多模态大模型学习笔记(十)——基于卷积神经网络的图像分类实战
这篇文章围绕一套可直接运行的 CNN 代码展开,便于对照实现与输出结果。
基于卷积神经网络的图像分类实战
这篇文章围绕一套可直接运行的 CNN 代码展开,便于对照实现与输出结果。
激活函数基础
非线性是深层网络有效的根因。没有激活函数,网络会退化为线性变换的堆叠,表达力极其有限;加入激活后,网络才能学习更复杂的决策边界。
不同激活的梯度分布差异明显,会直接影响收敛速度与稳定性。梯度是否稳定决定了训练过程是否平滑。
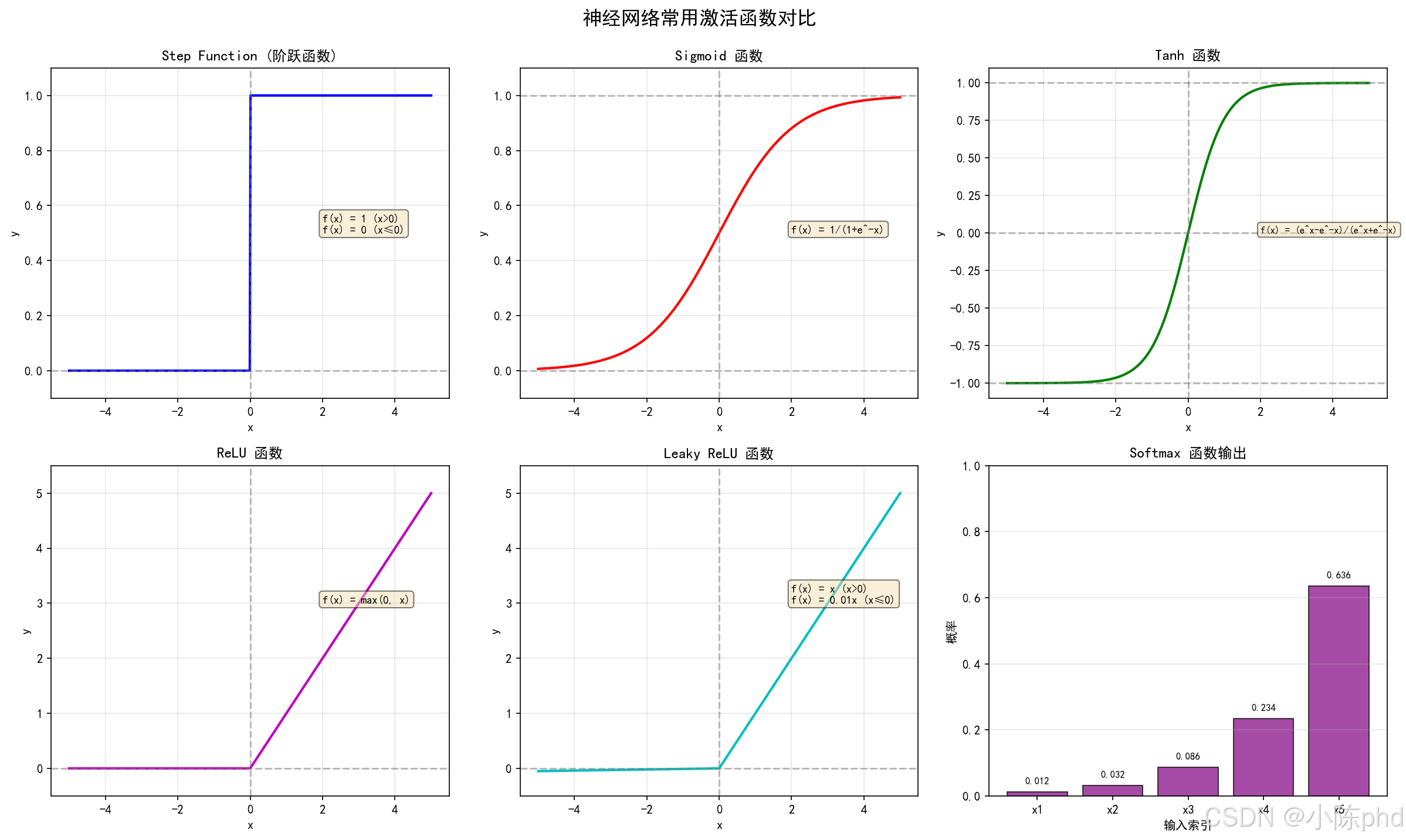
图中概览了常见激活的形态与梯度特性,可直观看到哪些激活更容易出现梯度饱和或稀疏。
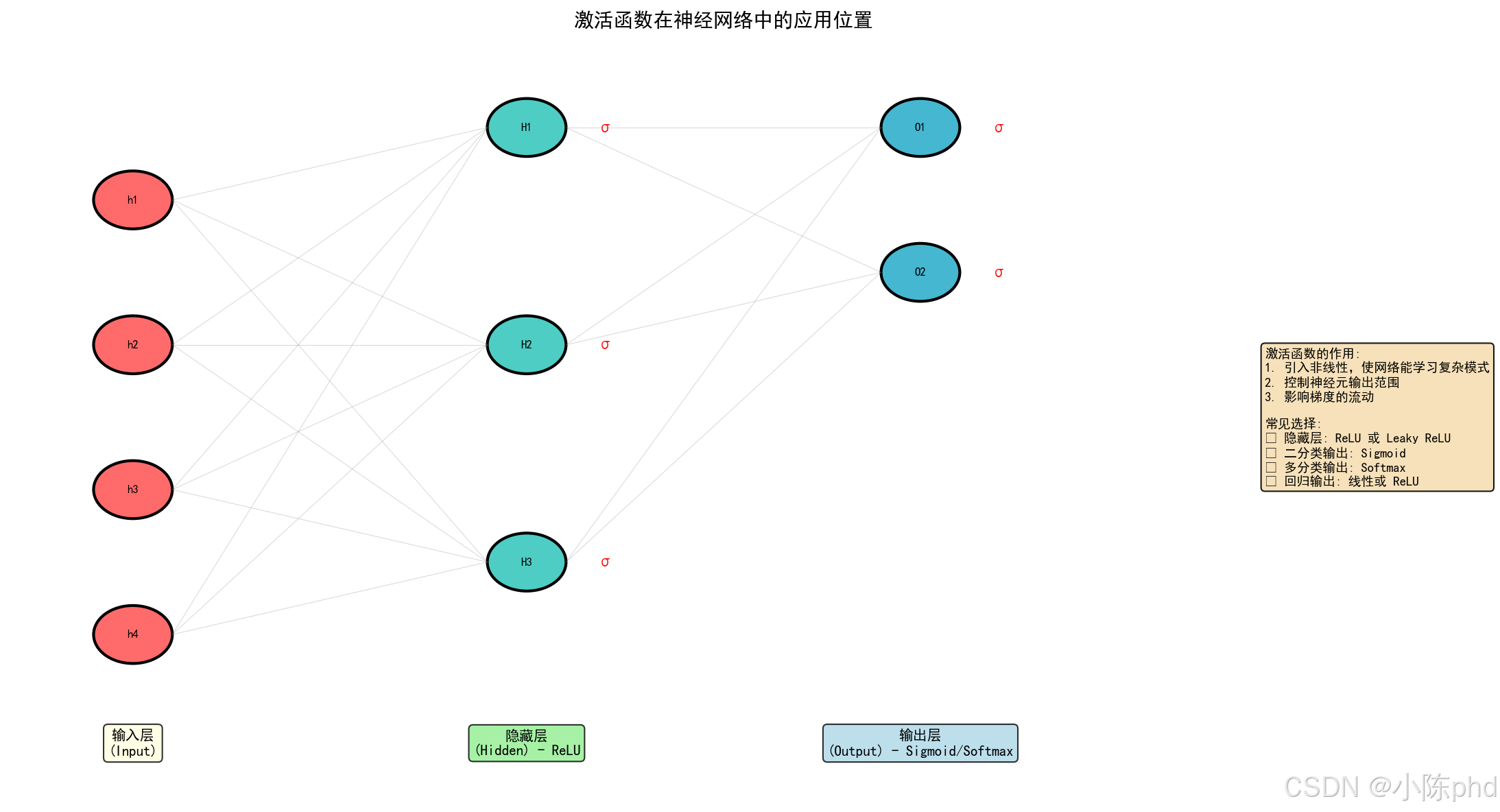
这张图把激活放在网络结构里展示,强调它与卷积、归一化的相对位置,这一顺序会影响收敛稳定性。
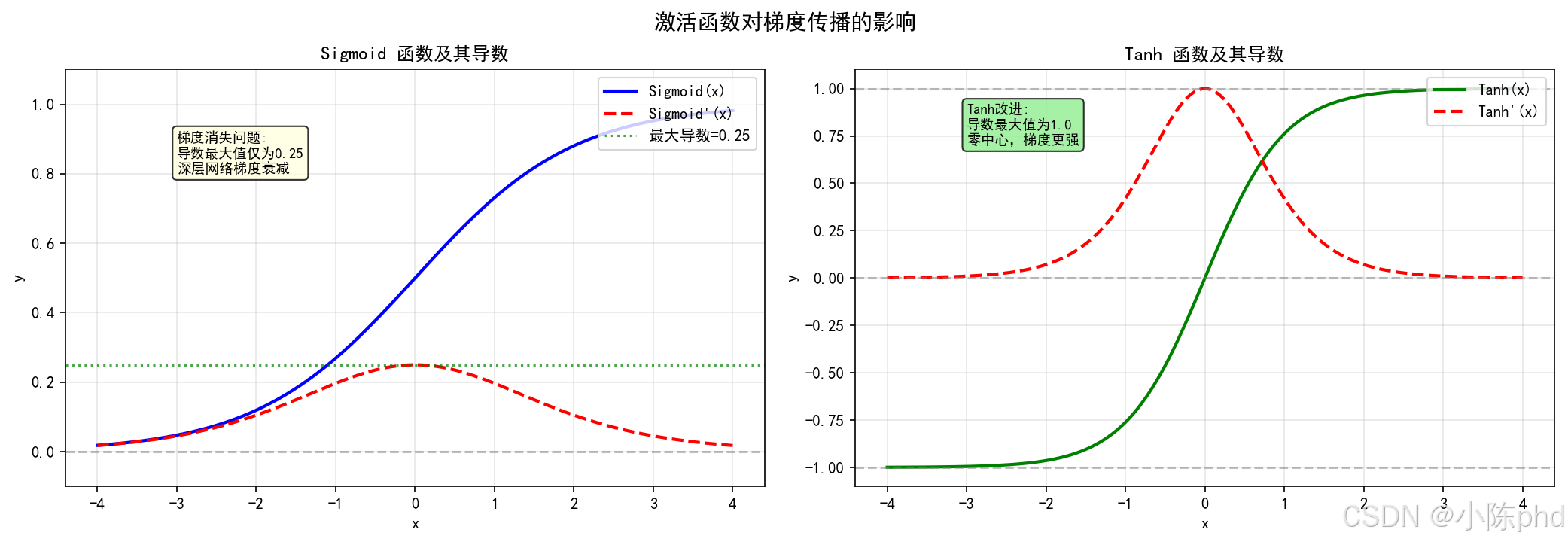
这张图把不同激活的梯度表现放在一起对比。同一模型、同一数据下,梯度越稳定,loss 曲线越平滑;梯度越不稳定,训练越容易抖动。因此代码将激活设计为可切换,便于公平对比。
1. 配置入口
把激活、归一化、优化器、调度器做成可配置,实验变量集中在一个入口,便于复现与消融对比。实现上通过 Config 统一管理实验变量。
@dataclass
class Config:
ACTIVATION: str = "relu"
NORM: str = "batch"
DROPOUT_P: float = 0.1
OPTIMIZER: str = "adamw"
LR: float = 3e-4
SCHEDULER: str = "cosine_warmup"
BATCH_SIZE: int = 128
EPOCHS: int = 15
只改一个字段就能切换实验条件,例如快速对比 ReLU 与 GELU 的收敛差异。
2. 数据管线
先用 FakeData 跑通训练流程,把注意力放在流程正确性;再加入数据增强,模拟真实训练的泛化需求。实现上用随机裁剪、翻转与归一化构建训练集。
train_tfms = [
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(CFG.IMG_SIZE, padding=4),
transforms.ToTensor(),
transforms.Normalize(mean, std),
]
train_dataset_full = datasets.FakeData(
size=CFG.TRAIN_SAMPLES,
image_size=(3, CFG.IMG_SIZE, CFG.IMG_SIZE),
num_classes=CFG.NUM_CLASSES,
transform=transforms.Compose(train_tfms),
)
流程能稳定跑通,并具备与真实任务一致的“增强 + 归一化”输入分布。
3. 模型结构
卷积负责局部特征提取,池化负责降采样与平移不变性,全局平均池化用于减少参数量。实现上用三层卷积块 + 池化 + 全局平均池化 + 线性头。
class ConvBlock(nn.Module):
def __init__(self, in_c, out_c, activation, norm, dropout_p, H, W):
self.conv = nn.Conv2d(in_c, out_c, kernel_size=3, padding=1)
self.norm = make_norm2d(norm, out_c, H, W)
self.act = make_activation(activation)
self.drop = nn.Dropout2d(p=dropout_p) if dropout_p > 0 else nn.Identity()
class SmallCNN(nn.Module):
def __init__(self, cfg: Config):
self.block1 = ConvBlock(3, 64, cfg.ACTIVATION, cfg.NORM, cfg.DROPOUT_P, H, W)
self.pool1 = nn.MaxPool2d(2)
self.block2 = ConvBlock(64, 128, cfg.ACTIVATION, cfg.NORM, cfg.DROPOUT_P, H//2, W//2)
self.pool2 = nn.MaxPool2d(2)
self.block3 = ConvBlock(128, 256, cfg.ACTIVATION, cfg.NORM, cfg.DROPOUT_P, H//4, W//4)
self.pool3 = nn.AdaptiveAvgPool2d((1,1))
self.head = nn.Linear(256, cfg.NUM_CLASSES)
模型结构清晰,训练速度快,适合快速做对比实验。
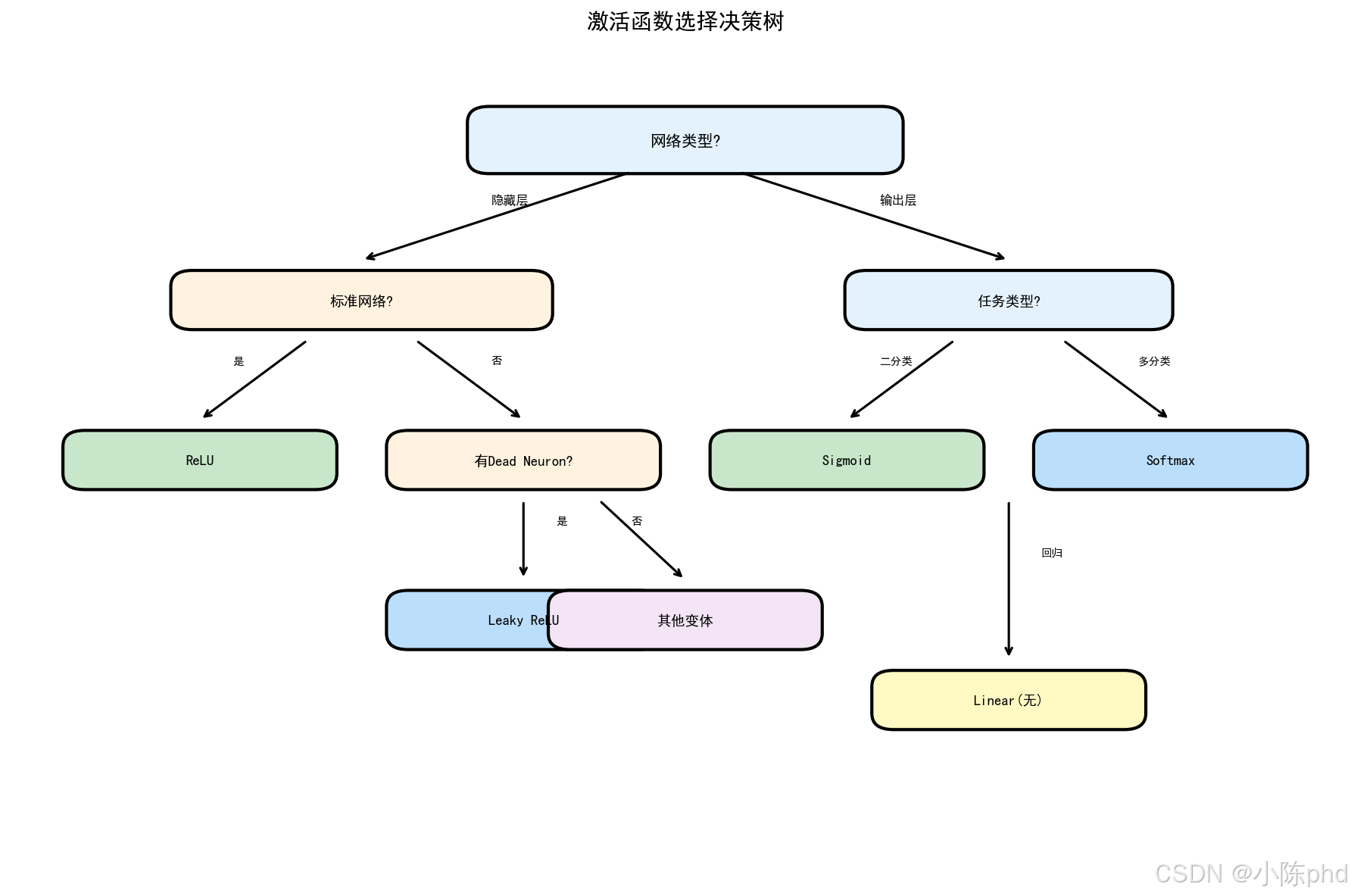
这张图给出激活选择的直观参考,可结合任务规模与收敛曲线做取舍。
4. 损失与优化
损失函数决定优化目标,优化器决定参数更新方式。分类任务常用交叉熵作为主损失。实现上交叉熵与 MSE 二选一,默认 AdamW。
def make_criterion(name: str):
if name == "cross_entropy":
return nn.CrossEntropyLoss()
if name == "mse":
return nn.MSELoss()
def make_optimizer(name: str, params, lr: float, weight_decay: float):
if name == "adamw":
return torch.optim.AdamW(params, lr=lr, weight_decay=weight_decay)
训练更稳定,loss 下降更平滑,收敛速度更可控。
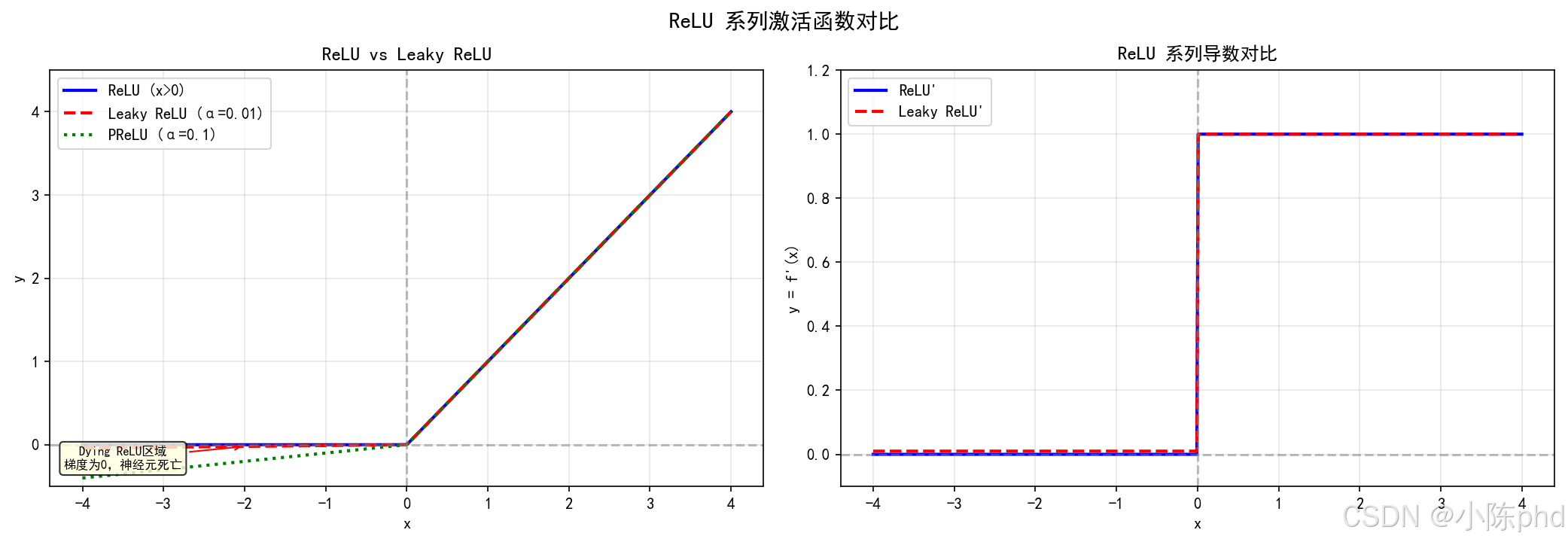
这张图对比 ReLU 相关特性,适合与调度器一起观察收敛是否稳定。
5. 调度器
Warmup 防止初期梯度爆炸或震荡,Cosine 让后期学习率平滑下降。实现上使用 LambdaLR 实现 warmup + cosine。
def make_scheduler(name: str, optimizer, *, steps_per_epoch=None):
if name == "cosine_warmup":
total_steps = CFG.EPOCHS * steps_per_epoch
warmup = CFG.COSINE_WARMUP_STEPS
def lr_lambda(step):
if step < warmup:
return float(step) / float(max(1, warmup))
progress = (step - warmup) / float(max(1, total_steps - warmup))
return 0.5 * (1.0 + math.cos(math.pi * progress))
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
训练曲线更稳定,验证集指标更可控。
6. 训练闭环
训练与验证分开统计,调度器根据验证损失更新,早停防止过拟合。实现上通过训练、验证、早停与最优权重保存完成闭环。
train_loss, train_acc, global_step = train_one_epoch(...)
val_loss, val_acc = evaluate(...)
if isinstance(scheduler, torch.optim.lr_scheduler.ReduceLROnPlateau):
scheduler.step(val_loss)
if CFG.EARLY_STOP:
if val_loss < best_val - 1e-6:
best_state = {k: v.cpu().clone() for k, v in model.state_dict().items()}
else:
bad_epochs += 1
训练过程可监控,最终模型来自验证最优权重而不是最后一轮。
7. 运行方式
先跑通默认配置,再逐项修改做对比,避免变量过多导致定位困难。运行方式如下:
python dl.py
日志输出包含 lr / train_loss / train_acc / val_loss / val_acc,便于观察收敛与过拟合趋势。
8. 结果分析
训练与验证曲线的相对关系决定是否过拟合;混淆矩阵用于类别级问题定位。脚本输出测试集准确率与混淆矩阵,并保留验证最优权重。
可以快速判断模型是否收敛、是否过拟合,以及哪些类别最容易混淆。
9. 可选扩展
训练闭环稳定后,扩展方向主要是数据集与模型规模。实现上可替换 FakeData 为 CIFAR-10 或自定义数据集、升级为 ResNet/MobileNet、接入 TensorBoard 做可视化,同一套训练闭环可直接迁移到真实任务。
如果这类内容对你有帮助,欢迎关注,后续会持续分享深度学习训练技巧、工程化落地与代码实战案例。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)