移动云大云海山数据库(He3DB)前沿探索:HTAP架构技术调研分析
PolarDB 采用分布式集群架构,这里的分布式集群是指主从架构,一个集群版集群包含一个主节点和最多15个只读节点(至少一个,用于保障高可用)。主节点处理读写请求,只读节点仅处理读请求。主节点和只读节点之间采用Active-Active的Failover方式,提供数据库的高可用服务。简单来说 PolarDB=一个单机磁盘超大的 MySQL。
概述
本文为 HTAP 架构设计提供参考依据,本次调研选取 PolarDB、PolarDB-X、GoldenDB 三款主流产品,从技术架构、核心实现逻辑、实际使用方式等维度展开深度分析。三款产品均以列存索引为核心实现分析型处理(AP)能力,结合行存满足在线事务处理(TP)需求,支持查询的自动路由与手动指定,数据同步均依托日志复制机制实现。其中,PolarDB 采用主从集群架构,通过 IMCI 列存索引、代价估算机制选择执行引擎,列存索引部署于只读节点并基于 Redo 日志异步同步;PolarDB-X 为分布式云原生架构,增设多类功能节点支持 MPP 并行计算,通过独立只读集群实现 TP/AP 负载隔离,列存基于类 LSM 树的 Delta Main 模型存储,依托 Binlog 同步并支持全量 + 增量数据合并;GoldenDB 支持行存、列存及行列混合表三种类型,由 CN 节点统一接入请求并根据表存储类型自动路由,列存数据基于 Binlog 日志复制转换,但其 HTAP 相关技术资料尚不完善。
友商方案
PolarDB
概述
PolarDB 采用分布式集群架构,这里的分布式集群是指主从架构,一个集群版集群包含一个主节点和最多15个只读节点(至少一个,用于保障高可用)。主节点处理读写请求,只读节点仅处理读请求。主节点和只读节点之间采用Active-Active的Failover方式,提供数据库的高可用服务。简单来说 PolarDB=一个单机磁盘超大的 MySQL 。
该产品通过列存索引实现 AP 能力,列存索引对用户可见,支持手动添加与修改,本质是将指定列数据转换为列存压缩存储形式。查询时,系统会通过代价估算机制判定采用 TP 执行引擎还是 AP 执行引擎,也支持用户强制指定 AP 查询。
注意:仅当查询 SQL 语句涉及的所有列均被列存索引完全覆盖时,才能通过列存索引实现查询加速。
架构
PolarDB 整体架构按功能划分为读写节点、TP 读节点与 AP 读节点,其 SQL 执行架构核心为代价估算驱动的执行引擎选择,流程为:SQL 解析→代价评估→生成逻辑执行计划→转换为物理执行计划,最终根据代价结果选择行存执行计划或列存执行计划,分别对应行存执行引擎、列存向量执行引擎,两套引擎搭配不同的算子、调度器与存储访问接口,实现行列混合执行。
总体架构
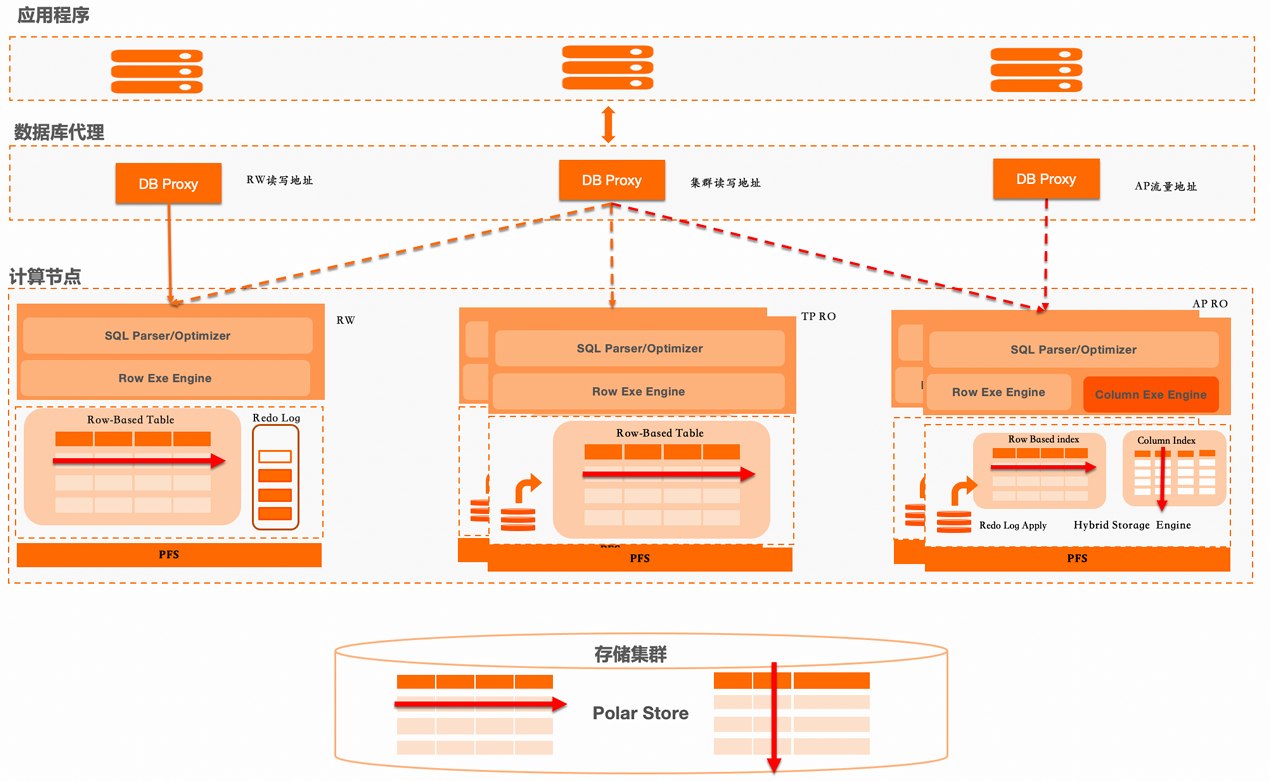
sql 执行架构
使用
列存索引支持建表时指定,也可在后续业务中动态修改,同时支持库表级批量配置,具体语法如下:
|
-- 建表时 -- 为某一列添加列存索引 CREATE TABLE <table_name>( <column_name_1> INT COMMENT 'COLUMNAR=1', <column_name_2> VARCHAR(100) ) ENGINE InnoDB;
-- 为全表添加列存索引 CREATE TABLE <table_name>( <column_name_1> INT, <column_name_2> VARCHAR(100) ) ENGINE InnoDB COMMENT 'COLUMNAR=1';
-- 动态修改 -- 为指定列添加列存索引 ALTER TABLE <table_name> MODIFY COLUMN <column_name_1> INT COMMENT 'COLUMNAR=1';
-- 为整个表添加列存索引 ALTER TABLE <table_name> COMMENT 'COLUMNAR=1';
-- 库表级批量修改 -- 为整个表添加列存索引 CREATE COLUMNAR INDEX ON <db_name>.<table_name>;
-- 为整个库添加列存索引 CREATE COLUMNAR INDEX FOR TABLES IN <db_name>; |
ap 查询使用方法
自动选择
新增列存索引只读节点后,需要为SQL语句中所查询的表都增加列存索引,且SQL语句的预估执行代价超过一定阈值,该SQL语句才会使用列索引进行查询。另外,SQL语句需要被转发到列存索引只读节点,才可以使用列存索引进行查询加速。
具体规则:使用集群地址并开启行存 / 列存自动引流后,若 SQL 预估执行代价高于阈值loose_imci_ap_threshold或loose_cost_threshold_for_imci,数据库代理会自动将 SQL 转发至列存索引只读节点,且阈值支持自定义修改。
手动分流
按应用类型做负载隔离,将 OLTP 类应用与不含只读列存节点的集群地址关联,其读请求由主节点或只读行存节点处理;将 OLAP 类应用与仅包含只读列存节点的集群地址关联,其读请求由只读列存节点专属处理。
强制指定
强制指定将SQL转发到列存索引只读节点,例如:
/FORCE_IMCI_NODES/EXPLAIN SELECT COUNT(*) FROM t1 WHERE t1.a > 1;
数据同步
PolarDB 使用读写分离的部署架构,RW 节点(写节点)承担写流量,RO 节点(只读节点)承担读流量。RO 节点通过异步复制的方式回放 RW 节点发送的日志以保持数据实时更新。
为了实现资源隔离,PolarDB 列存索引被部署在 RO 节点上,对列索引的更新是通过 Redo 日志异步物理复制的方式来实现的。
存储
采用列压缩存储,选择列式Heap Table作为底层主要存储架构来支持实时更新,SQL Server以及Oracle的Column Index也采用了相同的存储架构。
数据按RowGroup组织,每个RowGroup包含64K行。对于每一列的列索引,其存储都采用的是无序且追加写的格式。因此,IMCI无法像InnoDB的普通有序索引那样,可以精确地过滤掉不符合要求的数据。在读取DataPack时,需要从磁盘中加载进内存并解压缩,然后遍历DataPack中的所有记录,利用过滤条件筛选出符合条件的记录。
针对上述存储特性,PolarDB 引入查询剪枝技术:通过访问分区信息与统计信息,结合查询过滤条件,在查询执行前提前过滤无需访问的 DataPack,减少数据访问量、存储扫描次数,从而降低数据传输与计算消耗,提升查询效率。数据删除采用标记删除方式实现。
关于 ddl
目前未查询到 PolarDB 列存索引相关的 DDL 专属资料,结合产品常见问题整理核心要点:执行加减列等表结构变更操作时,会触发表数据重建;若原表已配置列存索引,数据重建的同时会同步重建列存索引数据,且列存索引重建过程需写入 Redo 日志。由于列存索引通常覆盖多列,重建产生的 Redo 日志量与原表数据量成正比,相较于无列存索引的表,会增加 IO 数据量,导致 DDL 执行时间变长。
PolarDB 的 DDL 同步依托 MySQL 的 binlog 或 Redo 日志实现主从同步。
部分原理
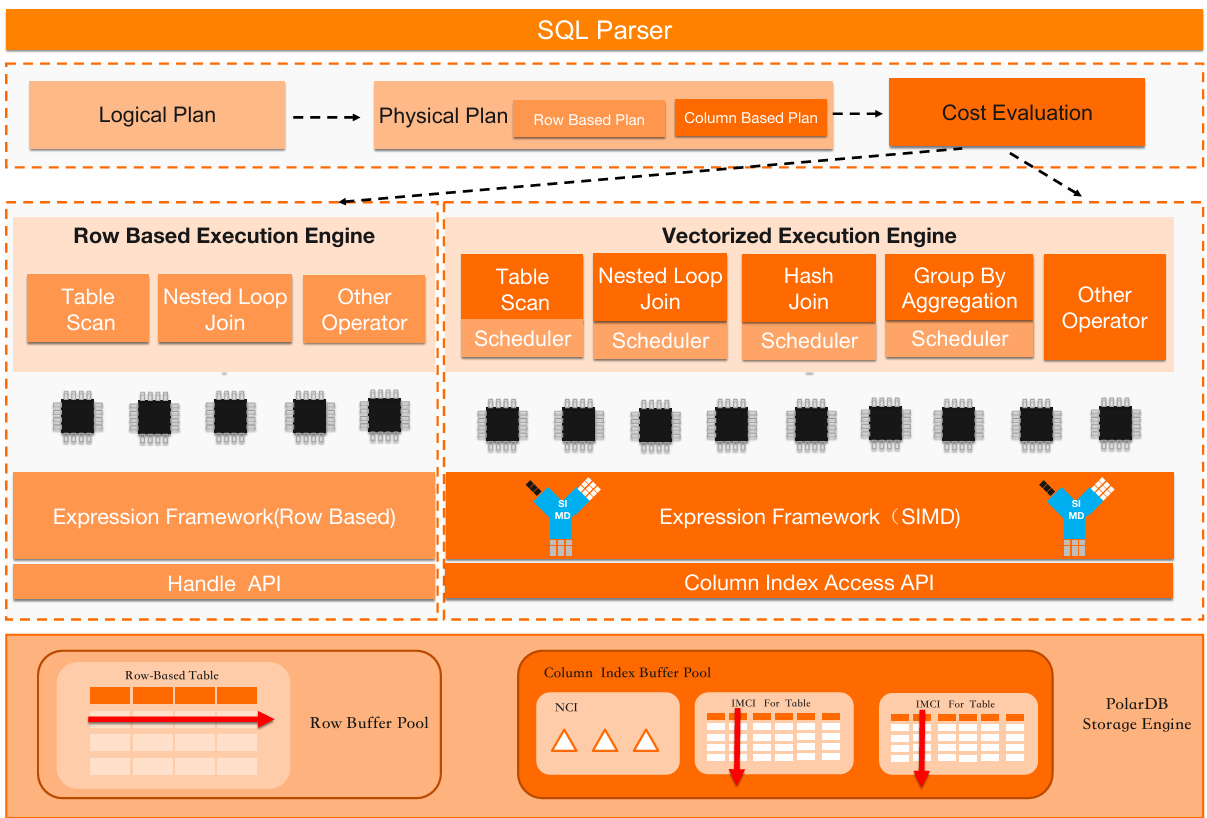
PolarDB 的核心优势为兼顾行列混合执行的优化器,因同时存在行存和列存两套执行引擎,优化器可对比两套引擎的执行代价,选择代价最低的执行计划。
在PolarDB中,除原生MySQL的行存串行执行外,还有能够发挥多核计算能力的基于行存的Parallel Query功能。因此,实际优化器会在行存串行执行、行存Parallel Query、以及IMCI三个之中选择其一。在目前的迭代阶段,优化器按如下的流程执行:
执行SQL的Parse过程并生成LogicalPlan,然后调用MySQL原生优化器,并执行优化操作(join order等)。同时该阶段获得的逻辑执行计划会转给IMCI的执行计划编译模块,并尝试生成一个列存的执行计划(此处可能会被白名单拦截并回滚回行存)。
PolarDB的Optimizer会根据行存计划,计算得出一个面向行存的执行Cost。如果此Cost超过一定阈值,则会尝试下推到IMCI执行器使用IMCI_Plan执行。
如果IMCI无法执行此SQL,则PolarDB会尝试编译出一个Parallel Query的执行计划并执行。如果无法生成PQ的执行计划,则说明IMCI和PQ均无法执行此SQL,则回滚回行存执行。
上述策略是基于这样一个判断,从执行性能上进行对比:行存串行执行 < 行存并行执行 < IMCI。 对比SQL兼容性,IMCI < 行存并行执行 < 行存串行执行。但是实际情况会更加复杂,例如:某些情况下,基于行存有序索引覆盖的并行Index Join会比基于列存的Sort Merge join有更低的Cost。按照当前策略,则会选择IMCI列存执行。
配置参数
同类产品技术参考
Oracle公司在2013年发表的Oracle 12C上,发布了Database In-Memory套件,其最核心的功能为In-Memory Column Store,即通过行列混合存储/高级查询优化(物化表达式,JoinGroup)等技术来提升OLAP性能。
微软在SQL Server 2016 SP1上,开始提供Column Store Indexs功能,用户可以根据负载特征,灵活的使用纯行存表、纯列存表、行列混合表以及列存表+行存索引等多种模式。
IBM在2013年发布的10.5版本(Kepler)中,增加了DB2 BLU Acceleration组件,通过列式数据存储配合内存计算以及DataSkipping技术,大幅提升分析场景的性能。
相关概念
涉及的mysql 概念:
binlog:逻辑日志,记录所有 SQL 操作(包含 DML、DDL),主要用于主从同步;
redo log:物理日志,记录数据库物理页的修改(包含 DML、涉及页修改的部分 DDL),主要用于数据恢复;
undo log:记录事务修改前的数据快照,主要用于事务回滚与多版本并发控制(MVCC)。
参考资料
IMCI(In-Memory-Column-Index)HTAP解决方案-蔡畅-阿里.pdf
PolarDB-X
概述
相较于 polardb , polardb-x 在主从基础上,加入分布式,是一个分布式版云原生数据库,同样通过列存索引实现 AP 能力,支持基于代价估算的查询自动路由,也支持用户强制指定 AP 查询。
基于分布式架构特性,PolarDB-X 建表时需指定分区规则,创建列存索引时需与表分区保持一致,查询时通过分布式执行提升效率。
架构
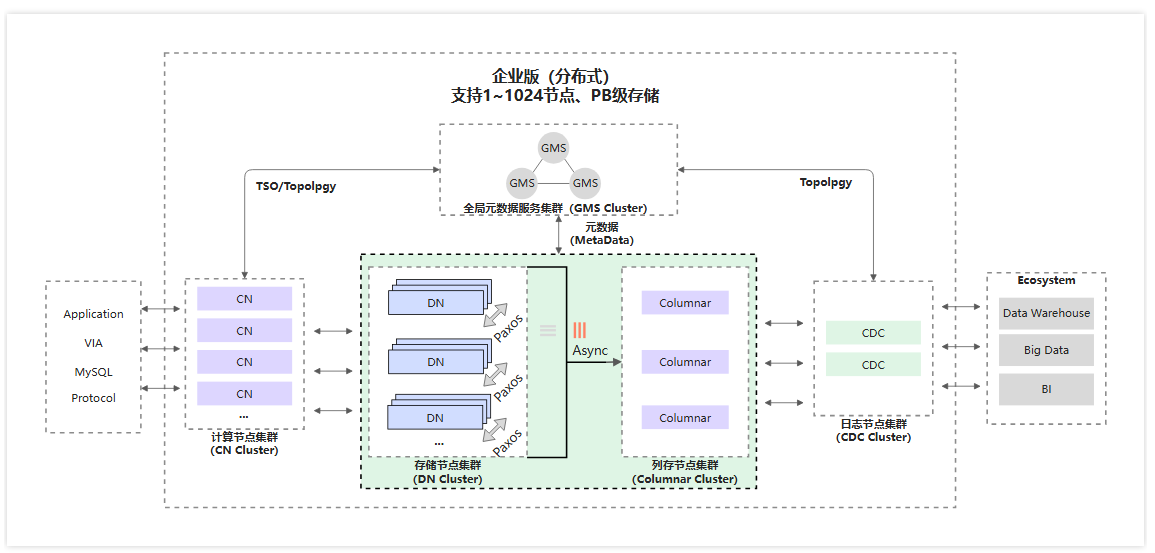
- 计算节点(Compute Node,CN)是系统的入口,采用无状态设计,包括SQL解析器、优化器、执行器等模块。负责数据分布式路由、计算及动态调度,负责分布式事务2PC协调、全局二级索引维护等,同时提供SQL限流、三权分立等企业级特性。
- 存储节点 (Data Node,DN)负责数据的持久化(面向行存数据),基于多数派Paxos协议提供数据高可靠、强一致保障,同时通过MVCC维护分布式事务的可见性,另外提供计算下推能力,以满足分布式的计算下推要求(例如Project/Filter/Join/Agg等下推计算)。
- 元数据服务(Global Meta Service,GMS)负责维护全局强一致的Table/Schema、Statistics等系统Meta信息,维护账号、权限等安全信息,同时提供全局授时服务(TSO)。
- 日志节点(Change Data Capture,CDC)提供完全兼容MySQL Binlog格式和协议的增量订阅能力,提供兼容MySQL Replication协议的主从复制能力。
- 列存引擎(Columnar)提供持久化列存索引,实时消费分布式事务的Binlog日志,基于对象存储介质构建列存索引,能满足实时更新的需求,结合计算节点可提供列存的快照一致性查询能力。
为了加速复杂分析型查询,PolarDB-X将计算任务切分并调度到多个计算节点上,从而利用多个节点的计算能力,加速查询的执行。这种方式也称为MPP并行计算。
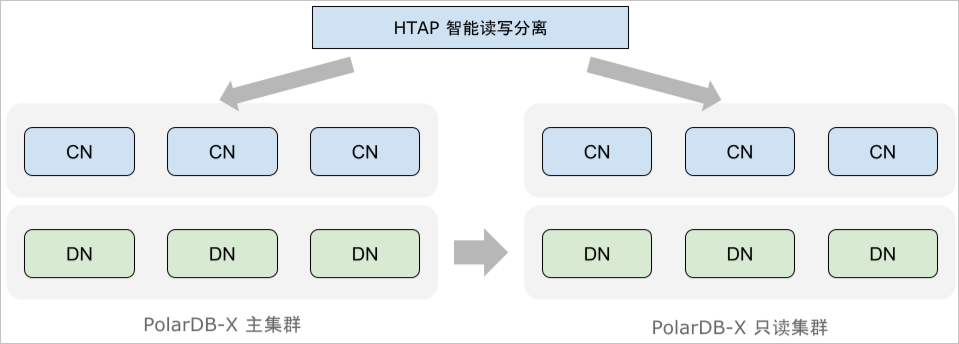
阻碍HTAP数据库实际应用的一大障碍是分析型查询(AP)对在线业务流量(TP)的影响。为了解决这一问题,PolarDB-X支持部署独立的只读集群,只读集群与原集群在硬件资源上完全分离,从而将AP查询对TP流量的影响降到最低。
PolarDB-X优化器会基于代价估计将请求区分为TP与AP负载,其中AP查询会被进一步改写为分布式执行计划,发往只读集群进行计算,避免它对主实例的TP查询造成影响。
使用
示例
|
创建表,分区: CREATE TABLE t_order ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `order_id` varchar(20) DEFAULT NULL, `buyer_id` varchar(20) DEFAULT NULL, `seller_id` varchar(20) DEFAULT NULL, `order_snapshot` longtext DEFAULT NULL, `order_detail` longtext DEFAULT NULL, PRIMARY KEY (`id`), KEY `l_i_order` (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 partition by hash(`order_id`) partitions 16;
创建列存索引,分区一致: CREATE CLUSTERED COLUMNAR INDEX `cc_i_seller` ON t_order (`seller_id`) partition by hash(`order_id`) partitions 16; |
使用 ap 查询的方法
根据代价估算自动路由。
利用 FORCE INDEX({index_name}) 语法强制指定 ap :
|
SELECT a.*, b.order_id FROM t_seller a JOIN t_order b FORCE INDEX(cc_i_seller) ON a.seller_id = b.seller_id WHERE a.seller_nick="abc"; |
数据同步
PolarDB-X 的列存数据同步基于 Binlog 主从复制实现,对于新建列存索引时表内已有数据,或者历史 binlog 文件已过期不存在,对这种场景有特殊处理逻辑:
当列存引擎在binlog事件流中,检测到创建列存索引ddl事件后,便开始同步该表DML操作,形成的数据称为增量数据,同时会另起线程去PolarDB-X行存通过select逻辑捞取已有的全部数据,称为全量数据。等全量数据捞取完毕,最后将全量数据和增量数据进行合并,便是该列存索引的所有数据,后续继续同步binlog数据即可。
存储
PolarDB-X 的列存存储采用Delta Main 模型(类 LSM 树结构),核心设计思想为:写入时采用顺序写入数据,数据更改以追加记录形式实现,追加记录认为是Delta Data(增量数据),等Delta Data写满阈值,转成Main Data数据(主体数据),一个单位内的数据可以认为是一段范围内的数据、一个分区内的数据或者一个文件内的数据,可根据实际情况进行分隔,这样对读性能进行优化,一段范围内的数据只需要读取Main Data和Delta Data,需要归并的数据大大降低,并且利用后台异步线程尽可能将Delta Data数据转成Main Data,进一步减少读开销。
关于 ddl
通过 binlog实现 同步。
参考资料
https://zhuanlan.zhihu.com/p/2359967708
https://www.polardbx.com/document?type=PolarDB-X
GoldenDB
概述
GoldenDB 可创建行存模式表、列存模式表和行列混合表三种表类型。 GoldenDB 对行列混合表同时在行存存储节点和列存存储节点创建表,并通过 Binlog 日志同步组件自动进行数据准实时同步。
应用的 SQL 请求统一通过 CN 接入,CN 根据 SQL 所访问表的存储类型进行自动路由:CN 可直接访问行式存储,或者通过 AP 的Coordinator/Worker 调度,对行式表或列式表进行查询计算。
说明:GoldenDB 的 HTAP 相关技术资料尚不完善,本次调研仅基于现有公开资料分析。
架构
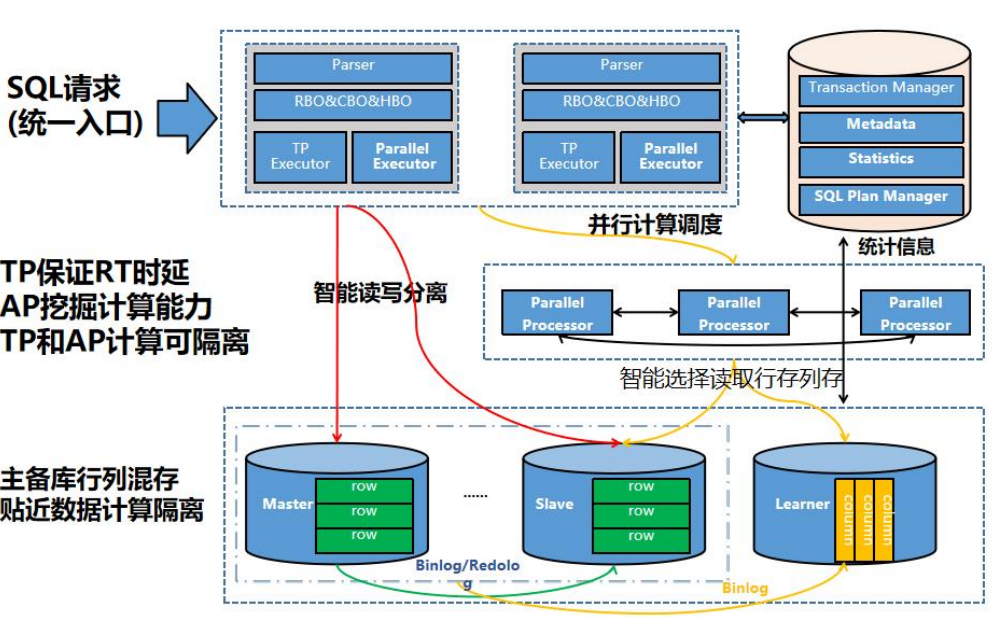
GoldenDB TP 部分由计算节点(CN)处理,并可增加AP组件(Coordinator 和 Worker)进行 SQL 统计查询。
GoldenDB 可选装列存存储 VEngine 节点,适用于交互式 SQL 数据仓库应用场景。通过 VEngine 节点,可创建行存模式表、列存模式表和行列混合表三种表类型。 GoldenDB 对行列混合表同时在行存存储节点和列存存储节点创建表,并通过日志同步组件自动进行数据准实时同步。
应用的 SQL 请求统一通过 CN 接入,CN 根据 SQL 所访问表的存储类型进行自动路由:CN 可直接访问行式存储,或者通过 AP 的Coordinator/Worker 调度,对行式表或列式表进行查询计算。
使用
目前暂无 GoldenDB 创建与管理列存表 / 列存索引的确切语法,根据现有资料推测:列存相关配置对用户可见,支持手动创建列存表,以及行存、列存、行列混合表的灵活切换_。_
使用 ap 查询的方法
GoldenDB 的 AP 查询采用全自动路由方式,由 CN 节点根据查询涉及表的存储类型、负载特征,自动调度至对应节点 / 组件执行,无需用户手动干预。
数据同步
列存数据基于 MySQL 的 Binlog 日志复制并转换而成。
参考资料
https://goldendb.com/#/docsIndex/docs/GoldenDB/v6.1.03.10/easyOperate_SQLBasicOperations

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)