大模型中的意图识别:方法、案例与引导式对话应用
本文系统介绍了大模型场景下的意图识别方法,对比了Function Calling、Embedding零样本/有监督、Few-shot、文本匹配和模型融合等多种技术,并提供了准确率数据。通过Amazon评论和银行客服案例展示了落地应用,重点探讨了引导式对话中意图识别与槽位抽取的一体化实现,以及LangGraph等流程编排方式。实验结果显示,Function Calling(GPT-4)和机器学习(X
意图识别指从用户的一句话或一段对话中,判断用户想要执行的动作或所属的类别(如「查余额」「办贷款」「转人工」等),是对话系统进行路由与后续处理的基础。本文系统介绍大模型场景下如何做意图识别:先给出多种常用方法(Function Calling、Embedding 零样本/有监督、Few-shot、文本匹配、模型融合等)及准确率对比,再用 Amazon 评论与银行客服案例说明落地方式;最后专门讲意图识别在引导式对话中的应用——从「先意图识别再路由」到 Function Calling / MCP 一次调用完成意图与槽位抽取,以及 LangGraph、策略编排等流程编排方式,便于你在选型或做智能客服、多轮对话时对照使用。
关键字:意图识别、大模型、Function Calling、Embedding、零样本分类、Few-shot、槽位抽取、引导式对话、智能客服、MCP、LangGraph、流程编排
1 提升用户意图识别准确率
1.1 几种提升用户意图识别准确率的方法
1.1.1 Function calling
Function Calling 是 OpenAI(及兼容接口)提供的一种 API 能力:在对话中除了返回自然语言外,模型还可以返回「应当调用哪个函数、以及传入哪些参数」。利用这一点,可以把意图识别转化为「模型在给定函数列表中选一个要调用的函数」:每个函数对应一个意图类别,模型选中的函数名即视为识别出的意图。
做法简述:
- 定义「工具」列表:为每个意图类别定义一个「函数」,在 API 中通过
functions(或tools)传入。每个函数至少包含:name:函数名(如handle_savings_account_management),与意图一一对应;description:用自然语言描述「在什么用户需求下应调用该函数」,相当于给模型看的类别说明,模型根据用户输入与描述的匹配程度选择要调用的函数。
- 发起一次请求:将用户当前输入作为
user消息,与上述函数列表一起传给 Chat Completions API,并设置function_call='auto'(或由模型自行决定是否调用函数)。 - 解析意图:若返回的
message中含有function_call,则其中的name即为识别出的意图;再通过本地映射(如type_dict[function_name])转成业务侧使用的类别标签。
因此:函数 A 映射到类 A、函数 B 映射到类 B;当大模型在响应中选择调用函数 A 时,即判定该输入属于类 A。无需单独训练分类器,也不依赖标注数据做 Embedding 比对,属于零样本意图识别。
💡 理解要点:就像给模型一份「菜单」(函数列表),用户说一句话,模型选一道「菜」(调用哪个函数),选中的那道菜就对应一个意图类别。
与后文的关系:本文 1.2.5 节会给出基于 Function Calling 的银行客服意图识别完整代码(含 functions 定义与 function_call_predict);2.3 节则说明在引导式对话中如何用 Function Calling 一次完成「意图 + 槽位」抽取。
1.1.2 借助 Embedding 模型进行零样本分类(zero-shot)
借助 Embedding 模型按词义编码的特性,可以做零样本分类:不训练分类器,直接根据「用户表述」与「各类别描述」的语义相似度判断类别。例如有 3 个分类(类 A、类 B、类 C),每个类别对应一句描述;对每条输入做 Embedding 后,与三个类别描述的向量计算距离(或相似度),输入归属于距离最近(或相似度最高)的那一类。
1.1.3 借助 Embedding 模型进行机器学习建模预测与分类
我们更进一步,对于Embedding之后的结果,我们可以进行有监督学习和分类。对于每一个输入语句,我们进行Embedding编码,然后将编码结果视作数值型特性并进行机器学习建模预测,预测类别。这里我们一个带有正确标注的数据集(每一个用户描述/问题,以及对应的分类结果)。我们将此数据集拆分成训练集,验证集和测试集后,然后进行机器学习,基于输入的一千多维度的 embedding vectors 去预测类别。
1.1.4 多样本分类(few-shot)
上面我们介绍了 zero-shot 的方法进行分类。更进一步的,我们可以通过 few-shot 的方法进行分类。首先,通过 zero-shot,我们可以筛选出哪些问题的分类是有问题的。然后,我们将这些问题以及正确的回答放在一起,作为reference写在prompt里面。这样可以有效地提高新问题的分类准确率。
1.1.5 基于文本搜索的有监督意图识别策略
上面的方案都是通过问题和每一个类别进行比对,然后进行配对。这里,我们换一个思路。既然我们的训练集中有那么多问题和分类的配对,对于新的一个问题,我们是否可以拿这个问题和训练集里的所有问题进行相似度计算,找到TopN的N个训练集中的问题,然后根据这几个问题所对应的分类,来决定我们现在这个新问题的类别。
总的来说,我们通过上面种种方法计算出来的准确率罗列如下:
| 意图识别方法评分 | 零样本分类(全数据集准确率) | 有监督分类(测试集准确率) |
|---|---|---|
| function_call_3.5 | 0.89863 | / |
| 机器学习_RF | / | 0.945205 |
| 机器学习_LGBM | / | 0.986301 |
| 机器学习_XGB | / | 1.0 |
| function_call_4 | 0.98356 | / |
| Few-shot-GPT3.5 | / | 0.986301 |
| Few-shot-GPT4 | / | 0.986301 |
| 文本匹配检索 | / | 0.794520 |
1.1.6 借助模型融合策略提升意图识别准确率
上面介绍的各种意图识别方法彼此相对独立,因此可以融合:对同一个新问题,用多种方法各自预测一个类别,再对预测结果投票,将票数最多的类别作为最终意图。这样可以在不增加单模型复杂度的前提下,提升整体稳定性和准确率。
💡 理解要点:模型融合类似于「多专家会诊」——每个方法投一票,取多数意见,往往比单一方法更稳。
🔍 实际例子:Function Calling 适合「类别即动作」的场景——每个意图恰好对应一个可调用的函数/动作,无需额外训练、一次 API 调用即可得到意图(详见 1.2.5 银行客服案例);Embedding 零样本/有监督适合类别固定、有标注或可描述的场景;Few-shot 和模型融合可在零样本基础上进一步提升准确率。
1.2 一个案例:Amazon Fine Food Reviews
完整的数据集中共有10个特征字段, 非常细致的记录了用户的评价行为和产品的接受度,除了基本的用户和产品信息,还有用户互动和反馈的相关内容,例如该评价对其他人是否有用、评价者的个人感受等等。具体的特征字段解释如下:
| 字段名 | 中文释义 | 描述 |
|---|---|---|
| Id | 行标识符 | |
| ProductId | 产品标识符 | 产品的唯一识别码 |
| UserId | 用户标识符 | 用户的唯一识别码 |
| ProfileName | 用户昵称 | 用户的个人昵称 |
| HelpfulnessNumerator | 有用的正面评价数 | 认为该评论有帮助的用户数量 |
| HelpfulnessDenominator | 有用评价的总数 | 表示有多少用户表示该评论有帮助或无帮助 |
| Score | 评分 | 产品的评分,介于1到5之间 |
| Time | 评论时间 | 评论发表的时间戳 |
| Summary | 评论摘要 | 对评论内容的简短总结 |
| Text | 评论文本 | 用户对产品的具体评价内容 |
这个例子的任务就是通过用户的评论来预测评分。评分分为1-5。
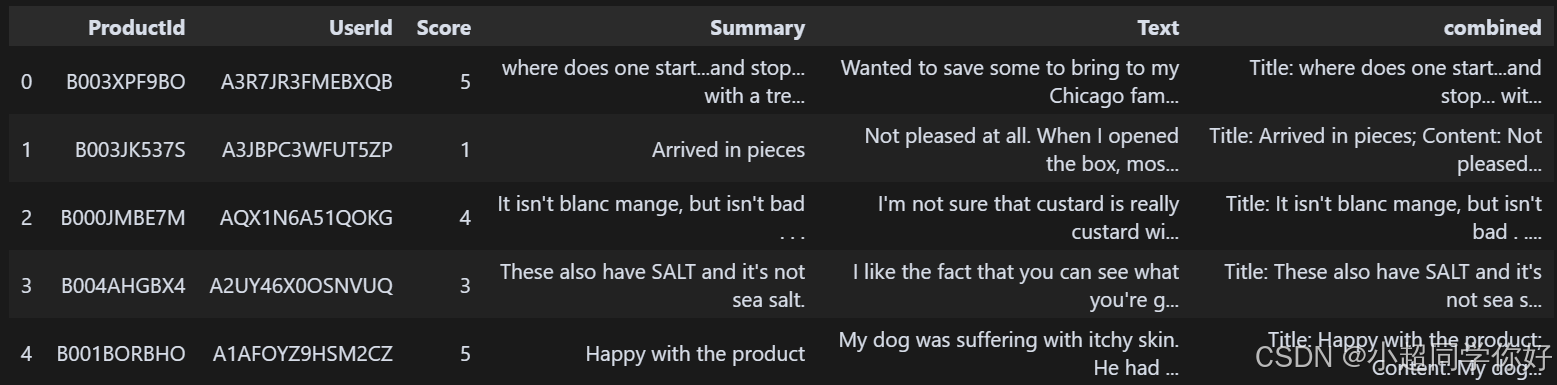
首先,我们进行数据预处理,包括选择几个字段,以及合并 Summary 以及 Text 这两个字段内容。
df = df[["ProductId", "UserId", "Score", "Summary", "Text"]] # Use main columns
df = df.dropna()
df.head(5)
# '\n' may affect embedding; replace with space
df["combined"] = (
"Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip() # Merge fields
)
df.head(5)
然后我们对 Combined 列的内容进行 embedding。
# Encode combined text with get_embedding and store results in new column 'embedding'
df_embedding_test["embedding"] = df_embedding_test.combined.apply(lambda x: get_embedding(x, engine=embedding_model))
这样一来,我们在原本的表格最右边新加了一列 embedding,用于储存生成的 embedding vector。
1.2.1 基于 Embedding 的零样本分类实现流程
我们可以首先对每个标签的描述(如“正面”和“负面”)进行Embedding转换,然后我们计算每个评论与这些分类描述之间的余弦相似度,评论与哪个分类标签的描述更接近,那么该评论就更可能属于该分类。同时为了使结果更具解释性,我们还可以设计一个预测分数,该分数是评论与“正面”标签的余弦相似度与其与“负面”标签的余弦相似度之差,如果这个差值大于0,标识为"积极",如果小于0,标识为"消极"。
需要说明的是,我们将4星和5星的评价定义为正面情绪,把1星和2星的评价定义为负面情绪,3星的评价被视为中立,在这个例子中不会使用它们。
# Note: replace datafile_path with your local file path
datafile_path = "00_data/01_Base/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)
# Use scores 1,2,4,5 and map to positive/negative; drop 3 (neutral)
df = df[df.Score != 3]
df["sentiment"] = df.Score.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"})
这里我们又增加了一列 sentiment,主要的目的是对于评价标定正面还是负面。
样本分类预测
我们拿每一句index之后的评论向量和 index之后的 negative 和 positive 进行比较,我们把这句评论归类到距离更近的那一类。
# Set embedding model name
EMBEDDING_MODEL = "text-embedding-ada-002"
# Zero-shot classification evaluation function
def evaluate_embeddings_approach(
labels = ['negative', 'positive'],
model = EMBEDDING_MODEL,
):
# Get embeddings for label strings
label_embeddings = [get_embedding(label, engine=model) for label in labels]
def label_score(review_embedding, label_embeddings):
# Score = cosine_sim(review, positive) - cosine_sim(review, negative)
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
# Compute score per review and predict sentiment
probas = df["embedding"].apply(lambda x: label_score(x, label_embeddings))
preds = probas.apply(lambda x: 'positive' if x>0 else 'negative')
report = classification_report(df.sentiment, preds)
print(report)
display = PrecisionRecallDisplay.from_predictions(df.sentiment, probas, pos_label='positive')
_ = display.ax_.set_title("2-class Precision-Recall curve")
evaluate_embeddings_approach(labels=['negative', 'positive'], model=EMBEDDING_MODEL)
然后我们计算性能:
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| negative | 0.61 | 0.88 | 0.72 | 136 |
| positive | 0.98 | 0.90 | 0.94 | 789 |
| accuracy | 0.79 | 0.89 | 0.90 | 925 |
| macro avg | 0.79 | 0.89 | 0.83 | 925 |
| weighted avg | 0.92 | 0.90 | 0.91 | 925 |
- 对于负面评论:
- 精确度(Precision): 0.61,意味着模型预测为负面的评论中,有61%确实是负面评论;
- 召回率(Recall): 0.88,说明能够检测到88%的实际负面评论;
- F1得分: 0.72,是精确度和召回率的调和平均值,为模型性能提供了一个整体评价;
- 样本(Support): 136,意味着测试数据中一共有136条负面评论;
- 对于正面评论:
- 精确度: 0.98,意味着模型预测为正面的评论中,有98%确实是正面评论;
- 召回率: 0.90,说明能够检测到90%的实际正面评论;
- F1得分: 0.94;
- 样本: 789,意味着测试数据中有789条正面评论;
- 总体评价:
- 准确率(Accuracy): 0.90,意味着模型对90%的评论做出了正确的预测;
- 宏平均(Macro avg) 和 加权平均(Weighted avg) 分别对各个标签的评价指标进行了平均,用于评估模型在整体上的性能;
接下来,我们进行一个小小的优化。原本我们只是 embedding negative 和 positive 这两个单词,现在我们将这两个单词扩充为两句话。
- negative(消极) --> ‘An Amazon review with a negative sentiment.’(带有消极情绪的亚马逊评论)
- positive(积极) --> ‘An Amazon review with a positive sentiment.’(带有积极情绪的亚马逊评论)
然后我们再次计算性能:
evaluate_embeddings_approach(labels=['An Amazon review with a negative sentiment.', 'An Amazon review with a positive sentiment.'])
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| negative | 0.98 | 0.73 | 0.84 | 136 |
| positive | 0.96 | 1.00 | 0.98 | 789 |
| accuracy | 0.96 | 925 | ||
| macro avg | 0.97 | 0.86 | 0.91 | 925 |
| weighted avg | 0.96 | 0.96 | 0.96 | 925 |
从结果上看,经过简单优化后的分类器在多个指标上都有所提升,尤其是负面评论的精确度和整体的 F1 得分。虽然负面评论的召回率有所下降,但考虑到精确度的显著提高,整体性能仍然更为出色。
💡 理解要点:零样本分类时,类别标签越丰富、越具描述性(如用完整句子代替单个词),Embedding 的区分效果往往越好,因为语义空间更清晰。
1.2.2 将 Embedding 作为文本特征编码器并进行有监督学习
这就是上一章节中提到的第二个思路:将编码结果视作数值型特性并进行机器学习建模预测,预测当前用户需求属于哪一类需求。
在这个案例中,我们的数据库是已标注的,我们使用在预处理统一的数据集并获取评论文本的Embedding表示中生成的文本Embedding向量,作为特征输入到一个随机森林回归器中,以预测评论的评分星级。具体步骤如下:
- Step 1.划分训练集和测试集
# Note: replace datafile_path with your local file path
datafile_path = "00_data/01_Base/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(list(df.embedding.values), df.Score, test_size=0.2, random_state=42)
- Step 2.构建随机森林模型并预测
选择随机森林回归器作为预测模型,是因为它能够处理较大的特征空间并提供重要的非线性建模能力。通过计算均方误差(MSE)和平均绝对误差(MAE),我们可以量化模型预测的准确性和可靠性,这些指标反映了预测评分与实际评分之间的偏差大小。
rfr = RandomForestRegressor(n_estimators=100)
rfr.fit(X_train, y_train)
preds = rfr.predict(X_test)
mse = mean_squared_error(y_test, preds)
mae = mean_absolute_error(y_test, preds)
print(f"ada-002 embedding 表现: mse={mse:.2f}, mae={mae:.2f}")
# ada-002 embedding 表现: mse=0.63, mae=0.53
- Step 3. 构建随机森林分类器
下面我们进行分类任务:
# train random forest classifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
probas = clf.predict_proba(X_test)
report = classification_report(y_test, preds)
print(report)
分类报告示例(随机森林分类器,5 星评级):
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 1 | 1.00 | 0.25 | 0.40 | 20 |
| 2 | 1.00 | 0.38 | 0.55 | 8 |
| 3 | 1.00 | 0.18 | 0.31 | 11 |
| 4 | 0.88 | 0.26 | 0.40 | 27 |
| 5 | 0.74 | 1.00 | 0.85 | 134 |
| accuracy | 0.76 | 200 | ||
| macro avg | 0.92 | 0.41 | 0.50 | 200 |
| weighted avg | 0.81 | 0.76 | 0.70 | 200 |
能够看到,随机森林分类模型已经能够较好的区分各个类别,从分类报告上来看:
-
评价星级 1:
- 精确度(Precision): 1.00 表示模型预测为评价星级为 1 的所有样本中,100% 都被正确分类。
- 召回率(Recall): 0.25 表示所有实际上属于评价星级为 1 的样本中,只有 25% 被模型正确找到并分类。
- F1得分: 0.40 是精确度和召回率的调和平均,考虑到二者的平衡,得分较低,说明模型在这个评价星级上的表现不佳。
- 样本数(Support): 20 表示实际上有 20 个样本属于评价星级 1。
-
评价星级 2、3、4:
- 这几个类别的情况与评价星级 1 类似,精确度较高,但召回率和F1得分较低,说明模型在这几个类别上的预测能力有待提升。
- 评价星级 5:
- 精确度稍低(0.74),但召回率非常高(1.00),说明模型倾向于将样本分类为评价星级 5,这可能导致其他类别的召回率降低。
- F1得分较高(0.85),说明在评价星级 5 上的预测表现较好。
- 样本数为 134,说明评价星级 5 的样本量较大。
整体来看,模型在1星至4星的评分类别上表现欠佳,尤其是在召回率上,所以对于较低星级的评论的预测正确性有待提高。然而,在5星评级上,模型的表现相对最佳,这可能是因为5星评价在数据集中出现频率较高。尽管存在类别不平衡的问题,但模型整体的准确率达到了76%,这显示出模型具备相对较好的分类能力。
除此之外,我们还可以使用OpenAI Embedding API 提供的plot_multiclass_precision_recall函数绘制多类别的精确度-召回率曲线图,更加直观的看到模型在各个星级类别上的性能。
plot_multiclass_precision_recall(probas, y_test, [1, 2, 3, 4, 5], clf)
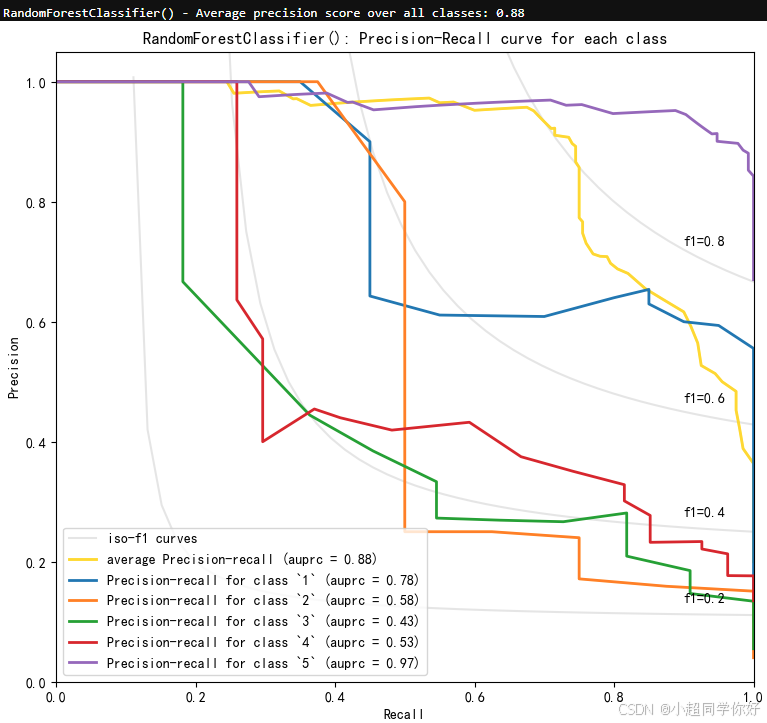
综上,Embedding 不仅可用于自由文本的特征编码,在处理具有丰富语义的分类变量(如职务名称、评分类别)时,也能捕捉潜在关系和层次结构;与 SVD/PCA 等降维方法相比,在保留信息的前提下往往能维持或提升模型性能。
🔍 实际例子:将评论文本先 Embedding 再喂给随机森林/XGB 等模型,相当于用「语义向量」代替原始文本,适合标注数据充足、希望利用语义的意图或情感分类任务。
1.2.3 借助 Embedding 进行聚类分析(K-means)
Embedding 为聚类算法提供了一种量化文本相似度的方式,使其可以基于向量间的距离或相似度将文本归纳到不同的类别中。
以我们所使用的亚马逊精选美食评论数据集来说,在经过预处理统一的数据集并获取评论文本的Embedding表示中的一系列处理后,我们现在已经有了评论文本的Embedding表示,那么我们就可以直接使用聚类算法,发现用户评论中的隐含主题或趋势,自动地为用户画像划分不同的类别。
# Note: replace datafile_path with your local file path
datafile_path = "00_data/01_Base/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)
matrix = np.vstack(df.embedding.values) # 1000 x 1536: each row = one review embedding
n_clusters = 4
kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
df["Cluster"] = labels
df.groupby(["Cluster"])["Text"].count().plot(kind='pie', title='Score Distribution', figsize=(4, 4), autopct='%1.2f%%')
我们做一个饼图:
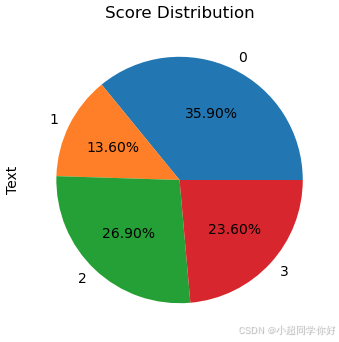
如上图所示,这张饼状图直观地展示了K-Means聚类算法将评论分为四个类别后的结果。从分布数量上来看,这是一个不均匀的分布,其中类别0包含了最多的评论(约36%),而类别1则包含了最少的评论(约14%)。类别中评论数量的差异可能暗示了聚类的质量。一个较好的聚类结果通常希望在各个类别之间有比较均衡的数据点分配,如果某个类别中的样本数量特别大,可能意味着聚类过程将过多不同的点归为同一类,但也可能确实反映了数据中的一个主要趋势。所以这样的效果是好还是坏,我们需要进行更进一步的探索来验证。
我们还可以对聚类完的Embedding数据进行降维可视化。这里我们使用t-SNE先将1536的维度降为2维,每个点的x和y坐标是由t-SNE算法计算出的,代表原始高维空间中的文本数据,最后,我们根据不同的聚类标签(Cluster)为点着色,以区分数据点所属的聚类。代码如下:
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200)
vis_dims2 = tsne.fit_transform(matrix)
x = [x for x, y in vis_dims2]
y = [y for x, y in vis_dims2]
legends_ = []
for category, color in enumerate(["purple", "green", "red", "blue"]):
legends_.append(category)
xs = np.array(x)[df.Cluster == category]
ys = np.array(y)[df.Cluster == category]
plt.scatter(xs, ys, color=color, alpha=0.3)
legends_.append(category)
avg_x = xs.mean()
avg_y = ys.mean()
plt.scatter(avg_x, avg_y, marker="x", linewidths=3 ,color=color, s=100)
plt.legend(legends_)
plt.title("Clusters identified visualized in language 2d using t-SNE")
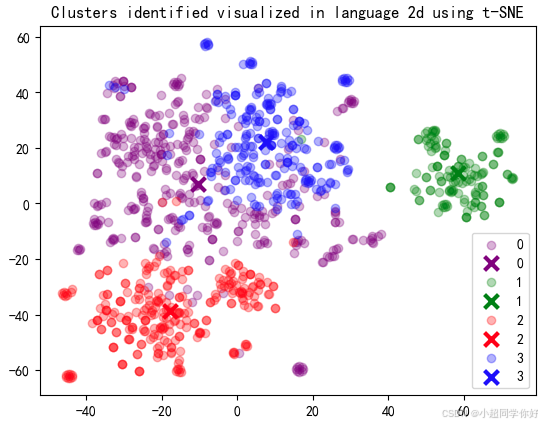
对于每一类,我们可以再用一个LLM Prompt,分析抽取出来的每个样本类别中的评论的主题和共性,从而确定每个类别到底属于哪一种评论类型。比如 prompt可以这么写:prompt=f'以下客户评论有什么共同点?\n\n客户观点:\n"""\n{reviews}\n"""\n\n主题:'。
1.2.4 借助 Embedding 进行文本搜索
Embedding 作为一种高效捕获语义信息的技术手段,借助Embedding 实现搜索查询,它可以通过语义化的方式高效且成本低廉地在大量文本中搜寻最为相关的评论。
# Note: replace datafile_path with your local file path
datafile_path = "./01_Base/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)
接下来,我们需要定义一个搜索函数,来实现在评论数据集中寻找与给定搜索描述最为相似的评论的功能。具体逻辑分为以下三个核心过程:
- 借助OpenAI的Embedding模型,将传入的搜索描述转化为Embedding向量;
- 计算搜索描述的 Embedding 向量与每条评论的 Embedding 向量之间的余弦相似度;
- 根据余弦相似度对评论进行排序,选择相似度最高的前
n个评论。
def search_reviews(df, product_description, n=3, pprint=True):
"""
Search top-n reviews by cosine similarity to product_description.
:param df: review DataFrame with 'embedding' column
:param product_description: query text to match
:param n: number of top results to return
"""
product_embedding = get_embedding(
product_description,
engine="text-embedding-ada-002"
)
df["similarity"] = df.embedding.apply(lambda x: cosine_similarity(x, product_embedding))
results = (
df.sort_values("similarity", ascending=False)
.head(n)
.combined.str.replace("Title: ", "")
.str.replace("; Content:", ": ")
)
if pprint:
for r in results:
print(r[:200])
print()
return results
函数接收四个参数,如下:
| 参数 | 描述 | 类型 | 默认值 |
|---|---|---|---|
df |
数据集的DataFrame | DataFrame | N/A |
product_description |
搜索描述,用于匹配评论 | str | N/A |
n |
指定返回的最相似评论数量 | int | 3 |
pprint |
一个布尔值,指定是否打印结果 | bool | True |
接下来,我们将调用search_reviews函数,输入不同的搜索描述,返回最相关的前3条评论。
results = search_reviews(df, "delicious beans", n=3)
Good Buy: I liked the beans. They were vacuum sealed, plump and moist. Would recommend them for any use. I personally split and stuck them in some vodka to make vanilla extract. Yum!
Jamaican Blue beans: Excellent coffee bean for roasting. Our family just purchased another 5 pounds for more roasting. Plenty of flavor and mild on acidity when roasted to a dark brown bean and befor
Delicious!: I enjoy this white beans seasoning, it gives a rich flavor to the beans I just love it, my mother in law didn't know about this Zatarain's brand and now she is traying different seasoning
匹配结果足以表明,Embedding 不仅能做关键词表面匹配,还能捕捉语义深层联系,在评论搜索中精确找到相关内容和用户情感,适合构建问答系统、个性化推荐等场景。
🔍 实际例子:用户搜「delicious beans」时,语义搜索能同时命中「好喝」「咖啡豆」「白豆调味」等不同表述,而不依赖字面一致。
1.2.5 借助 Embedding 模型进行多样本分类(Few-shot)
这里我们使用到另外一个数据集,模拟银行办理业务场景。我们希望将用户的问题进行分类,下面是五个类别以及每个类别各自的一个例子:
-
储蓄账户开设与管理
- 客户:“你好,我想开一个储蓄账户。我需要了解一下开户的流程和需要的文件。另外,我还想知道你们的利率是多少。”
-
贷款服务
- 客户:“我想咨询一下关于房屋贷款的事情。我刚看中了一套房子,想知道申请贷款的条件和大概的年利率。还有,贷款的最长期限可以是多久呢?”
-
信用卡服务
- 客户:“嗨,我昨天收到了你们邮寄的新信用卡,但我不太清楚怎么激活它。还有,能不能顺便帮我检查一下我的信用额度,看看是否可以提高一些?”
-
投资与理财咨询
- 客户:“你好,我最近在考虑一些投资理财的事情,但不太了解市场。你们能提供一些基础的股票或者基金投资建议吗?我主要是想为退休后做些准备。”
-
国际业务与汇款
- 客户:“我需要汇一笔款项到国外的家人那里,想问一下你们的国际汇款手续费是多少?同时,我还想了解一下汇款的时效和汇率。”
首先我们进行 zero-shot,我们将每一句用户的问题进行 embedding,将其输出的向量和这五个分类描述进行距离计算,用户的问题被归类为距离最近的那一个分类。然后,我们将训练集中所有分错类的语句提取出来,比如:
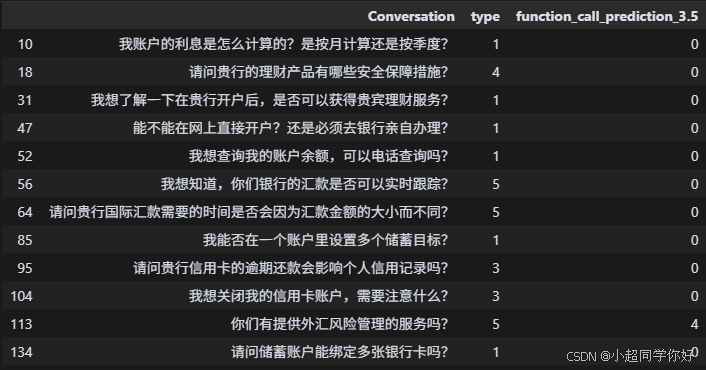
然后,我们基于误判样本创建Few-shot:
system_message = [{"role": "system", "content": "你是一个智能银行客户接待应用,输入的每个user message都是某位银行客户的需求。\
你的每一次回答都必须调用function call来完成。请仔细甄别用户需求,并合理调用外部函数来进行回答。"}]
few_shot_messages = []
def get_key_by_value(dict, value):
for key, val in dict.items():
if val == value:
return key
return None
for index, row in train_temp_3.iterrows():
text = row['Conversation']
intention_category = row['type']
function_name = get_key_by_value(type_dict, intention_category)
assistant_message = {
"role": "assistant",
"content": None,
"function_call": {
"name": function_name,
"arguments": "{}"
}
}
few_shot_messages.append({"role": "user", "content": text})
few_shot_messages.append(assistant_message)
messages = system_message + few_shot_messages
messages 打印出来的结果类似:
[{'role': 'system',
'content': '你是一个智能银行客户接待应用,输入的每个user message都是某位银行客户的需求。你的每一次回答都必须调用function call来完成。请仔细甄别用户需求,并合理调用外部函数来进行回答。'},
{'role': 'user', 'content': '我账户的利息是怎么计算的?是按月计算还是按季度?'},
{'role': 'assistant',
'content': None,
'function_call': {'name': 'handle_savings_account_management',
'arguments': '{}'}},
{'role': 'user', 'content': '请问贵行的理财产品有哪些安全保障措施?'},
{'role': 'assistant',
'content': None,
'function_call': {'name': 'handle_investment_advisory', 'arguments': '{}'}},
{'role': 'user', 'content': '我想了解一下在贵行开户后,是否可以获得贵宾理财服务?'},
{'role': 'assistant',
'content': None,
'function_call': {'name': 'handle_savings_account_management',
'arguments': '{}'}},
{'role': 'user', 'content': '能不能在网上直接开户?还是必须去银行亲自办理?'},
{'role': 'assistant',
'content': None,
'function_call': {'name': 'handle_savings_account_management',
'arguments': '{}'}},
...
{'role': 'user', 'content': '你们的汇款时效一般是多久?'},
{'role': 'assistant',
'content': None,
'function_call': {'name': 'handle_international_transactions',
'arguments': '{}'}},
{'role': 'user', 'content': '我丢失了我的银行卡,需要怎样办理挂失和重新申请?'},
{'role': 'assistant',
'content': None,
'function_call': {'name': 'handle_savings_account_management',
'arguments': '{}'}},
{'role': 'user', 'content': '你们银行储蓄账户的存款保险覆盖多少金额?'},
{'role': 'assistant',
'content': None,
'function_call': {'name': 'handle_savings_account_management',
'arguments': '{}'}}]
然后,我们把上述所有的信息放入prompt中,
def function_call_predict(messages, model='gpt-3.5-turbo-0613'):
# Get model response (with optional function call)
response = openai.ChatCompletion.create(
model=model,
messages=messages,
functions=functions,
function_call='auto',
)
response_message = response["choices"][0]["message"]
# Map chosen function to intent category
res = 0
if response_message.get("function_call"):
function_name = response_message["function_call"]["name"]
res = type_dict[function_name]
return res
最后,我们将所有的测试数据都走一遍,计算识别精度。
def process_dataset(dataset,
messages=None,
model_name='gpt-4-0613',
text_col_name='Conversation',
prediction_col_name='function_call_prediction_4'):
"""
Run intent recognition (function_call_predict) on each row of the dataset.
:param dataset: DataFrame to process
:param messages: Few-shot messages (system + examples); None for no prompt
:param model_name: model name for API
:param text_col_name: column name for user text input
:param prediction_col_name: column name for predicted intent
:return: DataFrame with prediction column filled
"""
if messages == None:
input_messages = []
else:
input_messages = messages.copy()
for index in range(len(dataset)):
success = False
while not success:
try:
text = dataset.at[index, text_col_name]
input_messages.append({"role": "user", "content": text})
result = function_call_predict(input_messages, model=model_name)
dataset.at[index, prediction_col_name] = result
success = True
input_messages = messages.copy()
except Exception as e:
print(f"Error on row {index}: {e}")
time.sleep(60) # Retry after 1 minute
if index % 10 == 0:
print(f"Processed {index}/{len(dataset)} rows")
return dataset
test_df = process_dataset(dataset=test_df,
messages=messages,
model_name='gpt-3.5-turbo-0613',
prediction_col_name='function_call_prediction_3.5_new')
我们创建了一列 function_call_prediction_3.5_new 来存放预测结果。
总的来说,我们通过上面种种方法计算出来的准确率罗列如下:
| 意图识别方法评分 | 零样本分类(全数据集准确率) | 有监督分类(测试集准确率) |
|---|---|---|
| function_call_3.5 | 0.89863 | / |
| 机器学习_RF | / | 0.945205 |
| 机器学习_LGBM | / | 0.986301 |
| 机器学习_XGB | / | 1.0 |
| function_call_4 | 0.98356 | / |
| Few-shot-GPT3.5 | / | 0.986301 |
2. 意图识别在引导式对话中的应用
引导式对话系统(如订披萨、售后换货、智能问诊)需要在每一轮根据用户回复做分支判断:是在填业务信息(槽位)、在问无关问题,还是要查外部系统。这本质上就是意图识别 + 槽位抽取在多轮对话中的落地。下面把引导式对话里常见的几种意图识别与槽位抽取方案做个整合,与上文「单轮意图分类」形成互补;更完整的场景与业务模式可参考同目录下的 引导式对话系统(上)、(下)。
2.1 引导式对话中意图与分支判断的角色
整体上,引导式对话通过槽位抽取、流程编排与外部功能调用配合完成业务闭环。其中关键一步是分支判断:根据用户本轮回复,系统进入三种分支之一。下图为整体技术架构示意。
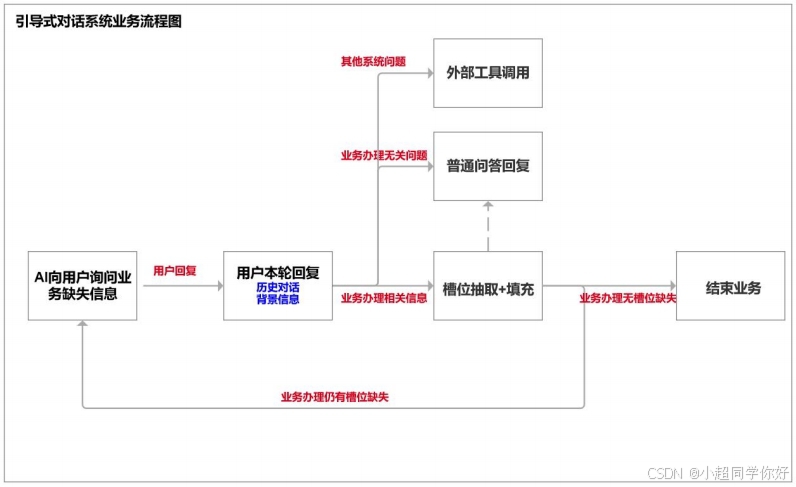
- 业务办理相关信息:进入「槽位抽取 + 填充」——从回复中抽取槽位值(如型号、购买时间、地址),更新状态后判断槽位是否已满,未满则继续追问,已满则结束业务(如生成工单、提交订单)。
- 业务办理无关问题:进入「普通问答回复」(如用户问「电扇怎么保养」),直接回答后回到等待用户输入,不中断主流程。
- 其他系统问题:进入「外部工具调用」(如查订单、查物流),调用接口后把结果回复用户,再继续对话。
因此,意图识别在这里的作用是:区分「本轮是在填槽位 / 问无关问题 / 调外部工具」,从而决定走哪条分支;槽位抽取则负责从自然语言中结构化出业务字段。
2.2 方案一:先意图识别再路由(提示词 + 多意图识别)
一种直观做法是先做意图识别,再按意图路由:
- 多意图识别(第一次调用大模型):判断本轮是「回答询问 / 闲聊 / 转人工 / 普通咨询 / 信息调整 / 信息补充」等。
- 路由决策:根据意图决定下一步——信息抽取、闲聊承接、转人工、查知识库等。
- 下游处理(可能第二次甚至多次调用大模型):例如意图为「信息抽取」时再调 LLM 做多槽位联合抽取;意图为「信息调整」或「信息补充」时,将历史槽位与本轮输入合并后再做槽位抽取。
- 话术回复:再调用一次 LLM 将结果包装成自然语言回复。
槽位抽取本身可用提示词 + Few-shot 指定输出格式(如 JSON),实现简单、易适配业务。但该方案存在明显问题:一轮对话多次调用大模型,延迟与成本高;意图边界模糊(如「我想换货,顺便问下保修政策」同时包含换货与咨询);信息调整/补充时易与「新信息」混淆,槽位状态难维护;多次调用还会放大错误。因此更适合做快速验证,不适合对延迟和稳定性要求高的生产环境。
2.3 方案二与方案三:Function Calling 与 MCP(意图与槽位一次完成)
Function Calling 和 MCP(Model Context Protocol) 把「选哪个动作」和「填哪些槽位」放在同一次大模型调用里完成:向模型声明一组工具(函数),每个工具对应一类业务动作及所需参数(槽位);模型根据用户输入直接返回要调用的函数名和参数(即意图 + 槽位值),格式由 schema 约束,稳定可解析。
- Function Calling:在单项目内定义工具与槽位 schema,一次调用同时完成意图选择与槽位抽取,适合个人或单项目开发。
- MCP:在 Function Calling 之上做标准化与复用,将工具与槽位逻辑封装在 Server 端,多项目/多语言通过 Client 调用,适合企业多业务线共用同一套客服或工单能力。
两者都避免了「先意图识别再路由」带来的多轮调用与意图边界模糊问题,槽位输出结构化、易校验,是当前引导式对话里更推荐的实现方式。选型上:快速原型或单轮简单槽位可用提示词结构化抽取;单项目、对复用无要求用原生 Function Calling;多项目协同、标准化客服建设用 MCP。
2.4 流程编排:LangGraph 与策略编排
意图与槽位确定之后,还需要流程编排决定「下一轮问什么、何时结束」:
- LangGraph:用图结构(节点、边、状态)编排对话流程。节点可对应「调用槽位抽取工具」「自由问答」「查知识库」等;根据状态中槽位是否填满做条件分支(继续追问 vs 结束业务)。适合需要清晰表达多分支、多轮状态的复杂对话。
- 策略编排(一次调用 + 程序化话术):Agent 层只做一次大模型调用(理解用户 + 决策:抽槽位 / 自由回复 / 调工具),由策略层用程序化的「缺失槽位检查 + 话术模板」生成追问或确认,不再为话术二次调用 LLM,降低延迟与错误累积。
二者都与 Function Calling / MCP 结合使用:由 FC 或 MCP 完成单轮内的意图与槽位抽取,由 LangGraph 或策略编排管理多轮状态与话术生成。更多细节与图示见 引导式对话系统(下):槽位抽取、Function Calling 与流程编排怎么落地?。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)