LangChain实战:新手手撸RAG全记录(六)
核心文件main.py实现了从文档检索到答案生成的完整流程,系统集成了向量数据库、大语言模型和实用工具,能够基于私有知识库提供精准的问答服务,本文将深入剖析这个核心文件的代码架构、设计思路以及开发过程中积累的实战经验。
核心文件main.py实现了从文档检索到答案生成的完整流程,系统集成了向量数据库、大语言模型和实用工具,能够基于私有知识库提供精准的问答服务,本文将深入剖析这个核心文件的代码架构、设计思路以及开发过程中积累的实战经验
6.1 整体架构分层
main.py采用了清晰的分层架构设计,主要包含模型层负责语言模型初始化、数据层负责向量数据库管理、逻辑层负责执行链构建、工具层负责实用工具加载以及状态层维护对话历史记录。这种分层设计的核心优势在于关注点分离让每一层只专注于单一职责,模型层只管模型调用、数据层只负责向量检索、逻辑层仅处理业务编排,清晰的边界划分降低了代码的认知负荷
class RAGApplication:
def __init__(self, config: Optional[RAGConfig] = None):
self._init_llm() # 模型层:语言模型初始化
self._init_vector_store() # 数据层:向量数据库初始化
self._init_chains() # 逻辑层:执行链构建
self._init_tools() # 工具层:实用工具加载
self.conversation_history = [] # 状态层:对话历史记录6.2 配置管理类
class RAGConfig:
def __init__(self):
self.project_path = Path("C:/Users/Administrator/Desktop/llm_app/rag")
self.data_dir = self.project_path / "data"
self.chroma_dir = self.data_dir / "chroma"
self.top_k = 5
self.temperature = 0.7
self.max_tokens = 4096配置管理类将所有可配置参数集中管理,通过RAGConfig统一维护项目路径、数据目录、向量库位置以及检索参数和模型参数,彻底避免了硬编码带来的维护噩梦,这种设计思路的好处在于修改参数只需改动一处即可全局生效,便于在不同环境间迁移部署
6.3 向量检索层实现
def _init_vector_store(self):
embeddings = get_embeddings()
self.vector_store = Chroma(
persist_directory=str(self.config.chroma_dir),
embedding_function=embeddings,
collection_name=self.config.collection_name
)
self.retriever = self.vector_store.as_retriever(
search_kwargs={"k": self.config.top_k}
)向量检索层的实现采用了Chroma向量数据库,通过embedding模型将文档转换为向量并持久化存储,利用as_retriever方法封装统一的检索接口,并配置Top-K参数返回最相似的K个文档片段,在相关性和多样性之间取得平衡
关键技术点包括持久化存储确保向量库自动保存到磁盘避免每次启动重复计算,检索器封装屏蔽了底层向量库的复杂性提供统一接口,Top-K检索让开发者可以根据场景灵活调整返回结果的数量,平衡检索精度和响应速度
6.4 LCEL链式执行
self.lcel_chain = (
RunnableParallel({
"context": self.retriever | self._format_docs_for_chain,
"question": RunnablePassthrough()
})
| self.prompt
| self.llm
| StrOutputParser()
)LCEL链式执行采用了LangChain Expression Language的声明式编程范式,通过管道符清晰地表达数据流向:首先通过RunnableParallel并行执行文档检索和问题传递,检索结果经过格式化后与原始问题共同填充提示模板,最后调用大语言模型生成答案并解析输出
这种设计亮点在于声明式编程让整个处理流程一目了然,并行执行提高了检索和传递的效率,每个组件都是独立的Runnable为后续流式输出打下基础
6.5 工具集成设计
def _init_tools(self):
self.tools = {
"calculator": self._calculator,
"datetime": self._get_datetime,
"extract_numbers": self._extract_numbers,
"count_words": self._count_words
}
def call_tool(self, tool_name: str, *args, **kwargs) -> str:
if tool_name not in self.tools:
return f"错误: 未知工具 '{tool_name}'"
try:
return self.tools[tool_name](*args, **kwargs)
except Exception as e:
return f"工具调用失败: {e}"工具集成采用了策略模式配合统一调用接口的设计,所有工具以键值对形式注册在字典中,通过统一的call_tool入口处理参数传递和异常捕获,每个工具独立实现自己的业务逻辑互不干扰
6.6 智能工具调用
def answer_with_tools(self, question: str) -> str:
if "计算" in question and any(op in question for op in ["+", "-", "*", "/"]):
numbers = re.findall(r'[\d+\-*/().]+', question)
if numbers:
return self.call_tool("calculator", numbers[0])
elif "时间" in question or "日期" in question:
return self.call_tool("datetime")
elif "提取数字" in question:
return self.call_tool("extract_numbers", question)
elif "词数" in question or "单词数" in question:
return self.call_tool("count_words", question)
return self.answer_with_lcel(question) # 默认使用RAG智能工具调用基于规则优先的简单策略,通过关键词匹配识别用户意图:包含计算和运算符时调用计算器工具,提到时间或日期时调用时间查询工具,需要提取数字时调用数字提取工具,询问词数时调用词数统计工具,如果都不匹配则默认直接使用RAG问答
6.7 带性能监控的问答
def answer_with_details(self, question: str) -> Dict[str, Any]:
start_time = time.time()
# 处理问题
processed_q = process_question(question)
# 检索文档
docs = retrieve_documents(processed_q, self.vector_store, top_k=self.config.top_k)
# 记录检索时间
retrieval_time = time.time()
result["retrieval_time"] = retrieval_time - start_time
# 生成答案
context = format_context_with_sources(docs)
prompt = ChatPromptTemplate.from_template(DETAILED_TEMPLATE)
formatted_prompt = prompt.format(context=context, question=question)
response = self.llm.invoke(formatted_prompt)
answer = response.content if hasattr(response, 'content') else str(response)
# 记录生成时间
result["generation_time"] = time.time() - retrieval_time
result["total_time"] = time.time() - start_time带性能监控的问答流程在开始记录起始时间,检索文档后记录检索耗时,生成答案后记录生成耗时,最终返回包含答案、信息来源、文档数量和各阶段耗时的详细信息
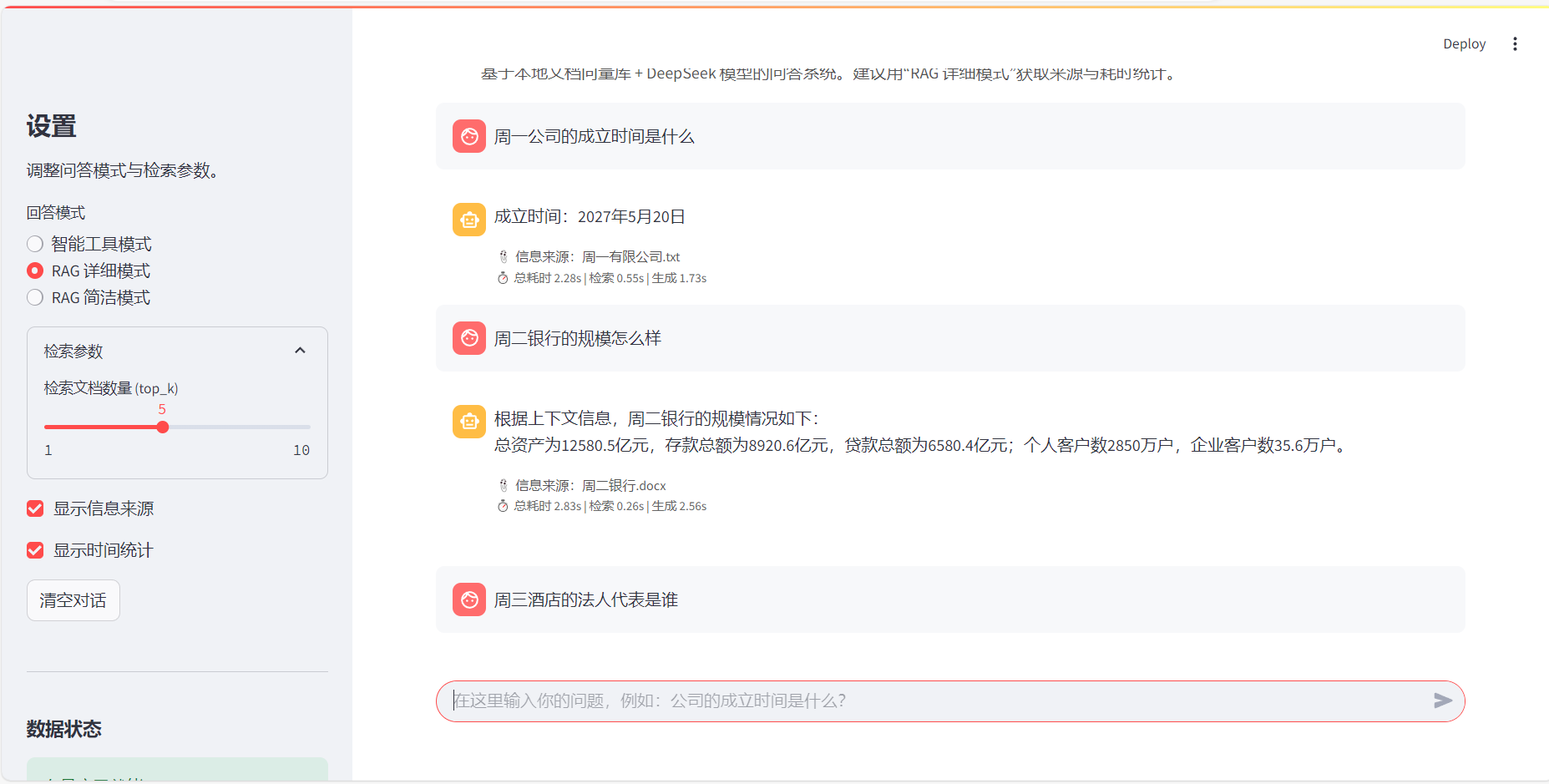
值得一提的是我自创的的文件都包含成立时间这类字段,所以当我问其中一个公司的成立时间时,向量检索很容易把另外两个文件里成立时间的段落也召回,于是来源列表就变成多个文件。我在main.py的RAGApplication.answer_with_details()里加了一个自动限定来源的机制:先根据问题推断最可能的文件来源,优先用 Chroma 的 metadata filter 检索:只在该文件内检索 top_k,如果限定后没检索到内容,再自动回退到全库检索
6.8 交互界面设计
def run_cli(self):
self.print_welcome()
while True:
user_input = input("\n📝 请输入问题: ").strip()
if user_input.lower() == '/exit':
print("👋 感谢使用,再见!")
break
elif user_input.lower() == '/help':
self.print_help()
elif user_input.lower() == '/tools':
self.print_tools()
elif user_input.lower() == '/history':
self.print_history()
elif user_input.lower() == '/stats':
self.print_stats()
elif user_input.lower() == '/clear':
self.clear_screen()
elif not user_input:
continue
命令行交互采用类似终端的命令系统,用户可以直接输入问题获得答案,也可以通过 /help、/tools、/history、/stats、/clear、/exit 等命令管理系统
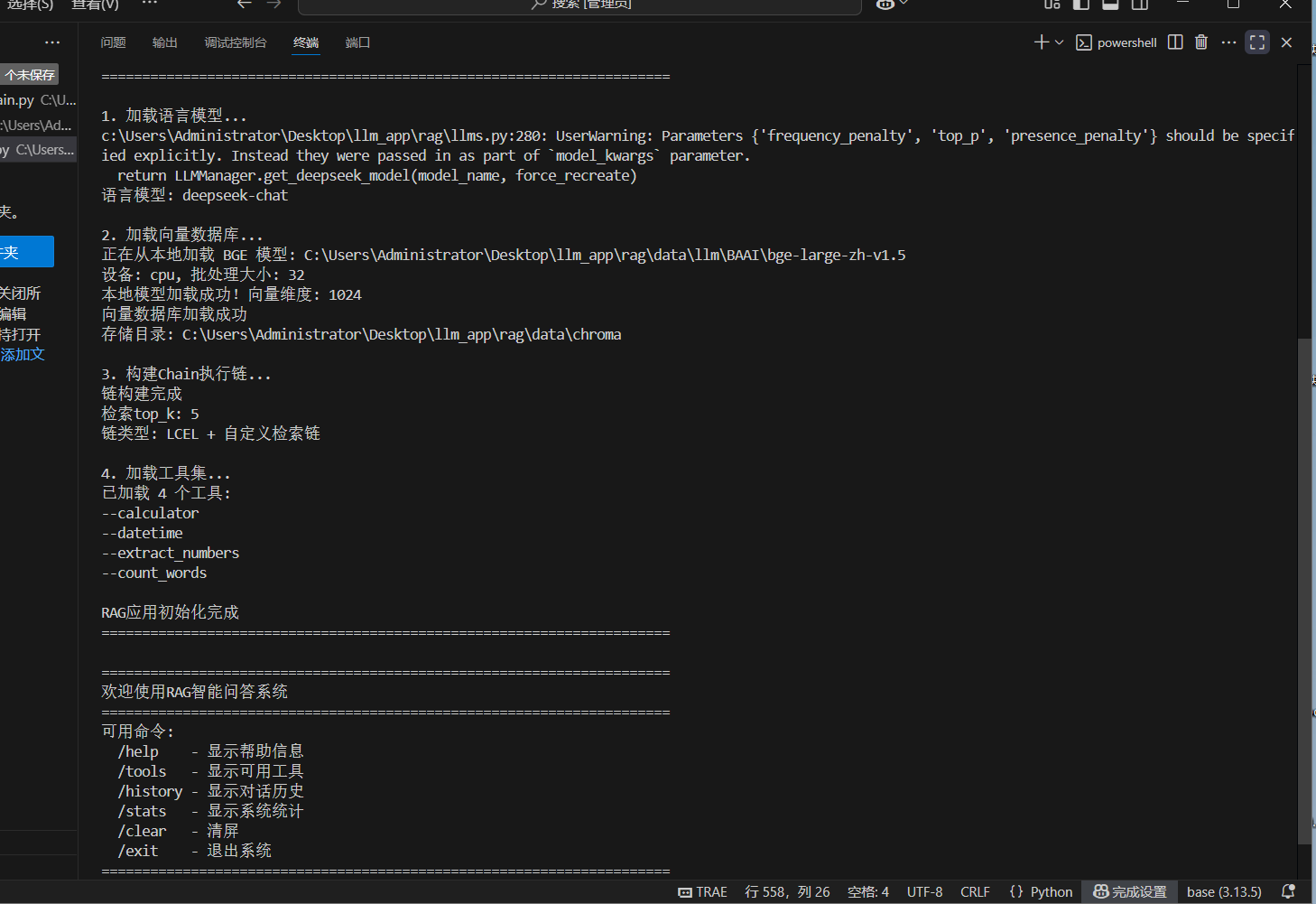
运行结果:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)