告别“救火式”运维!如何利用 Syslog 实现主动式服务器监控与故障响应?
Syslog(System Logging Protocol)是一种用于转发系统日志或事件消息的标准协议。它诞生于 1980 年代,最初为 Sendmail 开发,后来逐渐演变成类 Unix 系统以及网络设备(如路由器、交换机、防火墙等)通用的日志标准。Syslog 的核心价值在于其标准化。一个完整的 Syslog 消息通常包含以下三个关键要素:设备(Facility):标识产生日志消息的软件类型
在当今复杂的 IT 生态系统中,确保服务器的无缝运行是一项艰巨的任务。为了维持系统的高可用性,运维团队需要实时了解服务器的运行状况。而在众多的监控工具中,Syslog(系统日志)始终是识别潜在问题、诊断错误和确保系统安全的核心支柱。
本文将深入探讨 Syslog 的工作原理,对比主动式监控与被动式监控的差异,并详细介绍如何利用高效的工具实现自动化的日志管理。
一 什么是 Syslog 协议?
Syslog(System Logging Protocol)是一种用于转发系统日志或事件消息的标准协议。它诞生于 1980 年代,最初为 Sendmail 开发,后来逐渐演变成类 Unix 系统以及网络设备(如路由器、交换机、防火墙等)通用的日志标准。
Syslog 的核心价值在于其标准化。一个完整的 Syslog 消息通常包含以下三个关键要素:
设备(Facility):标识产生日志消息的软件类型。例如,内核(kern)、邮件系统(mail)、系统守护进程(daemon)或本地使用(local0-local7)。这有助于监控系统对来自不同源的日志进行分类处理。
严重程度(Severity):标识该事件的紧急程度。Syslog 将级别划分为从 0 到 7 的八个等级。
内容(Message):包含有关事件的具体详细信息,例如错误代码、时间戳、主机名以及具体的操作描述。
系统日志消息的结构如下所示:
Version Timestamp Hostname App-Name ProcID MsgID Structured-Data Message
例如:
<134>1 2024-01-15T14:23:45.003Z webserver01 nginx 2847 - - upstream timed out (110: Connection timed out) while connecting to upstream
二 深入理解 Syslog 严重程度级别
为了实现有效的监控,运维人员必须能够根据事件的严重程度采取不同的响应措施。下表详细列出了 Syslog 的标准严重程度等级及其含义:
| 级别 (Level) | 严重程度 (Severity) | 关键词 (Keyword) | 描述 (Description) |
| 0 | 紧急 | Emergency | 系统不可用。这是最严重的告警,通常意味着系统崩溃。 |
| 1 | 报警 | Alert | 必须立即采取行动。例如,主要数据库损坏。 |
| 2 | 临界 | Critical | 临界条件。通常指硬件故障或严重的软件错误。 |
| 3 | 错误 | Error | 运行时错误。这些事件不需要立即处理,但如果不解决会影响功能。 |
| 4 | 警告 | Warning | 警告条件。预示着如果忽略该信号,可能会发生错误。 |
| 5 | 通知 | Notice | 正常但重要的条件。例如,某些服务的启动或停止。 |
| 6 | 信息 | Informational | 纯粹的消息。记录系统的正常操作流程。 |
| 7 | 调试 | Debug | 调试级别的信息。包含详细的系统开发和测试信息。 |
三 主动监控与被动响应的博弈
在传统的运维场景中,许多团队往往处于“被动响应(Reactive)”模式。这意味着只有在业务中断或用户投诉后,运维人员才会去翻阅 Syslog 寻找原因。
被动响应的局限性:
修复成本高:故障发生后,业务损失已经造成。
诊断延迟:在成千上万行日志中手动查找错误极其耗时。
缺乏预警:无法在系统崩溃前捕捉到征兆。
相比之下,主动监控(Proactive Monitoring)提倡在问题演变成故障之前就发现它们。通过实时分析 Syslog,系统可以捕捉到“警告(Warning)”或“临界(Critical)”级别的信号。例如,当磁盘 I/O 错误频繁出现但尚未导致宕机时,主动监控系统会立即触发告警。
四 为什么 Syslog 是主动监控的关键?
Syslog 不仅仅是事后查证的工具,它在主动运维中扮演着多重角色:
1. 早期故障检测
大多数系统故障并非瞬间发生。通过 Syslog,运维人员可以监控到内存溢出(OOM)前兆、CPU 过热告警或文件描述符耗尽等细微变化。
2. 根因分析(RCA)
当故障确实发生时,Syslog 提供了精确的时间线。通过将 Syslog 与服务器的性能指标(如内存、磁盘使用率)进行关联,运维人员可以迅速判断故障是由软件配置错误还是底层硬件失效引起的。
3. 安全合规与审计
Syslog 记录了所有的用户登录尝试、特权提升(sudo 命令)以及防火墙拦截记录。对于安全团队而言,实时监控这些日志是防御暴力破解和未授权访问的第一道防线。
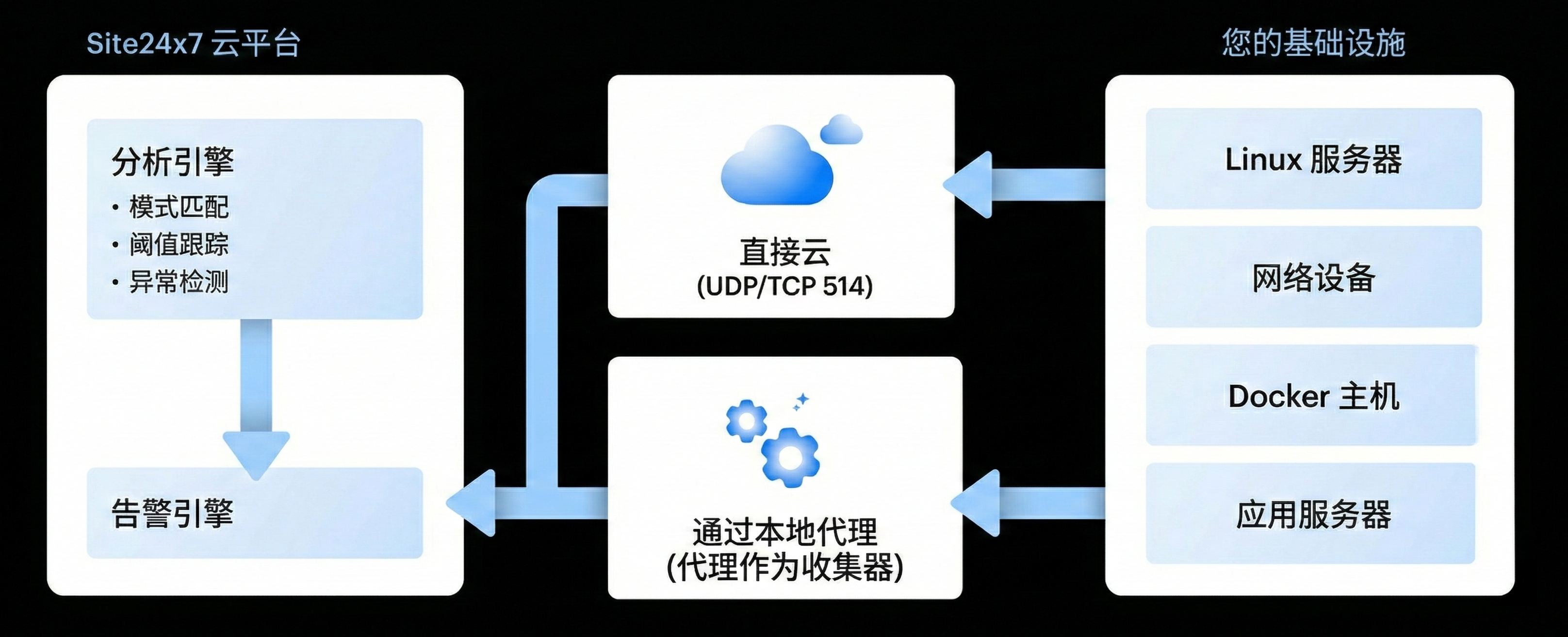
五 利用 Site24x7 优化 Syslog 监控流程
面对海量的日志数据,手动管理是不可能的。Site24x7 提供了一套完整的 Syslog 监控解决方案,旨在将复杂的日志流转化为可操作的洞察力。
1. 集中化日志管理
Site24x7 可以收集来自各种源(Linux 服务器、网络设备、云平台等)的 Syslog。通过一个统一的仪表盘,您可以管理全球范围内成百上千台设备的日志,告别逐台登录服务器查看日志的低效模式。
2. 智能过滤与告警规则
并非所有的日志都需要关注。Site24x7 允许您设置特定的过滤规则。例如,您可以配置系统只在接收到严重程度为 0-3(紧急到错误)的日志时才发送短信或邮件告警。这极大地减轻了“告警疲劳”。
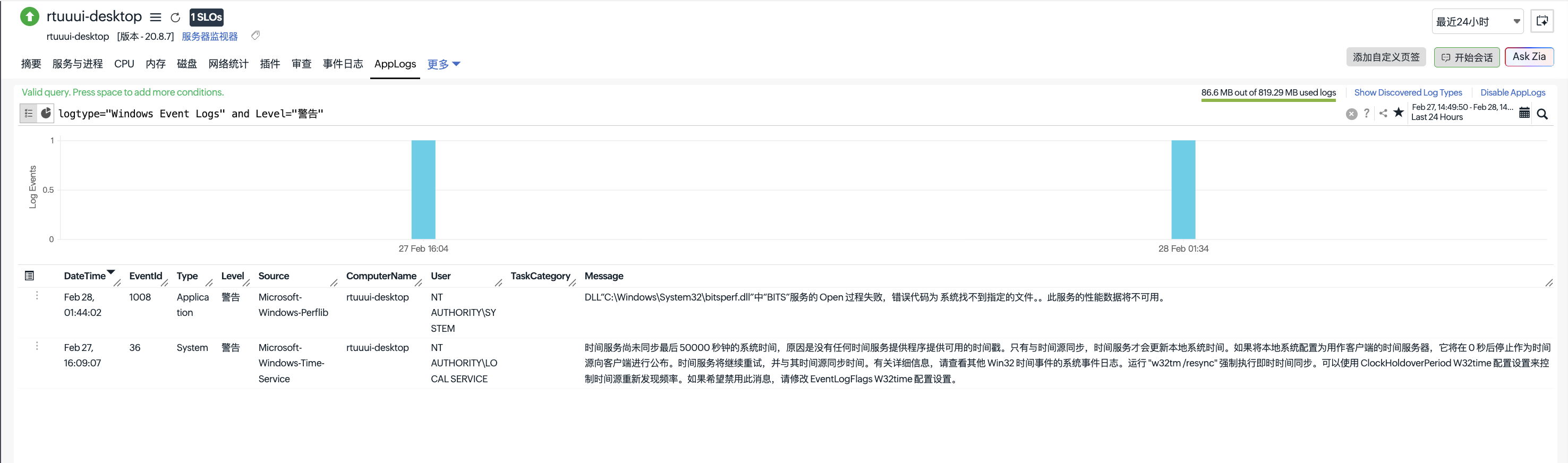
3. 实时可视化与报表
通过图表化展示日志频率,您可以直观地看到系统在特定时段内的异常波动。如果某一时段的“Error”日志数量突然激增,系统会自动标记为异常。
4. 自动化故障响应
Site24x7 不仅能告警,还能行动。您可以配置自动化脚本,当捕获到特定的 Syslog 消息(如某个服务进程意外终止)时,自动执行重启命令或清理缓存脚本,实现真正的“故障自愈”。
六 实施 Syslog 监控的最佳实践
为了充分发挥 Syslog 的威力,建议遵循以下最佳实践:
精简日志输出:避免在生产环境下开启 Debug 级别,这会消耗大量的存储和带宽。
同步系统时间:确保所有设备的网络时间协议(NTP)同步,否则在进行多设备故障关联分析时会遇到麻烦。
定期审查规则:随着应用更新,旧的日志匹配规则可能会失效。建议每季度审查一次告警阈值。
结合全栈监控:不要只看日志。将日志与应用性能(APM)和基础设施指标结合起来,才能获得完整的监控视图。
七 结语
Syslog 是服务器监控中最古老但最有效的技术之一。通过从被动的日志存储转向主动的日志分析,企业可以显著缩短平均修复时间(MTTR),提升系统的弹性。
在数字化竞争日益激烈的今天,利用像 Site24x7 这样智能化的工具来管理 Syslog,不仅是为了解决当下的技术难题,更是为了给业务的持续增长保驾护航。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)