大模型微调+RAG对话机器人教程(一)
这是一个基于大模型微调的华中科技大学学生手册问答机器人项目
这里我在autoDL上租了一台5090,数据盘扩容了150G,基础镜像选择pytorch2.7.0,Ubuntu22.04,cuda12.8,接下来开始配置环境。
1.查看硬件环境
首先通过nvidia-smi命令判断显卡驱动是否正常:
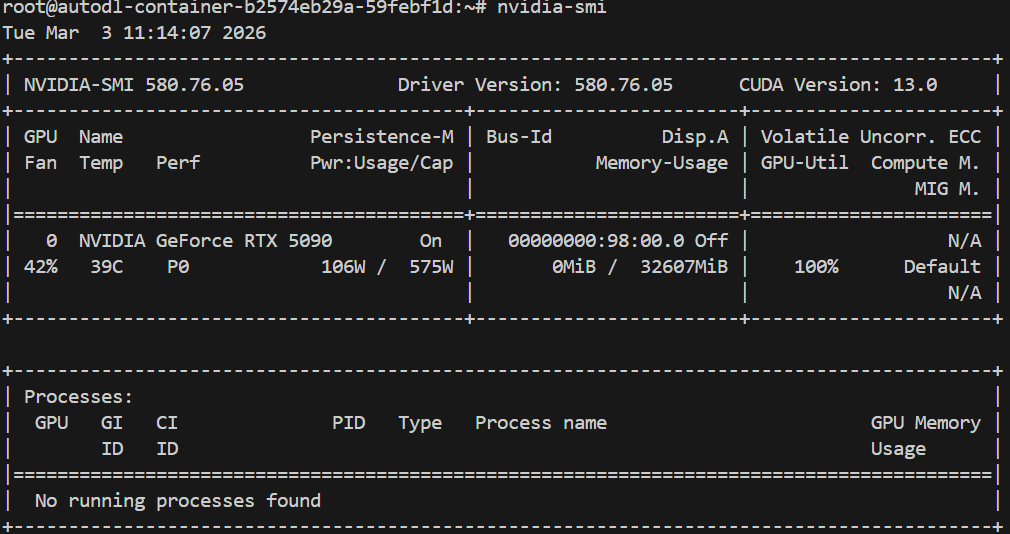
这里显卡驱动正常,之后运行nvcc -V命令判断cuda版本,这里显示没有nvcc命令
![]()
我们先判断cuda路径
ls -d /usr/local/cuda* #判断cuda路径 得到的结果如下
/usr/local/cuda /usr/local/cuda-12 /usr/local/cuda-12.8将它加入环境变量中并验证
# 1. 将路径写入 .bashrc
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
# 2. 刷新配置使之生效
source ~/.bashrc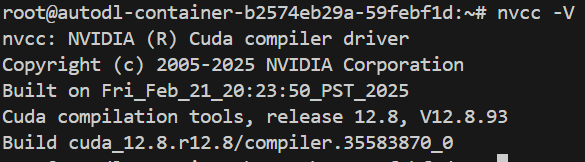
成功识别到cuda了,接下来去安装llamafactory
2.llama-factory的安装
首先在安装之前为了防止autoDL系统盘爆满,先建立软连接
rm -rf root/.cache #清空缓存文件夹
mkdir -p root/autodl-tmp/.cache #在数据盘建立文件夹
ln -s /root/autodl-tmp/.cache /root/.cache #建立软链接
ls -ld root/.cache #判断是否链接成功
出现这个提示就说明软连接成功了
接下来创建llamafactory的虚拟环境
conda create -n llamafactory python=3.11 -y #创建虚拟环境
conda init bash #创建完成之后需要初始化bash
source ~/.bashrc #更新配置
conda activate llamafactory #激活虚拟环境如果成功激活那命令行左侧的"(base)"会变为"(llamafactory)"
因为已经有了pytorch,我们就不需要再安装pytorch了,这里想记录一下如果以后在国内安装pytorch时我推荐使用南京大学镜像源,以下面的代码为例:
pip install torch torchvision torchaudio --index-url https://mirrors.nju.edu.cn/pytorch/whl/cu121
之后安装llamafacatory:
git clone --depth 1 https://bgithub.xyz/hiyouga/LLaMA-Factory.git#这里使用了一个镜像源
cd LLaMA-Factory
pip install -e ".[torch,metrics,bitsandbytes,qwen,modelscope]"安装完llamafactory之后运行llamafactory-cli version,成功出现版本说明安装成功了:
3.数据集的准备
这里我选择了魔塔社区的华中科技大学学生手册作为中文问答数据集:
# 1. 安装 git-lfs (AutoDL 通常自带,如果没有则运行此命令)
apt-get update && apt-get install git-lfs -y
# 2. 初始化 LFS 环境
git lfs install
# 3. 进入data文件夹
cd LLaMA-Factory/data
# 克隆仓库
git clone https://www.modelscope.cn/datasets/alleyf/HUST-Student-Handbook.git将数据集克隆完成后打开LLaMA-Factory/data/dataset_info.json,这个数据集是sharegpt格式,各种tag要单独放在tags字段里,不然会出现数据对齐的错误,将下面这段代码复制,粘贴到最后一段,注意逗号不要丢掉:
,
"hust_handbook": {
"file_name": "HUST-Student-Handbook/lora_hust_student_handbookt.jsonl",
"formatting": "sharegpt",
"columns": {
"messages": "conversations"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}4.大模型微调
回到LLaMA-Factory文件夹,输入命令:
llamafactory-cli webui

初次训练时需要先下载大模型,我这里选择的qwen2.5-7B-Instruct模型,在国内使用modelscope下载源,下面加载数据集。
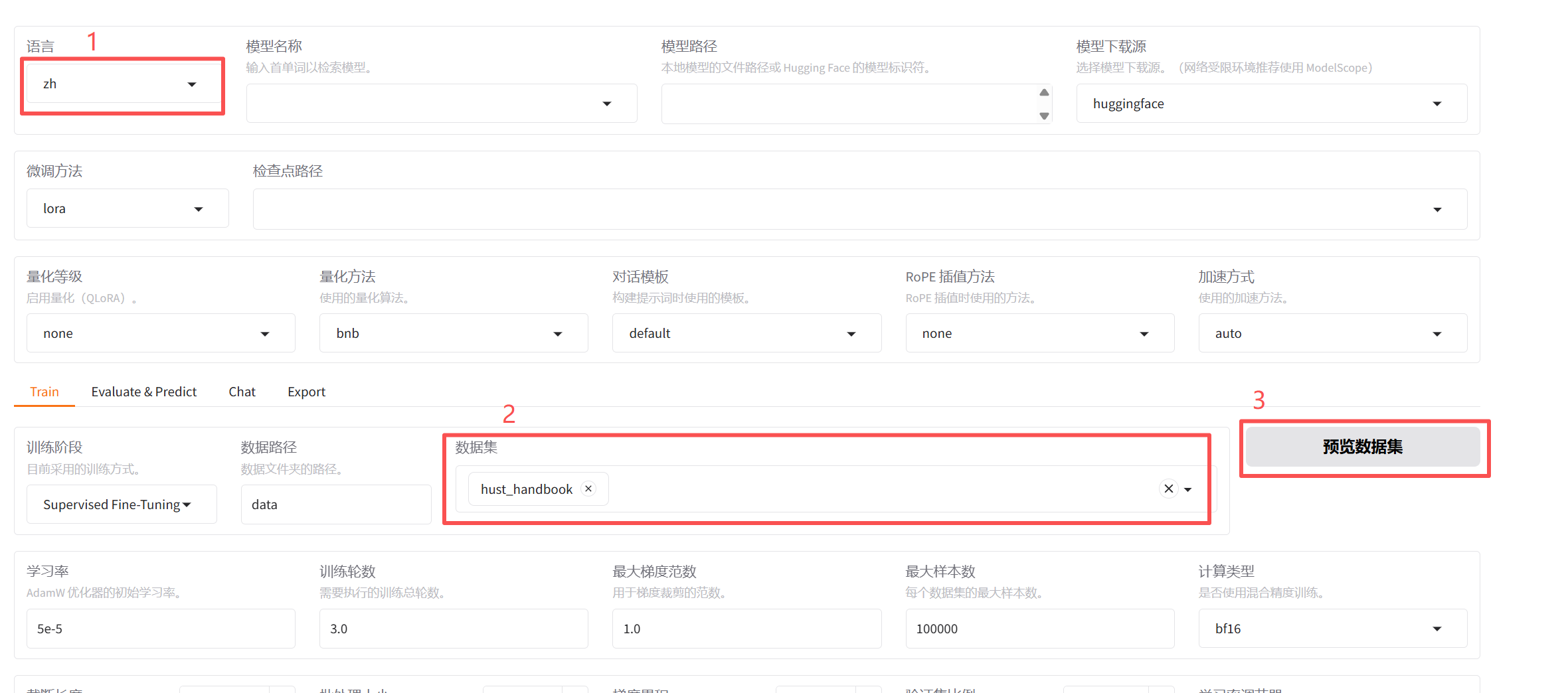
出现如下图的问答对时说明数据集已经加载成功了,接下来可以训练大模型了

在训练方面的参数设置如下: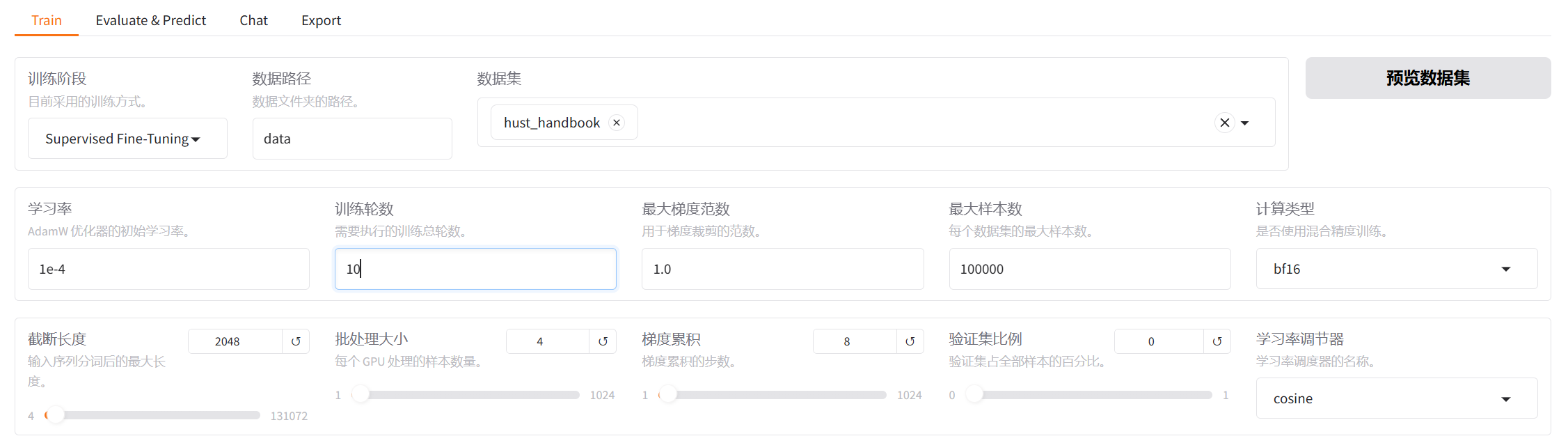
lora方面的参数设置如下:
之后点击开始训练就会进行训练了 ,初次训练还需要下载大模型,比较慢,要耐心等待。
训练完成之后看一下效果,先看损失函数,路径在/root/autodl-tmp/LLaMA-Factory/saves/Qwen2.5-7B-Instruct/lora/train_2026-03-03-14-46-38/training_loss.png: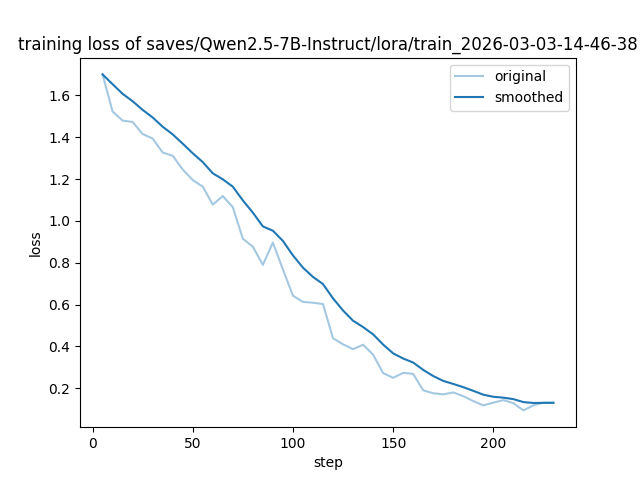
接下来加载模型进行对话与原数据集进行对比来看看问答效果: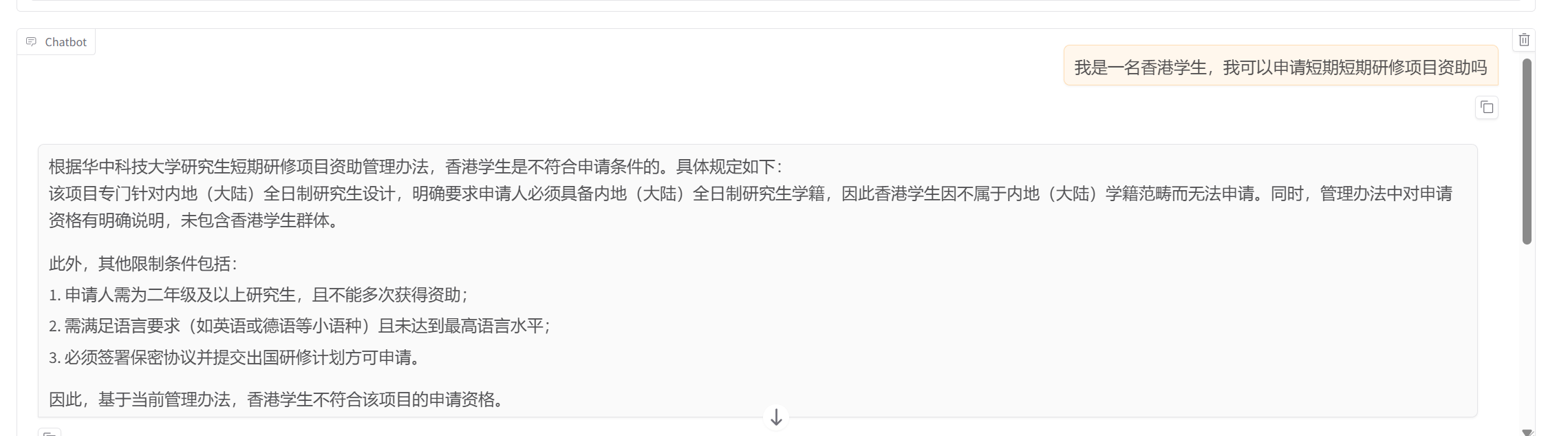
效果还是比较好的,这里只进行了微调学习专业术语和语气,为了避免幻觉问题并且为了能做到随时更新数据,我们还需要进行RAG

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)