Dataiku入门教程1-Data Preparation快速入门
平常学东西习惯留档,存货发一发,主要依据dataiku academy官方教程总结,供参考学习使用。Dataiku介绍:Dataiku DSS(Data Science Studio)是一款协作式的数据科学平台,主要面向的用户是数据分析师、数据科学家、数据工程师和业务分析师,解决的主要问题是让上面这些角色更快速、有效的探索数据、构建、交付数据产品。说到底,就是通过工具来提高数据相关从业者的生产力,
 平常学东西习惯留档,存货发一发,主要依据dataiku academy官方教程总结,供参考学习使用。
平常学东西习惯留档,存货发一发,主要依据dataiku academy官方教程总结,供参考学习使用。
Dataiku介绍:
Dataiku DSS(Data Science Studio)是一款协作式的数据科学平台,主要面向的用户是数据分析师、数据科学家、数据工程师和业务分析师,解决的主要问题是让上面这些角色更快速、有效的探索数据、构建、交付数据产品。说到底,就是通过工具来提高数据相关从业者的生产力,让人和工具配合起来更快地挖掘数据价值。其实类似的平台和工具很多,不管是Excel、Spss、jupyter、谷歌、微软azure和阿里云里中的部分工具都是为了解决类似的问题,只不过不同阶段数据量、人员素质等外界环境和需求的不同,各阶段面向不同用户各类产品的特性有所区别。
一句话总结:利用云平台更好链接具有coding与非coding经验的人,通过步骤可视化数据处理流程。
一、Data Preparation Quick Start数据准备快速入门
本教程面向初次使用 Dataiku 的用户,将指导您开始使用 Dataiku 进行数据准备。在本项目中,你将准备一个带有标签的招聘信息数据集,为后续通过机器学习任务区分虚假招聘和真实招聘做准备。
建议用时:30min
Get started
第一步是进入你的 Dataiku Design 节点首页Dataiku Cloud - Launchpad。
https://launchpad-dku.app.dataiku.io/在Overview面板中,实例启动后,单击Design节点tile中的Open Instance。
进入Design节点主页后,就可以创建教程项目了。
Create the project
在Dataiku Design主页上,点击+ New Project。
选择学习项目。
搜索并选择“Data Preparation Quick Start.”。
如果需要,更改要安装项目的文件夹,然后单击Create。
从项目主页,单击Go to Flow(或键入g + f)。
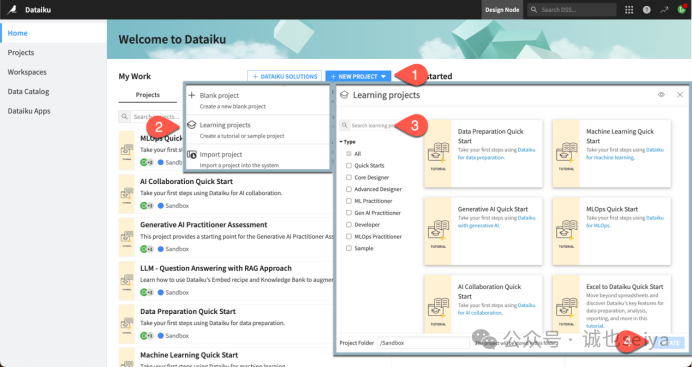
Understand the project
您创建的项目包括真实和虚假招聘信息的标记数据集。
在实际准备数据之前,先简单地探索一下。
第一步:打开数据集
双击job_posts数据集打开它。
此时你应该进入了数据集的 Explore(探索) 标签页,能看到类似 Excel 的表格。
第二步:计算总行数 (Compute Row Count)
注意,你现在看到的可能只是前 10,000 行(采样),不代表全部。
在表格上方,找到一个像 计数器 的小图标,点击 Compute row count,以确定整个数据集的行数。
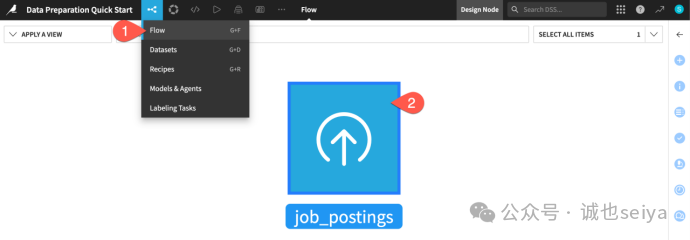
第三步:检查采样设置 (Sampling)
单击Sample按钮打开Sample设置面板。
点击 Sampling method 下拉菜单,看看目前的设置(默认通常是 First records)。
这一步不需要修改,只是让你熟悉一下在这里可以调整预览数据的范围。
看完后再次点击 Sample 按钮收起面板。
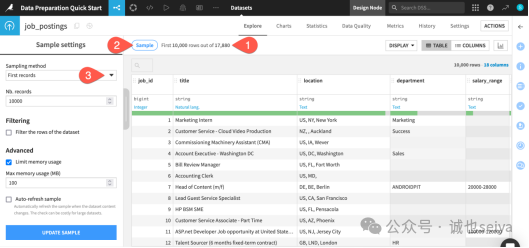
第四步:分析列分布
这是理解数据质量(是否有缺失值、异常值)最快的方法。
单击第一列job_id的标题,在弹出的菜单中选择 Analyze。
切换:在弹出的 Analyze 窗口中,你可以点击 左右箭头 () 来依次查看每一列的统计图表。
重点观察 fraudulent 列:
这是你的目标变量(Target Variable),即我们要预测的“是否为虚假职位”。
你应该能看到 0(真实职位)约占 95%,1(虚假职位)约占 5%。
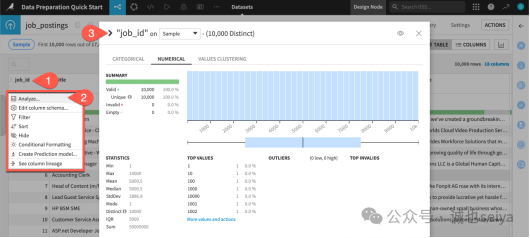
如果你想确认刚才看到的 5% 比例是否在整个数据集中都一致:
操作: 在 Analyze 窗口的右上角,将下拉菜单从 Sample 切换到 Whole data。
执行: 点击 Save and Compute。系统会跑一遍全量计算,给你最精确的统计分布。
Prepare data
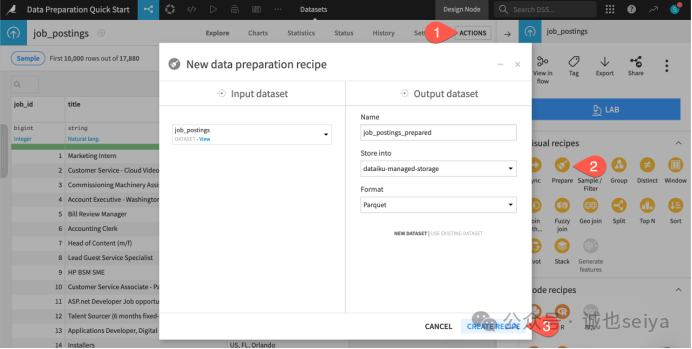
第一步:创建 Prepare Recipe
在 job_postings 数据集页面,点击右侧面板的 Actions标签页。
在 Visual recipes 菜单下,选择 Prepare。
点击 Create Recipe。不用改名字,直接用默认的 job_postings_prepared 即可。
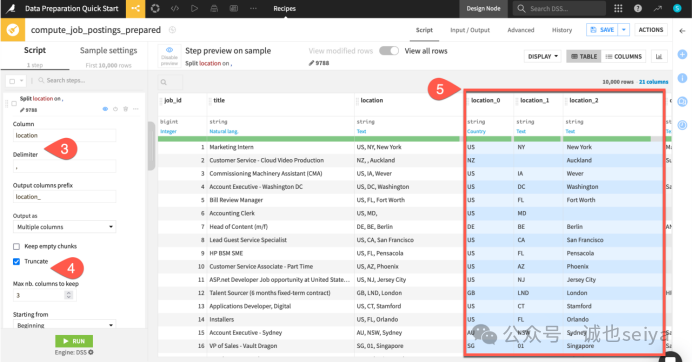
第二步:拆分地理位置 (Split Column)
我们要把 location 这一列(通常是“国家, 州, 城市”格式)拆开。
点击左侧脚本区的 + Add a New Step。
在搜索框输入并选择 Split column。
配置参数:
Column: 输入 location。
Delimiter: 输入英文逗号 ,。
勾选 Truncate,并将 Max columns to keep 设置为 3。
你会发现右侧预览中多了三列蓝色的新列(location_0 等)。
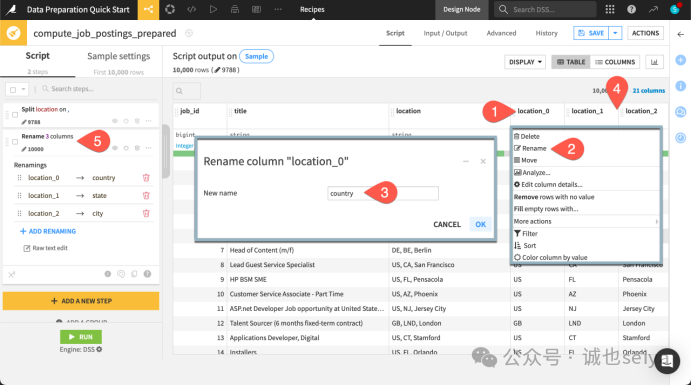
第三步:直接在表头重命名 (Rename)
在表格预览中,点击 location_0 的列名标题。
选择 Rename,输入 country 并回车。
对 location_1 和 location_2 重复此操作,分别命名为 state 和 city。
注意:你会发现这三次重命名在左侧脚本里被合并成了一个步骤。
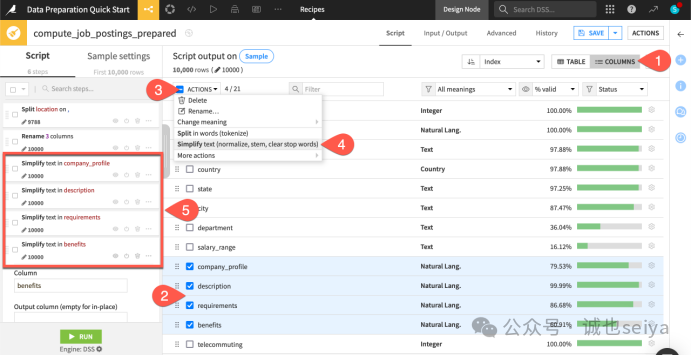
第四步:批量简化文本 (Columns View)
当需要对多列执行相同操作时,切换视图更有效率。
在表格上方,将视图从 Table 切换到 Columns。
勾选以下四列:company_profile, description, requirements, benefits。
点击上方的 Actions 下拉菜单,选择 Simplify text。
这个操作会自动去除多余空格、转换大小写等,让文本更规整。
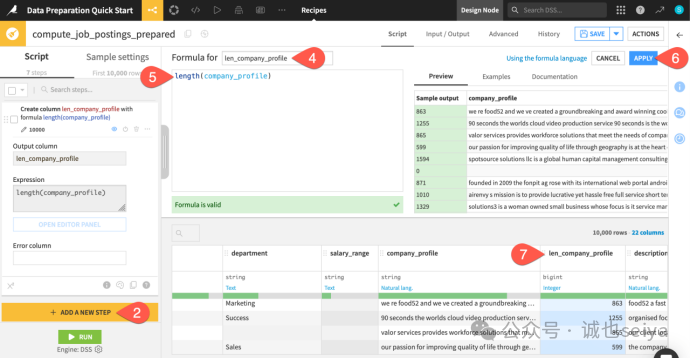
第五步:使用公式计算长度 (Formula)
Dataiku 有一套类似 Excel 但更强大的公式系统。
切回 Table 视图。
点击 + Add a New Step,搜索并选择 Formula。
配置参数:
Output column: 输入 len_company_profile。
Expression: 输入 length(company_profile)。点击 Apply。
复制步骤:
点击该步骤右侧的 三个点 (),选择 Duplicate step。
将新步骤的输出列名改为 len_description。
将公式改为 length(description)。
第六步:运行并检查结果
点击左下角的红色 Run 按钮(或使用快捷键 @ + r + u + n)。
等待任务完成后,点击 Explore dataset job_postings_prepared。
检查新生成的 country, len_description 等列是否符合预期。
最后,点击快捷键 g + f 回到 Flow 页面。
你会发现 Flow 页面现在多了一个橘色的圆形图标(Prepare Recipe)和一个新的蓝色方形图标(结果数据集)。
这代表了数据从“原始”到“清洗后”的流向。
Import data
下载并上传文件
准备文件:首先确保你已经下载了教程提供的 earnings_by_education.csv。
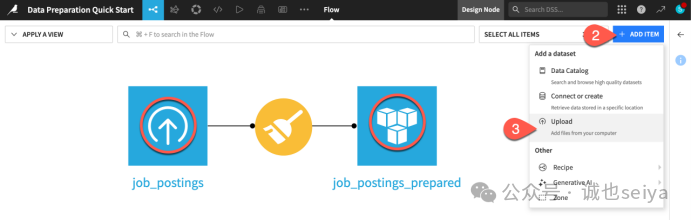
开始导入:回到 Flow 界面,点击左上角蓝色的 + ADD ITEM 按钮。
选择上传:在弹出的菜单中选择 Upload。
选择文件:点击 Select Files,从你的电脑中选中刚才下载的那个 CSV 文件。
配置格式与推断 Schema (关键步骤)
在点击创建之前,我们需要检查 Dataiku 是否正确读懂了表头和数据类型。
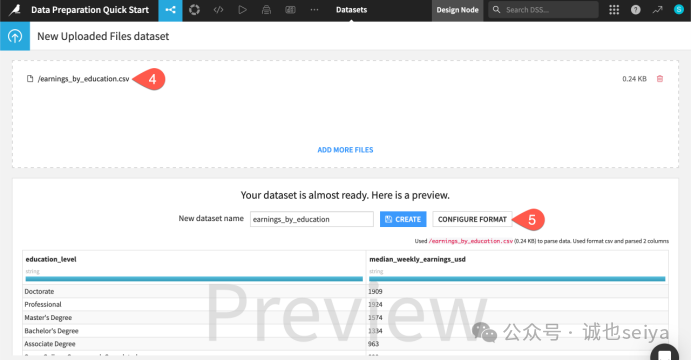
进入配置: 在上传界面,点击 Configure Format 按钮。
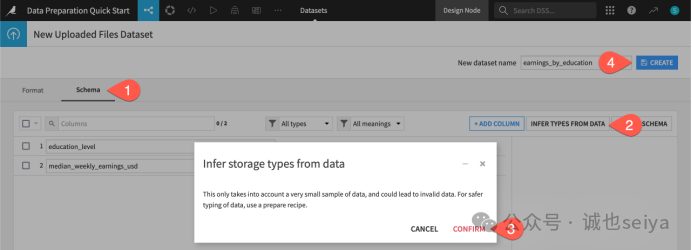
切换到 Schema: 在新页面的顶部标签栏中,点击 Schema 选项卡。
自动推断: 点击 Infer Types from Data。
观察变化: 重点看 median_weekly_earnings_usd 这一列。点击 Confirm 后,你会发现它的类型从 string(字符串/文本)变成了 int(整数)。这说明 Dataiku 成功识别了这一列是数字,以后可以用来做加减乘除计算。
完成创建
点击页面右上角的绿色 Create 按钮。
检查数据: 现在你就在新数据集的预览界面了。确认数据没问题后,按下快捷键 g + f 回到 Flow。
图标含义: 留意 Flow 里的蓝色方块图标。你会发现 job_postings 的图标可能和新上传的 earnings_by_education 不太一样,这代表了它们背后存储的物理方式(比如一个是上传的文件,一个是系统存储)。
Schema(模式):指的就是“这一列叫什么名字”以及“它是数字还是文本”。
JOIN data
我们的目标是:根据“学历(education level)”这个共同点,把每个职位对应的“平均周薪(median weekly earnings)”关联进去。
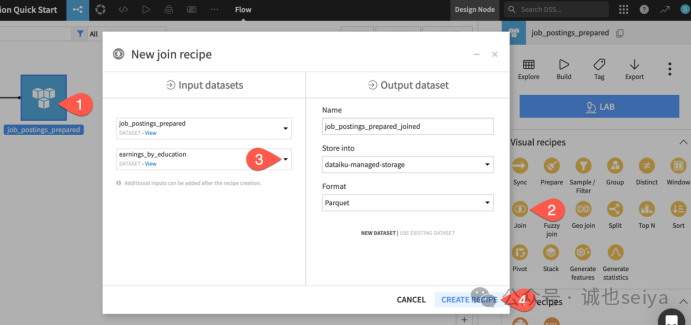
第一步:创建 Join Recipe
1.在 Flow 界面,点击选中 job_postings_prepared(它将作为“左表”)。
2.点击右侧面板的 Actions (),选择 Join。
3.在弹出的对话框左侧,点击 No dataset selected,然后选择你刚刚上传的 earnings_by_education(它将作为“右表”)。
4.点击 Create Recipe。
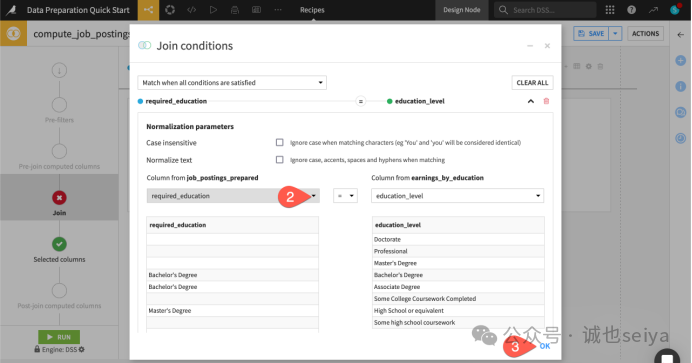
第二步:配置关联条件 (Join Step)
1.选择关联类型: 默认应该是 Left join。保持不变。
Left join 意味着我们会保留所有职位数据。即使某个职位的学历在薪资表里找不到,职位数据也不会消失。
2.添加关联键 (Join Key): 点击中间的 Add a Condition。
3.设置匹配列:
左侧(job_postings_prepared)选择 required_education。
右侧(earnings_by_education)选择 education_level。
点击 OK。
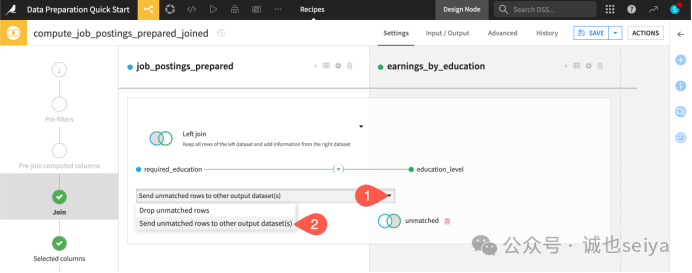
第三步:处理未匹配的行 (Unmatched Rows)
这是一个非常实用的调试技巧,可以帮你发现数据里的“脏数据”或拼写不一致。
1.在 Join 条件下方,点击下拉菜单,选择 Send unmatched rows to other output dataset(s)。
2.点击 + Add Dataset,起名为 unmatched。
3.点击 Use Dataset。
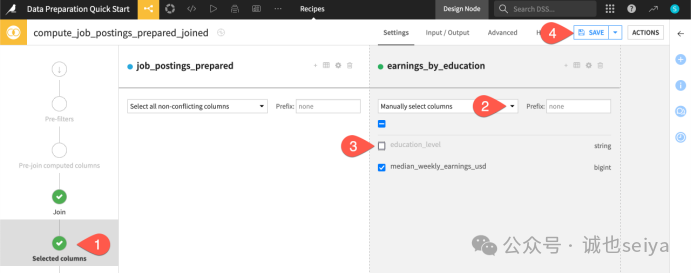
第四步:选择输出列 (Selected Columns)
1.为了让结果表更简洁,我们不需要重复的列。
2.在左侧导航栏,切换到 Selected columns 步骤。
3.在 earnings_by_education 下方,将下拉菜单改为 Manually select columns。
4.取消勾选 education_level(因为左表的 required_education 已经有相同信息了)。
5.点击顶部的蓝色 SAVE 按钮。
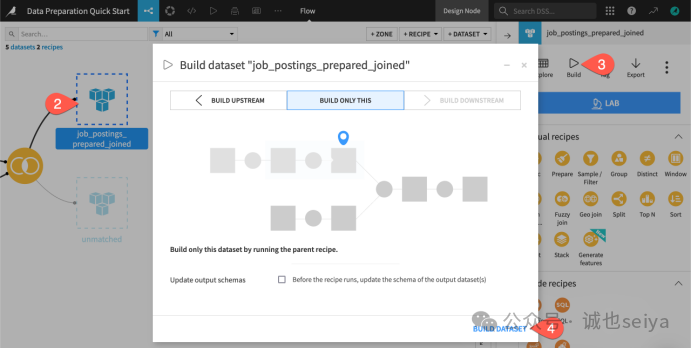
第五步:在 Flow 中直接构建 (Build)
不需要点 Recipe 里的 Run,也可以直接在流程图中操作。
1.按 g + f 回到 Flow。
2.点击那个空心的(还没跑出来的)job_postings_prepared_joined 数据集图标。
3.在右侧 Actions () 面板中,点击 Build。
4.保持默认的 Build Only This,点击 Build Dataset。
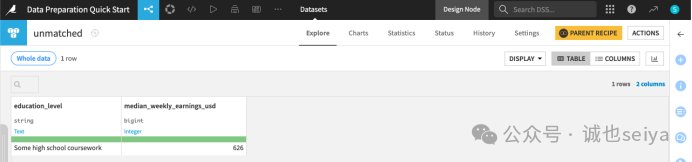
第六步:检查“没对上”的数据
任务完成后,你会发现 Flow 里多了一个名为 unmatched 的数据集。
1.双击打开 unmatched。
2.你会看到有一行“Some high school coursework”。
原因: 这是因为薪资表里的这个写法,在职位表里找不到完全一致的字符串。
看完后按 g + f 返回 Flow。
小贴士:你在点击齿轮图标时看到的 Recipe Engine,代表了 Dataiku 是如何处理数据的。
Schema(模式):指的就是“这一列叫什么名字”以及“它是数字还是文本”。
Write code
我们要做的任务是:把 salary_range(比如 "50000-70000" 这种字符串)转化成一个可以计算的数字列 min_salary。
第一步:创建 Code Notebook (实验区)
1.在 Flow 中,点击选中 job_postings_prepared 数据集。
2.点击右侧面板的 Lab () 标签页。
3.在 Code Notebooks 下方,点击 New。
4.选择 Python,并点击 Create。
5.当内核(Kernel)准备好后,运行前几个初始单元格(点击单元格左侧的播放按钮)。
第二步:编写 Python 代码
教程提供了一段代码,用来解析薪资范围并提取最小值。
粘贴代码: 将最后一个单元格的内容替换为以下代码:
Python# 定义提取最低薪资的函数def extract_min_salary(salary_range):if pd.isna(salary_range): # 保持缺失值为缺失return Nonetry:# 按照 '-' 分割字符串并取第一部分min_salary = int(salary_range.split('-')[0])return min_salaryexcept:return None # 处理无效值
运行: 运行该单元格,观察数据框 df 是否多出了 min_salary 这一列。
第三步:将 Notebook 转换为 Recipe (进入生产线)
实验室的成果需要搬到“生产线”(Flow)上才能被后续步骤使用。
1.点击页面上方的 + Create Recipe。
2.点击 OK(默认选择 Python recipe)。
3.配置输出: 在 Outputs 下点击 + Add,输入新数据集的名字:job_postings_python。
4.点击 Create Dataset,然后点击 Create Recipe。
5.关键修改: 进入代码编辑界面后,将最后一行代码修改为: job_postings_python.write_with_schema(df)
6.点击左下角的 Run。
第四步:调整流程图 (更新流水线)
现在你有了更高级的 job_postings_python 数据(带薪资数字),我们需要让后面的 Join Recipe 改用这个新表作为输入。
1.按下 g + f 回到 Flow。双击你之前建立的 Join recipe ()。
2.在 Join 步骤页,找到左表的 job_postings_prepared,点击它旁边的 Replace dataset () 图标。
3.选择你刚刚通过 Python 生成的 job_postings_python。
4.点击 Replace Dataset,然后点击 Run。
后面的write code步骤可做可不做,看个人情况。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)