[AI问答]DPDK lcore(逻辑核心)技术原理与实现详解
EAL 是 DPDK 的环境抽象层,负责屏蔽操作系统差异,提供统一的 CPU、内存、设备管理接口。CPU 拓扑探测:读取获取物理核、逻辑核、Socket 信息线程生命周期管理:创建 pthread、设置 CPU 亲和性、启动任务循环任务分发调度:通过回调函数机制将业务逻辑分发到指定 lcore机制实现方式性能影响线程创建一次性开销,运行时零调度任务分发回调函数注册到函数指针调用,< 10ns 延迟
DPDK lcore(逻辑核心)技术原理与实现详解
一、核心概念与设计哲学
lcore(Logical Core) 是 DPDK 对物理 CPU 核心的抽象,本质上是强制绑定到指定物理核的 pthread 线程。这种设计通过以下机制实现极致性能:
- 消除跨核调度:线程一旦绑定,内核调度器无法将其迁移到其他核心,避免上下文切换和缓存失效
- 零中断轮询:每个 lcore 运行一个死循环,主动轮询处理数据包,绕过内核中断和协议栈
- NUMA 感知:内存分配与 lcore 所在物理核的 NUMA 节点绑定,减少跨节点访问延迟
与传统线程不同,lcore 不是抢占式调度对象,而是独占 CPU 资源的执行单元,其设计目标是最大化数据平面吞吐量 。
二、实现架构与关键组件
2.1 EAL(Environment Abstraction Layer)角色
EAL 是 DPDK 的环境抽象层,负责屏蔽操作系统差异,提供统一的 CPU、内存、设备管理接口。在 lcore 管理中,EAL 承担以下职责:
- CPU 拓扑探测:读取
/sys/devices/system/cpu/获取物理核、逻辑核、Socket 信息 - 线程生命周期管理:创建 pthread、设置 CPU 亲和性、启动任务循环
- 任务分发调度:通过回调函数机制将业务逻辑分发到指定 lcore
2.2 核心数据结构
// 每个 lcore 的配置信息存储在全局数组 lcore_config[] 中
struct lcore_config {
pthread_t thread_id; // pthread 句柄
rte_lcore_function_t *f; // 回调函数指针
void *arg; // 函数参数
volatile enum rte_lcore_state_t state; // 线程状态
// ... 其他字段
};
2.3 线程本地存储(TLS)
每个 EAL pthread 维护一个 TLS 变量 _lcore_id,用于标识当前线程的逻辑核 ID。默认情况下,_lcore_id 等于物理 CPU ID,实现 1:1 绑定 。
三、初始化与启动流程
3.1 启动阶段(以 DPDK 程序为例)
./build/app/testpmd -c 0x3f -- -i # -c 参数指定 coremask(bitmask)
Step 1:CPU 拓扑检测
rte_eal_cpu_init(); // 读取 /sys/devices/system/cpu/cpuX/
- 解析
/sys/devices/system/cpu/cpuN/topology/获取核心层级关系 - 识别 NUMA 节点,建立核心到 Socket 的映射
Step 2:参数解析与核掩码处理
eal_parse_args(argc, argv); // 解析 -c 或 --lcores 参数
- 将十六进制 coremask(如
0x3f)转换为二进制位图(00111111) - 第一个被设置的核自动成为 MASTER 核,其余为 SLAVE 核
Step 3:线程创建与亲和性绑定
// 为每个 SLAVE 核创建线程
pthread_create(&lcore_config[lcore_id].thread_id, NULL,
eal_thread_loop, &lcore_config[lcore_id]);
// 立即设置 CPU 亲和性(关键步骤)
eal_thread_set_affinity(); // 内部调用 pthread_setaffinity_np(tid, sizeof(rte_cpuset_t), cpusetp);
pthread_setaffinity_np()是 Linux 非标准扩展,将线程绑定到指定 CPU- 绑定操作在 线程启动后立刻执行,确保线程从第一次调度开始就运行在目标核心
Step 4:任务循环启动
void *eal_thread_loop(void *arg) {
while (1) {
// 等待任务派发或执行已注册回调
if (lcore_config[lcore_id].f != NULL) {
lcore_config[lcore_id].f(lcore_config[lcore_id].arg);
}
// 无任务时挂起,避免空转耗电
rte_pause();
}
}
四、CPU 绑定机制深度解析
4.1 底层实现原理
// 伪代码:eal_thread_set_affinity 核心逻辑
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(cpu_id, &cpuset); // 将目标核加入 CPU 集合
pthread_setaffinity_np(thread_id, sizeof(cpu_set_t), &cpuset);
cpu_set_t:内核提供的位图结构,每个 bit 代表一个 CPUCPU_SET():将目标核置位,允许线程仅在该核运行- 绑定后,内核调度器无法在未经 DPDK 允许的情况下迁移线程
4.2 绑定时机与内存分配
- HugePage 预分配:在 lcore 创建前,EAL 已预留好大页内存
- NUMA 对齐:内存分配通过
rte_malloc_socket()确保与 lcore 所在 Socket 一致 - 缓存预热:线程绑定后首次访问内存,触发 Page Fault,建立 TLB 映射,后续访问零开销
五、任务分发与执行模型
5.1 Master/Slave 架构
| 角色 | 职责 | 绑定策略 |
|---|---|---|
| MASTER 核 | 初始化配置、管理控制平面、响应用户输入 | 通常分配 1 个核心 |
| SLAVE 核 | 数据包处理、转发、加密等数据平面任务 | 每个核心运行独立 lcore |
任务注册机制:
// 用户代码注册回调函数到指定 lcore
rte_eal_remote_launch(l2fwd_launch_one_lcore, // 回调函数
NULL, // 参数
lcore_id); // 目标 lcore ID
- 函数将任务写入
lcore_config[lcore_id].f - 目标 lcore 在下次循环时执行该函数
5.2 多核并行启动流程
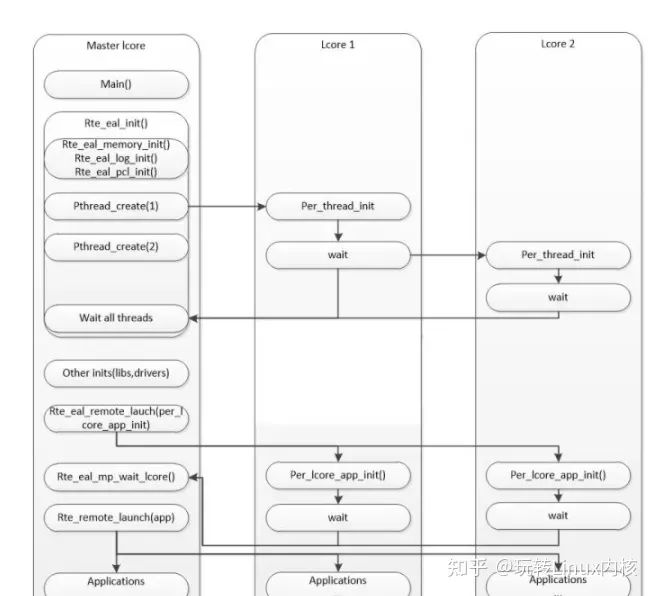
六、高级特性:灵活绑定(Flexible Affinity)
默认 1:1 绑定牺牲灵活性,DPDK 提供 --lcores 参数实现 M:N 映射 :
6.1 参数语法
--lcores='<lcore_set>[@cpu_set][,<lcore_set>[@cpu_set],...]'
lcore_set:逻辑核 ID(如1,2或(3-5))cpu_set:物理核集合(如@(0,2))- 省略
@cpu_set时,默认 1:1 绑定
6.2 复杂示例解析
--lcores='1,2@(5-7),(3-5)@(0,2),(0,6),7-8'
| lcore ID | 绑定物理核 | 说明 |
|---|---|---|
| lcore 1 | CPU 1 | 单核绑定 |
| lcore 2 | CPU 5,6,7 | 可在 5-7 间浮动(内核调度) |
| lcore 3,4,5 | CPU 0,2 | 3 个 lcore 共享 2 个物理核 |
| lcore 0,6 | CPU 0,6 | 每个 lcore 绑定双核 |
| lcore 7,8 | CPU 7,8 | 范围绑定 |
应用场景:
- 流量潮汐:低负载时减少活跃物理核,节能降耗
- 多租户隔离:不同租户 lcore 绑定到不同 CPU 集合
- 超线程利用:将两个 lcore 绑定到同一物理核的超线程上
七、性能优化原理
7.1 缓存亲和性(Cache Affinity)
- L1/L2 缓存私有:每个物理核有独立缓存,跨核迁移导致缓存失效
- 数据局部性:lcore 处理的数据始终位于本地 NUMA 节点,延迟 < 100ns
- 伪共享避免:DPDK 数据结构按缓存行对齐,防止多核竞争
7.2 TLB 效率提升
- HugePage 集成:lcore 使用 1GB/2MB 大页,TLB Miss 减少 99%
- 页表锁定:线程绑定后页表项不会被回收,地址转换零开销
7.3 上下文切换消除
- 无调度延迟:lcore 不触发内核调度,不存在
schedule()开销 - 中断隔离:数据核通过
isolcpus内核参数屏蔽中断,CPU 100% 用户态运行
7.4 轮询模式优势
// 与中断模式对比
// 中断模式:被动等待,上下文切换开销 > 5μs
// DPDK 轮询:主动查询,延迟 < 1μs
while (!quit) {
pkts = rte_eth_rx_burst(port, queue, pkts, 32); // 批量接收
process(pkts);
}
八、典型应用模式与最佳实践
8.1 数据面线程(Data Plane lcore)
// 绑定到独立物理核,隔离性最强
--lcores='1-15@1-15' # 16 核系统,lcore 1-15 独占 CPU 1-15
- 处理网络 I/O、加密、转发
- 禁用中断,避免任何内核干扰
- 内存分配严格 NUMA 对齐
8.2 控制面线程(Control Plane lcore)
// 绑定到 MASTER 核,处理慢路径
--lcores='0@0' # lcore 0 绑定 CPU 0
- 响应 CLI 命令、配置下发
- 不参与高速数据转发
- 允许内核调度,可使用系统调用
8.3 混合部署策略
# 生产环境推荐配置
isolcpus=2-15 # 内核不调度到这些核
--lcores='0@0,1@1,2-15@2-15' # MASTER 在 CPU0,控制面在 CPU1,数据面独占其余核
- 主核 (CPU 0):运行 Linux 内核、管理进程
- 控制核 (CPU 1):运行 DPDK MASTER lcore,处理控制信令
- 数据核 (CPU 2-15):运行 SLAVE lcore,100% 轮询转发
九、实现细节总结
| 机制 | 实现方式 | 性能影响 |
|---|---|---|
| 线程创建 | pthread_create() + pthread_setaffinity_np() |
一次性开销,运行时零调度 |
| 任务分发 | 回调函数注册到 lcore_config[].f |
函数指针调用,< 10ns 延迟 |
| 状态同步 | TLS (_lcore_id) + 无锁环形队列 |
无锁并发,线性扩展 |
| 内存访问 | HugePage + NUMA 本地分配 | TLB Miss 减少 99% |
通过上述机制,DPDK 将通用 CPU 改造为专用数据包处理引擎,单核性能可达 100 Mpps 以上,延迟低于 5μs,成为 NFV、5G UPF 等高性能网络应用的事实标准 。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)