CVPR 2026 | Less is More!CLIP模型的短板被补齐了?从“看颜色”到“懂结构”的降维打击
少即是多(Less is More)。剔除了颜色和材质的干扰,AI 终于看清了世界的真实模样。最重要的是,这种微调方法推理时完全不增加计算量,堪称视觉语言模型领域的“降维打击”!论文标题:StructXLIP: Enhancing Vision-language Models with Multimodal Structural Cues论文链接:https://arxiv.org/abs/260
你是否遇到过这种情况:给 AI 一段很长很细的描述,比如“一个穿着带有复杂褶皱、修身剪裁、有着对称设计的蓝色真丝连衣裙”,结果 AI 给你找来一张只要是蓝色的裙子就敷衍了事?
这是因为现有的 CLIP 类模型太看重“颜值”(颜色、材质)而忽视了“骨架”(几何结构)。今天介绍的 StructXLIP 就要给 AI 补上这一课:看画先看骨,结构定乾坤!
一、 核心科技:结构化“手术刀”
StructXLIP 的核心思想非常直观:在微调模型时,给它增加两个“马甲”视角。
- 视觉侧——边缘图提取:利用 Canny 算子(图 2 左)把色彩斑斓的图变成黑白分明的边缘图。就像给图片照了 X 光,只看物体的轮廓和空间布局。
- 文本侧——词库过滤:利用 LLM 把描述里的颜色(红色、蓝色)、材质(真丝、木制)统统删掉(图 2 右)。
这样,模型就被迫在“简笔画”和“纯形感文字”之间找对应关系。
公式 1:标准的 InfoNCE 损失(基础对齐)
LI,T=−logexp(i⋅t/τ)∑exp(i⋅t/τ)L_{I,T} = -\log \frac{\exp(i \cdot t / \tau)}{\sum \exp(i \cdot t / \tau)}LI,T=−log∑exp(i⋅t/τ)exp(i⋅t/τ)
通俗点说:让正确的图文对靠得近,错误的离得远。
二、 三大绝招:如何练就“火眼金睛”?
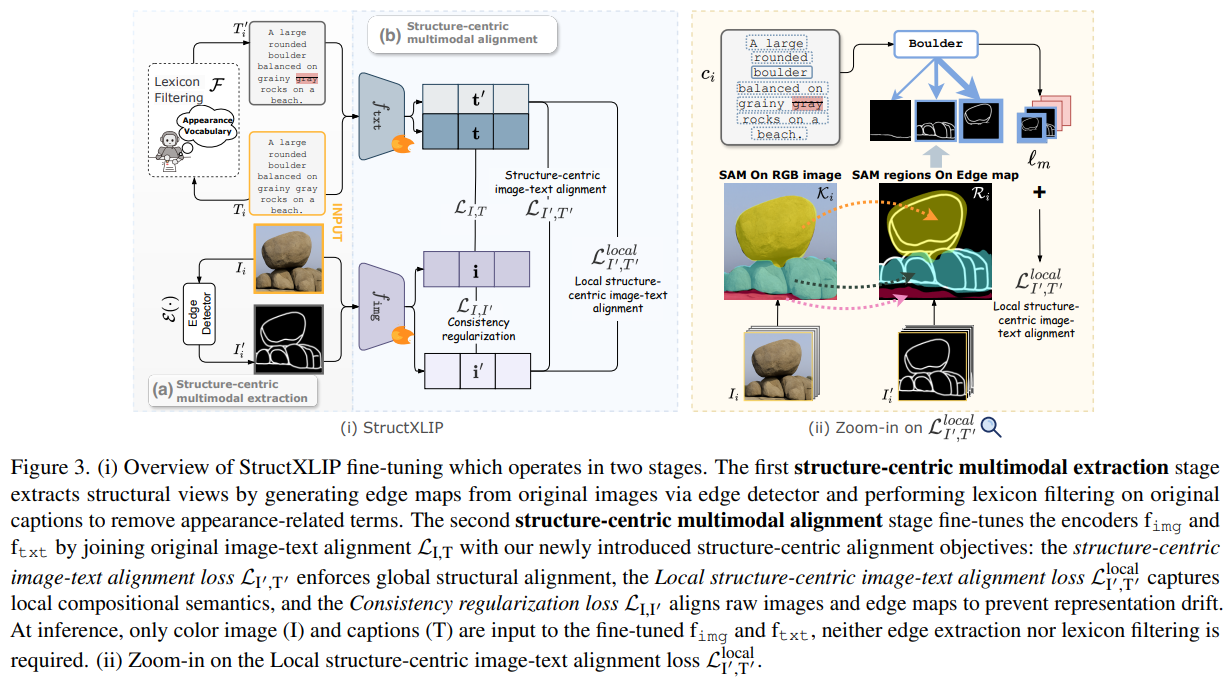
为了让模型学透结构,StructXLIP 祭出了三项训练损失(见论文 图 3):
- 全局结构对齐 (LI′,T′L_{I',T'}LI′,T′):让整张边缘图和过滤后的文本对齐。
- 局部结构对齐 (LlocalL_{local}Llocal)(图 3-ii):最硬核的一招!利用 SAM(分割一切模型)把边缘图切成小块,让文本里的每一个短句去匹配对应的局部边缘。
- 一致性正则 (LI,I′L_{I,I'}LI,I′):防止模型学了结构忘了颜色,通过这个损失让原始图和边缘图的特征保持在一个“频道”上。
论文公式:总损失函数
Ltotal=LI,T+λ1LI′,T′+λ2LI,I′+λ3LlocalL_{total} = L_{I,T} + \lambda_1 L_{I',T'} + \lambda_2 L_{I,I'} + \lambda_3 L_{local}Ltotal=LI,T+λ1LI′,T′+λ2LI,I′+λ3Llocal
这套“组合拳”保证了模型既懂细节又不跑偏。
三、 为什么这招管用?(信息论视角)
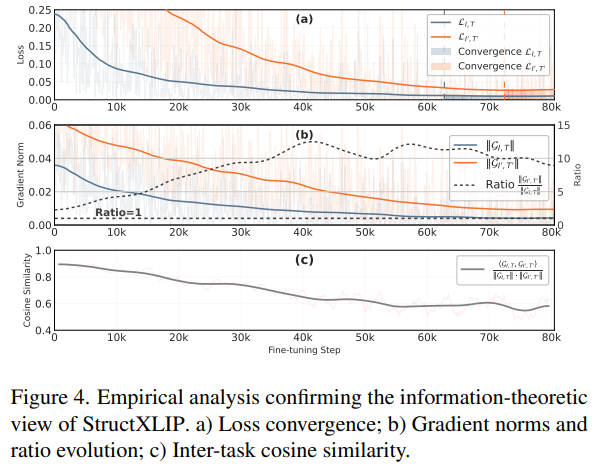
论文给出了一个有趣的解释(见论文 图 4):
原始图文包含的信息太多,模型容易偷懒(只看颜色就对上了)。而边缘图和结构文本的“互信息”极低,就像是一道超难的附加题。当模型努力攻克这道附加题时,它对基础题的理解也会变得极其深刻且稳健。
四、 战力惊人:横扫各大赛道
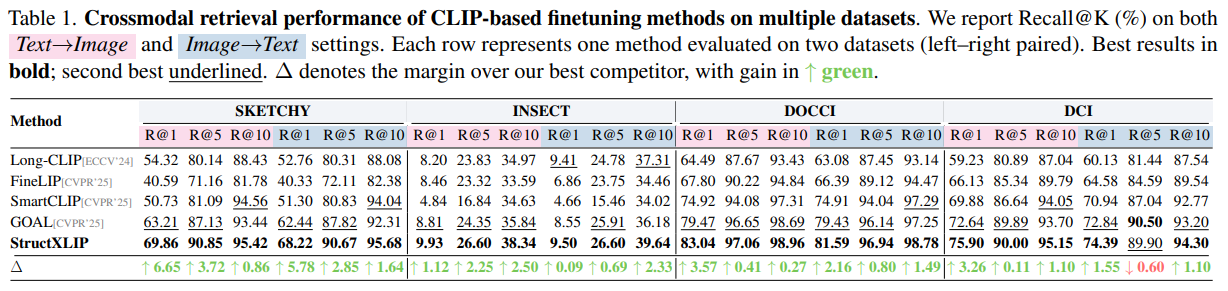
实验结果(见论文 Table 1)显示:
- 在时尚领域(SKETCHY):检索精度 R@1 提升了 +6.65%。对于衣服的剪裁、版型这些细节,StructXLIP 简直是专家。
- 在通用长文本(DOCCI):即便面对几百字的复杂描述,它也能精准命中。
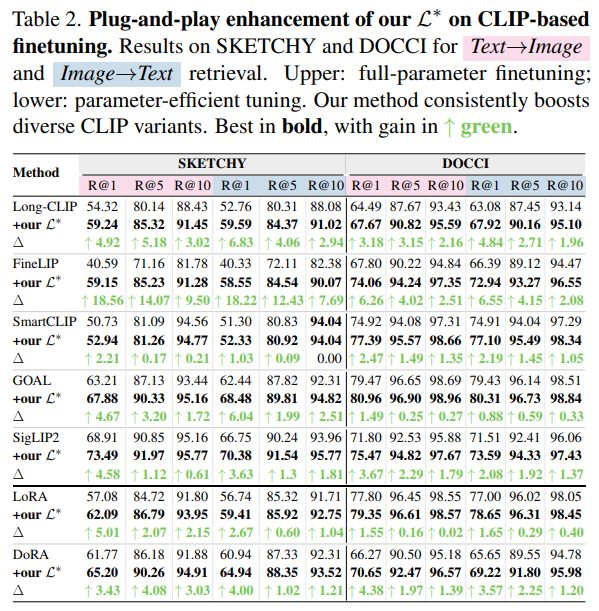
更厉害的是,StructXLIP 是个万能插件(见论文 Table 2)。无论你用的是 LoRA、DoRA 还是 Long-CLIP,只要加上这套结构损失,性能都能“原地起飞”。
五、 效果对比:AI 终于看懂了细节

看论文的 图 6:
- 左侧对比:传统模型(GOAL)找回的图虽然颜色对,但结构乱七八糟;StructXLIP 找回的图,连走廊上的灯柱数量和人的布局都更贴合。
- 右侧热力图:StructXLIP 的注意力(Grad-CAM)精准地聚焦在连衣裙的轮廓和树枝的走向词,而不是模糊的一片。
结语
StructXLIP 告诉我们:少即是多(Less is More)。剔除了颜色和材质的干扰,AI 终于看清了世界的真实模样。最重要的是,这种微调方法推理时完全不增加计算量,堪称视觉语言模型领域的“降维打击”!
- 论文标题:StructXLIP: Enhancing Vision-language Models with Multimodal Structural Cues
- 论文链接:https://arxiv.org/abs/2602.20089v1
- 代码链接:https://github.com/intelligolabs/StructXLIP

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)