Spring AI 系列之读懂大模型核心概念
Embedding是将文本、图像等数据转换为高维向量的技术。语义相似的文本在向量空间中距离更近。示例“这个多少钱” ↔ “这个什么价格”(距离近,语义相似)“我想要这个” ↔ “这个给我吧”(距离近,语义相似)技术方向核心要点大模型选择根据场景选择通用模型(GPT-4o/DeepSeek)或垂直模型(Claude/星火)Prompt工程明确目标、提供上下文、使用CoT提升推理能力RAG架构结合向量
🚀 Spring AI 入门:一文读懂大模型核心概念
从LLM到RAG,图解人工智能关键技术
一、大语言模型(LLM)发展全景
大语言模型(Large Language Model,LLM)是当今人工智能领域的核心技术。从2018年的GPT-1到2025年的GPT-4.5,参数规模从1.17亿暴增至18万亿,能力呈指数级增长。
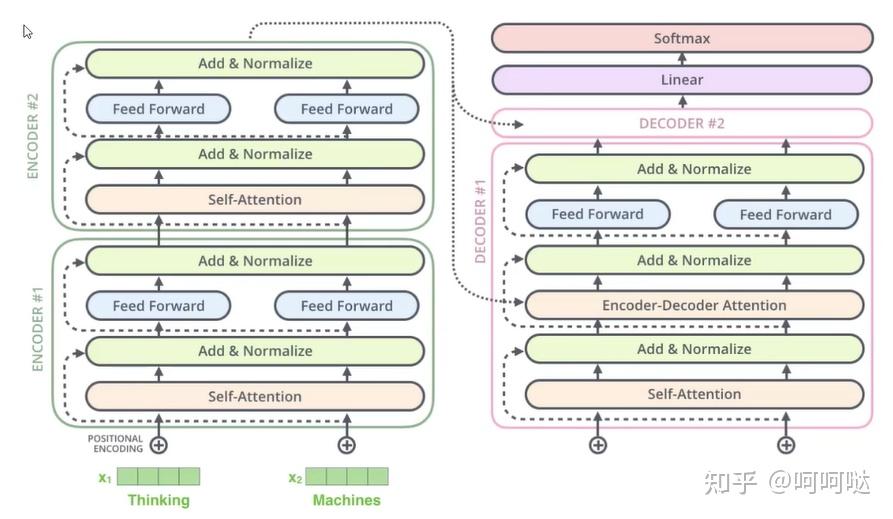
主流模型对比
| 类别 | 代表模型 | 研发公司 | 核心亮点 | 典型场景 |
|---|---|---|---|---|
| 通用大模型 | GPT-4o | OpenAI | 全模态交互,128k上下文 | 科研、创意产业 |
| Gemini 2.0 Pro | 实时搜索,20种语言切换 | 教育、企业服务 | ||
| DeepSeek-R1 | 深度求索 | 开源可商用,成本仅国际模型1/10 | 工业优化、全球化部署 | |
| 垂直领域模型 | Claude 3 Opus | Anthropic | 200k超长上下文,误判率<0.1% | 法律合规、医疗审查 |
| 星火X1 | 科大讯飞 | 中文数学能力国内第一 | 医疗诊断、教育解题 |
二、核心技术储备:构建AI知识体系
要掌握大模型技术,需要具备以下知识基础:
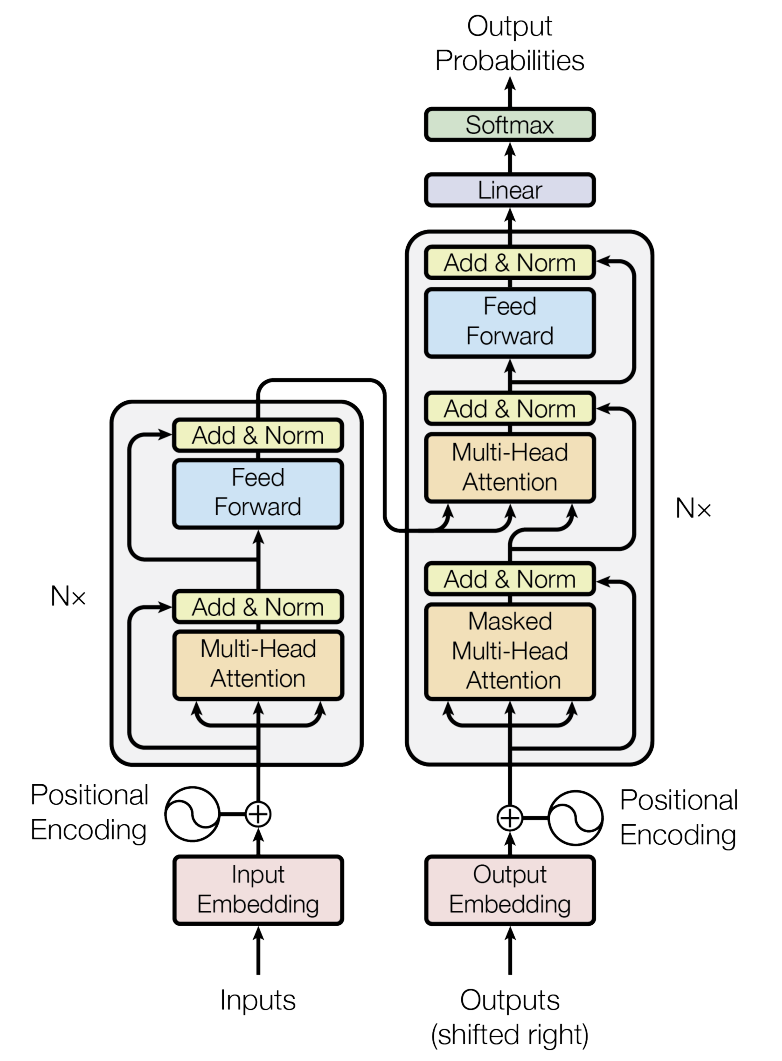
关键技术模块
- 基础架构:Transformer、BERT、GPT、MoE(混合专家模型)
- 神经网络:浅层/深层神经网络、向量数据库、Embeddings
- 机器学习:深度学习、强化学习、无监督/有监督学习
- NLP技术:自然语言处理(NLP)、自然语言理解(NLU)、自然语言生成(NLG)
三、Prompt Engineering:与大模型对话的艺术
Prompt Engineering是设计和优化输入提示以获得预期输出的过程。以下是核心技巧:
1. 基础原则
| 原则 | 说明 | 示例 |
|---|---|---|
| 明确目标 | 清晰描述任务 | “告诉我关于气候变化的事情” → “简要描述气候变化的主要原因及其对农业的影响” |
| 提供上下文 | 给模型必要的背景 | “作为一名高中生,请用简单语言解释微积分基本概念” |
| 使用具体指示 | 避免模糊不清 | “写一篇关于技术的文章” → “写一篇关于AI在医疗领域应用的文章,包含应用场景、优势和挑战” |
2. 进阶技巧:思维链(Chain of Thought)
零样本提示(Zero-shot):直接提问,不提供示例
少样本提示(Few-shot):提供2-3个示例,引导模型理解任务模式
思维链提示(CoT):要求模型"让我们逐步思考",显著提升推理准确性
示例对比:
普通提示:
"我去市场买了10个苹果。我给邻居2个苹果和修理工2个苹果。
然后我去买了5个苹果并吃了1个。我还剩下多少苹果?"
输出:11个苹果(错误)
CoT提示:
"我去市场买了10个苹果...我还剩下多少苹果?让我们逐步思考。"
输出:
首先,您从10个苹果开始。
您给了邻居和修理工各2个苹果,所以您还剩下6个苹果。
然后您买了5个苹果,所以现在您有11个苹果。
最后,您吃了1个苹果,所以您还剩下10个苹果。(正确)
四、RAG:检索增强生成技术详解
RAG(Retrieval-Augmented Generation)是当前企业级AI应用的核心技术,它通过检索外部数据来增强大模型的生成效果。
4.1 为什么需要RAG?
大模型存在以下局限:
- 知识截止:无法获取训练数据之后的信息
- 幻觉问题:可能生成看似合理但实际错误的内容
- 领域知识不足:对专业领域理解有限
4.2 RAG工作原理
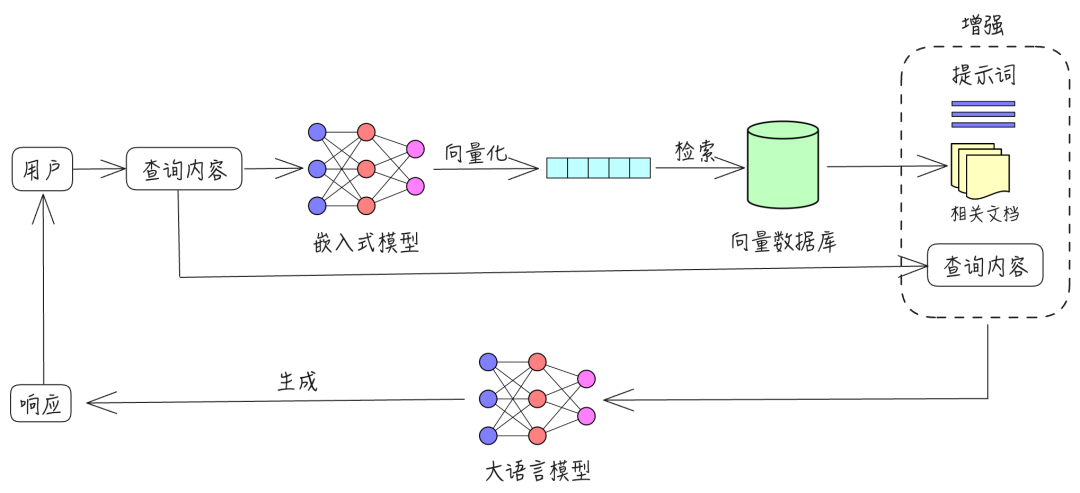
核心流程:
- 索引(Indexing):将文档分割成chunks,通过Embedding模型转换为向量,存入向量数据库
- 检索(Retrieval):用户查询向量化,匹配向量库中最相似的Top-K chunks
- 生成(Generation):将检索到的上下文与用户问题组合,提交给LLM生成回答
4.3 RAG vs 微调(Fine-tuning)
| 维度 | RAG(检索增强) | Fine-tuning(微调) |
|---|---|---|
| 类比 | 毕业后做老总,配备业务负责人辅助决策 | 毕业后系统学习7年医学,成为专业医生 |
| 知识更新 | 实时检索,永远最新 | 依赖训练数据,需要重新训练 |
| 成本 | 较低,只需维护知识库 | 较高,需要大量计算资源 |
| 适用场景 | 需要最新数据、多领域知识 | 特定领域深度优化 |
五、向量数据库与Embedding技术
5.1 什么是Embedding?
Embedding是将文本、图像等数据转换为高维向量的技术。语义相似的文本在向量空间中距离更近。
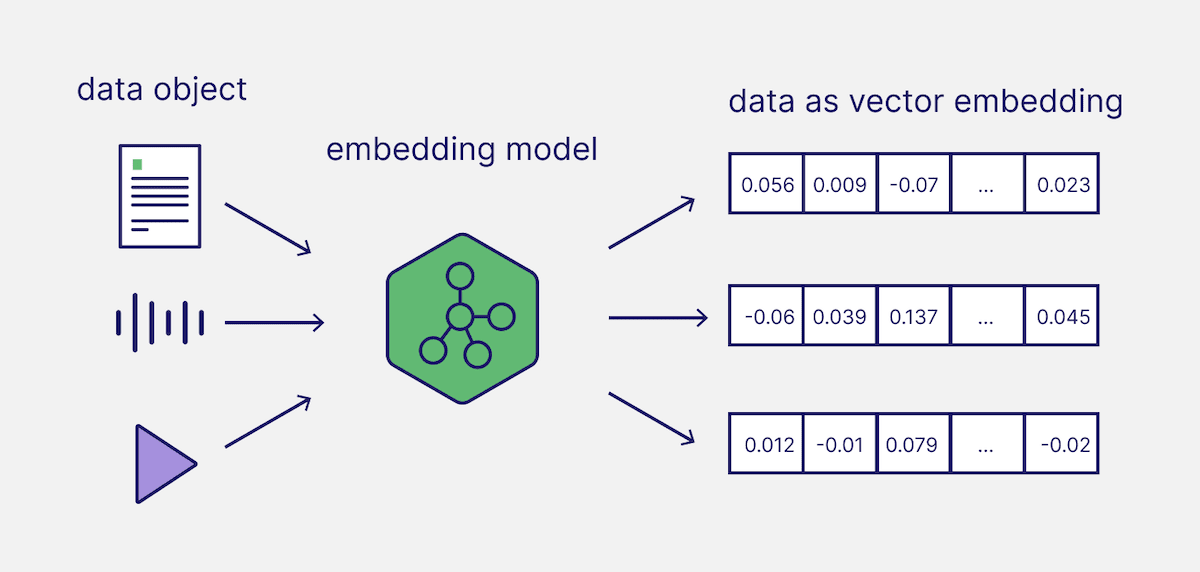
示例:
- “这个多少钱” ↔ “这个什么价格”(距离近,语义相似)
- “我想要这个” ↔ “这个给我吧”(距离近,语义相似)
5.2 向量相似度计算
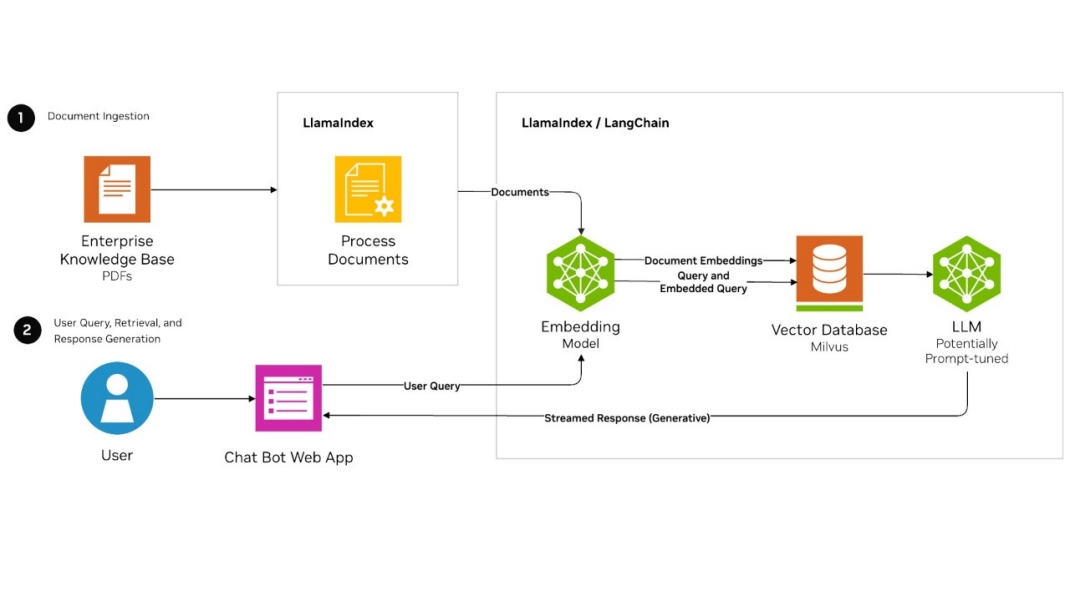
- 余弦相似度:衡量向量夹角,值越大越相似(范围[-1,1])
- 欧氏距离:衡量空间直线距离,值越小越相似
5.3 文档分割策略
RAG系统需要将长文档切分为chunks,常用方法:
| 方法 | 说明 | 适用场景 |
|---|---|---|
| 按句子切分 | 以。?!等标点分割 | 保持语义完整性 |
| 固定字符数 | 每N个字符切分 | 简单快速 |
| 滑动窗口 | 固定长度+重叠区域 | 保持上下文连贯 |
| 递归切分 | 优先按段落→句子→字符 | 推荐方案,平衡效果 |
六、实战:Java调用大模型API
使用Spring AI可以通过简单的Java代码实现与大模型交互:
// 构建HTTP客户端
OkHttpClient client = new OkHttpClient().newBuilder()
.connectTimeout(20, TimeUnit.SECONDS)
.readTimeout(20, TimeUnit.SECONDS)
.build();
// 构建请求体
String json = String.format("""
{
"model": "%s",
"messages": [{"role": "user", "content": "%s"}]
}
""", model, prompt);
RequestBody body = RequestBody.create(
MediaType.parse("application/json"), json);
// 发送请求
Request request = new Request.Builder()
.url("https://api.deepseek.com/v1/chat/completions")
.method("POST", body)
.addHeader("Authorization", "Bearer " + API_KEY)
.build();
Response response = client.newCall(request).execute();
七、总结与展望
| 技术方向 | 核心要点 |
|---|---|
| 大模型选择 | 根据场景选择通用模型(GPT-4o/DeepSeek)或垂直模型(Claude/星火) |
| Prompt工程 | 明确目标、提供上下文、使用CoT提升推理能力 |
| RAG架构 | 结合向量检索+大模型生成,解决知识更新和幻觉问题 |
| Embedding | 将语义转化为数学向量,实现高效相似度检索 |
随着DeepSeek-R1等开源模型的崛起,AI技术门槛正在快速降低。掌握这些核心概念,将帮助你在Spring AI开发中游刃有余,构建出更智能、更可靠的企业级应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)