打破 Agent 推理“存储墙”:清北与DeepSeek 联手发布大模型新推理架构
这篇由清华大学、北京大学与 DeepSeek(深度求索)联合发表的论文,并没有直接谈模型参数,而是切中了当前大模型落地的“七寸”:智能体(Agent)推理的存储带宽瓶颈。简单来说,当 LLM 变成 Agent,推理的逻辑变了,硬件的压力点也变了,这就需要有新的推理架构来应对新的挑战。DualPath 就是为了解决这些挑战而生的。


打破 Agent 推理“存储墙”:清北与DeepSeek 联手发布大模型新推理架构
论文:DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference
在二月份,DeepSeek又偷偷在arxiv上投放了一篇硬核论文,引起了大家对DeepSeek-V4的猜测与讨论。
这篇由清华大学、北京大学与 DeepSeek(深度求索)联合发表的论文,并没有直接谈模型参数,而是切中了当前大模型落地的“七寸”:智能体(Agent)推理的存储带宽瓶颈。简单来说,当 LLM 变成 Agent,推理的逻辑变了,硬件的压力点也变了,这就需要有新的推理架构来应对新的挑战。DualPath 就是为了解决这些挑战而生的。
![]()
一、问题背景:Agent 带来的“存储墙”
在传统的聊天机器人场景中,你问一句,它答一句,上下文相对固定。但在智能体(Agentic)范式下,LLM 需要频繁地与环境交互(比如查浏览器、运行 Python 代码),一干就是几十甚至上百轮 。
这种模式带来了两个显著变化:
-
极高的 KV-Cache 命中率:因为每一轮只增加一点点新指令,95% 以上的上下文都是重复的。
-
I/O 变重,计算变轻:GPU 不再忙着算数,而是在忙着从硬盘里“捞”之前存好的 KV-Cache。
而这也揭露出现在推理系统的痛点:在现在的架构里,预填充引擎(PE)忙着从硬盘搬数据,存储网卡累到冒烟;而解码引擎(DE)的网卡却在旁边闲着,形成了巨大的资源浪费 。
GPU 算力增长极快,但网络和显存带宽的增长却像蜗牛爬,这种“剪刀差”让 Agent 推理越来越卡 。这种负载不平衡严重限制了整个系统的吞吐量 。
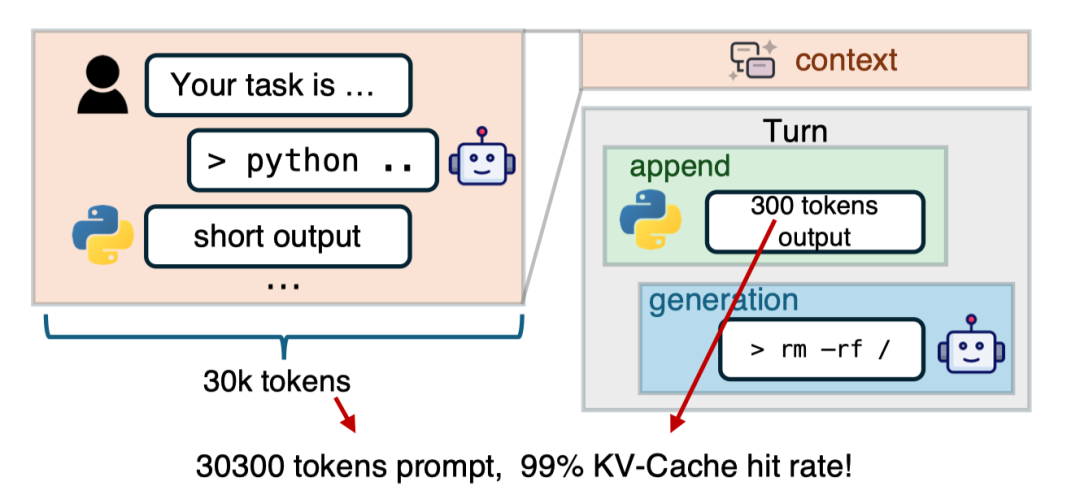
![]()
二、架构创新:双路径加载与带宽池化
既然 PE 搬不动了,DE 又没活干,DualPath 的思路就是:让 DE 帮着 PE 一起搬数据。
DualPath 的核心创新在于打破了“存储 → PE”的单一数据路径,引入了“存储到解码(Storage-to-Decode)”的新路径。并且在工程上将整个集群中原本被“孤立”在各节点的存储网卡整合进了一个全局虚拟资源池 。通过动态分配负载,系统可以同时动用 PE 和 DE 的带宽来加载同一个请求的记忆,彻底打破了单节点 I/O 的上限 。
数据流深度解析
-
PE 读取路径:KV-Cache 从存储读入 PE 缓冲区,用于处理当前 layer 的 cache-miss 部分,随后将该层完整的 KV-Cache 传给 DE 进行持久化或后续使用 。
-
DE 读取路径:KV-Cache 先被加载到 DE 缓冲区,再通过计算网络(RDMA)在 prefill 期间按需传回 PE,实现数据与计算的重叠 。
-
按层流式处理:为了应对 HBM 容量限制,DualPath 采用层级(Layerwise)加载范式,GPU 仅需持有单层 KV-Cache 即可开始计算,极大地提升了显存利用率和 batch size 。
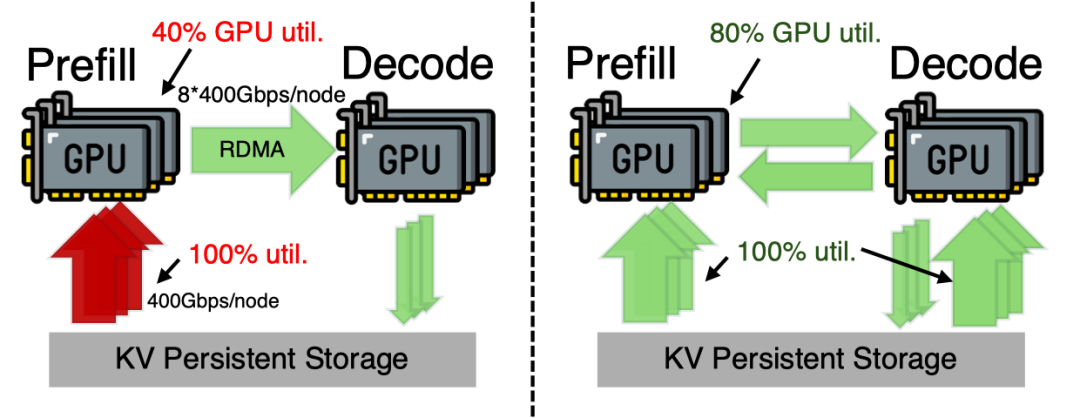
对比左侧(传统单路径,PE 红灯满载)和右侧(DualPath,双路绿灯并进,利用率翻倍)。
![]()
三、工程落地:以 CNIC 为中心的流量管理
这是全篇最具“深度”的工程细节。直接在节点间搬运海量 KV-Cache 极易干扰模型推理的集体通信(Collective Primitives),如专家并行中的 AllToAll 。
1. 流量隔离与 QoS 策略
DualPath 放弃了无法控制服务质量(QoS)的 GPUDirect Storage 方案,转而采用以计算网卡(CNIC)为中心的数据搬运方式 :
-
虚拟车道(Virtual Lanes, VL):在 InfiniBand 或 ROCe 网络中,将推理通信分配至高优先级VL,并将KV-Cache传输分配至低优先级VL。
-
带宽配额:通过 VL 仲裁器为高优先级流量预留 99% 的带宽,确保KV-Cache传输仅能利用“间隙”流量,从而实现对首字延迟(TTFT)的零干扰。
2. 避免 PCIe 竞争
现有的 GPU 缺乏 PCIe 级别的 QoS 控制 。DualPath 通过 RDMA Write 直接操作 GPU 显存,建立了一个受控的本地主机到设备(H2D)数据通道,解决了搬运数据与模型执行之间的 PCIe 争抢问题 。
3. 双层调度算法
为了防止在“借路”过程中重新产生新的瓶颈,DualPath 实现了一个双层调度器 :
-
层间调度(Inter-Engine):利用Token 计数作为 GPU、磁盘和网络压力的联合代理指标(Proxy)。调度器会实时监控各引擎的磁盘读取队列长度(read_qn),优先将请求分配给读取压力小的路径 。
-
层内调度(Intra-Engine):引入计算配额(Compute Quota)机制,基于 Attention 层的执行时间预测进行批处理选择,最大程度减少 GPU 步调不一致产生的气泡 。
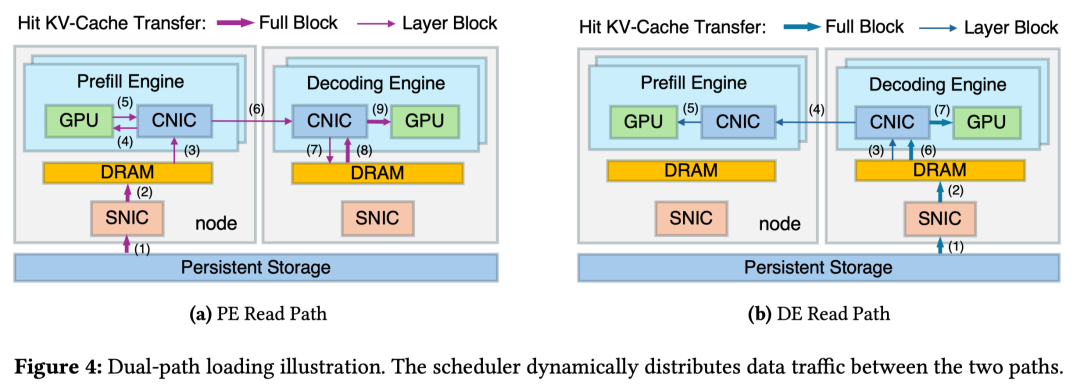
图4展示了数据是如何在 DRAM、CNIC 和 HBM 之间流动的
![]()
四、性能评价:线性扩展与效率翻倍
DeepSeek 的测试一向追求极致规模,这次直接拉出了 1,152 块 Hopper GPU 组成的大规模集群。
1. 离线批处理:打破 I/O 限制,逼近性能上限
在模拟强化学习训练中 Rollout 阶段的离线场景下,DualPath 展现了极强的吞吐提升能力。
-
加速比表现:在 DeepSeek-V3.2 660B 模型上,DualPath 相比基础架构(Basic)实现了最高 1.87 倍 的吞吐量提升 。在较小规模的 DS 27B 和 Qwen 32B 模型上,提升也分别达到了 1.78 倍 和类似的趋势 。
-
逼近理论极限:从图 7 可以看到,代表 DualPath 的橙色柱状图(Ours)在各种 Batch Size 和最大上下文长度(MAL)配置下,都无限接近于代表零 I/O 开销的灰色柱状图(Oracle) 。这说明 DualPath 通过双路径加载,几乎完全消除了 KV-Cache 读取带来的性能损耗 。
-
负载敏感度:DualPath 在“长上下文、短追加”的典型 Agent 负载下优势最明显 。随着追加生成的 Token 长度增加(计算压力增大),基础架构的性能会逐渐接近 DualPath,这验证了 DualPath 核心解决的是 I/O 密集型瓶颈 。
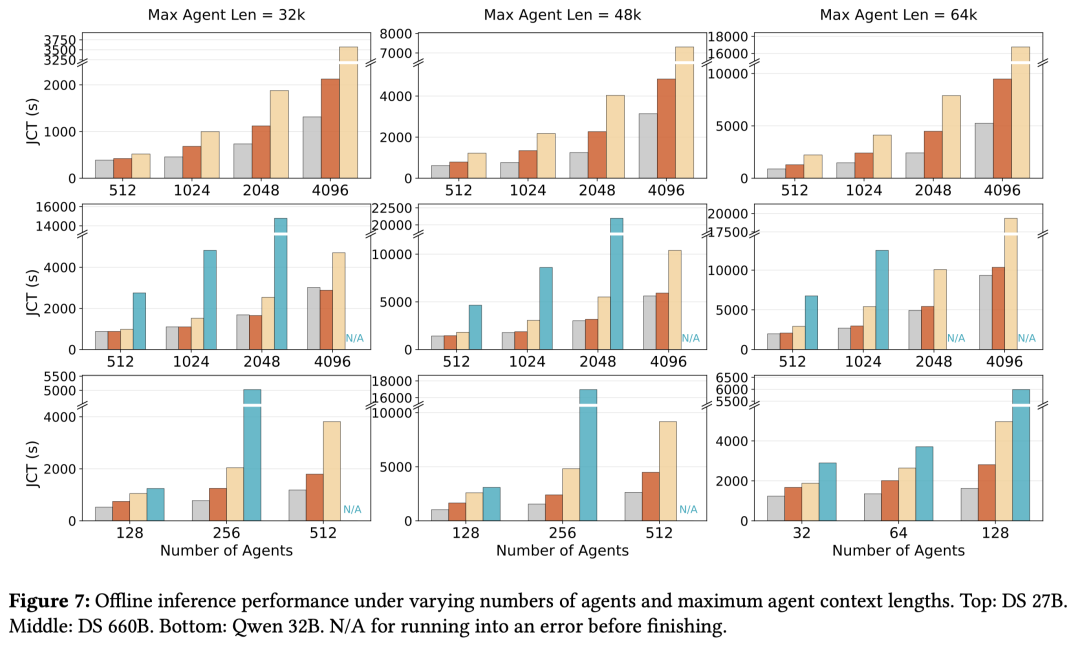
观察该图可以发现,随着 Agent 数量(Batch Size)从 512 增加到 4096,Basic 架构的 JCT 呈指数级跳升,而 Ours 保持了极佳的线性增长趋势,证明了其在大规模并发下的 I/O 韧性 。
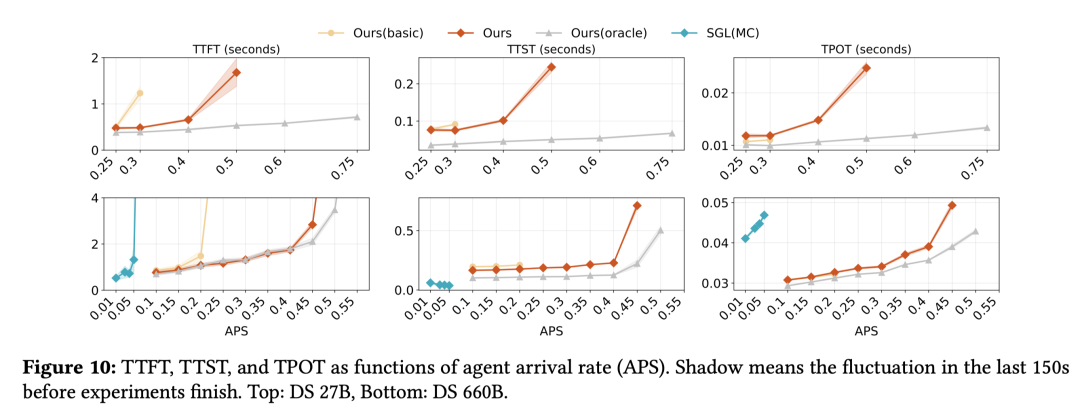
2. 在线服务:高负载下的 TTFT 稳定性
在线服务评价的核心在于:在满足 SLO(服务等级目标)的前提下,系统能承载多大的并发请求频率(APS)。
-
承载能力翻倍:在满足 TTFT ≤ 4s 的前提下,DualPath 在 DS 660B 模型上实现了 2.25 倍 的 APS 提升(从 0.2 提升至 0.45+)。
-
TTFT 更加稳定:图 12(左)揭示了延迟优化的本质。在 Basic 架构中,随着 APS 增加,排队时间(Queuing Time)由于存储网卡带宽不足而呈爆炸式增长 。而 DualPath 通过聚合解码引擎的带宽,使得读取 KV-Cache 的时间(Reading)和排队时间保持在极低且稳定的水平。
-
对解码无干扰:图 10 显示,DualPath 的逐 Token 生成延迟(TPOT)与 Basic 几乎一致 。这证明了其基于 CNIC 和 QoS 的流量隔离机制非常成功,在搬运海量 KV-Cache 的同时,完全没有干扰到延迟敏感的 Decoding 过程。
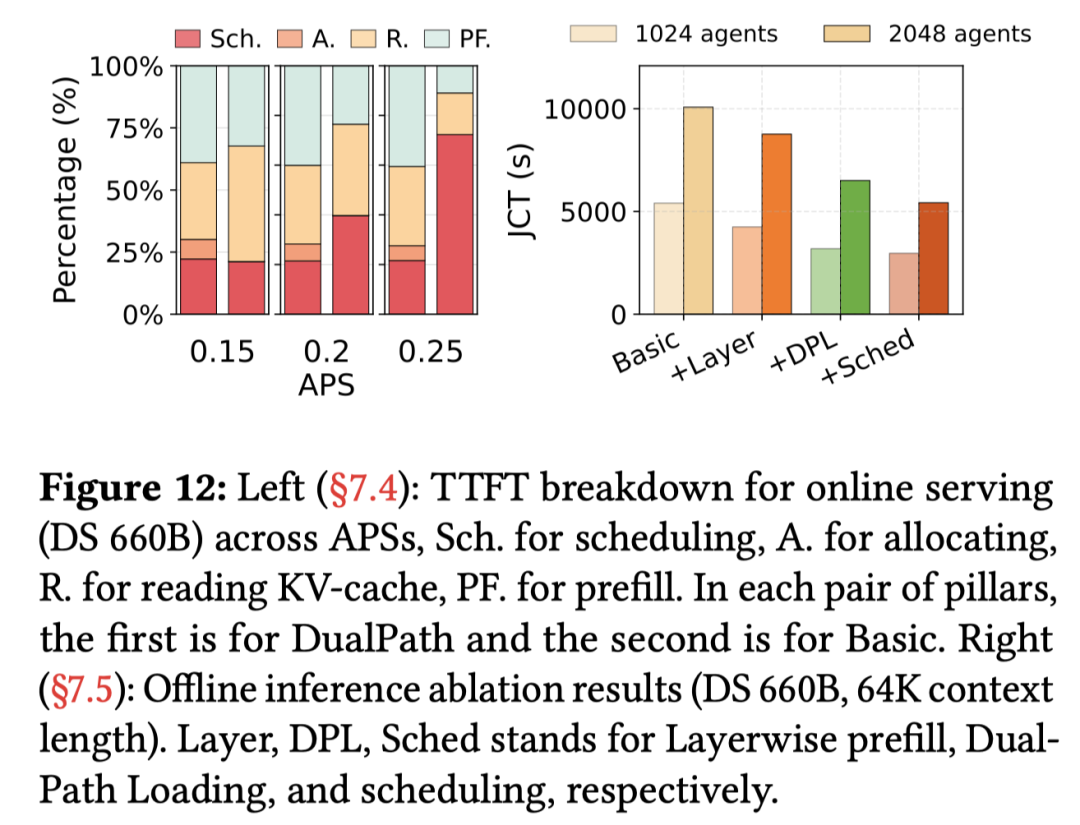
总结来说,在这 1152 块 Hopper GPU 的测试中,DualPath 展现了卓越的性能。
-
吞吐量:在智能体 RL 训练的 rollout 阶段(离线场景),吞吐量提升达 1.87 倍 。
-
可扩展性:从 6 节点(2P4D)线性扩展至 144 节点(48P96D),任务完成时间(JCT)保持稳定,证明了调度器不存在单点瓶颈 。
-
线上服务:在满足 SLO(如 TTFT < 4s)的前提下,平均服务能力提升了 1.96 倍 。
![]()
五、总结
从性能数据来看,DualPath 不仅仅是一个“加速插件”,它实际上重新定义了 PD 分离架构下的数据边界。通过将存储、计算、网络三者进行深度的空间和时间重叠(Overlap),它成功将 Agent 推理从 I/O 泥潭中拉了出来,为百万级长上下文 Agent 的大规模商业化落地清除了最后的障碍。
Future 加入我们的学术社区

点亮创新之光 照亮科研梦想
如果您希望持续获取最新的期刊动态、会议信息、论文写作与投稿技巧,我们诚挚邀请您加入烁智研学社区。

关注“烁智研学”公众号回复“CCF期刊微信群”

扫左侧二维码码加入“CCF期刊QQ交流群”
这是一个致力于共同成长、资源共享的科研平台。我们期待您的到来,一起在科研道路上走得更远、更稳!^o^y

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)