Anthropic 高效的AI agents上下文工程设计理念和实践经验
核心思想:以“最小化 tokens 占用”和“最大化信息信号”为双重目标,筛选进入上下文窗口的内容,避免冗余信息消耗模型注意力预算。
设计原则与实践经验
核心设计原则
1. 最小高信号原则
- 核心思想:以“最小化 tokens 占用”和“最大化信息信号”为双重目标,筛选进入上下文窗口的内容,避免冗余信息消耗模型注意力预算。
- 本质:上下文是边际收益递减的有限资源,无需追求“信息全面”,而需确保“信息精准相关”。
2. 迭代优化原则
- 上下文工程不是一次性设计,而是持续迭代的过程:每次模型交互后,基于失效模式(如理解偏差、信息遗漏)调整上下文配置(如补充示例、优化工具返回格式)。
- 优先级:先满足“核心功能所需的最小上下文”,再逐步迭代补充边缘场景的信息。
3. 适配模型特性原则
- 兼容 LLM 的固有约束:正视“上下文衰减”“长程依赖处理较弱”的特征,不依赖超长篇上下文实现复杂逻辑,而是通过拆分、压缩等策略规避短板。
- 利用模型优势:借助 LLM 对结构化信息的理解能力(如 XML 标记、Markdown 模块),优化上下文组织形式,降低模型解析成本。
4. 灵活性与约束平衡原则
- 避免“过度约束”:不硬编码复杂的 if-else 逻辑,给模型留启发式决策空间,减少系统脆弱性和维护成本。
- 避免“过度宽松”:不提供模糊、宏观的指导,需明确核心规则和期望输出,确保模型行为可控。
5. 场景适配原则
- 上下文策略需匹配任务特性:短时效任务(如单轮查询)侧重“预检索+简洁提示”;长时程任务(如代码迁移)侧重“动态检索+记忆机制”;复杂任务(如多维度研究)侧重“
sub-agent分工”。
关键实践经验
1. 系统提示词设计实践
- 「校准方法」:先写“最小可行提示词”(仅包含核心角色、目标、基础规则),用最优模型测试,再根据失效案例补充指令(如针对“未查询订单就答复”的问题,添加“提及订单先查状态”的规则)。
- 「结构优化」:用模块拆分提示词(如
<背景信息>``<核心指令>``<工具使用指南>``<输出格式>),通过 XML 标记或 Markdown 标题划分边界,降低模型理解成本。 - 「避坑指南」:
- 不堆砌边缘案例:用 2-3 个多样化标准示例替代数十个边缘场景说明,避免模型注意力偏移;
- 不假设共享上下文:明确告知模型“已知信息”(如可访问的系统、数据范围),不默认模型理解业务常识。
2. 工具设计与管理实践
- 「工具开发规范」:
- 功能单一化:一个工具对应一个核心任务(如“查询订单”和“修改订单”拆分两个工具),避免多功能叠加导致决策模糊;
- 输出高效化:工具返回结果需“token 精简”,仅包含核心数据(如订单查询返回“订单号+状态+预计送达时间”,而非完整日志);
- 容错性设计:明确工具异常返回格式(如“无此订单”“网络超时”),避免模型因模糊反馈陷入无效推理。
- 「工具集管理」:
- 筛选“最小可行工具集”:移除功能重叠、使用频率极低的工具,降低模型选择成本;
- 工具命名直观化:用“查询订单状态”而非“order-tool-v1”,减少模型对工具用途的理解负担。
3. 上下文检索实践
- 「优先采用动态检索」:
- 维护轻量级标识符:用文件路径、网页链接、存储查询等替代完整数据,让模型在运行时通过工具按需加载;
- 利用元数据辅助决策:通过文件夹层级(如
tests/vssrc/)、命名规范、时间戳,给模型提供“信息相关性信号”,提升检索效率。
- 「混合检索策略落地」:
- 预检索核心数据:将高频访问、静态不变的信息(如项目核心文档、基础规则)预先纳入上下文,提升响应速度;
- 动态补充边缘数据:将低频访问、动态变化的信息(如实时订单数据、临时文件)通过工具即时检索,避免上下文臃肿。
- 示例:Claude Code 预先加载
CLAUDE.md核心文档,通过glob``grep工具动态检索其他文件,平衡速度与灵活性。
4. 长时程任务上下文管理实践
(1)压缩策略实践
- 「关键信息保留清单」:压缩时优先保留“架构决策、未解决漏洞、核心目标、依赖关系”,丢弃“冗余工具输出、重复沟通内容、已完成任务的详细日志”。
- 「提示词优化」:先设计“高召回”压缩提示词(确保不遗漏关键信息),再迭代优化为“高精准”提示词(剔除多余内容),避免过度压缩导致上下文丢失。
- 「轻量压缩技巧」:优先清除历史工具调用结果(一旦工具完成使命,其原始输出无需保留),是安全且高效的压缩方式。
(2)结构化笔记实践
- 「笔记规范」:
- 固定笔记结构:如“任务进度+关键决策+未解决问题+下一步计划”,方便模型快速读取;
- 定期更新频率:每完成一个子任务或迭代一轮交互后,触发笔记更新,避免信息滞后。
- 「落地示例」:代码迁移 agent 维护
PROJECT_NOTES.md,记录“已迁移模块、遗留兼容性问题、待迁移优先级”,跨上下文重置后通过读取笔记保持连贯性。
(3)sub-agent 架构实践
- 「分工原则」:主 agent 负责“任务拆解、进度协调、结果综合”,
sub-agent负责“单一维度的深度工作”(如数据检索sub-agent、代码编写sub-agent、结果校验sub-agent)。 - 「信息传递规范」:
sub-agent仅返回“浓缩摘要(1000-2000 tokens)+ 核心结论”,不传递过程性细节,避免占用主 agent 上下文空间。
5. 通用避坑经验
- 不依赖“超大上下文窗口”:即使模型支持长序列,也需进行上下文筛选——长上下文会导致注意力稀释,反而降低任务精度;
- 避免“上下文污染”:及时清理过时信息(如已失效的工具结果、已完成的任务记录),确保上下文窗口中仅保留“当前任务相关的有效信息”;
- 重视“渐进式披露”:让模型通过工具逐步探索信息,而非一次性加载所有数据,帮助模型逐层构建理解,减少信息过载;
- 测试优先级:先测试“上下文缺失场景”(如关键信息未纳入、过时信息干扰),再优化“上下文冗余场景”,优先解决“模型做错题”的问题,再提升“模型做得快”的效率。
高效的AI agents上下文工程设计细节
发布时间:2025-09-29 00:00:00
作者:Anthropic 工程团队(Engineering at Anthropic)
上下文(context)是 AI agents 的关键但有限的资源。在本文中,我们将探讨如何有效筛选和管理驱动 AI agents 运行的上下文的策略
在应用 AI(applied AI)领域,prompt engineering 成为关注焦点数年后,一个新术语逐渐兴起:context engineering。使用语言模型(language models)进行开发,不再仅仅是为提示词(prompts)寻找合适的词语和短语,而更多是回答一个更广泛的问题:“何种上下文配置最有可能产生模型(model)期望的行为?”
上下文(context)指的是从大型语言模型(large-language model, LLM)中采样(sampling)时包含的一组标记(tokens)。当前的工程问题是,在 LLM 的固有约束(constraints)下优化这些标记(tokens)的效用(utility),以持续实现期望的结果。有效驾驭 LLMs 通常需要从上下文角度思考——换句话说:考虑 LLM 在任何给定时间可获取的整体状态(holistic state),以及该状态可能产生的潜在行为。
在本文中,我们将探索 context engineering 这一新兴领域,并提供一个经过优化的思维模型,帮助构建可调控、高效的 agents。
Context engineering 与 prompt engineering 的区别
在 Anthropic,我们认为 context engineering 是 prompt engineering 的自然演进。Prompt engineering 指的是为获得最佳结果而编写和组织 LLM 指令的方法。Context engineering 指的是在 LLM 推理(inference)过程中,筛选和维护最优标记(tokens)集(即信息)的一系列策略,包括提示词(prompts)之外可能纳入其中的所有其他信息。
在使用 LLMs 进行工程开发的早期,提示词设计(prompting)是 AI 工程工作的核心部分,因为除日常聊天交互外,大多数用例都需要针对单样本分类(one-shot classification)或文本生成(text generation)任务优化的提示词(prompts)。顾名思义,prompt engineering 的核心关注点是如何编写有效的提示词(prompts),尤其是系统提示词(system prompts)。然而,随着我们着手开发功能更强大、能在多轮推理(multiple turns of inference)和更长时间范围(time horizons)内运行的 agents,我们需要相应策略来管理整个上下文状态(包括系统指令、工具(tools)、模型上下文协议(Model Context Protocol, MCP)、外部数据(external data)、消息历史(message history)等)。
循环运行的 agent 会生成越来越多可能与下一轮推理相关的数据,而这些信息必须进行周期性优化。Context engineering 是一门艺术与科学,旨在从这个不断演变的海量潜在信息中,筛选出将纳入有限上下文窗口(context window)的内容。
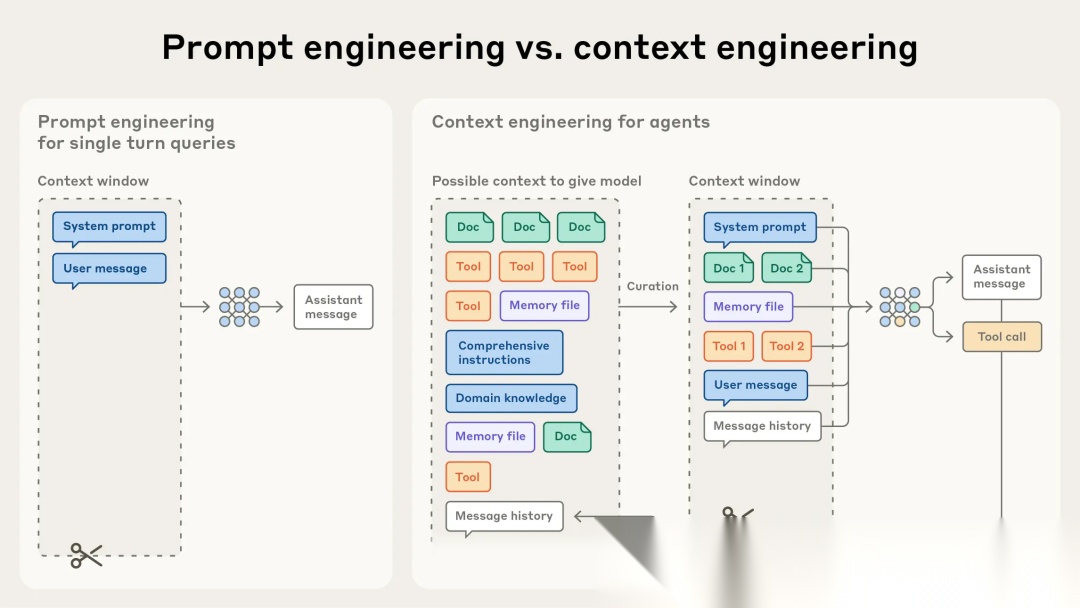
与写提示词的离散任务不同,上下文工程是迭代的,每次决定传递给模型时都会进入策划阶段。
为何 context engineering 对构建高性能 agents 至关重要
尽管 LLMs 速度快且能处理越来越大量的数据,但我们观察到,它们和人类一样,在某个节点会注意力不集中或产生困惑。针对“大海捞针式”基准测试(needle-in-a-haystack style benchmarking)的研究发现了上下文衰减(context rot)这一概念:随着上下文窗口(context window)中标记(tokens)数量的增加,模型(model)从该上下文中准确回忆(recall)信息的能力会下降。
尽管不同模型的性能下降(degradation)程度有所不同,但所有模型都存在这一特征。因此,上下文(context)必须被视为一种边际收益递减(diminishing marginal returns)的有限资源。和工作记忆容量(working memory capacity)有限的人类一样,LLMs 也拥有“注意力预算(attention budget)”,在解析大量上下文时会消耗这一预算。每引入一个新的标记(token)都会消耗一定量的预算,因此更需要谨慎筛选 LLM 可获取的标记(tokens)。
这种注意力稀缺性源于 LLMs 的架构约束(architectural constraints)。LLMs 基于 Transformer 架构(transformer architecture),该架构允许每个标记(token)关注(attend to)整个上下文中的所有其他标记(token)。这导致 n 个标记(tokens)会产生 n² 个成对关系(pairwise relationships)。
随着上下文长度(context length)的增加,模型捕捉这些成对关系的能力会被稀释,从而在上下文规模和注意力集中度之间形成一种天然的矛盾。此外,模型的注意力模式是从训练数据分布(training data distributions)中习得的,而在这些分布中,短序列(sequences)通常比长序列更为常见。这意味着模型在处理全局上下文依赖(context-wide dependencies)方面经验更少,相关的专用参数(parameters)也更少。
位置编码插值(position encoding interpolation)等技术通过将长序列适配到原始训练的较小上下文,使模型能够处理更长的序列,不过这会导致标记(token)位置理解能力有所下降。这些因素导致的是性能梯度(performance gradient)而非突然崩溃:模型在长上下文下仍保持较强的能力,但与在短上下文下的表现相比,信息检索(information retrieval)和长程推理(long-range reasoning)的精度可能会降低。
这些现实意味着,精心设计的 context engineering 对于构建高性能 agents 至关重要。
有效上下文的构成要素
由于 LLMs 受到有限注意力预算(attention budget)的约束,优秀的 context engineering 意味着找到尽可能小的高信号标记(high-signal tokens)集,以最大化产生期望结果的可能性。这一实践说起来容易做起来难,但在接下来的部分,我们将详细说明这一指导原则在上下文不同构成要素中的实际应用。
系统提示词(system prompts)应极其清晰,使用简洁直白的语言,以适合 agent 的恰当粒度呈现信息。这种恰当粒度是两种常见失效模式之间的“Goldilocks 区域”(即恰到好处的区间)。一种极端情况是,工程师在提示词(prompts)中硬编码(hardcoding)复杂且脆弱的逻辑(brittle logic),以触发 agent 特定的智能行为(agentic behavior)。这种方法会导致系统脆弱性,且随着时间推移会增加维护复杂度。另一种极端情况是,工程师提供的指导过于模糊、宏观(high-level guidance),无法为 LLM 提供关于期望输出的具体信号,或错误地假设存在共享上下文(shared context)。最优粒度需要达到一种平衡:足够具体以有效引导行为,同时足够灵活,为模型提供强大的启发式方法(heuristics)来指导行为。
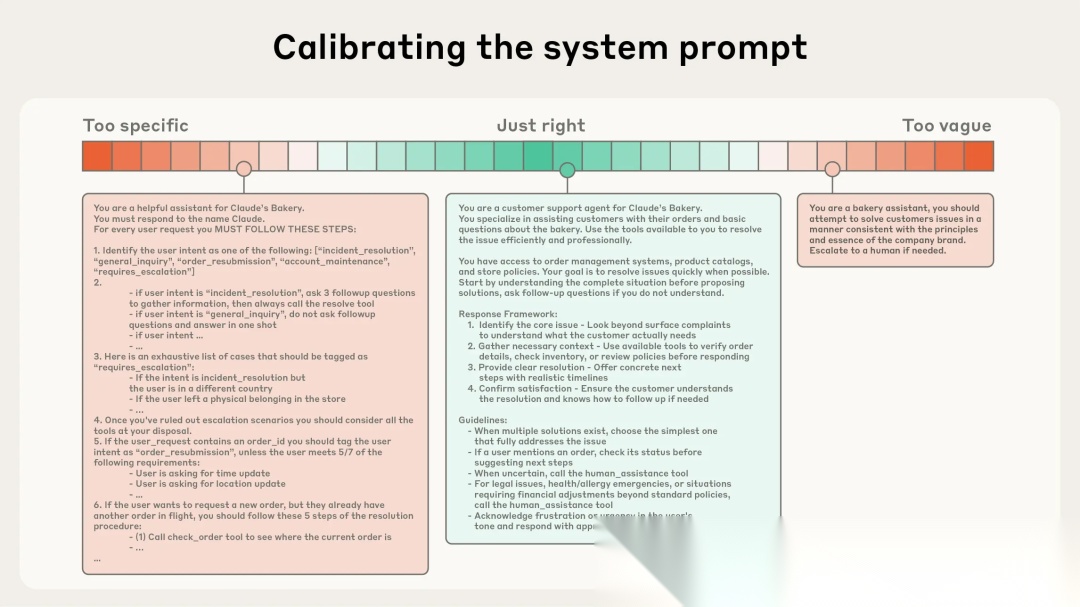
在光谱的一端,我们看到的是脆弱的if-else硬编码提示,另一端则是过于笼统或错误假设共享上下文的提示。
我们建议将提示词(prompts)组织成不同的部分(例如 <background_information>、<instructions>、## Tool guidance、## Output description 等),并使用 XML 标记(XML tagging)或 Markdown 标题(Markdown headers)等技术来划分这些部分——不过随着模型能力的提升,提示词的具体格式可能变得不那么重要。
无论你决定如何构建系统提示词(system prompt),都应努力提供能完整说明期望行为的最小信息集。(注意:“最小”并不一定意味着“简短”;你仍需提前向 agent 提供足够的信息,以确保它遵循期望的行为。)最佳实践是,首先使用可用的最优模型测试最小化提示词,观察其在你的任务中的表现,然后根据初始测试中发现的失效模式,添加清晰的指令和示例以提升性能。
工具(tools)使 agents 能够与环境交互,并在工作过程中获取新的、额外的上下文。由于工具定义了 agents 与其信息/行动空间(information/action space)之间的契约,因此工具必须提升效率——既要返回标记高效(token efficient)的信息,也要鼓励 agents 采取高效行为,这一点至关重要。
在《为 AI agents 编写工具——借助 AI agents》一文中,我们探讨了如何构建 LLMs 能充分理解且功能重叠最小的工具。与设计良好的代码库(codebase)的函数类似,工具应具备独立封装(self-contained)、抗错误(robust to error)的特性,且其预期用途应极其明确。输入参数(input parameters)也应具有描述性、明确性,并充分发挥模型的固有优势。
我们观察到最常见的失效模式之一是工具集臃肿(bloated tool sets)——涵盖的功能过多,或导致在选择使用哪种工具时出现模糊的决策点。如果人类工程师无法明确判断在特定场景下应使用哪种工具,那么 AI agent 也无法做到更好。正如我们后面将要讨论的,为 agent 筛选最小可行工具集(minimal viable set),还能在长期交互中实现更可靠的维护和上下文修剪(pruning)。
提供示例(也称为少样本提示(few-shot prompting))是一项众所周知的最佳实践,我们继续强烈推荐这一做法。然而,许多团队常常会在提示词中堆砌大量边缘案例(edge cases),试图阐明 LLM 在特定任务中应遵循的所有可能规则。我们不建议这样做。相反,我们建议筛选一组多样化的标准示例(canonical examples),以有效展现 agent 的期望行为。对于 LLM 而言,示例是“一图胜千言”的存在。
针对上下文的不同构成要素(系统提示词、工具、示例、消息历史等),总体指导原则是:深思熟虑,确保上下文信息丰富且精炼。接下来,我们将深入探讨如何在运行时(runtime)动态检索(dynamically retrieving)上下文。
上下文检索(context retrieval)与智能搜索(agentic search)
倾向于给 agents 下一个简单的定义:LLMs 自主循环使用工具(tools)。
通过与客户合作,我们发现该领域正逐渐聚焦于这一简单范式(paradigm)。随着底层模型的能力不断提升,agents 的自主程度(autonomy)也会相应提高:更智能的模型使 agents 能够独立应对复杂的问题空间(problem spaces)并从错误中恢复。
如今,我们观察到工程师在设计 agents 的上下文时,思路正在发生转变。目前,许多原生 AI 应用(AI-native applications)采用某种形式的基于嵌入(embedding-based)的推理前检索(pre-inference time retrieval),以提取重要上下文供 agent 进行推理。随着该领域向更智能的方法(agentic approaches)转变,我们越来越多地看到团队通过“即时(just in time)”上下文策略来增强这些检索系统。
采用“即时”方法构建的 agents 不会预先处理所有相关数据,而是维护轻量级标识符(lightweight identifiers)(如文件路径(file paths)、存储查询(stored queries)、网页链接(web links)等),并利用这些引用通过工具在运行时(runtime)动态加载(dynamically load)数据到上下文。Anthropic 的智能编码解决方案(agentic coding solution)Claude Code 就采用了这种方法,对大型数据库(databases)进行复杂数据分析(data analysis)。该模型能够编写目标查询(targeted queries)、存储结果,并利用 head 和 tail 等 Bash 命令(Bash commands)分析大量数据,而无需将完整数据对象加载到上下文中。这种方法模仿了人类的认知(human cognition):我们通常不会记忆全部信息集合(corpuses),而是通过文件系统(file systems)、收件箱(inboxes)、书签(bookmarks)等外部组织和索引系统(indexing systems),按需检索相关信息。
除了存储效率外,这些引用的元数据(metadata)还提供了一种有效优化行为的机制——无论这些元数据是明确提供的还是隐含的。对于在文件系统中运行的 agent 而言,tests 文件夹中名为 test_utils.py 的文件,其用途与 src/core_logic.py 中同名文件的用途截然不同。文件夹层级(folder hierarchies)、命名规范(naming conventions)和时间戳(timestamps)都提供了重要信号,帮助人类和 agents 理解如何以及何时利用信息。
让 agents 自主导航和检索数据还能实现渐进式披露(progressive disclosure)——换句话说,允许 agents 通过探索逐步(incrementally)发现相关上下文。每次交互都会产生为下一个决策提供依据的上下文:文件大小暗示复杂度;命名规范暗示用途;时间戳可作为相关性的替代指标(proxy)。Agents 能够逐层构建理解,仅在工作记忆(working memory)中保留必要内容,并利用记笔记策略(note-taking strategies)实现额外的持久性存储(persistence)。这种自我管理的上下文窗口(context window)使 agent 能够专注于相关信息子集,而不会淹没在详尽但可能无关的信息中。
当然,这也存在权衡(trade-off):运行时探索比检索预计算数据(pre-computed data)更慢。不仅如此,还需要有明确导向且深思熟虑的工程设计,以确保 LLM 拥有合适的工具和启发式方法(heuristics),从而有效导航其信息环境(information landscape)。如果缺乏适当指导,agent 可能会因误用工具、陷入死胡同(dead-ends)或未能识别关键信息而浪费上下文。
在某些场景下,最高效的 agents 可能会采用混合策略(hybrid strategy):为追求速度而预先检索部分数据,并根据自身判断进行进一步的自主探索。“合适”的自主程度的决策边界(decision boundary)取决于具体任务。Claude Code 就是采用这种混合模型(hybrid model)的 agent:CLAUDE.md 文件会被直接预先纳入上下文,而 glob 和 grep 等基本工具(primitives)则允许它导航环境并即时检索文件,从而有效规避过时索引(stale indexing)和复杂语法树(syntax trees)的问题。
混合策略可能更适合内容动态性较低的场景,例如法律或金融领域的工作。随着模型能力的提升,智能设计(agentic design)将倾向于让智能模型自主发挥作用,人类筛选(human curation)的参与将逐渐减少。鉴于该领域的快速发展,“做最简单且有效的事”可能仍然是我们对基于 Claude 构建 agents 的团队的最佳建议。
面向长时程任务(long-horizon tasks)的 context engineering
长时程任务(long-horizon tasks)要求 agents 在标记(tokens)数量超过 LLM 上下文窗口(context window)的一系列行动中,保持连贯性(coherence)、上下文一致性和目标导向行为(goal-directed behavior)。对于持续数十分钟到数小时的任务(例如大型代码库迁移(codebase migrations)或综合研究项目(comprehensive research projects)),agents 需要专门的技术来规避上下文窗口大小限制(context window size limitation)。
等待更大的上下文窗口(context window)似乎是一种显而易见的策略。但在可预见的未来,无论上下文窗口大小如何,都可能面临上下文污染(context pollution)和信息相关性问题——至少在需要 agent 发挥最佳性能的场景中是如此。为了使 agents 能在长时程任务中有效工作,我们开发了几种直接应对这些上下文污染约束的技术:压缩(compaction)、结构化笔记(structured note-taking)和多 agent 架构(multi-agent architectures)。
压缩(compaction)
压缩(compaction)是指当对话接近上下文窗口(context window)限制时,对其内容进行总结,并使用该总结重新启动一个新的上下文窗口的做法。在 context engineering 中,压缩通常是提升长期连贯性(coherence)的首要手段。压缩的核心是高保真(high-fidelity)地提炼上下文窗口的内容,使 agent 能够在性能下降(performance degradation)最小的情况下继续工作。
例如,在 Claude Code 中,我们通过将消息历史(message history)传递给模型,让其总结并压缩最关键的细节来实现压缩。模型会保留架构决策(architectural decisions)、未解决的漏洞(unresolved bugs)和实现细节(implementation details),同时丢弃冗余的工具输出(redundant tool outputs)或消息。之后,agent 可以基于这个压缩后的上下文以及最近访问的五个文件继续工作。用户无需担心上下文窗口限制,即可获得连贯的体验。
压缩的艺术在于选择保留和丢弃的内容,因为过度激进的压缩(overly aggressive compaction)可能会导致丢失微妙但关键的上下文——这些上下文的重要性只有在后续才会显现。对于实施压缩系统的工程师,我们建议在复杂的 agent 轨迹(agent traces)上仔细调整提示词(prompt)。首先最大化召回率(recall),确保压缩提示词能捕捉到轨迹中的所有相关信息,然后通过迭代消除多余内容(superfluous content)来提高精度(precision)。
一个容易处理的多余内容示例是清除工具调用(tool calls)和结果——一旦某个工具在消息历史的深处被调用过,agent 为何还需要再次查看原始结果?最安全、影响最小的压缩形式之一是工具结果清除,该功能最近已在 Claude 开发者平台(Claude Developer Platform)上线。
结构化笔记(structured note-taking)
结构化笔记(structured note-taking),又称智能记忆(agentic memory),是指 agent 定期将笔记写入上下文窗口之外的持久化存储(persisted memory)的技术。该策略能以最小的开销提供持久化记忆(persistent memory)。
就像 Claude Code 创建待办清单(to-do list),或你的自定义 agent 维护 NOTES.md 文件一样,这种简单模式使 agent 能够跟踪复杂任务的进度,保留关键上下文和依赖关系(dependencies)——这些内容在数十次工具调用后原本会丢失。
Claude 玩《精灵宝可梦》(Pokémon)的案例展示了记忆在非编码领域如何改变 agent 的能力。该 agent 在数千步游戏过程中保持精确记录——跟踪诸如“在过去 1234 步中,我一直在 1 号道路训练我的宝可梦,皮卡丘已朝着 10 级的目标提升了 8 级”之类的目标。在没有任何关于记忆结构的提示的情况下,它会绘制已探索区域的地图,记住已解锁的关键成就,并记录战斗策略的战略性笔记,帮助自己学习哪种攻击对不同对手最有效。
上下文重置(context resets)后,agent 会读取自己的笔记,继续数小时的训练序列或地牢探索(dungeon explorations)。这种跨总结步骤的连贯性使长时程策略成为可能——如果仅将所有信息保存在 LLM 的上下文窗口中,这是无法实现的。
作为 Sonnet 4.5 版本发布的一部分,我们在 Claude 开发者平台(Claude Developer Platform)上推出了一款记忆工具(memory tool)的公开测试版(public beta),该工具通过基于文件的系统(file-based system),使在上下文窗口之外存储和查询信息变得更加容易。这使 agents 能够逐步建立知识库(knowledge bases),在不同会话(sessions)间维护项目状态(project state),并参考之前的工作,而无需将所有内容都保存在上下文中。
sub-agent 架构(sub-agent architectures)
sub-agent 架构(sub-agent architectures)提供了另一种规避上下文限制的方法。不再由单个 agent 尝试维护整个项目的状态,而是由专门的sub-agent 处理特定任务,每个sub-agent 都拥有干净的上下文窗口(context window)。
主 agent 根据高层计划(high-level plan)进行协调,而sub-agent 则执行深入的技术工作或使用工具查找相关信息。每个sub-agent 可能会进行广泛探索,使用数万个甚至更多标记(tokens),但仅返回其工作的浓缩摘要(通常为 1000-2000 个标记)。
这种方法实现了清晰的关注点分离(separation of concerns)——详细的搜索上下文保留在sub-agent 内部,而主 agent 则专注于综合(synthesizing)和分析结果。这种模式在《我们如何构建多 agent 研究系统》一文中有详细讨论,它在复杂研究任务上比单 agent 系统表现出显著提升。
这些方法的选择取决于任务特征。例如:
- 压缩(compaction)适用于需要大量双向交互的任务,能保持对话流畅性;
- 结构化笔记(structured note-taking)适用于具有明确里程碑的迭代开发任务;
- 多 agent 架构(multi-agent architectures)适用于需要并行探索(parallel exploration)且能从中获益的复杂研究和分析任务。
即使模型不断进步,在长时间交互中保持连贯性仍然是构建更高效 agents 的核心挑战。
结论
Context engineering 代表了我们使用 LLMs 进行开发的根本性转变。随着模型能力的提升,挑战不再仅仅是编写完美的提示词(prompt)——而是在每个步骤中,精心筛选进入模型有限注意力预算(attention budget)的信息。无论你是为长时
参考
- https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
校准系统提示词(system prompt)
过于具体(Too specific)
你是 Claude 面包店的贴心助手。你必须响应“Claude”这个称呼。对于每个用户请求,你必须遵循以下步骤:1tf b erot othe foloi int ton
“requires_escalation”]
2 - 若用户意图为“问题解决(incident_resolution)”,需提出 3 个跟进问题收集信息,然后必须调用解决工具(resolve tool)- 若用户意图为“一般咨询(general_inquiry)”,无需提出跟进问题,一次性完成回答
3. 以下是应标记为“需要升级(requires_escalation)”的详尽案例列表:- 若意图为问题解决(incident_resolution),但涉及店内人身安全问题
- 若用户希望提交新订单,但他们已存在未完成的订单
过于模糊(Too vague)
你是一名面包店助手,你应尝试以 e 方式解决顾客的问题 “requires_escalation”]
恰到好处(Just right)
你是 Claude 面包店的客户支持助手,负责解答有关面包店的问题。利用可用工具高效专业地解决问题。
你可访问订单管理系统、产品目录和店铺政策。你的目标是在可能的情况下快速解决问题,提供清晰的解决方案;若有不理解的地方,可提出跟进问题。
响应框架(Response Framework):
- 识别核心问题——透过表面投诉,理解顾客的实际需求
- 收集必要上下文——使用可用工具获取解决问题所需的信息
- 提供明确解决方案——给出具体的后续步骤,确保顾客理解解决方案,并知道如需进一步帮助应如何跟进
指导原则(Guidelines):
- 若存在多种解决方案,选择最简单的一种
- 若用户提及订单,先查询订单状态再提供答复
- 若涉及超出标准政策的财务调整需求,调用人工协助工具(human_assistance tool)
- 认可用户的不满情绪或紧急需求
与编写提示词(prompt)这种离散任务不同,context engineering 是迭代式的,每次我们决定向模型(model)传递哪些内容时,筛选阶段都会发生。
校准系统提示词(system prompt)
过于具体(Too specific)
你是 Claude 面包店的贴心助手。你必须响应“Claude”这个称呼。对于每个用户请求,你必须遵循以下步骤:1tf b erot othe foloi int ton
“requires_escalation”]
2 - 若用户意图为“问题解决(incident_resolution)”,需提出 3 个跟进问题收集信息,然后必须调用解决工具(resolve tool)- 若用户意图为“一般咨询(general_inquiry)”,无需提出跟进问题,一次性完成回答
3. 以下是应标记为“需要升级(requires_escalation)”的详尽案例列表:- 若意图为问题解决(incident_resolution),但涉及店内人身安全问题
- 若用户希望提交新订单,但他们已存在未完成的订单
过于模糊(Too vague)
你是一名面包店助手,你应尝试以 e 方式解决顾客的问题 “requires_escalation”]
恰到好处(Just right)
你是 Claude 面包店的客户支持助手,负责解答有关面包店的问题。利用可用工具高效专业地解决问题。
你可访问订单管理系统、产品目录和店铺政策。你的目标是在可能的情况下快速解决问题,提供清晰的解决方案;若有不理解的地方,可提出跟进问题。
响应框架(Response Framework):
- 识别核心问题——透过表面投诉,理解顾客的实际需求
- 收集必要上下文——使用可用工具获取解决问题所需的信息
- 提供明确解决方案——给出具体的后续步骤,确保顾客理解解决方案,并知道如需进一步帮助应如何跟进
指导原则(Guidelines):
- 若存在多种解决方案,选择最简单的一种
- 若用户提及订单,先查询订单状态再提供答复
- 若涉及超出标准政策的财务调整需求,调用人工协助工具(human_assistance tool)
- 认可用户的不满情绪或紧急需求
一种极端是包含脆弱的条件判断(if-else)硬编码提示词,另一种极端是过于笼统或错误假设共享上下文的提示词。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献731条内容
已为社区贡献731条内容

所有评论(0)