Linux ——— 进程间通信、自定义实现日志类、共享内存
本文摘要: 匿名管道通信原理 本质为内核内存缓冲区,仅支持血缘进程通信(通过fork继承文件描述符) 单向通信通过关闭多余读写端实现,生命周期由引用计数管理 代码示例展示父子进程通过pipe()创建管道,fork()继承fd实现数据传递 进程池与任务分发 父进程创建多个子进程,每个子进程绑定独立管道 通过轮询机制向子进程分发任务指令(函数指针下标) 子进程通过重定向标准输入到管道读端接收任务并执行
目录
匿名管道通信的原理
一、核心需求梳理
深入理解 Linux匿名管道(pipe) 的通信原理,核心要搞清楚:管道的本质(内核级文件而非磁盘文件)、仅支持血缘关系进程通信的原因、基于进程核心结构体(task_struct/files_struct)的文件描述符继承机制,以及管道单向通信的实现逻辑(读写端关闭策略)。
二、匿名管道通信的完整原理
1. 匿名管道的本质:内核维护的 “伪文件”
管道(pipe)虽然被归为 “文件”,但和磁盘文件有本质区别:
- 存储位置:管道是内核在内存中开辟的一块环形缓冲区(对应内核中的
struct file结构体),完全存在于内核空间,不会落地到磁盘(无 inode、无数据块,进程退出后内核自动释放); - 文件属性:管道文件只有 “读” 和 “写” 两种操作方法,无 “创建 / 删除 / 修改权限” 等磁盘文件的属性,是专门用于进程间通信(IPC)的内核对象;
- 核心作用:作为两个进程间的 “数据传输通道”,数据从写端写入内核缓冲区,从读端读出,实现进程间的数据传递。
2. 匿名管道仅支持 “血缘关系” 进程通信的原因
匿名管道的关键特征是 “匿名”—— 它没有文件名,无法通过路径被非血缘进程访问,只能通过fork后的文件描述符继承机制传递:
- 只有父子、兄弟、爷孙等有血缘关系的进程(由同一父进程
fork创建),才能继承指向同一管道的文件描述符; - 非血缘进程(如两个独立启动的进程)无法获取管道的文件描述符,因此无法使用匿名管道通信(若要无血缘通信,需用命名管道
fifo,本质是给管道绑定磁盘文件名)。
3. 进程结构体与文件描述符的继承逻辑(核心)
Linux 中进程的文件操作核心依赖两个结构体,这是管道通信的底层基础:
(1)父进程的初始状态
每个进程都有一个核心控制块task_struct(进程描述符),其中包含files_struct(文件描述符表):
files_struct是一个数组,下标就是文件描述符(fd),默认:- fd=0:标准输入(绑定键盘);
- fd=1:标准输出(绑定显示器);
- fd=2:标准错误(绑定显示器);
- 父进程调用
pipe(int fd[2])创建管道时,内核会分配一个管道缓冲区,并在files_struct中分配两个新的 fd:- fd=3:管道的读端(对应管道的读方法);
- fd=4:管道的写端(对应管道的写方法)。
(2)子进程的继承过程
父进程调用fork()创建子进程时:
- 子进程会复制父进程的
task_struct,但共享files_struct的指针(即子进程的文件描述符表和父进程指向同一套 fd 映射); - 因此子进程的 fd=3、fd=4 也指向父进程创建的同一个管道缓冲区,fd=0/1/2 也继承父进程的绑定关系(键盘 / 显示器);
- 管道缓冲区自身维护一个引用计数:记录当前有多少个 fd 指向自己(初始为 2:父进程的 3 和 4),
fork后子进程也持有 3 和 4,引用计数变为 4。
(3)引用计数的作用
引用计数保证管道的生命周期:
- 当进程关闭一个管道 fd(如父进程关闭 fd=3),引用计数减 1;
- 只有当引用计数减至 0 时(所有指向管道的 fd 都被关闭),内核才会释放管道缓冲区;
- 即使父 / 子进程退出,只要还有其他进程持有管道 fd,管道就不会被释放,避免数据丢失。
4. 管道单向通信的实现:关闭多余的读写端
管道是半双工通信(同一时间只能单向传输),因此需要通过 “关闭一端 fd” 实现单向通信,核心逻辑:
| 通信方向 | 父进程操作 | 子进程操作 | 最终效果 |
|---|---|---|---|
| 父写子读 | 关闭读端(close (3)),保留写端(4) | 关闭写端(close (4)),保留读端(3) | 父进程只能向管道写数据,子进程只能从管道读数据 |
| 子写父读 | 关闭写端(close (4)),保留读端(3) | 关闭读端(close (3)),保留写端(4) | 子进程只能向管道写数据,父进程只能从管道读数据 |
为什么要关闭多余端?
- 若不关闭,父子进程都能读写,会导致数据混乱(比如父写的同时子也写,读端无法区分数据来源);
- 同时,管道的 “读空 / 写满” 机制依赖读写端的数量:若写端全部关闭,读端读取到 EOF;若读端全部关闭,写端写入会触发 SIGPIPE 信号(进程退出)。
三、核心总结
- 匿名管道本质是内核内存缓冲区(伪文件),无磁盘存储,进程退出后内核释放;
- 仅支持血缘进程通信:依赖
fork继承管道 fd,非血缘进程无法获取匿名管道的 fd; - 通信核心是
files_struct继承:父子进程共享管道 fd,引用计数管理管道生命周期; - 单向通信通过 “关闭多余读写端” 实现:父写子读(父关读、子关写),反之亦然。
匿名管道通信的接口使用
// Linux系统调用头文件:包含fork/waitpid/pipe等进程/管道相关函数
#include<unistd.h>
// 标准库头文件:包含exit/atoi等通用函数
#include<stdlib.h>
// 字符串操作头文件:包含strlen/memset等函数
#include<string.h>
// 标准输入输出头文件:包含printf/scanf等
#include<stdio.h>
// 系统类型头文件:定义pid_t等类型
#include<sys/types.h>
// 进程等待头文件:包含waitpid函数
#include<sys/wait.h>
// C++标准库头文件
#include<iostream>
#include<string>
using namespace std;
// 宏定义:管道文件描述符数组大小(固定为2,0=读端,1=写端)
#define N 2
// 宏定义:缓冲区大小(接收/发送数据的最大长度)
#define SIZE 1024
// 子进程写数据函数
// 参数wfd:管道写端的文件描述符
void Writer(int wfd)
{
// 基础发送字符串
string s = "hello, I am child";
// 获取子进程自身的PID(进程ID)
pid_t self = getpid();
// 计数:标记发送的消息序号
int number = 0;
// 数据缓冲区:存储要发送的格式化字符串
char buffer[SIZE];
// 循环发送10条消息
while(true)
{
// 清空缓冲区(避免残留脏数据)
buffer[0] = 0;
// 格式化字符串:拼接基础信息+子进程PID+消息序号
// 格式:"hello, I am child-子进程PID-序号"
snprintf(buffer, sizeof(buffer), "%s-%d-%d", s.c_str(), self, number++);
// 向管道写端写入数据
// write(文件描述符, 数据地址, 数据长度):成功返回写入字节数,失败返回-1
write(wfd, buffer, strlen(buffer));
// 发送10条后退出循环
if(number == 10)
{
break;
}
// 休眠1秒:模拟子进程每隔1秒发送一条消息
sleep(1);
}
}
// 父进程读数据函数
// 参数rfd:管道读端的文件描述符
void Reader(int rfd)
{
// 数据缓冲区:存储从管道读取的内容
char buffer[SIZE];
// 循环读取管道数据,直到读端关闭
while(true)
{
// 清空缓冲区
buffer[0] = 0;
// 从管道读端读取数据
// read(文件描述符, 数据缓冲区, 缓冲区大小):
// - 成功:返回读取的字节数(n>0);
// - 读端关闭且无数据:返回0(n==0);
// - 失败:返回-1(n<0)
ssize_t n = read(rfd, buffer, sizeof(buffer));
if(n > 0)
{
// 读取成功:在字符串末尾加'\0',确保格式化输出
buffer[n] = 0;
// 打印父进程PID和读取到的消息
cout << "father get a message[" << getpid() << "]# " << buffer << endl;
}
else if(n == 0)
{
// 读端关闭(子进程关闭写端),无数据可读
cout << "father read file down" << endl;
break;
}
else
{
// 读取错误(如管道异常),退出循环
break;
}
}
}
int main()
{
// 管道文件描述符数组:pipefd[0]=读端,pipefd[1]=写端(固定规则)
int pipefd[N] = {0};
// 创建匿名管道:成功返回0,失败返回-1
// 核心:匿名管道仅能用于有亲缘关系的进程(父子/兄弟)通信
int n = pipe(pipefd);
if(n < 0)
{
// 管道创建失败,程序退出
return 1;
}
// 创建子进程:fork成功返回子进程PID(父进程视角),0(子进程视角),失败返回-1
pid_t id = fork();
if(id < 0)
{
// 子进程创建失败,程序退出
return 2;
}
else if(id == 0)
{
// 子进程执行逻辑
// 管道通信规则:单向通信(本例子写父读),关闭子进程不需要的读端
close(pipefd[0]);
// 子进程向管道写端写入数据
Writer(pipefd[1]);
// 数据发送完成,关闭写端(触发父进程read返回0)
close(pipefd[1]);
// 子进程正常退出,退出码0
exit(0);
}
else
{
// 父进程执行逻辑
// 关闭父进程不需要的写端
close(pipefd[1]);
// 父进程从管道读端读取数据
Reader(pipefd[0]);
// 等待子进程退出:避免子进程变成僵尸进程
// waitpid(子进程PID, 退出状态指针, 选项):0表示阻塞等待
pid_t rid = waitpid(id, nullptr, 0);
if(rid < 0)
{
// 等待子进程失败,程序退出
return 3;
}
// 读取完成,关闭读端
close(pipefd[0]);
}
return 0;
}一、代码整体功能总结
这段代码是Linux 下父子进程通过匿名管道实现单向通信的完整示例,核心逻辑是:
- 父进程先创建匿名管道,再
fork出子进程; - 子进程关闭管道读端,每隔 1 秒向管道写端写入一条带自身 PID 和消息序号的字符串,共写 10 条后关闭写端并退出;
- 父进程关闭管道写端,持续从管道读端读取子进程发送的消息并打印,直到子进程关闭写端(读端返回 0),最后等待子进程退出(避免僵尸进程),完成通信。
二、代码分模块详细解释
1. 头文件部分:区分系统调用 / 标准库 / 类型定义
// Linux系统调用头文件(核心)
#include<unistd.h> // 包含pipe/fork/write/read/sleep/close等管道/进程函数
#include<stdlib.h> // 包含exit等进程退出函数
#include<string.h> // 包含strlen/memset等字符串操作函数
#include<stdio.h> // 包含snprintf等格式化函数
#include<sys/types.h> // 定义pid_t(进程ID类型)、ssize_t(读写返回值类型)
#include<sys/wait.h> // 包含waitpid(进程等待函数)
// C++标准库(仅用于输出和字符串处理,核心逻辑仍是C的系统调用)
#include<iostream>
#include<string>
using namespace std;
- 核心依赖是
<unistd.h>和<sys/types.h>,这是 Linux 进程 / 管道通信的基础; - C++ 库仅用于简化字符串(
string)和输出(cout),换成纯 C 也可实现(用char[]和printf)。
2. 宏定义:固定常量,提升代码可读性
#define N 2 // 管道文件描述符数组大小(Linux管道固定为2:0=读端,1=写端)
#define SIZE 1024 // 数据缓冲区大小(单次读写的最大字节数)
3. 子进程写数据函数 Writer
void Writer(int wfd) // wfd:管道写端的文件描述符
{
string s = "hello, I am child";
pid_t self = getpid(); // 获取子进程自身的PID(用于标识消息来源)
int number = 0; // 消息序号,标记第几条消息
char buffer[SIZE]; // 存储格式化后的待发送数据
while(true)
{
buffer[0] = 0; // 清空缓冲区(避免残留上一次的脏数据)
// 格式化字符串:拼接"基础内容-子进程PID-消息序号"
snprintf(buffer, sizeof(buffer), "%s-%d-%d", s.c_str(), self, number++);
// 核心:向管道写端写入数据
// write(文件描述符, 数据地址, 数据长度):成功返回写入字节数,失败返回-1
write(wfd, buffer, strlen(buffer));
if(number == 10) break; // 写满10条退出循环
sleep(1); // 休眠1秒,模拟周期性发送
}
}
- 核心操作是
write(wfd, buffer, strlen(buffer)):将格式化后的字符串写入管道内核缓冲区; snprintf是安全的格式化函数,避免缓冲区溢出(对比sprintf);getpid()获取子进程 PID,用于在消息中标识 “哪个子进程发送的”(本例只有 1 个子进程,多子进程场景更有用)。
4. 父进程读数据函数 Reader
void Reader(int rfd) // rfd:管道读端的文件描述符
{
char buffer[SIZE]; // 存储从管道读取的内容
while(true)
{
buffer[0] = 0; // 清空缓冲区
// 核心:从管道读端读取数据
// read(文件描述符, 缓冲区, 缓冲区大小):
// - 返回值n>0:成功读取n个字节;
// - n=0:管道写端全部关闭(子进程关闭写端),无数据可读;
// - n<0:读取失败(如管道异常)。
ssize_t n = read(rfd, buffer, sizeof(buffer));
if(n > 0)
{
buffer[n] = 0; // 手动加字符串结束符(read只读数据,不补'\0')
cout << "father get a message[" << getpid() << "]# " << buffer << endl;
}
else if(n == 0) // 子进程关闭写端,读端读到EOF
{
cout << "father read file down" << endl;
break;
}
else break; // 读取错误,退出循环
}
}
- 核心操作是
read(rfd, buffer, sizeof(buffer)):从管道内核缓冲区读取数据到用户缓冲区; - 关键注意点:
read不会自动在数据末尾加'\0',因此需要手动buffer[n] = 0,否则cout打印会乱码; n==0是管道通信的关键信号:表示所有写端都已关闭,父进程无需继续读取。
5. main 函数:核心流程(创建管道→fork 子进程→单向通信)
int main()
{
int pipefd[N] = {0}; // 管道文件描述符数组:pipefd[0]=读端,pipefd[1]=写端
// 步骤1:创建匿名管道
int n = pipe(pipefd);
if(n < 0) return 1; // 管道创建失败,退出(返回非0表示异常)
// 步骤2:fork创建子进程
pid_t id = fork();
if(id < 0) return 2; // fork失败,退出
else if(id == 0) // 子进程执行分支(fork返回0给子进程)
{
// 步骤3:子进程关闭不需要的读端(单向通信:子写父读)
close(pipefd[0]);
// 步骤4:子进程向管道写数据
Writer(pipefd[1]);
// 步骤5:数据写完,关闭写端(触发父进程read返回0)
close(pipefd[1]);
exit(0); // 子进程正常退出,退出码0
}
else // 父进程执行分支(fork返回子进程PID给父进程)
{
// 步骤3:父进程关闭不需要的写端
close(pipefd[1]);
// 步骤4:父进程从管道读数据
Reader(pipefd[0]);
// 步骤5:等待子进程退出(避免子进程变成僵尸进程)
pid_t rid = waitpid(id, nullptr, 0);
if(rid < 0) return 3; // 等待失败,退出
// 步骤6:读取完成,关闭读端
close(pipefd[0]);
}
return 0;
}
这是整个代码的核心,结合管道原理拆解关键步骤:
(1)创建管道:pipe(pipefd)
- 调用
pipe后,内核会创建一块管道缓冲区,并给pipefd赋值:pipefd[0]:管道读端 fd;pipefd[1]:管道写端 fd;
- 管道的读写端是 “成对存在” 的,必须通过
fork让子进程继承这两个 fd,才能通信。
(2)fork 创建子进程:pid_t id = fork()
- 父进程视角:
fork返回子进程的 PID(正数); - 子进程视角:
fork返回 0; - 父子进程会继承同一个 pipefd 数组,指向内核中同一块管道缓冲区(这是血缘进程通信的核心)。
(3)关闭多余的 fd:实现单向通信
- 子进程关闭读端
close(pipefd[0]):只保留写端,只能向管道写数据; - 父进程关闭写端
close(pipefd[1]):只保留读端,只能从管道读数据; - 若不关闭,父子进程都能读写,会导致数据混乱(比如父写子读、子写父读同时发生)。
(4)进程等待:waitpid(id, nullptr, 0)
- 父进程阻塞等待子进程退出,避免子进程变成 “僵尸进程”(占用系统资源);
waitpid的第三个参数0表示 “阻塞等待”,直到子进程退出才返回。
三、核心总结
- 匿名管道通信的核心是内核缓冲区 + 文件描述符继承:父子进程通过继承的 fd 操作同一块内核缓冲区;
- 单向通信必须关闭多余 fd:子写父读→子关读端、父关写端;
read返回0是关键信号:表示所有写端已关闭,父进程可安全退出读取循环;waitpid必须调用:避免子进程成为僵尸进程,浪费系统 PID 资源;- 管道是 “面向字节流” 的:数据无边界,需通过约定(如固定长度、结束符)区分消息(本例通过次数限制)。
使用匿名管道实现一个简易版本的进程池
Task.hpp
#pragma once // 防止头文件重复包含(替代传统的#ifndef...#define...#endif)
// Linux系统/标准库头文件
#include<iostream> // 输入输出流(cout)
#include<vector> // 容器vector,用于存储任务函数指针
#include<time.h> // 时间函数(srand的种子time(nullptr))
#include<unistd.h> // Linux系统调用(fork/pipe/dup2/close/read/write/sleep等)
#include<stdlib.h> // 通用函数(rand/exit等)
#include<string.h> // 字符串操作(本例未用到)
#include<stdio.h> // 标准输入输出(本例未用到)
#include<sys/types.h> // 系统类型定义(pid_t等)
#include<sys/wait.h> // 进程等待(waitpid)
#include<string> // C++字符串类
using namespace std; // 简化std::前缀的使用
// 定义任务函数类型:无返回值、无参数的函数指针
// 后续所有任务函数都需符合该签名(test_t1/test_t2等)
typedef void(*task_t)();
// ==================== 具体的任务函数(模拟LOL游戏后台任务) ====================
// 任务1:刷新日志
void test_t1()
{
cout << "lol 刷新日志" << endl;
}
// 任务2:更新野区,刷新野怪
void test_t2()
{
cout << "lol 更新野区,刷新野怪" << endl;
}
// 任务3:检查版本更新并提醒用户
void test_t3()
{
cout << "lol 检查是否需要更新,并且提醒用户更新" << endl;
}
// 任务4:处理用户释放技能,更新CD/血量/蓝量
void test_t4()
{
cout << "lol 用户释放技能,更新CD以及血量和蓝量" << endl;
}ipc_use.cpp
#include"Task.hpp" // 包含任务类型和具体任务函数的定义
// 宏定义:要创建的子进程(奴隶进程)数量
#define PORCESSNUM 10
// 全局变量:任务集,存储所有可执行的任务函数指针
vector<task_t> tasks;
// ==================== 装载任务:将所有具体任务加入任务集 ====================
// 参数rtasks:任务集的引用(避免拷贝,直接修改原容器)
void LoadTask(vector<task_t>& rtasks)
{
rtasks.push_back(test_t1); // 加入任务1
rtasks.push_back(test_t2); // 加入任务2
rtasks.push_back(test_t3); // 加入任务3
rtasks.push_back(test_t4); // 加入任务4
}
// ==================== 通道类:封装“父进程-子进程”通信的核心信息 ====================
class channel
{
public:
// 构造函数:初始化通信通道的关键信息
// cmdfd:父进程向子进程发送任务的管道写端文件描述符
// slaverid:子进程的PID(用于后续回收子进程)
// name:子进程的名称(便于调试/日志)
channel(int cmdfd, pid_t slaverid, const string& name)
: _cmdfd(cmdfd)
, _slaverid(slaverid)
, _name(name)
{}
public:
int _cmdfd; // 管道写端文件描述符(父进程写任务指令)
pid_t _slaverid; // 子进程PID(父进程回收子进程用)
string _name; // 子进程名称(如process_0、process_1)
};
// ==================== 子进程执行逻辑:阻塞等待并执行任务 ====================
void PorcessSlaver()
{
// 子进程无限循环,直到父进程关闭写端(read返回0)
while(true)
{
// 约定:任务指令是4字节的整数(cmdcode),代表任务集的下标
// 例如cmdcode=0 → 执行test_t1,cmdcode=1 → 执行test_t2
int cmdcode = 0;
// 从标准输入(0号文件描述符)读取任务指令:
// - 父进程未发送任务时,子进程阻塞在此处
// - 父进程发送任务后,读取4字节的cmdcode
// - 父进程关闭写端后,read返回0,子进程退出循环
int n = read(0, &cmdcode, sizeof(cmdcode));
// 读取到完整的任务指令(4字节)
if(n == sizeof(cmdcode))
{
// 校验指令合法性:cmdcode在任务集下标范围内
if(cmdcode >= 0 && cmdcode < tasks.size())
{
// 执行任务:通过函数指针调用对应任务
tasks[cmdcode]();
}
}
// 读端检测到写端关闭(n=0),退出循环(子进程准备退出)
if(n == 0)
{
break;
}
}
}
// ==================== 初始化子进程:创建多个子进程并建立通信管道 ====================
// 参数pchannels:存储所有子进程通道信息的容器指针
void InitPorcess(vector<channel>* pchannels)
{
// 存储父进程已创建的管道写端(用于子进程关闭继承的多余写端)
vector<int> oldfds;
// 循环创建PORCESSNUM个子进程
for(int i = 0; i < PORCESSNUM; i++)
{
// 1. 创建匿名管道:pipefd[0]=读端,pipefd[1]=写端
int pipefd[2] = {0};
int n = pipe(pipefd);
if(n < 0) // 管道创建失败,直接退出程序
{
exit(1);
}
(void)n; // 消除未使用变量的警告
// 2. 创建子进程
pid_t id = fork();
if(id == 0)
{
// ---------------- 子进程执行逻辑 ----------------
// 关键:子进程会继承父进程的所有文件描述符,需关闭之前创建的管道写端
// (避免每个子进程持有多个写端,导致父进程关闭写端后子进程仍不退出)
for(auto fd : oldfds)
{
close(fd);
}
// 子进程只需要读端,关闭写端
close(pipefd[1]);
// 重定向标准输入(0号文件描述符)到管道读端:
// - 原本0号是键盘输入,现在改为从管道读端读取任务指令
// - 这样子进程的read(0, ...)就等价于read(pipefd[0], ...)
dup2(pipefd[0], 0);
// 重定向后,pipefd[0]和0号都指向管道读端,关闭pipefd[0]避免文件描述符泄漏
close(pipefd[0]);
// 子进程进入任务执行循环
PorcessSlaver();
// 任务循环退出(写端关闭),打印退出日志并退出子进程
cout << "I am child, My pid is: " << getpid() << " : " << "My task is over" << endl;
exit(0);
}
// ---------------- 父进程执行逻辑 ----------------
// 父进程只需要写端,关闭读端
close(pipefd[0]);
// 构造子进程通道信息并加入容器
string name = "process_" + to_string(i); // 子进程名称:process_0/process_1...
pchannels->push_back(channel(pipefd[1], id, name));
// 记录当前管道写端,供后续子进程关闭继承的写端
oldfds.push_back(pipefd[1]);
}
}
// ==================== 父进程控制逻辑:轮询向子进程分发任务 ====================
// 参数rchannels:所有子进程的通道信息(只读)
void ControlPorcess(const vector<channel>& rchannels)
{
// 轮询下标:用于选择当前要发送任务的子进程
int which = 0;
// 模拟发送10个任务(注释的while(true)可改为无限发送)
for(int i = 0; i < 10; i++) //while(true)
{
// 随机选择一个任务(cmdcode为任务集的随机下标)
int cmdcode = rand() % tasks.size();
// 向当前选中的子进程发送任务指令:
// 写入4字节的cmdcode到子进程对应的管道写端
write(rchannels[which]._cmdfd, &cmdcode, sizeof(cmdcode));
// 轮询:切换到下一个子进程(取模避免下标越界)
which++;
which = which % rchannels.size();
// 休眠1秒:模拟任务分发间隔
sleep(1);
}
}
// ==================== 清理收尾:关闭管道并回收子进程 ====================
// 参数rchannels:所有子进程的通道信息(只读)
void QuitPorcess(const vector<channel>& rchannels)
{
// 遍历所有子进程通道
for(auto& c : rchannels)
{
// 关闭父进程的管道写端:子进程的read会返回0,触发退出循环
close(c._cmdfd);
// 阻塞等待子进程退出,避免僵尸进程
waitpid(c._slaverid, nullptr, 0);
// 打印子进程回收日志
cout << c._name << " is recycle" << endl;
}
// 【备选写法】先关闭所有写端,再统一回收子进程(效果相同)
// for(auto& c : rchannels)
// {
// close(c._cmdfd);
// }
// for(auto& c : rchannels)
// {
// waitpid(c._slaverid, nullptr, 0);
// cout << c._name << " is recycle" << endl;
// }
}
// ==================== 主函数:程序入口 ====================
int main()
{
// 步骤1:装载所有任务到任务集
LoadTask(tasks);
// 步骤2:设置随机数种子(保证每次运行rand结果不同)
srand((unsigned int)time(nullptr));
// 步骤3:创建容器存储所有子进程的通道信息
vector<channel> channels;
// 步骤4:初始化子进程(创建管道+子进程,建立通信通道)
InitPorcess(&channels);
// 步骤5:父进程分发任务(轮询向子进程发送任务指令)
ControlPorcess(channels);
// 步骤6:清理资源(关闭管道,回收子进程)
QuitPorcess(channels);
return 0;
}一、代码核心功能总结
这份代码是Linux 下基于匿名管道的多子进程任务分发系统,模拟 LOL 游戏后台的任务处理逻辑:
- 父进程创建 10 个子进程(奴隶进程),为每个子进程单独建立匿名管道用于通信;
- 父进程作为 “控制端”,轮询向不同子进程发送 “任务指令”(用整数表示任务下标);
- 子进程作为 “执行端”,阻塞等待管道中的任务指令,收到后执行对应任务(刷新日志、更新野区等);
- 父进程分发完 10 个任务后,关闭所有管道写端,回收所有子进程,避免僵尸进程和资源泄漏。
二、代码分模块详细解释
1. 头文件 / 宏定义 / 全局变量:基础准备
// Task.hpp 核心定义
#pragma once // 防止头文件重复包含
// Linux系统调用+标准库头文件(进程/管道/容器/字符串等)
#include<iostream>
#include<vector>
#include<time.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<stdio.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<string>
using namespace std;
// 任务函数类型:无返回值、无参数的函数指针(所有任务必须符合该签名)
typedef void(*task_t)();
// 4个具体任务函数(模拟LOL后台任务)
void test_t1() { cout << "lol 刷新日志" << endl; }
void test_t2() { cout << "lol 更新野区,刷新野怪" << endl; }
void test_t3() { cout << "lol 检查是否需要更新,并且提醒用户更新" << endl; }
void test_t4() { cout << "lol 用户释放技能,更新CD以及血量和蓝量" << endl; }
// ipc_use.cpp 宏定义+全局变量
#define PORCESSNUM 10 // 要创建的子进程数量(固定10个)
vector<task_t> tasks; // 全局任务集:存储所有可执行的任务函数指针
- 函数指针
task_t:统一任务函数的格式,让父进程只需发送 “下标” 就能指定子进程执行的任务,无需关心任务具体实现; - 全局
tasks容器:存储所有任务函数的指针,子进程通过 “下标(cmdcode)” 就能找到并执行对应任务,是 “指令→任务” 的映射核心。
2. LoadTask:装载任务到任务集
void LoadTask(vector<task_t>& rtasks)
{
rtasks.push_back(test_t1);
rtasks.push_back(test_t2);
rtasks.push_back(test_t3);
rtasks.push_back(test_t4);
}
- 把 4 个具体任务函数的指针加入
tasks容器,建立 “下标→任务” 的映射:tasks[0]→ 刷新日志;tasks[1]→ 更新野区;tasks[2]→ 检查版本更新;tasks[3]→ 处理技能释放。
- 用引用传参(
&rtasks):避免拷贝容器,直接修改全局tasks,节省内存。
3. channel类:封装子进程通信的核心信息
class channel
{
public:
channel(int cmdfd, pid_t slaverid, const string& name)
: _cmdfd(cmdfd), _slaverid(slaverid), _name(name) {}
public:
int _cmdfd; // 父进程向该子进程发指令的管道写端fd
pid_t _slaverid; // 子进程PID(父进程回收子进程用)
string _name; // 子进程名称(如process_0,便于调试/日志)
};
- 面向对象封装:把 “通信 fd + 子进程 PID + 名称” 打包,避免零散变量管理,父进程只需维护
vector<channel>就能管理所有子进程; - 核心作用:父进程通过
_cmdfd给子进程发指令,通过_slaverid回收子进程,_name用于打印日志。
4. PorcessSlaver:子进程的核心执行逻辑
void PorcessSlaver()
{
while(true)
{
int cmdcode = 0; // 任务指令:存储任务集的下标
// 从标准输入(0号fd)读取4字节的cmdcode
int n = read(0, &cmdcode, sizeof(cmdcode));
// 读取到完整的任务指令(4字节)
if(n == sizeof(cmdcode))
{
// 校验指令合法性:下标在任务集范围内
if(cmdcode >= 0 && cmdcode < tasks.size())
{
tasks[cmdcode](); // 执行任务(函数指针调用)
}
}
// 父进程关闭写端,read返回0 → 子进程退出循环
if(n == 0) break;
}
}
- 子进程的 “死循环 + 阻塞读”:
- 若无任务指令,子进程阻塞在
read(0, ...),不占用 CPU 资源; - 父进程发送指令后,
read读取 4 字节的cmdcode,通过函数指针执行对应任务;
- 若无任务指令,子进程阻塞在
- 关键约定:任务指令是4 字节整数(
int类型),代表tasks的下标,简单且高效(无需解析字符串); - 退出条件:父进程关闭管道写端,
read返回 0,子进程退出循环并准备退出。
5. InitPorcess:创建子进程 + 管道,建立通信通道(核心难点)
void InitPorcess(vector<channel>* pchannels)
{
vector<int> oldfds; // 存储父进程已创建的管道写端(供子进程关闭)
for(int i = 0; i < PORCESSNUM; i++) // 创建10个子进程
{
// 步骤1:创建匿名管道
int pipefd[2] = {0};
int n = pipe(pipefd);
if(n < 0) exit(1);
(void)n; // 消除未使用变量警告
// 步骤2:fork创建子进程
pid_t id = fork();
if(id == 0) // 子进程分支
{
// 关键:关闭继承的旧管道写端(核心设计点!)
for(auto fd : oldfds) close(fd);
// 子进程只需要读端,关闭写端
close(pipefd[1]);
// 核心:重定向标准输入(0号fd)到管道读端
dup2(pipefd[0], 0);
// 重定向后,pipefd[0]和0号都指向读端,关闭pipefd[0]避免泄漏
close(pipefd[0]);
// 子进程进入任务循环
PorcessSlaver();
// 任务结束,退出子进程
cout << "I am child, My pid is: " << getpid() << " : " << "My task is over" << endl;
exit(0);
}
// 父进程分支
// 父进程只需要写端,关闭读端
close(pipefd[0]);
// 构造channel对象,加入容器
string name = "process_" + to_string(i);
pchannels->push_back(channel(pipefd[1], id, name));
// 记录当前管道写端,供后续子进程关闭
oldfds.push_back(pipefd[1]);
}
}
这是代码最核心、最复杂的部分,拆解关键设计点:
(1)为什么要维护oldfds?
- 父进程循环创建管道 + 子进程,每个子进程会继承父进程所有已打开的 fd(包括之前创建的管道写端);
- 若不关闭这些 “旧 fd”,每个子进程会持有 10 个管道写端(而非仅自己的 1 个),导致父进程关闭写端后,子进程的
read仍不会返回 0(因为还有其他写端未关闭); - 解决方案:子进程创建时,先关闭
oldfds中存储的所有旧管道写端,只保留自己的管道读端。
(2)dup2(pipefd[0], 0):标准输入重定向(核心技巧)
- 原本 0 号 fd 是 “标准输入”(绑定键盘),子进程需要从管道读指令,因此用
dup2把 0 号 fd 重定向到管道读端; - 效果:子进程的
read(0, ...)等价于read(pipefd[0], ...),无需传递pipefd[0],简化子进程逻辑; - 重定向后,
pipefd[0]和 0 号 fd 都指向管道读端,需关闭pipefd[0],避免文件描述符泄漏。
(3)父子进程的 fd 管理原则
- 子进程:关闭写端 + 旧 fd → 重定向 0 号到读端 → 关闭原读端 → 只保留 “重定向后的 0 号 fd”;
- 父进程:关闭读端 → 保留写端 → 记录写端到
oldfds→ 把写端 / PID / 名称加入channels容器。
6. ControlPorcess:父进程轮询分发任务运行
void ControlPorcess(const vector<channel>& rchannels)
{
int which = 0; // 轮询下标:选择当前要发送任务的子进程
// 模拟发送10个任务(注释的while(true)可改为无限发送)
for(int i = 0; i < 10; i++)
{
// 随机生成任务指令(0-3的随机数,对应4个任务)
int cmdcode = rand() % tasks.size();
// 向当前子进程的管道写端写入4字节的cmdcode
write(rchannels[which]._cmdfd, &cmdcode, sizeof(cmdcode));
// 轮询切换子进程(取模避免下标越界)
which++;
which = which % rchannels.size();
sleep(1); // 休眠1秒,模拟任务分发间隔
}
}
- 轮询分发:
which从 0 到 9 循环,依次给 10 个子进程发任务,实现 “负载均衡”; - 随机任务:
rand() % tasks.size()生成 0-3 的随机数,随机选择任务; - 核心操作:
write(rchannels[which]._cmdfd, &cmdcode, sizeof(cmdcode))→ 向指定子进程的管道写端写入任务指令。
7. QuitPorcess:清理资源,回收子进程
void QuitPorcess(const vector<channel>& rchannels)
{
for(auto& c : rchannels)
{
close(c._cmdfd); // 关闭管道写端,触发子进程read返回0
waitpid(c._slaverid, nullptr, 0); // 阻塞回收子进程
cout << c._name << " is recycle" << endl;
}
}
- 关闭写端:父进程关闭所有管道写端,子进程的
read返回 0,退出任务循环; - 回收子进程:
waitpid阻塞等待子进程退出,避免僵尸进程; - 两种写法:可以先批量关闭所有写端,再批量回收子进程(效果相同),核心是 “先关写端,再回收”。
8. main函数:程序入口,串联所有逻辑
int main()
{
LoadTask(tasks); // 步骤1:装载任务到任务集
srand((unsigned int)time(nullptr)); // 步骤2:设置随机数种子
vector<channel> channels; // 步骤3:创建通道容器
InitPorcess(&channels); // 步骤4:创建子进程+管道
ControlPorcess(channels); // 步骤5:分发任务
QuitPorcess(channels); // 步骤6:清理资源
return 0;
}
- 流程清晰:装载任务 → 初始化随机数 → 创建子进程 → 分发任务 → 清理资源;
srand((unsigned int)time(nullptr)):设置随机数种子,保证每次运行的随机任务不同(否则rand会生成固定序列)。
三、核心设计要点总结
- 多进程管道通信的核心:为每个子进程单独创建管道,通过
fork继承 fd,父写子读实现单向通信; - fd 管理的关键:子进程必须关闭继承的旧 fd,否则会导致管道写端无法真正关闭;
- 重定向技巧:用
dup2把管道读端重定向到标准输入,简化子进程的读指令逻辑; - 任务分发逻辑:轮询 + 随机任务,实现子进程的负载均衡;
- 资源回收:先关闭管道写端触发子进程退出,再用
waitpid回收子进程,避免僵尸进程。
四、代码执行流程(简化版)
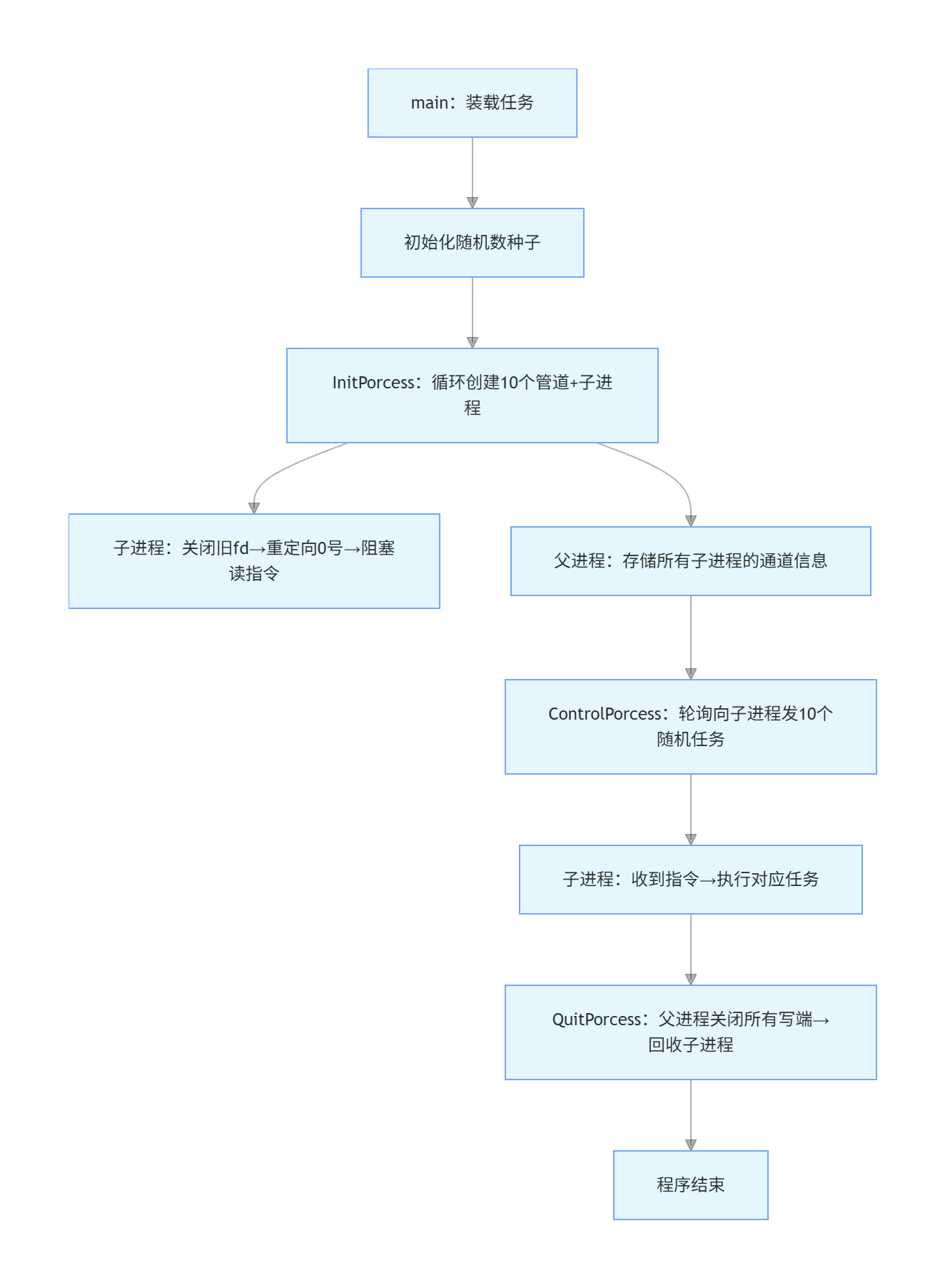
五、管道的 4 种核心情况
- 读写端正常,管道为空:读端执行读操作时,管道中没有数据可供读取,因此读端会进入阻塞状态,等待数据写入。
- 读写端正常,管道被写满:写端执行写操作时,管道的容量已被占满,没有剩余空间,因此写端会进入阻塞状态,等待读端读取数据以腾出空间。
- 读端正常,写端关闭:写端关闭后,管道中剩余的数据会被读端依次读完。当数据全部读完后,读端会读到返回值
0,这表示已到达管道的文件结尾(EOF),读操作不会再阻塞,而是正常结束。 - 写端正常写入,读端关闭:读端已经关闭,写端继续向管道写入数据是无意义的。此时操作系统会向写进程发送
SIGPIPE信号,默认情况下会终止该写进程。
命名管道的原理及指令
一、命名管道(FIFO)的核心概念
命名管道(也叫 FIFO,First In First Out)是 Linux 下一种特殊的进程间通信(IPC)机制,它在文件系统中拥有一个可见的文件名(如示例中的myfifo),但本质上和匿名管道一样,是内核维护的内存级缓冲区,不占用磁盘存储空间。
二、mkfifo myfifo 命令解析
mkfifo 是 Linux 中创建命名管道的专用命令:
- 执行
mkfifo myfifo后,系统会在当前目录创建一个名为myfifo的特殊文件; - 从
ll输出可以看到,文件权限位以p开头(prw-rw-r--),这是管道文件的专属标识,区别于普通文件(-)、目录(d)等; - 这个文件只是一个 “入口标记”,本身不存储数据,仅用于让不同进程通过路径名找到同一个内核缓冲区。
三、为什么有名管道的大小一直是 0?
从 ll 输出可以看到,myfifo 的大小始终是 0,这是因为:
- 命名管道的数据存储在内核的内存缓冲区中,而非磁盘文件中;
- 文件系统中显示的大小,只是这个 “入口标记” 的元数据大小,而非管道中实际传输的数据量;
- 当向管道写入数据时,数据直接进入内核缓冲区,不会写入磁盘,因此文件大小始终为 0。
四、底层原理:与匿名管道的异同
相同点
- 本质都是内核维护的环形缓冲区,数据从写端写入,读端读出,遵循 “先进先出” 的顺序;
- 都是半双工通信(同一时间只能单向传输数据);
- 读写操作会阻塞:写端写入时若无读端打开,会阻塞等待;读端读取时若无数据,也会阻塞等待。
不同点
| 特性 | 匿名管道(pipe) | 命名管道(FIFO) |
|---|---|---|
| 文件名 | 无,仅通过文件描述符(fd)标识 | 有,在文件系统中存在可见文件名 |
| 通信范围 | 仅支持有血缘关系的进程(父子、兄弟等) | 支持无血缘关系的任意进程 |
| 生命周期 | 随进程退出而销毁,内核自动释放 | 手动创建后,除非删除,否则一直存在 |
五、无血缘进程如何通过命名管道通信?
两个无血缘关系的进程(如两个独立启动的程序)能通过同一个命名管道通信,核心原因是:
- 路径 + 文件名的唯一性:在 Linux 文件系统中,每个文件的路径(如
/home/ranjiaju/test/learning-linux/Naming_Pipeline/myfifo)是唯一的; - 当进程 A 打开这个路径时,内核会创建一个管道缓冲区;
- 当进程 B 打开完全相同的路径时,内核会识别到这是同一个 FIFO,让进程 B 共享同一个内核缓冲区;
- 这样,进程 A 的写端和进程 B 的读端就会指向同一个缓冲区,从而实现跨进程通信。
六、结合示例操作的流程解析

- 左侧终端:执行
echo "hello mkfifo" >> myfifo向管道写入数据,此时写端会阻塞,等待读端打开管道; - 右侧终端:执行
cat myfifo打开管道读端,内核将左侧写入的数据从缓冲区读出,输出hello mkfifo; - 左侧的
echo命令完成,管道缓冲区清空,两个进程的通信结束。
通过命名管道实现通信
comm.hpp
#pragma once // 防止头文件重复包含
// Linux系统/标准库头文件:涵盖进程/文件/管道/错误处理等核心功能
#include <iostream> // 输入输出流(cout)
#include <vector> // 容器(本例未使用,预留)
#include <time.h> // 时间函数(本例未使用,预留)
#include <errno.h> // 错误码定义(perror依赖)
#include <unistd.h> // Linux系统调用(unlink/read/write/close等)
#include <stdlib.h> // 通用函数(exit)
#include <string.h> // 字符串操作(本例未使用,预留)
#include <stdio.h> // 标准输入输出(perror)
#include <sys/types.h> // 系统类型定义(pid_t等)
#include <sys/wait.h> // 进程等待(本例未使用,预留)
#include <sys/stat.h> // 文件状态/权限(mkfifo依赖)
#include <string> // C++字符串类
#include <fcntl.h> // 文件打开选项(O_RDONLY/O_WRONLY等)
using namespace std; // 简化std::前缀
// 宏定义:命名管道的绝对路径(核心!文件系统中唯一标识管道)
// 所有进程通过该路径打开同一个命名管道,实现无血缘通信
#define FIFO_FILE "/home/ranjiaju/test/learning-linux/Naming_Pipeline/myfifo"
// 宏定义:命名管道的访问权限(0664)
// 0:八进制标识;664:所有者/组可读可写(rw),其他用户只读(r)
#define MODE 0664
// 枚举错误码:统一管理管道操作的错误类型,便于定位问题
enum
{
FIFO_CREATE_ERR = 1, // 创建命名管道失败的退出码
FIFO_DELETE_ERR, // 销毁命名管道失败的退出码
FIFO_OPEN_ERR, // 打开命名管道失败的退出码
FIFO_READ_ERR // 读取命名管道失败的退出码
};
// Init类:基于RAII(资源获取即初始化)机制,自动管理命名管道生命周期
// 构造函数创建管道,析构函数销毁管道,无需手动调用mkfifo/unlink
class Init
{
public:
// 构造函数:程序运行时自动创建命名管道
Init()
{
// =================创建命名管道核心调用=================
// mkfifo(管道路径, 权限):成功返回0,失败返回-1
// 若管道已存在,会报错(保证管道是本次运行创建的)
int n = mkfifo(FIFO_FILE, MODE);
// 判断创建是否失败
if (n == -1)
{
perror("mkfifo"); // 打印具体错误原因(如文件已存在、权限不足)
exit(FIFO_CREATE_ERR); // 以指定错误码退出程序
}
}
// 析构函数:程序退出时自动销毁命名管道
~Init()
{
// =================销毁命名管道核心调用=================
// unlink(文件路径):删除文件系统中的管道入口(内核缓冲区随进程退出释放)
// 成功返回0,失败返回-1(如管道不存在、权限不足)
int n = unlink(FIFO_FILE);
// 判断销毁是否失败
if (n == -1)
{
perror("unlink"); // 打印销毁失败原因
exit(FIFO_DELETE_ERR); // 以指定错误码退出程序
}
}
};server.cc
#include"comm.hpp" // 包含公共常量、错误码、Init类定义
// server角色:命名管道的管理方(创建/销毁)+ 数据读取方
int main()
{
// 核心:创建Init对象,触发构造函数→自动创建命名管道
// 程序退出时,析构函数自动调用→销毁命名管道
Init it;
// =================打开命名管道(只读模式)=================
// open(管道路径, 打开模式):
// - O_RDONLY:只读模式打开,**会阻塞**直到有进程以写模式打开该管道
// - 成功返回文件描述符(fd),失败返回-1
int fd = open(FIFO_FILE, O_RDONLY);
// 注释:这里的阻塞是命名管道的核心特性——读端必须等写端打开,反之亦然
// 判断管道是否打开失败
if(fd < 0)
{
perror("open"); // 打印打开失败原因(如路径不存在、权限不足)
exit(FIFO_OPEN_ERR); // 以指定错误码退出
}
// =================开始通信(循环读取客户端数据)=================
// 服务端持续读取,客户端持续写入,直到客户端关闭写端
while(true)
{
char buffer[1024] = {0}; // 数据缓冲区,初始化为0(避免脏数据)
// read(文件描述符, 缓冲区, 缓冲区大小):
// - 成功:返回读取的字节数(n>0);
// - 写端关闭且无数据:返回0(n==0);
// - 失败:返回-1(n<0)
int x = read(fd, buffer, sizeof(buffer));
// 情况1:读取到有效数据
if(x > 0)
{
buffer[x] = 0; // 手动添加字符串结束符(read不自动补'\0')
cout << "client say# " << buffer << endl; // 打印客户端发送的内容
}
// 情况2:客户端关闭写端(read返回0),退出循环
else if(x == 0)
{
break;
}
// 情况3:读取失败(如管道异常)
else
{
perror("read"); // 打印读取失败原因
exit(FIFO_READ_ERR); // 以指定错误码退出
}
}
// 关闭文件描述符,释放资源(规范操作)
close(fd);
return 0;
// 程序退出→Init对象析构→自动调用unlink销毁命名管道
}client.cc
#include"comm.hpp" // 包含公共常量、错误码定义
// client角色:命名管道的数据写入方(无需创建/销毁管道,由server负责)
int main()
{
// =================打开命名管道(只写模式)=================
// open(管道路径, O_WRONLY):
// - O_WRONLY:只写模式打开,**会阻塞**直到有进程以读模式打开该管道
// - 成功返回文件描述符,失败返回-1
int fd = open(FIFO_FILE, O_WRONLY);
// 判断管道是否打开失败
if(fd < 0)
{
perror("open"); // 打印打开失败原因
exit(FIFO_OPEN_ERR); // 以指定错误码退出
}
// =================开始通信(循环写入数据)=================
string line; // 存储用户输入的字符串
while(true)
{
cout << "Please Enter@ "; // 提示用户输入
// getline(cin, line):读取用户输入的一行内容(包含空格,区别于cin>>)
getline(cin, line);
// write(文件描述符, 数据地址, 数据长度):
// - 成功:返回写入的字节数;失败:返回-1
// 把用户输入的内容写入命名管道,服务端会读取该数据
write(fd, line.c_str(), line.size());
}
// 关闭文件描述符(本例while(true)不会执行到这里,仅作规范)
close(fd);
return 0;
}一、代码整体功能总结
这份代码是Linux 下无血缘关系进程通过命名管道(FIFO)实现通信的完整示例,核心分工清晰:
comm.hpp:封装公共常量(管道唯一路径、权限)、错误码、基于 RAII 的管道生命周期管理类(自动创建 / 销毁管道),是服务端和客户端的公共依赖;server.cc(服务端):作为管道的 “管理方 + 读端”,自动创建管道→以只读模式打开(阻塞等待客户端连接)→循环读取客户端写入的数据→程序退出时自动销毁管道;client.cc(客户端):作为管道的 “写端”,以只写模式打开(阻塞等待服务端就绪)→循环读取用户输入并写入管道→数据实时传输给服务端。
代码完整体现了命名管道的核心特性:文件系统可见的唯一路径(实现无血缘通信)+ 内核内存缓冲区(无磁盘存储)+ 双向阻塞(保证通信双方就绪)。
二、分模块详细解释
1. comm.hpp:公共层(核心封装)
这一层解决了 “管道标识统一、生命周期自动管理、错误码标准化” 三大核心问题,是服务端和客户端的基础。
(1)宏定义:管道的核心标识与权限
// 命名管道的绝对路径(文件系统中唯一,无血缘通信的核心)
#define FIFO_FILE "/home/ranjiaju/test/learning-linux/Naming_Pipeline/myfifo"
// 管道权限:八进制0664(所有者/组可读可写,其他用户只读)
#define MODE 0664
- 绝对路径的关键:
FIFO_FILE是文件系统中唯一的标识,服务端和客户端通过这个路径打开的是同一个内核管道缓冲区(而非磁盘文件),这是无血缘进程能通信的根本原因; - 权限 0664:保证同一用户 / 组下的服务端和客户端都能读写管道,避免因权限不足导致打开失败。
(2)枚举错误码:标准化错误退出
enum
{
FIFO_CREATE_ERR = 1, // 创建管道失败的退出码
FIFO_DELETE_ERR, // 销毁管道失败的退出码
FIFO_OPEN_ERR, // 打开管道失败的退出码
FIFO_READ_ERR // 读取管道失败的退出码
};
- 用枚举替代 “魔法数字”,让错误码有明确含义(比如退出码为 1→创建失败,2→销毁失败),调试时能快速定位问题类型。
(3)Init 类:RAII 机制自动管理管道生命周期(核心设计)
class Init
{
public:
// 构造函数:程序启动时自动创建命名管道
Init()
{
int n = mkfifo(FIFO_FILE, MODE); // 创建管道入口文件
if (n == -1) { perror("mkfifo"); exit(FIFO_CREATE_ERR); }
}
// 析构函数:程序退出时自动销毁命名管道
~Init()
{
int n = unlink(FIFO_FILE); // 删除管道入口文件
if (n == -1) { perror("unlink"); exit(FIFO_DELETE_ERR); }
}
};
- RAII(资源获取即初始化):C++ 的核心资源管理机制,构造函数创建资源,析构函数释放资源,无需手动调用
mkfifo/unlink,避免漏销毁管道导致残留; mkfifo解析:- 作用:在文件系统中创建名为
myfifo的 “入口文件”(类型为p,大小为 0),但这个文件仅作为标识,数据实际存储在内核内存缓冲区; - 失败场景:管道已存在(上一次程序异常退出未销毁)、目录无写权限,
perror("mkfifo")会打印具体错误原因;
- 作用:在文件系统中创建名为
unlink解析:- 作用:删除文件系统中的
myfifo入口文件,内核缓冲区会在所有进程关闭管道后自动释放; - 必要性:若不销毁,下次运行
mkfifo会报错 “文件已存在”,保证每次运行都是全新的管道。
- 作用:删除文件系统中的
2. server.cc:服务端(管道管理 + 数据读取)
服务端是管道的创建者和读端,核心逻辑是 “等客户端连接→读数据→退出销毁管道”。
(1)创建 Init 对象:自动创建管道
Init it; // 构造函数触发mkfifo,创建myfifo文件
- 执行这行代码后,文件系统中会出现
myfifo文件(权限 0664,类型p,大小 0),但无数据存储(数据在内存)。
(2)打开管道(只读模式,阻塞特性)
int fd = open(FIFO_FILE, O_RDONLY);
if(fd < 0) { perror("open"); exit(FIFO_OPEN_ERR); }
open(FIFO_FILE, O_RDONLY)的核心特性:- 阻塞:若此时无客户端以
O_WRONLY打开管道,服务端会阻塞在open调用处,直到客户端启动(命名管道的 “同步特性”,保证通信双方就绪); - 成功返回文件描述符(fd),后续通过 fd 操作管道;
- 失败场景:管道不存在(Init 创建失败)、权限不足(比如客户端创建的管道权限为 0600)。
- 阻塞:若此时无客户端以
(3)循环读取管道数据
while(true)
{
char buffer[1024] = {0}; // 初始化缓冲区,避免脏数据
int x = read(fd, buffer, sizeof(buffer));
if(x > 0) // 读取到有效数据
{
buffer[x] = 0; // 手动加字符串结束符(read只读字节,不补'\0')
cout << "client say# " << buffer << endl;
}
else if(x == 0) // 客户端关闭写端,read返回0
{
break;
}
else // 读取失败(如管道异常)
{
perror("read"); exit(FIFO_READ_ERR);
}
}
close(fd); // 关闭文件描述符,释放资源
read的核心逻辑:- 阻塞读:若管道中无数据,
read会阻塞,直到客户端写入数据; x>0:读取到x字节数据,必须手动加buffer[x] = 0(否则cout打印会乱码,因为read不处理字符串结束符);x==0:所有写端关闭(客户端退出),服务端退出循环;x<0:读取失败(如管道被破坏),直接退出程序。
- 阻塞读:若管道中无数据,
(4)程序退出:自动销毁管道
- 服务端退出时,
Init对象it析构→调用~Init()→执行unlink(FIFO_FILE)→删除文件系统中的myfifo,完成资源清理。
3. client.cc:客户端(数据写入)
客户端仅作为管道的写端,无需管理管道生命周期,核心逻辑是 “打开管道→写数据”。
(1)打开管道(只写模式,阻塞特性)
int fd = open(FIFO_FILE, O_WRONLY);
if(fd < 0) { perror("open"); exit(FIFO_OPEN_ERR); }
open(FIFO_FILE, O_WRONLY)的核心特性:- 阻塞:若服务端未以
O_RDONLY打开管道,客户端会阻塞在open处,直到服务端启动(命名管道的双向阻塞,保证通信双方都就绪)。
- 阻塞:若服务端未以
(2)循环写入用户输入数据运行
string line;
while(true)
{
cout << "Please Enter@ ";
getline(cin, line); // 读取用户输入(支持空格,区别于cin>>)
write(fd, line.c_str(), line.size()); // 写入管道内核缓冲区
}
close(fd); // 本例while(true)不会执行到,仅作规范
getline(cin, line):读取用户输入的一行内容(包括空格),更符合交互需求(cin>>line会在空格处停止);write的核心逻辑:- 把用户输入的字符串写入内核管道缓冲区,服务端的
read会立即读取到; - 若管道缓冲区满(默认几 KB),
write会阻塞,直到服务端读取数据腾出空间;
- 把用户输入的字符串写入内核管道缓冲区,服务端的
- 客户端退出:用户按
Ctrl+C终止程序→写端关闭→服务端read返回 0→服务端退出循环并销毁管道。
三、核心设计亮点与关键细节
1. RAII 机制的优势
- 自动管理管道生命周期:即使程序异常退出(如
Ctrl+C),Init的析构函数仍会执行(C++ 特性),避免管道残留导致下次运行报错; - 无需手动调用
mkfifo/unlink,降低人为操作失误的风险。
2. 命名管道核心特性的体现
- 路径唯一性:
FIFO_FILE是绝对路径,保证服务端和客户端打开的是同一个内核缓冲区,实现无血缘进程通信; - 内存级文件:所有数据存储在内核缓冲区,文件系统中的
myfifo大小始终为 0,不占用磁盘空间; - 双向阻塞:
open的阻塞特性保证通信双方都就绪后才开始传输数据,read/write的阻塞特性实现数据的实时传输。
3. 错误处理的规范性
- 每个系统调用(
mkfifo/open/read/write/unlink)都做了错误判断; - 用
perror打印具体错误原因(如mkfifo: File exists→管道残留,open: Permission denied→权限不足),便于调试; - 标准化错误码退出,快速定位问题类型。
四、代码执行流程(实操视角)
- 启动服务端:
./server→Init构造创建myfifo→open(O_RDONLY)阻塞,等待客户端; - 启动客户端:
./client→open(O_WRONLY)→阻塞解除(双方就绪); - 客户端输入:比如输入
hello fifo→write写入内核缓冲区→服务端read读取→打印client say# hello fifo; - 客户端退出:按
Ctrl+C→写端关闭→服务端read返回 0→退出循环→close(fd)→Init析构删除myfifo→服务端退出。
五、核心总结
- 命名管道通信的核心:文件系统唯一路径(标识)+ 内核内存缓冲区(数据存储),突破了匿名管道仅支持血缘进程通信的限制;
- 代码核心设计:用 RAII 自动管理管道生命周期,避免手动操作的漏销毁问题;
- 关键特性:
open的双向阻塞保证通信双方就绪,read/write的阻塞特性实现数据实时传输; - 错误处理:每个系统调用都做错误判断 +
perror打印原因,标准化错误码便于调试。
设计一个简易版本的日志类
log.hpp
#pragma once // 防止头文件重复包含(替代传统的#ifndef...#define...#endif)
// 标准库/系统头文件
#include <iostream> // 标准输入输出流(cout,用于屏幕打印日志)
#include <stdio.h> // 标准输入输出(snprintf/vsnprintf等格式化函数)
#include <string> // C++字符串类(处理日志路径/文件名)
#include <time.h> // 时间函数(获取当前时间,格式化日志时间戳)
#include <stdarg.h> // 可变参数处理(va_list/va_start等,支持自定义日志内容)
#include <sys/types.h> // 系统类型定义(pid_t/off_t等,文件操作需用)
#include <sys/wait.h> // 进程等待(本例未用到,预留)
#include <sys/stat.h> // 文件状态(mkdir/stat等,处理日志目录)
#include <fcntl.h> // 文件控制(open函数的标志位,如O_WRONLY/O_CREAT等)
#include <unistd.h> // Linux系统调用(close/write等文件操作)
#include "comm.hpp" // 自定义公共头文件(本例未用到,预留)
using namespace std; // 简化std::前缀的使用
// 宏定义:日志缓冲区大小(存储格式化后的日志内容)
#define SIZE 1024
// 宏定义:默认日志文件名(单文件模式下的文件名)
#define LogFile "log.txt"
// ==================== 日志等级枚举(区分不同严重程度的日志) ====================
enum
{
Info, // 信息级:普通运行信息(如"程序启动成功")
Debug, // 调试级:开发调试信息(如"函数执行到某一步")
Warning, // 警告级:非致命问题(如"配置项未设置,使用默认值")
Error, // 错误级:可恢复错误(如"文件读取失败,重试中")
Fatal // 致命级:不可恢复错误(如"内存分配失败,程序退出")
};
// ==================== 日志输出去向枚举(控制日志打印位置) ====================
enum
{
Screen = 1, // 输出到屏幕(cout)
Onefile, // 输出到单个文件(log.txt)
Classfile // 按日志等级分文件输出(如log.txt.Info、log.txt.Error)
};
// ==================== 日志类:封装日志格式化、输出逻辑 ====================
class Log
{
public:
// ==================== 构造函数:初始化日志默认配置 ====================
Log()
{
_printMethod = Screen; // 默认输出方式:打印到屏幕
_path = "./log/"; // 日志文件存储路径:当前目录下的log文件夹(文件输出模式下生效)
}
// ==================== 自定义日志输出方式 ====================
// 参数method:日志输出去向(Screen/Onefile/Classfile)
void Enable(int method)
{
_printMethod = method; // 修改当前日志输出方式
}
// ==================== 日志等级转字符串:便于日志格式化输出 ====================
// 参数level:日志等级枚举值(Info/Debug等)
// 返回值:对应等级的字符串(如Info→"Info")
string levelToString(int level)
{
switch (level)
{
case Info:
return "Info";
case Debug:
return "Debug";
case Warning:
return "Warning";
case Error:
return "Error";
case Fatal:
return "Fatal";
default:
return "None"; // 未知等级
}
}
// ==================== 重载()运算符:让Log对象像函数一样调用(核心日志格式化) ====================
// 参数1 level:日志等级(Info/Debug等)
// 参数2 format:日志内容格式化字符串(如"用户%d登录失败,IP:%s")
// 参数3 ...:可变参数(匹配format中的占位符)
void operator()(int level, const char *format, ...)
{
// ------------- 第一步:格式化日志头部(等级+时间戳) -------------
char leftbuffer[SIZE] = {0}; // 存储日志头部(等级+时间)
time_t t = time(nullptr); // 获取当前时间戳(秒数)
struct tm *ctime = localtime(&t); // 转换为本地时间结构体(年/月/日/时/分/秒)
// 格式化日志头部:[等级] [年/月/日-时:分:秒]
snprintf(leftbuffer, sizeof(leftbuffer), "[%s] [%d/%d/%d-%d:%d:%d]",
levelToString(level).c_str(), // 日志等级字符串
ctime->tm_year + 1900, // 年(tm_year是从1900开始的偏移)
ctime->tm_mon + 1, // 月(tm_mon从0开始,+1为实际月份)
ctime->tm_mday, // 日
ctime->tm_hour, // 时
ctime->tm_min, // 分
ctime->tm_sec); // 秒
// ------------- 第二步:格式化用户自定义日志内容(可变参数) -------------
va_list s; // 可变参数列表
va_start(s, format); // 初始化可变参数列表,指向format后的第一个参数
char rightbuffer[SIZE] = {0}; // 存储用户自定义日志内容
// 格式化可变参数:将format和可变参数拼接为字符串(安全版sprintf)
vsnprintf(rightbuffer, sizeof(rightbuffer), format, s);
va_end(s); // 释放可变参数列表
// ------------- 第三步:拼接日志头部+用户内容 -------------
char logtxt[SIZE * 2] = {0}; // 存储完整日志内容
snprintf(logtxt, sizeof(logtxt), "%s %s\n", leftbuffer, rightbuffer);
// ------------- 第四步:输出日志(屏幕/文件) -------------
printLog(level, logtxt);
}
// ==================== 输出单个文件:将日志写入指定文件 ====================
// 参数1 logname:文件名(如log.txt)
// 参数2 rlogtxt:完整的日志内容
void printOneFile(const string &logname, const string &rlogtxt)
{
// 拼接完整文件路径:日志存储路径 + 文件名(如./log/log.txt)
string _logname = _path + logname;
// 打开文件:
// O_WRONLY:只写模式;O_CREAT:文件不存在则创建;O_APPEND:追加写入(避免覆盖旧日志)
// 0666:文件权限(所有用户可读可写,执行权限关闭)
int fd = open(_logname.c_str(), O_WRONLY | O_CREAT | O_APPEND, 0666);
if (fd < 0) // 文件打开失败,直接退出程序
exit(1);
// 写入日志内容到文件
write(fd, rlogtxt.c_str(), rlogtxt.size());
close(fd); // 关闭文件描述符,避免泄漏
}
// ==================== 按等级分文件输出:不同等级日志写入不同文件 ====================
// 参数1 level:日志等级(用于拼接文件名)
// 参数2 rlogtxt:完整的日志内容
void printClassFile(int level, const string &rlogtxt)
{
// 拼接等级专属文件名:log.txt + . + 等级字符串(如log.txt.Info)
string filename = LogFile;
filename += ".";
filename += levelToString(level);
// 调用单文件输出函数,写入等级专属文件
printOneFile(filename, rlogtxt);
}
// ==================== 日志输出总入口:根据输出方式选择打印位置 ====================
// 参数1 level:日志等级(分文件模式下需要)
// 参数2 logtxt:完整的日志内容
void printLog(int level, string logtxt)
{
switch (_printMethod)
{
case Screen:
// 输出到屏幕(cout)
cout << logtxt << endl;
break;
case Onefile:
// 输出到单个文件(log.txt)
printOneFile(LogFile, logtxt);
break;
case Classfile:
// 按等级分文件输出
printClassFile(level, logtxt);
break;
default:
// 未知输出方式,不处理
break;
}
}
// ==================== 析构函数 ====================
// 无动态分配资源(如堆内存/打开的文件描述符),空实现
~Log()
{
}
private:
int _printMethod; // 当前日志输出方式(Screen/Onefile/Classfile)
string _path; // 日志文件存储路径(文件输出模式下生效)
};测试Log类
// 引入公共头文件(包含FIFO文件名、错误码定义、系统头文件等)
#include"comm.hpp"
// 引入日志类头文件(日志格式化、输出逻辑)
#include"log.hpp"
// 程序功能:命名管道(FIFO)服务器端
// 核心逻辑:创建/打开命名管道,阻塞等待客户端连接,读取客户端发送的数据,通过日志记录运行状态
int main()
{
// 初始化对象(创建命名管道、初始化运行环境等,具体逻辑在comm.hpp的Init类中)
Init it;
// 创建日志对象(用于记录服务器运行日志)
Log log;
// 设置日志输出方式:按日志等级分文件输出(如log.txt.Info、log.txt.Fatal)
log.Enable(Classfile);
// ================= 第一步:打开命名管道(FIFO) =================
// 以只读模式打开命名管道:
// 关键特性:O_RDONLY模式下,open会**阻塞等待**客户端(写端)打开该FIFO后才返回
// FIFO_FILE:在comm.hpp中定义的命名管道文件名(如"./fifo")
int fd = open(FIFO_FILE, O_RDONLY);
// 判断命名管道是否打开失败
if(fd < 0)
{
// 记录致命错误日志:包含错误描述、错误码、当前进程PID
// strerror(errno):将系统错误码转换为可读的字符串(如"File not found")
// errno:系统全局变量,存储最近一次系统调用的错误码
// getpid():获取当前进程的PID(便于定位哪个进程出错)
log(Fatal, "FIFO_OPEN_ERR, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
// 退出程序:FIFO_OPEN_ERR是comm.hpp中定义的错误码(标识管道打开失败)
exit(FIFO_OPEN_ERR);
}
// 测试日志:验证不同等级日志的输出(管道打开成功)
log(Info, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
log(Debug, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
log(Warning, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
log(Error, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
log(Fatal, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
// ================= 第二步:与客户端通信(循环读取数据) =================
// 通信规则:服务器只读、客户端只写,服务器阻塞读取客户端发送的数据
while(true)
{
// 数据缓冲区:存储从管道读取的客户端数据
char buffer[1024] = {0};
// 从命名管道读取数据:
// 返回值x:
// - x > 0:成功读取x个字节;
// - x == 0:客户端关闭写端(退出);
// - x < 0:读取失败(如管道异常);
int x = read(fd, buffer, sizeof(buffer));
// 情况1:成功读取客户端数据
if(x > 0)
{
// 在读取的字节末尾添加字符串结束符(避免乱码)
buffer[x] = 0;
// 打印客户端发送的内容到屏幕(调试用)
cout << "client say# " << buffer << endl;
}
// 情况2:客户端关闭写端(退出)
else if(x == 0)
{
// 记录调试日志:客户端退出,服务器也退出循环
log(Debug, " client quit, me too!, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
// 退出循环,结束通信
break;
}
// 情况3:读取数据失败(致命错误)
else
{
// 记录致命错误日志:管道读取失败
log(Fatal, "FIFO_READ_ERR, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
// 退出程序:FIFO_READ_ERR是comm.hpp中定义的错误码(标识管道读取失败)
exit(FIFO_READ_ERR);
}
}
// 第三步:关闭命名管道文件描述符(释放资源)
close(fd);
return 0;
}一、Log 类代码详细解释
Log类是一个通用日志工具类,核心目标是:封装日志的 “格式化(时间戳 + 等级 + 自定义内容)” 和 “多渠道输出(屏幕 / 单文件 / 分等级文件)”,支持可变参数的日志内容,让日志调用像函数一样简洁。
1. 前置枚举定义:标准化日志等级和输出去向
// 日志等级枚举:区分日志的严重程度,便于筛选/定位问题
enum
{
Info, // 普通运行信息(如"程序启动成功")
Debug, // 开发调试信息(如"函数执行到某一步")
Warning, // 非致命问题(如"配置项未设置,用默认值")
Error, // 可恢复错误(如"文件读取失败,重试")
Fatal // 致命错误(如"管道打开失败,程序退出")
};
// 日志输出去向枚举:控制日志打印位置,灵活切换
enum
{
Screen = 1, // 输出到屏幕(cout)
Onefile, // 输出到单个文件(log.txt)
Classfile // 按等级分文件(如log.txt.Info、log.txt.Error)
};
- 枚举的价值:用 “语义化常量” 替代魔法数字,比如
log(Info, ...)比log(0, ...)更易读,也避免传参错误(比如传 6 会被识别为None等级)。
2. 成员变量:存储日志核心配置
private:
int _printMethod; // 当前日志输出方式(默认Screen)
string _path; // 日志文件存储路径(默认./log/,文件输出模式生效)
_printMethod:决定日志最终输出到哪里,通过Enable函数修改;_path:文件输出时的根路径,比如输出到./log/log.txt,而非当前目录,便于日志文件集中管理。
3. 构造函数:初始化默认配置
Log()
{
_printMethod = Screen; // 默认输出到屏幕(调试阶段常用)
_path = "./log/"; // 默认日志文件存储在当前目录的log文件夹
}
- 无参构造:开箱即用,默认满足 “屏幕输出” 的调试需求,无需手动配置。
4. Enable 函数:动态切换输出方式
void Enable(int method)
{
_printMethod = method; // 修改输出方式(如切换为分文件输出)
}
- 核心作用:运行时灵活切换日志去向,比如开发时用
Screen,生产环境用Classfile,无需修改日志调用代码。
5. levelToString:日志等级转字符串(格式化必备)
string levelToString(int level)
{
switch (level)
{
case Info: return "Info";
case Debug: return "Debug";
case Warning: return "Warning";
case Error: return "Error";
case Fatal: return "Fatal";
default: return "None";
}
}
- 作用:把枚举值(如
Info=0)转换为可读字符串(如"Info"),用于日志头部格式化(比如[Info] [2026/2/13-10:00:00])。
6. 重载 () 运算符:日志格式化核心(最关键)
这是Log类的核心函数,让Log对象可以像 “函数” 一样调用(如log(Info, "xxx")),处理可变参数并拼接完整日志内容。
void operator()(int level, const char *format, ...)
{
// 第一步:格式化日志头部(等级+时间戳)
char leftbuffer[SIZE] = {0};
time_t t = time(nullptr); // 获取当前时间戳(秒)
struct tm *ctime = localtime(&t); // 转换为本地时间(年/月/日/时/分/秒)
// 拼接头部:[等级] [年/月/日-时:分:秒]
snprintf(leftbuffer, sizeof(leftbuffer), "[%s] [%d/%d/%d-%d:%d:%d]",
levelToString(level).c_str(), // 等级字符串
ctime->tm_year + 1900, // 年(tm_year是1900年至今的偏移)
ctime->tm_mon + 1, // 月(tm_mon从0开始,+1为实际月份)
ctime->tm_mday, // 日
ctime->tm_hour, // 时
ctime->tm_min, // 分
ctime->tm_sec); // 秒
// 第二步:处理可变参数,格式化用户自定义日志内容
va_list s; // 可变参数列表(存储format后的所有参数)
va_start(s, format); // 初始化列表,指向format后的第一个参数
char rightbuffer[SIZE] = {0};
vsnprintf(rightbuffer, sizeof(rightbuffer), format, s); // 安全格式化可变参数
va_end(s); // 释放可变参数列表
// 第三步:拼接头部+用户内容,形成完整日志
char logtxt[SIZE * 2] = {0};
snprintf(logtxt, sizeof(logtxt), "%s %s\n", leftbuffer, rightbuffer);
// 第四步:输出日志(根据_printMethod选择去向)
printLog(level, logtxt);
}
关键细节解析:
- 可变参数处理:
va_list/va_start/vsnprintf/va_end是 C/C++ 处理 “不确定个数参数” 的标准方式,支持像printf一样传占位符(如%s/%d); - 时间戳格式化:
localtime把时间戳转换为人类可读的时间,注意tm_year+1900、tm_mon+1的修正(系统结构体的偏移规则); - 安全格式化:用
snprintf/vsnprintf而非sprintf,避免缓冲区溢出(指定缓冲区大小)。
7. printOneFile:单文件输出实现
void printOneFile(const string &logname, const string &rlogtxt)
{
string _logname = _path + logname; // 拼接完整路径(如./log/log.txt)
// 打开文件:只写+创建(不存在则建)+追加(不覆盖旧日志),权限0666
int fd = open(_logname.c_str(), O_WRONLY | O_CREAT | O_APPEND, 0666);
if (fd < 0) exit(1);
write(fd, rlogtxt.c_str(), rlogtxt.size()); // 写入日志
close(fd); // 关闭文件描述符,避免泄漏
}
核心要点:
- 追加模式(O_APPEND):日志是追加写入,而非覆盖,保证历史日志不丢失;
- 文件权限(0666):所有用户可读可写,避免因权限不足导致日志写入失败;
- 路径拼接:结合
_path(./log/)和文件名(log.txt),日志文件集中存储在 log 文件夹。
8. printClassFile:按等级分文件输出
void printClassFile(int level, const string &rlogtxt)
{
string filename = LogFile; // 基础文件名:log.txt
filename += ".";
filename += levelToString(level); // 拼接等级:log.txt.Info
printOneFile(filename, rlogtxt); // 调用单文件输出
}
- 作用:不同等级的日志写入不同文件,比如
Info级写入log.txt.Info,Fatal级写入log.txt.Fatal,便于后续筛选日志(比如只看错误日志)。
9. printLog:日志输出总入口
void printLog(int level, string logtxt)
{
switch (_printMethod)
{
case Screen:
cout << logtxt << endl; // 输出到屏幕
break;
case Onefile:
printOneFile(LogFile, logtxt); // 输出到log.txt
break;
case Classfile:
printClassFile(level, logtxt); // 按等级分文件
break;
default:
break;
}
}
- 核心逻辑:根据
_printMethod的值,分发到不同的输出函数,是 “单一入口 + 多实现” 的设计模式,便于扩展(比如后续加 “网络输出” 只需加 case)。
10. 析构函数:空实现
~Log() {}
- 无动态分配的资源(如堆内存、未关闭的文件描述符),因此无需额外清理。
二、server.cc 中 Log 类的使用详解
server.cc是命名管道服务端,核心业务是 “打开管道→读取客户端数据→处理异常”,Log类的作用是记录整个过程的运行状态,便于调试和问题定位。
1. 初始化 Log 对象并配置输出方式
Log log; // 创建Log对象,默认输出到屏幕
log.Enable(Classfile); // 切换为“按等级分文件输出”
- 生产环境常用
Classfile:不同等级日志分文件存储,比如Fatal级日志单独存储,便于快速定位致命错误。
2. 场景 1:管道打开失败→记录 Fatal 级日志
if(fd < 0)
{
// 日志内容:错误类型+错误描述+错误码+进程PID
log(Fatal, "FIFO_OPEN_ERR, error string: %s, error code: %d, pid: %d",
strerror(errno), errno, getpid());
exit(FIFO_OPEN_ERR);
}
- 关键参数解析:
Fatal:日志等级(致命错误,程序直接退出);strerror(errno):把系统错误码(如errno=2)转换为可读字符串(如"No such file or directory");errno:系统全局变量,存储最近一次系统调用的错误码;getpid():获取当前进程 PID,多进程场景下能定位 “哪个进程打开管道失败”;
- 输出效果:日志会写入
./log/log.txt.Fatal,内容示例:plaintext
[Fatal] [2026/2/13-10:05:00] FIFO_OPEN_ERR, error string: No such file or directory, error code: 2, pid: 12345
3. 场景 2:管道打开成功→测试不同等级日志
log(Info, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
log(Debug, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
log(Warning, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
log(Error, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
log(Fatal, "server open file done, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
- 效果:会在
./log/目录下生成 5 个文件:log.txt.Info:存储 Info 级日志;log.txt.Debug:存储 Debug 级日志;- ... 以此类推;
- 日志内容示例(Info 级):
[Info] [2026/2/13-10:06:00] server open file done, error string: Success, error code: 0, pid: 12345
4. 场景 3:客户端退出→记录 Debug 级日志
else if(x == 0)
{
log(Debug, " client quit, me too!, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
break;
}
Debug级:仅用于开发调试,记录 “客户端正常退出” 的状态,不影响程序运行。
5. 场景 4:管道读取失败→记录 Fatal 级日志
else
{
log(Fatal, "FIFO_READ_ERR, error string: %s, error code: %d, pid: %d", strerror(errno), errno, getpid());
exit(FIFO_READ_ERR);
}
- 致命错误:读取管道失败(如管道被破坏),记录日志后直接退出程序,便于后续排查根因。
三、核心总结
1. Log 类核心设计要点
- 易用性:重载
()运算符,让日志调用像printf一样简洁(log(等级, 格式化字符串, 参数)); - 灵活性:支持 3 种输出方式(屏幕 / 单文件 / 分等级文件),运行时可切换;
- 安全性:用
snprintf/vsnprintf避免缓冲区溢出,文件操作后关闭 fd; - 实用性:日志包含 “等级 + 时间戳 + 错误信息 + PID”,便于问题定位。
2. server.cc 中 Log 类的使用核心
- 按 “场景 + 严重程度” 选择日志等级:致命错误(Fatal)、调试信息(Debug)、普通信息(Info)等;
- 日志内容包含 “错误描述 + 错误码 + PID”:多维度定位问题;
- 生产环境用
Classfile输出:不同等级日志分文件,便于筛选和分析。
systemv共享内存的原理及命令
// 查看操作系统的共享内存
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ systemv]$ ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
// 释放共享内存时的命令
[ranjiaju@iZ2vc15k23y9vpuyi3tiqzZ systemv]$ ipcrm -m 对应共享内存的shmid
一、基础命令解释
1. ipcs -m:查看 System V 共享内存段
ipcs是用于查看 System V IPC(进程间通信)资源的命令,-m参数专门筛选共享内存(Shared Memory) 段。执行该命令后,输出列的具体含义如下:
key:用户级标识,可由开发者指定或自动生成,是进程创建 / 获取共享内存的 “钥匙”;shmid:内核级唯一标识符,是内核管理共享内存的核心 ID;owner:共享内存的创建者用户;perms:访问权限,格式与文件权限一致(如 644);bytes:共享内存的字节大小;nattch:当前挂接(关联)至该共享内存的进程数量,即内核层面的引用计数;status:共享内存的状态标识(如是否被标记为待删除)。
该命令执行后输出为空的情况下,表明当前系统中不存在已创建的 System V 共享内存段。
2. ipcrm -m <shmid>:删除指定的 System V 共享内存段
ipcrm是删除 System V IPC 资源的命令,-m参数指定操作对象为共享内存,其后需跟随shmid(内核级 ID),该命令的作用是向内核发送释放对应共享内存段的指令。⚠️ 注意:若该共享内存仍有进程挂接(nattch > 0),内核不会立即释放物理内存,仅将其标记为 “IPC_RMID”(待删除状态),直至所有进程解除挂接后,物理内存才会被真正回收。
二、释放共享内存使用shmid而非key的原因
核心在于key与shmid的 “层级属性” 和 “唯一性” 存在本质差异:
- key 为用户级标识,不具备全局唯一性
key是开发者在用户态指定的 32 位整数(可通过ftok()生成),存在重复可能(如不同进程使用相同参数生成相同key),也可能成为无效标识(如对应共享内存已被删除),因此内核不会将key作为管理共享内存的核心依据。 - shmid 为内核级唯一 ID,可精准定位目标资源进程调用
shmget()创建 / 获取共享内存时,内核会为该共享内存分配全局唯一的shmid,该 ID 直接对应内核中管理该共享内存的结构体,是内核识别共享内存的核心标识。 - 单一 key 可能对应多个 shmid多次调用
shmget(key, size, IPC_CREAT | 0644)且size参数不同时,内核会创建多个共享内存段,这些内存段的key相同,但shmid不同。此时仅通过key无法精准定位待删除的共享内存,必须依赖shmid。
简言之:key是进程查找共享内存的 “索引标识”,而shmid是共享内存在内核中的 “唯一身份标识”,删除操作需基于精准的内核级标识,而非可能重复的用户级标识。
三、System V 共享内存核心原理
1. 物理内存层面:内核开辟的公共内存空间
共享内存是操作系统在物理内存中划分出的连续内存区域(按内存页大小对齐),其大小由开发者通过shmget()的size参数指定,内核会按内存页大小向上取整(如页大小为 4KB 时,申请 5KB 实际分配 8KB)。该物理内存区域不归属于任何进程,由内核统一管理,是所有具备访问权限的进程均可访问的公共内存区域。
2. 虚拟内存映射:实现进程对同一物理内存的访问
进程无法直接访问物理内存,需通过 “虚拟地址→页表→物理地址” 的映射关系完成访问。两个进程通过共享内存通信的核心流程为:
- 进程调用
shmget()创建共享内存,内核分配物理内存并返回shmid; - 进程调用
shmat(shmid, NULL, 0),内核修改该进程的页表,将上述物理内存映射至进程虚拟地址空间的共享区(用户空间中栈、堆之外的内存区域),并返回映射后的虚拟地址起始值; - 另一进程通过相同
key调用shmget()获取同一shmid,再调用shmat(),内核修改该进程的页表,将同一块物理内存映射至其虚拟共享区; - 两个进程对各自虚拟地址的读写操作,本质均为对同一块物理内存的操作,以此实现数据共享。
3. 共享内存的优势:数据拷贝次数极少
与管道(命名管道 / 匿名管道)相比,共享内存的通信效率更高:
- 管道通信:进程写入数据时,数据需从用户空间拷贝至内核缓冲区;进程读取数据时,需从内核缓冲区拷贝回用户空间,总计两次数据拷贝;
- 共享内存:仅在
shmat()阶段完成内存映射(无数据拷贝),后续进程直接读写物理内存,无额外数据拷贝操作,是效率最高的 IPC 方式。
4. 挂接、解挂与内核的 “先描述、再组织” 管理机制
操作系统对共享内存的管理遵循 “先描述,再组织” 的原则:
- 描述:内核数据结构定义Linux 内核中,每个共享内存段对应一个
struct shmid_kernel结构体,核心字段包括:shm_nattch:挂接的进程数量(引用计数,对应ipcs -m输出的nattch列);shm_segsz:共享内存的字节大小;shm_key:用户级标识key;shm_pages:指向物理内存页帧的指针;shm_perm:共享内存的权限、所有者等属性信息。
- 组织:内核数据结构的管理方式所有
struct shmid_kernel结构体被内核以链表或哈希表的形式组织,内核可通过shmid快速查找对应的结构体,实现对共享内存的高效管理。 - 挂接(shmat)与解挂(shmdt)
- 挂接:进程调用
shmat()时,内核查找对应shmid_kernel结构体,将shm_nattch值加 1,并修改进程页表完成映射; - 解挂:进程调用
shmdt(addr)时,内核将shm_nattch值减 1,并删除进程页表中对应的映射关系。
- 挂接:进程调用
- 共享内存的正确释放流程① 所有使用该共享内存的进程调用
shmdt()完成解挂,直至shm_nattch值归 0;② 调用shmctl(shmid, IPC_RMID, NULL)或ipcrm -m shmid触发共享内存删除指令;③ 内核回收物理内存,并删除对应的struct shmid_kernel结构体。
总结
ipcs -m用于查看共享内存段的详细信息,ipcrm -m <shmid>用于删除共享内存,shmid作为内核级唯一标识,比用户级的key具备更高的精准性;- System V 共享内存是内核在物理内存中开辟的公共区域,进程通过页表将该区域映射至自身虚拟共享区,从而实现对同一物理内存的访问与数据共享;
- 内核通过
shmid_kernel结构体描述共享内存(包含引用计数shm_nattch),并以链表 / 哈希表形式组织管理,释放共享内存需先完成所有进程的解挂(引用计数归 0),再删除内核中的对应标识。
通过共享内存实现通信
comm.hpp
#pragma once // 头文件保护,防止重复包含(替代传统的#ifndef...#define...#endif)
#include<iostream> // 标准输入输出流(cout/cin)
#include<string.h> // C风格字符串操作(如memset等,此处暂未直接使用但预留)
#include<string> // C++ string类(用于定义ftok的路径)
#include<sys/ipc.h> // IPC(进程间通信)核心头文件(定义key_t、ftok等)
#include<sys/shm.h> // 共享内存相关系统调用头文件(shmget/shmat/shmdt/shmctl)
#include<sys/types.h> // 系统类型定义(如pid_t、key_t等)
#include<stdlib.h> // 标准库(exit函数)
#include<unistd.h> // 系统调用(sleep、fork等,此处暂未直接使用但预留)
using namespace std; // 启用std命名空间,简化cout/string等使用
// ftok函数的参数1:自定义路径(需是系统中存在的、可访问的路径)
// ftok通过"路径+项目ID"生成唯一的key,用于标识共享内存
const string pathname = "/home/ranjiaju";
// ftok函数的参数2:项目ID(非0即可,通常用16进制,保证和路径组合的唯一性)
const int proj_id = 0x1111;
// 共享内存大小:4096字节(4KB)
// 注:操作系统以4KB为单位分配共享内存,若设置4097则会分配8KB但仅能使用4097
// 因此建议按4096的倍数设置,避免内存浪费
const int size = 4096;
// 功能:生成共享内存的唯一key(System V IPC的核心标识)
// 返回值:成功返回合法key,失败终止进程
key_t GetKey()
{
// ftok:将路径和项目ID转换为唯一的key_t类型值
key_t key = ftok(pathname.c_str(), proj_id);
// 错误处理:ftok失败返回-1,打印错误信息并退出
if(key < 0)
{
perror("ftok"); // 打印ftok失败的原因(如路径不存在、权限不足)
exit(1); // 终止进程,退出码1表示key生成失败
}
return key;
}
// 功能:共享内存辅助函数(封装shmget调用,避免代码冗余)
// 参数flag:shmget的权限/创建标志(如IPC_CREAT、IPC_EXCL等)
// 返回值:成功返回共享内存标识符shmid,失败终止进程
int GetShareMemHelper(int flag)
{
key_t key = GetKey(); // 先获取唯一key
// shmget:创建/获取共享内存
// 参数1:共享内存key;参数2:内存大小;参数3:标志位(创建/权限)
int shmid = shmget(key, size, flag);
// 错误处理:shmget失败返回-1,打印错误信息并退出
if(shmid < 0)
{
perror("shmget"); // 打印shmget失败原因(如key不存在、权限不足)
exit(2); // 终止进程,退出码2表示共享内存获取/创建失败
}
return shmid;
}
// 功能:创建全新的共享内存(确保不存在则创建,存在则报错)
// 标志位说明:
// IPC_CREAT:创建共享内存;IPC_EXCL:与IPC_CREAT配合,确保创建全新的(存在则失败);
// 0666:共享内存权限(所有用户可读可写,八进制)
int CreateShm()
{
return GetShareMemHelper(IPC_CREAT | IPC_EXCL | 0666);
}
// 功能:获取已存在的共享内存(不存在则创建,存在则直接获取)
// 注:仅用IPC_CREAT,无IPC_EXCL,因此不会强制创建新的,而是复用已有共享内存
int GetShm()
{
return GetShareMemHelper(IPC_CREAT);
}processa.cc(共享内存读取端 / 消费者)
#include"comm.hpp" // 包含共享内存工具函数头文件
int main()
{
// 1. 创建全新的共享内存(若已存在则shmget报错,确保processa先启动创建内存)
int shmid = CreateShm();
// 2. 将共享内存附加到当前进程的地址空间
// shmat参数:shmid(共享内存ID)、nullptr(系统自动分配附加地址)、0(读写权限)
// 返回值:成功返回共享内存的起始地址,失败返回(void*)-1
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
// 3. 循环读取共享内存中的内容(死循环,持续监听)
while(true)
{
// 打印共享内存中的字符串(processb会写入内容)
cout << "client say@ " << shmaddr << endl;
sleep(1); // 每秒读取一次,避免高频占用CPU
}
// 以下代码因死循环无法执行,仅作规范展示:
// 4. 解除共享内存与进程的附加关系(分离)
shmdt(shmaddr);
// 5. 删除共享内存(释放系统资源)
// shmctl参数:shmid、IPC_RMID(删除指令)、nullptr(无需额外参数)
shmctl(shmid, IPC_RMID, nullptr);
return 0;
}processb.cc(共享内存写入端 / 生产者)
#include"comm.hpp" // 包含共享内存工具函数头文件
int main()
{
// 1. 获取已存在的共享内存(复用processa创建的内存,若不存在则创建)
int shmid = GetShm();
// 2. 将共享内存附加到当前进程的地址空间(与processa操作一致)
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
// 3. 循环读取用户输入并写入共享内存(死循环,持续写入)
while(true)
{
cout << "Please Enter@ "; // 提示用户输入
// fgets:读取用户输入的字符串到共享内存
// 参数:目标地址(共享内存起始地址)、最大读取长度(避免越界)、输入流(标准输入)
fgets(shmaddr, size, stdin);
}
// 以下代码因死循环无法执行,仅作规范展示:
// 4. 解除共享内存与进程的附加关系
shmdt(shmaddr);
return 0;
}一、核心系统级调用接口详解
这段代码的核心是 System V 共享内存的 5 个核心系统调用,以下逐一解释其功能、参数、返回值:
1. ftok - 生成 IPC 唯一标识 Key
key_t ftok(const char *pathname, int proj_id);
- 功能:将「文件路径 + 项目 ID」转换为唯一的
key_t类型值,作为 System V IPC(共享内存 / 消息队列 / 信号量)的全局唯一标识,让不同进程能通过这个 Key 找到同一个 IPC 资源。 - 参数:
pathname:系统中存在且可访问的文件 / 目录路径(代码中用/home/ranjiaju),ftok 会读取该文件的 inode 号作为计算依据;proj_id:项目 ID(非 0 整数,代码中用0x1111),用于区分同一路径下的不同 IPC 资源(如同一目录下的共享内存和消息队列)。
- 返回值:
- 成功:返回非负的
key_t值(唯一标识); - 失败:返回
-1,并设置errno(可通过perror打印错误,如路径不存在、权限不足)。
- 成功:返回非负的
2. shmget - 创建 / 获取共享内存
int shmget(key_t key, size_t size, int shmflg);
- 功能:根据 Key 创建新的共享内存段,或获取已存在的共享内存段的标识符(shmid)。
- 参数:
key:ftok 生成的唯一 Key,用于定位共享内存;size:共享内存大小(字节),操作系统以 4KB(页大小)为单位分配,代码中设为 4096(刚好 1 页,避免内存浪费);shmflg:标志位(权限 + 创建策略),是代码中宏的组合(见下文宏解释)。
- 返回值:
- 成功:返回非负的共享内存标识符
shmid; - 失败:返回
-1,设置errno(如 Key 不存在、权限不足、已存在但用了IPC_EXCL)。
- 成功:返回非负的共享内存标识符
3. shmat - 附加共享内存到进程地址空间
void *shmat(int shmid, const void *shmaddr, int shmflg);
- 功能:将内核中的共享内存段映射(附加)到当前进程的虚拟地址空间,让进程能像操作普通内存一样读写共享内存(这是共享内存最快的核心原因:无数据拷贝)。
- 参数:
shmid:shmget 返回的共享内存标识符;shmaddr:指定映射的起始地址,通常设为NULL(让系统自动分配,推荐做法);shmflg:映射权限,0表示读写权限,SHM_RDONLY表示只读权限。
- 返回值:
- 成功:返回共享内存在进程地址空间的起始地址(
void*,代码中转char*方便操作字符串); - 失败:返回
(void*)-1(注意不是NULL,需强转后判断)。
- 成功:返回共享内存在进程地址空间的起始地址(
4. shmdt - 分离共享内存
int shmdt(const void *shmaddr);
- 功能:将共享内存段从当前进程的地址空间中解除映射(分离),但不会删除共享内存本身。
- 参数:
shmaddr:shmat 返回的共享内存起始地址。 - 返回值:
- 成功:返回
0; - 失败:返回
-1,设置errno。
- 成功:返回
5. shmctl - 控制共享内存(如删除)
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
- 功能:对共享内存执行控制操作(删除、获取状态、修改权限等)。
- 参数:
shmid:共享内存标识符;cmd:控制命令(核心是IPC_RMID,见下文宏解释);buf:指向shmid_ds结构体的指针,执行IPC_RMID时设为NULL即可(无需传递状态)。
- 返回值:
- 成功:返回
0; - 失败:返回
-1,设置errno。
- 成功:返回
二、关键宏定义详解
代码中用到的宏是控制共享内存行为的核心,以下解释:
| 宏 | 含义与作用 |
|---|---|
IPC_CREAT |
若指定 Key 的共享内存不存在则创建,存在则直接返回其 shmid(复用已有内存)。 |
IPC_EXCL |
必须与IPC_CREAT配合使用:若内存已存在则报错,确保创建全新的共享内存。 |
IPC_RMID |
shmctl的控制命令,标记共享内存为 “待删除”,所有进程分离后释放内核资源。 |
0666 |
共享内存的访问权限(八进制):所有用户(所有者 / 组 / 其他)都有读写权限。 |
SHM_RDONLY |
(代码未用但相关)shmat的标志位,指定共享内存只读。 |
补充:
0666的权限规则和文件权限一致:6=110(读 + 写),三位分别对应所有者、所属组、其他用户。
三、代码实现逻辑拆解
代码分为 3 个部分,核心是 “封装通用逻辑 + 分角色实现读写”:
1. comm.hpp - 共享内存工具函数封装
目的:避免 processa 和 processb 重复写相同的系统调用逻辑,简化错误处理。
- 定义常量:
pathname+proj_id(保证 ftok 生成唯一 Key)、size(4096 字节共享内存); GetKey():封装 ftok,失败则打印错误并退出进程;GetShareMemHelper(flag):封装 shmget,先调用GetKey()获取 Key,再根据 flag 调用 shmget;CreateShm():调用 Helper,传入IPC_CREAT|IPC_EXCL|0666,强制创建全新内存(给 processa 用);GetShm():调用 Helper,传入IPC_CREAT,复用已有内存(给 processb 用)。
2. processa.cc(读取端 / 消费者)
执行流程(核心是 “创建 + 读取”):
1. 调用CreateShm()创建全新共享内存(若已存在则报错,保证processa先启动);
2. 调用shmat将共享内存附加到进程地址空间,得到shmaddr;
3. 死循环:每秒读取shmaddr指向的内容(打印processb写入的字符串);
4. (死循环无法执行)shmdt分离内存 + shmctl删除内存(释放内核资源)。
3. processb.cc(写入端 / 生产者)
执行流程(核心是 “复用 + 写入”):
1. 调用GetShm()获取共享内存(复用processa创建的,若不存在则自动创建);
2. 调用shmat将共享内存附加到进程地址空间,得到shmaddr;
3. 死循环:读取用户输入,用fgets写入shmaddr指向的共享内存;
4. (死循环无法执行)shmdt分离内存(无需删除,由创建者processa负责)。
四、两个进程能通信的核心关键点
两个进程能实现通信,本质是 “找到同一块内存 + 直接操作该内存”,具体有 4 个核心:
1. 唯一的 Key 标识(全局定位)
processa 和 processb 使用完全相同的 pathname(/home/ranjiaju)和 proj_id(0x1111) 调用 ftok,生成的 Key 完全一致。这个 Key 是内核中共享内存的 “身份证”,让两个进程能找到同一块共享内存。
2. 内核级的共享内存(数据共享)
共享内存是分配在内核空间的内存段,不是某个进程的私有内存。只要进程通过 shmat 将其附加到自己的地址空间,就能直接读写这块内存(这是共享内存比管道 / 消息队列快的核心:无数据拷贝)。
3. 相同的物理内存映射(地址关联)
虽然 processa 和 processb 的shmaddr(虚拟地址)可能不同,但这些虚拟地址最终会映射到同一个物理内存段(内核的共享内存)。因此 processb 写入的内容,processa 能立刻读取到。
4. 权限匹配(访问许可)
创建共享内存时设置了0666权限,确保 processb(即使不是创建者)能读写该共享内存,不会因权限问题无法访问。
总结
- 核心接口:ftok 生成唯一 Key,shmget 创建 / 获取内存,shmat 映射到进程空间,shmdt 分离,shmctl 删除;
- 关键宏:
IPC_CREAT(复用 / 创建)、IPC_EXCL(强制新建)、IPC_RMID(删除)、0666(权限); - 通信核心:两个进程通过相同 Key 找到同一块内核级共享内存,映射后直接操作同一块物理内存,实现数据共享。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)