通义实验室发布:Fun-CosyVoice3.5与Fun-AudioGen-VD语音双模型
阿里通义实验室发布两款革命性语音生成模型Fun-CosyVoice3.5和Fun-AudioGen-VD,支持"FreeStyle"自然语言指令控制。Fun-CosyVoice3.5实现多语种复刻与精细控制,新增4种语言支持,生僻字错误率降低10%,延迟减少35%。Fun-AudioGen-VD提供全场景声音设计,支持音色定制、情绪模拟和环境特效。两款模型大幅降低语音创作门槛,
今天,阿里通义实验室语音团队重磅推出两款具有革命性意义的语音生成模型——Fun-CosyVoice3.5 与 Fun-AudioGen-VD,这两款模型凭借独特的“FreeStyle”指令功能,在语音生成领域掀起了一阵新的浪潮。
自然语言操控:打破传统语音生成壁垒
以往,语音生成往往需要用户进行复杂的参数调节,对于非专业人士来说,这一过程不仅繁琐,而且难以达到理想的效果。然而,阿里通义此次发布的两款模型却彻底改变了这一局面。
它们支持“FreeStyle”指令,用户无需再为各种参数设置而烦恼,只需通过一句自然语言描述,就能精准控制声音的表达风格,甚至从零构建复杂的音频场景。这种创新性的交互方式,大大降低了语音创作的技术门槛,让更多人能够轻松参与到高品质语音的创作中来。
Fun-CosyVoice3.5:多语种复刻与精细化控制专家
Fun-CosyVoice3.5 作为 CosyVoice 的升级版,在语音表达的“理解力”方面实现了核心突破。
指令式生成:随心调整语音效果
在指令式生成方面,该模型展现出了强大的灵活性。用户可以输入诸如“语气坚定点”“语速放慢并带点情绪起伏”等指令,模型会实时根据这些指令调整输出效果,让语音更加贴合用户的需求。无论是用于商务演讲、有声读物录制,还是日常交流,都能轻松实现个性化的语音表达。
语种扩容:拓展全球语音交流版图
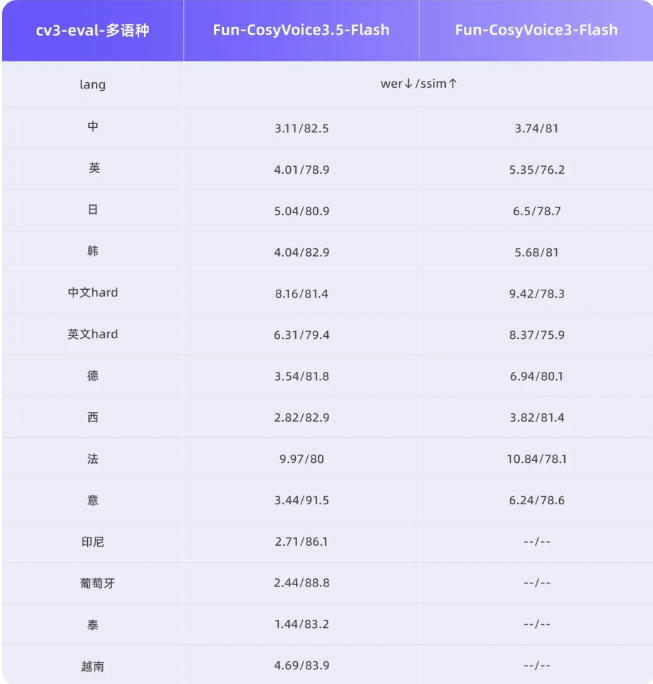
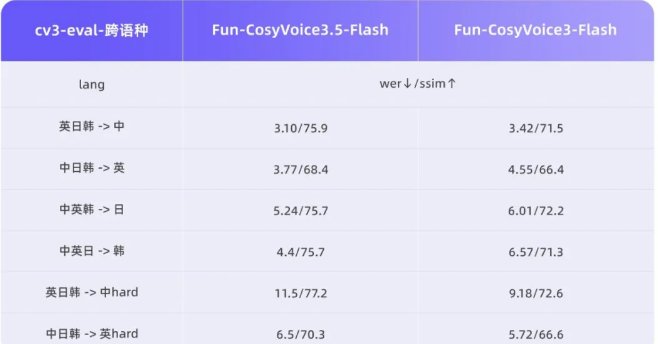
为了满足日益增长的全球语音交流需求,Fun-CosyVoice3.5 新增了对泰语、印尼语、葡萄牙语及越南语的支持。在 13 种语言的转写准确率(WER)和音色相似度上,该模型始终保持业内领先水平,为跨国交流、多语言内容创作等提供了有力支持。
生僻字优化:提升语音识别准确性
生僻字一直是语音识别和生成中的难题,但 Fun-CosyVoice3.5 通过专项调优,将生僻字读错率从 15.2% 大幅降至 5.3%。这一改进使得模型在处理包含生僻字的内容时更加准确可靠,进一步提升了语音生成的质量。
性能提升:保障实时交互流畅度
在性能方面,Fun-CosyVoice3.5 也有显著提升。首包延迟降低 35%,这意味着在实时交互场景下,用户能够更快地获得语音反馈,极大地提升了交流的流畅度和体验感。
Fun-AudioGen-VD:全场景声音设计的“声音导演”
如果说 Fun-CosyVoice3.5 专注于语音表达的精细化控制,那么 Fun-AudioGen-VD 则更像是一位全能的“声音导演”,能够根据描述生成“人物 + 场景”的一体化音频。
音色定制:打造专属独特声音
在音色定制方面,Fun-AudioGen-VD 支持用户指定性别、年龄、口音,甚至可以细化到“沙哑、磁性、低沉”等特质。无论是想要塑造一个成熟稳重的男性声音,还是一个甜美可爱的女性声音,该模型都能轻松实现,满足不同场景下的多样化需求。
情绪与角色:模拟复杂心理状态
除了音色定制,Fun-AudioGen-VD 还能够模拟各种角色的声音,并表现出丰富的情绪。它可以模拟客服的亲切热情、播音员的专业沉稳、孩童的天真活泼等角色声音,甚至能表现出“表面镇定但内心颤抖”等复杂心理状态,为音频内容增添更多的生动性和真实感。
环境沉浸感:营造全方位空间模拟
为了营造更加逼真的音频场景,Fun-AudioGen-VD 支持叠加背景音和空间特效。用户可以添加战场轰鸣、咖啡馆喧嚣等背景音,以及大教堂回声、水下听感等空间特效,实现全方位的空间模拟,让听众仿佛身临其境。
行业助力:推动语音技术应用新发展
阿里通义实验室表示,这两款模型的发布将进一步降低高品质语音创作的门槛,为播客、游戏开发、影视后期等领域提供强大的 AI 助力。
- 在播客领域,创作者可以利用这些模型轻松实现个性化的语音表达和丰富的场景音效,提升节目质量;
- 在游戏开发中,模型可以为游戏角色赋予更加生动逼真的声音,增强玩家的沉浸感;
- 在影视后期制作中,能够快速生成高质量的语音内容,提高制作效率。
阿里通义发布的这两款语音生成模型,无疑为语音技术领域注入了新的活力。它们以自然语言操控为核心,在多语种复刻、精细化控制、全场景声音设计等方面取得了重要突破,为众多行业带来了全新的发展机遇。
随着技术的不断进步和应用场景的不断拓展,相信这两款模型将在未来发挥更加重要的作用,推动语音技术迈向新的高度。
调用地址:
API地址:https://help.aliyun.com/zh/model-studio/text-to-speech?spm=a2c4g.11186623.help-menu-2400256.d_0_3_2_0.d5536a31V2tEJP
文章来源:AITOP100,原文地址:https://www.aitop100.cn/infomation/details/33362.html

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)