RAG 系统评估终极指南——从底层算法到 LLM-as-Judge 新范式
RAG系统评估:从检索到生成的全面优化 RAG(检索增强生成)系统结合了信息检索与大模型生成能力,但实际应用中常面临检索不准、生成幻觉等问题。本文系统性拆解RAG评估方法: 双核架构特性 检索器决定上下文质量,生成器影响答案准确性 级联误差导致端到端性能急剧下降(如80%检索+80%生成≈64%准确率) 检索模块评估 核心指标:Recall@K、MRR、NDCG 工程实现:Python代码示例展示
文章目录
✍️ 引言:为什么你的 RAG 总是“听不懂人话”?
“为什么我的 RAG 系统一演示就翻车?”
“加了最新的 BGE 向量模型,为什么回答还是在胡说八道?”
作为一名架构师,过去两年里我听到了太多这样的抱怨。2024到2026年,RAG(Retrieval-Augmented Generation) 无疑是企业拥抱生成式 AI 最成熟、最火热的架构。它巧妙地给患有“知识更新停滞症”和“重度幻觉症”的大语言模型(LLM)塞了一本“开卷考试的参考书”。
然而,搭建一个 Demo 只需要 50 行代码,但把准确率从 60% 提升到 90%,却需要一个极其庞大且精细的评估工程。如果你没有一套科学的评估体系,所谓的“优化”就像是蒙着眼睛在高速上开车——你根本不知道自己是在前进还是在倒退。
今天,我们将花一万字的篇幅,系统性地扒开 RAG 评估的“黑盒”,从传统的 IR(信息检索)指标,到最前沿的 LLM-as-Judge 范式,再到业界主流的评估框架与基准。准备好咖啡,我们发车!
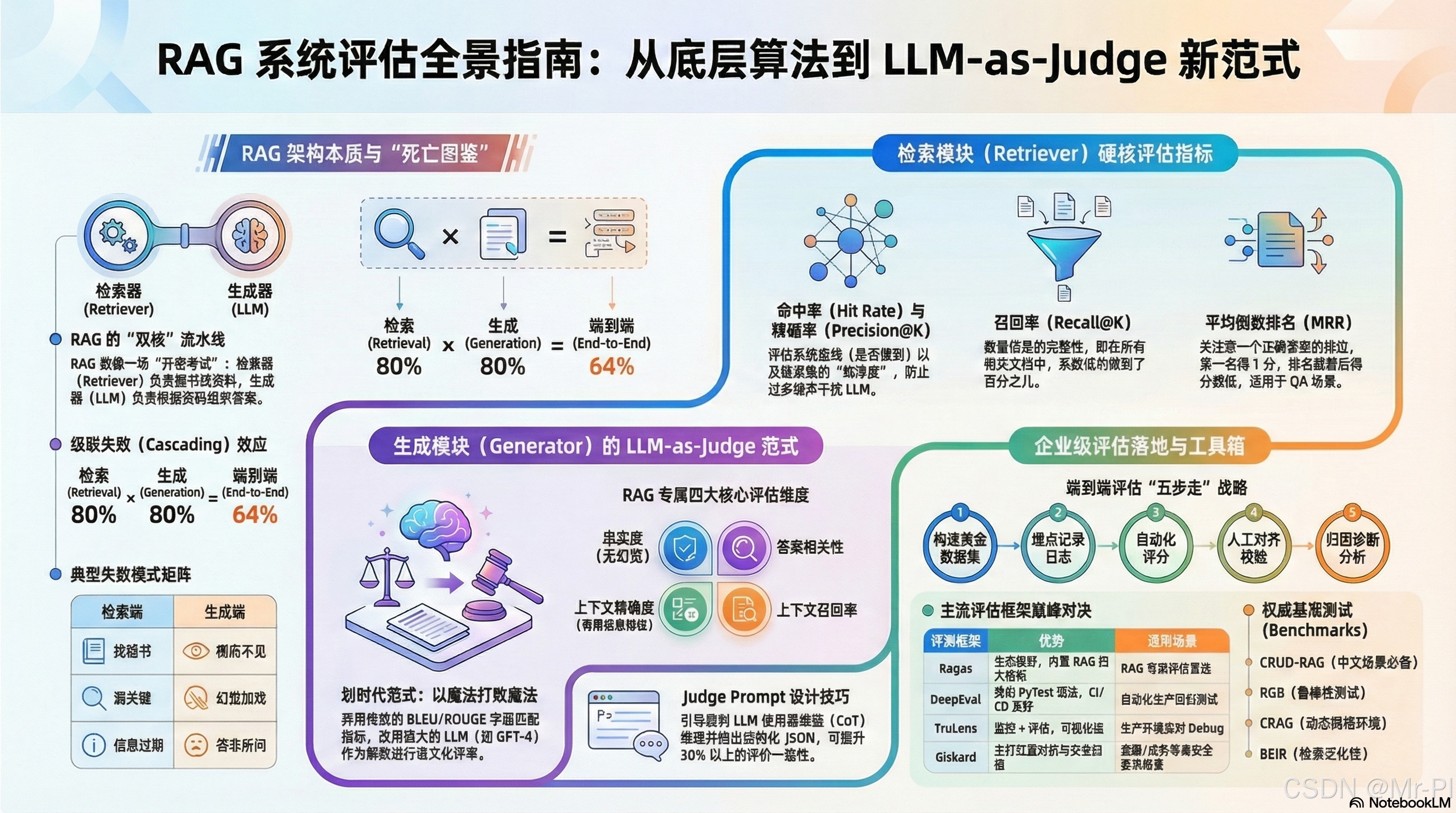
1. RAG 架构的“双核”本质:不只是检索+生成
要评估一个系统,首先要透彻理解它的流转机制。
RAG 的本质是一个流水线作业(Pipeline)。我们可以用“开卷考试”来比喻这个过程:用户提出问题(考题),检索器(Retriever) 就像是一个翻书极快但不怎么动脑子的图书管理员,负责从海量知识库中找出相关的段落(参考资料);生成器(Generator / LLM) 则是一个绝顶聪明但记忆不准的学霸,他根据图书管理员找来的资料,组织语言写出最终答案。
这个双核架构带来了巨大的优势:
- 时效性:只要更新向量库,模型就能知道今天早上发生的新闻。
- 可溯源:每一句话都可以对应到检索出的具体 Chunk,业务人员敢用。
但同时,它也带来了致命的级联雪崩效应。
2. 评估的阿喀琉斯之踵:误差是如何放大的?
为什么 RAG 的评估如此棘手?因为在一个 Pipeline 中,错误是乘法关系,而不是加法关系。
假设你的检索器准确率是 80%,生成器的准确率是 80%,那么端到端的理论准确率可能只有 0.8 × 0.8 = 0.64(64%)。这被称为级联失败(Cascading Failures)。
我们来看看 RAG 系统中典型的失败模式矩阵:
💡 架构师忠告:
很多新手喜欢把所有的优化精力都放在换更强大的 LLM(比如从 Llama-3 换到 GPT-4o)上。但如果你塞给 GPT-4o 的都是垃圾上下文,它也只能生成“高情商的垃圾”。垃圾进,垃圾出(Garbage In, Garbage Out) 在 RAG 中体现得淋漓尽致。
这就要求我们的评估必须分而治之:既要评估检索的“准度”,也要评估生成的“纯度”,最后还要评估端到端的“综合度”。
3. 拆解检索模块(Retriever):用传统 IR 智慧武装自己
在这一步,我们暂时忘掉大模型,回归到经典的信息检索(Information Retrieval, IR) 领域。我们要评估的是:系统能不能把最相关的文档,排在最前面?
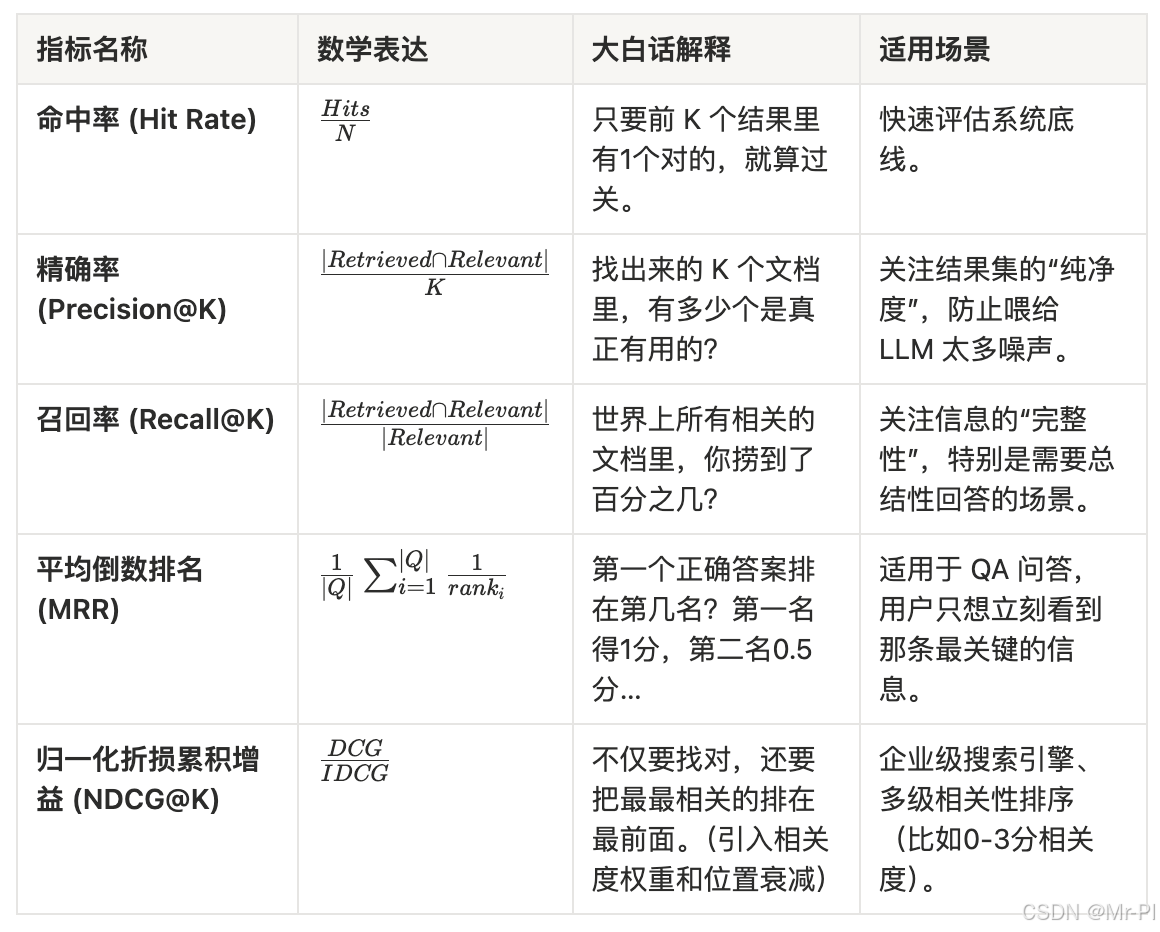
3.1 核心数学指标速查手册
这里我们要引入几个硬核指标,建议结合公式理解:
3.2 💡 算法工程师的 Python 实战宝典
别看公式吓人,在工程实现上非常简单。下面我写了一套可以直接在生产环境复用的 Python 评估代码(用 NumPy 加速计算):
import numpy as np
from typing import List
# 模拟数据:retrieved_lists 是 RAG 检索回来的文档 ID
# relevant_lists 是人工标注(Ground Truth)的正确文档 ID
retrieved = [['doc_1', 'doc_2', 'doc_3', 'doc_4', 'doc_5'], # Query 1 检索结果['doc_9', 'doc_8', 'doc_7', 'doc_6', 'doc_5'] # Query 2 检索结果
]
relevant =[
['doc_2', 'doc_3'], # Query 1 真正相关的文档['doc_10'] # Query 2 真正相关的文档(不幸没搜到)
]
def eval_recall_at_k(retrieved_lists: List[List[str]], relevant_lists: List[List[str]], k: int = 3) -> float:
"""计算 Recall@K:真实答案中有多少被检索到了"""
scores =[]
for ret, rel in zip(retrieved_lists, relevant_lists):
if not rel: continue # 容错处理
# 截取前 K 个检索结果
ret_k = ret[:k]
# 计算交集
intersect = len(set(ret_k) & set(rel))
scores.append(intersect / len(rel))
return np.mean(scores)
def eval_mrr(retrieved_lists: List[List[str]], relevant_lists: List[List[str]]) -> float:
"""计算 MRR (Mean Reciprocal Rank):第一个相关文档越靠前,分数越高"""
rr =[]
for ret, rel in zip(retrieved_lists, relevant_lists):
rel_set = set(rel)
found = False
for rank, doc in enumerate(ret, start=1):
if doc in rel_set:
rr.append(1.0 / rank)
found = True
break
if not found:
rr.append(0.0)
return np.mean(rr)
# 测试执行
k_val = 3
print(f"🔥 Recall@{k_val}: {eval_recall_at_k(retrieved, relevant, k_val):.4f}")
print(f"🔥 MRR: {eval_mrr(retrieved, relevant):.4f}")
# 输出:
# 🔥 Recall@3: 0.5000 (Query1命中2个中的1个=0.5,Query2命中0个=0,求均值)
# 🔥 MRR: 0.2500 (Query1在第2个位置命中=0.5,Query2=0,求均值)
实战避坑指南:很多初级开发只看 Recall 不看 Precision。如果在生产中把 K 设为 20,Recall 当然高,但 LLM 的上下文窗口会被塞满无关垃圾,导致生成注意力涣散(Lost in the Middle 现象)。因此,评估时务必监控 Precision/Recall 的折中曲线(PR Curve)。
4. 拆解生成模块:从老旧的 NLP 指标到 LLM-as-Judge 的飞跃
检索有了结果,现在压力来到了大模型这边。我们要评估它的“作文水平”。
4.1 传统指标的陨落与挣扎
在 LLM 爆发前,NLP 领域评估文本主要靠“数词汇”。
- BLEU & ROUGE:基于 N-gram 的字面重合度。如果标准答案是“手机是苹果公司在2007年发布的”,模型回答“苹果于2007年推出了iPhone”,虽然意思完全一致,但由于字面词汇不同,BLEU 得分会极低。在 RAG 中,这俩指标基本已被淘汰。
- 语义嵌入指标(BERTScore / MoverScore):利用小模型(如 BERT)将句子转为向量算相似度。比字面匹配强,但仍无法捕捉深层的逻辑矛盾(如“包含”与“不包含”仅仅差一个字,向量相似度极高,但意思截然相反)。
4.2 🌟 划时代范式:LLM-as-Judge(大模型做裁判)
进入 2024 年后,业界达成共识:用魔法打败魔法。只有强大的 LLM,才能听懂另一个 LLM 在说什么。
使用 GPT-4o 或 Claude 3.5 作为自动评审员(Judge),通过精心设计的 Prompt 给出分数和理由。
RAG 专属的四大 LLM-as-Judge 核心评估维度:
- 🎯 忠实度 (Faithfulness)
- 拷问:回答中是否出现了上下文中没有的“幻觉”?
- 算法:让 Judge 把答案拆解成多个原子陈述(Atomic Statements),逐一在上下文中寻找依据。
- 🔗 答案相关性 (Answer Relevancy)
- 拷问:模型是在一本正经地答非所问吗?
- 算法:从生成的答案中反向推导(Reverse-engineer)出问题,算反向推导出的问题与原问题的语义相似度。
- 📐 上下文精确度 (Context Precision)
- 拷问:检索出来的文档,对最终的回答有多大用处?有用的是不是排在前面?
- 📏 上下文召回率 (Context Recall)
- 拷问:相比于理想的参考答案(Ground Truth),检索到的上下文是否包含了所有必要的信息?
代码级巧思:如何写一个 Judge Prompt?
我们不能简单地问 LLM “请打1-10分”。高级的做法是让模型先输出推理步骤(Chain of Thought),然后输出结构化 JSON。这能让一致性提升 30% 以上。
5. 端到端评估:构建企业级评测流水线
作为系统架构师,我们要从全局视角看问题。局部的最优不代表全局的最优。
如何实施一次科学的端到端 RAG 评估?请严格遵守这 “五步走”战略:
- 构建黄金测试集 (Golden Dataset)
- 不要用人工瞎编的数据!去收集真实用户的历史 QA。
- 数据结构必须包含四元组:
[用户问题 (Question), 标准答案 (Ground Truth), 理想上下文集合 (Golden Contexts)] - 建议规模:日常迭代 100-200 条,发版基准测试 1000+ 条。
- 跑批与埋点记录
- 在测试环境中运行 RAG 系统,记录每一个请求的完整生命周期日志(尤其是检索回来的 Raw Text 和最终生成的 Text)。
- 多维度的自动化评分
- 并发调用 Judge 模型计算 RAG 专属四大指标。
- 一致性校验与人工对齐 (Human Alignment)
- 自动化指标不可全信。每月抽取 10% 的数据进行人工盲评。使用李克特 5 分量表(Likert Scale),并计算 Fleiss’ Kappa 值来验证自动评分与人类评分的相关性。
- 归因与诊断分析
- 案例:如果 Context Recall 高,但 Faithfulness 低 → \rightarrow → 说明检索很给力,但生成模型太弱或者 Prompt 没写好,建议微调(SFT)大模型。
- 案例:如果 Context Recall 低,但生成答案不错 → \rightarrow → 说明大模型在靠自己的内部知识“盲答”,这是个极度危险的信号(随时会产生幻觉),必须优化检索策略(如引入混合检索、查询重写)。
6. 🛠️ 实用工具箱:2025-2026 主流框架巅峰对决
不要重复造轮子!当下业界已经诞生了一批非常成熟的开源框架。我为您做了一个横向对比:
| 评测框架 | 核心标签 | 优势 (Pros) | 劣势 (Cons) | 适用场景 |
|---|---|---|---|---|
| 🟠 Ragas | 行业老大哥 | 首创 RAG 核心四大指标,生态极好(无缝对接 LangChain/LlamaIndex),内置数据集生成功能。 | 内部写死了很多 Prompt,修改不太灵活;大规模评测较慢。 | RAG 专项评估的首选。 |
| 🔵 DeepEval | 全家桶+工程化 | 类似 PyTest 的语法,对 CI/CD 极其友好。提供 Confident AI 可视化面板,支持测试大语言模型的偏见、毒性等全方位指标。 | 概念稍微庞杂,有一定的学习曲线。 | 适合研发团队搭建自动化的生产回归测试。 |
| 🟢 TruLens | 可观测性驱动 | 核心理念是“监控(Tracing)+ 评估(Eval)”。能清晰看到 LangChain 内部每一个组件的耗时和得分(Groundedness)。 | 需要深入嵌入业务代码,侵入性较强。 | 生产环境实时监控与 Debug。 |
| 🟣 Giskard | 安全与漏洞扫描 | 主打红蓝对抗(Red Teaming)。不仅测指标,还能自动生成 Prompt 注入攻击、测试系统的鲁棒性。 | RAG 专项的细粒度指标不如 Ragas 丰富。 | 金融/政务等对安全合规要求极高的系统。 |
🚀 实战演示:用 Ragas 跑通你的第一次评估
这里给大家展示一段使用 Ragas 的现代化 Python 代码。只要你有数据,5分钟就能拿到专业报告:
# 安装: pip install ragas datasets
import os
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
# 1. 准备你的测试数据字典 (注意字段名是规范的)
data = {
"question":[
"2026年马斯克发布了什么新产品?",
"深度学习中Transformer的核心机制是什么?"
],
"answer":[
"根据资料,马斯克在2026年发布了脑机接口的最新家用头盔版本。",
"Transformer 的核心机制是自注意力(Self-Attention)机制。"
],
"contexts": [["马斯克旗下的 Neuralink 昨天举行发布会,正式推出了代号为 'MindLink' 的2026款家用脑机接口头盔。"],["在自然语言处理中,模型结构非常重要。"] # 故意给一条烂上下文,测试评估器的反应
],
"ground_truth":[
"2026年马斯克发布了家用脑机接口头盔。",
"核心机制是自注意力(Self-Attention)机制。"
]
}
# 2. 转换为 HuggingFace Dataset 格式
dataset = Dataset.from_dict(data)
# 3. 配置 LLM 作为裁判 (默认使用 OpenAI 环境变量 OPENAI_API_KEY)
# os.environ["OPENAI_API_KEY"] = "sk-xxxxxx..."
# 4. 一键执行评估
print("🚀 正在召唤 LLM-Judge 进行评估,请稍候...")
result = evaluate(
dataset,
metrics=[faithfulness, answer_relevancy, context_precision, context_recall],
)
# 5. 打印华丽的成绩单
print("\n📊 RAG 评测结果报告:")
print(result)
# 预期结果:
# {'faithfulness': 0.95, 'answer_relevancy': 0.92, 'context_precision': 0.50, 'context_recall': 0.50}
7. 眺望前沿:CRUD-RAG、RGB 等核心基准与未来趋势
除了工具,学术界和工业界还构建了海量的基准测试集 (Benchmarks)。它们就像是“全国统考试卷”,让不同的模型和方案能在同一个起跑线上比拼。
7.1 必读的四大神仙基准
- 📦 CRUD-RAG (2024 中文巨作)
复旦大学等提出的体系。它把 RAG 的行为极其精妙地映射为数据库的四大操作:- C (Create):创造性生成(如:写一篇关于某论文的总结)。
- R (Read):精准阅读问答(如:财报中具体的数字是多少)。
- U (Update):纠错能力(当检索内容有误时,模型能否识别并更新)。
- D (Delete):总结与浓缩能力。
- 价值:打破了传统纯 QA 的局限,覆盖了更广泛的企业级场景。
- 🌈 RGB (鲁棒性之王)
测试模型在“有噪声(Noise)”和“信息被截断”时的表现。你的模型是会被误导,还是能坚定地辨别真伪? - 🦀 CRAG (Comprehensive RAG)
Meta 团队开源的动态基准。它不局限于本地文档,而是模拟真实生产环境去调用 Web 搜索引擎的 Mock API,评估系统融合静态知识与动态网络信息的能力。 - 🔬 BEIR
评测检索模块(Embedding/BGE 模型)的试金石。包含18个异构数据集,测试你的检索器在没见过的领域(Zero-shot 泛化)是不是还能搜得准。
7.2 🔮 2026 评估风向标 (未来趋势)
未来的 RAG 将不再是简单的检索拼接,而是升级为Agentic RAG(基于智能体的 RAG)。它会自己规划、自己调用工具、甚至自己纠错。相应的评估也将从静态的“结果对比”走向对“推理过程(Trajectory)”的动态评估。
8. ✅ 架构师的最佳实践清单:干货带走
读到这里,知识已经足够密集。为了让你明天上班就能用上,我整理了一份《RAG 评估落地执行清单》:
- 先定规矩再干活:千万不要在没有构建至少 100 条高质量评测集(包含 Ground Truth)之前,去盲目调整 Chunk Size 或换 Embedding 模型。
-[ ] 引入法官:抛弃 BLEU 和 ROUGE。立刻在你的链路中集成 Ragas 或 DeepEval,使用 GPT-4o 级别模型作为 Judge 计算Faithfulness和Relevancy。 - 警惕数字陷阱:不要追求 100% 的 Recall。关注 Precision,减少送到 LLM 嘴边的“垃圾”才是减少幻觉的根本。
- 闭环思维:建立 CI/CD 质量门禁(Quality Gates)。每次代码或模型合并前,自动化跑一遍评估,分数下降则阻止合并。
- 尊重常识:虽然大模型打分很快,但每个版本发布前,务必保留 50-100 条数据进行人工盲审对齐。人的体感,永远是产品的最后一道防线。
9. 参考文献与拓展阅读
(为保持文章的严谨性,附上核心文献,强烈建议进阶读者深读)
- Gan, A. et al. (2025). Retrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey. (系统性综述的顶梁柱)
- Lyu, Y. et al. (2024). CRUD-RAG: A Comprehensive Chinese Benchmark… (做中文场景必读)
- Es, S. et al. (2024). Ragas: Automated Evaluation of Retrieval Augmented Generation.
- Meta AI (2024). CRAG: Comprehensive RAG Benchmark.
感谢阅读到这里!如果这篇文章解开了你对于 RAG 评估的疑惑,欢迎点赞、收藏并在评论区留下你在业务中遇到的 RAG “奇葩翻车”案例,我们一起探讨! 👇👇👇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)