UniReason 1.0: A Unified Reasoning Framework for World Knowledge Aligned Image Generation and Edit
这篇论文的工程落地价值很高。它证明了在统一自回归/Flow-Matching架构下,不必为了 T2I 和 Editing 维护两套复杂的控制逻辑。只要通过高质量的 Agent 合成数据流,将 Editing 作为 T2I 的 Post-generation Refinement step 融入马尔可夫链中,并通过 LLM/VLM 注入世界知识先验,就能大幅拔高模型在复杂长尾 Case 下的生成逼真
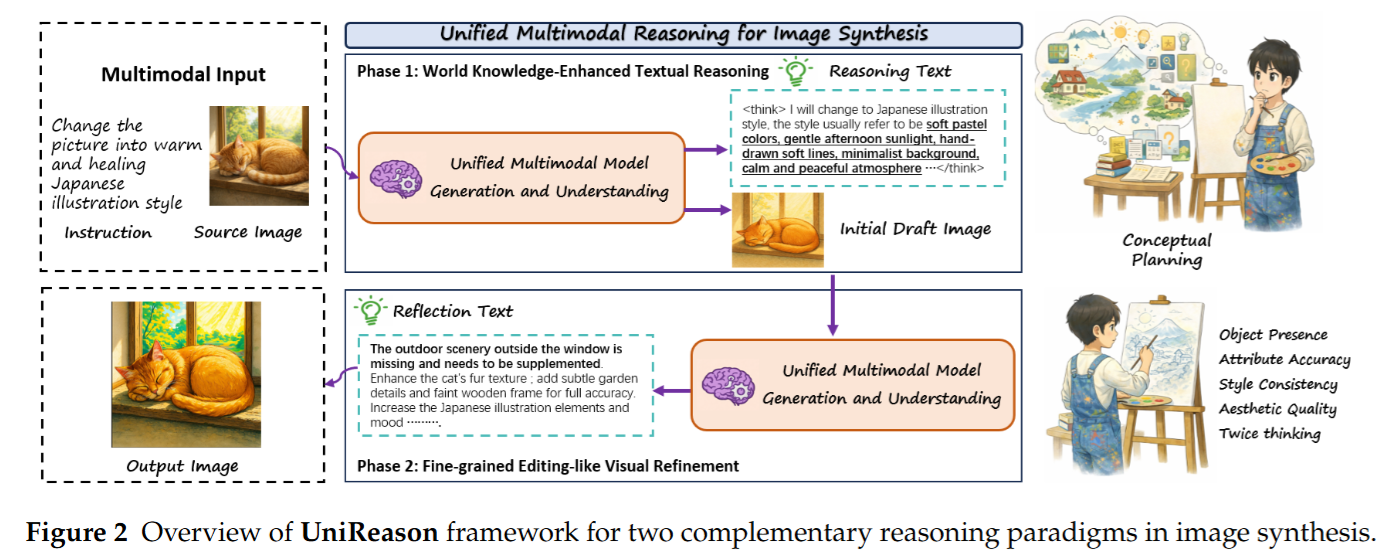
这篇由复旦大学等机构提出的 《UniReason 1.0》,本质上是在解决多模态统一模型(Unified Multimodal Models)在复杂长程逻辑和隐式世界知识对齐上的缺陷。其核心技术贡献在于:将 T2I 生成(Text-to-Image)与图像编辑(Image Editing)在架构和数据流上进行了结构性统一,提出了一种基于交错推理(Interleaved Reasoning)的“生成-反思-编辑”范式。
1. 研究动机与痛点 (Motivation)
当前的 Unified Models(如 Show-o, Janus)或采用“Reason-then-generate”范式的模型(如基于 LLM 重写 Prompt)存在两个致命限制:
- 知识鸿沟(Knowledge Gap): 现有的 CoT(思维链)主要集中在语义重组或空间布局分解(Spatial layout),而缺乏对隐式世界知识(如物理规律、文化常识、空间拓扑、因果逻辑)的推演。
- 开环生成的误差累积: 纯 T2I 是一个开环过程,缺乏视觉反馈(Visual Feedback)。而“看图找茬并修改”本质上就是图像编辑(Image Editing)任务。过去的工作将 T2I 和 Editing 割裂,导致模型无法利用 Editing 的表征能力来进行生成后的自校正(Self-correction)。
2. 核心架构与数学建模 (Formulation)
模型基于 BAGEL (采用 Mixture-of-Transformers, MoT 架构) 构建。多模态理解(文本输出)和视觉生成(图像输出)共享同一个基础模型。
- 多模态理解(Understanding Branch): 采用标准的自回归 Next-Token Prediction (NTP) 损失 Ltext\mathcal{L}_{text}Ltext。
- 多模态生成(Generation Branch): 基于 VAE Latent 空间,采用带矫正流(Rectified Flow)的 Flow-Matching 目标函数 Limage\mathcal{L}_{image}Limage。
交错推理的马尔可夫建模:
作者将推理生成定义为一个迭代过程:(Ik+1,Tk+1)=F(I≤k,T≤k,C)(I^{k+1}, T^{k+1}) = \mathcal{F}(I^{\le k}, T^{\le k}, C)(Ik+1,Tk+1)=F(I≤k,T≤k,C)
- CCC 是初始多模态 Context。
- 当 k=1k=1k=1 时,这正好等价于一次以文本推理轨迹(Reasoning Trace)为条件引导的 Image Editing 操作。这就从数学和结构上统一了 T2I 的 Refinement 与图像编辑任务。
3. 两阶段推理范式 (Methodology)
UniReason 1.0 的推理由两个正交且互补的模块组成:
Phase 1: 融合世界知识的文本推理 (World Knowledge-Enhanced Textual Reasoning)
在输出视觉 Token 之前,模型被强制先输出一段 Textual CoT。这不仅是 Prompt Expansion,而是基于 5 大细分领域(文化常识、自然科学、空间推理、时间逻辑、形式逻辑)进行知识外推。
- 目的: 解决 Initial Synthesis(初稿生成)时的隐式知识对齐问题,作为后续生成的强条件引导。
Phase 2: 细粒度类编辑的视觉精修 (Fine-grained Editing-like Visual Refinement)
生成初稿 I1I^1I1 后,模型利用视觉特征提取器对其进行编码,结合之前的 CoT 文本进行自省(Self-reflection),输出一段“找茬文本”(Reflection Text T2T^2T2),指出现有图像在物体缺失、属性错误或逻辑不符等方面的问题。随后触发生成分支,将此过程作为一个 Editing 任务,输出精修后的 I2I^2I2。
4. 数据飞轮与合成管线 (Data Construction Pipeline)
高质量的交错数据是该论文成功的关键。作者设计了一个 Agentic Data Pipeline,构建了约 300k 的高质量推理数据集:
- Seed & Expand: 利用 Wikipedia 构建种子 Prompt,通过 Gemini 2.5 Pro 生成复杂的 CoT 推理轨迹。
- Draft Generation: Qwen-Image 渲染初始草图。
- Verification (Critic): Gemini 2.5 Pro 作为 VLM 诊断图文不符,输出结构化的修改建议(涵盖物体、属性、风格等 5 个维度)。
- Refinement (Teacher): 使用专业的图像编辑模型 Qwen-Image-Edit,根据修改建议执行指令编辑。
- Final Judge: Gemini 2.5 Pro 再次进行对比评估(Reward/Preference 模型逻辑),只有当 Refined Image 显著优于 Draft 且无幻觉时,才保留该数据对。
5. 两阶段 SFT 训练策略 (Training Recipe)
为了防止复杂的推理任务破坏模型基础的生成分布,作者采用了标准的 Two-Stage SFT:
- Stage 1(基础生成能力建设): 冻结理解分支,仅训练生成分支。使用 7M T2I 数据 + 500k 图像编辑开源数据。目标是强迫模型拟合高质量的 Flow-matching 轨迹,获得极强的 Instruction-following 和细粒度 Editing 能力。
- Stage 2(交错推理微调): 全参微调(Unfreeze all)。引入构造的 300k 推理与精修数据。
- 联合优化损失:L=λtextLtext+λimgLimg\mathcal{L} = \lambda_{text} \mathcal{L}_{text} + \lambda_{img} \mathcal{L}_{img}L=λtextLtext+λimgLimg
- Trick: 对于视觉精修数据,仅对“反思文本”和“最终精修图像”计算 Loss,对初稿图像和初始推理文本(Draft inputs)不计算梯度(Unsupervised),以让模型专注于学习“如何根据偏差进行修正映射”。
6. 核心实验结论与启发 (Key Takeaways for Engineers)
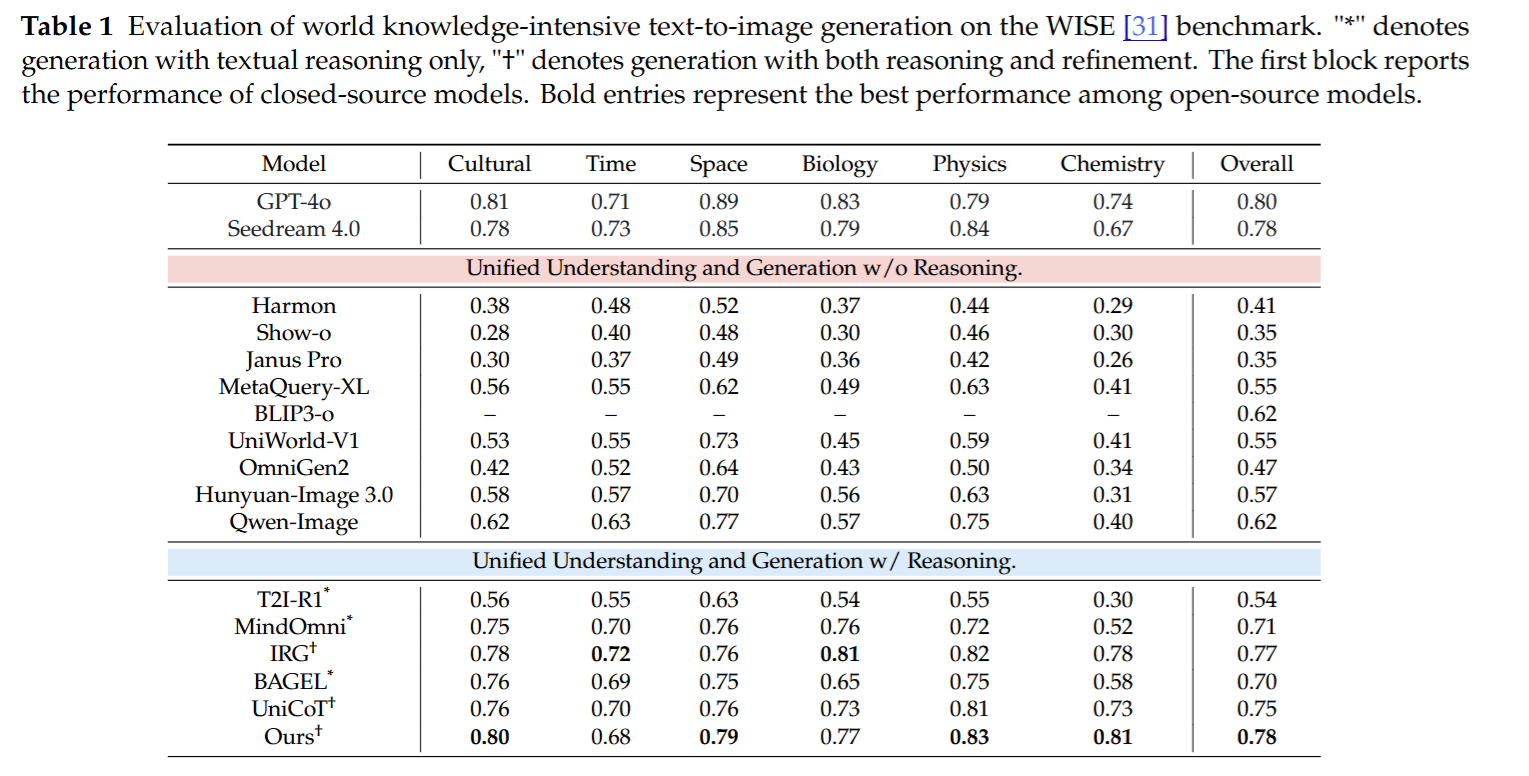
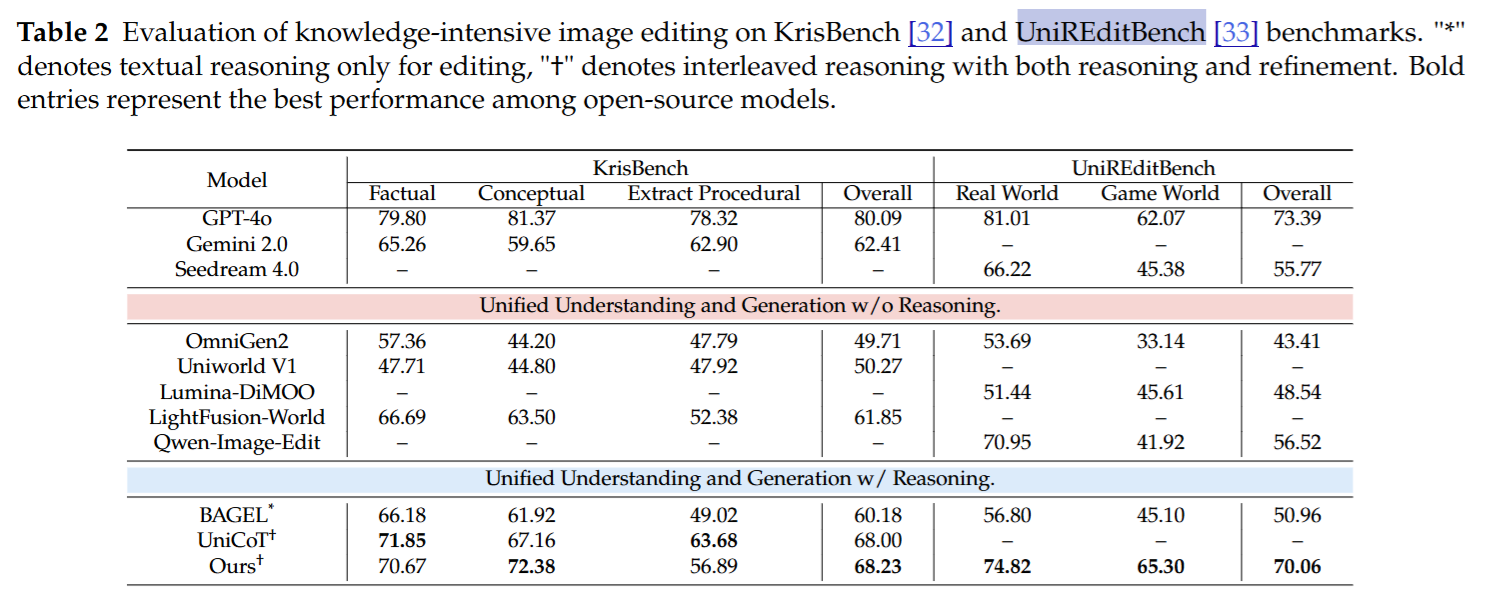
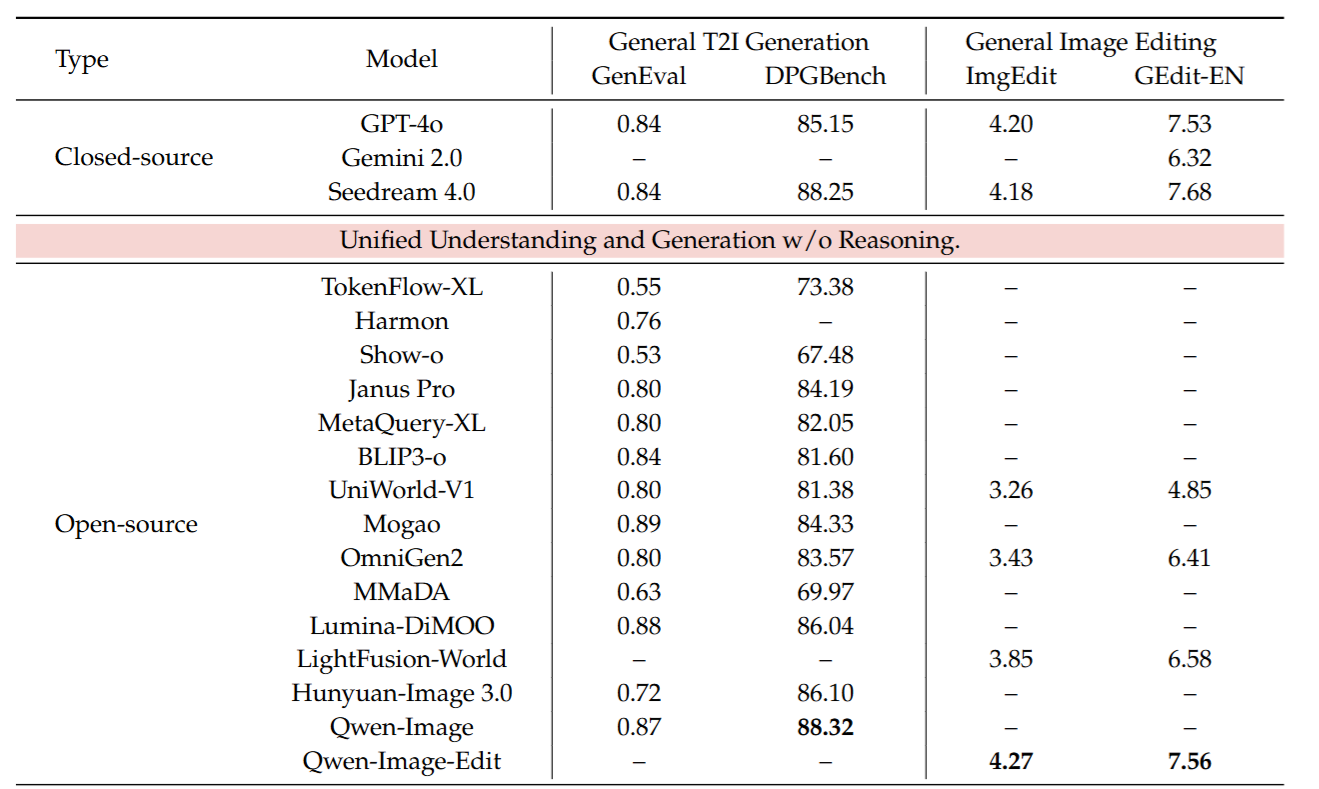
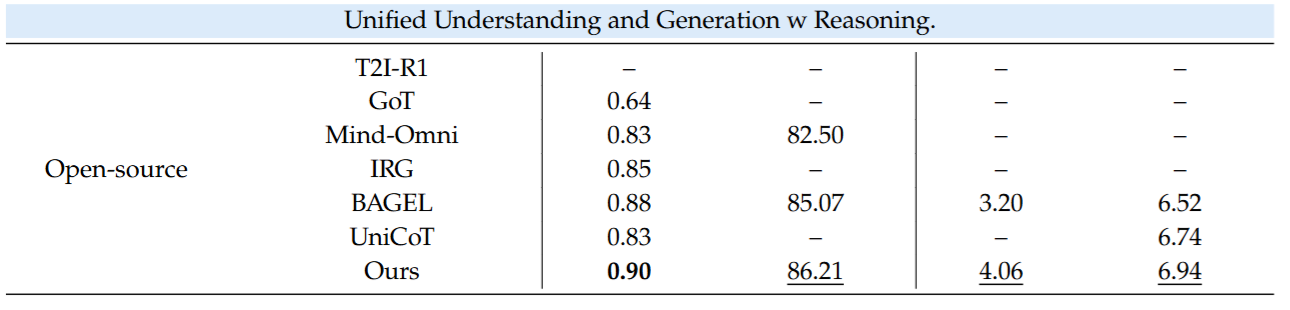
- SOTA 性能: 在考察硬逻辑的 WISE(T2I)和 KrisBench(Editing)榜单上,击败了现有开源多模态大模型(OmniGen2, Show-o, Janus-Pro),甚至部分指标超越了 GPT-4o 和 Gemini 2.0。
- Ablation Study 中的重要工程发现(图3): 论文分析了“模型本身的 Editing 能力得分”与“引入 Refinement 后带来的收益”之间的相关性。结果显示强正相关(Monotonically increasing)。
- 启发: 视觉反思与修图(Visual Refinement)强依赖于底层的细粒度编辑能力。如果不通过联合训练赋予模型强大的图像编辑先验,即使引入交错推理,模型也“知道错在哪,但手残改不好”。
总结
这篇论文的工程落地价值很高。它证明了在统一自回归/Flow-Matching架构下,不必为了 T2I 和 Editing 维护两套复杂的控制逻辑。只要通过高质量的 Agent 合成数据流,将 Editing 作为 T2I 的 Post-generation Refinement step 融入马尔可夫链中,并通过 LLM/VLM 注入世界知识先验,就能大幅拔高模型在复杂长尾 Case 下的生成逼真度与逻辑正确性。
在交错推理(Interleaved Reasoning)的范式中,“草图(Draft Image,即初稿)”的定位非常特殊:它在数据构造时是被用来“找茬”的靶标,而在模型训练时,它是作为前置条件(Context/Condition)而不是生成目标(Target)存在的。
为了让你在代码和数据流层面有直观的体感,我们把“草图”在**数据构造(Data Pipeline)和训练阶段(Training Phase)**的具体体现拆解开来:
一、 数据构造阶段:草图是如何产生并发挥作用的?
在离线准备数据集(Phase II Data Construction)时,草图本质上是整个 Agent 闭环的起点。
- 生成草图 (Draft Generation):
- 给定一条复杂的 Prompt(比如包含空间拓扑关系),直接送入初始生成器(论文中用的是 Base Model 或 Qwen-Image),进行一次常规的 Text-to-Image Forward 推理。
- 输出结果:得到草图(Draft Image, IdraftI_{draft}Idraft) 以及它生成前吐出的初始推理文本(Initial Reasoning Text)。注意:此时的草图往往是不完美的(存在逻辑错误或细节缺失)。
- VLM 诊断草图 (Critic/Verification):
- 将
(Prompt, Draft Image)喂给强力的外部 VLM(论文中用了 Gemini 2.5 Pro)。 - Gemini 充当“找茬专家”,对比 Prompt 和草图,输出结构化的诊断信息(比如:“画面中缺失了发光属性”,“左边的人物手部扭曲”)。这段文本就是数据集里的 反思文本(Reflection Text, TreflectT_{reflect}Treflect)。
- 将
- 教师模型基于草图进行精修 (Teacher Editing):
- 将
(Draft Image, Prompt, Reflection Text)输入给一个强大的专门用于图像编辑的模型(论文中用的是 Qwen-Image-Edit)。 - 它把草图当作底图,执行 Instruction-guided Image Editing,输出精修后的图像(Refined Image, IrefinedI_{refined}Irefined)。
- 将
- 落盘数据流:
经过最后一道 Gemini 对比校验(确保 IrefinedI_{refined}Irefined 真的比 IdraftI_{draft}Idraft 好)后,存入数据集的其实是一个序列/元组 (Tuple):Data = [Prompt, Initial Reasoning, Draft Image, Reflection Text, Refined Image]
二、 训练阶段(SFT):草图在 Loss 里怎么算?
这是整个工程中最 Trick 也是最关键的一步。
在第二阶段的交错推理微调(Stage-2 SFT)中,模型需要处理上述构造好的长序列。多模态模型的输入实际上是一个拼接好的交错 Token 序列(Interleaved Sequence)。
序列结构大致如下:[BOS] <Prompt> <Initial_Reasoning_Tokens> <Draft_Image_Tokens> <Reflection_Text_Tokens> <Refined_Image_Tokens> [EOS]
核心工程处理:草图不计算 Loss(Unsupervised / Loss Masking)。
- 前向传播(Forward Pass):
草图的图像 Token(经过 ViT 或 VAE 编码后的特征向量)会作为输入序列的一部分,被灌入统一的 Transformer 架构中。它参与 Attention 计算,作为后续生成任务的 KVKVKV Cache(前置上下文)。 - 反向传播(Backward Pass):
论文中明确提到:“…while leaving the initial reasoning text and visual draft unsupervised.”- 在构建 Loss Mask 时,对应
<Initial_Reasoning_Tokens>和<Draft_Image_Tokens>位置的 Label 会被设置为-100(或者对应的 Ignore Index)。 - 即:梯度不会流向“生成草图”的这一步。 模型只对
<Reflection_Text_Tokens>(文本交叉熵 Loss)和<Refined_Image_Tokens>(Latent Flow-Matching Loss)进行监督计算。
- 在构建 Loss Mask 时,对应
三、 为什么要这么设计?(算法直觉)
作为算法工程师,你肯定能立刻 Get 到这样设计的必要性:
- 避免分布退化(Learning Sub-optimal Distribution):
草图既然被挑出了毛病,说明它是一张**“次优图”甚至“错图”**。如果我们对草图计算重构 Loss 或 Flow-matching Loss,模型就会学到这种错误的生成分布,导致基础 T2I 能力退化。 - 统一图像编辑任务(Formulated as Image Editing):
将草图作为 Context(不计算 Loss),而将 Refined Image 作为 Target。在这个局部视角下,这就是一个标准的 Image Editing 任务!
数学表达即为:Irefined=F(Idraft,Treflect,C)I_{refined} = \mathcal{F}(I_{draft}, T_{reflect}, C)Irefined=F(Idraft,Treflect,C)
这使得模型能复用第一阶段(Stage 1)辛苦学到的底层编辑表征能力,把“编辑能力”完美平移到了“生成后的自校正”上。 - 迫使模型学习“相对映射(Delta)”:
模型在预测反思文本和精修图时,注意力机制(Cross-Attention / Self-Attention)必须高度关注草图(IdraftI_{draft}Idraft)。模型学到的不再是“如何从头画一幅完美的画”,而是**“当前草图的状态与理想状态之间的 Diff(残差)是什么,以及如何修复这个 Diff”**。
总结
在工程实现上,草图在训练时充当的是“只读不写(只参与 Attention,不计算 Loss)”的视觉 Prompt。通过这种 Teacher-Forcing 的序列构造和精准的 Loss Masking,UniReason 成功教会了模型“如何审视自己刚刚生成的(可能不太完美的)结果,并对其进行 P 图修改”。
在实际推理(Inference)时,模型没有现成的草图标签,草图是模型“自己现场画出来”的。整个过程是一个典型的“自回归 + 连续生成”的串联流水线(Pipeline),模型在“自导自演”。
为了让你在脑海中建立清晰的推理流图(Inference Compute Graph),我们一步步拆解当用户输入一句 Prompt(比如:“画一个赛博朋克风格的女孩”)时,UniReason 在底层到底是怎么跑的:
推理流水线拆解 (Inference Pipeline)
在推理阶段,模型的 KV Cache 是随着步骤不断生长的。
Step 1: 文本推理(World Knowledge-Enhanced Textual Reasoning)
- 输入:
[BOS] <Prompt> - 动作: 激活模型的多模态理解分支(Language Modeling Head)。模型像普通的 LLM 一样,自回归(Autoregressive, 逐个 Token) 地生成一段思考过程(CoT)。
- 输出: 生成了
<Reasoning_Tokens>(比如:“赛博朋克需要霓虹灯、机械义体……”)。 - 当前 Context 累积:
[Prompt] + [Reasoning_Tokens]
Step 2: 生成草图(Initial Draft Generation)
- 输入: 带着刚才累积的 Context。
- 动作: 此时触发一个特殊的标识符,切换到多模态生成分支(Generation Expert / Flow-Matching Head)。
- 模型在 VAE 的 Latent 空间中随机采样一段纯噪声 z0z_0z0。
- 把
[Prompt] + [Reasoning_Tokens]作为条件(Condition),注入到 Transformer 的 Cross-Attention 或 AdaLN 模块中。 - 调用 ODE Solver(比如 Euler 采样器),跑 N 步(比如 20-30 步)去噪/流匹配过程。
- 输出: 解码得到**草图(Draft Image)**的 Latent 表征。
- 当前 Context 累积: 将生成的草图 Latent 拼接到序列中。现在的 Context 变成了:
[Prompt] + [Reasoning_Tokens] + [Draft_Image_Tokens]。- (注:此时模型等于自己给自己造出了你所说的那个“草图标签”。)
Step 3: 视觉反思(Self-Reflection)
- 输入: 带着上述所有 Context(此时模型能“看”到自己刚画的草图和之前的推理文本)。
- 动作: 再次切换回理解分支(Language Head)。模型审视现有的 Context,开始自回归生成反思文本。
- 输出: 生成
<Reflection_Tokens>(比如:“发现画面缺少了机械义体的细节,光影也不够霓虹”)。 - 当前 Context 累积:
[Prompt] + [Reasoning_Tokens] + [Draft_Image_Tokens] + [Reflection_Tokens]
Step 4: 最终精修(Fine-grained Visual Refinement)
- 输入: 完整的超长 Context。
- 动作: 再次切换到生成分支(Flow-Matching Head)。这一步在数学形式上完全等价于一次图像编辑(Image Editing)操作。
- 在 Flow-matching / Diffusion 架构中,做图像编辑通常有两种做法:
- Img2Img 方式: 给刚才生成的草图 Latent 加一定比例的噪声,然后以完整的 Context 为条件,重新降噪生成。
- Concat / ControlNet 方式: 直接把草图 Latent 作为额外通道(Channel)拼接到输入中,或者通过专门的 Encoder 注入结构信息,预测新的速度场(Velocity Field)。
- 基于模型的结构,它会根据反思文本的指导,去修改草图的特征。
- 在 Flow-matching / Diffusion 架构中,做图像编辑通常有两种做法:
- 输出: 最终的精修图像(Refined Image)。
为什么模型推理时能这么顺滑地切来切去?
这就是**统一多模态模型(Unified Multimodal Model)**的魅力,也是论文选择基于 BAGEL 架构的原因:
- 统一的表征空间: 无论是文本的词向量,还是图像的 Patch 特征(ViT 提取或 VAE Latent),在模型内部都被展平(Flatten)成了一维的序列(Sequence of Tokens)。
- 同一个骨干网络(Shared Backbone): 文本的生成和图像特征的提取/生成,都在同一个 Transformer 块里做 Attention 计算。草图虽然是生成的,但它在 Step 3 和 Step 4 就变成了 KV Cache 里的 Key 和 Value,供后续的 Token 查询。
- 训练数据的功劳: 正是因为在训练阶段(我们上一问聊到的),我们强行灌给了模型
[Prompt -> 推理 -> 草图(不算Loss) -> 反思 -> 精修图]这样的长序列,模型学习到了这种状态转移的概率分布。所以推理时,它自然而然地知道:写完推理就该画草图,画完草图就该写反思,写完反思就该出精修图。
总结
在实际推理时,“草图”既是 Step 2 的输出(预测目标),又是 Step 3 和 Step 4 的输入(条件上下文)。
UniReason 并不是在推理时需要一个外部给定的草图,而是将“生成草图”和“反思修改草图”串联进了一次完整的自回归前向传播中。它自己给自己当甲方(提要求),自己当初级画师(画草图),自己当总监(提修改意见),最后自己当高级画师(出精修图)。这也是“交错推理(Interleaved Reasoning)”这个词的硬核工程体现。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)