微软PlugMem:用知识图拿下Agents长期记忆难题
当前大语言模型(LLM)Agent在复杂环境中长期运行面临严峻的记忆挑战。简单地将历史交互作为原始文本存储会导致**上下文爆炸**——记忆体积无限增长、计算成本飙升、关键信息淹没在噪声中。

一、 Agent记忆的困境
当前大语言模型(LLM)Agent在复杂环境中长期运行面临严峻的记忆挑战。简单地将历史交互作为原始文本存储会导致上下文爆炸——记忆体积无限增长、计算成本飙升、关键信息淹没在噪声中。
现有解决方案陷入两难困境:
- 任务专用型记忆(如LiCoMemory、AWM):针对特定场景手工设计,无法跨任务迁移
- 任务无关型记忆(如Vanilla RAG):虽具通用性,但直接检索原始经验导致信息稀疏,真正决策相关的知识被大量低级别细节掩盖
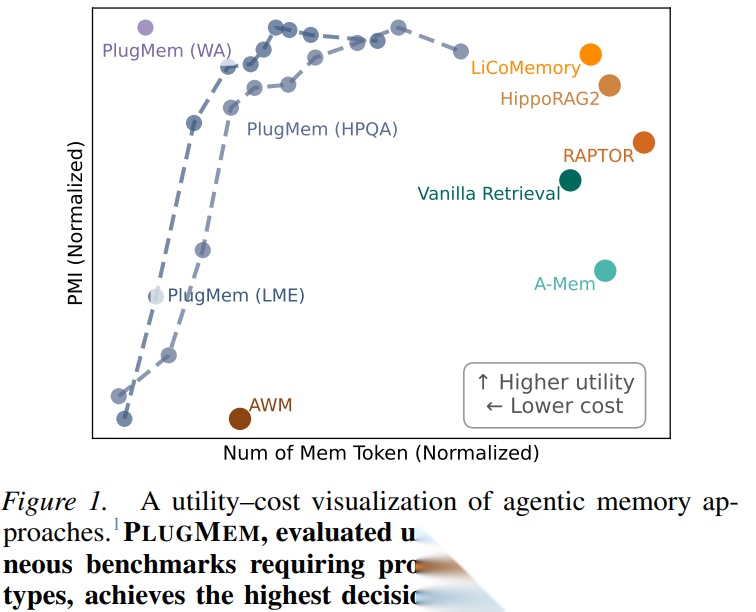
Figure 1: 效用-成本可视化对比
上图清晰展示了这一trade-off:PlugMem在三个异构基准测试上均实现了最高决策效用与最低记忆成本的最优平衡,而任务专用方法(橙色)和通用基线(绿色)均无法同时兼顾两者。
二、方案:知识中心的记忆架构
受认知科学启发(Tulving, 1972; Squire, 2004),PlugMem提出将情景记忆(原始经验)抽象为知识级记忆的通用框架,核心创新在于以"知识"而非"实体"或"文本块"作为记忆的基本单元。
2.1 三层记忆图谱架构
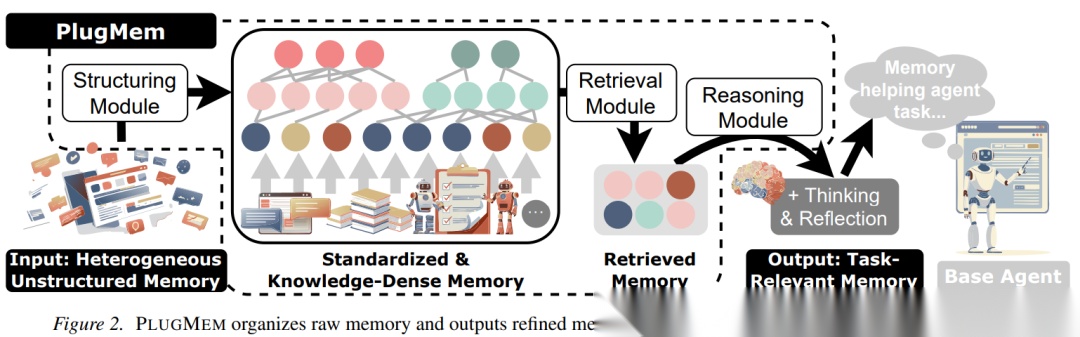
Figure 2: PlugMem系统架构
结构化模块(Structuring Module):将异构原始记忆标准化为统一格式,并提取两类知识:
- 语义记忆(Semantic):命题形式的事实知识(“知道什么”)
- 程序记忆(Procedural):处方形式的操作知识(“知道如何做”)
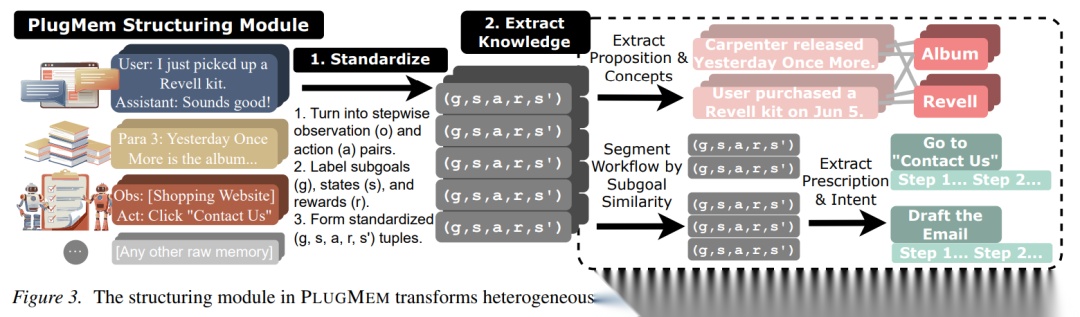
Figure 3: 结构化模块工作流程
检索模块(Retrieval Module):采用"抽象-具体"交替的多跳检索策略。通过高层概念/意图节点作为路由信号,激活相关的低层命题/处方节点,实现跨文档、跨会话的证据链构建。
推理模块(Reasoning Module):将检索到的知识聚合并压缩为任务对齐的紧凑表示,相比原始记忆减少1-2个数量级的token消耗。
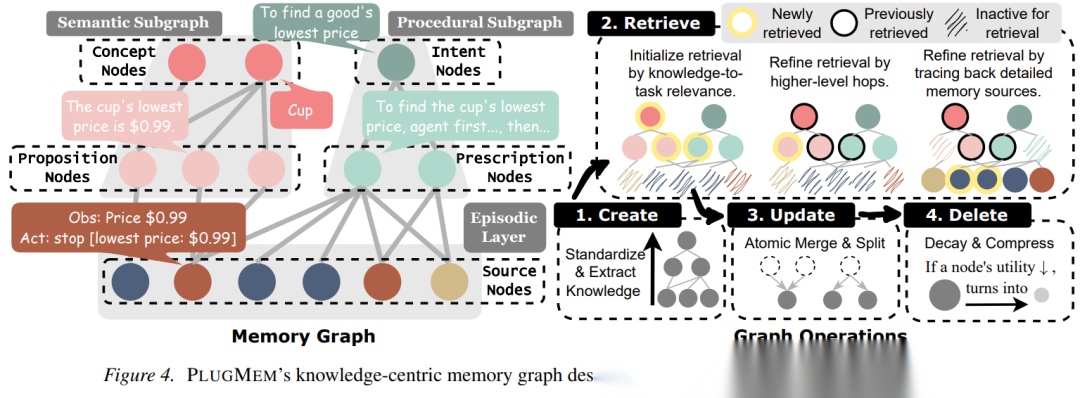
2.2 关键设计差异
| 特性 | 传统GraphRAG | PlugMem |
|---|---|---|
| 记忆单元 | 实体/文本块 | 命题(Proposition)/处方(Prescription) |
| 图谱结构 | 实体-关系-实体 | 概念→命题 / 意图→处方 |
| 检索粒度 | 基于邻接扩展 | 抽象层路由+具体层激活 |
| 任务适应性 | 需手工调整 | 即插即用 |
Table 1: 与代表性Agent记忆系统的对比

三、 通用性与效率的双重突破
3.1 核心实验结果
PlugMem在零修改条件下评估于三个异构基准,均超越任务专用设计:
| 基准测试 | 任务类型 | PlugMem表现 | 关键指标 |
|---|---|---|---|
| LongMemEval | 长程对话问答 | Acc 75.1% | 信息密度 1.6e-2(最高) |
| HotpotQA | 多跳知识检索 | EM 61.4 / F1 74.1 | 信息密度 1.4e-1(最高) |
| WebArena | 网页Agent决策 | SR 52.6%/58.4% | 记忆token仅301(基线8000+) |
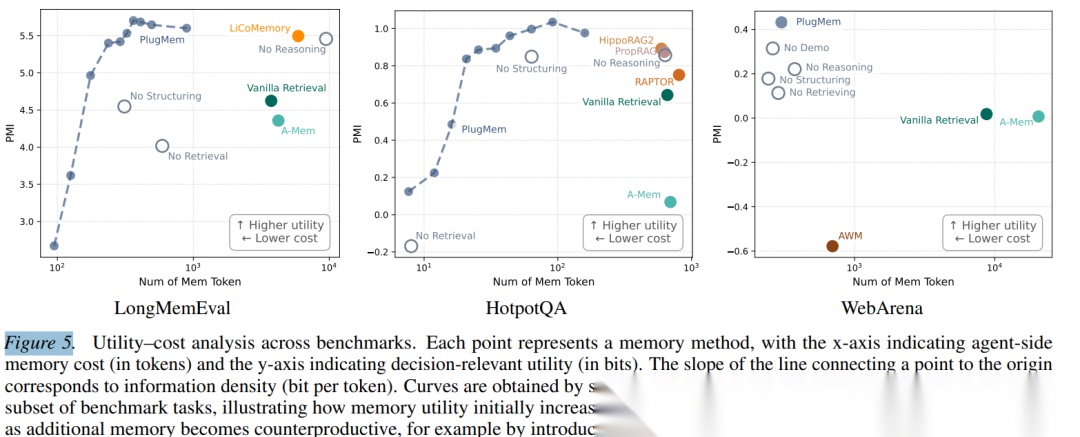
Figure 5: 跨基准效用-成本分析
3.2 关键洞察
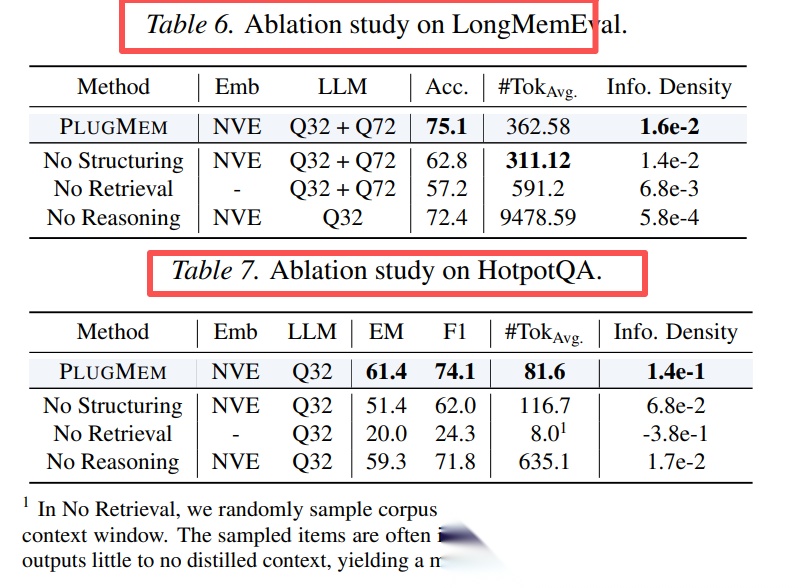
消融实验(Table 6-8)揭示了三模块的互补角色:
- 检索是决定性瓶颈:移除后性能断崖式下跌
- 结构化决定检索上限:无结构化时退化为普通RAG
- 推理主导效率:移除后token成本激增10-100倍
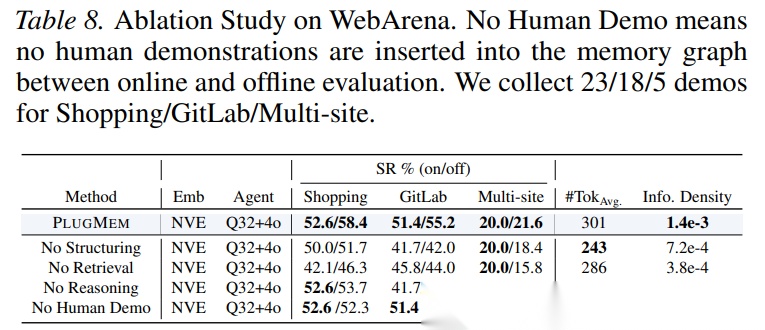
知识迁移验证(Table 5 Offline列):在WebArena的离线测试集上,PlugMem利用在线阶段积累的记忆+少量人工演示,成功率显著提升(Shopping: 58.4% vs 42.1%基线),证明其提取的程序知识可跨任务实例复用。
3.3 为什么通用设计能超越专用方案?
论文指出关键认知:Agent记忆的本质是检索驱动。任务专用设计常将领域启发式与记忆表示耦合,假设"相关记忆会被用到";而PlugMem优先解决如何让正确知识在决策时刻被激活这一根本问题——通过知识中心的结构化表示,使语义上有意义、决策上相关的抽象能够跨任务索引和恢复。
更重要的是,PlugMem定位为通用记忆骨干,任务专用技术可自然叠加其上。实验表明,集成RMM的反思机制(LongMemEval)或HippoRAG2的图遍历策略(HotpotQA)可进一步提升性能,验证了其可扩展的架构设计。
总结
PlugMem通过认知科学启发的知识抽象、知识中心的图谱组织、以及"抽象-具体"交替的检索机制,首次实现了真正任务无关且高效的Agent长期记忆。其核心启示在于:在LLM Agent时代,记忆的竞争力不在于存储更多原始经验,而在于将经验转化为可检索、可复用、可压缩的知识——这正是人类记忆区别于简单记录的本质特征。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献533条内容
已为社区贡献533条内容

所有评论(0)