从论文选题定方向到精准投期刊:详解维普智教如何重构科研论文写作工作流(附步骤)
在 AI 赋能科研的背景下,“学术幻觉”(虚构文献、编造数据)成为制约 AI 落地的核心痛点。本文基于维普智教最新推出的「科研写作」智能体矩阵,深度解析其如何通过“AI+ 真实学术资源”的深度融合,实现从选题定题、大纲构建、综述生成、长文创作、语言润色到投稿选刊的全流程闭环。文章详细拆解了六大核心智能体的技术逻辑与实操步骤,重点阐述其如何利用海量真实期刊数据杜绝“幻觉”,确保内容可溯源、可验证。通
导读:当通用大模型(LLM)在创意写作领域大放异彩时,科研界却对其望而却步。原因无他——“学术幻觉”(Academic Hallucination)。虚构的参考文献、编造的实验数据、杜撰的研究结论,这些看似完美的“AI 生成物”,实则是学术诚信的定时炸弹。
科研,容不得半点虚假。严谨,是学术的生命线。
如何在享受 AI 效率红利的同时,坚守学术的严谨底色?维普智教给出的答案是:“AI + 真实学术资源”的深度融合。今天,我们将深度实测维普智教全新推出的「科研写作」智能体矩阵,看它如何覆盖从选题到投稿的全流程,实现真正的“零幻觉”科研辅助。
免费体验:
一、痛点复盘:通用 AI 为何搞不定“严肃科研”?
在开始实操之前,我们先来剖析一下通用大模型在科研场景下的“水土不服”:
- 数据源污染:通用模型训练数据混杂网络噪音,缺乏经过同行评审的高质量学术语料。
- 概率性幻觉:基于 Next Token Prediction 的生成机制,导致其在面对具体事实(如文献标题、作者、年份)时,倾向于“一本正经地胡说八道”。
- 逻辑断层:难以理解复杂的学术逻辑框架,生成的文章往往结构松散,缺乏深度论证。
- 投稿盲目:无法实时获取期刊的最新收录偏好和审稿动态,推荐期刊往往凭“印象流”。
结论:科研写作需要的不是“能聊天的 AI”,而是“懂学术、有依据、可溯源”的垂直领域智能体。
二、核心方案:维普智教「科研写作」智能体矩阵解析
维普智教依托维普资讯海量的真实期刊文献库,构建了六大核心智能体,形成了一套完整的科研工作流闭环。
2.1 研究前沿,精准定题 —— “科研选题”智能体
痛点:选题难,要么太旧没价值,要么太新没资料,甚至凭空想象出“伪热点”。
技术逻辑:
该智能体并非随机生成题目,而是扫描真实期刊热点,基于近几年的发文趋势和引用数据,推送真实存在且持续被关注的研究方向。
实操步骤:
- 进入智能体中心 → 选择“科研写作” → 点击“科研选题”
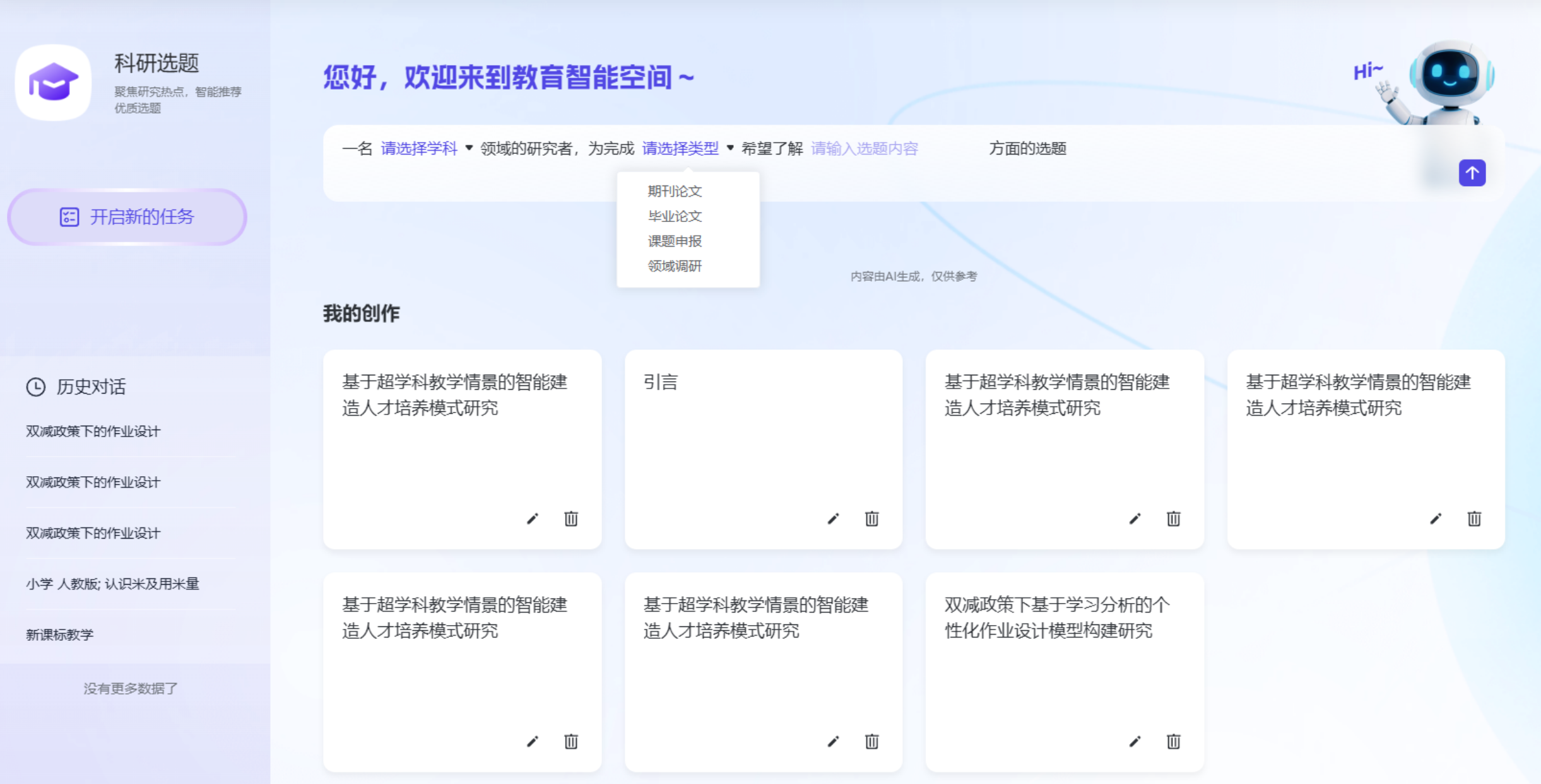
- 输入研究学科领域、论文类型(期刊论文/课题申报/毕业论文等)。
- 输出结果:系统推荐三个高价值选题,每个选题附带:
- 中英文题目
- 匹配理由(基于可行性、新颖性、价值性三维指数评估)
- 真实参考文献支撑
- 一键生成大纲入口
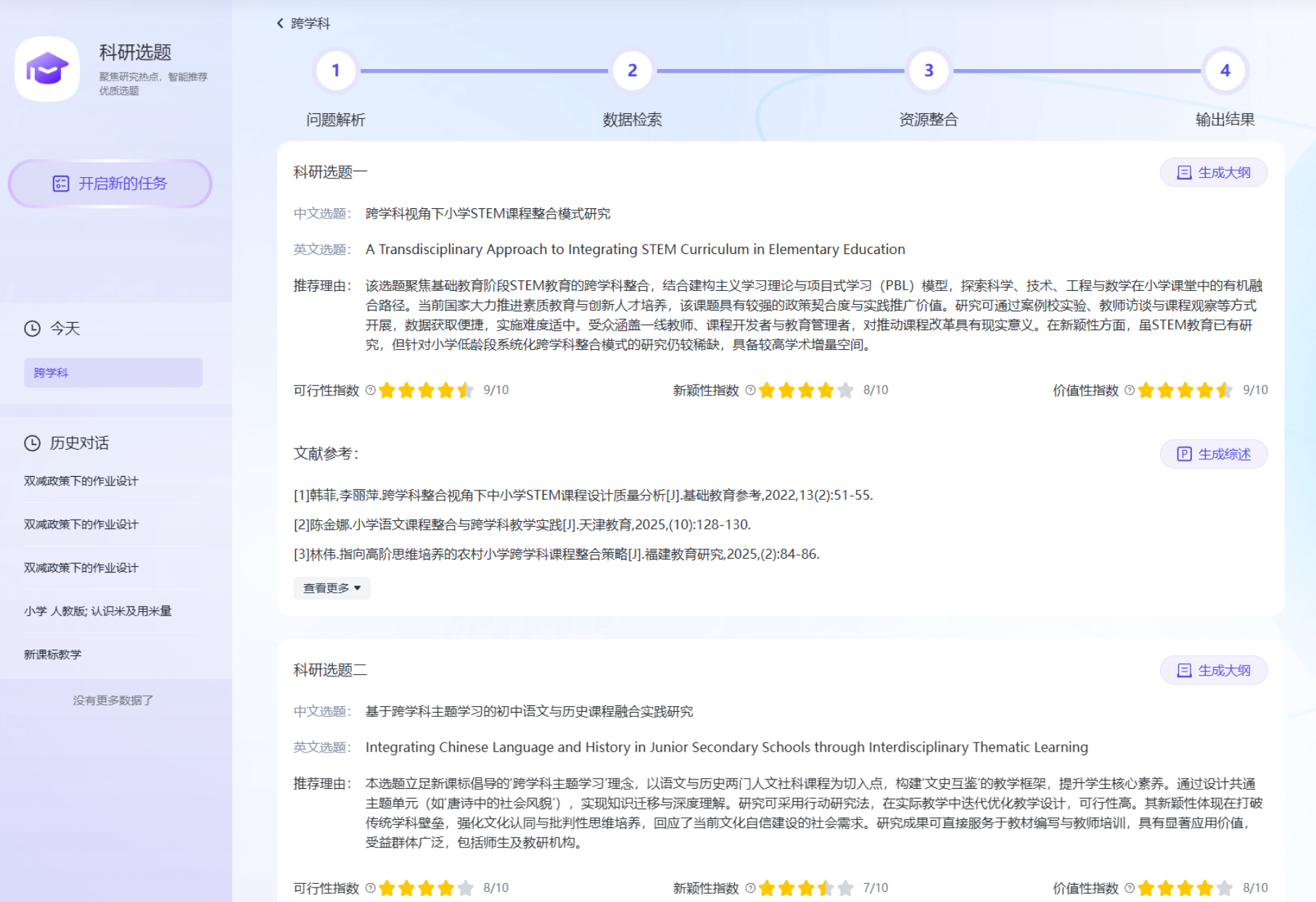
实测点评:这里的“可行性指数”和“新颖性指数”并非拍脑袋决定,而是基于维普数据库的统计规律计算得出,极大地降低了选题的试错成本。
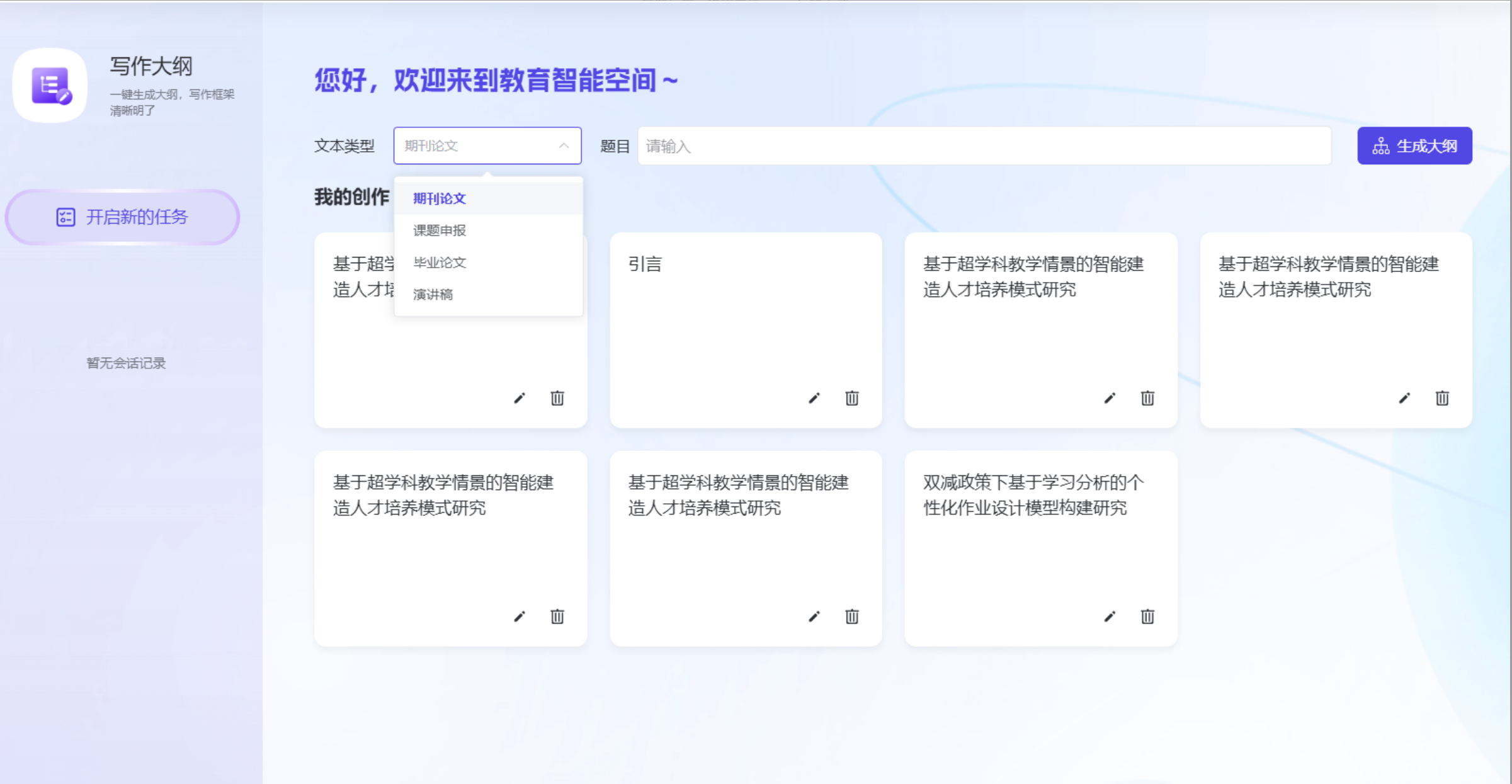
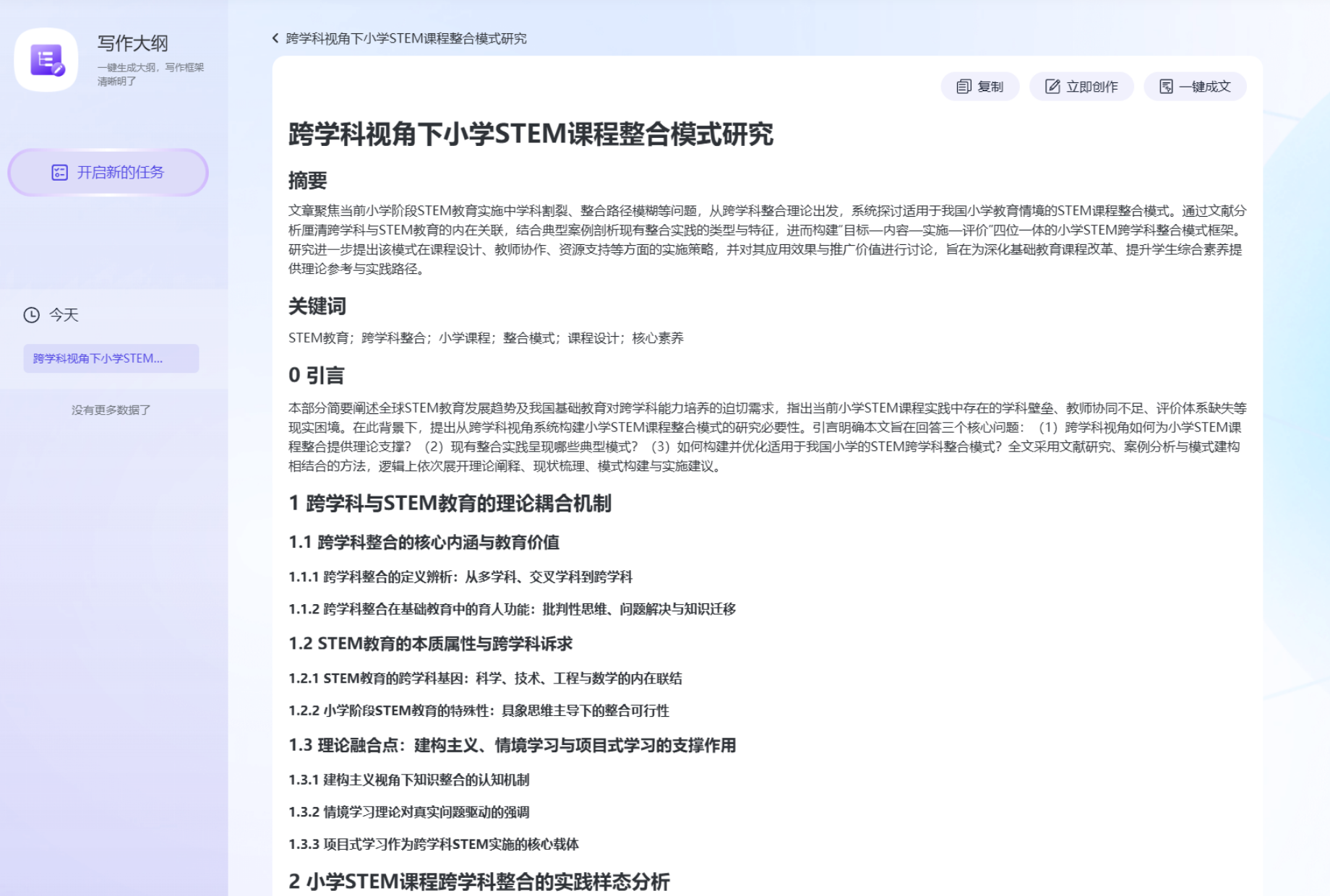
2.2 框架清晰,逻辑自洽 —— “写作大纲”智能体
痛点:题目有了,但不知道如何搭建符合学术规范的逻辑框架。
技术逻辑:
基于同类高质量论文的真实结构模式进行提炼,确保生成的摘要、引言、方法、结论等核心要素齐全且逻辑严密。
实操步骤:
- 选择“写作大纲” → 指定文本类型。
- 输入确定的选题。
- 输出结果:一键生成结构完整的大纲,层级分明,可直接作为写作的“骨架”。
2.3 高效梳理,综述速成 —— “多篇综述”智能体
痛点:文献综述是科研中最耗时的环节,阅读、整理、归纳极易出错,且容易遗漏关键文献。
技术逻辑:
这是维普智教的王牌功能。它不调用通用知识库,而是实时检索维普真实文献库,对选中的多篇文献进行智能归纳。
实操步骤:
- 选择“多篇综述” → 输入关键词。
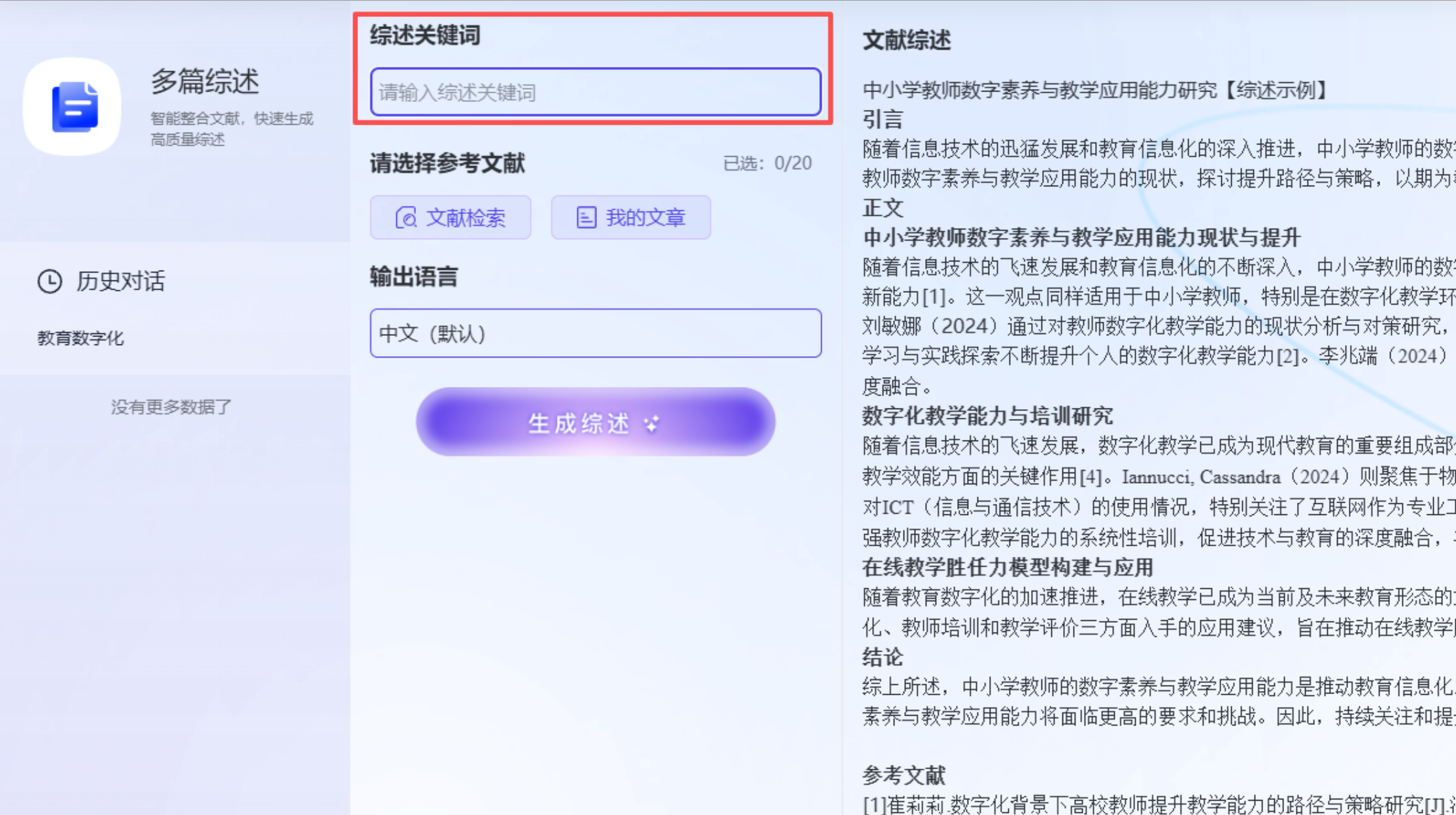
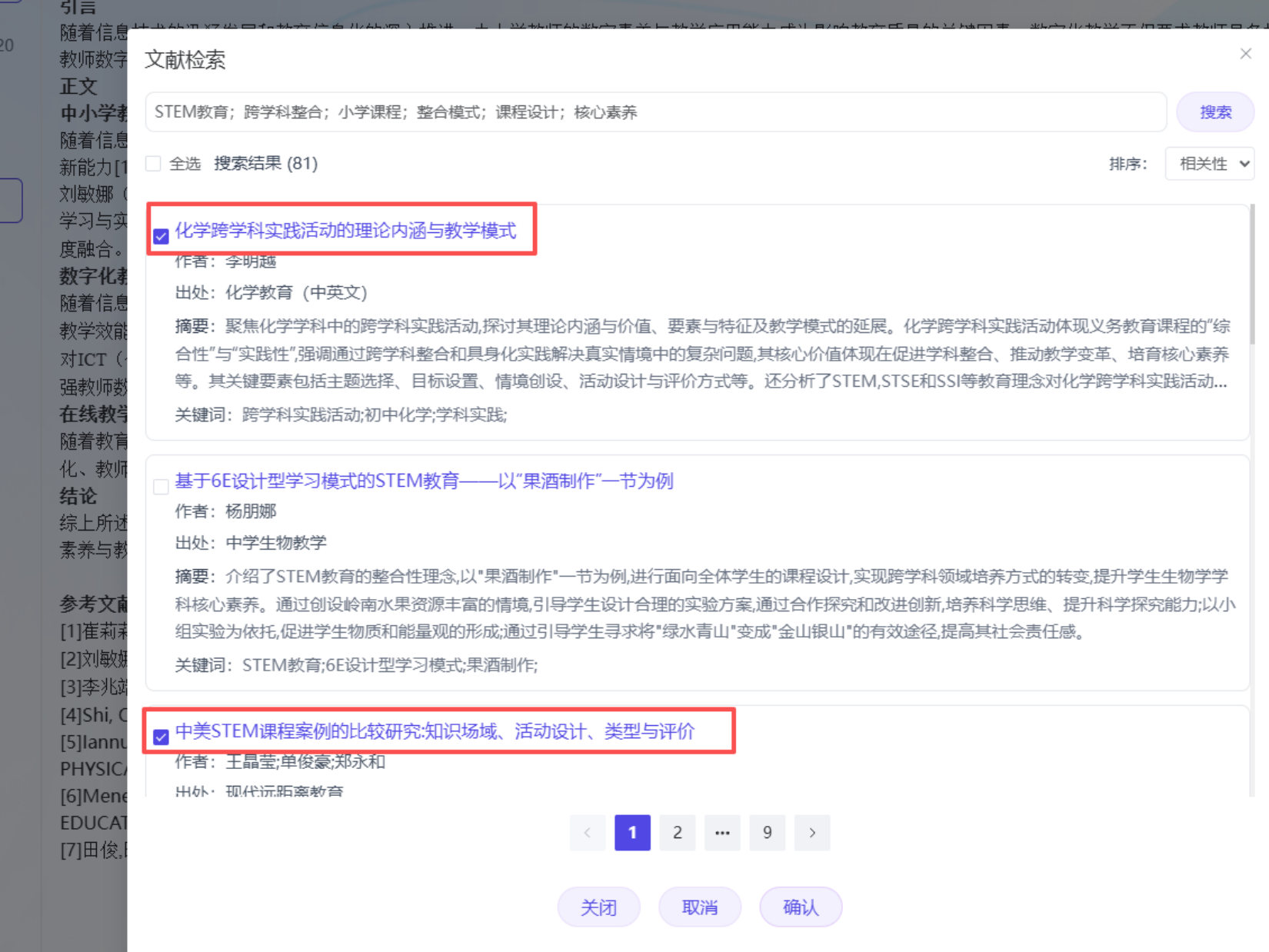
- 系统快速检索相关文献,支持人工勾选多篇核心文献(确保质量)。
- 输出结果:秒速生成高质量综述,自动归纳研究背景、现状、方法,并同步标注真实参考文献。
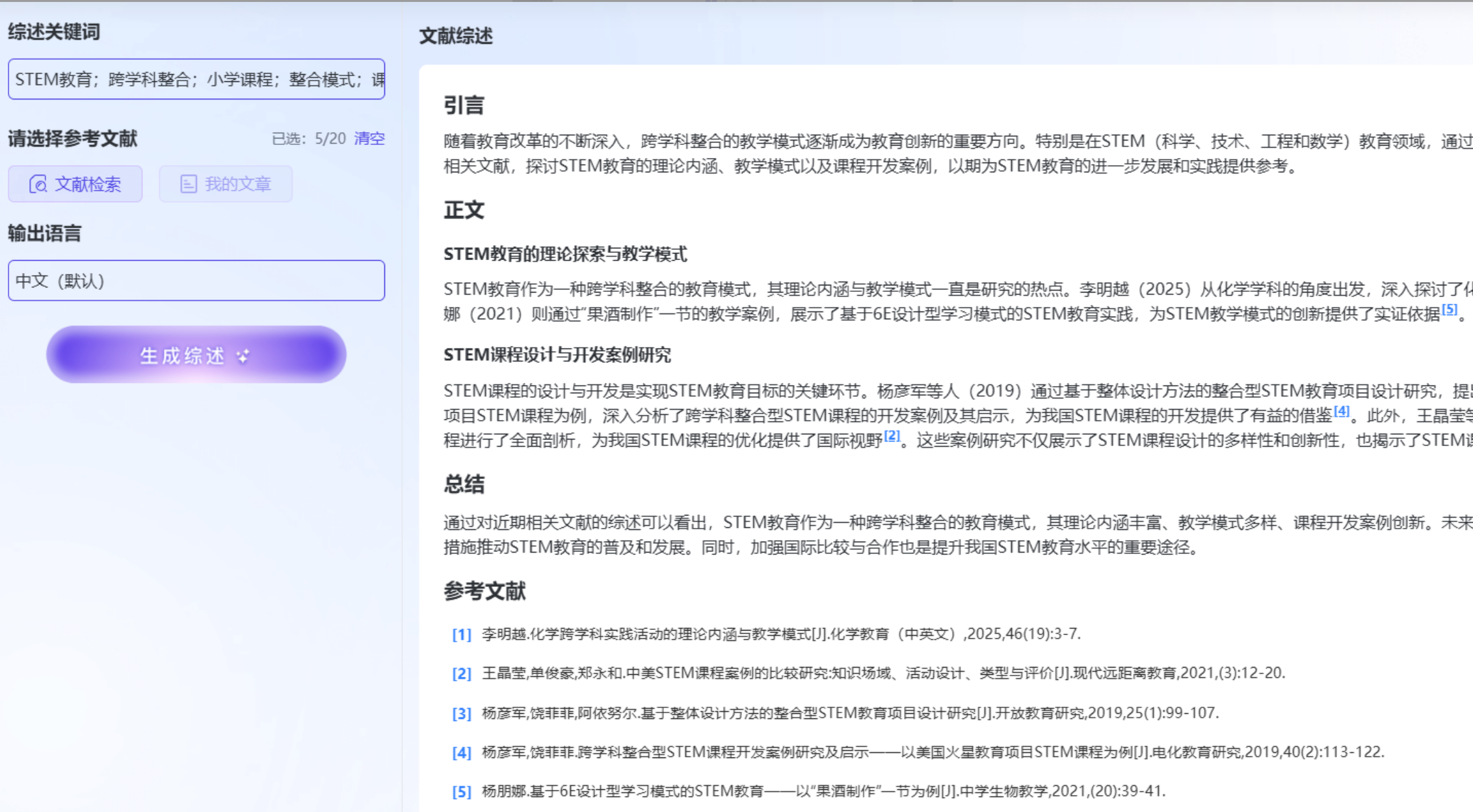
技术亮点:所有综述内容均源自真实文献,杜绝了“虚构研究现状”的风险。生成的内容可直接嵌入开题报告,引用格式规范准确。此外,配合“文章研读”智能体,上传 PDF 即可快速解析核心观点,进一步提升阅读效率。
2.4 内容填充,高效创作 —— “长文写作”智能体
痛点:大纲有了,但填充内容时容易主观臆断,缺乏论据支撑。
技术逻辑:
严格关联已有研究成果,确保每一个关键论断都有真实文献作为支撑。
实操步骤:
- 选择“论文创作”(长文写作) → 选择“论文创作” → 根据提示文本类型 → 输入论文题目 。
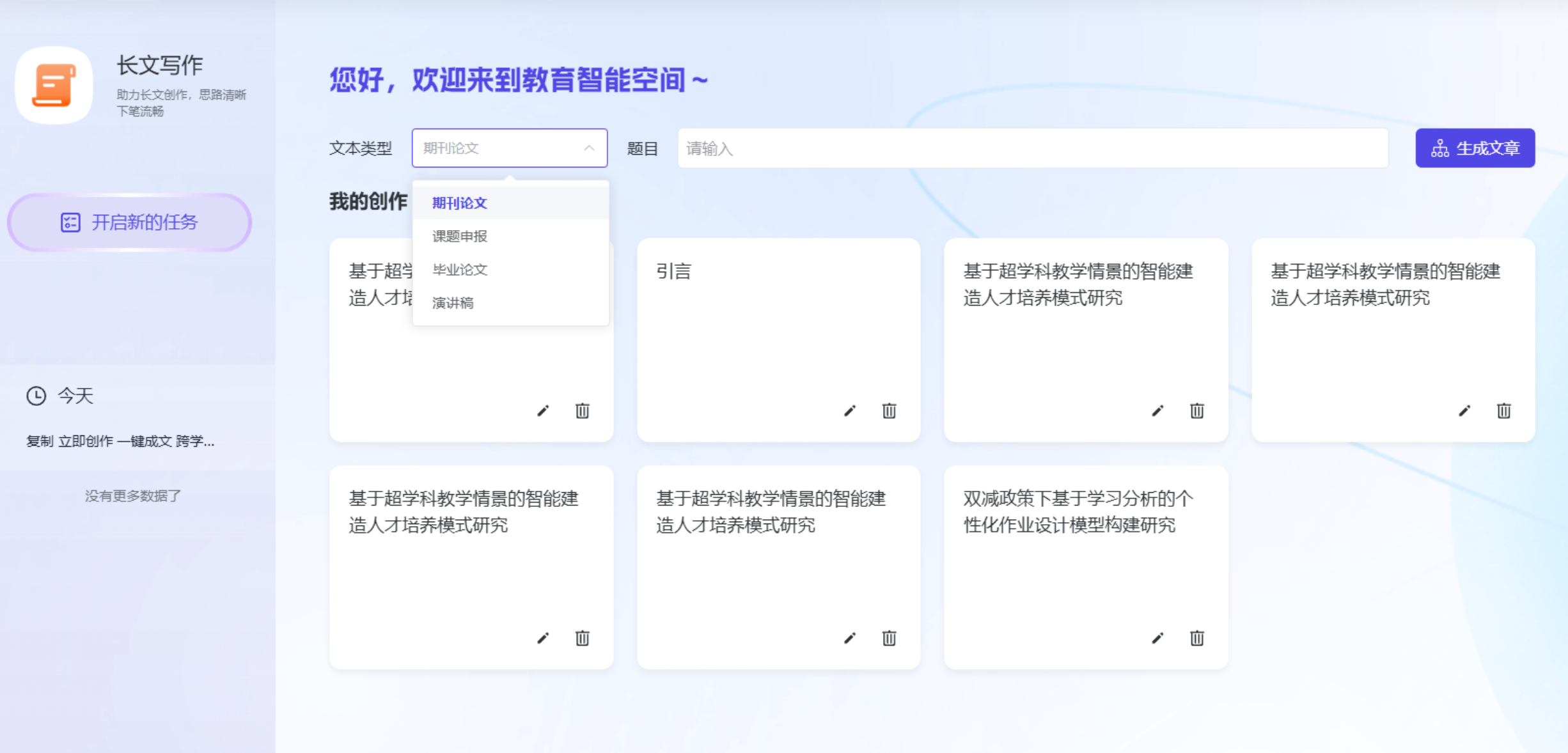
- 输出结果:AI 在 3 分钟内生成长文文稿。注意,这里的内容不是“编”出来的,而是基于检索到的真实知识进行的逻辑重组。
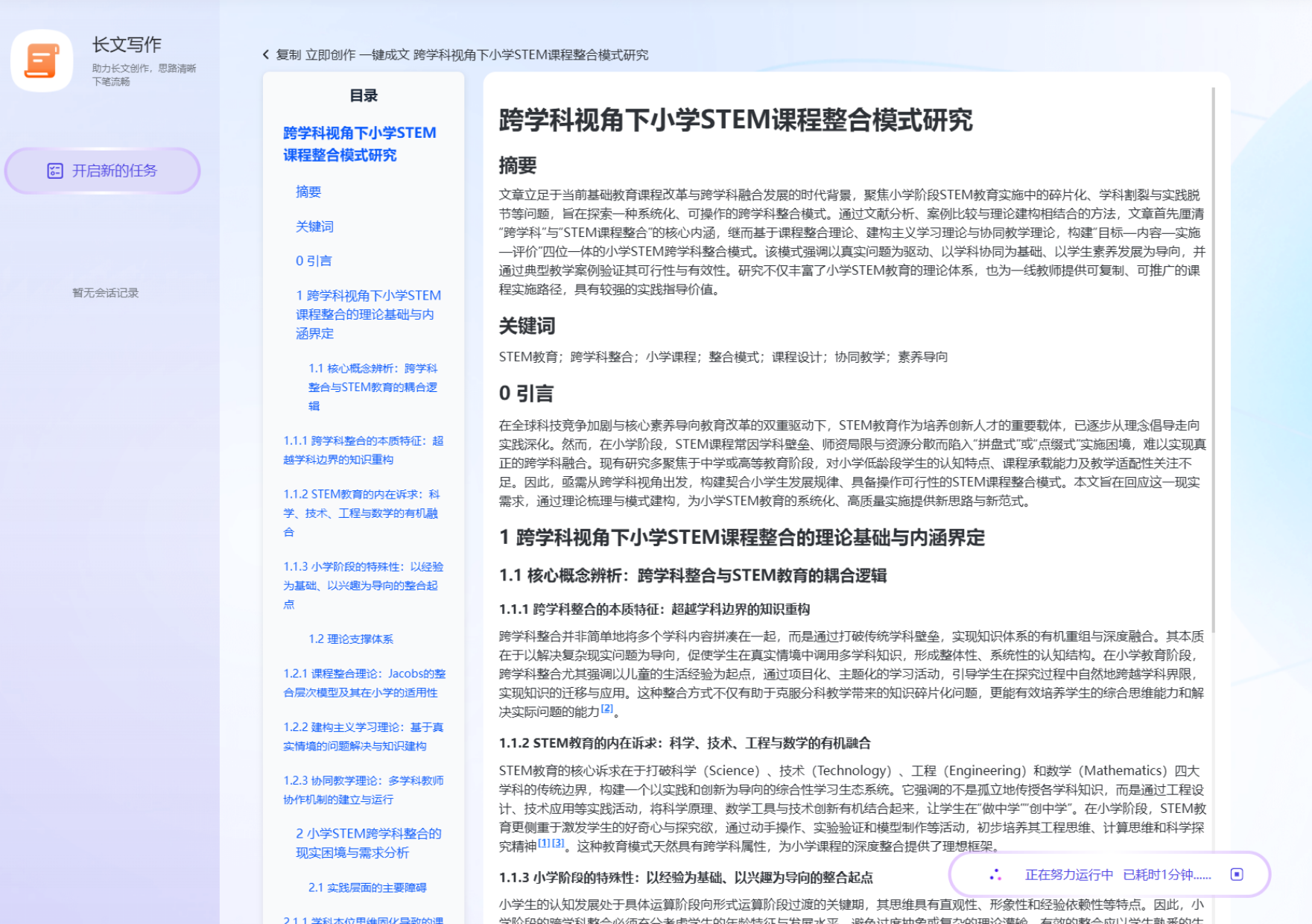
2.5 语言锤炼,表述升维 —— “写作润色”智能体
痛点:初稿完成,但语言表达过于口语化,缺乏学术“范儿”。
技术逻辑:
基于学术语料库训练的专用润色模型,专注于提升语言的规范性、准确性和逻辑性。
实操步骤:
- 选择“写作润色” → 粘贴内容或上传文档。
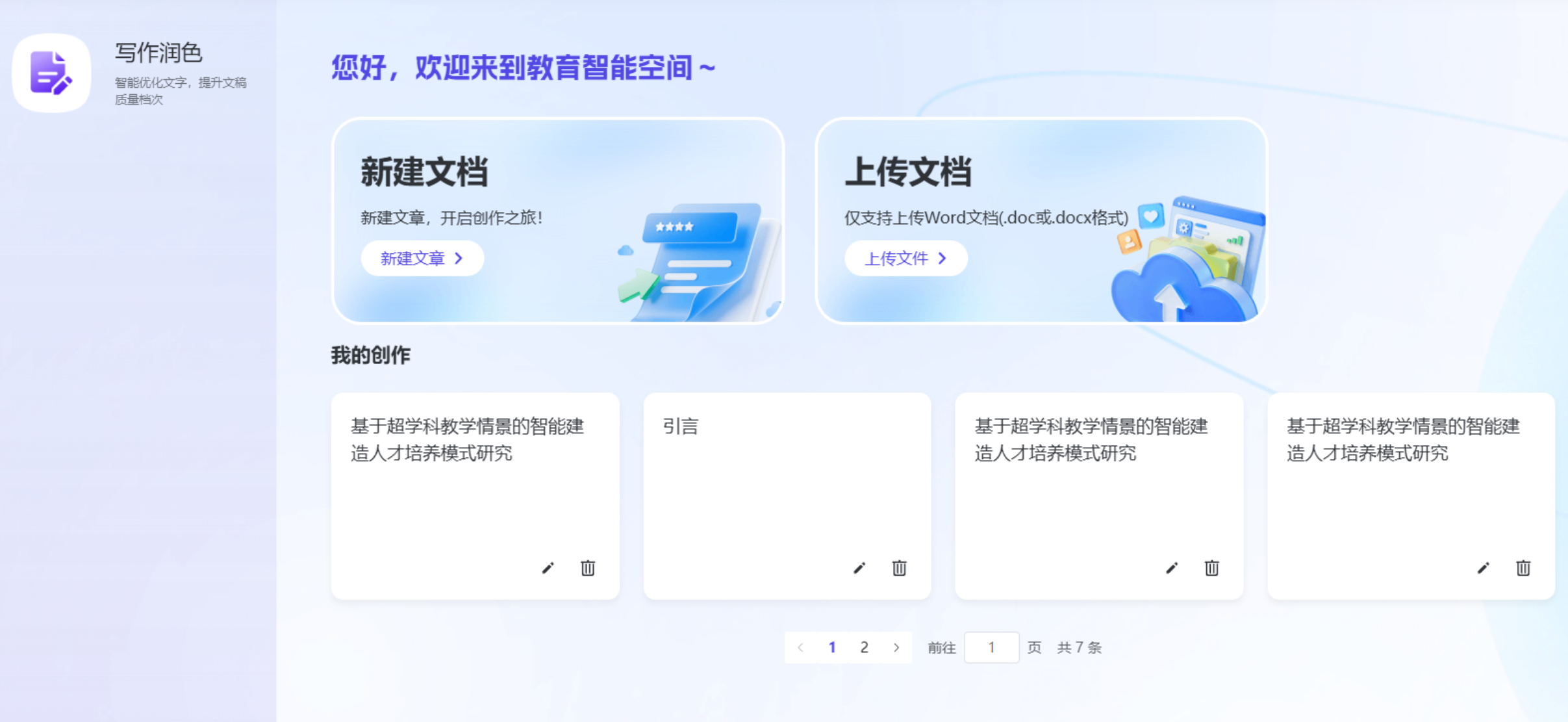
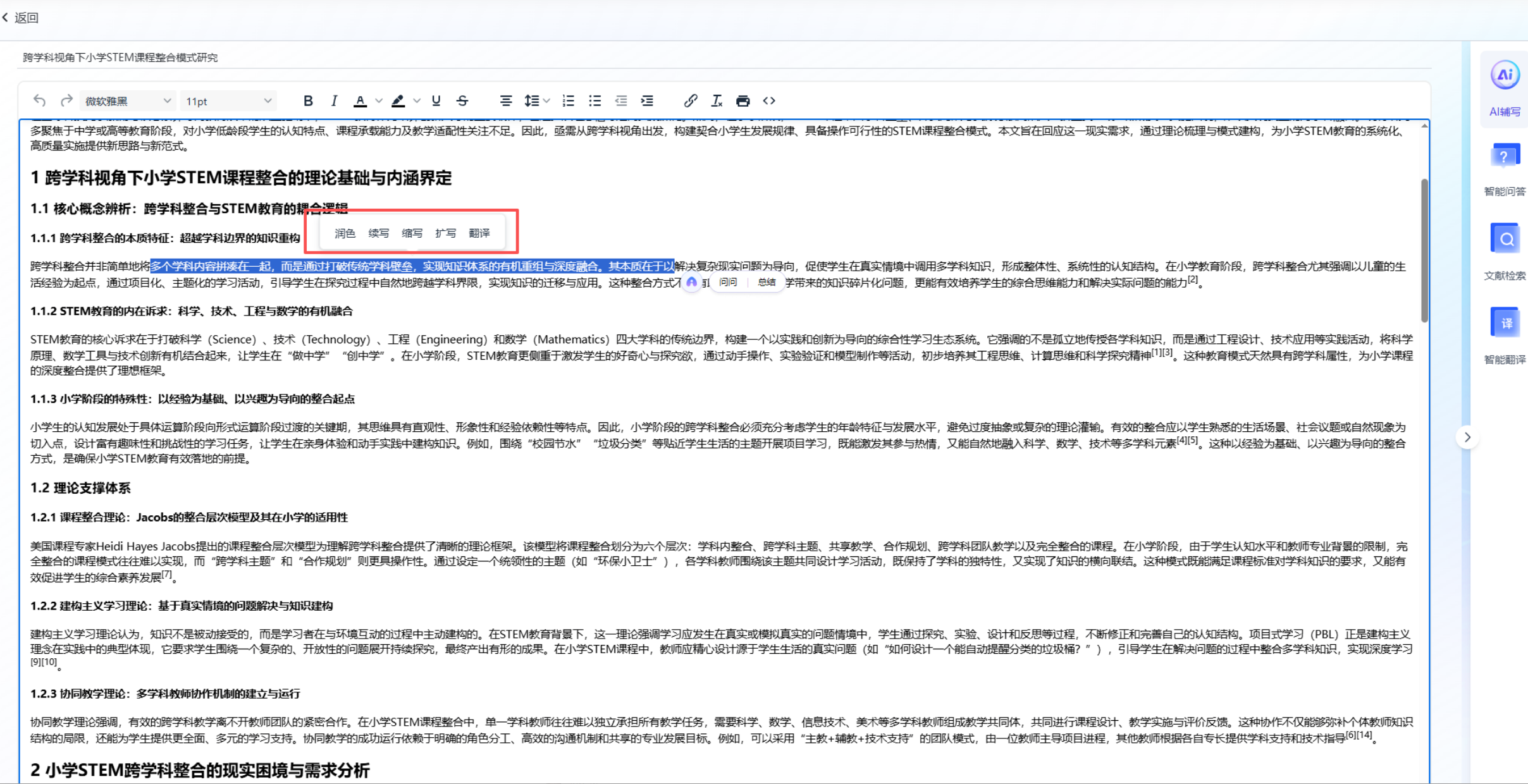
- 选择润色方向:润色、续写、缩写、扩写、翻译。
- 输出结果:获取优化后的学术文本。同时支持智能问答和文献检索,多维度辅助优化。
2.6 精准匹配,高效投稿 —— “投稿选刊”智能体
痛点:论文写好了,投向哪家期刊?盲目投稿导致反复被拒,浪费时间。
技术逻辑:
基于真实投稿数据与官方期刊指标(而非 AI 猜测),进行多维度的匹配分析。
实操步骤:
- 进入“投稿选刊”智能体 → 填写论文相关信息。
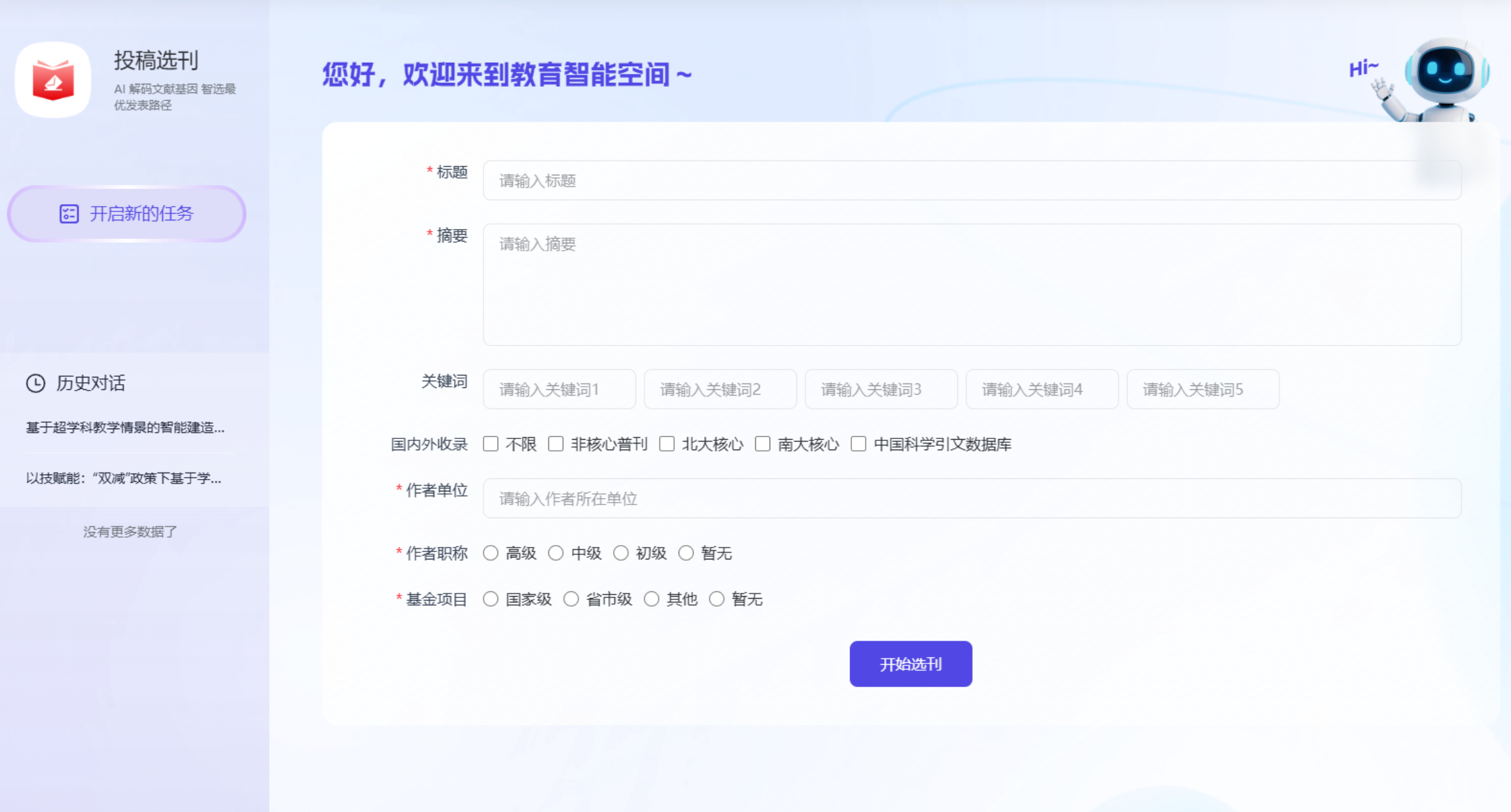
- 输出结果:AI 根据以下维度智能推荐全球主流期刊:
- 期刊收录偏好关联
- 投稿难度系数
- 学术产出效能
- 论文创新评估指数

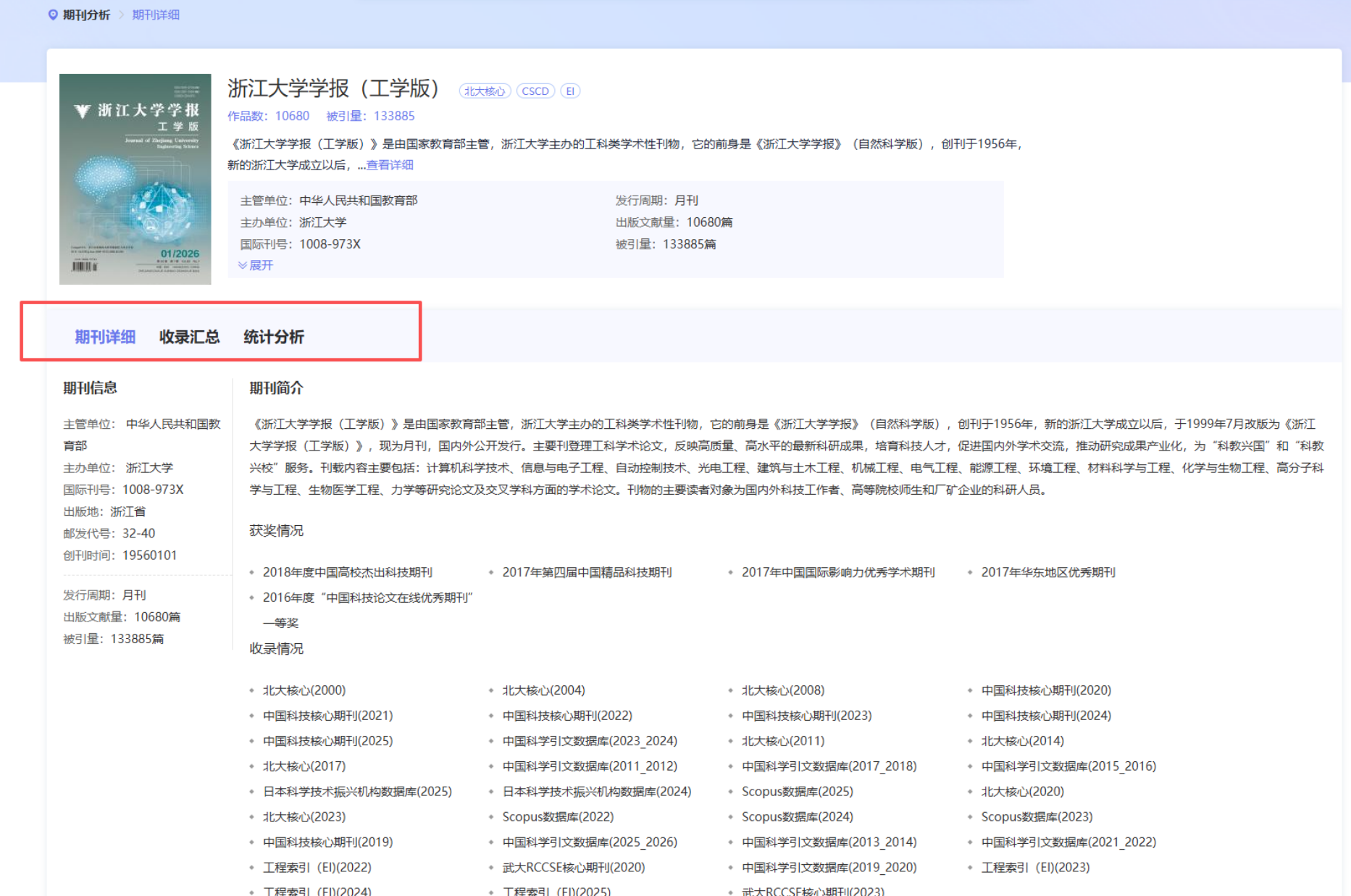
- 深度详情:点击期刊名,可查看收录汇总、发文统计等详细信息,帮助用户锁定目标,提高录用几率。
三、深度对比:通用大模型 vs 维普智教
为了更直观地展示差异,我们从以下几个维度进行对比:
表格
| 维度 | 通用大模型 (Generic LLM) | 维普智教 (Weipu Zhijiao) | 核心差异 |
|---|---|---|---|
| 数据底座 | 互联网通用语料,混杂噪音 | 维普海量真实学术期刊库 | 真实性 |
| 文献引用 | 高频出现虚构文献(幻觉) | 100% 真实存在,附带原文链接 | 可溯源 |
| 选题依据 | 基于概率预测,可能为伪热点 | 基于真实期刊热点数据 | 前瞻性 |
| 综述生成 | 拼凑摘要,逻辑松散 | 基于多篇真实文献的深度归纳 | 逻辑性 |
| 投稿推荐 | 凭印象猜测,缺乏数据支撑 | 基于真实投稿数据与官方指标 | 精准度 |
| 适用场景 | 创意灵感、日常问答 | 严肃学术写作、课题申报、论文发表 | 专业性 |
结论:在严肃的科研场景下,“可验证性”是第一原则。维普智教通过将 AI 能力锚定在真实学术资源上,从根本上解决了“幻觉”问题,使其成为真正可用的科研生产力工具。
四、最佳实践:如何构建“人机协同”的科研新范式?
工具再强大,也只是辅助。为了最大化发挥维普智教的效能,建议遵循以下Best Practices:
- 选题阶段:人机互补
- 利用“科研选题”智能体获取灵感和数据支撑,但研究者需结合自身的专业判断,筛选出最具价值的方向。
- 综述阶段:严格筛选
- 在使用“多篇综述”时,务必人工勾选高质量的核心期刊文献。遵循“Garbage In, Garbage Out”原则,确保输入源的权威性。
- 写作阶段:逻辑把控
- AI 生成的长文是高质量的初稿(Draft)。研究者应重点关注其逻辑链条是否严密,论据是否充分,并进行必要的深度加工和创新点升华。
- 投稿阶段:动态调整
- 利用“投稿选刊”获取推荐列表后,建议进一步查阅目标期刊的最新征稿启事,确保论文主题与期刊当期关注点高度契合。
五、结语
AI 浪潮不可逆转,但科研的严谨本色不能丢。
维普智教的价值,不在于替代研究者的思考,而在于将研究者从繁琐的检索、阅读、排版和格式调整中解放出来,让他们有更多的时间去思考“什么是真问题”、“什么是真创新”。
从选题到投稿,这套“零幻觉”的全流程智能体矩阵,或许正是开启科研效率新纪元的钥匙。
互动讨论:
你在科研写作中是否遭遇过 AI“胡编乱造”的坑?对于“AI+ 真实文献库”这种垂直模式,你看好吗?欢迎在评论区留言,我们一起探讨 AI 时代的科研新范式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)