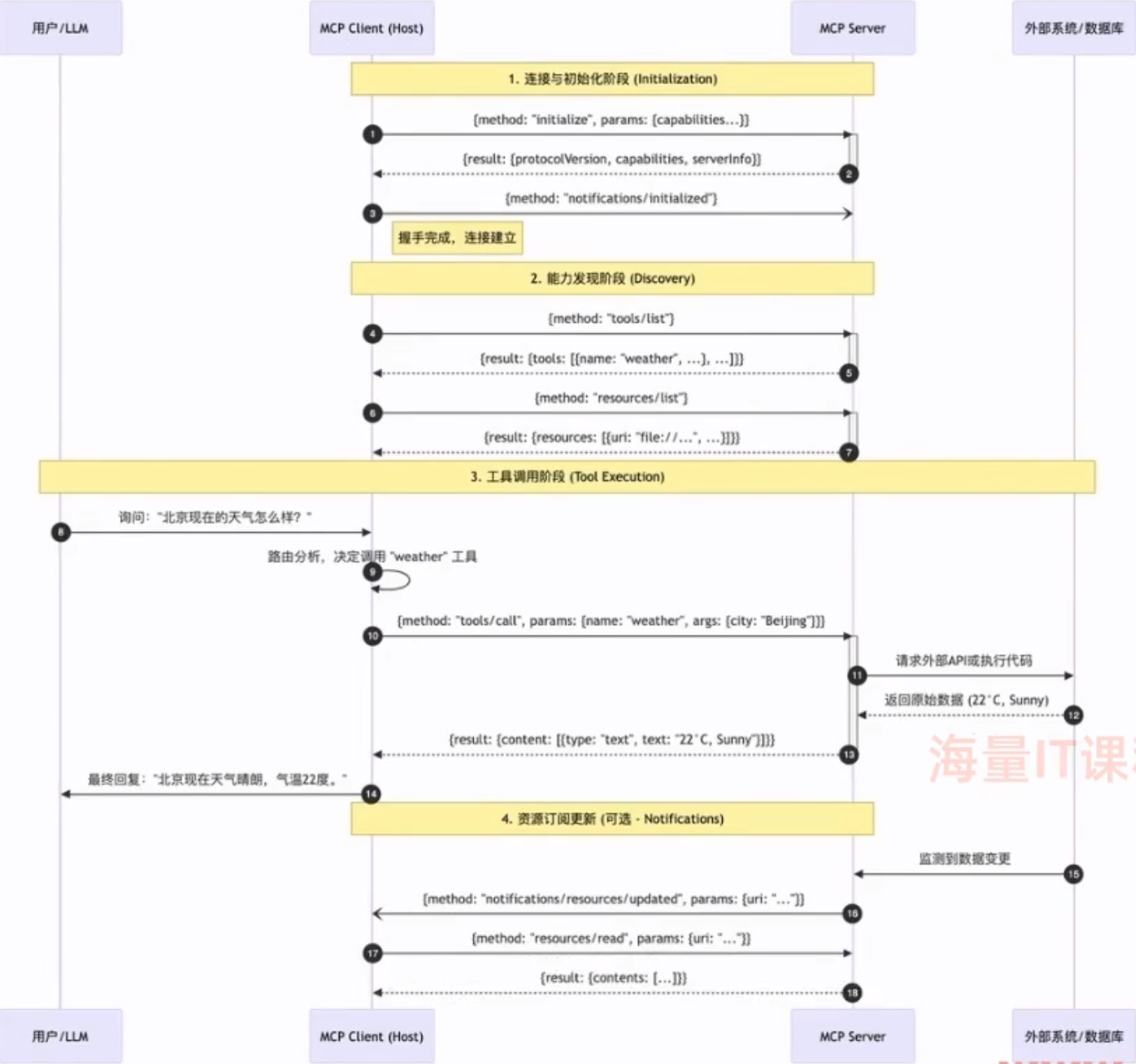
⚙️ 标准交互流程 (五步走):
-
启动与发现:
- Host 启动,加载内置的 MCP Client。
- Client 根据配置连接到 MCP Server (例如启动一个本地进程)。
- Client 询问 Server:“你能做什么?” -> Server 返回工具列表 (List Tools)。
- Host 获知可用工具,将其注册到 Agent 的工具库中。
-
用户触发:
- 用户向 Host 提问:“帮我读取桌面的 config.txt 文件”。
-
决策与调用:
- Host (Agent) 分析意图,决定调用
read_file工具。 - Host 指挥 Client:“调用
read_file,参数path=~/Desktop/config.txt”。 - Client 将指令打包成 JSON-RPC 请求,发送给 Server。
- Host (Agent) 分析意图,决定调用
-
执行与反馈:
- Server 收到请求,执行真实的文件读取操作。
- Server 将文件内容封装成 JSON-RPC 响应,回传给 Client。
- Client 解析响应,将结果交给 Host。
-
最终回复
- Host 拿到文件内容,结合上下文生成自然语言回答:“config.txt 的内容是…”。
🟣 第三部分:工程落地关键点
- 🔧 部署模式选择
- 本地进程 (Stdio):
- 场景:访问本地文件、本地数据库。
- 实现:Host 直接 spawn 一个子进程运行 Server,通过标准输入输出 (Stdin/Stdout) 通信。
- 优势:低延迟,无需网络,安全性高(仅限本地)。
- 远程服务 (HTTP/SSE):
- 场景:访问云端 API、共享微服务。
- 实现:Server 部署为独立的 Web 服务,Client 通过 HTTP POST 或 SSE 连接。
- 优势:可跨网络,支持多 Host 共享同一个 Server。
- 本地进程 (Stdio):
- 🛡️安全与权限
- 最小权限原则:Server 只应暴露必要的工具。例如,文件 Server 不应暴露 delete_file,除非明确需要。
- 用户确认:对于敏感操作(如写入文件、发送邮件),Host 应在调用前弹出对话框让用户二次确认。
- 隔离运行:建议将不同的 MCP Server 运行在独立的沙箱或容器中,防止一个 Server 被攻破后影响整个系统。
- 📈扩展性设计
- 多 Server 支持:一个 Host 应能同时连接多个 Server(如同时连接 文件Server + GitHub Server + 数据库Server)。
- 动态加载:支持在不重启 Host 的情况下,动态添加或移除 MCP Server 连接。
流程演示DEMO
import json
import subprocess
import requests
# --- 1. MCP Client 实现 (通信代理) ---
class MCPClient:
def __init__(self, command):
# 场景 A: 本地进程通信 (Stdio)
self.process = subprocess.Popen(
command,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
text=True
)
self.request_id = 0
def _send_json_rpc(self, method, params=None):
"""发送标准的 JSON-RPC 2.0 请求"""
self.request_id += 1
request = {
"jsonrpc": "2.0",
"id": self.request_id,
"method": method,
"params": params or {}
}
# 写入 stdin 并添加换行符
self.process.stdin.write(json.dumps(request) + "\n")
self.process.stdin.flush()
# 读取 stdout 响应
response_line = self.process.stdout.readline()
return json.loads(response_line)
def list_tools(self):
"""发现工具:调用 tools/list 接口"""
response = self._send_json_rpc("tools/list")
return response.get("result", {}).get("tools", [])
def call_tool(self, name, arguments):
"""调用工具:调用 tools/call 接口"""
params = {"name": name, "arguments": arguments}
response = self._send_json_rpc("tools/call", params)
return response.get("result", {}).get("content")
# --- 2. Host 实现 (决策大脑) ---
class Host:
def __init__(self):
# 初始化 Client,启动一个本地的 file-server
self.client = MCPClient(command=["mcp-server-filesystem"])
# 1. 服务发现
self.available_tools = self.client.list_tools()
print(f"发现工具: {[t['name'] for t in self.available_tools]}")
def run(self, user_query):
# 2. 决策 (模拟 LLM 判断)
# 实际场景中这里是 LLM 根据 user_query 和 available_tools 决定 action
if "读取" in user_query and "config.txt" in user_query:
action_name = "read_file"
action_args = {"path": "~/Desktop/config.txt"}
# 3. 通过 Client 执行调用
print(f"正在调用工具: {action_name}...")
result = self.client.call_tool(action_name, action_args)
# 4. 整合结果并回复
return f"文件读取成功,内容是: {result}"
return f"文件读取成功,内容是: {result}"
return "我不确定该如何操作。"
# --- 运行示例 ---
if __name__ == "__main__":
host = Host()
response = host.run("帮我读取桌面的 config.txt 文件")
print(response)
MCP Client与Server的交互原理
MCP Server
🔹 MCP Server 是什么?
MCP = Model Control Protocol(模型控制协议)
它是让 AI Client(如大模型、Agent)能安全、结构化访问外部服务/数据的“桥梁”。
不是框架,不是库 —— 是协议 + 架构模式。
📌 核心理论:三能力暴露模型
MCP Server 向 Client 暴露三种原子能力:
-
📁 Resources(资源) → “我有什么数据?”
- 例:文件、数据库记录、API 返回结果
- 本质:只读数据源,Client 可查询但不可修改
-
⚙️ Tools(工具) → “我能帮你做什么?”
- 例:执行函数、调用 API、运行脚本
- 关键:Client 决定参数,Server 执行并返回结果
- 安全边界:Server 控制权限与输入校验
-
💬 Prompts(提示模板) → “你怎么问我才最有效?”
- Server 预定义专业 Prompt 模板,引导 Client 正确提问
- 例:“请用 SQL 查询用户表,字段包括 name, email, created_at"
🛠️ 工程应用方法:如何构建一个 MCP Server?
✅ 步骤一:选择通信协议(HTTP/gRPC/WebSocket)
✅ 步骤二:实现三个接口端点:
GET /resources→ 返回可用资源列表POST /tools/{tool_name}→ 接收参数,执行逻辑,返回结果GET /prompts→ 返回预定义 Prompt 模板
✅ 步骤三:封装业务逻辑为 Tool 函数,确保无副作用、可重试、有日志
✅ 步骤四:添加认证 & 限流机制(JWT + Rate Limiting)
🚀 最佳落地方案:轻量级 Python 示例
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import sqlite3
app = FastAPI()
# === Resources ===
@app.get("/resources")
def list_resources():
return ["users.db", "logs.txt"]
# === Tools ===
class ToolInput(BaseModel):
user_id: int
@app.post("/tools/get_user")
def get_user(input: ToolInput):
conn = sqlite3.connect("users.db")
cursor = conn.cursor()
cursor.execute("SELECT * FROM users WHERE id=?", (input.user_id,))
row = cursor.fetchone()
conn.close()
if not row:
raise HTTPException(404, "User not found")
return {"id": row[0], "name": row[1], "email": row[2]}
# === Prompts ===
@app.get("/prompts")
def get_prompts():
return [
{
"name": "query_user_by_id",
"template": "请调用 get_user 工具,传入 user_id 参数获取用户信息"
}
]
▶️ 启动后,Client 可通过 HTTP 调用:
curl http://localhost:8000/resources
curl -X POST http://localhost:8000/tools/get_user -H "Content-Type: application/json" -d '{"user_id": 1}'
curl http://localhost:8000/prompts
💡 核心知识总结(一句话版)
- MCP Server = 数据+功能+指令的标准化出口,让 AI Client 像插 U 盘一样“即插即用”外部系统。
🎯 为什么它重要?
- ✅ 解耦:AI 不直接碰数据库/API,由 Server 统一管控
- ✅ 安全:所有操作经过 Server 审计与过滤
- ✅ 可扩展:新增 Tool/Resources/Prompt 无需改 Client
- ✅ 标准化:不同团队/系统遵循同一协议,互操作性强
🧩 进阶技巧:动态注册 Tool
- → 支持热加载新工具,适合插件化架构!
TOOL_REGISTRY = {}
def register_tool(name, func):
TOOL_REGISTRY[name] = func
@register_tool("add_numbers")
def add(a: int, b: int) -> int:
return a + b
@app.post("/tools/{tool_name}")
def run_tool(tool_name: str, params: dict):
if tool_name not in TOOL_REGISTRY:
raise HTTPException(404, "Tool not found")
return TOOL_REGISTRY[tool_name](**params)
🔐 安全建议清单
- 🔒 所有 Tool 输入必须做 Schema 校验(Pydantic)
- 🛑 禁止执行任意代码(eval/exec/shell)
- 📊 记录每次 Tool 调用日志(谁?何时?做了什么?)
- 🧭 使用 RBAC 控制哪些 Client 能访问哪些 Resource/Tool
📈 未来演进方向
- 🤖 自动发现 Resource/Tool(类似 OpenAPI Swagger)
- 🔄 支持异步 Tool(长任务回调通知)
- 🌐 多语言 SDK(Go/Rust/Node.js 客户端)
- 🧠 结合 RAG:Resource 自动向量化供检索增强生成
✅ 最终结论:
- MCP Server 不是炫技,而是工程落地的必需品。
- 它把混乱的外部系统整理成 AI 能理解的“乐高积木”,让智能体真正具备“动手能力”。
- 用得好 → AI 成为超级助手
- 用不好 → AI 变成危险黑洞
✨ 记住这个公式:
- MCP Server = Resources(数据) + Tools(动作) + Prompts(指南) × 安全 × 标准化
MCP Client与Server交互
🔹 MCP协议核心解析:基于JSON-RPC的Client-Server交互
✅ 核心思想:
是LLM或Agent框架)发起请求 → Server执行具体任务 → 返回结构化结果
- 所有交互通过
method+params+result标准化封装
📌 1. JSON-RPC消息结构详解
🔵 Client 请求示例(调用天气服务)
{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/call",
"params": {
"name": "get_weather",
"arguments": { "city": "Beijing" }
}
}
🟢 Server 响应示例(返回天气数据)
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"content": [
{ "type": "text", "text": "Sunny, 25C" }
]
}
}
💡 关键字段说明:
| 字段 | 作用 |
|---|---|
jsonrpc |
固定为 "2.0",标识协议版本 |
id |
请求唯一ID,用于匹配响应(同步/异步都支持) |
method |
调用的方法名,如 tools/call 是MCP标准入口 |
params.name |
实际要调用的工具名称(如 get_weather) |
params.arguments |
传给工具的参数对象 |
result.content |
服务器返回的内容数组,每项含 type 和 text |
- ⚠️ 注意: MCP规定所有输出必须是 content: [{ type: “…”, text: “…” }] 格式,便于前端渲染或后续处理。
📌 2. MCP协议规范与SDK
- 🌐 官方资源:
- 👉 GitHub仓库:https://github.com/modelcontextprotocol
- 📦 SDK 提供:
- Python / TypeScript 等语言的客户端和服务端模板
- 自动序列化/反序列化 JSON-RPC 消息
- 内置常见工具实现(FileSystem, SQLite, Git…)
- 支持自定义工具注册和权限控制
🛠️ 工程应用方法:
- 定义工具接口 —— 在Server端实现函数并注册到MCP路由
- 配置Client连接 —— 指定Server地址、认证方式(可选)
- 发送标准化请求 —— 使用SDK构造符合MCP规范的JSON-RPC消息
- 解析响应内容 —— 提取 result.content[].text 进行展示或下一步逻辑
📌 3. 常见MCP Server类型及功能
- 🔸 modelcontextprotocol/server —— 官方参考实现,包含基础工具集
🔸 FileSystem- → 允许Agent读写本地文件(需沙箱隔离防误删)
- → 应用场景:代码生成后保存、日志分析、配置文件修改
- 🔸 SQLite
- → 让Agent直接查询数据库(只读或受限写入)
- → 应用场景:用户行为分析、订单状态查询、报表生成
- 🔸 Git
- → 执行git命令(commit/push/diff等),需权限管控
- → 应用场景:自动化PR描述、分支管理、变更摘要
- 🔸 Memory
- → 基于知识图谱的记忆服务,记录用户偏好/历史对话
- → 应用场景:个性化推荐、长期记忆增强、上下文延续 - → 应用场景:个性化推荐、长期记忆增强、上下文延续
📌 4. 自建MCP Server方案 vs 传统开发服务成本对比
| 维度 | 自建MCP Server | 传统REST/gRPC服务 |
|---|---|---|
| 🏗️ 架构复杂度 | ✅ 极低(只需实现几个handler) | ❌ 高(需设计API、鉴权、文档、Swagger等) |
| ⏱️ 开发周期 | ✅ 1~2天即可上线一个工具 | ❌ 数周起步(尤其涉及多角色协作时) |
| 🔐 安全性 | ✅ 内建沙箱+参数校验机制 | ❌ 需自行实现RBAC、输入过滤、速率限制 |
| 🤖 AI适配性 | ✅ 天然支持LLM调用,无需额外适配层 | ❌ 需包装成Prompt-friendly接口或中间件 |
| 💰 运维成本 | ✅ 单进程部署,无状态,易扩展 | ❌ 可能依赖DB、缓存、网关等组件 |
| 📈 可扩展性 | ✅ 新增工具=新增函数+注册,零侵入 | ❌ 修改API可能影响下游系统 |
🎯 最佳落地方案建议:
- ✔️ 对于内部AI助手项目 → 优先采用MCP协议快速搭建工具链
- ✔️ 对外暴露服务 → 可先用MCP原型验证需求,再逐步迁移到成熟微服务架构
- ✔️ 混合模式 → 核心业务走传统API,辅助功能(如文件操作、记忆存储)走MCP
📌 5. 完整代码演示:自建一个简单的MCP Server(Python版)
from mcp.server import Server
from mcp.types import TextContent
# 初始化Server实例
app = Server("my-mcp-server")
# 注册一个名为 get_weather 的工具
@app.call_tool()
async def get_weather(name: str, arguments: dict):
city = arguments.get("city", "Unknown")
# 模拟天气数据逻辑
return [TextContent(type="text", text=f"Sunny, 25C in {city}")]
if __name__ == "__main__":
# 启动服务,默认监听本地端口
app.run()
curl -X POST http://localhost:8000 \
-H "Content-Type: application/json" \
-d '{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/call",
"params": {
"name": "get_weather",
"arguments": {"city": "Shanghai"}
}
}'
✅ 输出结果:
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"content": [
{ "type": "text", "text": "Sunny, 25C in Shanghai" }
]
}
}
📌 7. 总结:MCP的核心价值一句话概括
-
“让AI像人一样‘动手’——通过标准化协议安全调用现实世界的能力,而不必重新发明轮子。”
-
“让AI像人一样‘动手’——通过标准化协议安全调用现实世界的能力,而不必重新发明轮子。”
A2A
🔹 A2A (Agent-to-Agent) 协议深度解析:Google的多智能体协作架构
📌 1. 技术定义与核心认知
- A2A = Agent-to-Agent Protocol
- 由 Google 推出的一种标准化通信协议,旨在解决多个异构 AI Agent 之间的互操作性问题。
- 它不是让一个 Agent 变得无所不能,而是建立一套“通用语言”,让擅长不同领域的 Agent(如编程、测试、绘图)能够像人类团队一样协同工作。
✅ 核心理念:
- 垂直分工:每个 Agent 只专注一个特定领域(Vertical Specialization),拒绝“大而全”的单体模型。
- 协作优先:通过标准化的消息传递和任务分发,实现复杂任务的拆解与并行处理。
- 层级定位:
- MCP (Model Context Protocol) 负责底层工具连接(手和脚)
📌 2. 实践原理:它是如何工作的?
- A2A 的核心在于将复杂的业务流程抽象为有向无环图 (DAG) 或 状态机,通过以下机制运作:
- 角色注册 (Registry):系统维护一个可用 Agent 列表及其能力描述(Capabilities)。
- 意图识别 (Intent Routing):主协调器(Orchestrator)接收用户指令,将其拆解为子任务。
- 动态编排 (Dynamic Orchestration):根据任务依赖关系,自动调用相应的 Agent。
- 例如:用户说“写个网页并测试” -> A2A 解析 -> 调用
Coder-Agent-> 等待完成 -> 调用Tester-Agent。
- 例如:用户说“写个网页并测试” -> A2A 解析 -> 调用
- 上下文共享 (Context Sharing):Agent 之间通过共享内存或消息队列传递中间结果,保持状态一致。
⚠️ 现状挑战:由于涉及复杂的分布式状态管理和容错机制,目前 A2A 的实现复杂度较高,工业界认可度尚在爬坡期。
📌 3. 应用场景:什么时候该用 A2A?
🔸 软件开发流水线 (SDLC)
- 场景:自动化代码生成、Review、单元测试、部署。
- 流程:Product-Agent (写需求) → Dev-Agent (写代码) → QA-Agent (跑测试) → Ops-Agent (部署)。
🔸 复杂数据分析报告
- 场景:从原始数据到商业洞察。
- 流程:SQL-Agent (取数) → Python-Agent (清洗/建模) → Viz-Agent (画图) → Writer-Agent (撰写结论)。
🔸 跨平台客户服务
- 场景:处理复杂的客诉。
- 流程:NLP-Agent (理解情绪) → Policy-Agent (查规则) → Action-Agent (执行退款/补偿)。
📌 4. 应用价值:为什么要搞这么复杂?
| 维度 | 传统单体 Agent | A2A 多智能体架构 |
|---|---|---|
| 🧠 能力边界 | 受限于上下文窗口和模型泛化能力,容易幻觉 | ✅ 术业有专攻,每个 Agent 可针对特定任务微调,精度更高 |
| 🛡️ 安全性 | 权限难以细粒度控制,一旦越权风险大 | ✅ 沙箱隔离,Coder 只能写代码,DB-Agent 才能查库,最小权限原则 |
| 🔄 可维护性 | 逻辑耦合严重,修改一处牵一发而动全身 | ✅ 模块化替换,觉得 Tester 不行?直接换个更强的 Tester Agent,不影响其他 |
| 🚀 扩展性 | 升级困难 | ✅ 即插即用,新增一个功能只需增加一个新 Agent 节点 |
📌 5. 代码落地演示:基于 LangGraph 的严谨 A2A 实现
为了确保代码的完整性和严谨性,本示例包含:
- 强类型状态定义:使用
TypedDict和Annotated管理共享状态。 - 显式路由逻辑:不仅仅是线性执行,展示了如何根据状态决定下一步(条件边)。
- 完整的依赖安装与运行结构:可直接复制运行的脚本。
前置准备:
pip install langgraph langchain-core
完整代码 (a2a_workflow.py):
from typing import Annotated, TypedDict, List, Literal
from langgraph.graph import StateGraph, END
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
# ==========================================
# 1. 定义共享状态 (Shared State)
# A2A 的核心是状态在 Agent 间流转
# ==========================================
class AgentState(TypedDict):
# 消息历史列表,支持追加操作
messages: Annotated[List[BaseMessage], lambda x, y: x + y]
# 当前工作流阶段,用于路由决策
current_stage: str
# 任务执行结果标记
task_status: Literal["pending", "success", "failed"]
# ==========================================
# 2. 定义垂直领域的 Agent (Vertical Agents)
# 每个函数代表一个独立的 Agent 节点
# ==========================================
def coder_agent(state: AgentState) -> dict:
"""
👨💻 程序员 Agent
职责:接收需求,生成代码逻辑
"""
print("\n[👨 Coder Agent] 正在分析需求并编写代码...")
# 模拟 LLM 处理逻辑
last_msg = state["messages"][-1].content if state["messages"] else "No input"
generated_code = f"def solve_task():\n # Solving: {last_msg}\n return 'Success'"
return {
"messages": [AIMessage(content=f"Code Generated:\n{generated_code}")],
"current_stage": "testing",
"task_status": "pending"
}
def tester_agent(state: AgentState) -> dict:
"""
🧪 测试员 Agent
职责:验证代码逻辑,返回测试结果
"""
print("\n[🧪 Tester Agent] 正在运行单元测试和边界检查...")
# 模拟测试逻辑:这里假设测试总是通过,实际项目中可接入真实测试框架
test_result = "All tests passed. Coverage: 98%."
status = "success"
# 模拟一个失败场景来演示路由逻辑 (可选)
# if "bug" in str(state["messages"]):
# test_result = "Critical bug found!"
# status = "failed"
return {
"messages": [AIMessage(content=f"Test Report: {test_result}")],
"current_stage": "review" if status == "success" else "fixing",
"task_status": status
}
def fixer_agent(state: AgentState) -> dict:
"""
🔧 修复员 Agent (仅在测试失败时激活)
职责:根据测试报告修复代码
"""
print("\n[🔧 Fixer Agent] 检测到失败,正在紧急修复...")
return {
"messages": [AIMessage(content="Bug fixed. Re-submitting for testing.")],
"current_stage": "testing",
"task_status": "pending"
}
def reviewer_agent(state: AgentState) -> dict:
"""
👁️ 审核员 Agent
职责:最终确认,结束流程
"""
print("\n[👁️ Reviewer Agent] 进行最终代码审查...")
return {
"messages": [AIMessage(content="✅ Code Review Passed. Ready for deployment.")],
"current_stage": "done",
"task_status": "success"
}
# ==========================================
# 3. 构建 A2A 协作图 (Orchestration Graph)
# 定义节点连接与条件路由逻辑
# ==========================================
workflow = StateGraph(AgentState)
# 注册所有 Agent 节点
workflow.add_node("coder", coder_agent)
workflow.add_node("tester", tester_agent)
workflow.add_node("fixer", fixer_agent)
workflow.add_node("reviewer", reviewer_agent)
# 设置入口点
workflow.set_entry_point("coder")
# 定义线性连接:Coder -> Tester
workflow.add_edge("coder", "tester")
# 定义条件路由:Tester -> (Fixer OR Reviewer)
def route_after_test(state: AgentState) -> Literal["fixer", "reviewer"]:
if state["task_status"] == "failed":
return "fixer"
return "reviewer"
workflow.add_conditional_edges(
"tester",
route_after_test,
{
"fixer": "fixer",
"reviewer": "reviewer"
}
)
# 定义修复后的回路:Fixer -> Tester (闭环)
workflow.add_edge("fixer", "tester")
# 定义结束点:Reviewer -> END
workflow.add_edge("reviewer", END)
# 编译图
app = workflow.compile()
# ==========================================
# 4. 执行与验证
# ==========================================
if __name__ == "__main__":
print("🚀 启动 A2A 多智能体协作流程...\n")
# 初始输入
initial_input = {
"messages": [HumanMessage(content="Create a function to calculate Fibonacci sequence")],
"current_stage": "coding",
"task_status": "pending"
}
try:
# invoke 触发整个流程
final_state = app.invoke(initial_input)
print("\n" + "="*40)
print("✅ A2A 协作完成!最终输出日志:")
print("="*40)
for msg in final_state["messages"]:
role = "User" if isinstance(msg, HumanMessage) else "Agent"
# 简单截断长内容以便阅读
content = msg.content[:100] + "..." if len(msg.content) > 100 else msg.content
print(f"[{role}]: {content}")
t("✅ A2A 协作完成!最终输出日志:")
print("="*40)
for msg in final_state["messages"]:
role = "User" if isinstance(msg, HumanMessage) else "Agent"
# 简单截断长内容以便阅读
content = msg.content[:100] + "..." if len(msg.content) > 100 else msg.content
print(f"[{role}]: {content}")
except Exception as e:
print(f"❌ 流程执行出错: {e}")
代码逻辑解析:
- 状态驱动:AgentState 中的 task_status 字段决定了流程走向。
- 条件路由:route_after_test 函数体现了 A2A 的智能决策能力——测试失败自动转给 Fixer,成功后转给 Reviewer。
- 闭环处理:Fixer 完成后不会直接结束,而是回到 Tester 重新验证,形成自动化闭环。- 条件路由:route_after_test 函数体现了 A2A 的智能决策能力——测试失败自动转给 Fixer,成功后转给 Reviewer。
- 闭环处理:Fixer 完成后不会直接结束,而是回到 Tester 重新验证,形成自动化闭环。
📌 6. 最佳工程建议与避坑指南
- 🎯 不要过度设计 (Over-engineering)
- 如果任务很简单(如只是查天气),不要用 A2A。单个 Prompt 或 MCP 工具调用足矣。
- A2A 适用于长链路、多步骤、高容错要求的场景。
- 🏗️ 明确边界 (Clear Boundaries)
- 严格定义每个 Agent 的输入/输出 Schema。如果 Coder 输出的代码格式 Tester 读不懂,整个链条就会断裂。
- 建议使用 Pydantic 等库进行强类型约束。
- 🧩 引入“管理者” (The Manager Pattern)
- 在复杂场景中,需要一个专门的 Manager-Agent 来监控流程,处理异常(比如测试失败了,是重试还是回滚?)。
- 📉 成本控制
- 多 Agent 意味着多次 LLM 调用,Token 消耗成倍增加。
- 优化策略:小任务用小模型(如 Haiku/Llama-3-8B),关键决策用大模型(如 Opus/GPT-4)。
📌 7. 总结:A2A 的未来展望
- “独行快,众行远。”
- A2A 代表了 AI 应用开发的下一个阶段:从Prompt Engineering(提示词工程)转向 Agent Engineering(智能体工程)。
- 虽然目前因复杂性导致落地门槛高,但随着 MCP (底层连接) 的成熟和 A2A (上层编排) 标准的统一,未来我们将看到真正的“AI 员工团队”在企业中大规模上岗。
💡 一句话掌握:
MCP 是给 Agent 装手脚(连工具),A2A 是给 Agent 建组织(定流程)。两者结合,才是完整的 AI 自动化解决方案。
Agent之Memory(记忆)与上下文技术体系
- 记忆系统与上下文循环

- 记忆与记忆压缩
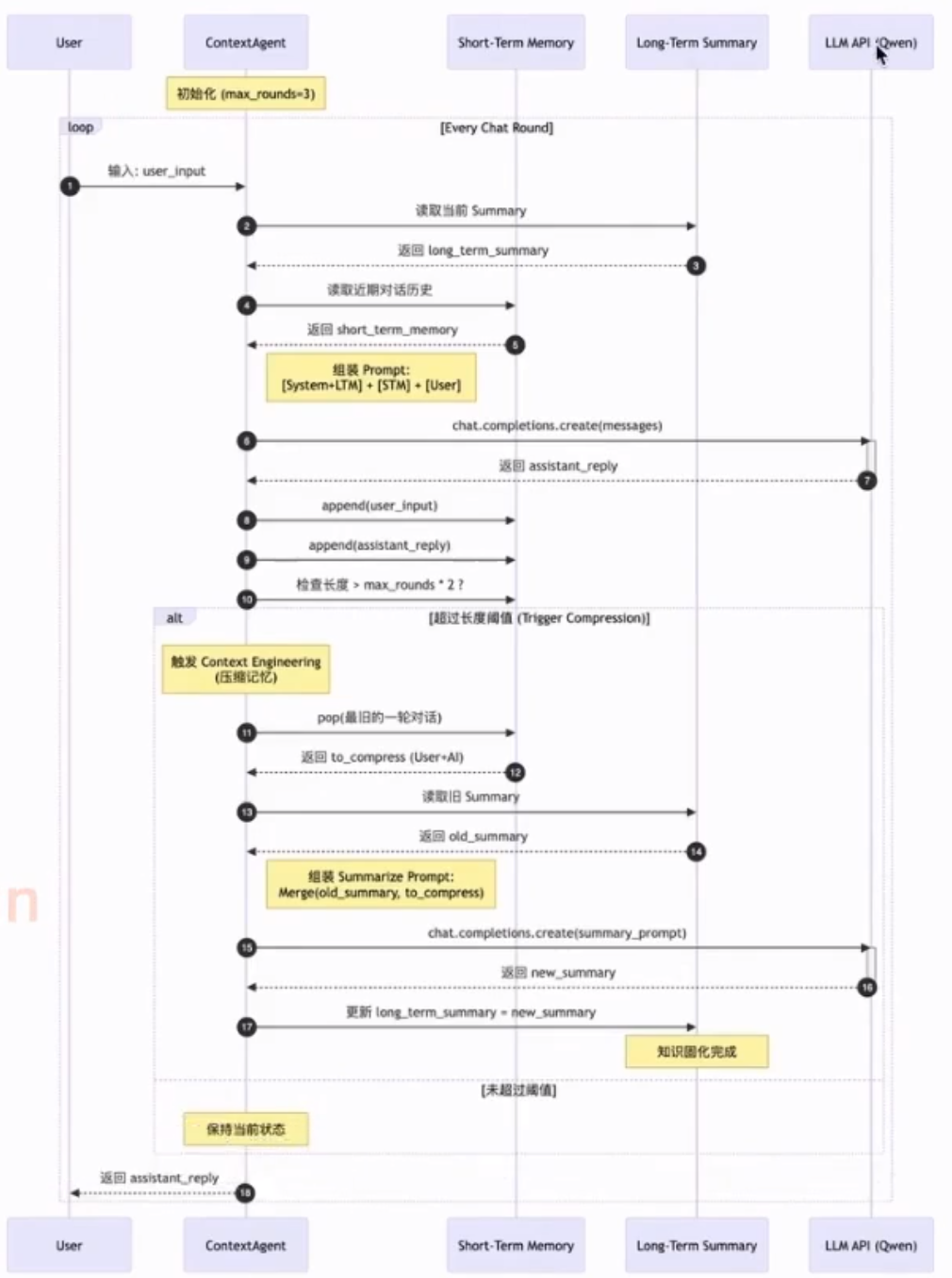
上下文记忆系统的DEMO
from openai import OpenAI
import os
import dotenv
dotenv.load_dotenv()
client = OpenAI(
# 如果没有配置环境变量,请用阿里云百炼API Key替换:api_key="sk-xxx"
api_key=os.getenv("ALI_MODEL_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 压缩Agent记忆
class CompressedAgentMemory:
def __init__(self, model="qwen3.5-35b-a3b"):
self.model = model
self.short_term_memory = [] # 储存近期的完整的对话历史
self.long_term_summary = "" # 储存之前的任务总结,此处采用字符串形式储存,也可以保存成文件或者数据库
self.max_short_term_rounds = 3 # 设置阀值,超过该值,将压缩记忆
def _summarize_memory(self, old_summary, new_memory):
"""
总结记忆,将新的记忆与旧的记忆利用LLM进行总结,并返回新的总结
Args:
old_summary: 旧的记忆总结
new_memory: 新的记忆
Returns:
new_summary: 新的记忆总结
"""
print("开始记忆和压缩...")
# 构造总结任务的提示词
prompt = f"""
你是一个经验丰富的记忆管理总结专家,请将以下对话内容浓缩并更新到现有的”背景摘要“中。
要求:保留关键事实(如:姓名,姓名,性别,年龄,职业,兴趣爱好,联系方式,决定,决策,事件等)。
现有的背景摘要:{old_summary}
新的对话内容:{new_memory}
请生成一个新的,内容精炼的背景摘要。
"""
response = client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
)
# 返回新的总结
return response.choices[0].message.content
def chat(self, user_input):
# 构建最终的prompt
system_prompt = f"""
你是一个智能助手。
以下是之前的对话背景摘要(长期记忆):
{self.long_term_summary if self.long_term_summary else "无长期记忆"}
"""
# 组合消息:带聊天摘要+短期记忆+当前用户输入
# 聊天摘要
messages = [
{"role": "system", "content": system_prompt},
]
# 短期记忆
messages.extend(self.short_term_memory)
# 当前用户输入
messages.append({"role": "user", "content": user_input})
# 调用LLM
response = client.chat.completions.create(
model=self.model,
messages=messages,
)
# 回复的信息
assistant_replay = response.choices[0].message.content
# 更新短期记忆(本次对话)
self.short_term_memory.append({"role": "user", "content": user_input})
self.short_term_memory.append(
{"role": "assistant", "content": assistant_replay}
)
# 判断是否需要压缩记忆
if len(self.short_term_memory) > self.max_short_term_rounds * 2:
# 拿出最老的一轮对话进行压缩
need_compress_memory = self.short_term_memory[:2]
# 剩下的作为新的短期记忆
self.short_term_memory = self.short_term_memory[2:]
# 把最老的一轮对话转换成字符串并压缩并更新长期记忆
need_compress_memory_str = f"User: {need_compress_memory[0]['content']}\nAssistant: {need_compress_memory[1]['content']}"
self.long_term_summary = self._summarize_memory(
self.long_term_summary, need_compress_memory_str
)
# 返回回复
return assistant_replay
if __name__ == "__main__":
agent = CompressedAgentMemory()
print("Round1:", agent.chat("你好我是孙海亮,我是一名全栈AI工程师"))
print("Round2:", agent.chat("我最近在研究AI LLM技术"))
print("Round3:", agent.chat("我想开发一个帮我写代码的工具!"))
# 测试记忆
print("Rlund4", agent.chat("我是谁?"))
print("Round5", agent.chat("我最近在研究什么技术?"))
Agent 技术实践(翻译)
工作流
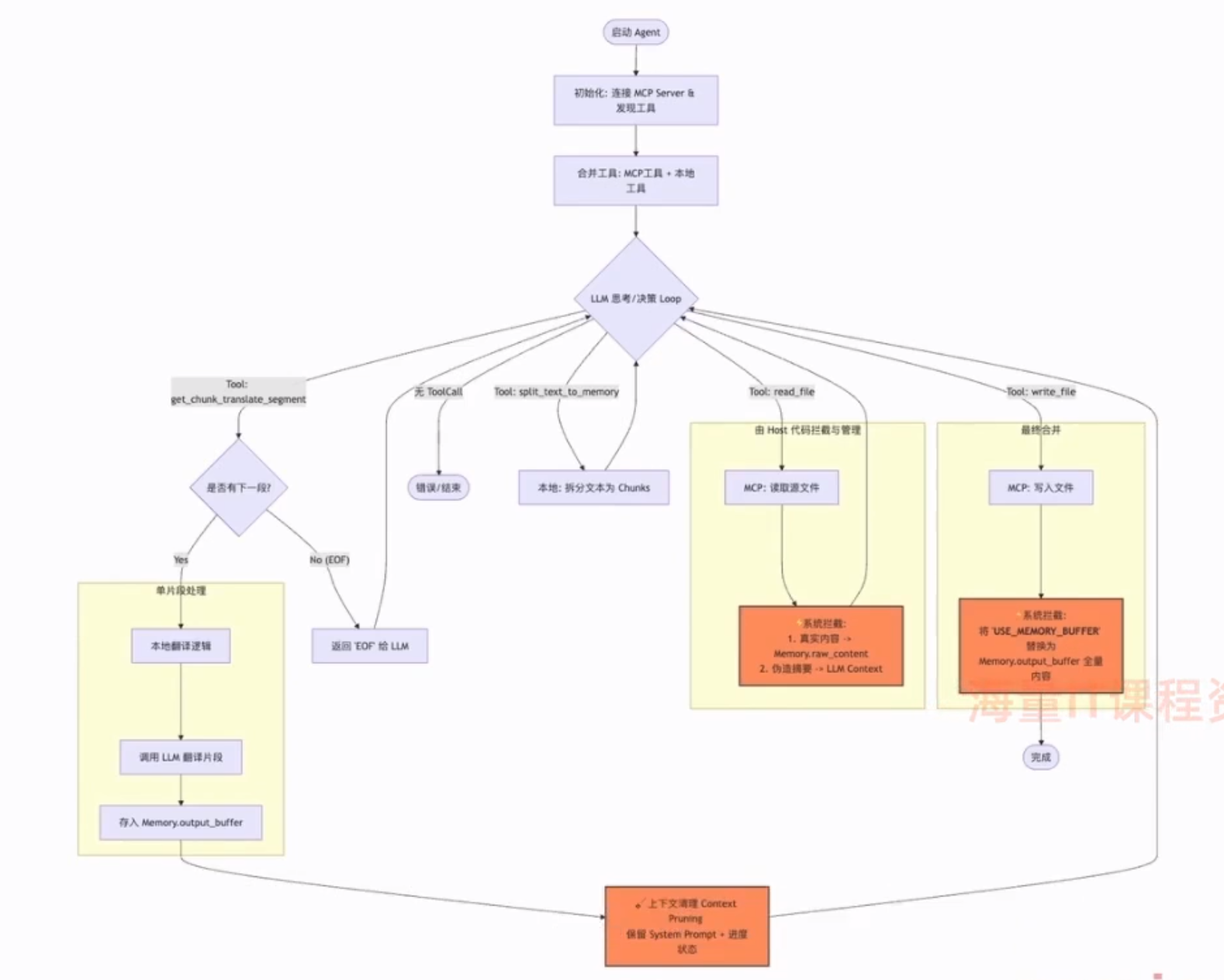
时序图
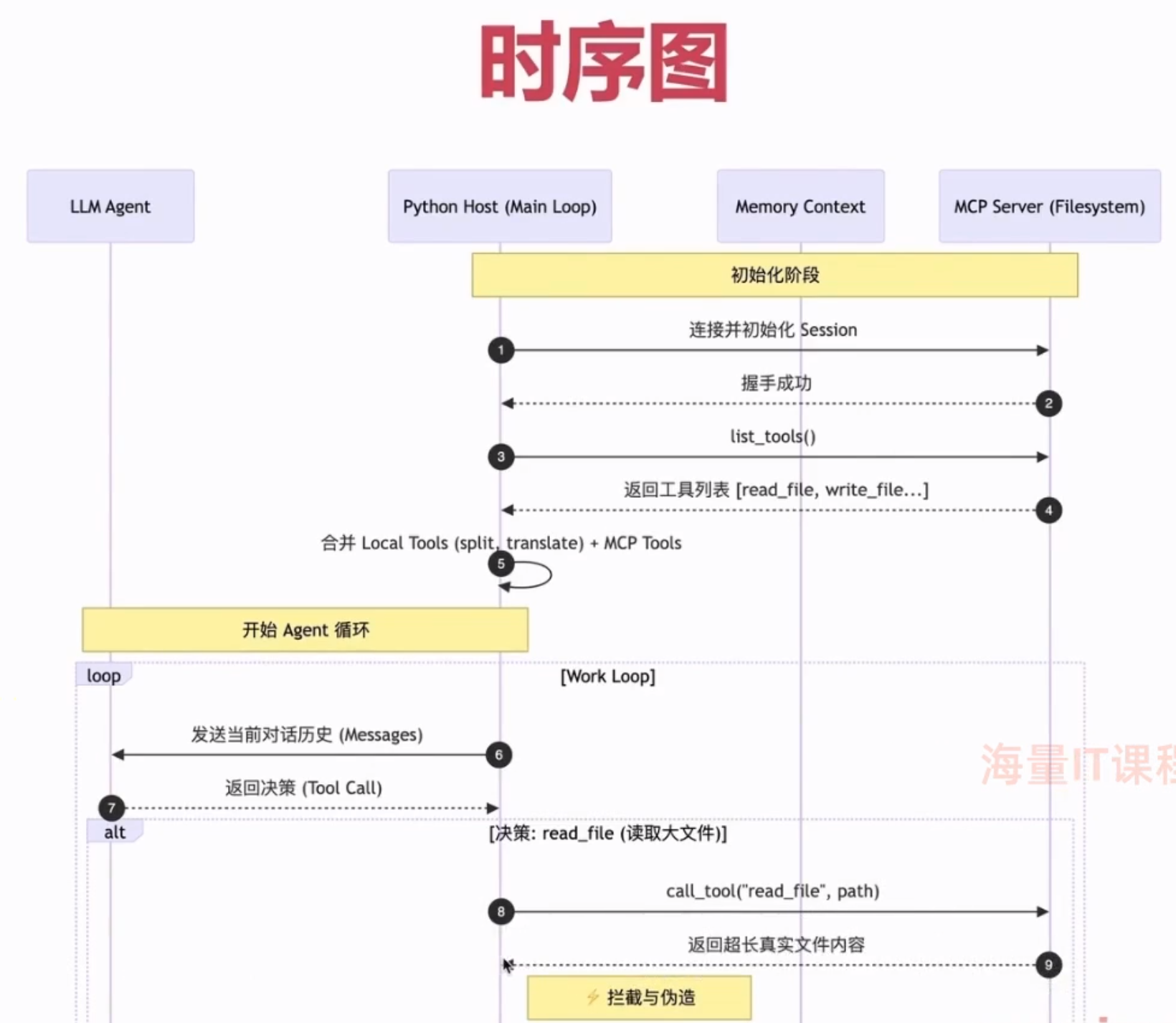


代码实战
先做一个MCP服务
第一步:安装相关依赖pip install fastapi uvicorn pydantic
第二步:创建代码目录
mcp-jsonrpc-server/
│
├── app/
│ ├── main.py
│ ├── config.py
│ ├── tools.py
│ ├── registry.py
│ └── schemas.py
│
├── requirements.txt
└── run.sh
第三步:往代码目添加MCP服务基本代码
- JSON-RPC 数据结构(schemas.py)
# app/schemas.py
from pydantic import BaseModel
from typing import Any, Optional
class JSONRPCRequest(BaseModel):
jsonrpc: str
id: Optional[int | str]
method: str
params: Optional[dict] = None
class JSONRPCResponse(BaseModel):
jsonrpc: str = "2.0"
id: Optional[int | str]
result: Any = None
error: Optional[dict] = None
- 工具注册(tools.py)
# app/tools.py
import os
# 指向agent的data目录
DOCUMENT_DIR = "./data"
def add(a: int, b: int) -> int:
"""Add two numbers."""
return a + b
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# ========= Markdown 读取 =========
def read_markdown_tool(filename: str) -> dict:
"""
读取 DOCUMENT_DIR 下的 markdown 文件。
与 registry.call_tool 中的 func(**params) 对齐:params 应包含 {"filename": "..."}。
"""
if not filename:
raise ValueError("filename is required")
if ".." in filename:
raise ValueError("Invalid filename")
file_path = os.path.join(DOCUMENT_DIR, filename)
if not os.path.exists(file_path):
raise ValueError("File not found")
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
return {"filename": filename, "content": content}
# ========= Markdown 写入 =========
def write_markdown_tool(filename: str, content: str) -> dict:
"""
将内容写入 DOCUMENT_DIR 下的 markdown 文件。
与 registry.call_tool 中的 func(**params) 对齐:params 应包含 {"filename": "...", "content": "..."}。
"""
if not filename:
raise ValueError("filename is required")
if content is None:
raise ValueError("content is required")
if ".." in filename:
raise ValueError("Invalid filename")
file_path = os.path.join(DOCUMENT_DIR, filename)
os.makedirs(DOCUMENT_DIR, exist_ok=True)
with open(file_path, "w", encoding="utf-8") as f:
f.write(content)
return {"filename": filename, "status": "written", "length": len(content)}
TOOLS = {
"add": {
"func": add,
"description": "Add two integers",
"parameters": {"a": "int", "b": "int"},
},
"multiply": {
"func": multiply,
"description": "Multiply two integers",
"parameters": {"a": "int", "b": "int"},
},
"read_markdown_tool": {
"func": read_markdown_tool,
"description": "Read a markdown file",
"parameters": {"filename": "string"},
},
"write_markdown_tool": {
"func": write_markdown_tool,
"description": "Write a markdown file",
"parameters": {"filename": "string", "content": "string"},
},
}
- 工具调度层(registry.py)
# app/registry.py
from app.tools import TOOLS
def list_tools():
return [
{
"name": name,
"description": meta["description"],
"parameters": meta["parameters"],
}
for name, meta in TOOLS.items()
]
def call_tool(name: str, params: dict):
if name not in TOOLS:
raise ValueError("Tool not found")
func = TOOLS[name]["func"]
return func(**params)
- 主程序(main.py)
# app/main.py
from fastapi import FastAPI
from app.schemas import JSONRPCRequest, JSONRPCResponse
from app.registry import list_tools, call_tool
app = FastAPI()
@app.post("/rpc")
async def rpc_handler(request: JSONRPCRequest):
if request.jsonrpc != "2.0":
return JSONRPCResponse(
id=request.id,
error={"code": -32600, "message": "Invalid JSON-RPC version"},
)
try:
if request.method == "tools/list":
result = list_tools()
elif request.method == "tools/call":
tool_name = request.params.get("name")
arguments = request.params.get("arguments", {})
result = call_tool(tool_name, arguments)
else:
return JSONRPCResponse(
id=request.id,
error={"code": -32601, "message": "Method not found"},
)
return JSONRPCResponse(id=request.id, result=result)
except Exception as e:
return JSONRPCResponse(
id=request.id, error={"code": -32000, "message": str(e)}
)
第四步:启动服务
uvicorn app.main:app --host 0.0.0.0 --port 8000
在做一个Agent调用MCP+本地服务
- 第一步:封装MCP请求
import requests
class MCPHttpClient:
def __init__(self, url: str):
self.url = url
self.session = requests.Session() # 复用 TCP 连接
def call(self, method: str, params: dict = None, request_id: int = 1):
payload = {
"jsonrpc": "2.0",
"id": request_id,
"method": method,
"params": params or {},
}
try:
response = self.session.post(self.url, json=payload, timeout=5)
response.raise_for_status() # 抛出 HTTP 错误
data = response.json()
# JSON-RPC 成功时服务端可能返回 error: null,仅当 error 非空才视为错误
err = data.get("error")
if err is not None:
raise RuntimeError(f"RPC Error: {err}")
return data.get("result")
except requests.RequestException as e:
raise RuntimeError(f"Request failed: {e}")
def list_tools(self):
"""列出 MCP Server 暴露的所有工具(自定义 + 内置),对应 JSON-RPC 方法 tools/list"""
return self.call("tools/list")
def call_tool(self, name: str, arguments: dict):
"""
调用 MCP Server 上的具体工具。
- JSON-RPC method 固定为 tools/call
- 具体工具名称通过 params.name 传递
- 参数通过 params.arguments 传递
这与 mcp_workspace/mcp_server/app/main.py 中的实现严格对应。
"""
return self.call(
"tools/call",
{"name": name, "arguments": arguments},
)
- 第二步:封装本地的API
import os
import dotenv
import asyncio
from openai import OpenAI
from typing import List, Dict, Any
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 拆分文档
"""
拆分文档,将原始文本拆分成多个chunk,每个chunk的大小为800,overlap为100
参数:
memory: 上下文记忆
返回:
f"拆分完成,内存已有{len(chunks)}个chunk"
"""
def local_tool_split(memory):
"""
拆分文档
"""
print("【local】开始拆分文档...")
splitter = RecursiveCharacterTextSplitter(
chunk_size=800, chunk_overlap=100
)
chunks = splitter.split_text(memory.row_content)
memory.source_chunks = chunks
print(f"【local】拆分文档完成,共拆分成{len(chunks)}个chunk")
memory.read_cursor = 0
print(f"【local】游标重置为{memory.read_cursor}")
memory.output_buffer = []
print("【local】输出缓冲区重置")
return f"拆分完成,内存已有{len(chunks)}个chunk"
# 读取下一份chunk并进行翻译
def local_tool_get_next_chunk_and_tanslate(memory, model_client):
# 游标从0开始计算,如果游标>=切割片段数量,证明没有更多数据了
if memory.read_cursor >= len(memory.source_chunks):
print("已经全部翻译完成,没有更多了...")
return "EOF"
chunk = memory.source_chunks[memory.read_cursor]
idx = memory.read_cursor
memory.read_cursor += 1
response = model_client.chat.completions.create(
model=memory.model_name,
messages=[
{"role": "system", "content": "直译Markdown为中文,保留格式。"},
{"role": "user", "content": chunk},
],
temperature=0.1,
)
print(
f"【local】翻译:第{idx+1}/{len(memory.source_chunks)}段,结果为:{response.choices[0].message.content[:100]}..."
)
return response.choices[0].message.content
# 保存chunk到内存
def local_tool_save(content, memory):
memory.output_buffer.append(content)
print(
f"【local】保存chunk到内存,当前内存已有{len(memory.output_buffer)}个chunk"
)
return f"保存chunk到内存,当前内存已有{len(memory.output_buffer)}个chunk"
# 定义符合OpenAI格式的tool的Schema
LOCAL_TOOL_SCHEMA = [
{
"type": "function",
"function": {
"name": "local_tool_split",
"description": "将读取到内存中的长文本,拆分并存入内存队列",
"parameters": {
"type": "object",
"properties": {},
},
},
},
{
"type": "function",
"function": {
"name": "local_tool_get_next_chunk_and_tanslate",
"description": "从内存队列中取出下一个片段进行翻译,如果返回EOF表示取完了",
"parameters": {
"type": "object",
"properties": {},
},
},
},
]
- 第三步:主项目文件
import os
import dotenv
import asyncio
from openai import OpenAI
from typing import List, Dict, Any
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_text_splitters import RecursiveCharacterTextSplitter
from mcp_http_client import MCPHttpClient
from tools import LOCAL_TOOL_SCHEMA
from tools import (
local_tool_split,
local_tool_get_next_chunk_and_tanslate,
local_tool_save,
)
import json
dotenv.load_dotenv()
client = OpenAI(
api_key=os.getenv("ALI_MODEL_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
INPUT_FILE = "input.md"
OUTPUT_FILE = "./data/output_zh.md"
MODEL_NAME = "qwen3.5-35b-a3b"
ALLOWED_PATH = "./data"
# 上下文记忆
class ContextMemory:
def __init__(self, model=client):
# 存储原始文本
self.row_content = ""
# 存储原始文本的chunks
self.source_chunks: List[str] = []
# 当前正在处理的游标
self.read_cursor: int = 0
# 存储翻译后内容的缓冲区
self.output_buffer: List[str] = []
# 存储模型名称
self.model_name = MODEL_NAME
def get_full_output(self) -> str:
return "\n\n".join(self.output_buffer)
memory = ContextMemory()
# =====主逻辑=====
def run_agent():
# 连接MCP服务器
mcp_client = MCPHttpClient("http://127.0.0.1:8000/rpc")
# 获取工具列表
print("正在连接MCP服务...")
try:
mcp_tools = mcp_client.list_tools()
# 将工具列表转换为字典,方便查询tool名字是否在列表中
mcp_tools_map = {tool["name"]: tool for tool in mcp_tools}
print(f"MCP服务工具列表: {mcp_tools},共提供了{len(mcp_tools)}个工具")
except Exception as e:
print(f"Error: {e}")
return
# 将MCP服务提供的工具列表转换为OpenAI格式的tool列表
openai_tools = []
for tool in mcp_tools:
openai_tools.append(
{
"type": "function",
"function": {
"name": tool["name"],
"description": tool["description"],
"parameters": tool["parameters"],
},
}
)
# 合并OpenAI格式的tool列表和本地的tool列表(MCP 工具 + 本地 Python 工具)
all_tools = openai_tools + LOCAL_TOOL_SCHEMA
print(f"所有工具列表: {all_tools},共提供了{len(all_tools)}个工具")
# 为了让模型更容易正确拼参数,这里显式给出文件名(不带路径),与 mcp_server 中的实现保持一致
input_name = os.path.basename(
INPUT_FILE
) # 例如 "./data/input.md" -> "input.md"
output_name = os.path.basename(
OUTPUT_FILE
) # 例如 "./data/output_zh.md" -> "output_zh.md"
messages = [
{
"role": "system",
"content": (
"你是一个严谨的 Markdown 翻译 Agent,负责将英文 Markdown 精确翻译为中文 Markdown,保留原有结构与格式。\n\n"
f"当前允许读写的文件根目录为:{ALLOWED_PATH}(MCP 服务端会固定在该目录下读写文件)。\n\n"
"你可以使用以下工具,请严格按顺序调用,禁止跳步,禁止并发调用工具:\n\n"
"1. MCP 工具 `read_markdown_tool`\n"
f" - 作用:从 `{ALLOWED_PATH}` 目录读取 Markdown 文件内容。\n"
f' - 参数:`{{"filepath": "{os.path.join(ALLOWED_PATH, input_name)}"}}` —— 只传文件名,不带路径。\n'
" - 调用约定:第一步必须先调用一次该工具,拿到真实文件内容后再继续分析。\n\n"
"2. 本地工具 `local_tool_split`\n"
" - 作用:把已经加载到内存中的整篇 Markdown 文本拆分为多个片段,存入内存队列。\n"
" - 参数:固定位`{}`,`memory`,由系统自动注入,你只需传空对象。\n"
" - 调用约定:仅在确认已经完成文件读取之后调用一次。\n\n"
"3. 本地工具 `local_tool_get_next_chunk_and_tanslate`\n"
' - 作用:从内存队列中依次取出片段进行翻译;当工具返回字符串 `"EOF"` 时表示已翻译完所有片段。\n'
" - 参数:固定位`{}`,`memory`,`model_client` 由系统注入,你只需传空对象。\n\n"
"4. MCP 工具 `write_markdown_tool`\n"
f" - 作用:将所有翻译好的中文 Markdown 写入 `{ALLOWED_PATH}` 目录下的目标文件。\n"
f' - 参数:`{{"filename": "{output_name}", "content": "__USE_MEMORY_BUFFER__"}}`。\n'
" 其中 `content` 固定写为 `'__USE_MEMORY_BUFFER__'`,系统会自动将内存中的翻译结果拼接为完整 Markdown 再写入。\n\n"
"重要约束:\n"
" - 在没有真实看到 `read_markdown_tool` 返回内容之前,绝对不要臆造文件内容。\n"
" - 工具调用之间不要做无意义的思维展开,尽量直接根据工具返回结果做下一步决策。\n"
" - 最终回答中不要暴露你的思维链,只保留必要的工具调用和结果说明。\n"
),
},
{
"role": "user",
"content": (
f"请读取 `{input_name}`,将其中的英文 Markdown 翻译为中文,并保存到 `{output_name}`。"
),
},
]
print("Agent开始工作...")
# 是否需要修剪历史消息,如果需要,则修剪历史消息
should_prune_history = False
while True:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
tools=all_tools,
tool_choice="auto",
)
print(f"模型回复: {response.choices[0].message}")
assistant_message = response.choices[0].message
# 将模型回复添加到messages中
messages.append(assistant_message)
# 如果模型回复没有工具调用,则结束
if not assistant_message.tool_calls:
print(f"Agent: {assistant_message,assistant_message.content}")
print("Agent出错,结束工作...")
break
# 强制串行,模型只能先读取后拆分,如果发现想并行强制改为串行
if len(assistant_message.tool_calls) > 1:
print(
f"⚠️ 警告:检测到并发调用 {len(assistant_message.tool_calls)} 个工具,强制截断,只执行第一个。"
)
# 只保留第一个工具调用
assistant_message.tool_calls = [assistant_message.tool_calls[0]]
# 执行MCP工具
for tool_call in assistant_message.tool_calls:
name = tool_call.function.name
raw_args = tool_call.function.arguments
if isinstance(raw_args, str):
try:
args = json.loads(raw_args)
except json.JSONDecodeError:
args = {}
else:
args = raw_args or {}
# tool执行结果
tool_result = ""
print("决策判断")
# MCP TOOLS则需要调用远程的MCP服务
if name in mcp_tools_map:
# 拦截:如果参数用了占位符__USE_MEMORY_BUFFER__,则需要将内存中的翻译结果拼接为完整 Markdown 再写入。
if (
name == "write_markdown_tool"
and args.get("content") == "__USE_MEMORY_BUFFER__"
):
print(
f"拦截写入请求:{name}的参数用了占位符__USE_MEMORY_BUFFER__,需要将内存中的翻译结果拼接为完整 Markdown 再写入。"
)
args["content"] = memory.get_full_output()
# 调用MCP工具
try:
res = mcp_client.call_tool(name, args)
if name == "read_markdown_tool":
args["filename"] = INPUT_FILE
print(f"调用MCP工具: {name}, 参数: {args}")
tool_result = res.get("content")
print(f"MCP工具返回结果: {tool_result}")
if tool_result is not None:
print(
f"读取到文案:{tool_result[:100]}, 文案长度:{len(tool_result)}"
)
# 将读取到的文案存入内存
memory.row_content = tool_result
# 只告诉大模型已经读取到,让大模型继续调用下一步的切割文案的工具,不要把真实结果给大模型,浪费token
tool_result = f"文件读取成功,内容已经存入系统内存,字符长度:{len(tool_result)},请继续调用local_tool_split工具进行文案分割"
else:
print(f"读取文件失败: {tool_result}")
else:
tool_result = "执行成功(MCP TOOL)"
break
except Exception as e:
print(f"MCP工具调用失败: {e}")
tool_result = f"MCP工具调用失败: {e}"
break
# LOCAL TOOL则需要调用本地的Python工具
elif name == "local_tool_split":
tool_result = local_tool_split(memory)
# 这个api执行完就完成了文本切割,你只需要告诉大模型这个结果,让他继续往下做,不要给数据没意义且耗费token的文本
tool_result = "[已省略大文本]"
# 标记需要修剪历史消息
should_prune_history = True
# 做一个简报防止模型失忆
status_summmary = (
f"文本已经拆分为{len(memory.source_chunks)}段\n"
f"请开始循环:调用`local_tool_get_next_chunk_and_tanslate`获取第{memory.read_cursor}段,并翻译为中文,直到返回`EOF`表示全部翻译完成\n"
)
break
elif name == "local_tool_get_next_chunk_and_tanslate":
print(f"调用本地工具: {name}, 参数: {args}")
tool_result = local_tool_get_next_chunk_and_tanslate(
memory, client
)
# 如果返回EOF,则表示全部翻译完成
if tool_result != "EOF":
tool_result = local_tool_save(tool_result, memory)
# 清理垃圾消息
should_prune_history = True
# 做一个简报防止模型胡来
current = memory.read_cursor
total = len(memory.source_chunks)
# 做简报,防止模型失忆
status_summmary = (
f"第{current}段翻译完成,进度{current}/{total}\n"
"历史上下文已经释放内存。\n"
f"请立即调用`local_tool_get_next_chunk_and_tanslate`继续下一段"
)
else:
tool_result = f"工具{name}调用失败: {e}"
# 反馈结果给模型,让模型知道工具调用结果
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(tool_result),
}
)
if should_prune_history:
# 保留system消息,修剪其他消息
system_message = messages[0]
first_user_message = messages[1]
# 告诉大模型当前的节点,让模型知道下一步该干啥呢
new_user_message = {
"role": "user",
"content": f"系统通知:{status_summmary}",
}
# 更新messages,这样让模型记住调用节点,而且发给LLM的只有2条消息,不会浪费token
messages = [
system_message,
first_user_message,
new_user_message,
]
# 标记不需要修剪历史消息
#
should_prune_history = False
run_agent()
- 源码
https://github.com/sunhailiang-tourist/agent-and-mcp

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)