05-文本处理工具
所谓的文本处理工具,就是对文本进行操作的一些命令工具
对文本可以做的操作:
1. 查看文本内容
2. 编辑文本内容
3. 过滤文本内容
总结:过滤文本内容、对文本内容进行编辑、对文本内容进行处理(统计、截取..)
过滤出包含root关键字的行有哪些?
统计root关键字出现的行的数量?
统计Linux系统中可以登录系统的用户有哪些?
截取系统上所有可以登录系统的用户名称?
以后做一些自动化监控脚本的时候,比如监控系统的用户数量、监控系统有哪些用户登录,监控系统SSH
登录的会话数量…
一、文本查看工具
(一)cat命令:一次性查看文本内容
(1)第一个场景:查看文本内容(一次性可以查看一个文件,也可以查看多个文件)
[root@rhel9 ~]# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
(2)第二个场景:cat命令可以整合多个文件为一个新文件
[root@rhel9 ~]# cat /etc/passwd /etc/group > /root/passwd-group
(3)第三个场景:cat命令配合多行输入,创建带有内容的文件
格式:EOF可以自定义,以什么开头就以什么结尾
cat > 文件路径 <<EOF
文件内容
EOF
案例:创建/opt/cat文件,要求文件内容如下,并且是通过cat配合多行输入实现
name=devops
age=30
sex=boy
答:
cat > /opt/cat <<AAA
name=devops
age=30
sex=boy
AAA
cat命令的常用选项
-A 查看文件中的特殊字符
-n 显示行号
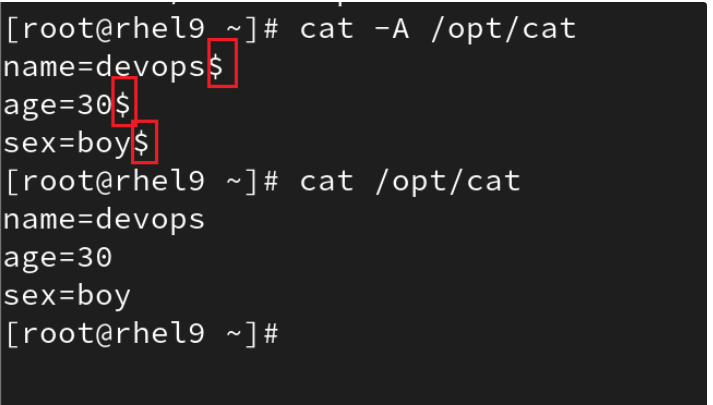
这里的$表示结尾部分
很多人喜欢在windows主机上编写文件内容,然后上传到Linux系统中—>导致文件具有一些特殊字符
比如shell脚本→如果你在windows上写脚本,上传到Linux中,内容肉眼查看是没有问题的,但是无论怎么执行都会报错!
因为上传之后,文件中具备了一些特殊字符,cat命令是看不到的,必须是cat -A才能看到
二、more命令分页查看文本内容
因为cat命令在读取的时候,会将内容全部读取一遍,如果文件比较大的话,会卡顿而且会消耗服务器的资源。此时需要一个既可以查看文本内容的命令工具,也可以有效的提高查看效率,也可可以减少性能消耗。more命令出来了,只会加载看到部分内容,还没有查看到的内容不会加载(而cat命令直接全部读取加载出来)。如果more命令把一个文件内容查看完了,more会自动退出
格式:more 文件
三、less命令分页查看文本内容
more命令有的,less命令也有,并且再此基础之上改进了
1. 分页查询,看多少加载多少,不会一上来就全部加载(解决了cat的难点)
2. 一页的一页的查询,也可以一行一行的查询(解决了more无法一行一行的查看的难点)
1. ctrl b 向下翻页
2. ctrl f 向上翻页
3. 查看的过程可以通过v命令,切换到vim编辑器
4. 查看的过程中可以通过 / 或者 ? 进行关键字的过滤(过滤的时候建议从第一行开始过滤,不要翻页到后面过滤。因为它不像vim编辑器那样,vim编辑器过滤的时候,过滤到末尾的时候,下一次过滤会重新从开始,而less不会)
四、head/tail
(一)head命令:默认查看文件的头10行内容,也可以通过选项查看指定头N行内容
[root@rhel9 ~]# head /etc/passwd | cat -n
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
常用选项:
-n 查看指定的行数
-n 3 和 -n +3 都是表示查看文件的头3行内容
-n -3 去掉末尾3行,其他全部查看
[root@rhel9 ~]# head -n 3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@rhel9 ~]# head -n +3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
(二)tail命令:默认查看文件的末尾10行内容,也可以通过选项查看指定末尾N行内容
[root@rhel9 ~]# tail /etc/passwd | cat -n
1 zhangsan:x:1003:1005::/home/zhangsan:/bin/bash
2 lisi::1004:1006::/home/lisi:/bin/bash
3 developer:x:1005:1007::/home/developer:/bin/bash
4 memeda01:x:2027:2027::/home/memeda01:/bin/bash
5 demotest:x:2028:2028::/home/demotest:/bin/bash
6 ituser1:x:2029:2029::/home/ituser1:/bin/bash
7 user1:x:2030:2031::/home/user1:/bin/bash
8 user2:x:2031:2032::/home/user2:/bin/bash
9 bob:x:2032:2033::/home/bob:/bin/bash
10 ddddduser:x:2033:2034:test dddduser:/home/ddddduser:/bin/bash
常用选项:
-n 指定行数
-n +3 从第3行开始查看
-n 3 和 -n -3 表示查看末尾3行
-f 实时监控文件的追加情况-->使用排错情况,根据日志文件的信息进行排错
举例:某天你发现启动sshd服务失败了,怎么排错?
1. 开俩窗口,左边一个 右边一个
2. 左边的窗口通过tail -f命令实时监控日志文件的追加情况
3. 右边的窗口去执行启动sshd服务
课后习题:请你通过head命令和tail命令查看/etc/passwd文件的第5行内容到第12行内容
head -n 最大行 /etc/passwd | tail -n +最小行
五、grep命令根据关键字过滤关键字所在的行
(一)grep文本过滤工具:根据用户写的关键字,过滤关键字所在的行
语法格式:
grep [选项] 关键字 文件
常用选项:
-v 取反,不匹配关键字所在的行,其他的都打印输出
grep -v '/bin/bash' /etc/passwd -->不过滤可以登录系统的用户,也就是说将所有不可以登录系统的用户信息的打印出出来
-i 忽略关键字的大小写
-o 打印关键字内容,不会打印关键字所在的行
-c 统计关键字出现的行的次数
-q 不输出过滤出来的信息,通常应用在脚本中
通过$?来判断是否过滤出来
$? 返回值是0 过滤出来的
$? 返回值为非0 没有过滤出来
-Ax 将匹配行以及其后x行打印
-Bx 将匹配行以及其前x行打印
-Cx 将匹配行以及其前后x行打印
以上3个选项,在过滤的时候常用。比如过滤日志文件中信息,排错的话你肯定是过滤fail或者error这样的关键字,得到关键字所在的行
-r 根据关键字,查看关键字所在的文件-->过滤文件的,比如你不知道文件名是什么,但是你知道文件的内容关键字
SELINUX工作模式-->但是我不知道是哪个配置文件,但是我知道文件的内容一定有SELINUX关键字
-r通常和-l配合使用,-l表示过滤关键字的文件名字
过滤网页文件
--color=auto 显示关键字的颜色高亮
(二)正则表达式
所谓的正则表达式,就是通过不同的元字符实现不同规律的过滤
比如:过滤出以某某某关键字结果的行,借助$元字符
比如:过滤出以root关键字开头的行,借助^元字符
难点在于元字符比较多,学习起来的时候其实学的就是元字符的使用
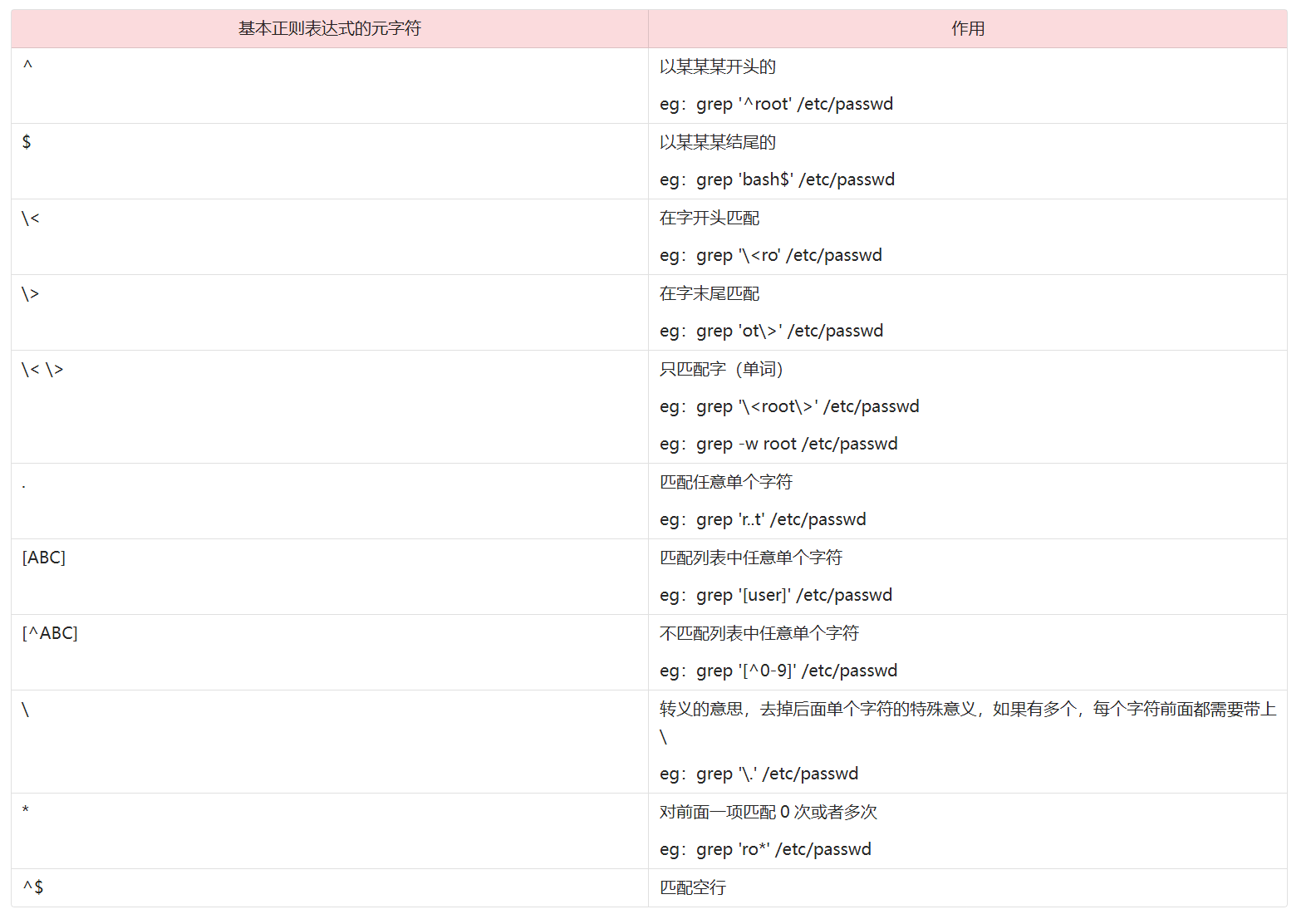
对于Linux系统来说,字(单词)的组成是数字、下划线、字母组成的
(三)扩展正则表达式
支持的元字符包含基本正则元字符,同时也支持更多的元字符。
grerp -E 或者 egrep
综合实战:要求你通过grep命令以及正则表达式,过滤出当前操作系统除了lo网卡之外的所有网卡的ipv4
地址
[root@rhel9 ~]# ifconfig | grep netmask | grep -E '([0-9]{1,3}\.){3}[0-9]{1,3}' -o | grep -Ev '^255|255$|^127'
20.0.0.130
20.0.0.131
六、文本截取工具
所谓的截取:指的就是截取字符串、截取某一列
(一)cut截取字符串或者截取列(字段)
数据库中 关系型数据库:分为列和行的
列 字段
行 记录(数据)
案例需求一:截取当前Linux系统上所有可以登录的系统用户名称,将其保存到/opt/login-user文件中
[root@rhel9 ~]# grep '/bin/bash$' /etc/passwd | cut -d: -f1 > /opt/login-user
[root@rhel9 ~]# cat /opt/login-user root devops
root
devops
ituser
ctuser
解读 cut -d: -f1
-d 指定分隔符
-f 指定列
-f1 提取第1列
-f1,6 提取第1列和第6列
-f1-6 提取第1和到第6列
-c 提取字符
-c1 提取第1个字符
-c1,4 提取第1个和第4个字符
-c1-4 提取第1个到第4个字符
案例二:通过cut命令提取网卡的ipv4地址
[root@rhel9 ~]# ifconfig ens160 | grep netmask | cut -d ' ' -f10
20.0.0.130
七、文本分析工具
[root@rhel9 ~]# lastb | cut -d ' ' -f 1 | head -n -2 |sort | uniq -c
1 abc
3 devops
1 memeda
1 root
1 user
(一)sort命令 排序/去重
sort命令默认是根据字符标进行排序,先比较第1 个字符,如果是一样的,则比较第2个,以此类推
常用选项:
-n 根据数字排序
-r 倒序,默认是升序
-t 指定分隔符
-k 指定列
-u 去掉重复的行
如果根据用户的UID大小进行排序,要求你排序的时候,UID最小的那个用户信息排序到第一行,UID最大
的那个用户信息排序到最后一行
[root@rhel9 ~]# sort -t: -k3 -n passwd | cut -d: -f3
sort去重,去掉的是重复的行内容,只有当多行内容是一模一样的,才能进行去重操作
[root@rhel9 ~]# sort -u file
123
456
abc
sort命令在排序或者去重的时候,对原文件是不会操作的
(二)uniq命令去重
去重,也可以统计重复行的次数
uniq进行去重,只能去掉相邻重复的行,如果不是相邻的则无法去重
如果要去掉不相邻重复的行,则需要借助sort命令先排序,然后再进行去重
[root@rhel9 ~]# sort file | uniq
123
456
abc
[root@rhel9 ~]# sort file
123
456
abc
abc
[root@rhel9 ~]# sort file | uniq -c
1 123
1 456
2 abc
(三)wc 命令 统计行数
统计文件的行数→wc命令
统计其他的数量→wc命令
wc:统计行数 字符数量 字节数
wc -l 统计行数
wc做统计的时候,通常是统计文件的数量,而不是文件内容的行数
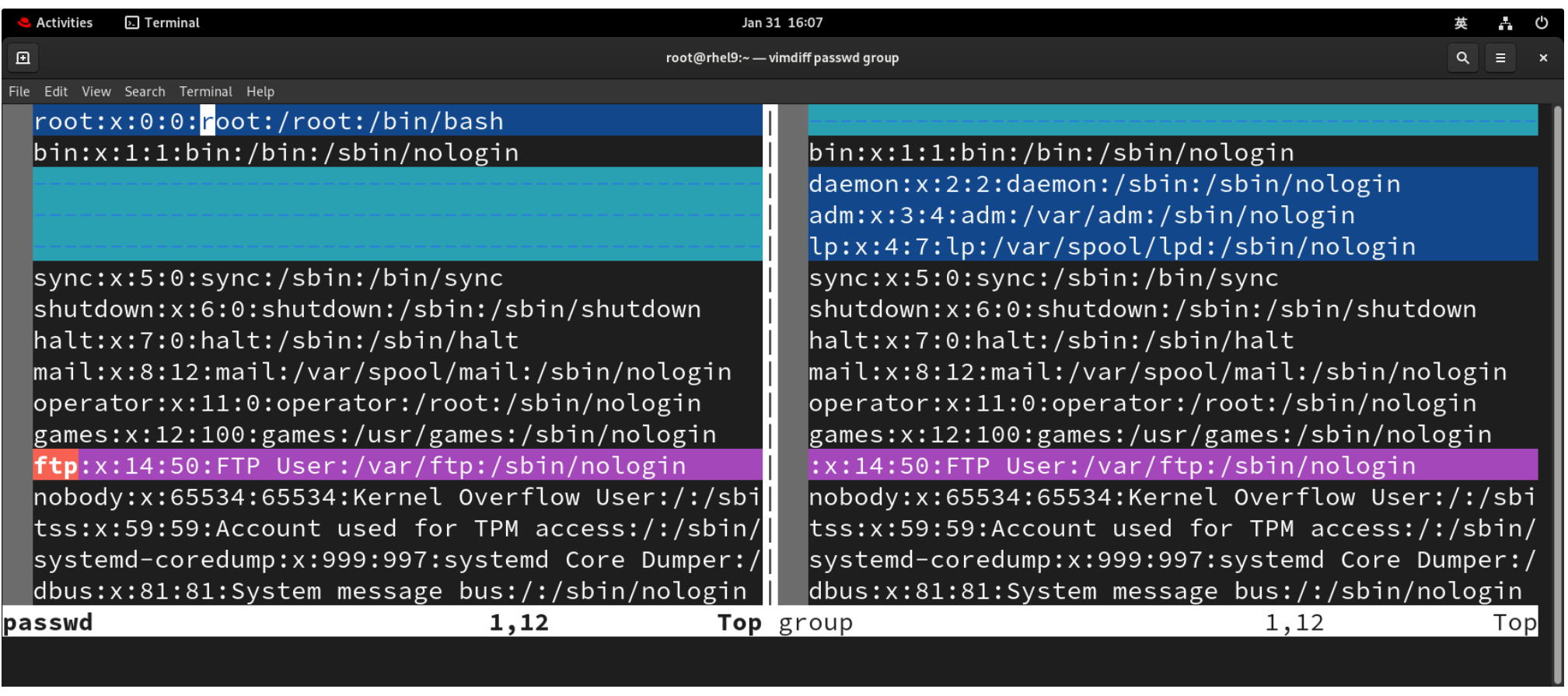
(四)文本比较工具
对比多个文件之间的差异性
- diff:不建议直接使用,一般是简单判断文件是否被修改了
- vimdiff:带有颜色高亮的比较工具,会进入到vim编辑器中
(五)文本编辑工具
sed和vim作用是一样的,都是用来进行文件内容操作的,比如编辑内容、删除内容、新增内容等
vim和sed之间最大的区别在于:
vim是一个交互式的编辑工具
sed是非交互式的编辑工具
所以sed命令工具在自动化脚本中最为场景,只要脚本中涉及到文件内容的编辑,一定用的是sed而不是vim
sed:流编辑器(Stream Edit)处理文件内容的时候,从上往下一行一行的依次处理
sed如何处理一个文件的:sed '1p' /etc/passwd
[root@rhel9 ~]# sed '1p' passwd
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
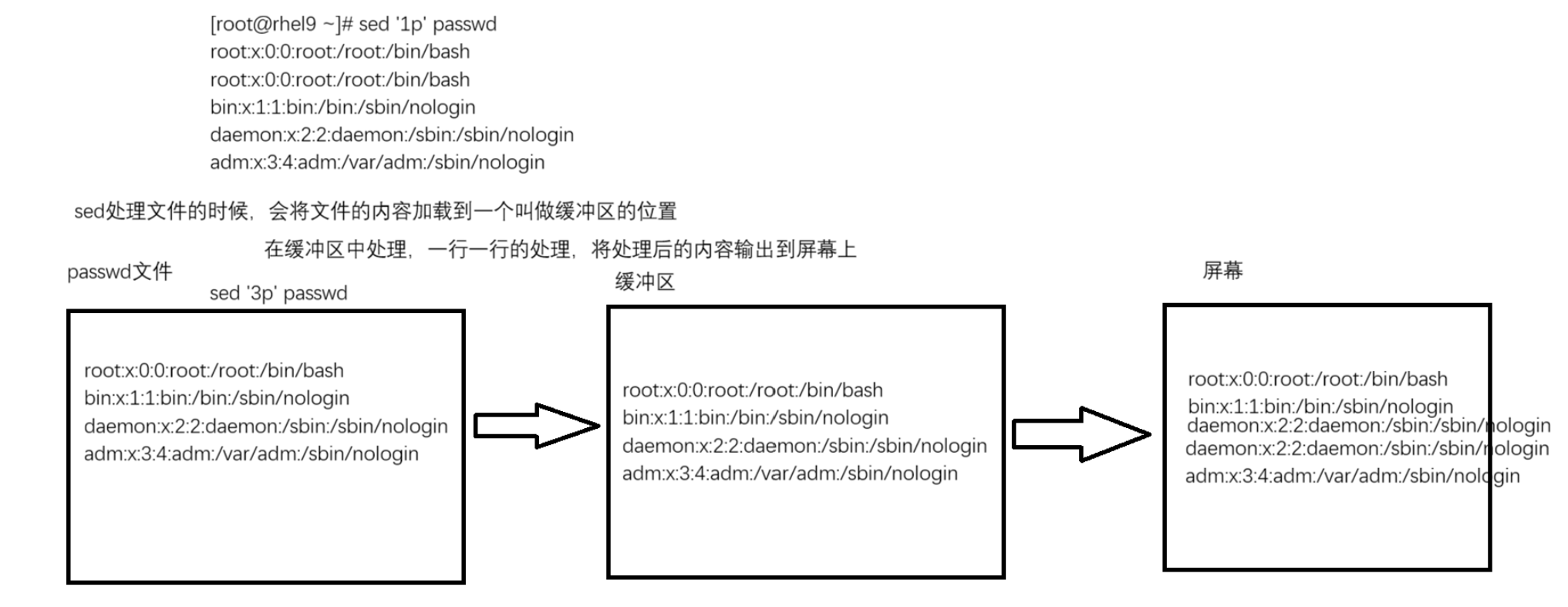
默认情况下,缓冲区的内容是会显示到屏幕上的,如果想要隐藏,可以借助-n选项不输出缓冲区(模式空间)的内容
sed无论是打印、删除、编辑文件,原文件都不会发生改变,因为sed处理这些内容的时候处理的是缓冲区的内容,可以借助-i选项来操作原文件
如果通过sed命令处理文件的时候,没有指定是第几行,那么默认会对所有行操作
语法格式:sed [选项] '地址定界 处理动作' 文件
常用选项:
-n 不输出缓冲区的内容(模式空间)
-i 对原文件做操作
-e 同时接多个 地址定界/处理动作
-r 支持扩展正则,默认是支持基本正则的
(一)地址定界:告诉sed要处理哪一行或者哪几行
#基于数字,直接选择操作第几行,选择要处理的指定行的范围
sed '1p' passwd: 1表示处理第1行
sed '5,12p' /etc/passwd -n:5,12表示处理第5行到第12行
sed '$p' /etc/passwd -n $p表示文本的最后一行,$是一个变量。
#基于关键字过滤,处理关键字所在的行
sed '/root/p' passwd -n:'/root/p',/root/就是要匹配的关键字所在的行
sed '/^bin/,/daemon/p' passwd -n
#基于关键字过滤,忽略关键字大小写
sed '/root/Ip' passwd -n
#基于关键字过滤,使用其他的字符代替/
sed '\%/bin%p' passwd -n
#基于数字和关键字过滤联合匹配
sed '1,/daemon/p' passwd -n:从第1行开始匹配,一直到匹配到第一个daemon关键字所在的行截止
sed '/daemon/,5p' passwd -n:从第一个匹配到daemon关键字所在行开始,一直到第5行结束匹配
(二)处理动作:对匹配到的行做什么操作
- 删除匹配的行:d
- 打印:p
(1)在匹配的行的后面一行新增:a\
#在/etc/ssh/sshd_config配置文件中的#Port 22这一行后面新增Port 2222
sed -i.bak '/#Port 22/a\Port 2222' /etc/ssh/sshd_config
(2)在匹配的行的前面一行新增:i\
#在/etc/ssh/sshd_config配置文件中的#Port 22这一行前面新增Port 2222
sed -i.bak '/#Port 22/i\Port 8888' /etc/ssh/sshd_config
(3)替换匹配的行的内容:c\
#替换/etc/selinux/config中的SELINUX=enforcing
sed '/^SELINUX=/c\SELINUX=disabled' /etc/selinux/config -i
(4)替换关键字:s/要替换的关键字/替换后的关键字/特性
sed 's/disabled/enforcing/' /etc/selinux/config -i.bak
sed 's/disabled/enforcing/g' /etc/selinux/config -i.bak
g表示全局替换,默认只会替换每一行第一个匹配到的关键字
sed 's#disabled#enforcing#g' /etc/selinux/config -i
sed 's/disabled/enforcing/i' /etc/selinux/config -i.bak
i表示忽略关键字的大小写

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)