【AI也有“开卷考试”?揭秘RAG如何让模型更聪明】
就是把长文档切成小块。比如一篇5000字的产品说明书,切成10段,每段500字。产品名价格库存手机2999100电脑599950[0.23, -0.56, 0.89, ...] ← 这是"本产品保修期为一年"[0.21, -0.52, 0.91, ...] ← 这是"一年内免费维修"[0.90, 0.10, 0.10, ...] ← 这是"产品颜色有红色蓝色"缺点简单说怎么办切断关系一句话被切成几

目录
1. 先说说大模型的"幻觉"问题
1.1 你遇到过这种情况吗?
假设你在做一个旅游APP的项目,有一份产品需求文档。遇到问题时,你去问AI助手:
你问:“这个APP的支付功能对接哪家服务商?”
AI回答:“建议对接微信支付和支付宝,同时可以考虑PayPal作为备选…”(说得头头是道)
但问题是:这份需求文档是公司内部刚写完的,AI根本没见过!它只是在"编造"一个听起来合理的答案。
这就是大模型的幻觉——当AI不知道答案时,它不会说"我不知道",而是会自己编一个。
1.2 为什么会有幻觉?
| 原因 | 简单解释 |
|---|---|
| 知识截止日期 | AI只学到训练时的知识,新知识不知道 |
| 不懂"不知道" | AI被训练成"必须回答",不会说不知道 |
| 数据没看过 | 你的私有文档、公司资料,AI根本没见过 |
1.3 那怎么办?
你可能会想:那把文档和问题一起发给AI不就行了?
这个方法确实有效,但新问题来了:
- 文档太长怎么办? AI有字数限制,比如一次只能看4000字
- 太贵了怎么办? 大模型按字数收费,发整本书钱包受不了
- 找不着重点怎么办? 答案可能就藏在某一小段,给整篇AI反而看花眼
于是有人想:能不能只把相关的那几段发给AI?
问题来了:怎么知道哪几段相关?
这就是RAG要解决的问题。
2. RAG是什么?能干啥?
2.1 RAG是啥?
RAG = Retrieval Augmented Generation
- Retrieval = 检索(找资料)
- Augmented = 增强(给AI加Buff)
- Generation = 生成(AI写答案)
大白话解释:RAG就像给AI配了个"随身图书馆"和"图书管理员"。
2.2 没RAG vs 有RAG
| 场景 | 没RAG的AI | 有RAG的AI |
|---|---|---|
| 问你公司内部文档 | 瞎编(没见过) | “稍等,我去查下资料” → 查完再回答 |
| 问最新新闻 | 只知道训练时的旧闻 | 先去搜最新资讯再回答 |
| 问产品使用手册 | 不知道(没看过) | 先检索手册内容再回答 |
2.3 RAG解决了什么问题?
| 问题 | 怎么解决的 |
|---|---|
| 幻觉 | 给AI真实资料,让它照着说 |
| 知识更新 | 实时检索最新信息 |
| 私有数据 | 只在你本地检索,不泄露 |
| 省钱 | 只传相关片段,不传整本书 |
3. RAG怎么工作?三步走搞定
RAG的工作流程其实特别简单,就像我们人类查资料一样。
3.1 第一步:整理资料(一次性的)
就像你去图书馆,图书馆先把书整理好:
你所有的文档 → 切成小段 → 给每段编个号 → 存进"专用书架"
这一步是提前做好的,用户来之前就已经准备好了。
3.2 第二步:用户提问(实时的)
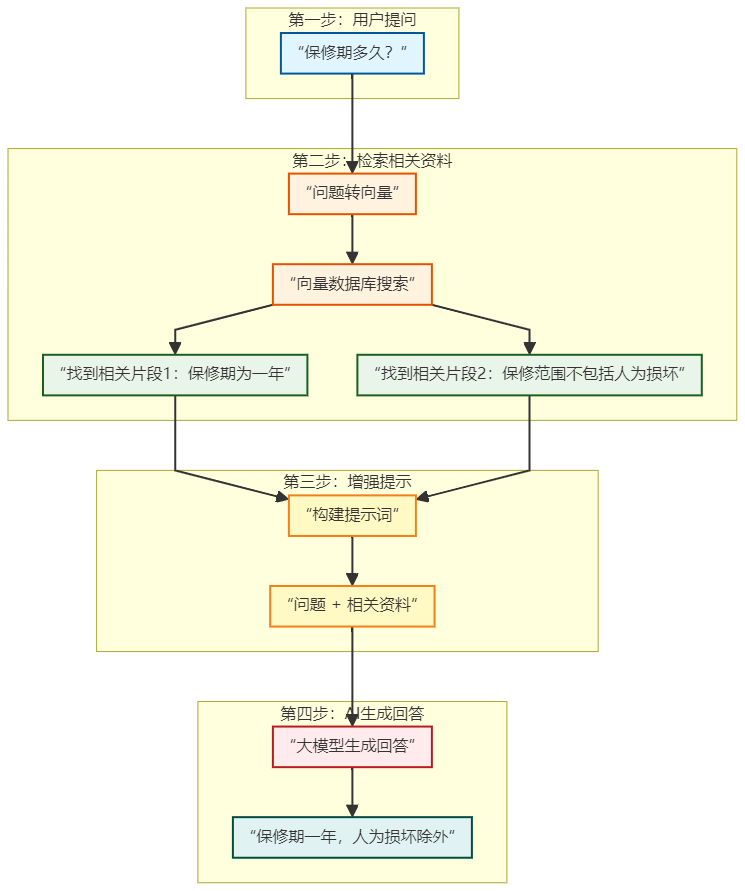
你问:"这个产品的保修期是多久?"
↓
去"专用书架"找跟这个问题最相关的几段
↓
找到:
- "本产品保修期为一年"(非常相关)
- "保修范围不包括人为损坏"(有点相关)
- "产品尺寸为15厘米"(不相关,排除)
3.3 第三步:AI回答
把问题和找到的相关段落一起给AI:
"这个产品的保修期是多久?根据资料:本产品保修期为一年,保修范围不包括人为损坏"
AI看着资料回答:"本产品保修期为一年,但需要注意人为损坏不在保修范围内"
3.4 一张图看懂
4. RAG的核心秘密:怎么找到相关内容的?
上面第二步说"去书架找相关段落",但计算机怎么知道哪段和问题相关?
4.1 计算机不认识文字
这是个关键问题:计算机不认识"本产品保修期为一年"这句话,它只认识数字。
要让计算机理解两句话是否相关,得先把文字变成它认识的东西——数字。
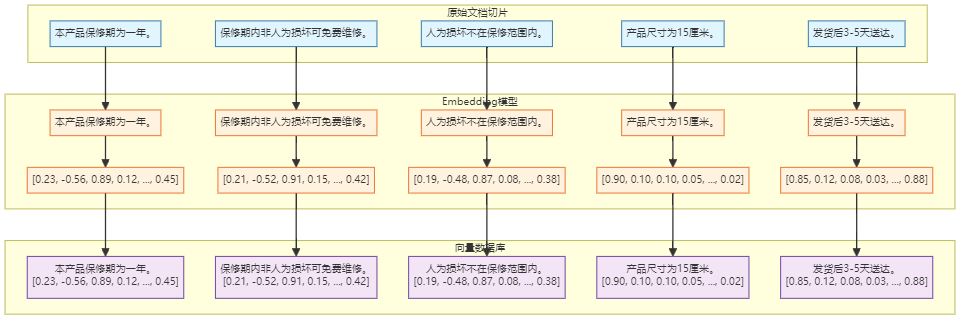
4.2 把文字变成"数字密码"
有个神奇的技术叫Embedding,它能:
- 把任何文字(不管长短)变成一串固定长度的数字
- 意思相近的文字,得到的数字串也长得像
4.3 举个栗子
"本产品保修期为一年" → [0.23, -0.56, 0.89, 0.12, ...] # 一串数字
"一年内免费维修" → [0.21, -0.52, 0.91, 0.15, ...] # 这串数字和上面那串很像
"产品颜色有红色蓝色" → [0.90, 0.10, 0.10, 0.05, ...] # 这串数字和前面差别很大
4.4 可以想象成"语义GPS"
- “本产品保修期为一年” 和 “一年内免费维修” → 在GPS上离得很近(都在"保修区")
- “产品颜色有红色蓝色” → 在GPS上离得远(在"颜色区")
- “快递发货需要3天” → 离得更远(在"物流区")
4.5 找到相关段落的完整过程
1. 提前准备:
每段文字 → 转成数字密码 → 存进数据库
2. 用户提问:
"这个产品的保修期是多久?" → 也转成数字密码 → [0.21, 0.28, 0.72, ...]
3. 找最像的:
数据库里找和 [0.21, 0.28, 0.72] 最像的几组数字密码
4. 取出原文:
找到的数字密码对应的原文就是相关段落
5. 切片是什么?为什么要切?
5.1 什么是切片?
就是把长文档切成小块。比如一篇5000字的产品说明书,切成10段,每段500字。
5.2 为什么要切?
| 原因 | 解释 |
|---|---|
| AI有字数限制 | 比如AI一次只能看4000字,长文档看不了 |
| 省成本 | 按字数收费,发整本书太贵 |
| 找得准 | 答案可能就在某一小段,整篇发反而找不着 |
打个比方:你要在一本500页的产品手册里找保修信息,是把整本书都给人看,还是先翻到保修那一页再给人看?
5.3 怎么切?
常见的切法:
| 切法 | 例子 | 优缺点 |
|---|---|---|
| 按字数 | 每500字一段 | 简单,但可能切断一句话 |
| 按段落 | 每个自然段是一段 | 自然,但段落可能太长 |
| 按章节 | 按文档原本的章节切 | 语义完整,但章节可能太大 |
| 按句子 | 每个句子是一段 | 灵活,但可能丢失上下文 |
5.4 为什么要重叠?
这是个细节但很重要!
原文:"本产品保修期为一年。保修期内出现非人为损坏可免费维修。"
如果不重叠切成两段:
段1:"本产品保修期为一年。"
段2:"保修期内出现非人为损坏可免费维修。"
问:"保修期内坏了怎么办?"
- 段1有"保修期"但没提坏了怎么办
- 段2有"免费维修"但前提是"保修期内"
如果重叠:
段1:"本产品保修期为一年。保修期内出现"
段2:"保修期内出现非人为损坏可免费维修。"
这样两个段都知道"保修期内"这个前提。
一般会重叠10-20%的内容,就像两个人交接班,要重叠一会儿确保信息完整。
6. 向量数据库:专门存"数字密码"的仓库
6.1 什么是向量数据库?
普通数据库(比如MySQL)存的是表格数据:
| 产品名 | 价格 | 库存 |
|---|---|---|
| 手机 | 2999 | 100 |
| 电脑 | 5999 | 50 |
向量数据库存的是"数字密码"(也叫向量):
[0.23, -0.56, 0.89, ...] ← 这是"本产品保修期为一年"
[0.21, -0.52, 0.91, ...] ← 这是"一年内免费维修"
[0.90, 0.10, 0.10, ...] ← 这是"产品颜色有红色蓝色"
6.2 普通数据库vs向量数据库
| 对比 | 普通数据库 | 向量数据库 |
|---|---|---|
| 存什么 | 产品名、价格、库存 | 数字密码(向量) |
| 怎么查 | 找价格<3000的产品 | 找跟这个最像的5个 |
| 查询方式 | 精确匹配 | 找"最像的" |
6.3 为什么需要专门的数据库?
因为我们不是要找"等于多少",而是要找"最像的"。
# 普通数据库查不了这个
找和 [0.21, 0.28, 0.72] 最像的5个向量
向量数据库专门干这个,又快又准。就像百度搜图,你上传一张照片,它找出最像的几张。
6.4 数据库里到底存什么?
每一行大概长这样:
{
"id": "001",
"text": "本产品保修期为一年,保修期内非人为损坏可免费维修", // 原文(一定要存!)
"vector": [0.12, 0.58, 0.31, ...], // 对应的数字密码
"来源": "产品说明书.docx", // 其他信息(可选)
"页码": 15 // 方便追溯
}
关键:一定要存原文!不然找到数字密码也不知道说的是啥。
7. Token是什么?为什么总听人说?
7.1 Token是啥?
Token可以理解为"AI眼里的字数单位"。不是按我们人类的字数算,是按AI分词的方式算。
就像我们看一句话会自然分成词:
- “保修期一年” → 保修期 / 一年(2个词)
- AI也有它自己的分词方式
7.2 中英文差异
# 英文(按空格和词根切)
"This product has one-year warranty"
→ 分成 ["This", " product", " has", " one-year", " warranty"] = 5个token
# 中文(按语义单元切)
"本产品保修期为一年"
→ 分成 ["本", "产品", "保修期", "为", "一年"] = 5个token
7.3 大概换算
| 语言 | 换算关系 | 例子 |
|---|---|---|
| 英文 | 1个词 ≈ 1.3个token | “warranty period” ≈ 2-3个token |
| 中文 | 1个字 ≈ 2-3个token | “保修期” ≈ 4-6个token |
| 1000个token ≈ 500-700个中文字 |
7.4 为什么Token这么重要?
原因一:因为要花钱!
用大模型API是按token收费的:
| 模型 | 价格(大概) |
|---|---|
| GPT-4 | 输入$0.03/1000 tokens |
| 输出$0.06/1000 tokens |
换算成人民币,问一次可能几毛到几块,问多了就贵了。
原因二:有字数限制!
每个模型一次能处理的token是有限的:
| 模型 | 一次能看多少中文字 |
|---|---|
| GPT-3.5 | 约3000-12000字 |
| GPT-4 | 约6000-24000字 |
| GPT-4 Turbo | 约20万字 |
超出的部分会被截断,或者根本发不过去。
7.5 RAG怎么帮你省钱?
假设你有一本10万字的产品手册:
不切直接问:
- 10万字 ≈ 20万token
- 按GPT-4算 ≈ 6块钱一次
- 问100次就600块!
RAG只发相关片段:
- 找到相关的500字 ≈ 1000token
- 一次只要3分钱
- 问100次才3块钱
省了200倍!
8. RAG的缺点:它也不是万能的
RAG很好用,但也有搞不定的时候。
8.1 缺点一:切段会切断关系
原文:"本产品保修期为一年。保修期内如果出现非人为损坏,可以免费维修。但需要保留购买凭证。"
切成三段:
段1:"本产品保修期为一年"
段2:"保修期内如果出现非人为损坏,可以免费维修"
段3:"但需要保留购买凭证"
问:"保修期内维修需要什么条件?"
- 段1有"保修期"但没提维修条件
- 段2有"免费维修"但没提需要凭证
- 段3有"保留购买凭证"但和什么相关?
就像把一句话拆成三半,中间的联系就断了。
怎么办?
- 切片时重叠一部分
- 或者用更智能的切法,保证语义完整
8.2 缺点二:没有全局视角
有些问题需要看完整本书才能回答:
| 问题类型 | 例子 | 为什么RAG搞不定 |
|---|---|---|
| 统计类 | “这份说明书里提到多少次’保修’?” | 要数遍全书,RAG只找相关片段 |
| 对比类 | “第一章和最后一章的注意事项有什么不同?” | 要看前后对比,RAG找不到这种关系 |
| 总结类 | “这份产品手册主要讲了什么?” | 要把握整体,RAG只见树木不见森林 |
就像只看拼图的几块,猜不出整张图是什么。
怎么办?
- 新技术如GraphRAG,把文档建成图,可以跨片段找关系
- 或者用层次化RAG,先粗后细
8.3 缺点三:可能找到不相关的内容
问:"手机保修期多久?"
向量数据库可能找到:
✓ "本手机保修期为一年"(相关)
✗ "保修条款适用于所有电子产品"(有保修但不具体)
✗ "手机尺寸为6.1英寸"(有手机但不相关)
就像搜"苹果",可能找到水果,也可能找到手机。
怎么办?
- 加一个"重排序"步骤:先粗筛100个,再精读一遍挑出最相关的5个
- 能过滤掉大部分不相关的内容
8.4 缺点总结
| 缺点 | 简单说 | 怎么办 |
|---|---|---|
| 切断关系 | 一句话被切成几段,联系断了 | 切片时重叠一部分 |
| 没全局视角 | 只见树木不见森林 | 用新技术如GraphRAG |
| 找到不相关 | 搜到带关键词但不相关的内容 | 加"重排序"再筛一遍 |
9. 总结:一张图看懂RAG
9.1 RAG本质
RAG就是给AI配了个图书馆:
- 平时把书(文档)整理好、编号(转成向量)
- 你问问题时,先去查书(检索)
- 把查到的那几页(相关片段)给AI看
- AI看着资料回答你
9.2 优点
✅ 减少胡说八道
✅ 能回答私有文档问题
✅ 省成本
✅ 知识可以随时更新
9.3 缺点
❌ 切段可能切断关系
❌ 难回答全局性问题
❌ 可能找到不相关内容
9.4 一句话总结
RAG不是完美的技术,但它让AI从"瞎编"变成了"查资料再回答",靠谱多了!
附录:常见问题
Q:RAG需要自己训练模型吗?
A:完全不需要,直接用现成的Embedding模型和大模型就行。
Q:要花多少钱?
A:小项目可能免费(开源工具),大项目看调用量,但比直接问省钱。
Q:难实现吗?
A:基础版本几百行代码就能跑起来,网上有很多现成的教程。
Q:中文支持好吗?
A:有专门的中文Embedding模型(如BAAI/bge-large-zh),挺好用的。
Q:我的文档是PDF/Word可以吗?
A:可以,先转成文字,后面流程都一样。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)