Apple 的 ANE 被逆向,AI 硬件被公开,宣传的 38 TOPS 居然是数字游戏?
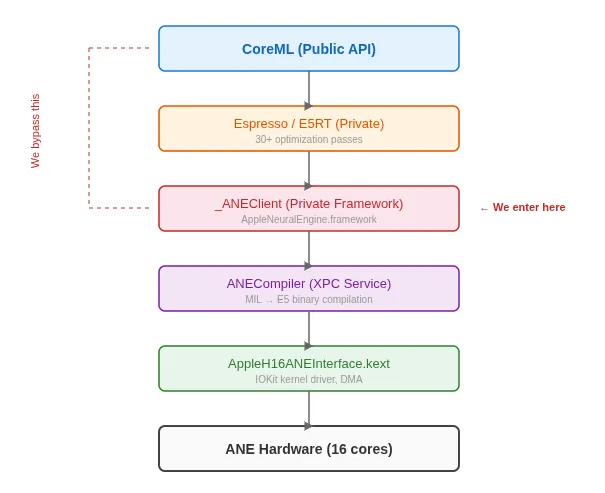
dyld_info,通过逆向,可以让开发者绕过苹果的官方限制,直接在 ANE 上进行神经网络的训练和推理调用。这里的意义,我理解是在于不需要官方 CoreML,可以自己构造计算图和直接驱动 ANE。而在逆向并直接测试硬件底层的过程中,maderix发现了几个关于 ANE 的结论:算力 “38 TOPS” 是数字游戏官方宣传 M4 ANE 算力为实测数使用 FP16 和 INT8 运行完全相同的操作
近日,有个大佬逆向 Apple Neural Engine (ANE) ,针对苹果芯片底层 AI 逻辑做了一次细节公开,因为苹果 ANE(M4 芯片上为 16 核运算单元)长期以来是一个纯粹的“黑盒”,对大家来说缺少公开接口、文档和指令集架构 (ISA),开发者只能通过 CoreML 框架间接调用,而作者 maderix 通过逆向把 CoreML 给脱了个干干净净:
- 利用
dyld_info扫描私有 framework,通过 Method Swizzling hook CoreML (MIL) - 成功逆向出完整的编译运行流程,实现了在内存中直接将 MIL(模型中间语言,类似于 NVIDIA 的 PTX)编译为 ANE 原生二进制文件
也就是实现了内存中将 MIL 直接编译为 ANE binary ,通过逆向,可以让开发者绕过苹果的官方限制,直接在 ANE 上进行神经网络的训练和推理调用。
这里的意义,我理解是在于不需要官方 CoreML,可以自己构造计算图和直接驱动 ANE。
而在逆向并直接测试硬件底层的过程中,maderix 发现了几个关于 ANE 的结论:
-
算力 “38 TOPS” 是数字游戏
-
官方宣传 M4 ANE 算力为 38 TOPS
-
实测数使用 FP16 和 INT8 运行完全相同的操作,吞吐量没有任何变化
-
而 ANE 在执行 INT8 运算时,实际上会先将其反量化(Dequantize)为 FP16,然后再进行计算
-
所以苹果宣传的 “38 TOPS INT8” 是基于真实 FP16 峰值算力乘以 2 包装出来的数字,M4 ANE 的真实物理硬件峰值算力实际上是 19 TFLOPS (FP16),不是 38 TOPS 真 INT8
当然,这里是通过实测显示 INT8 未带来 2× 吞吐提升从而推断出来,不是硬件 RTL 级证明。
-
-
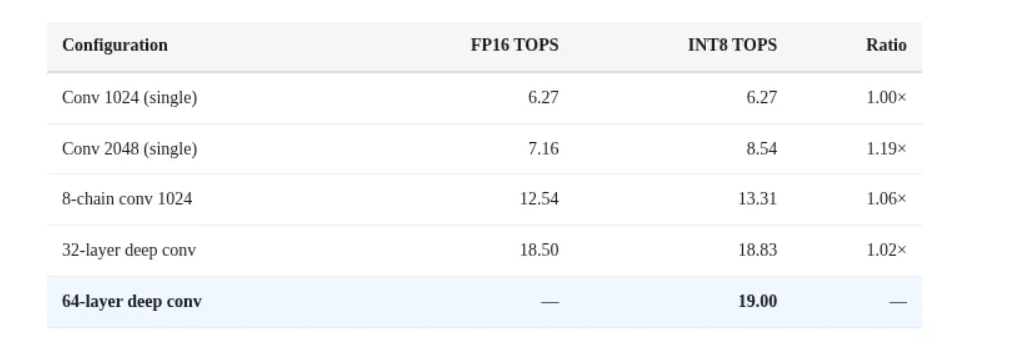
本质它是卷积引擎,而非矩阵乘法引擎
-
ANE 的底层硬件设计更倾向于处理卷积(Convolution)而非标准的矩阵乘法(Matrix Multiplication)
-
如果将相同的计算逻辑重写为卷积运算,吞吐量可以直接飙升 3 倍(这一点在苹果开源的
ml-ane-transformers参考代码中曾有隐晦的暗示,里面大量用卷积模拟 Transformer 结构)
1x1 Conv 走卷积 datapath,MatMul 走 fallback 路径,所以并非数学不同,而是硬件执行路径不同,性能差异来自底层 datapath 优化,而非 FLOPs 差异。
-
-
硬件缓存 约 32MB 的内部 SRAM
- maderix 通过不断扩展矩阵乘法的规模(Scaling Test),观察性能出现急剧下降的“断崖点”,由此反向推测出 ANE 内部拥有大约 32MB 的高速 SRAM 缓存,超过这个容量限制就会导致性能暴跌
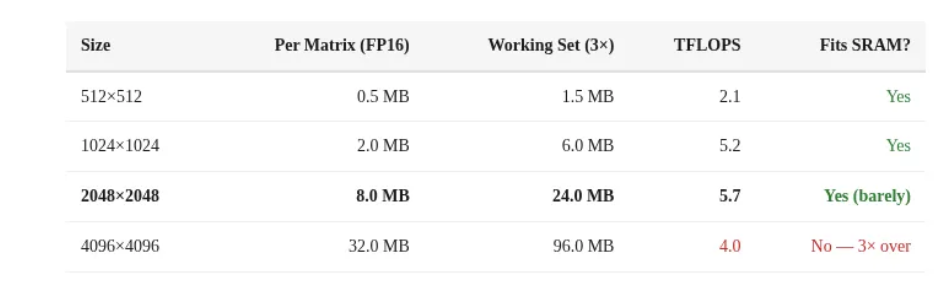

- 所以 ANE 是典型的 dataflow + on-chip memory 设计,很像 TPU 的架构思路,小 batch 更高效,可以避免中间 tensor 溢出 SRAM
- maderix 通过不断扩展矩阵乘法的规模(Scaling Test),观察性能出现急剧下降的“断崖点”,由此反向推测出 ANE 内部拥有大约 32MB 的高速 SRAM 缓存,超过这个容量限制就会导致性能暴跌
-
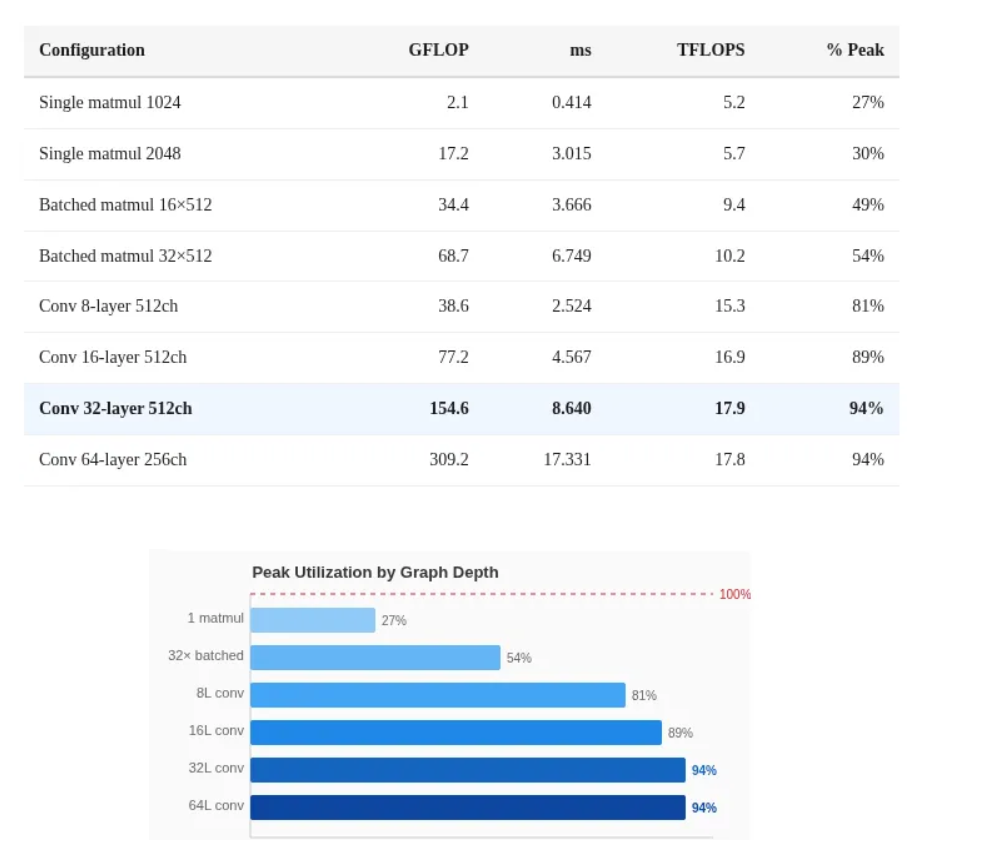
算力压榨:需利用计算图填满流水线
-
单操作低效:由于 ANE 的 16 个核心是基于流水线(Pipelined)设计的,如果只向它提交单个算子/操作,大部分核心将处于空转状态,只能发挥约 30% 的峰值性能
-
必须将 16 到 64 个操作 链接在一张计算图(Computation Graph)中一次性提交,这样不同的核心可以同时处理图中不同阶段的操作,从而将硬件利用率拉满至 94%
-
这么看 ANE 不是“单核算力 × 16”,而是“深度流水线机器”
-
-
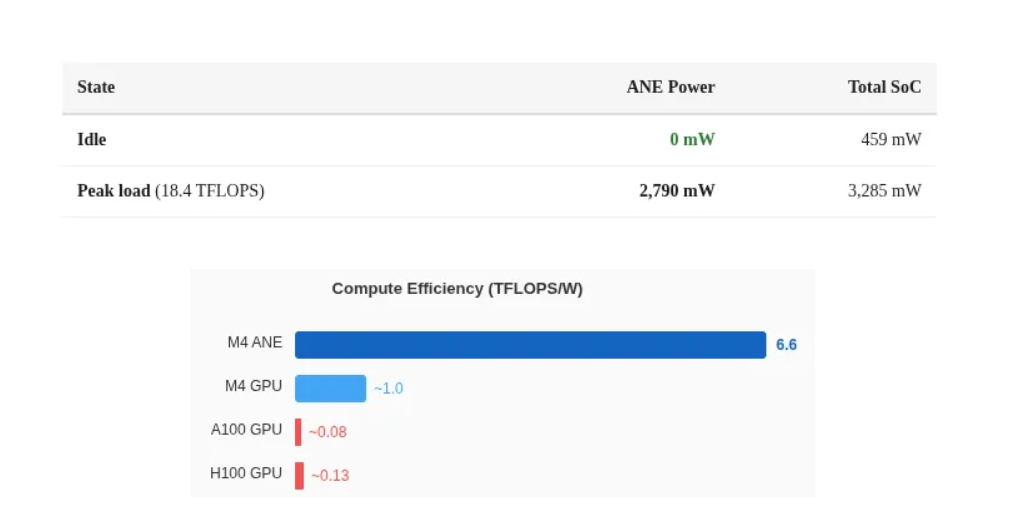
极致的 0mW 空闲功耗
-
ANE 拥有极为强悍的硬件级电源门控(Power Gating)技术
-
在空闲状态下,ANE 不是进入低功耗待机模式,而是做到完全断电、零泄漏,功耗为绝对的 0mW,这也解释了其在移动端设备上极佳的能效表现
-
| 官方 | 推测 | |
|---|---|---|
| INT8 | 38 TOPS | ≈ 19 TFLOPS 等效 |
| FP16 | 未强调 | ≈ 19 TFLOPS |
| SRAM | 未公开 | ≈ 32MB |
| 单算子利用率 | 未说明 | ≈ 30% |
| 图级利用率 | 未说明 | ≈ 94% |
最后,作者得到一个结论:ANE 对于小规模操作, CoreML 会增加 2-4 倍的开销 ,而在高吞吐量配置下,由于 ANE 计算时间占据主导地位,这种差距会缩小,但对于延迟敏感型工作负载(例如 LLM 令牌解码、实时推理),CoreML 的开销则非常显著。
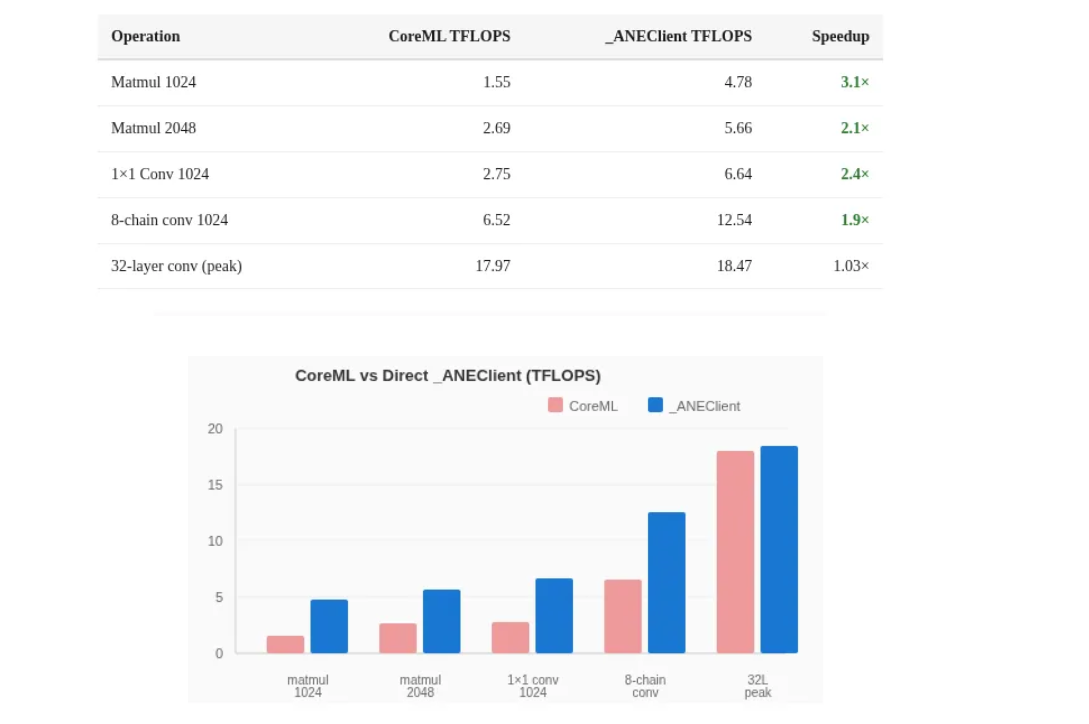
从这点看,ANE 不是通用 GPU,而是卷积优化机器 + 深流水线架构,总结下来:一个拥有 19 TFLOPS FP16 算力、32MB SRAM 缓存的“卷积加速器”,需要通过图编译的批处理来喂饱其 16 核流水线,并具备移动端顶级的电源管理能力。
另外,M4 的 CPU 核心也采用了苹果的 SME(可扩展矩阵扩展)技术,他们之间的对比:
- ANE: 大批量推理、16 层以上的深度图、能量受限场景以及持续吞吐量
- SME : 单标记解码(零调度开销)、ANE 不支持的自定义操作、小型矩阵以及任何需要 FP32+ 精度的操作
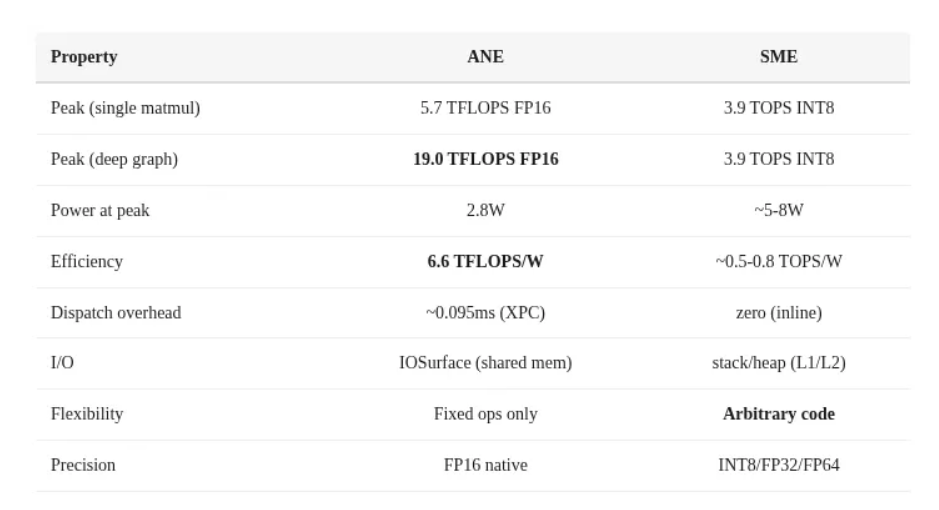
所以,M4 上理想的 LLM 推理策略是混合模式 :在 ANE 上进行预填充(大批量、高吞吐量),在 SME 上进行解码(单标记、对延迟敏感)。
另外,这个项目还有一些极限性能体现,例如 maderix 而为了让单步训练耗时压缩到 9.3 毫秒(持续输出 1.78 TFLOPS 的算力),必须进行极底层优化,确保 CPU 和 ANE 绝不互相等待:
- GCD 异步 cblas 重叠计算 :当 ANE 正在疯狂计算下一步的前向传播时,CPU 正在并行运行矩阵乘法 (
cblas_sgemm) 来计算当前步的权重梯度,两者完全重叠运行。 - 通道优先 (Channel-First) 内存布局 :将 CPU 端的数据布局格式彻底重写,与 ANE 底层原生的
[1, C, 1, S]IOSurface 共享内存格式完全对齐。,从而消灭了数据在两个芯片间来回拷贝、转置 (Transpose) 产生的性能开销。 - 前向抽头 (Forward Taps):在标准的反向传播中,经常需要重新计算某些值(耗时操作),所以直接让 ANE 在执行前向传播时,顺便把中间的隐藏状态和注意力分数直接以 Concat(拼接)的形式“吐”出来并缓存,反向传播时直接白嫖这些数据
更极客的是项目中的 exec() 重启法 ,因为 ANE 编译器存在严重的内存泄漏,在一个进程里连续编译大约 119 次后系统就会崩溃,而 每次权重更新,都必须重新编译 ANE 程序,这意味着每跑 119 步训练程序就会死掉。
而为了“逃课”,maderix 在训练循环中写了一个逻辑:定期保存当前的 Checkpoint,然后直接调用系统的 exec() 命令杀掉并重新启动自己的进程,通过这种不断“自杀并转生”的方式,暴力清空内存状态,完美绕过了苹果底层的内存泄漏限制。
所以整个基准测试,也可以看作是一个对 ANE 的极限性能压制场景。
参考链接
https://github.com/maderix/ANE

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)