【VeRL】Qwen3-235B-A22B 强化学习昇腾Atlas 800T A2复现与部署实践
在大模型训练与推理场景中,如何高效利用昇腾硬件资源进行大规模语言模型的部署与训练是一个重要课题。本文详细记录了在昇腾Atlas 800T A2环境下复现部署Qwen3-235B-A22B Verl强化学习的全过程,包括环境配置、参数调优、数据集处理等关键环节。
作者:昇腾实战派
知识地图链接:强化学习知识地图
一、背景概述
在大模型训练与推理场景中,如何高效利用昇腾硬件资源进行大规模语言模型的部署与训练是一个重要课题。本文详细记录了在昇腾Atlas 800T A2环境下复现部署Qwen3-235B-A22B Verl强化学习的全过程,包括环境配置、参数调优、数据集处理等关键环节。
二、环境配置
硬件版本:Atlas 800T A2
2.1 版本信息
| 组件 | 版本 |
|---|---|
| HDK | 25.2.1 |
| CANN | 8.3.RC1 |
| VeRL | 796871d7d092f7cbc6a64e7f4a3796f7a2217f5e https://github.com/verl-project/verl/commit/796871d7d092f7cbc6a64e7f4a3796f7a2217f5e |
| vllm | 38217877aa70041c0115ee367b75197af9cbc5ad https://github.com/vllm-project/vllm/commit/38217877aa70041c0115ee367b75197af9cbc5ad |
| vllm-ascend | 1de16ead8eecfec8903ec1b330b27a4fa2593c35 https://github.com/vllm-project/vllm-ascend/commit/1de16ead8eecfec8903ec1b330b27a4fa2593c35 |
| MindSpeed | 1cdd0ab https://gitcode.com/Ascend/MindSpeed/commit/1cdd0ab |
| Megatron-LM | core_v0.12.1 |
| transformers | 8365f70e925 |
| torch | 2.7.1 |
| toch-npu | 2.7.1 |
2.2 部署指导
2.2.1 镜像部署
下载镜像
登录ascend-verl镜像仓库,选择需要的镜像,拷贝镜像拉取命令
https://quay.io/repository/ascend/verl?tab=tags&tag=latest

服务器执行拉取命令
docker pull quay.io/ascend/verl:verl-8.2.rc1-910b-ubuntu22.04-py3.11-latest

创建容器
docker run -it -u root --ipc=host --net=host \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /var/log/npu/:/usr/slog \
-v /usr/lib/jvm/:/usr/lib/jvm \
-v /workspace:/workspace \
quay.io/ascend/verl:verl-8.2.rc1-910b-ubuntu22.04-py3.11-latest \
/bin/bash
2.2.2 手动部署
基础环境配置
首先安装驱动固件及CANN软件包,具体参考昇腾社区安装指导:
https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/850alpha001/softwareinst/instg/instg_0005.html
核心组件安装
torch及torch-npu安装
pip install torch==2.7.1
wget https://gitcode.com/Ascend/pytorch/releases/download/v7.2.0-pytorch2.7.1/torch_npu-2.7.1-cp310-cp310-manylinux_2_28_aarch64.whl
pip install torch_npu-2.7.1-cp310-cp310-manylinux_2_28_aarch64.whl
vllm安装
git clone https://github.com/vllm-project/vllm.git
cd vllm
git checkout 38217877aa70041c0115ee367b75197af9cbc5ad
pip install -r requirements/build.txt
VLLM_TARGET_DEVICE=empty pip install -v -e .
cd ..
vllm-ascend安装
git clone https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend
git checkout 1de16ead8eecfec8903ec1b330b27a4fa2593c35
pip install -r requirements.txt
export COMPILE_CUSTOM_KERNELS=1
python setup.py install
cd ..
其他组件安装
# transformers
git clone https://github.com/huggingface/transformers.git
cd transformers
git checkout 8365f70e925
pip install -e .
# MindSpeed
git clone https://gitcode.com/Ascend/MindSpeed.git
cd MindSpeed
git checkout 1cdd0abd75e40936ad31721c092f57c695dd72c4
pip install -e .
# Megatron-LM
pip install git+https://github.com/NVIDIA/Megatron-LM.git@core_v0.12.1
# VeRL
git clone https://github.com/volcengine/verl.git
cd verl
git checkout 796871d7d092f7cbc6a64e7f4a3796f7a2217f5e
pip install -e .
# rl-plugin
git clone https://gitcode.com/Ascend/MindSpeed-RL.git -b 2.2.0
cd MindSpeed-RL/rl-plugin
pip install -v .
cd ../..
三、核心参数配置(GRPO算法)
3.1 数据配置
data.max_prompt_length=8192
data.max_response_length=4096
actor_rollout_ref.actor.ppo_mini_batch_size=128
3.2 并行参数配置
3.2.1 Actor并行配置
actor_rollout_ref.actor.megatron.pipeline_model_parallel_size=8
actor_rollout_ref.actor.megatron.tensor_model_parallel_size=4
actor_rollout_ref.actor.megatron.expert_model_parallel_size=4
3.2.2 Ref模型并行配置
actor_rollout_ref.ref.megatron.pipeline_model_parallel_size=8
actor_rollout_ref.ref.megatron.tensor_model_parallel_size=4
actor_rollout_ref.ref.megatron.expert_model_parallel_size=4
3.2.3 Rollout并行配置
actor_rollout_ref.rollout.tensor_model_parallel_size=8
+actor_rollout_ref.rollout.dp_model_parallel_size=8
+actor_rollout_ref.rollout.rollout_world_size=128
3.3 完整训练脚本
HF_MODEL_PATH=/path/to/Qwen3-235B-A22B
DIST_CKPT_PATH=/path/to/Qwen3-235B-A22B-mcore
TRAIN_DATA_PATH=/path/to/train.parquet
TEST_DATA_PATH=/path/to/test.parquet
CKPTS_DIR=/path/to/checkpoints/
log_path=/path/to/output
export CUDA_DEVICE_MAX_CONNECTIONS=1
offload=True
python3 -m verl.trainer.main_ppo --config-path=config \
--config-name='ppo_megatron_trainer.yaml'\
algorithm.adv_estimator=grpo \
data.train_files=$TRAIN_DATA_PATH \
data.val_files=$TEST_DATA_PATH \
data.train_batch_size=128 \
data.max_prompt_length=8192 \
data.max_response_length=4096 \
data.filter_overlong_prompts=False \
data.truncation='error' \
actor_rollout_ref.model.path=$HF_MODEL_PATH \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.actor.ppo_mini_batch_size=128 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=1 \
actor_rollout_ref.actor.megatron.pipeline_model_parallel_size=8 \
actor_rollout_ref.actor.megatron.tensor_model_parallel_size=4 \
actor_rollout_ref.actor.megatron.expert_model_parallel_size=4 \
actor_rollout_ref.actor.megatron.use_dist_checkpointing=True \
actor_rollout_ref.actor.megatron.dist_checkpointing_path=$DIST_CKPT_PATH \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.001 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.actor.entropy_coeff=0 \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \
actor_rollout_ref.rollout.tensor_model_parallel_size=8 \
+actor_rollout_ref.rollout.dp_model_parallel_size=8 \
+actor_rollout_ref.rollout.rollout_world_size=128 \
actor_rollout_ref.rollout.name=vllm \
+actor_rollout_ref.rollout.enable_expert_parallel=True \
actor_rollout_ref.actor.megatron.param_offload=${offload} \
actor_rollout_ref.actor.megatron.optimizer_offload=${offload} \
actor_rollout_ref.actor.megatron.grad_offload=${offload} \
actor_rollout_ref.rollout.gpu_memory_utilization=0.5 \
actor_rollout_ref.rollout.n=16 \
actor_rollout_ref.rollout.max_num_batched_tokens=1024 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \
actor_rollout_ref.ref.megatron.pipeline_model_parallel_size=8 \
actor_rollout_ref.ref.megatron.tensor_model_parallel_size=4 \
actor_rollout_ref.ref.megatron.expert_model_parallel_size=4 \
actor_rollout_ref.ref.megatron.param_offload=${offload} \
actor_rollout_ref.ref.megatron.use_dist_checkpointing=True \
actor_rollout_ref.ref.megatron.dist_checkpointing_path=$DIST_CKPT_PATH \
algorithm.use_kl_in_reward=False \
trainer.critic_warmup=0 \
trainer.logger='["console"]' \
trainer.project_name='verl_grpo_example_gsm8k_math' \
trainer.experiment_name='qwen3_30b_moe_megatron' \
trainer.device=npu \
trainer.n_gpus_per_node=8 \
trainer.nnodes=16 \
trainer.save_freq=50 \
trainer.default_local_dir="${CKPTS_DIR}" \
trainer.test_freq=5 \
trainer.total_epochs=15 \
trainer.val_before_train=false \
+actor_rollout_ref.actor.megatron.override_transformer_config.recompute_method=uniform \
+actor_rollout_ref.actor.megatron.override_transformer_config.recompute_granularity=full \
+actor_rollout_ref.actor.megatron.override_transformer_config.recompute_num_layers=1 \
++actor_rollout_ref.actor.megatron.override_transformer_config.num_layers_in_first_pipeline_stage=11 \
++actor_rollout_ref.actor.megatron.override_transformer_config.num_layers_in_last_pipeline_stage=11 \
+actor_rollout_ref.actor.megatron.override_transformer_config.use_flash_attn=True \
++actor_rollout_ref.ref.megatron.override_transformer_config.use_flash_attn=True 2>&1 | tee ""${log_path}/verl_qwen3_235b_$(date +%Y%m%d_%H%M).log""
四、数据集处理
使用开源GSM8K数据集进行训练,数据集链接:https://huggingface.co/datasets/openai/gsm8k
数据集预处理命令:
python3 examples/data_preprocess/gsm8k.py --local_save_dir ~/data/gsm8k
该脚本将数据集转换为parquet格式,确保包含RL奖励计算所需的必要字段。
五、复现结果示例
5.1 精度表现
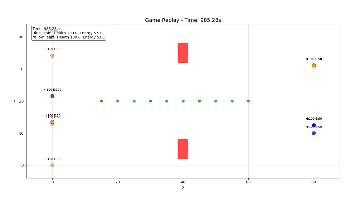
16机128卡训练日志的精度数据示例:

5.2 性能数据
训练过程中的性能监控数据示例:
六、部署建议
- 版本兼容性:确保各组件版本严格匹配,避免因版本不兼容导致的问题
- 硬件资源:根据模型规模合理配置计算资源,确保训练过程稳定
- 内存管理:合理设置offload参数,优化内存使用效率
- 监控调试:建议配置完善的日志监控系统,便于问题排查和性能优化

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)