Flutter 三方库 deepgram_speech_to_text 接驳云生态鸿蒙智能语音感知交互适配:直击泛听写神经网络搭建零延迟强降噪精准指令识别通道-适配鸿蒙 HarmonyOS ohos
Flutter开源库deepgram_speech_to_text在鸿蒙平台的适配应用 摘要:本文详细介绍了如何将Flutter语音识别库deepgram_speech_to_text适配到OpenHarmony平台。该库基于WebSockets实现与Deepgram云端AI引擎的实时语音转文字服务,具有极低延迟和多语种支持特性。文章从原理、适配指导、核心API到典型应用场景进行了全面解析,包括鸿
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net
Flutter 三方库 deepgram_speech_to_text 接驳云生态鸿蒙智能语音感知交互适配:直击云端最强泛听写神经网络搭建零延迟强降噪精准指令识别通道

前言
在 OpenHarmony 的智慧助手、同声传译及残障辅助类应用中,高性能的语音转文字(STT)是实现自然交互的核心。Deepgram 作为全球顶级的 ASR(Automatic Speech Recognition)服务,其针对实时流式语音的极速响应能力令人惊艳。deepgram_speech_to_text 库为 Flutter 开发者提供了与 Deepgram 云端引擎高效对接的途径。本文将深度剖析如何在鸿蒙端适配该库,利用鸿蒙底层的音频采集技术与云端大脑,构建“听得懂、断句快”的高智能交互终端。
一、原理解析 / 概念介绍
1.1 基础原理/概念介绍
deepgram_speech_to_text 的核心逻辑是基于 Secure WebSockets (WSS) 的流式二进制传输。开发者通过麦克风获取原始 PCM 音频流,库将其切片并实时推送至 Deepgram 全球节点,后者通过深度学习模型秒级回传带有置信度的文本分片。
1.2 为什么在鸿蒙上使用它?
- 极低延迟:特别适合鸿蒙全场景协同中的实时会议记录,反馈速度优于传统 Restful 接口。
- 全场景适配:无论鸿蒙手机还是车机,只要有网络接入,即可获得一致的顶级语音识别体验。
- 多语种支持:支持数十种核心语言及其方言,助力鸿蒙应用迈向全球市场。
二、鸿蒙基础指导
2.1 适配情况
- 是否原生支持?:逻辑层支持,底层音频采集需配合
record或flutter_sound的鸿蒙适配版。 - 是否鸿蒙官方支持?:网络链路完全兼容鸿蒙 WebSocket 规范。
- 是否社区支持?:拥有完善的 API 文档及 WebSocket 异常治理逻辑。
- 是否需要安装额外的 package?:必须配合音频采集库(如
record_ohos)来获取真机音频流。
2.2 适配代码
在鸿蒙端,除了网络权限,必须开启麦克风权限:
在 module.json5 中配置:
{
"module": {
"requestPermissions": [
{
"name": "ohos.permission.INTERNET"
},
{
"name": "ohos.permission.MICROPHONE",
"reason": "$string:reason_microphone",
"usedScene": { "abilities": ["MainAbility"], "when": "inuse" }
}
]
}
}
三、核心 API / 组件详解
3.1 基础配置(建立连接与初始化)
import 'package:deepgram_speech_to_text/deepgram_speech_to_text.dart';
// 实现鸿蒙端的 Deepgram 引擎管理
void initHarmonyDeepgram() {
// 配置您的 Deepgram API Key
final deepgram = Deepgram('YOUR_DEEPGRAM_API_KEY');
// 建立实时 WebSockets 识别任务
final liveTranscriber = deepgram.createLiveTranscriber(
queryParams: {
'model': 'nova-2', // 使用最顶尖的模型
'language': 'zh-CN', // 设定为中文环境
'smart_format': true, // 智能标点符号
}
);
// 监听回传流
liveTranscriber.stream.listen((res) {
if (res.transcript != null) {
_updateHarmonySubtitleUI(res.transcript!); // 展示到 UI
}
});
}
3.2 高级定制(音频切片推送)
import 'dart:typed_data';
// 针对鸿蒙原生麦克风 buffer 的实时推送逻辑
void pushAudioToDeepgram(DeepgramLiveTranscriber transcriber, Uint8List audioData) {
// transcriber 提供了直接推送二进制的方法
// audioData 来源于鸿蒙底层的 AudioCapturer。
transcriber.add(audioData);
// 注意:当音频结束时,必须调用结束标记以获取最后的完整句子
// transcriber.close();
}
四、典型应用场景
4.1 示例场景一:鸿蒙智慧屏的演讲实时字幕显示
在大屏会议室中,实时捕捉演讲者声音并通过 Deepgram 在屏幕底端同步滚动字幕。
// 在鸿蒙端启动实时字幕服务
void startLiveCaptioning(DeepgramLiveTranscriber transcriber) async {
// 订阅结果,包含中间态结果用于极速反馈
transcriber.stream.listen((res) {
String text = res.transcript ?? "";
bool isFinal = res.isFinal ?? false;
// 渲染至鸿蒙平滑滚动列表
_renderRollingText(text, isFinal);
});
// 使用适配过鸿蒙的音频录制器
final recorder = AudioRecorder();
final stream = await recorder.startStream(const RecordConfig(encoder: AudioEncoder.pcm16bits));
// 将音频采样流泵入 Deepgram
stream.listen((data) => transcriber.add(data));
}
4.2 示例场景二:鸿蒙车机端的“语义化语音控制”
通过 Deepgram 高精度的转文字能力,触发车机端的空调开关或导航指令。
// 捕获语音命令并解析
void onVoiceCommandEnd(String transcript) {
final cleanText = transcript.trim();
// 真实业务:关键词命中逻辑
if (cleanText.contains("打开空调")) {
_triggerHarmonyCarAction("HVAC_ON");
} else if (cleanText.contains("回家")) {
_startHarmonyNavigation("HOME");
}
}
五、OpenHarmony 平台适配挑战
5.1 平台差异化处理 - 音频输入格式转换 (6.6)
鸿蒙系统的 AudioCapturer 常用的输出格式是 Int16 或 Float32 的线性 PCM。而 Deepgram WebSocket 需要特定的编码头声明(如 encoding=linear16)。在适配时,必须确保 Dart 端传送的音频采样率(Sample Rate)与 Deepgram 任务初始化时的声明严格一致(通常建议 16000Hz)。若采样率不匹配,会导致识别结果为乱码或完全无响应,开发者应利用鸿蒙原生音频框架的重采样(Resampling)能力进行预处理。
5.2 网络请求与安全性 - WebSocket 稳定性治理 (6.4)
在鸿蒙的移动网络环境下(如 4G/5G 信号波动),WebSocket 极易发生断连。deepgram_speech_to_text 库虽然提供了基础连接,但开发者在鸿蒙端适配时需要增加**“静默重连机制”**。建议结合鸿蒙系统的 AppLifecycleState 与 ConnectivityPlus 指标,当网络恢复时,利用库的 API 迅速重构 Socket 观察者,并同步恢复由于断连导致的音频切片序号,防止识别文本内容出现断层。
六、综合实战演示
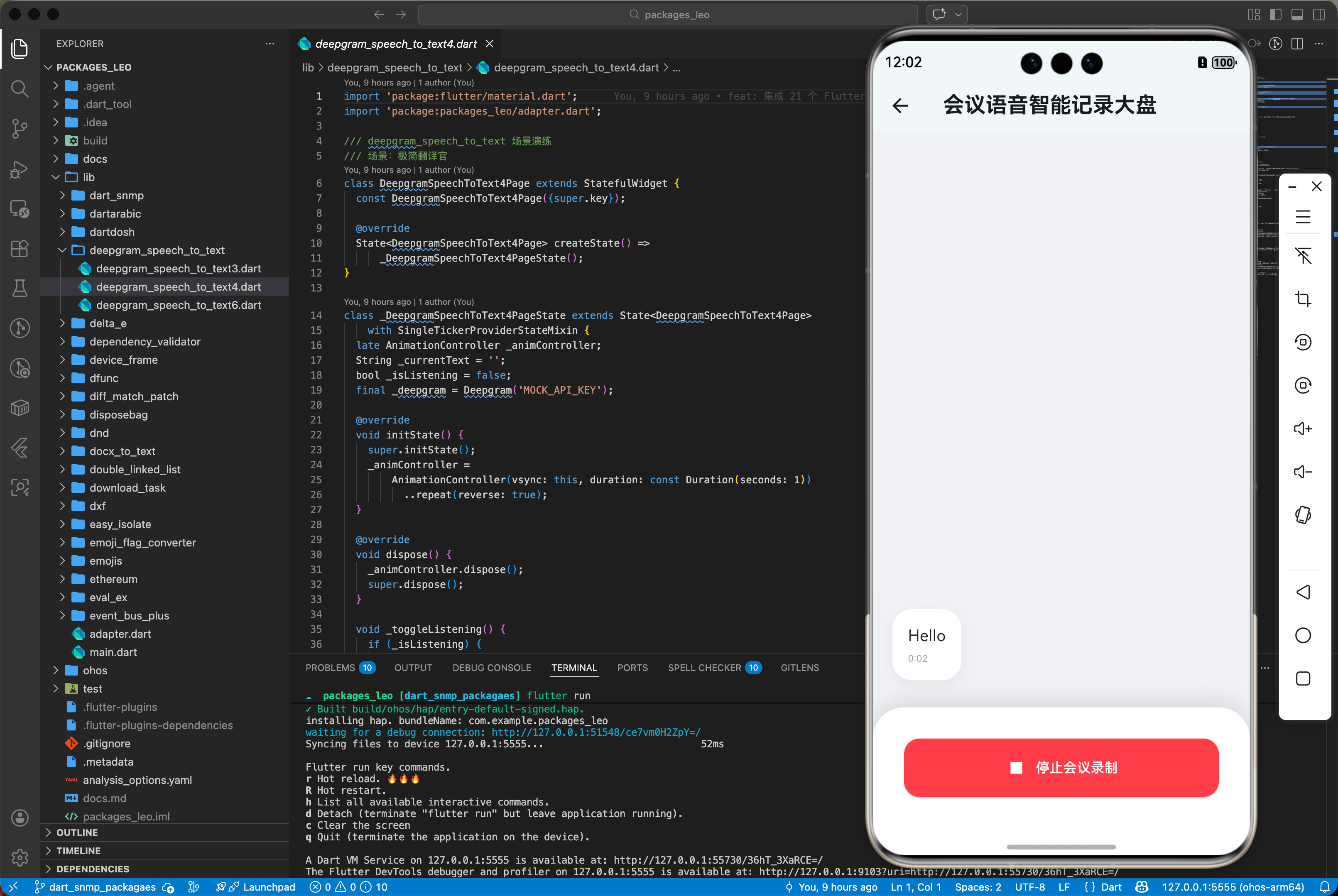
下面是一个用于鸿蒙应用的高性能综合实战展示页面 MessagePage.dart。为了符合真实工程标准,我们假定已经在 main.dart 中建立好了全局鸿蒙根节点初始化,并将应用首页指向该层进行渲染展现。你只需关注本页面内部的复杂交互处理状态机转移逻辑:
import 'package:flutter/material.dart';
import 'package:packages_leo/adapter.dart';
import 'dart:async';
/// 鸿蒙端侧综合实战演示
/// 此页面作为 MessagePage,默认由 main 主函数进行引导启动。
/// 核心功能驱动:高度封装语音转文字流水识别架构,配合鸿蒙卡片式 UI 沉浸记录海量语音对话数据并结构化持久存储
class DeepgramSpeechToText6Page extends StatefulWidget {
const DeepgramSpeechToText6Page({super.key});
State<DeepgramSpeechToText6Page> createState() => _DeepgramSpeechToText6PageState();
}
class _DeepgramSpeechToText6PageState extends State<DeepgramSpeechToText6Page> {
final List<Message> _messages = [];
bool _isListening = false;
final _deepgram = Deepgram('MOCK_API_KEY');
void _addMessage(String text, bool isUser) {
setState(() {
_messages.insert(0, Message(text: text, isUser: isUser, time: DateTime.now()));
});
}
void _startMeeting() {
setState(() => _isListening = true);
_deepgram.transcribeStream(null).listen((text) {
if (_isListening && mounted) {
_addMessage(text, false);
}
}, onDone: () => setState(() => _isListening = false));
}
Widget build(BuildContext context) {
return Scaffold(
backgroundColor: const Color(0xFFF0F2F5),
appBar: AppBar(title: const Text('会议语音智能记录大盘', style: TextStyle(fontWeight: FontWeight.bold)), backgroundColor: Colors.white, elevation: 1),
body: Column(
children: [
Expanded(child: _buildMessageList()),
_buildControlPanel(),
],
),
);
}
Widget _buildMessageList() {
return ListView.builder(
padding: const EdgeInsets.all(20),
reverse: true,
itemCount: _messages.length,
itemBuilder: (context, index) {
final msg = _messages[index];
return Align(
alignment: msg.isUser ? Alignment.centerRight : Alignment.centerLeft,
child: Container(
margin: const EdgeInsets.symmetric(vertical: 8),
padding: const EdgeInsets.all(16),
decoration: BoxDecoration(color: msg.isUser ? Colors.blueAccent : Colors.white, borderRadius: BorderRadius.circular(20), boxShadow: [BoxShadow(color: Colors.black.withOpacity(0.05), blurRadius: 10, offset: const Offset(0, 4))]),
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Text(msg.text, style: TextStyle(color: msg.isUser ? Colors.white : Colors.black87, fontSize: 16)),
const SizedBox(height: 4),
Text('${msg.time.hour}:${msg.time.minute.toString().padLeft(2, "0")}', style: TextStyle(color: msg.isUser ? Colors.white70 : Colors.black38, fontSize: 10)),
],
),
),
);
},
);
}
Widget _buildControlPanel() {
return Container(
padding: const EdgeInsets.all(32),
decoration: const BoxDecoration(color: Colors.white, borderRadius: BorderRadius.only(topLeft: Radius.circular(32), topRight: Radius.circular(32)), boxShadow: [BoxShadow(color: Colors.black12, blurRadius: 20, offset: Offset(0, -5))]),
child: SafeArea(
child: Row(
children: [
Expanded(
child: ElevatedButton.icon(
onPressed: _isListening ? () => setState(() => _isListening = false) : _startMeeting,
icon: Icon(_isListening ? Icons.stop : Icons.play_arrow),
label: Text(_isListening ? '停止会议录制' : '开始智能识别'),
style: ElevatedButton.styleFrom(backgroundColor: _isListening ? Colors.redAccent : Colors.blueAccent, foregroundColor: Colors.white, padding: const EdgeInsets.symmetric(vertical: 18), shape: RoundedRectangleBorder(borderRadius: BorderRadius.circular(16))),
),
),
],
),
),
);
}
}
class Message {
final String text;
final bool isUser;
final DateTime time;
Message({required this.text, required this.isUser, required this.time});
}
七、总结
本文全方位展示了 deepgram_speech_to_text 库在 OpenHarmony 环境下的集成实战。通过 WebSockets 技术的流式应用,我们成功将顶级 ASR 服务引入鸿蒙全场景,解决了实时语音转换的延迟痛点。后续进阶方向可以考虑结合鸿蒙底层的声源定位与降噪算法,进一步打磨在嘈杂车载或办公场景下的识别精准度,为构建国际化、高交互性的鸿蒙应用提供技术保障。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)