AI Agent 认知策略—Self-Ask 原理、架构与代码实现
Self-Ask框架:让语言模型将复杂问题分解为更简单的子问题,先回答子问题再回答主问题方式,显著的缩小了组合性差距,并且可以在回答子问题时,轻松接入搜索引擎的搜索结果,进一步提高准确性。
Self-Ask 原理、架构与代码实现
1 介绍
在自然语言处理领域,大语言模型(LLMs)已展现出强大能力。但当面对复杂的推理问题,特别是在处理需要将多个子问题的答案进行组合以得出最终解答的任务时,模型存在显著缺陷。即模型能正确回答了各个子问题,却无法整合这些信息以生成正确的答案。
例如,模型能够准确回答 “贾斯汀・比伯是哪年出生的?” 以及 “大师赛冠军通常在哪些年份产生?”,但当被问及 “谁是贾斯汀・比伯出生那一年的大师赛冠军?”这样的2跳组合问题时,却可能给出错误答案。
这一局限暴露了大模型的核心问题:擅长记忆事实,但不擅长基于事实进行推理。传统提示方法(如直接提问)无法引导模型 “主动思考”,导致复杂任务的解决依赖于训练数据中是否存在现成答案,而非真正的推理能力。
2023 年 10 月,来自华盛顿大学、OpenAI 等机构的研究人员 Ofir Press、Muru Zhang 等在 arXiv 上发表了名为《Measuring and Narrowing the Compositionality Gap in Language Models》的论文,论文中引入了组合性差距这一术语,来描述在所有 “由多个子问题组成、且模型能把每个子问题都答对” 的组合问题里,模型把整个组合问题回答错误的比例。并且提出了一种创新的方法 —**Self-Ask(自我询问)框架:**让语言模型将复杂问题分解为更简单的子问题,先回答子问题再回答主问题方式,显著的缩小了组合性差距,并且可以在回答子问题时,轻松接入搜索引擎的搜索结果,进一步提高准确性。
该框架是在思维链基础上进行改进,核心机制为:引导大语言模型在回答初始复杂问题前,显式地自我提问是否可以把问题改写/拆解成一个简单的子问题,并进行回答,回答时可以调用搜索工具来获得答案,然后根据工具返回结果,继续进行自我提问,直到模型认为无需继续提出子问题后,再整合之前的子问题及其答案,生成最终的答复。这是一种递归式的问题拆解与解答过程,能让模型更系统地剖析复杂问题,更深入地探索问题的各个方面,从而提高答案的质量和准确性 。这就如同人类面对复杂问题时(如做复杂数学题目),会将大问题拆分成多个小问题,逐个思考解决后再汇总答案。
2 实验示例
Self-Ask建立在思维链(CoT)的基础上,但不同于输出连续的、未划分的思维链,而是让模型在回答问题之前显示地提出它想要问的下一个后续问题。
具体步骤是:通过在提示词中加入 1-shot 或 few-shot 提示演示如何回答问题,接着附加推理时的问题。在提示的末尾插入短语 “Are follow up questions needed here:”,然后模型输出响应。在大多数情况下,模型首先输出 “是”,表示需要后续问题,并输出后续问题(Follow up);接着模型回答它,并添加Intermediate answer:用于放置子问题的中间答案,继续重复提问和回答后续问题,直到模型认为自己有足够的信息;此时,输出 “所以最终答案是:”;这使得最终答案易于解析,即最后一行中 “:” 后面的内容。在极少数情况下,语言模型会认为不需要提出后续问题,可以立即回答问题,具体提出多少个后续问题是由模型来思考决策的。

图:直接提示与思维链和self-ask方法对比。白色背景的文本是提示,绿色背景的文本是语言模型的输出,带下划线的文本是推理时的问题。
上图示例中,展示了三种方法:直接提示、思维链、self-ask在回答问题超导现象被发现时,美国的总统是谁?的对比。
-
直接提示(模型直接输出答案):
问题:西奥多・海克尔和哈里・沃恩・沃特金斯谁活得更久? 答案:哈里・沃恩・沃特金斯。 问题:超导现象被发现时,美国的总统是谁? 答案:富兰克林・D・罗斯福 (错误) -
思维链(模型先输出推理过程再给答案):
问题:西奥多・海克尔和哈里・沃恩・沃特金斯谁活得更久? 答案:西奥多・海克尔去世时 65 岁。哈里・沃恩・沃特金斯去世时 69 岁。所以最终答案(人名)是:哈里・沃恩・沃特金斯。 问题:超导现象被发现时,美国的总统是谁? 答案:超导现象于 1911 年由海克・卡末林・昂内斯发现。伍德罗・威尔逊在 1913 年至 1921 年期间担任美国总统。所以最终答案(总统名)是:伍德罗・威尔逊。(正确) -
self-ask(模型显式拆解问题为子问题,逐一解答后整合答案,含 “Follow up:”“Intermediate answer:” 等结构化支架):
问题:西奥多・海克尔和哈里・沃恩・沃特金斯谁活得更久? 这里需要后续问题吗:是。 Follow up:西奥多・海克尔去世时多大年纪? Intermediate answer:西奥多・海克尔去世时 65 岁。 Follow up:哈里・沃恩・沃特金斯去世时多大年纪? Intermediate answer:哈里・沃恩・沃特金斯去世时 69 岁。 所以最终答案是:哈里・沃恩・沃特金斯 问题:超导现象被发现时,美国的总统是谁?(真正的用户问题) 这里需要后续问题吗:是。 Follow up:超导现象是什么时候被发现的? Intermediate answer:超导现象于 1911 年被发现。 Follow up:1911 年美国的总统是谁? Intermediate answer:威廉・霍华德・塔夫脱。 所以最终答案是:威廉・霍华德・塔夫脱。(正确)Self-ask 优于思维链的优势在于,它将完整问题的分解(通过提出子问题)与这些子问题的实际答案分离开来,这使得子问题的回答可以借助外部的工具,如搜索引擎。此外,Self-ask 提供的严格框架使模型更容易以简洁、可解析的方式陈述最终答案。在某些情况下,思维链不会输出简短形式的最终答案,而是倾向于使用完整句子。
用搜索引擎工具改进
另外,self-ask 在回答子问题时,可以利用外部搜索工具,即在Follow-up后的子问题,用搜索引擎来代替LLM来回答子问题。该子问题被输入搜索引擎;获取搜索引擎的查询结果,再反馈给语言模型,语言模型生成另一个子问题,依此类推,直到输出最终答案。如下图所示:
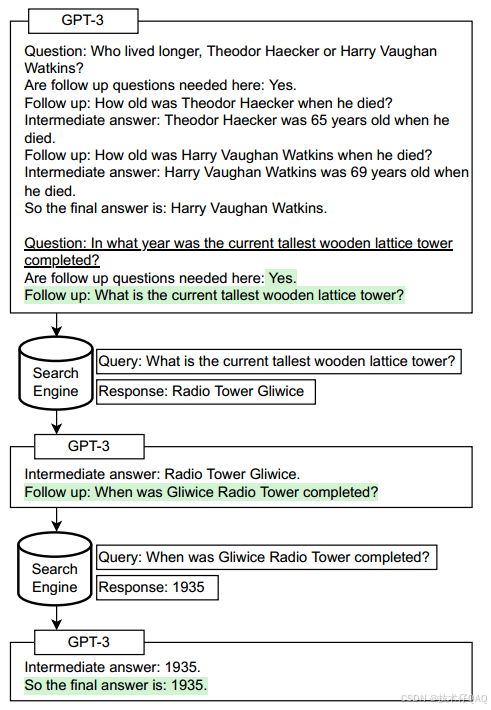
上图展示了 Self - Ask 结合搜索引擎解决问题的流程示例,逐步推理得出最终答案,具体步骤如下:
-
初始问题与子问题拆解
首先使用一个少样本提示词,并将初始问题附加到该提示词后,发送给模型(这里是使用的模型是GPT-3)。初始问题是 “In what year was the current tallest wooden lattice tower completed?”(目前最高的木制 lattice 塔是哪一年建成的? )。
模型判断需要后续问题(“Are follow up questions needed here: Yes” ),并提出第一个子问题 “What is the current tallest wooden lattice tower?”(目前最高的木制 lattice 塔是什么? )
-
结合搜索引擎获取子问题答案
将子问题 “What is the current tallest wooden lattice tower?” 作为查询(“Query” )发给搜索引擎,得到响应(“Response” )“Radio Tower Gliwice” ,即确定最高木制 lattice 塔是 Gliwice 无线电塔。
-
基于子问题答案继续推理
记录中间答案(“Intermediate answer: Radio Tower Gliwice” ),并提出新子问题 “When was Gliwice Radio Tower completed?”(Gliwice 无线电塔是哪一年建成的? )
-
再次结合搜索引擎与模型得出最终答案
把新子问题作为查询发给搜索引擎,得到响应 “1935” 。记录中间答案(“Intermediate answer: 1935” ),整合信息后输出最终答案 “So the final answer is: 1935” ,即确定目标塔的建成年份是 1935 年。
Self-Ask框架通过“拆解复杂问题生成子问题→借助外部工具(搜索引擎)获取子问题答案→模型整合信息推理” 的分步处理迭代循环,让模型更系统地解决多跳推理问题,也展示了大语言模型与外部工具协同工作的过程。
同类技术对比
| 维度 | 直接提示 | 思维链(CoT) | ReAct | self-ask |
|---|---|---|---|---|
| 核心逻辑 | 直接输出答案,无中间步骤。 | 引导模型输出连续推理步骤(如 “一步步思考”),但步骤无结构化格式。 | 结合推理和行动,可调用外部工具获取信息。 | 显式拆分成子问题,并记录中间结果。 |
| 适用场景 | 单跳事实问答(如 “XXX 的生日是哪天?”) | 简单推理任务(如数学题) | 适用于需要外部知识或实时信息支持的任务,如查询天气、获取最新新闻等 | 多跳推理、需要结合外部工具的任务 |
| 工具整合 | 无 | 弱(步骤无明确边界,难对接工具) | 强(可调用外部工具获取信息) | 强(子问题可直接作为工具查询输入) |
| 性能瓶颈- | 依赖模型自身知识、超出自身知识的问题易出现幻觉。 | 在处理需要外部知识的问题时,由于自身知识局限,准确性可能不足。 | 对外部工具的依赖性较强,若工具出现问题,会影响整体结果。 | 对于不需要中间问题的简单问题,可能会增加推理步骤,降低效率。 |
3 核心思想
self-ask 的核心思想是模拟人类分步推理的认知过程:面对复杂问题时,先将其拆解为一系列可解决的子问题,逐一解答子问题后,再整合结果得到最终答案。
具体来说,通过以下设计方法实现:
- 显式子问题分解:用 “Follow up: [子问题]” 的提示词格式,引导模型先生成需要解决的小问题。
- 结构化中间输出:再通过模型生成小问题的答案,用 “Intermediate answer: [子问题答案]” 记录每步结果,确保推理过程可追踪。
- 动态终止机制:让模型自己决定是否需要更多子问题,依次迭代,直到信息足够,再用 “Final answer: [结果]” 输出答案。
深层来看,self-ask 其实是降低了推理的 “难度”。复杂问题的难点在于 “一次性记住所有步骤并组合”,而拆分成子问题后,模型每次只需解决一个简单问题,最后再汇总,自然不容易出错。
4 工作流程
self-ask 实现工作流程如下图所示:
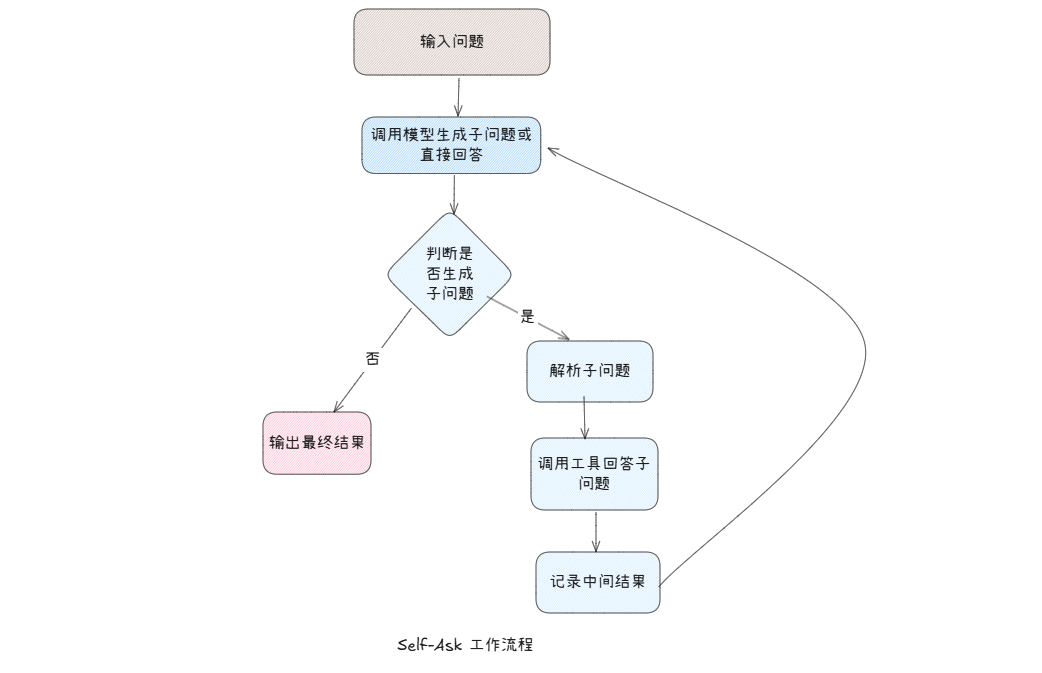
步骤说明如下:
- 输入问题:用户输入需要解决的复杂问题(多跳推理问题)。比如 “弗里达・卡罗出生地的电话区号是什么?”。
- 模型判断是否需要子问题:构建提示词( “Are follow up questions needed here:”)引导模型判断是否需分解问题,若模型认为当前信息已经足够回复用户问题,则直接生成答案,否则生成子问题。
- 解析子问题:解析模型生成的子问题:
Follow up:后面的信息(如 “Follow up: 子问题内容”),子问题需为可独立解答的简单问题。 - 回答子问题:模型自主回答子问题,或调用外部工具(如搜索引擎)获取答案,避免模型知识过时或不足。
- 记录中间结果:用 “Intermediate answer:” 存储子问题答案,作为后续推理的依据。
- 重复迭代:返回步骤 2,判断是否需要更多子问题,直至模型认为信息足够。
- 整合与输出:模型基于所有中间答案,推理得到最终结果,用 “Final answer:” 输出。
5. 应用场景
self-ask 的适用场景如下:
-
复杂事实性问答:这类场景的核心需求是准确回答涉及多步推理、需要多个事实信息支撑的问题。self-ask 框架通过拆解问题为中间问题,逐步获取事实信息,能够很好地满足这一需求,其逐步推理的方式与复杂事实性问答对信息准确性和完整性的要求相匹配。
-
知识图谱查询辅助:在知识图谱查询中,有时需要明确多个实体之间的关系,核心需求是理清实体关联路径。self-ask 可以通过提出中间问题,逐步明确实体间的关系。
-
多步骤问题解决:如解决数学应用题、逻辑推理题等,核心需求是清晰的步骤和准确的中间结果。self-ask 的中间问题拆解和逐步解答模式,能够满足这类场景对步骤和中间结果的要求。
6. 代码实现
6.1 前置准备
-
环境要求:
- Python 3.11+
- 安装依赖库:
pip install openai requests python-dotenv TavilyClient
-
基础配置:
-
设置API Key
创建
.env文件,配置模型 API访问密钥,这里使用千问模型,需配置QWEN_API_KEY及QWEN_BASE_URL。# 千问模型接口访问key # 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key QWEN_API_KEY="sk-*******" # 千问模型接口访问地址 QWEN_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1" -
搜索引擎 API 密钥(这里使用tavily)
.env文件中配置搜索引擎tavily API 密钥:# tavily 搜索API KEY # 访问 https://tavily.com 注册并获取API Key,用户每月有1000次免费调用额度. TAVILY_API_KEY="tvly-ZuSNSW4CehsNizV****"
-
6.2 编写代码
-
定义用于判断是否需要生成子问题的prompt(参考论文示例):
def _get_followup_prompt(self, query: str, history: str) -> str: """用于判断是否需要生成子问题的prompt""" return f""" 问题:{query} 已有的推理过程:{history} 接下来还需要问什么问题吗?请仅回答"Yes"或"No"。如果回答Yes,请同时给出具体的追问(格式:Follow up:[你的问题])。 """ -
定义基于综合中间答案得到最终结果的prompt
def _get_final_answer_prompt(self, query: str, history: str) -> str: """基于综合中间答案得到最终结果的prompt""" return f""" 请根据以下问题和推理过程,给出最终答案: 问题:{query} 推理过程:{history} 请直接给出答案,无需额外解释。 """ -
调用模型生成子问题或最终答案:
def _call_llm(self, prompt: str) -> str: """调用LLM生成回答""" try: response = self.client.chat.completions.create( model=self.llm_model, messages=[{"role": "user", "content": prompt}], temperature=0 # 降低随机性,保证输出稳定 ) return response.choices[0].message.content except Exception as e: print(f"LLM调用失败: {e}") return "" -
对接搜索引擎工具获取子问题的答案:
def _search(self, query: str) -> Optional[str]: """使用搜索答案""" if not tavily_api_Key: print("未配置tavily_api_Key,跳过搜索") return None client = TavilyClient(api_key=tavily_api_Key) try: # 调用Tavily API执行搜索 response = client.search(query, max_results=2) # 提取搜索结果项 items = response.get("results", []) # 提取所有摘要并合并为字符串(用换行分隔) combined_summary = "\n".join([item["content"] for item in items]) print(f"搜索结果:\n{combined_summary}") return combined_summary except Exception as e: print(f"搜索过程中发生错误: {e}") return None -
核心流程:
run该方法实现 self-ask 的完整逻辑:拆解问题→生成子问题→求解子问题→整合答案,步骤如下:
def run(self, query: str) -> str: """运行Self-Ask流程""" self.history = [] current_history = "" step = 0 while step < self.max_steps: step += 1 # 1. 判断是否需要继续提问 followup_prompt = self._get_followup_prompt(query, current_history) followup_response = self._call_llm(followup_prompt) # 2. 解析是否需要子问题 if "No" in followup_response: # 无需更多子问题,生成最终答案 final_prompt = self._get_final_answer_prompt(query, current_history) final_answer = self._call_llm(final_prompt) return final_answer elif "Yes" in followup_response and "Follow up:" in followup_response: # 提取子问题 followup_question = followup_response.split("Follow up:")[-1].strip() self.history.append({"followup": followup_question, "answer": ""}) print(f"子问题 {step}: {followup_question}") # 3. 搜索子问题答案(失败则用LLM回答) search_answer = self._search(followup_question) if search_answer: intermediate_answer = search_answer else: print(f"搜索无结果,使用LLM回答子问题:{followup_question}") intermediate_answer = self._call_llm(followup_question) # 4. 记录中间答案,更新历史 self.history[-1]["answer"] = intermediate_answer current_history += f"\nFollow up:{followup_question}\nIntermediate answer: {intermediate_answer}" print(f"中间答案 {step}: {intermediate_answer}") else: # LLM输出格式异常,直接用LLM回答原问题 print("LLM输出格式异常,直接回答原问题") return self._call_llm(query) # 超过最大步骤,强制生成最终答案 final_prompt = self._get_final_answer_prompt(query, current_history) return self._call_llm(final_prompt)
6.3 完整实现代码
完整代码位于项目根目录下:cognitive_pattern/self_ask/self_ask.py
import os
from typing import Optional, List, Dict
from dotenv import load_dotenv
from openai import OpenAI, Client
from tavily import TavilyClient
# 加载环境变量
load_dotenv()
# tavily 搜索API KEY
tavily_api_Key = os.getenv("TAVILY_API_KEY")
def initialize_model_client() -> Client:
"""
获取模型调用客户端,使用openai SDK,支持所有兼容openai接口的模型服务,默认使用千问模型
Returns:
OpenAI客户端实例
"""
# 获取千问API密钥
# 千问模型接口访问key
# 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
qwen_api_key = os.getenv("QWEN_API_KEY") # 从环境变量获取
if not qwen_api_key:
raise ValueError(f"缺少环境变量QWEN_API_KEY")
# 获取千问请求端口URL
qwen_base_url = os.getenv("QWEN_BASE_URL")
if not qwen_base_url:
raise ValueError(f"缺少环境变量QWEN_BASE_URL")
client = OpenAI(
api_key=qwen_api_key,
base_url=qwen_base_url,
)
return client
class SelfAskAgent:
def __init__(self, client: Client, llm_model: str = "qwen-plus-latest", max_steps: int = 5):
"""
初始化Self-Ask代理
:param client: 模型调用客户端
:param llm_model: 用于生成子问题和答案的LLM模型,默认使用千问模式:qwen-plus-latest
:param max_steps: 最大推理步骤(防止无限循环)
"""
self.client = client
self.llm_model = llm_model
self.max_steps = max_steps
self.history: List[Dict] = [] # 记录推理历史:子问题、中间答案
def _call_llm(self, prompt: str) -> str:
"""调用LLM生成回答"""
try:
response = self.client.chat.completions.create(
model=self.llm_model,
messages=[{"role": "user", "content": prompt}],
temperature=0 # 降低随机性,保证输出稳定
)
return response.choices[0].message.content
except Exception as e:
print(f"LLM调用失败: {e}")
return ""
def _search(self, query: str) -> Optional[str]:
"""使用搜索答案"""
if not tavily_api_Key:
print("未配置tavily_api_Key,跳过搜索")
return None
client = TavilyClient(api_key=tavily_api_Key)
try:
# 调用Tavily API执行搜索
response = client.search(query, max_results=2)
# 提取搜索结果项
items = response.get("results", [])
# 提取所有摘要并合并为字符串(用换行分隔)
combined_summary = "\n".join([item["content"] for item in items])
print(f"搜索结果:\n{combined_summary}")
return combined_summary
except Exception as e:
print(f"搜索过程中发生错误: {e}")
return None
def _get_followup_prompt(self, query: str, history: str) -> str:
"""生成用于判断是否需要子问题的prompt"""
return f"""
问题:{query}
已有的推理过程:{history}
接下来还需要问什么问题吗?请仅回答"Yes"或"No"。如果回答Yes,请同时给出具体的追问(格式:Follow up:[你的问题])。
"""
def _get_final_answer_prompt(self, query: str, history: str) -> str:
"""生成用于综合中间答案得到最终结果的prompt"""
return f"""
请根据以下问题和推理过程,给出最终答案:
问题:{query}
推理过程:{history}
请直接给出答案,无需额外解释。
"""
def run(self, query: str) -> str:
"""运行Self-Ask流程"""
self.history = []
current_history = ""
step = 0
while step < self.max_steps:
step += 1
# 1. 判断是否需要继续提问
followup_prompt = self._get_followup_prompt(query, current_history)
followup_response = self._call_llm(followup_prompt)
# 2. 解析是否需要子问题
if "No" in followup_response:
# 无需更多子问题,生成最终答案
final_prompt = self._get_final_answer_prompt(query, current_history)
final_answer = self._call_llm(final_prompt)
return final_answer
elif "Yes" in followup_response and "Follow up:" in followup_response:
# 提取子问题
followup_question = followup_response.split("Follow up:")[-1].strip()
self.history.append({"followup": followup_question, "answer": ""})
print(f"子问题 {step}: {followup_question}")
# 3. 搜索子问题答案(失败则用LLM回答)
search_answer = self._search(followup_question)
if search_answer:
intermediate_answer = search_answer
else:
print(f"搜索无结果,使用LLM回答子问题:{followup_question}")
intermediate_answer = self._call_llm(followup_question)
# 4. 记录中间答案,更新历史
self.history[-1]["answer"] = intermediate_answer
current_history += f"\nFollow up:{followup_question}\nIntermediate answer: {intermediate_answer}"
print(f"中间答案 {step}: {intermediate_answer}")
else:
# LLM输出格式异常,直接用LLM回答原问题
print("LLM输出格式异常,直接回答原问题")
return self._call_llm(query)
# 超过最大步骤,强制生成最终答案
final_prompt = self._get_final_answer_prompt(query, current_history)
return self._call_llm(final_prompt)
# 示例运行
if __name__ == "__main__":
# 初始话模型调用客户端
client = initialize_model_client()
# 初始化代理
agent = SelfAskAgent(client=client, max_steps=5)
# 测试2跳问题
question = "超导被发现时,谁是美国总统?"
print(f"问题:{question}")
answer = agent.run(question)
print(f"最终答案:{answer}")
# 测试4跳问题
question = "贾斯汀·比伯出生那年谁赢得了大师赛?,这个赢得了大师赛的人出生的那年谁是美国总统"
print(f"\n问题:{question}")
answer = agent.run(question)
print(f"最终答案:{answer}")
6.4 运行测试
测试
执行命令:python self_ask.py
输出结果
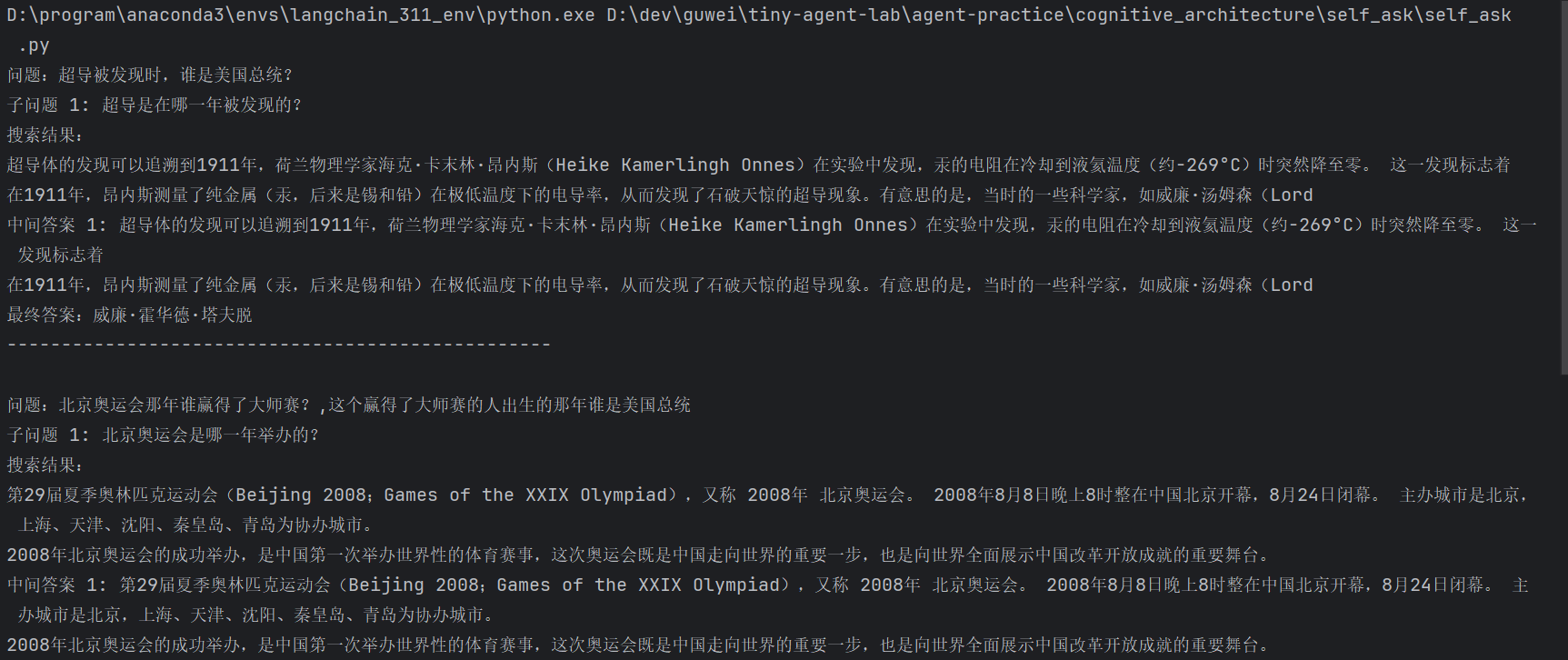
D:\program\anaconda3\envs\langchain_311_env\python.exe D:\dev\guwei\tiny-agent-lab\agent-practice\cognitive_architecture\self_ask\self_ask.py
问题:超导被发现时,谁是美国总统?
子问题 1: 超导是在哪一年被发现的?
搜索结果:
超导体的发现可以追溯到1911年,荷兰物理学家海克·卡末林·昂内斯(Heike Kamerlingh Onnes)在实验中发现,汞的电阻在冷却到液氦温度(约-269°C)时突然降至零。 这一发现标志着
在1911年,昂内斯测量了纯金属(汞,后来是锡和铅)在极低温度下的电导率,从而发现了石破天惊的超导现象。有意思的是,当时的一些科学家,如威廉·汤姆森(Lord
中间答案 1: 超导体的发现可以追溯到1911年,荷兰物理学家海克·卡末林·昂内斯(Heike Kamerlingh Onnes)在实验中发现,汞的电阻在冷却到液氦温度(约-269°C)时突然降至零。 这一发现标志着
在1911年,昂内斯测量了纯金属(汞,后来是锡和铅)在极低温度下的电导率,从而发现了石破天惊的超导现象。有意思的是,当时的一些科学家,如威廉·汤姆森(Lord
最终答案:威廉·霍华德·塔夫脱
--------------------------------------------------
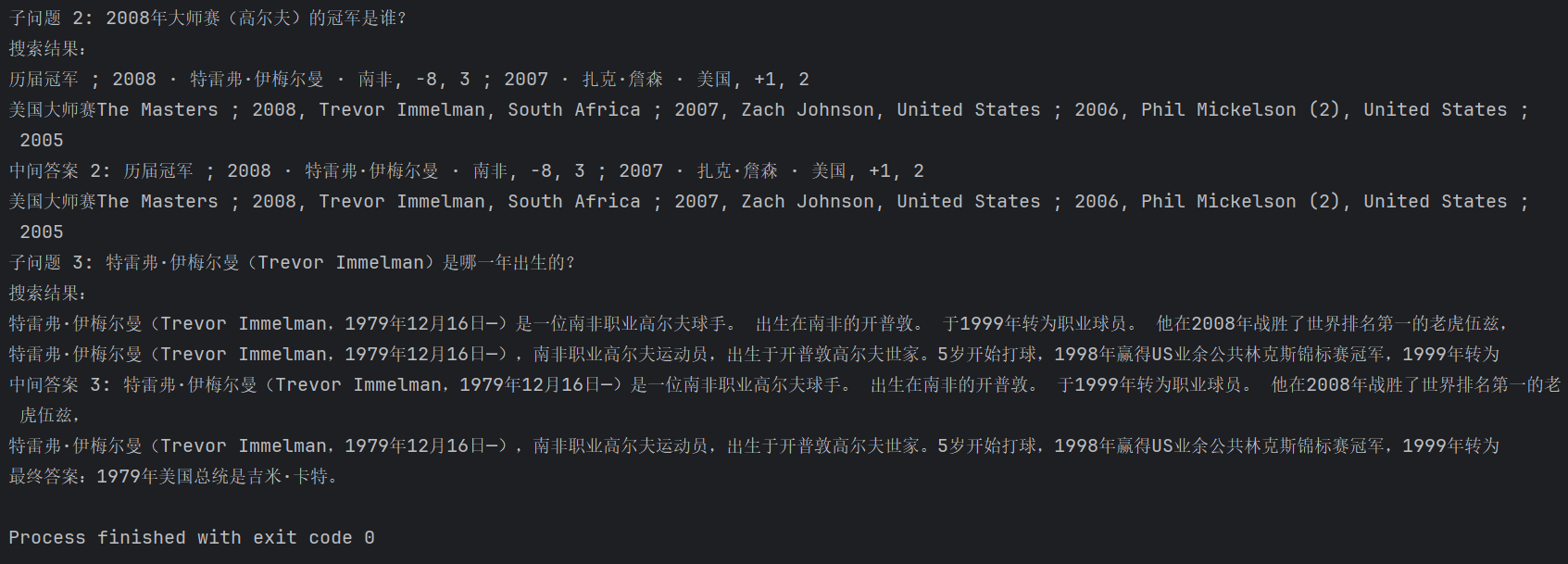
问题:北京奥运会那年谁赢得了大师赛?,这个赢得了大师赛的人出生的那年谁是美国总统
子问题 1: 北京奥运会是哪一年举办的?
搜索结果:
第29届夏季奥林匹克运动会(Beijing 2008;Games of the XXIX Olympiad),又称 2008年 北京奥运会。 2008年8月8日晚上8时整在中国北京开幕,8月24日闭幕。 主办城市是北京,上海、天津、沈阳、秦皇岛、青岛为协办城市。
2008年北京奥运会的成功举办,是中国第一次举办世界性的体育赛事,这次奥运会既是中国走向世界的重要一步,也是向世界全面展示中国改革开放成就的重要舞台。
中间答案 1: 第29届夏季奥林匹克运动会(Beijing 2008;Games of the XXIX Olympiad),又称 2008年 北京奥运会。 2008年8月8日晚上8时整在中国北京开幕,8月24日闭幕。 主办城市是北京,上海、天津、沈阳、秦皇岛、青岛为协办城市。
2008年北京奥运会的成功举办,是中国第一次举办世界性的体育赛事,这次奥运会既是中国走向世界的重要一步,也是向世界全面展示中国改革开放成就的重要舞台。
子问题 2: 2008年大师赛(高尔夫)的冠军是谁?
搜索结果:
历届冠军 ; 2008 · 特雷弗·伊梅尔曼 · 南非, −8, 3 ; 2007 · 扎克·詹森 · 美国, +1, 2
美国大师赛The Masters ; 2008, Trevor Immelman, South Africa ; 2007, Zach Johnson, United States ; 2006, Phil Mickelson (2), United States ; 2005
中间答案 2: 历届冠军 ; 2008 · 特雷弗·伊梅尔曼 · 南非, −8, 3 ; 2007 · 扎克·詹森 · 美国, +1, 2
美国大师赛The Masters ; 2008, Trevor Immelman, South Africa ; 2007, Zach Johnson, United States ; 2006, Phil Mickelson (2), United States ; 2005
子问题 3: 特雷弗·伊梅尔曼(Trevor Immelman)是哪一年出生的?
搜索结果:
特雷弗·伊梅尔曼(Trevor Immelman,1979年12月16日—)是一位南非职业高尔夫球手。 出生在南非的开普敦。 于1999年转为职业球员。 他在2008年战胜了世界排名第一的老虎伍兹,
特雷弗·伊梅尔曼(Trevor Immelman,1979年12月16日—),南非职业高尔夫运动员,出生于开普敦高尔夫世家。5岁开始打球,1998年赢得US业余公共林克斯锦标赛冠军,1999年转为
中间答案 3: 特雷弗·伊梅尔曼(Trevor Immelman,1979年12月16日—)是一位南非职业高尔夫球手。 出生在南非的开普敦。 于1999年转为职业球员。 他在2008年战胜了世界排名第一的老虎伍兹,
特雷弗·伊梅尔曼(Trevor Immelman,1979年12月16日—),南非职业高尔夫运动员,出生于开普敦高尔夫世家。5岁开始打球,1998年赢得US业余公共林克斯锦标赛冠军,1999年转为
最终答案:1979年美国总统是吉米·卡特。
7 总结
综上,self-ask 是一种为提升语言模型组合性推理能力设计的结构化提示框架,核心思想是通过显式拆解复杂问题为子问题、分步求解并整合答案,以缩小组合性差距(模型能正确回答子问题却无法生成整体答案的比例),是增强大模型复杂任务处理能力的重要思路。
其对子问题的解答上,可灵活集成外部工具进行处理,可以做如下优化:
- 多工具集成:除搜索引擎外,整合计算器、数据库查询、API 调用等,适配不同类型问题。
- 工具选择机制:让模型自主判断子问题需要哪种工具,而非固定优先搜索。
8 实验测试及结果(附录)
论文中的使用多跳问答来量化语言模型的推理能力,通过设计数据集、对比提示方法及结合外部工具,系统探究了组合性差距的特性及缩小策略,具体如下:
测试数据集
实验使用 4 类数据集,涵盖自动生成、手动构建及已有公开数据集,确保测试的全面性:
-
Compositional Celebrities (CC):自动生成的 8.6k 个 2 跳 问题,基于 17 类模板(如 “名人出生地的国家代码”“名人出生年份的诺贝尔奖得主”),特点是子事实(如名人出生地、年份相关事实)在训练数据中常见,但组合形式罕见(几乎未在训练数据或互联网中出现),可有效区分模型的 “记忆” 与 “推理” 能力;
-
2WikiMultiHopQA和Musique:已有的公开 2-hop 问题数据集,基于维基百科事实,用于跨数据集验证方法的通用性与稳定性。
-
Bamboogle:手动构建的 125 个 2-hop 问题,源自维基百科关键条目,问题高度多样化(无固定模板),且经筛选确保搜索引擎的 “精选摘要” 输出错误(证明问题未在网络中广泛存在),用于测试模型对非结构化、复杂问题的推理能力。
论文中获取Bamboogle数据的方式:通过查询文章主题的两个不相关事实来生成每篇文章的 2 跳问题。例如,在阅读 “旅行者 2 号” 的文章时,我们了解到它是第一个接近天王星的探测器,并且它是用泰坦 IIIE 火箭发射的,由此产生了问题:“第一个接近天王星的航天器是用什么火箭发射的?” 然后,我们将我们的问题输入互联网搜索引擎,只有当查询引出的 “精选摘要” 答案不正确时,才将其添加到最终数据集;我们使用搜索引擎来筛选我们的数据集,因为我们假设搜索引擎无法回答这些问题,表明这些问题不在网络上。
这种问题形式有很多优点:几乎所有问题都有唯一正确答案,易于分解为子问题(让我们能验证语言模型是否了解背景事实),而且大多数问题的答案范围很广(不同于是非题或选择题)。因此,随机猜对正确答案的概率很低。
关键测试结果
-
组合性差距的特性:
- GPT-3 系列中,模型规模从 0.35B 增至 175B 时,单跳问题准确率提升显著快于多跳问题,组合性差距稳定在 40% 左右(Instruct 与非 Instruct 模型一致),表明更大模型更擅长记忆事实而非组合推理;
- 模型对事实的信心(perplexity,即对正确子问题答案的困惑度)与组合能力正相关:当子问题答案的最大困惑度极低(1.000-1.002)时,组合问题准确率达 81.1%,显著高于高困惑度场景(42.6%)。
-
对比同类方法的效果:
以下表格呈现了论文中不同方法在各测试数据集上的准确率结果。
方法 Bamboogle 2WikiMultiHopQA Musique 直接提示 17.6 25.4 5.6 思维链 46.4 29.8 12.6 搜索引擎 0.0 2.2 1.5 搜索引擎 + 后处理 - 26.3 6.5 self-ask 57.6 30.0 13.8 self-ask+ 搜索 60.0 40.1 15.2 结合数据可得出以下关键结论:
-
诱导性提示显著优于直接提示:self-ask 使组合问题准确率大幅提升,甚至能缩小组合性差距(部分模型中接近闭合);
-
self-ask 优于思维链:在 Bamboogle(高多样性问题)上,self-ask 准确率(57.6%)比思维链(46.4%)高 11%,因结构化拆解更适应非模板化问题;在 2WikiMultiHopQA 和 Musique 上,self-ask 准确率(30.0%、13.8%)略高于思维链(29.8%、12.6%);
-
思维链存在格式一致性问题:在 Bamboogle 中,40% 的思维链输出为完整句子(非短形式答案),而 self-ask 因结构化支架,该比例仅 17%(结合搜索引擎后降至 3%)。
-
self-ask + 搜索引擎进一步提升性能:在 2WikiMultiHopQA 上准确率达 40.1%(高于 self-ask 的 30.0%),在 Musique(15.2% vs 13.8%)和 Bamboogle(60.0% vs 57.6%)上提升 5%-10%,因搜索引擎补充了模型缺失的实时或罕见事实;
-
兼容性优势:无需修改模型或提示,仅通过 API 接口即可联动,实现简单(数行代码)。
-
与同类分解式方法(如 Least-to-most)相比,self-ask 在相近准确率下生成的 tokens 更少(如 2WikiMultiHopQA 中,self-ask 平均生成 569 tokens,Least-to-most 为 844 tokens),速度快 30% 以上,更高效。
-
完整源码地址:
-
GitHub 仓库:https://github.com/tinyseeking/tidy-agent-practice/tree/main/cognitive_pattern/self_ask
-
Gitee 仓库(国内):https://gitee.com/tinyseeking/tidy-agent-practice/tree/main/cognitive_pattern/self_ask
-
self-ask + 搜索引擎进一步提升性能:在 2WikiMultiHopQA 上准确率达 40.1%(高于 self-ask 的 30.0%),在 Musique(15.2% vs 13.8%)和 Bamboogle(60.0% vs 57.6%)上提升 5%-10%,因搜索引擎补充了模型缺失的实时或罕见事实;
-
兼容性优势:无需修改模型或提示,仅通过 API 接口即可联动,实现简单(数行代码)。
-
与同类分解式方法(如 Least-to-most)相比,self-ask 在相近准确率下生成的 tokens 更少(如 2WikiMultiHopQA 中,self-ask 平均生成 569 tokens,Least-to-most 为 844 tokens),速度快 30% 以上,更高效。
-
完整源码地址:
- GitHub 仓库:https://github.com/tinyseeking/tidy-agent-practice/tree/main/cognitive_pattern/self_ask
- Gitee 仓库(国内):https://gitee.com/tinyseeking/tidy-agent-practice/tree/main/cognitive_pattern/self_ask

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)