Dataiku入门教程2-Generative AI Quick Start 生成式AI快速入门
本教程指导用户通过Dataiku平台快速掌握生成式AI应用开发技能。主要内容包括:1)使用Prompt Studio优化LLM提示词并集成到数据处理流程;2)将LLM与传统数据工具结合构建求职职位分析流水线;3)应用RAG技术,通过嵌入BLS文档创建增强型AI模型;4)开发职业前景评分系统,实现从数据准备到AI赋能的完整流程。教程涵盖数据清洗、模型测试、结果验证等关键环节,帮助用户快速构建AI驱动
 完成本快速入门教程后,你将掌握以下技能(吗?):
完成本快速入门教程后,你将掌握以下技能(吗?):
1.测试并优化输入至大语言模型的自然语言提示词,再将效果最佳的提示词应用于数据处理管道。
2.展示大语言模型与传统数据准备、机器学习工具协同配合的强大能力。
3.运用检索增强生成(RAG)技术,借助自有文档对基础大语言模型进行功能增强。
4.迈出构建生成式人工智能驱动聊天机器人的第一步。
Get started
第一步:打开dataiku
1.首先需要进入 Dataiku Design 节点(设计节点)的首页。
https://launchpad-dku.app.dataiku.io/spaces/bf88232f/overview2.前往 Launchpad:首先进入 Dataiku 的启动台(Launchpad)。
3.打开实例:在 Overview(概览)面板中,等到你的实例启动完成后,点击 Design 节点方块里的 Open Instance(打开实例)。
第二步:创建项目
进入Design节点首页后,你就可以开始创建教程项目了。
新建项目:在首页点击 + New Project(新建项目)。
选择学习项目:在弹出的选项中选择 Learning projects。
搜索教程:搜索并选择Generative AI Quick Start(生成式 AI 快速入门)。
确认创建:如果有需要,可以修改项目的保存文件夹,然后点击 Create。
进入流程图:在项目主页,点击Go to Flow(前往流程图)或者直接在键盘上敲g+f。
Understand the project
1.学习目标
通过本教程,你将掌握以下技能:
Prompt 工程:在将提示词投入生产环境前,先进行测试和优化。
工具协同:观察 LLM 如何与传统数据清洗及机器学习模型配合工作。
RAG 技术:使用检索增强生成(RAG) 技术,用你自己的文档来增强大模型的能力。
搭建助手:迈出构建生成式 AI 聊天机器人的第一步。
2. 读懂 Flow 的“视觉语言”
在 Dataiku 中,不同形状和颜色代表了不同的处理能力。你可以通过下表快速识别:
|
形状 |
代表意义 |
颜色与图标含义 |
|
方形 (Square) |
数据容器 |
蓝色:数据集;粉色:知识库(Knowledge Bank)。图标代表存储位置(如 S3、Snowflake)或文档内容。 |
|
圆形 (Circle) |
处理步骤 (Recipe) |
黄色:可视化插件;橙色:代码;绿色:机器学习;粉色:生成式 AI。 |
|
菱形 (Diamond) |
模型与代理 |
绿色:传统 ML 模型;粉色:生成式 AI 模型或代理(Agent)。 |
3. 项目背景求职者的智能流水线
想象你是一名求职者,为了不再盲目刷职位板,你搭建了一个自动化的处理流程。这个 Flow 分为三个核心区域:
|
Data Preparation |
对原始职位数据进行初步清洗 |
|
Machine Learning |
使用分类模型预测职位的真伪(Label:0 为真,1为假) |
|
Generative AI |
我们即将开始的部分,用 AI 处理那些传统工具搞不定的“非结构化文本” |
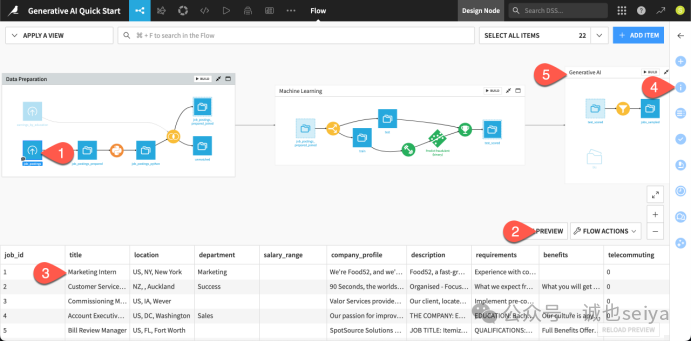
4.探索初始数据
我们从一小部分经过预处理的职位发布数据开始,这些数据就在 Generative AI 流程区中。
1.双击名为 Sample/Filter 的圆形图标(它输出 jobs_sampled 数据集)。
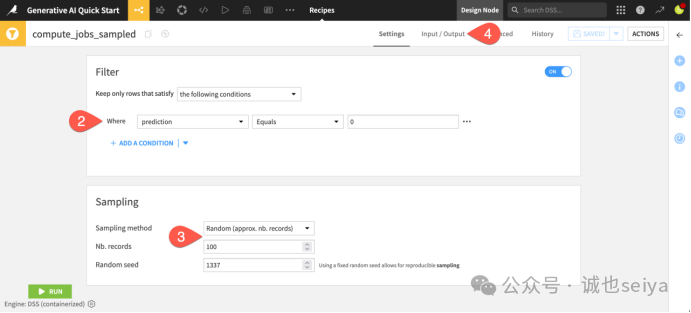
2.确认逻辑:你会发现这个 Recipe 过滤出了真实的职位(即 prediction 列的值为 0,代表模型预测它不是虚假职位)。
3.采样策略:它从输入数据中抽取了约 100 条记录。这能确保后续的 AI 处理速度更快,并降低调用 LLM 的 API 成本。
4.查看数据:切换到 Input/Output 选项卡,点击 jobs_sampled 即可看到这些我们将要处理的数据。
连接到 LLM Mesh
在 Dataiku 中,我们不直接调用某个具体的模型,而是通过 LLM Mesh 这个统一的网关来管理。
1.获取 LLM 提供商的 API 密钥
确认身份:如果你是在进行Dataiku 的试用,那么你就是自己的实例管理员。
选择提供商:选择一个Dataiku 支持的 LLM 连接。
建议:最好选择一个支持图像输入的模型连接,否则后续的检索增强生成(RAG)章节将无法完整体验。
获取密钥:按照LLM 提供商(如 OpenAI, Anthropic 等)的官方文档获取 API 密钥(API Key)。
2.在 Dataiku 中创建 LLM 连接
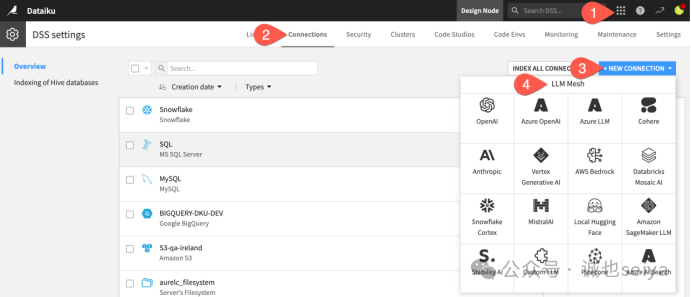
拿到密钥后,回到 Dataiku 的 Design Node(设计节点)进行配置:
(1)进入管理界面:点击顶部导航栏的九宫格 (Waffle) 菜单 (),选择 Administration(管理)。
(2)新建连接:切换到 Connections 标签页,点击 + New Connection。
(3)选择 LLM Mesh: 向下滚动到 LLM Mesh 区域,选择你的提供商。
(4)配置参数:
为连接起个名字。
填入你的 API 密钥。
点击 Test(测试)确保密钥有效。
(5)选择具体模型:确认有效后,勾选该连接可以访问的具体模型:
文本补全模型:至少选择一个(为了省钱,测试阶段选个便宜的就行)。
RAG 专用模型: 一个支持图像输入的文本模型,以及一个嵌入模型 (Embedding model)。
(6)安全设置:根据需要限制可以使用该连接的用户组,最后点击 Create。
3. 安装内部代码环境
为了完成 RAG(检索增强生成)部分,还需要管理员安装两个内部代码环境:
用于 Text Extraction(文本提取)的环境。
用于 Retrieval Augmented Generation(检索增强生成)的环境。
通过可视化界面查询 LLM
(Query LLMs from a visual interface)
1.使用 LLM 进行分类和摘要
1.返回流程图:回到“Generation AI 快速入门”项目的 Flow (快捷键 g + f)。
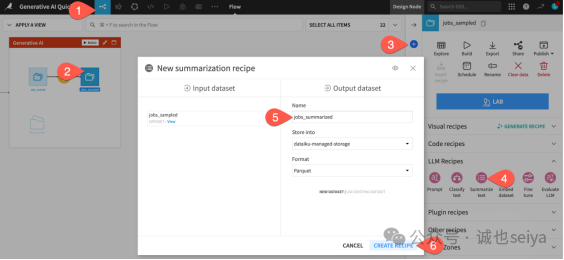
2.选择数据集:在“生成式 AI”流程区,单击选择 jobs_sampled 数据集。
3.打开操作面板:点击右侧面板的 Actions (操作) () 标签页。
4.选择recipes:在 GenAI recipes(生成式 AI recipes)菜单中,选择 Summarize text(文本摘要)。
5.命名输出:将输出数据集命名为 jobs_summarized。
6.创建recipes:点击 Create Recipe,接受系统默认的存储位置和格式。
2.运行生成式 AI recipes (Run a GenAI recipe)
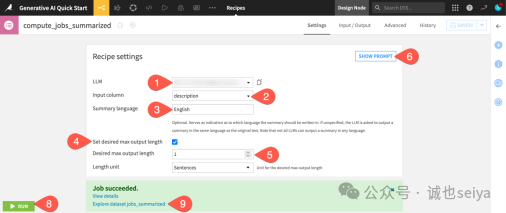
1.选择模型:在recipes的 Settings(设置)标签页中,找到 LLM 字段,从你的 LLM 连接中选择一个模型。
2.设置输入列:在输入列 (Input column) 中选择 description(这一列包含了冗长的职位描述文本)。
3.设置语言:将 Summary language(摘要语言)设置为 English。
4.限制长度:勾选 Set desired max output length(设置所需最大输出长度)复选框。
5.设定句数:将最大输出长度设置为 1 sentence(1 个句子)。
6.预览提示词:在运行之前,点击 Show Prompt(显示提示词)查看系统将发送给 LLM 的具体指令。
注意:阅读这段提示词,你会发现此时还不能修改它。看完后点击 Cancel。
7.执行任务:点击底部的 Run 按钮(或输入快捷键 @+r+u+n)。
8.查看结果:任务完成后,点击 Explore dataset jobs_summarized。在表格最右侧的 summary 列中,你就能看到 LLM 生成的回复了。现在,你拥有了非常精炼的职位描述!
5.设计自然语言提示词
1.创建提示词工作室 (Create a Prompt Studio)
这类需求需要用到 Prompt Studio,这是一个专门用于提示词工程的开发环境。
1.进入菜单:从顶部导航栏的 GenAI () 菜单中,选择 Prompt Studios。
2.新建工作室:点击 + New Prompt Studio。
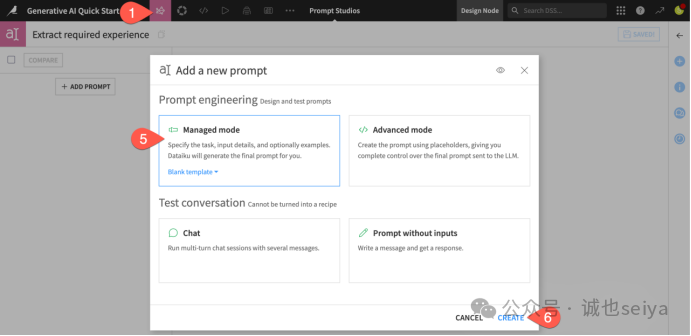
3.命名:将其命名为 Extract required experience(提取要求经验年限)。
4.初始化:点击 Create,选择 Managed mode (Blank template)(托管模式/空白模板),然后点击 Create 开始你的第一个提示词设计。
2.设计提示词 (Design a prompt)
jobs_summarized 数据集中包含 required_experience 列,但该列数据缺失严重,且类似“Mid-Senior Level”的分类值非常模糊。更有效的信息是实际要求的工作年限。由于这些数据缺乏结构,无法使用正则表达式提取,而 LLM 能够从 requirements(要求)列中提取出数值形式的年限。
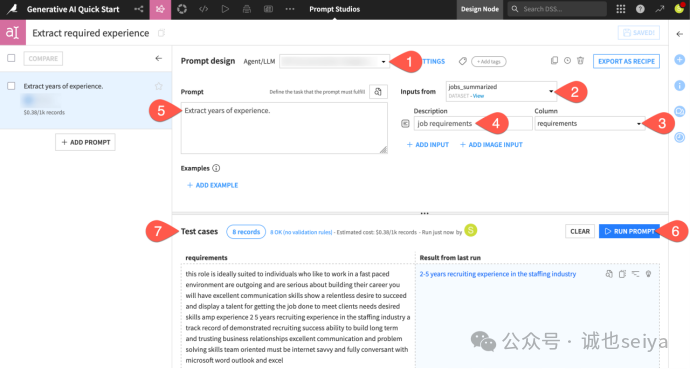
1.配置参数:
Agent/LLM:选择你的 LLM 连接中的模型。
Inputs from:选择 jobs_summarized 数据集。
输入列:选择 requirements。
描述字段:输入 job requirements 帮助 LLM 理解背景。
2.编写初步提示词:在 Prompt 字段中粘贴:Extract years of experience.(提取年限)。
3.运行测试:点击 Run Prompt,在测试案例上执行,并观察结果以及在 1,000 条记录上运行该提示词的成本预估。
3. 迭代提示词 (Iterate on a prompt)
快速迭代是成功的关键。你可以通过图标 () 查看历史记录,或者创建一个新提示词进行对比。
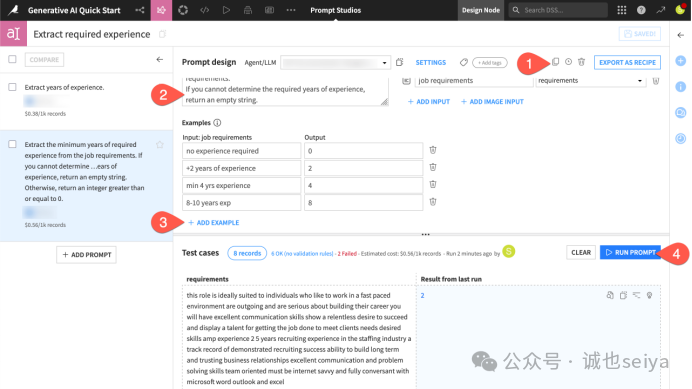
1.复制提示词:点击 Duplicate () 图标复制一个新提示词。
2.优化指令:在新提示词中,使用更详细的背景和期望:
"从职位要求中提取最低工作年限要求。如果无法确定,返回空字符串;否则,返回一个大于或等于 0 的整数。"
3.添加示例 (Few-shot):通过点击 + Add Example 引导模型,例如:
输入:no experience required -> 输出:0
输入:8-10 years exp -> 输出:8
4.再次测试:点击 Run Prompt 查看效果。在正式运行大数据集之前,先在工作室测试是控制成本的重要手段。
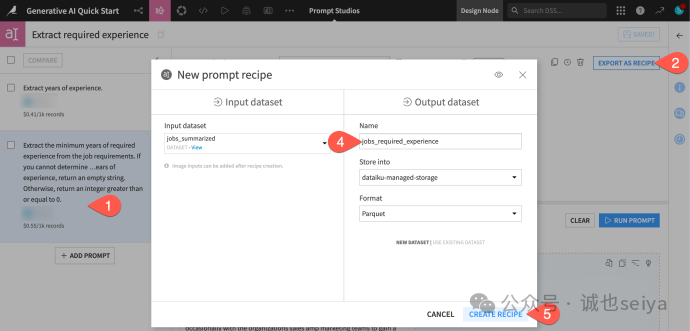
4.对比结果与导出 (Compare and Export)
1.横向对比:在左侧面板选中两个提示词,点击 Compare,观察详细指令和示例如何更好地约束了 LLM 的输出。
2.导出至流程图:选中效果最好的提示词,点击 Export as Recipe。
3.命名输出:将输出数据集命名为 jobs_required_experience 并创建recipes。
Coding 提示词
https://developer.dataiku.com/latest/concepts-and-examples/llm-mesh.html
5. 查看提示词recipes (View a Prompt recipe)
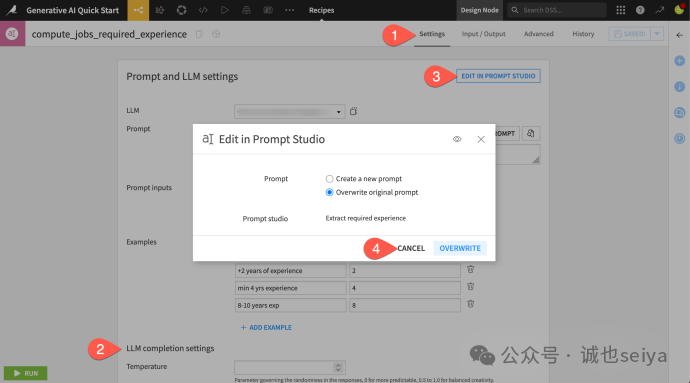
在 Prompt recipe(提示词recipes)中,你会发现它继承了工作室里的所有设置,但现在你可以对整个输入数据集执行这些指令了。
1.编辑关联:点击 Edit in Prompt Studio 可以随时回到实验室进行迭代,然后再同步回recipes。
2.安全防护:注意recipes中的 Guardrails(护栏) 设置,它可以检测毒性言论、个人隐私信息 (PII) 或禁用词,从而降低 AI 风险。
5.将生成式 AI 与传统数据工具结合
1.构建包含 GenAI 的data pipeline
虽然使用了LLM,但这些recipes已完全集成到 Flow 的流水线中,与可视化recipes和代码recipes无异。
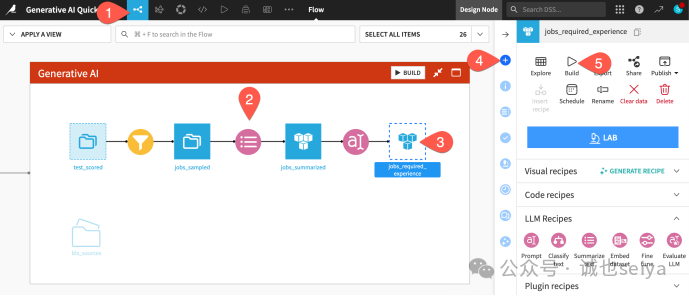
1.返回流程图:在提示词recipes页面,按 g + f 回到 Flow。
2.观察颜色:你会看到粉色的 Summarize () 和 Prompt () recipes,它们与黄色的可视化recipes、橙色的代码recipes以及绿色的机器学习recipes并列运行。
3.执行构建:
·点击选中尚未构建(空心)的 jobs_required_experience 数据集。
·在右侧 Actions () 面板中点击 Build。
·点击 Build Dataset。此时系统不仅会处理测试案例,还会对整个输入数据集运行提示词指令。
2. 检查 GenAI recipes的输出结果 (Inspect the output)
GenAI recipes的输出就是一个普通的 Dataiku 数据集,可以直接用于后续的清洗、建模或可视化。
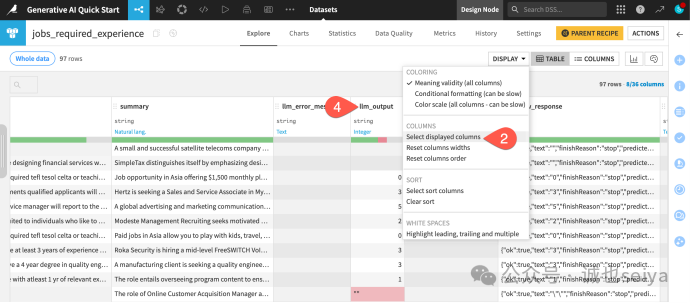
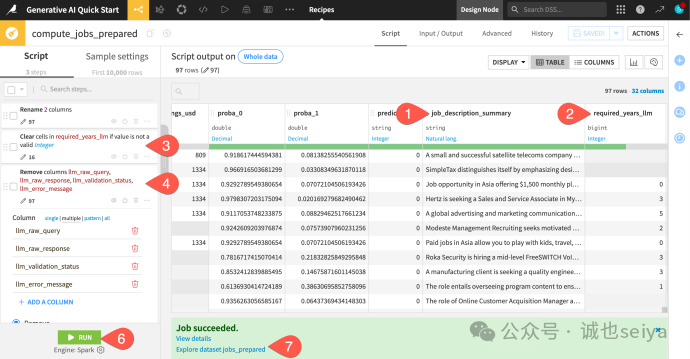
1.打开数据集:任务完成后,双击打开 jobs_required_experience。
2.筛选显示列:为了方便查看,点击 Display > Select displayed columns。
3.选择列名:仅勾选以下几列进行观察:
summary:由第一个 GenAI recipes生成的职位描述摘要。
requirements:原始的职位要求文本。
所有以 llm_ 开头的列:这是模型生成的原始输出和元数据。
4.核对质量:重点检查 llm_output 列,看看 LLM 从原始要求中提取的年限数字是否准确。
3. 进行后续数据准备 (Do more data preparation)
LLM 的输出通常需要进一步规范化(例如,模型可能偶尔返回了非数字字符)。
1.创建 Prepare recipes:在 jobs_required_experience 数据集页面,点击右侧 Actions (),选择 Prepare recipes,命名为 jobs_prepared 并创建。
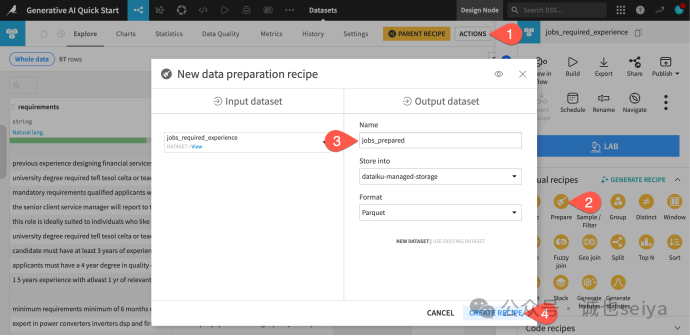
2.添加清洗步骤:
重命名:将 summary 重命名为 job_description_summary;将 llm_output 重命名为 required_years_llm。
值校验:在 required_years_llm 的列标题菜单中,选择 Clear invalid cells for meaning integer(清除不符合整数含义的无效单元格),确保这一列全是干净的数字。
删除冗余:删除 llm_error_message 以及其他所有以 llm_ 开头的无关辅助列。
3.运行recipes:点击底部的 Run(或快捷键 @ + r + u + n)。
4.查看终稿:打开 jobs_prepared,你会看到一个既包含 AI 提取信息、又经过专业清洗的完美数据集。
6.检索增强生成
(Retrieval Augmented Generation, 简称 RAG)
1.向量化(Embed)你的文档
要把非结构化的文件(如PDF、图片)变成 AI 能理解的形式,第一步是进行“向量化嵌入”(Embedding)。
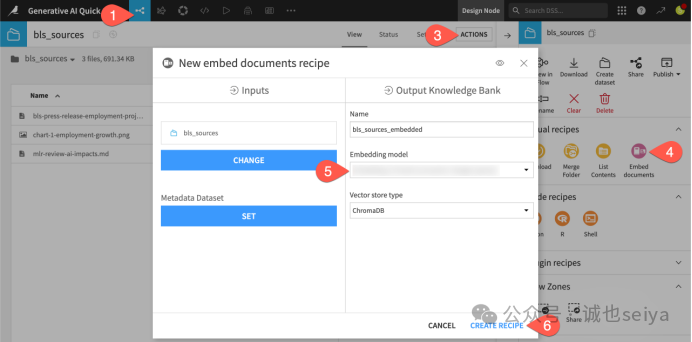
1.准备资料:在 bls_sources 文件夹中,已经为你准备了三份来自美国劳工统计局 (BLS) 的文件:一份关于就业预测的 PDF、一张行业增长预测 图片,以及一篇关于 AI 影响的 Markdown 文章。
2.创建嵌入算子:
·回到 Flow (g + f),双击进入 bls_sources 文件夹。
·点击右侧 Actions (),选择 Embed documents 算子。
·确认 Embedding model(嵌入模型)设置,然后点击 Create Recipe。
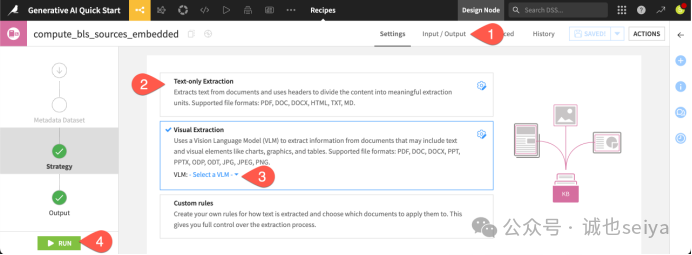
2. 配置提取方法 (Configure extraction methods)
针对不同格式的文件,需要使用不同的提取手段。
1.图片处理:如果输出步骤缺少一个用于存储生成图像的文件夹,请在 Input / Output 标签页为 Images Folder 指定名称为 bls_sources_embedded_images。
2.视觉模型 (VLM):对于 PDF 和图片,需要进行视觉提取。在 VLM 选项旁,选择一个支持图像输入的模型。
3.运行:点击 Run。完成后,你会得到一个粉色的知识库 (Knowledge Bank):bls_sources_embedded。
无法满足支持图像输入的嵌入模型的要求时,请参阅教程
https://knowledge.dataiku.com/latest/gen-ai/rag/tutorial-rag-embed-dataset.html?opals=true
3. 创建并测试增强型 LLM (Create and test an augmented LLM)
有了知识库后,我们就可以创建一个“读过书”的增强型 AI 了。
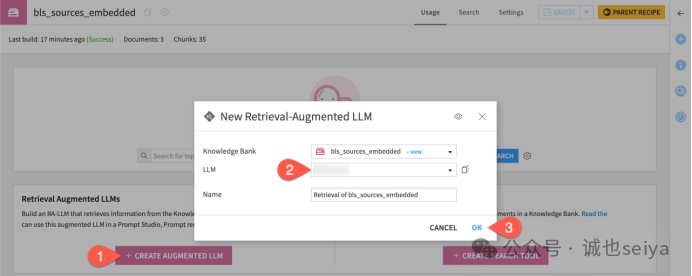
1·生成模型:点击知识库图标,选择 + Create Augmented LLM。
2·选择模型:选择支持图像输入的 LLM,点击 OK。g+f回到你的flow,此时 Flow 中会出现一个粉色钻石图标。
Tips:此时flow这一部分的依赖关系:①增强型大语言模型(augmented LLM)是基于 知识库(knowledge bank) 生成的项目。②知识库是「嵌入文档(Embed documents)」recipe的输出结果。③「嵌入文档」recipe以源文档文件夹作为输入。
3·配置测试:
双击打开这个 Retrieval of bls_sources_embedded 增强型 LLM,在 Design 标签页将检索文档数(number of documents to retrieve)设为 1。
将搜索模式切换为 Smart mode(智能模式)。
在对话框输入测试问题:
“How many jobs does the BLS project the US economy to add from 2023 to 2033?”
验证结果:AI 应该回答“6.7 million”,并准确标注出处是 PDF 新闻稿的第 1 页。
4.用增强型大语言模型的返回结果丰富数据集
既然你已确认增强型大语言模型能够调用嵌入的知识库,就可以沿用此前基础模型的操作流程:在提示词工作室(Prompt Studio)中设计提示词,再将效果最佳的提示词导出至提示词配方(Prompt recipe)。
1.在增强型大语言模型的Design标签页中,点击「Test in Prompt Studio」。
2.将其命名为「Enrich jobs with industry trends」。点击「Create」。
3.不要使用默认的无输入提示词,点击「+ 添加提示词(+ Add Prompt)」>「托管模式(空白模板)(Managed mode (Blank template))」>「创建」。
4.将下方文本复制粘贴到「提示词(Prompt)」输入框中:
|
Score each job posting on a scale of 1 to 5 based on low to high growth potential according to industry trends. 5 is a job of high growth potential and 1 is a job with low growth potential. Also provide a one sentence explanation for your score. In the response, separate the integer score and the text explanation with a comma. 根据行业趋势,为每条招聘信息的增长潜力从 1 到 5 打分(1 代表增长潜力最低,5 代表增长潜力最高)。同时为你的评分提供一句解释。在返回结果中,用逗号分隔整数评分和文字解释。 |
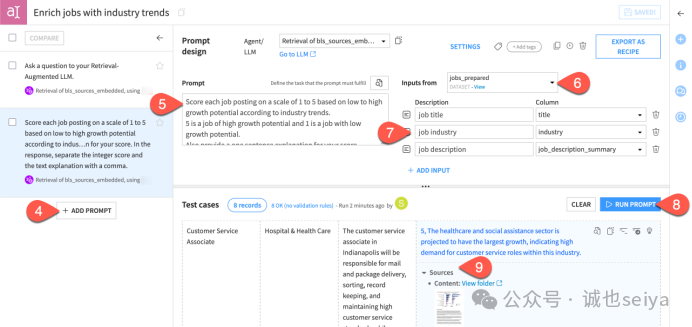
5.在「输入来源(Inputs from)」旁,选择 jobs_prepared 作为输入数据集。将以下三列作为输入发送给大语言模型:
|
描述 |
列名 |
|
职位名称 |
title |
|
所在行业 |
industry |
|
职位描述 |
job_description_summary |
6.点击「运行提示词(Run Prompt)」进行测试。
查看测试用例结果,不仅要关注大语言模型的返回内容,还要留意大语言模型所参考的信息来源。
在这个场景下,你可以跳过后续的提示词优化,直接将其导出到数据流(Flow)中。
7.在「用行业趋势丰富招聘信息(Enrich jobs with industry trends)」的提示词工作室中,确保已选中最新的提示词。
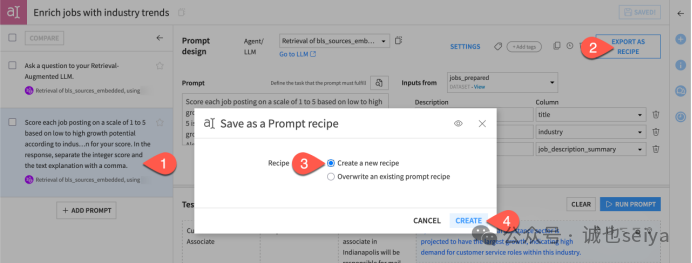
8.点击「Export as Recipe」。
9.在弹出的对话框中,选择「Create a new recipe)」。点击「Create」。
10.将输出数据集命名为 jobs_growth_potential。
11.点击「Create Recipe」。点击「运行(Run)」,在输入数据集上执行该提示词配方。
12.结果分析与收尾
打开最终的 jobs_growth_potential 数据集,你会发现 llm_output 列里现在充满了 AI 结合 BLS 权威数据给出的“职业前景预测”。
建议:这里的输出结果是“分数+解释”混在一起的字符串。你可以再接一个 Prepare Recipe,使用 Split column(拆分列)把分数和解释分开,这样就能在 Dataiku 里轻松画出职业前景分布图了!
操作:对llm_output 列使用「拆分列(Split column)」,创建独立的 growth_score(增长评分)和 growth_explanation(增长解释)列。同样,你也可以对 llm_raw_response 列使用「展开对象(Unnest object)」,深入查看原始来源数据。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)