Dataiku 入门 - Core Designer-2-Visual Recipes可视化步骤
本教程详细介绍了Dataiku DSS Core Designer中Visual Recipes全流程操作指南。主要内容包括:1) 关联(Join)插件使用,通过合并交易、商户和卡片数据实现数据整合;2) 准备(Prepare)插件进行数据清洗转换,包括日期处理、数字转换和文本清理;3) 分组(Group)插件按卡号聚合消费数据;4) 窗口(Window)插件实现滑动窗口分析;5) TopN插件筛

第二期~涵盖完整的Core Designer-Visual Recipes全流程。
Dataiku DSS Core Designer-Visual Recipes
可视化步骤
教程| 关联 (Join) 插件
本教程将介绍如何使用关联(Join) 插件,通过合并多个数据集来丰富数据信息。
项目目标
将以下三个数据集整合为一个:
tx (交易数据): 包含信用卡交易 ID、信用卡 ID (card_id)、商户 ID (merchant_id) 及授权状态。
merchants (商户数据): 包含商户位置、类别等。
cards (卡片数据): 包含持卡人信用评分 (FICO) 及激活月份。
分步教程
1. 准备关联键 (Join Keys)
在开始之前,需确认各表之间的关联字段:
tx 与 cards: 使用 card_id (来自 tx) 和 id (来自 cards)。
tx 与 merchants: 使用 merchant_id (来自 tx) 和 id (来自 merchants)。
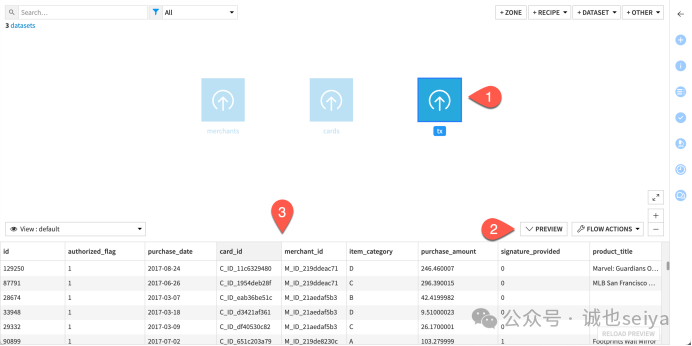
2. 创建并配置关联插件
第一步:建立tx 与 cards 的关联
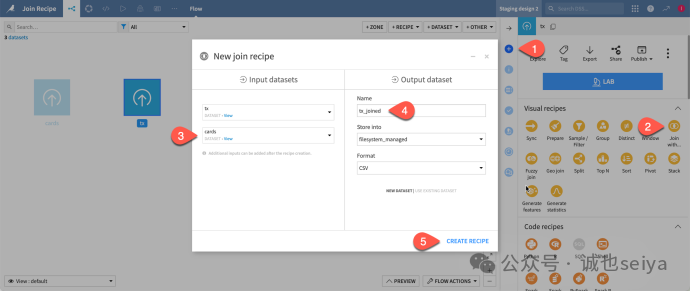
1.在Flow 界面选中 tx,点击右侧 Join with...。
2.选择 cards 作为第二个输入集,输出命名为 tx_joined。
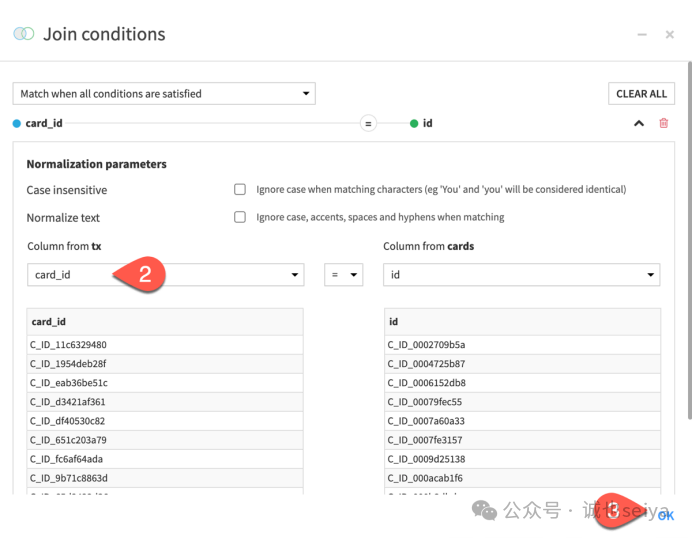
3.定义条件: 在 Join 步骤中,手动将匹配列从 id 修改为 card_id (tx 表) 匹配 id (cards 表)。
关联类型: 默认使用 Left Join (左关联),保留所有交易记录。
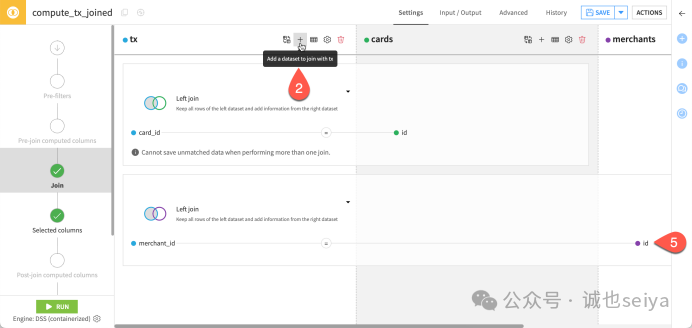
第二步:添加第三个数据集(merchants)
无需新建插件,在当前Join 步骤点击+ 号。
添加merchants 数据集。
设置关联条件:使用merchant_id (tx
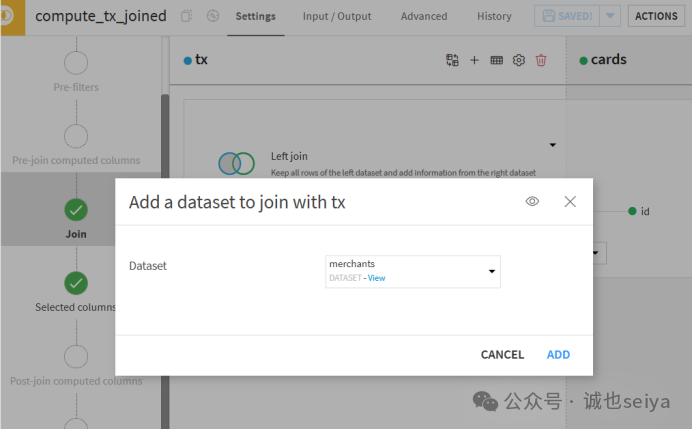
表) 匹配 id (merchants 表)。
默认情况下,recipe将删除不匹配的行,但是我们也可以配置recipe将不匹配的行发送到另一个输出数据集
3. 选择列与重命名
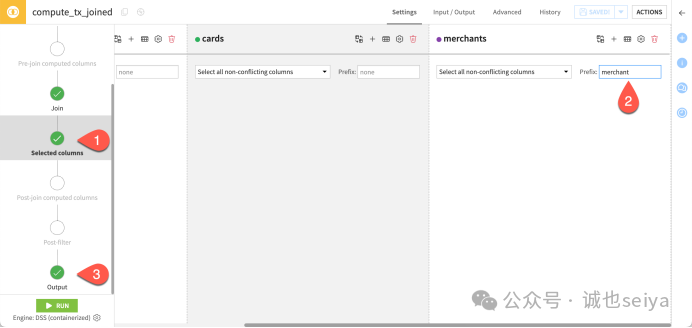
为了避免列名冲突(例如两张表都有id 或 category),可以在 Selected columns 步骤进行优化:
添加前缀: 为 merchants 数据集的所有列添加前缀 merchant_。
筛选字段: 勾选需要保留的列,剔除重复或无用的字段。
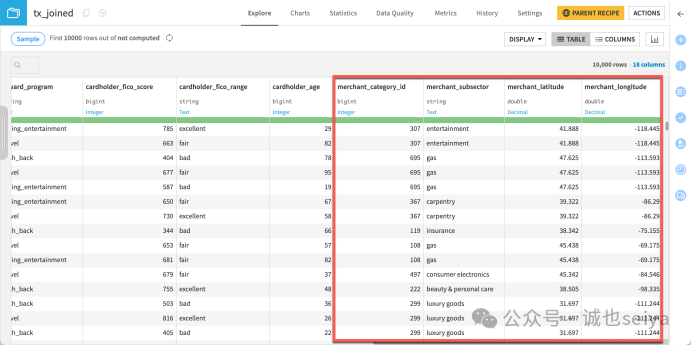
4. 执行与结果
点击Run 执行。完成后查看 tx_joined,你会发现原始交易数据已成功合并了卡片信息和带有 merchant_ 前缀的商户信息。
教程| 准备 (Prepare) 插件
在完成数据集关联后,我们得到了tx_joined。现在,我们将使用 准备(Prepare) 插件 对数据进行清洗、转换和富化。
项目目标
创建Prepare 插件并定义处理步骤(Script)。
处理日期、数字和文本数据。
使用Dataiku 公式语言 (Formula)。
分步步骤
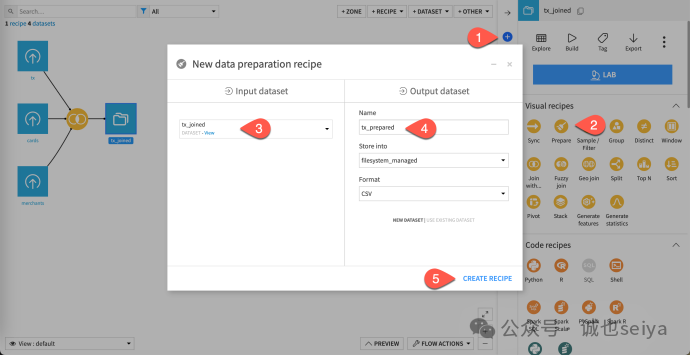
1. 创建 Prepare 插件
在Flow 中选中tx_joined,点击右侧操作栏的 Prepare。
将输出数据集命名为tx_prepared,点击 Create Recipe。
2. 日期处理 (Date Processing)
日期通常以字符串形式导入,需要解析后才能进行计算。
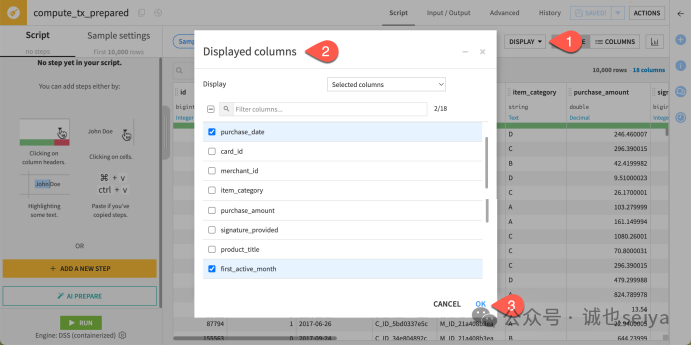
筛选显示列(可选): 为了专注操作,点击右上角 Display > Select displayed columns,仅勾选 purchase_date 和 first_active_month。
解析purchase_date:
点击脚本面板底部的+ Add a New Step,搜索 Parse to standard date format。
在Column字段中,输入purchase_date 列,点击 Find with Smart Date。
系统会自动识别出yyyy-MM-dd 格式,点击 Use Date Format。该操作会直接覆盖原列。
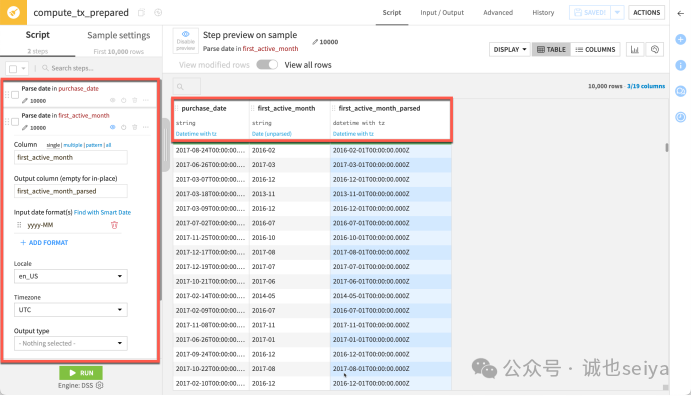
解析first_active_month(快捷操作):
点击该列标题的下拉菜单,直接选择Parse date。
识别格式为yyyy-MM,点击使用。
这会生成一个新列first_active_month_parsed。
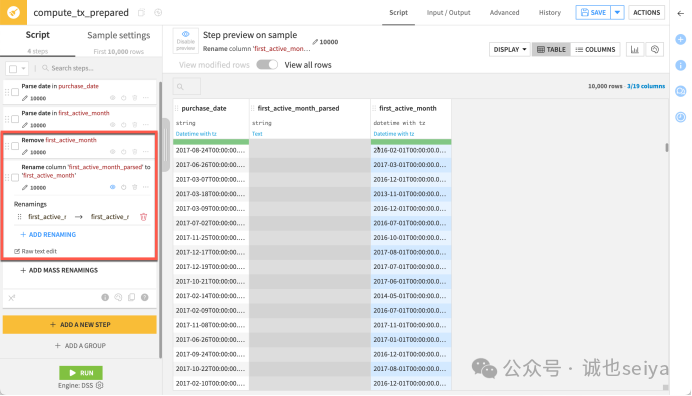
整理字段:
1.点击原 first_active_month 标题下拉菜单,选择 Delete。
2.点击新生成的 first_active_month_parsed,选择 Rename 改回 first_active_month。
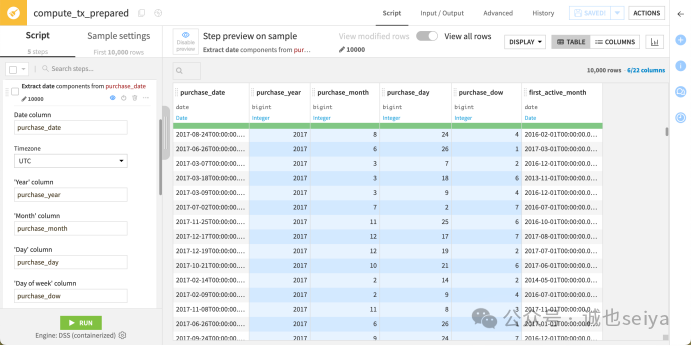
提取日期组件: 点击 purchase_date 下拉菜单选择 Extract date components。在脚本中填入输出列名:purchase_year、purchase_month、purchase_day 和 purchase_dow(注:1 代表周一)。
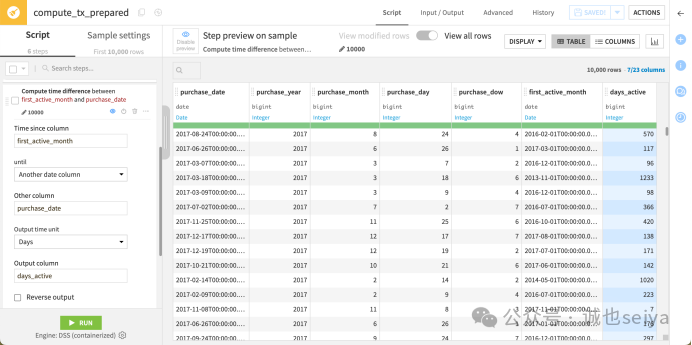
计算活跃天数: 点击 first_active_month 下拉菜单选择 Compute time since。
Until 选择 Another date column。
Other column 选择 purchase_date。
Output unit 设为 Days,命名为 days_active。
3. 数字转换 (Process Numbers)
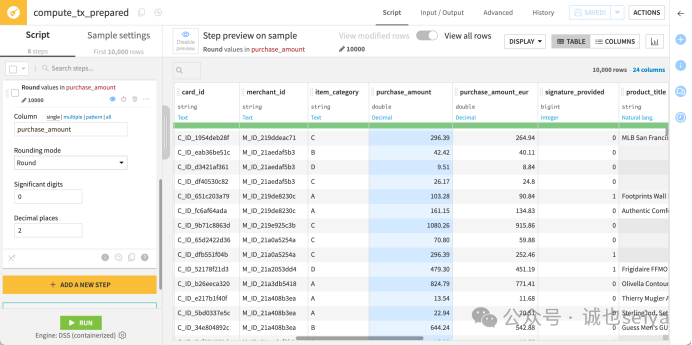
汇率转换: 点击 + Add a New Step,搜索 Convert currencies。
Column: purchase_amount。
From: USD,To: EUR。
Date source: 选择 From Column (Date) 并填入 purchase_date,这样系统会根据当天的历史汇率转换。
四舍五入: 点击 purchase_amount 标题,选择 Round to integer,并将 Decimal places 设置为 2。
4. 文本清理与提取 (Process Text)
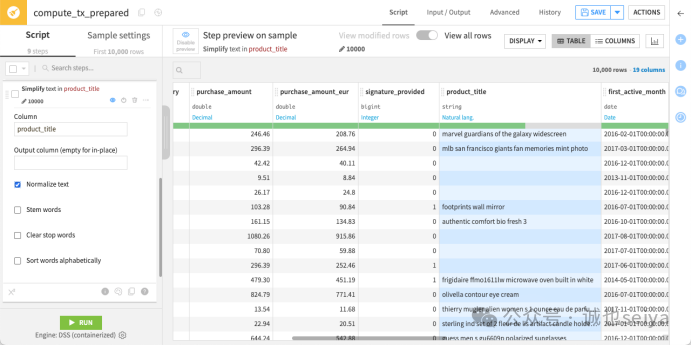
文本规范化: 点击 product_title 标题,选择 Simplify text。这会执行转小写、去标点、去重音等操作。
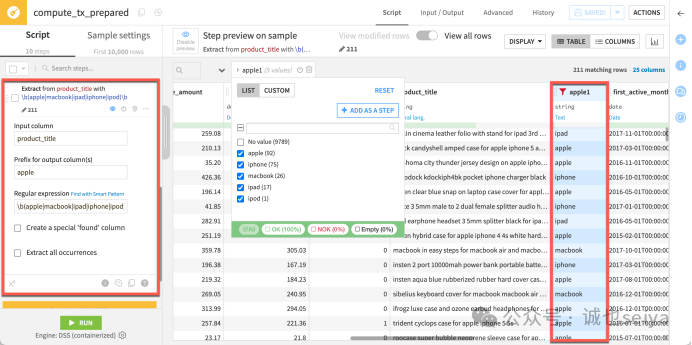
正则提取(Regex): 添加 Extract with regular expression 步骤。
Input column: product_title。
Regular expression: \b(apple|macbook|ipad|iphone|ipod)\b。
Prefix: apple。
提示:你可以通过列过滤器查看提取效果,过滤掉"No value" 的行。
5. 高级公式 (Use a Formula)
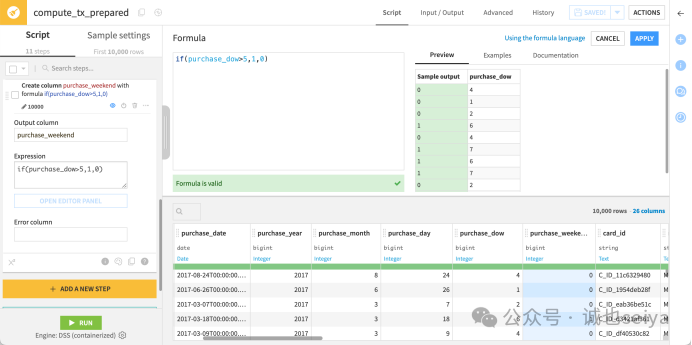
添加Formula 步骤,用于判断周末交易。
Formula for: purchase_weekend。
Formula expression: if(purchase_dow > 5, 1, 0)。
点击Apply 后,你会看到 purchase_dow 为 6 或 7 的行被标记为 1。
6. 整理与运行
步骤分组: 选中脚本面板中前 6 个日期处理步骤,点击 Actions > Group,重命名为 Process dates。
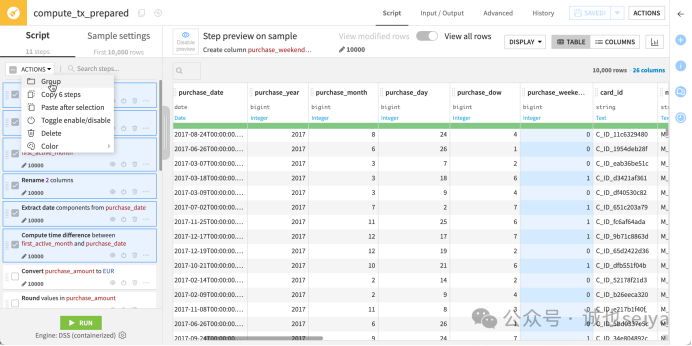
执行: 点击左下角的 Run。完成后点击 Explore dataset tx_prepared 查看最终清洗后的完整数据。
教程| 分组 (Group) 插件
在完成了tx_prepared 数据集的准备工作(解析日期、处理数值和文本等)后,我们将使用 分组(Group) 插件 根据特定字段(键)对数据进行聚合统计。
1. 创建分组插件
分组插件允许您根据一个或多个键(Keys) 的值来聚合其他列的值。
1.在Flow 界面选中 tx_prepared 数据集。
2.在右侧 Actions 面板的 Visual Recipes 栏下,点击 Group。
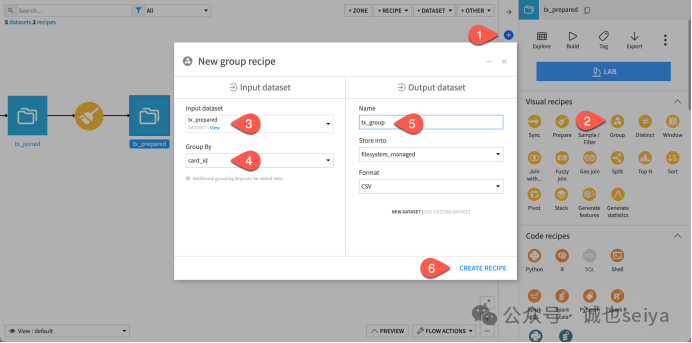
在弹出的对话框中:
3.Input dataset: 保持为 tx_prepared。
4.Group by: 选择 card_id。
5.Output dataset: 命名为 tx_group。
6.点击 Create Recipe。
2. 选择聚合方式 (Aggregations)
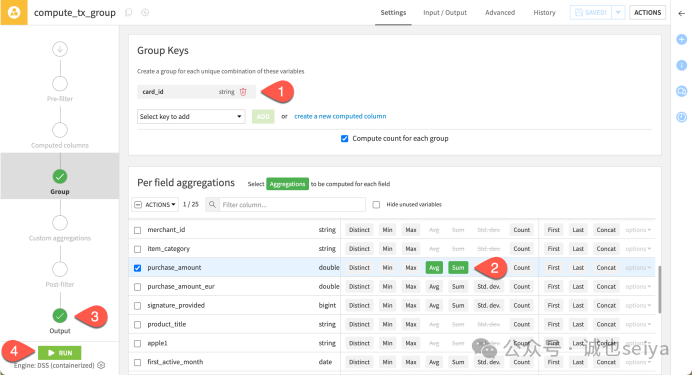
在Group 步骤中,您需要定义如何处理每个分组内的数据。本教程的目标是按卡号分组,并计算每张卡的消费总额和平均消费额。
1.确认分组键: 确保 card_id 已被列为分组键 (Group key)。
2.配置字段聚合(Per field aggregations):
找到purchase_amount 字段。
1.勾选 Avg (平均值)。
2.勾选 Sum (总和)。
默认统计: Dataiku 会默认计算每个分组的 Count (行数,即消费次数)。
提示: 只有数值类型(如 Double)的列才能进行 Sum 和 Avg 计算。插件界面会通过图标提醒您每列的存储类型。
3. 检查输出并运行
查看输出结构: 切换到 Output 步骤。你会发现输出结果仅包含 4 列:分组键 (card_id) 以及三个统计结果列 (count, sum, avg)。
注意: 任何未被选作“分组键”或“聚合字段”的原始列(如 purchase_date)都不会出现在输出结果中。如果您需要在保留原始行的同时添加统计信息,通常需要使用 窗口(Window) 插件。
执行: 点击左下角的 Run。
4. 探索结果
1.打开生成的 tx_group 数据集:
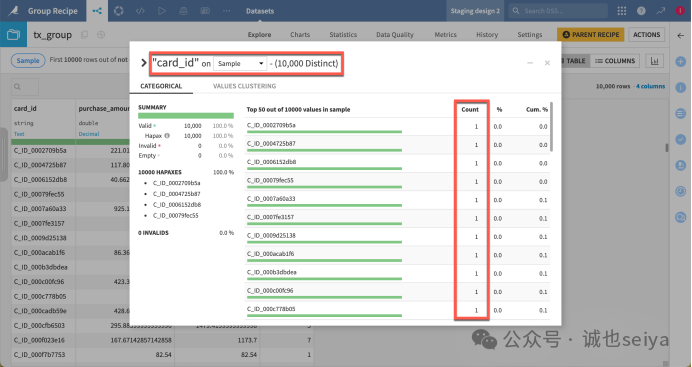
2.点击 card_id 列的下拉菜单,选择 Analyze。
你会发现所有值都是唯一的——这意味着现在每张信用卡在表中只有一行记录,汇总了其所有的交易历史。
教程| 窗口 (Window) 插件
在分组教程中,您学习了如何按卡号聚合数据。现在,我们将使用更高级的窗口(Window) 插件。与分组插件不同,窗口插件可以在保留数据集中每一行记录的同时,执行聚合计算,并允许您通过定义不同的“时间窗口”来观察计算结果的变化。
项目目标
Ø配置不同类型的窗口帧(Window Frame)。
Ø计算每一行的累计总额(Cumulative Sum)。
Ø基于“行数范围”和“数值范围”计算窗口。
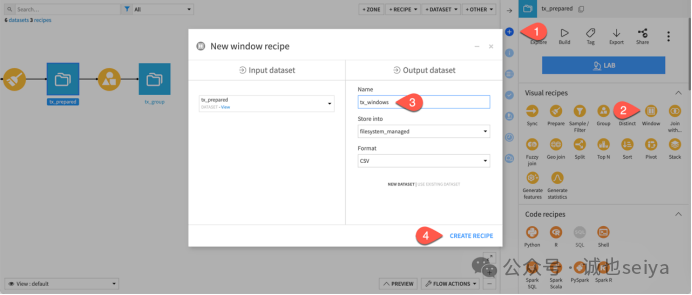
1. 创建窗口插件
1.在Flow 中选中 tx_prepared 数据集。
2.在右侧 Actions 面板点击 Window 插件。
3.将输出数据集命名为 tx_windows,点击 Create Recipe。
2. 使用未定义范围的窗口
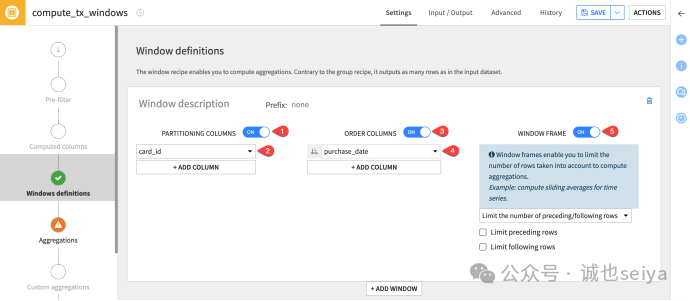
首先练习无边界窗口:按card_id 分组并按日期排序。
Window definitions 步骤:
1.开启 Partitioning Columns(分区列),选择 card_id。
2.开启 Order Columns(排序列),选择 purchase_date。
3.开启 Window Frame,暂不修改默认设置。
Aggregations 步骤: 勾选 purchase_amount 的 Sum。
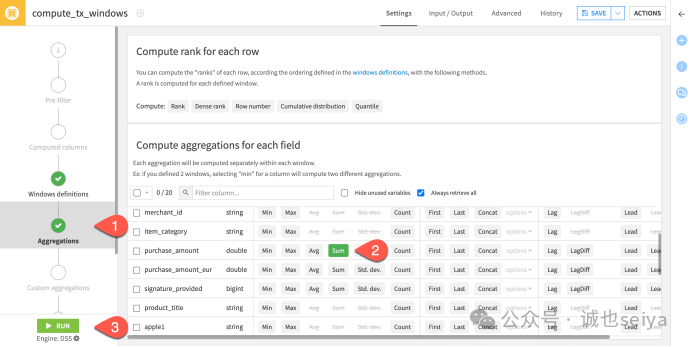
运行并查看: 此时,同一张卡的所有行显示的 purchase_amount_sum 都是相同的,因为窗口包含了该卡的所有记录。
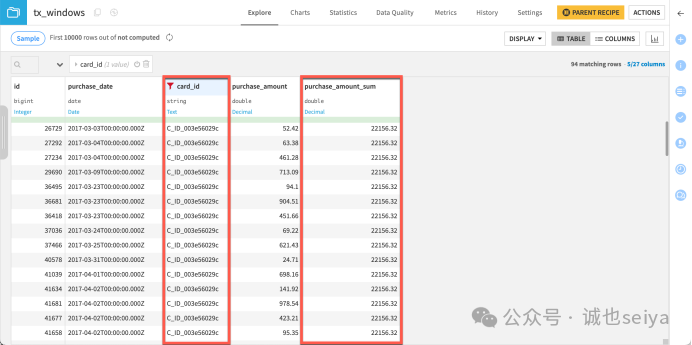
3. 计算累计总额 (Cumulative Sum)
目标:计算每张卡在当前交易日期(含)之前的所有消费总额。
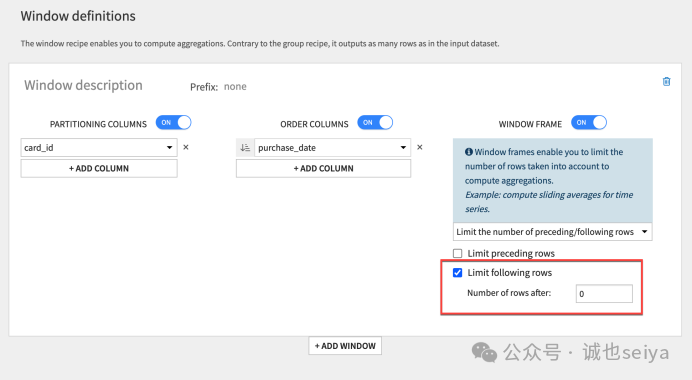
返回插件,在Window Frame 设置中,勾选 Limit following rows 并设为 0。
这表示窗口范围是:从起始行到当前行。
运行结果: purchase_amount_sum 会随着日期增长而递增。
4. 使用“行数”和“数值”范围
A. 基于行数 (Range of rows)
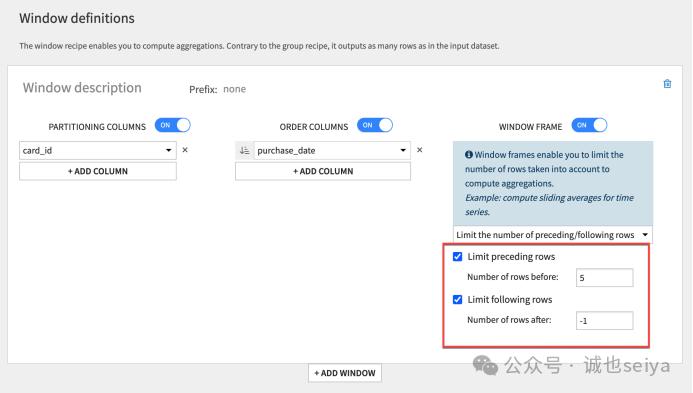
设置固定长度的滑动窗口:
Limit preceding rows: 勾选并设为 5。
Limit following rows: 设为 -1。
结果: 窗口包含当前行之前的 5 行(不含当前行)。消费总额不再持续增长,因为它只计算最近 5 笔交易。
B. 基于数值范围 (Value range)
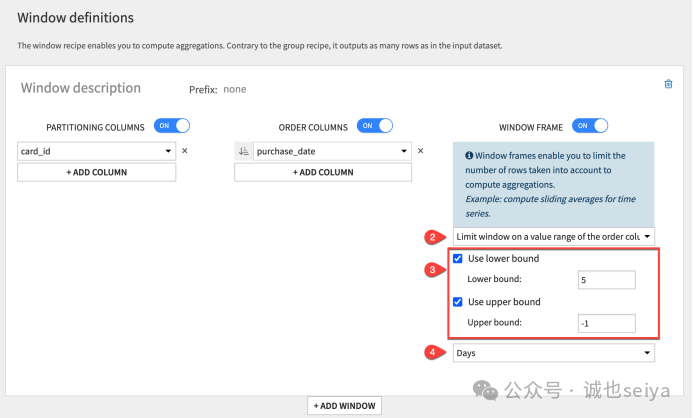
按时间跨度(天数)定义窗口:
勾选Limit window on a value range of the order column。
范围: 下限设为 5,上限设为 -1,单位选 Days。
结果: 窗口包含当前日期前 5 天内的记录。如果前 5 天内没有交易,该行结果将为空(Empty)。(-1 是一种 “不包含后续行” 的写法)
5. 计算排名与滞后 (Compute rank & lag)
探索更复杂的分析函数:
Aggregations 步骤:
开启Row number:可理解为截至目前的消费次数统计。
开启purchase_date 的 LagDiff:设置值为 1,单位为 Days。
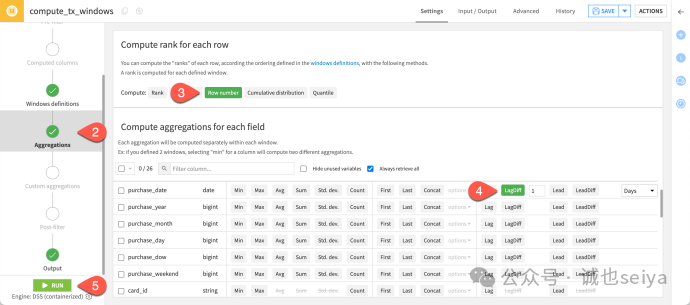
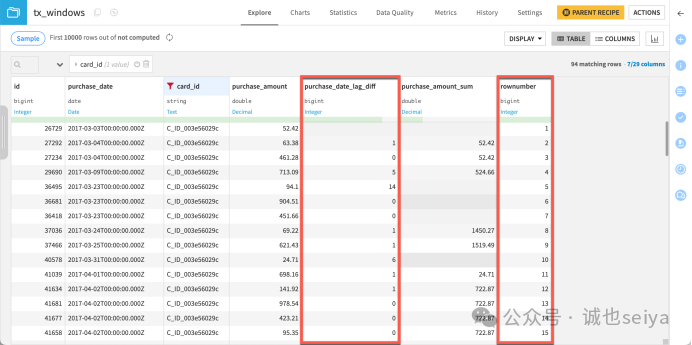
结果: purchase_date_lag_diff 显示了连续两笔交易之间的时间间隔天数。
教程| Top N 插件
在本教程中,我们将使用Top N 插件 来筛选出练习数据集中金额最大的几笔交易。
项目目标
Ø找出全数据集中金额最高的5 笔交易。
Ø找出每个商品类别中金额最高的5 笔交易。
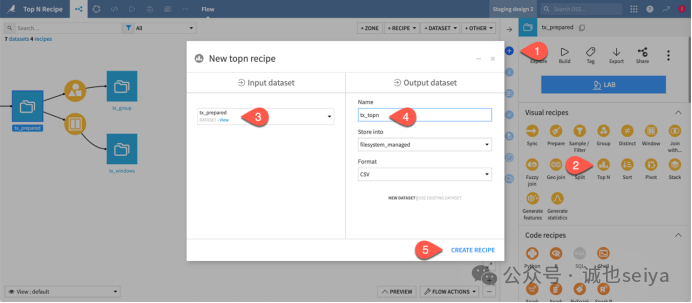
1. 创建 Top N 插件
1.在Flow 中选中 tx_prepared 数据集,在右侧 Actions 面板点击 Top N。
2.保持 tx_prepared 为输入集,输出命名为 tx_topn。
3.点击 Create Recipe。
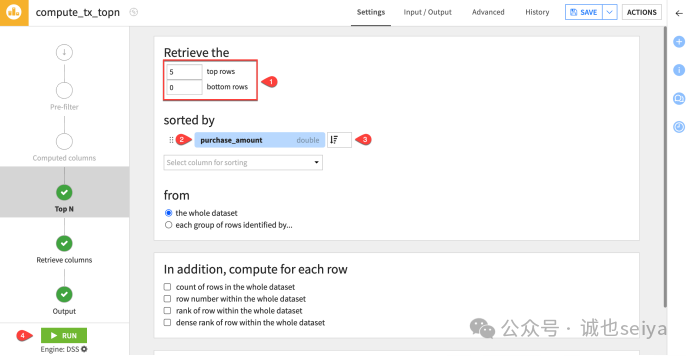
2. 查找金额最高的交易
若要获取全表最大额的5 笔订单:
1.在插件配置页,设置获取 前(Top) 5 行,末尾(Bottom) 0 行。
2.选择 purchase_amount 作为排序字段。
3.将排序方式改为 降序(Descending),确保最高金额排在最前面。
4.运行(Run) 插件并查看结果。你会发现输出仅包含全表金额最大的 5 条记录。
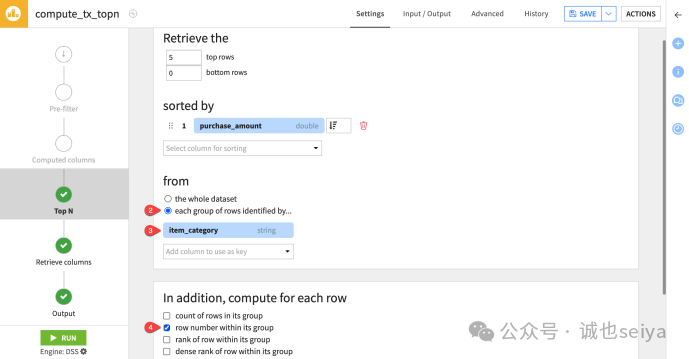
3. 按商品类别进行分组筛选
我们将增加一些复杂度,筛选出每个类别下的前5 名。
1.点击 Parent Recipe 回到配置界面。
2.在 from 选项下,选择 each group of rows identified by。
3.在下拉菜单中选择 item_category 作为键列(Key column)。
4.在下方勾选 row number within its group,以便在输出中显示组内排名。
4. 筛选输出字段
为了让结果更直观,我们只保留必要的列:
1.进入 Retrieve columns 步骤。
2.将 Mode 切换为 Select columns。
3.先将所有列移出选区,然后仅将 item_category、purchase_amount 移回 Selected columns 区域。
4.运行并查看输出。
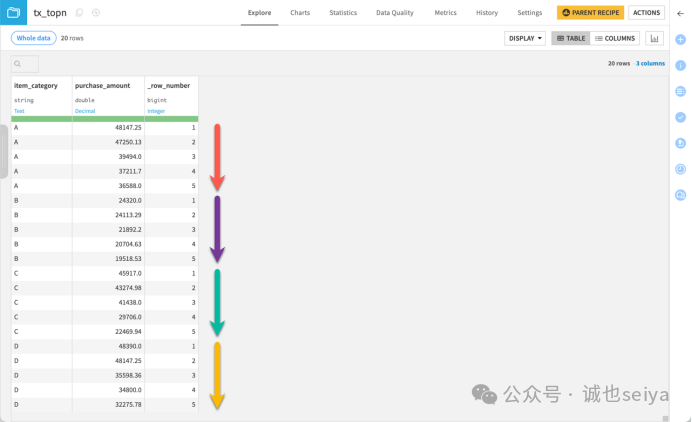
结果观察: 输出将包含 item_category、purchase_amount 和 _row_number 三列。你会看到类别 A、B、C、D 每个组内都有 5 笔按金额降序排列的记录,且 _row_number 的值从 1 到 5。
教程| 透视 (Pivot) 插件
透视(Pivot) 插件 可将数据集转换为透视表,即包含汇总统计数据的表格。这一操作通常也被称为将数据从“长格式 (Long)”转换为“宽格式 (Wide)”。
项目目标
使用透视插件创建汇总统计表。
理解透视插件如何通过两步算法(预过滤步骤)计算Schema。
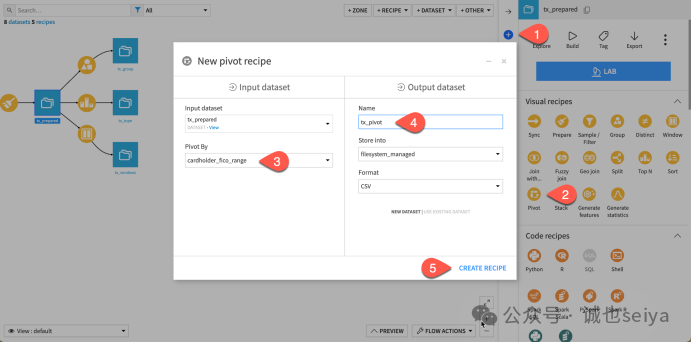
1. 创建透视插件
我们将对tx_prepared 数据集进行形状转换。该表中的 cardholder_fico_range 列将 FICO 评分(美国信用评级系统)分成了四个档位:bad (差)、excellent (极好)、fair (中等) 和 good (好)。
1.在Flow 中选中 tx_prepared。
2.在右侧 Actions 面板的插件菜单中选择 Pivot。
3.在对话框中,选择按 cardholder_fico_range 进行透视。
4.将输出命名为 tx_pivot,点击 Create Recipe。
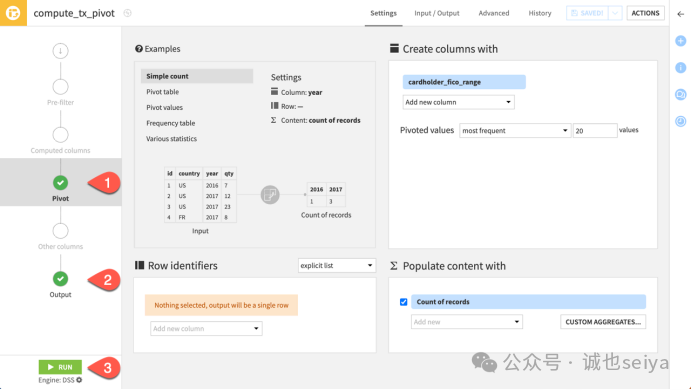
2. 配置透视步骤
透视列(如cardholder_fico_range)中的每个唯一值都将成为新列。新列的内容由聚合指标决定。
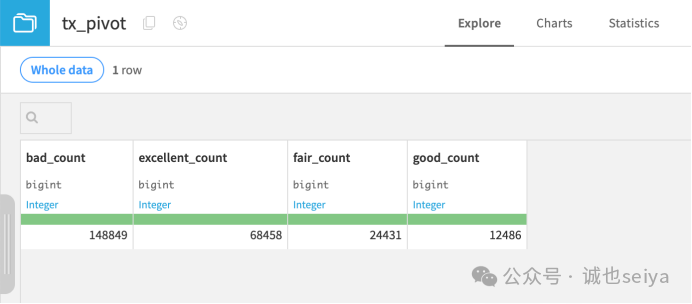
1.初始尝试: 保持默认设置运行(默认聚合为 Count of records)。
2.结果观察: 此时输出仅有一行,包含四个档位的记录总数。因为此时尚未选择“行标识符 (Row identifier)”。
3. 添加行标识符 (Row Identifier)
行标识符允许我们按特定组生成聚合。
1.点击 Parent Recipe 返回 Pivot 步骤。
2.选择 authorized_flag 作为行标识符。
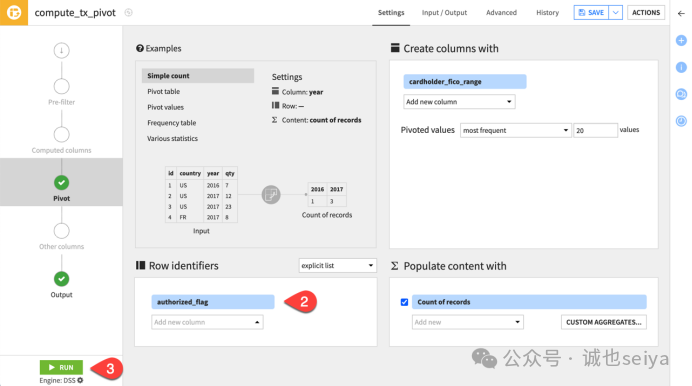
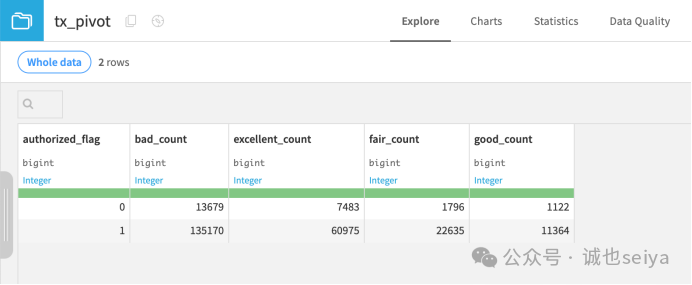
运行结果: 因为该字段有两个值(0 和 1),输出现在变为两行,展示了不同 FICO 评分下已授权和未授权交易的计数。
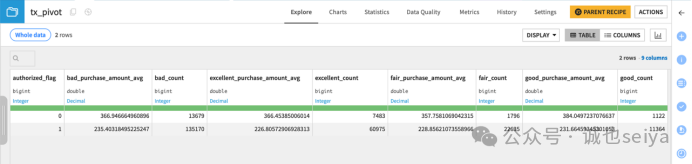
4. 添加多项聚合指标
在Populate content with 模块点击 Add new,选择 purchase_amount。
点击count(purchase_amount) 将其改为 Avg。
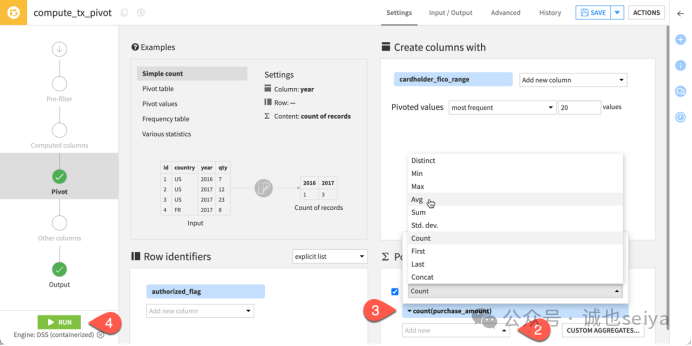
结果: 每增加一个聚合指标,输出数据集就会根据透视列的唯一值数量成倍增加列(本例中增加了 4 列)。
5. 理解两步算法与 Schema 更新
透视插件使用两步算法:第一步查找新列值并生成Schema;第二步填充数据。
在透视插件中,输入数据的具体值会直接影响输出的列结构(Schema)。如果透视列中出现了新值(例如增加了 extraordinary 档位),默认的重建操作会跳过第一步,导致新值无法显示。
更新Schema 的两种方法:
手动删除(Drop): 在 Output 步骤点击 Drop 按钮手动重置。
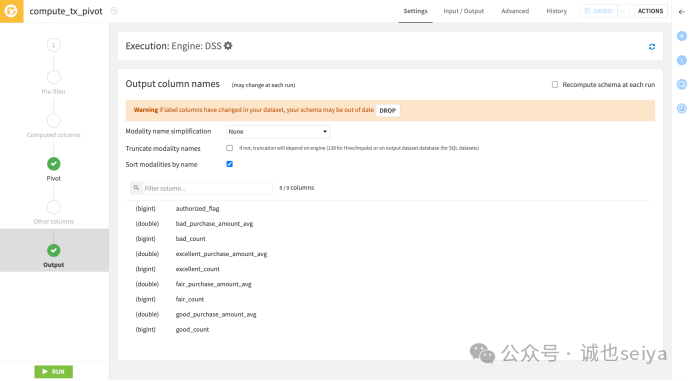
自动重计: 勾选 Recompute schema at each run,每次运行自动更新。注意:如果下游步骤依赖旧列名,自动重计可能会破坏Flow。
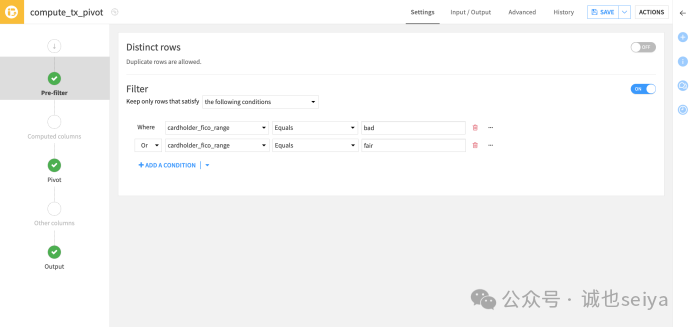
6. 使用预过滤器 (Pre-filter)
透视列的唯一值过多会导致列数失控(默认上限200 列,仅透视频率最高的 20 个值)。
在Pre-filter 步骤开启过滤器。
设置条件仅保留cardholder_fico_range 为 bad 或 fair 的行。
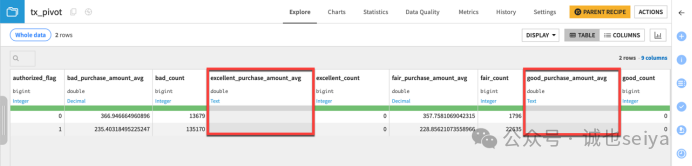
清理旧列: 如果直接运行,原本的 good 和 excellent 列会保留但为空白。为了彻底移除它们,需在 Output 步骤点击 Drop 按钮,然后重新运行。
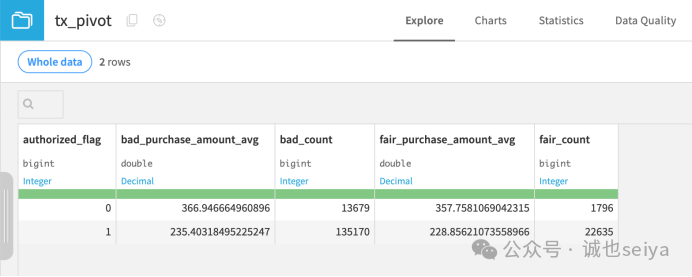
教程| 去重 (Distinct) 插件
在本教程中,我们将学习如何使用去重(Distinct) 插件 来识别并移除 Dataiku 数据集中的重复行。
项目目标
移除所有列完全重复的行。
验证数据集中每一行的唯一性。
查找特定列组合下的唯一值。
1. 创建去重插件
1.在Flow 界面选中 tx_prepared 数据集。
2.在右侧 Actions 面板的 Visual Recipes 栏下,点击 Distinct。
3.在弹出对话框中,将输出数据集命名为 tx_distinct。
4.点击 Create Recipe。
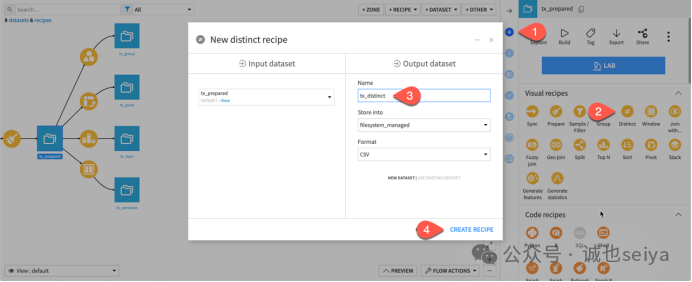
2. 全列去重
首先,我们使用默认设置来检查数据集中是否存在完全相同的行。
1.操作模式(Operation mode): 选择 Remove duplicates (on all columns)。
2.计数设置: 确保勾选了 Compute count of original rows for each deduplicated output row(计算每行去重后对应的原始行数)。
3.运行结果: 运行并打开输出数据集,你会看到新增了一列 count。如果所有行的 count 都等于 1,说明该样本中没有完全重复的记录。
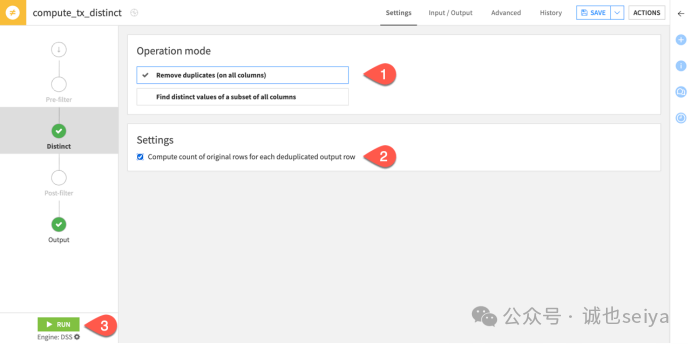
3. 设置后置过滤器 (Post-filter) 验证
为了确信全表没有重复项,我们可以过滤出计数值大于1 的行。
1.在插件中进入 Post-filter 步骤。
2.开启过滤器并添加条件:count > 1。
3.运行并观察: 如果输出数据集为空,则可以确定原数据集中不存在完全重复的行。
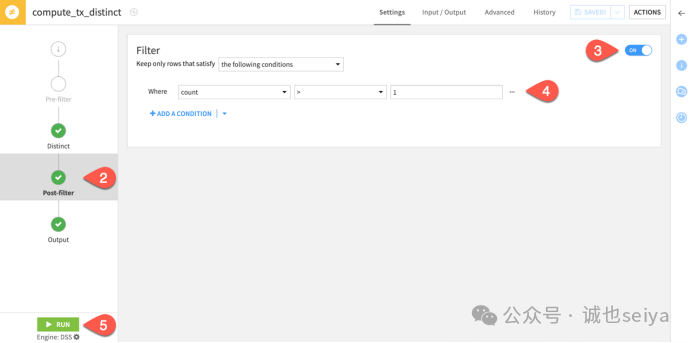
4. 查找子集列的唯一值
现在,我们尝试更复杂的场景:查找同一天内使用同一张卡进行多次消费的记录(即purchase_date 和 card_id 的组合重复项)。
1.重新打开 Distinct 插件。
2.操作模式: 切换为 Find distinct values of a subset of all columns。
3.选择列: 在 Selected columns 框中保留 purchase_date 和 card_id。
4.保持计数与过滤: 确保计数勾选框和后置过滤器(count > 1)仍然生效。
5.运行结果: 此时 tx_distinct 数据集将显示所有在同一天使用同一张卡消费多次的实例。
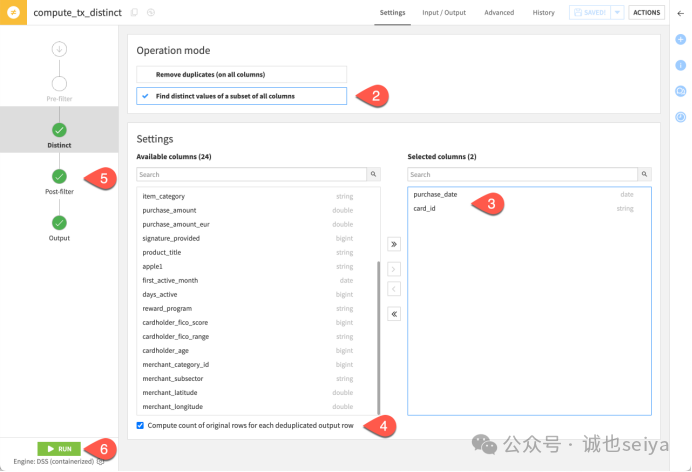
提示: 在使用 窗口(Window) 插件 之前,使用去重插件查找重复项非常有用,这可以帮助你确认数据行是否具有唯一的排序顺序。
教程| 模糊关联 (Fuzzy join) 插件
模糊关联(Fuzzy join) 插件用于在两个数据集的关联键(Join keys)不完全匹配的情况下执行关联操作。这在处理存在拼写错误、不同语言译名或格式不统一的地理/文本数据时非常有用。
项目目标
Ø对比标准关联与模糊关联的区别。
Ø在标准关联中使用文本规范化(Normalization)。
Ø基于Damerau-Levenshtein 距离执行模糊匹配。
Ø调试匹配结果并调整“模糊程度”以适应实际需求。
在Dataiku Design主页上,点击+ New Project。
选择Learning projects,搜索并选择Fuzzy Join Recipe,从项目主页,单击Go to Flow(或键入g + f)。
1. 标准关联中的文本规范化
标准关联基于完全相等的逻辑。但在Dataiku 中,你可以开启“规范化”来处理一些微小的差异。
Ø局限性: 默认情况下,Cancun 无法匹配 Cancún,Hongkong 无法匹配 Hong Kong。
Ø解决方案: 在 Join 步骤的关联条件中,勾选 Normalize text。
Ø效果: 开启后,系统会忽略大小写、重音符号、空格和连字符。例如,Cancun 现在可以成功匹配 Cancún。
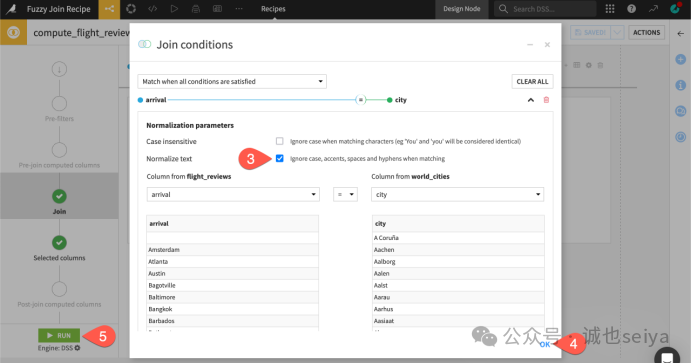
2. 执行模糊关联
当规范化仍无法匹配(如Las Vega 与 Las Vegas,或 Lisboa 与 Lisbon)时,就需要使用模糊关联插件。
设置步骤
1.创建插件: 选中flight_reviews h和 world_cities两个数据集,在 Actions 面板选择 Fuzzy join。
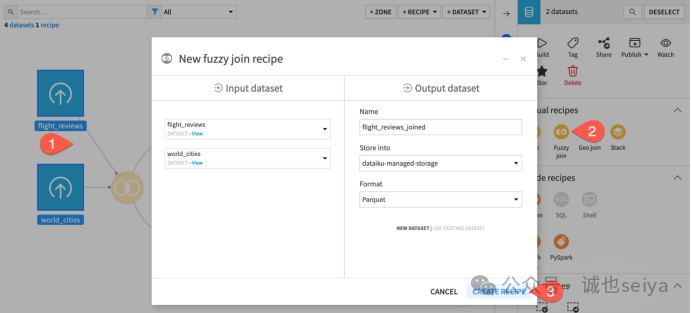
2.选择关联键: 分别选择 arrival 和 city 作为关联键。
3.配置距离算法: 默认使用 Damerau-Levenshtein 距离,阈值设为 1。
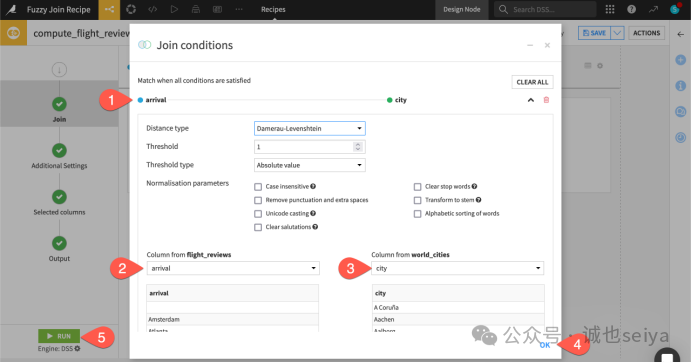
什么是Damerau-Levenshtein 距离? 它衡量将一个单词转换为另一个单词所需的最少操作次数(插入、删除、替换或相邻字符交换)。
例如Lisboa 替换一个字母 n 即可变为 Lisbon,距离为 1。
3. 调试与优化匹配
模糊匹配并非越“模糊”越好,需要通过调试工具来平衡准确率。
调试匹配详情
在Additional Settings 步骤中,开启 Output matching details。
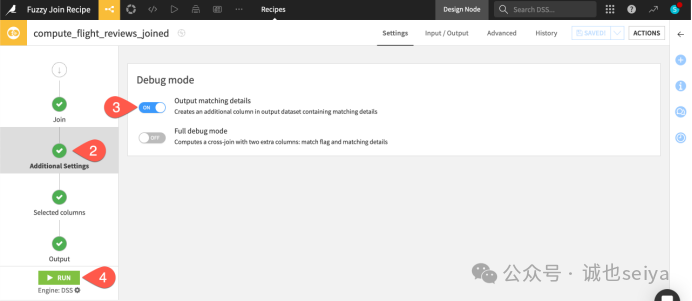
效果: 输出结果会包含一个 meta 列,记录了匹配的具体距离等元数据。你可以配合 Prepare 插件 的 Unnest object 步骤提取出距离数值进行分析。
我们来筛选出仅执行了非精确匹配的行—— 更具体地说,就是键值之间的distance为1 的行。
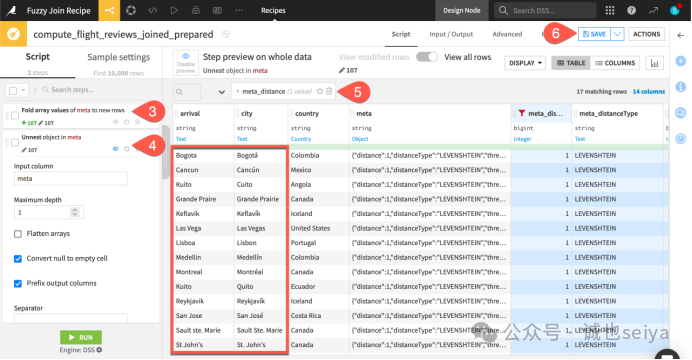
1.在flight_reviews_joined 数据集中,从Actions 选项卡选择Prepare。
2.点击Create Recipe。从meta 列的下拉菜单中,选择Fold to one element per line。
3.打开meta 列的下拉菜单,选择Unnest object。
4.打开meta_distance 列的下拉菜单,选择Filter。仅保留值等于1 的行。
5.点击Save,然后对比arrival 和city 两列之间的编辑距离(edit distance)。
调整“模糊度”的风险
增加阈值: 返回到模糊连接配方的Join步骤。打开并展开连接条件。保持Damerau-Levenshtein距离类型,如果将距离阈值增加到 2,原本无法匹配的行可能会被填满。
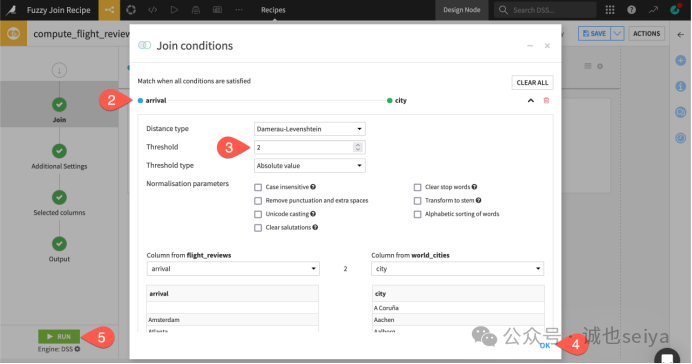
副作用: 过高的阈值会导致大量错误匹配(例如 Atlanta 错误匹配到 Alanya)。
行数膨胀: 模糊关联可能会导致一行匹配到多个相似项,从而使输出行数远多于输入行数(例如从 130 行膨胀到 670 行)。
详细教程| 地理关联 (Geo join) 插件
地理关联(Geo join) 插件允许您根据地理空间条件(而非传统的文本或数值匹配)来合并数据集。这对于分析点与点、点与区域之间的空间关系至关重要。
项目背景与目标
选择Learning projects,搜索并选择Geo join Recipe,从项目主页,单击Go to Flow(或键入g + f)。
我们将分析信用卡交易中的地理分布关系。
目标:为每一个商户(加油站)找出其方圆 10 公里 以内的所有持卡人。
数据集:
Øtx:信用卡交易记录。
Øcardholders:持卡人的经纬度坐标。
Ømerchants:商户(加油站)的经纬度坐标。
1. 准备工作:启用数据采样
地理空间计算较为耗时,因此我们先启用采样以减小数据量。
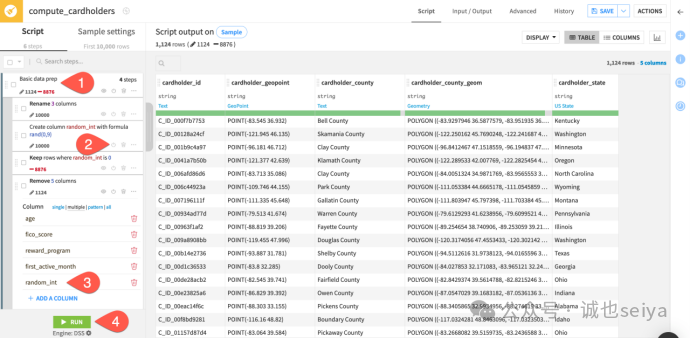
1.分别打开创建 cardholders 和 merchants 的 Prepare 插件。
2.展开 Basic data prep 步骤组。
3.点击电源图标启用已停用的两个步骤(生成随机整数并过滤)。
4.在随后的 Remove column 步骤中添加 random_int 以将其删除。
5.点击 Run 并选择 Run Only This 来构建小样本数据集。
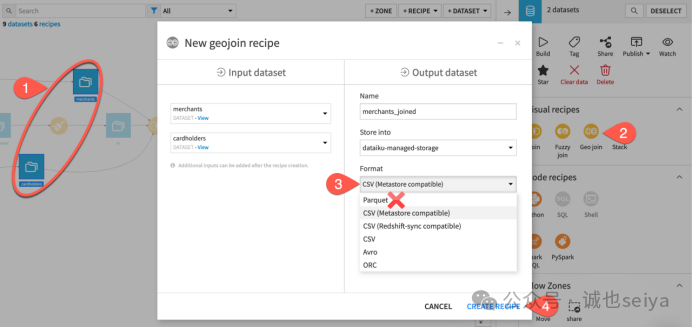
2.创建地理连接(Geo Join)任务
1.在Flow 界面中,先选中merchants(商家)数据集,再选中cardholders(持卡人)数据集。
2.打开右侧的Actions 选项卡,选择Geo join recipe。
3.根据你的实例配置,默认的存储位置和格式可能不同。如果使用S3 存储,请选择 Parquet 以外的格式,比如 CSV(元数据存储兼容)。
4.点击Create Recipe(创建任务)。
3.关键步骤:修改存储类型
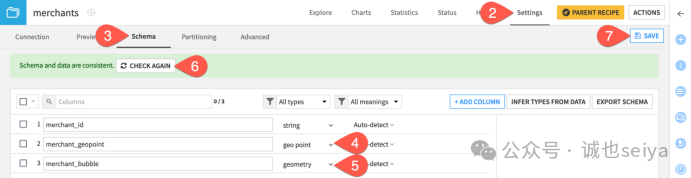
非常重要:地理关联要求列的存储类型(Storage Type) 必须是地理类型。仅靠 Dataiku 自动检测到的“意义 (Meaning)”是不够的。
1.打开 merchants 数据集的 Settings > Schema。
2.将 merchant_geopoint 的存储类型改为 geo point。
3.将 merchant_bubble 的存储类型改为 geometry。
4.保存后,对 cardholders 数据集重复此操作:将 cardholder_geopoint 设为 geo point,将 cardholder_county_geom 设为 geometry。
3. 配置地理关联条件
我们接下来用Geo join recipe 来找出:
Ø每个商家周围10 公里范围内的所有持卡人
Ø保留默认的左连接,这样输出结果会包含所有商家,即使有些商家在10 公里范围内没有任何持卡人
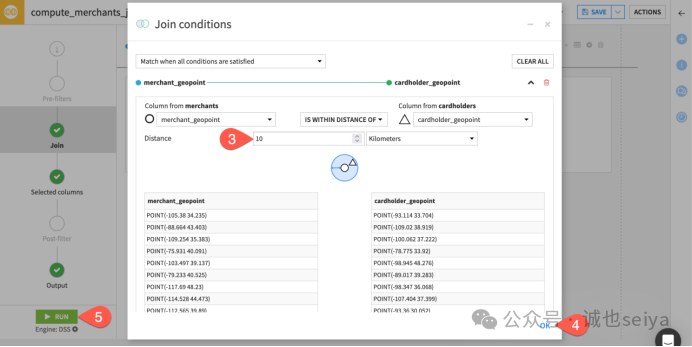
1.在Flow 中先选中 merchants,再选中 cardholders。
2.在右侧 Actions 面板选择 Geo join 插件并创建。
3.在 Join 步骤中,点击编辑默认关联条件:
4.条件设置:当 merchant_geopoint 在距离之内(is within distance of) 10 Kilometers(来自 cardholder_geopoint)时匹配。
5.关联类型:保持 Left join,以确保保留所有商户信息,即使其附近没有持卡人。
6.点击 Run 执行。
4. 验证结果
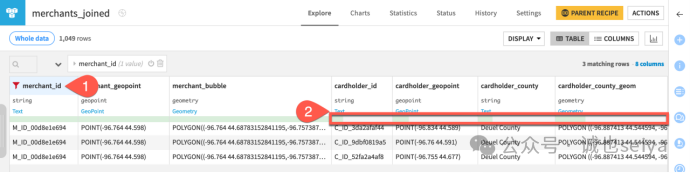
数据检查:你会发现某些商户有多行记录,这表示其10 公里内有多个持卡人;而某些行的持卡人信息为空,说明该商户附近没有匹配项。
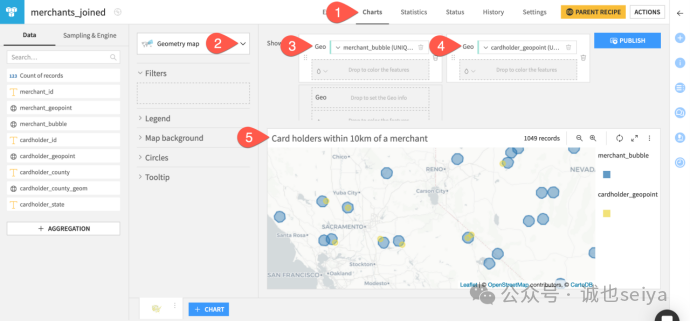
地图可视化:
1.打开merchants_joined数据集的 Charts 标签页。
2.选择 Geometry map。
3.将 merchant_bubble(10 公里半径的圆圈)拖入第一个 Geo 字段,点三个小点,聚合方式选 Make unique。
4.将 cardholder_geopoint 拖入第二个 Geo 字段,聚合方式选 Make unique,并改点颜色为黄色。
确认:缩放地图,你会发现所有黄点都落在了商户的蓝色圆圈内。
教程| 数据准备中的视觉逻辑处理器
在数据准备任务中,定义基于多个条件或输入列的复杂规则是一项常见工作,例如重新编码分类值或定义“如果-那么 (if-then)”逻辑。Dataiku 提供了多种工具来解决这些问题,本教程将重点介绍四种核心方法。
项目背景
该项目基于简化的信用卡欺诈案例。通过交易、商户和持卡人数据,构建模型预测哪些交易应获得授权。
选择Learning projects,搜索并选择Visual Logic,从项目主页,单击Go to Flow(或键入g+f)
authorized_flag: 目标变量,1 表示授权成功,0 表示授权失败。
1. Switch 公式函数 (Switch Formula)
类似于Excel 中的SWITCH(),该函数适用于在单列分类数据中重新映射值。
操作步骤:
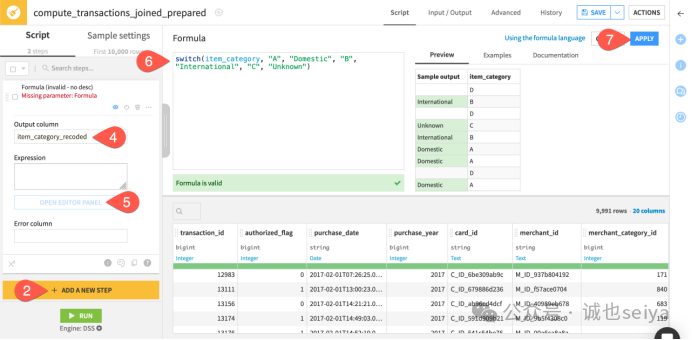
1.打开计算transactions_joined_prepared的Prepare,在 Prepare 插件 中添加 Formula 步骤。
2.输出列命名为 item_category_recoded。
3.在编辑器中输入以下表达式:
switch(item_category,"A","Domestic","B","International","C","Unknown")
注意:未在公式中指定的原始值(如类别D)在输出列中将保持为空。
2. Switch Case 处理器
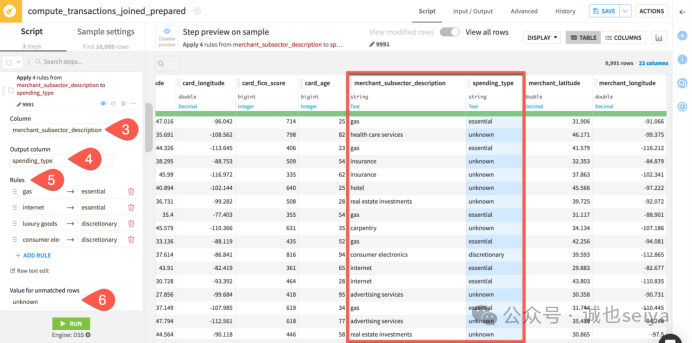
当处理具有大量唯一值(如拥有38 个值的商户细分行业)的列时,Switch Case 处理器比手动编写公式更易于维护。
操作步骤:
1.在prepare步骤,添加 Switch case 步骤。
2.选择 merchant_subsector_description 作为目标列,输出列命名为 spending_type。
3.添加规则映射(例如:gas -> essential, luxury goods -> discretionary,luxury goods -> discretionary、consumer electronics -> discretionary)。
4.为不匹配的行设置默认值 unknown。
进阶功能:支持“不区分大小写”或“规范化(忽略重音)”匹配模式。如果已有 Excel 映射表,可使用 Raw text edit 直接粘贴。
3. 创建 If, Then, Else 语句 (Visual If-Then-Else)
对于涉及多个列的复杂逻辑,该处理器提供了可视化的条件判断功能。
1. 在同一个Prepare配方中,单击+ Add a New Step。
2. 搜索并在脚本中添加一个Create if, then, else语句步骤。
3.1 定义 If 块 (验证 FICO 分数)
条件:如果 card_fico_score < 300 或(OR) card_fico_score > 850,则将新列 risk 设为 invalid。
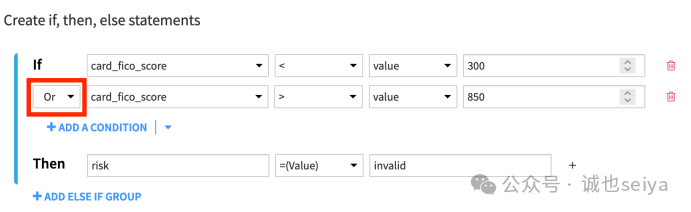
预览(preview):如果没有任何行满足此极端条件,risk 列将显示为空。
3.2 添加 Else If 与 Else 块 (分级风险)
让我们使用最后一个else语句为不满足上面任何条件的任何值定义一个规则。
1. 在编辑器面板的底部,单击+ Add Else。
2. 如果以上条件均不满足,则将新建的列risk设为low。
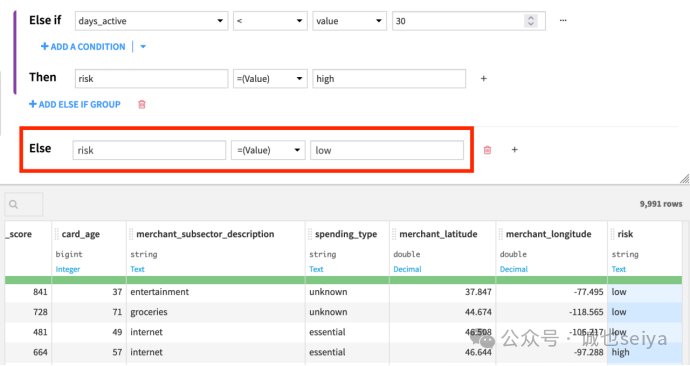
如果需要更多可能的输出,而不仅仅是invalid、high和low。你可以用附加的else if块来定义它们。
1.在第一个else if块下面(在else块上面),点击+ Add else if组。
重要提示:条件的顺序至关重要。处理器会按顺序评估,一旦满足某一条规则就会停止。如果把 < 60 放在 < 30 之前,所有激活 15 天的卡都会被错误地标记为“中风险”。
2. 提供days_active < 60的条件。
3. 如果满足此条件,则将新列风险设置为值medium。
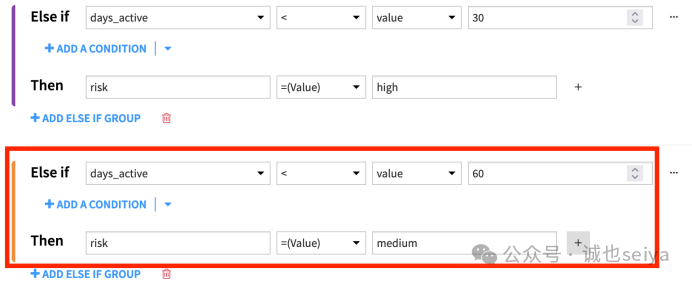
Else If (高风险):如果 days_active(卡片激活天数)< 30,则 risk = high。
Else If (中风险):如果 days_active < 60,则 risk = medium。
Else (低风险):如果不满足上述所有条件,则 risk = low。
3.3 嵌套逻辑与分组 (Nested Logic)
你可以通过“添加组 (Add a group)”来实现更复杂的逻辑,例如:if D and (E or F)。if (A or B) then "invalid"
else if C then "high"
else if D then "medium"
else "low"
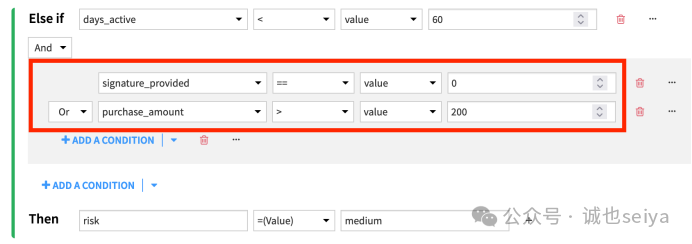
案例:将中风险条件改为:days_active < 60 且 (signature_provided == 0 或 purchase_amount > 200)。
1.在编辑器面板中,返回定义“中等风险”(medium risk values)的第二个 else if 代码块。
2.点击+ Add a Condition 旁边的下拉箭头,选择Add a group(添加一个组)。
3.除了原有的第一个条件外,强制要求“中等风险” 值还必须满足以下两个条件中的至少一个;
Øsignature_provided == 0(未提供签名)
ØOR
Øpurchase_amount > 200(消费金额大于 200)
4. 广泛应用的过滤条件
你不必等到Prepare recipe 中才去检查无效的FICO 评分,而是可以在数据流程的更早期就进行这类检查。例如,你可以在 Join recipe(连接任务)的Pre-filter(前置筛选)步骤中完成这项检查。
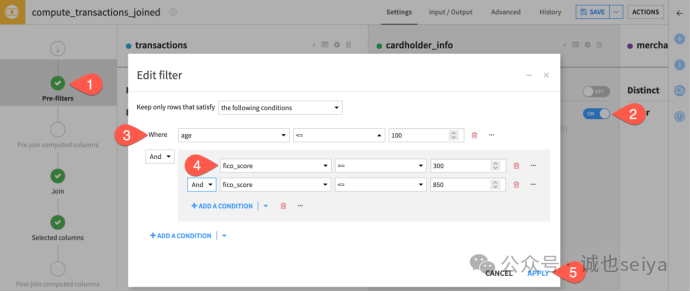
1.导航到Join recipe 的Pre-filters 步骤。
2.开启cardholder_info(持卡人信息)数据集的筛选开关。
3.在执行连接操作前,仅保留该数据集中满足以下所有条件的行:
age <= 100(设定一个任意的年龄上限)。
4.点击+ Add a Condition 旁边的下拉菜单,选择Add a group(添加条件组),除了年龄上限之外,为FICO 评分同时设置下限和上限:
fico_score >= 300ANDfico_score <= 850
5.点击Apply,再点击任务右下角的 Run(运行),然后再次点击 Run 以构建下游的整个 Flow(数据流程)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)