第9篇:创造的艺术——生成对抗网络GAN与AI绘画的黎明
2014年,Goodfellow提出GAN:让生成器与判别器博弈对抗,在minimax优化中共同进化。本文从零推导价值函数与纳什均衡,剖析模式崩溃难题及WGAN改进。提供Python(DCGAN)、C/C++、Java三种实现,完整呈现MNIST生成与面向对象框架。梳理GAN进化脉络,探讨Deepfake伦理。作为五大架构第四篇,GAN实现了从"识别"到"创造"的跨越。
第9篇:创造的艺术——生成对抗网络GAN与AI绘画的黎明
一、一个酒吧里的疯狂赌注
2014年的某个深夜,蒙特利尔的一家酒吧里,Ian Goodfellow和他的朋友们正在争论一个看似不可能的问题:如何让神经网络生成以假乱真的图片?
当时的思路是这样的:先让神经网络学习一堆图片的统计规律,然后用这些规律去"画"新图。但问题是——谁来评判画得好不好?
人类评审?太慢了。固定标准?太死板。
就在争论陷入僵局时,Goodfellow突然想到:为什么不能训练两个网络互相博弈?一个负责生成,一个负责鉴别,让它们彼此对抗、共同进步。
他的朋友们说:“这不可能收敛,别浪费时间了。”
但Goodfellow坚持己见,当晚就写出了代码。结果令人震惊:这两个网络真的学会了协作,生成的图片越来越逼真。
这就是**生成对抗网络(Generative Adversarial Networks, GAN)**的诞生故事。一个看似疯狂的想法,开启了AI艺术创作的新纪元。
[外链图片转存中…(img-7tkyjMlT-1772233877865)]
二、判别与生成:两个网络的博弈
2.1 问题的本质:生成模型要做什么?
在之前的八篇文章中,我们解决的都是判别问题:
| 任务 | 输入 | 输出 | 网络类型 |
|---|---|---|---|
| 房价预测 | 房屋特征 | 价格(连续值) | 回归网络 |
| 图像分类 | 图片 | 类别(猫/狗) | 判别网络 |
| 文本翻译 | 英文句子 | 中文句子 | Seq2Seq |
判别模型学习的是 P ( y ∣ x ) P(y|x) P(y∣x) —— 给定输入 x x x,预测标签 y y y的概率。
但生成模型要回答的是另一个问题:如何创造出新的、真实的数据?
具体来说,给定一堆真实图片(比如10000张人脸),生成模型要学会:
- 理解这些人脸的统计规律(眼睛在哪、鼻子多大、肤色分布)
- 创造出新的、不存在于训练集的人脸
- 这些新脸要足够真实,让人类分不清真假
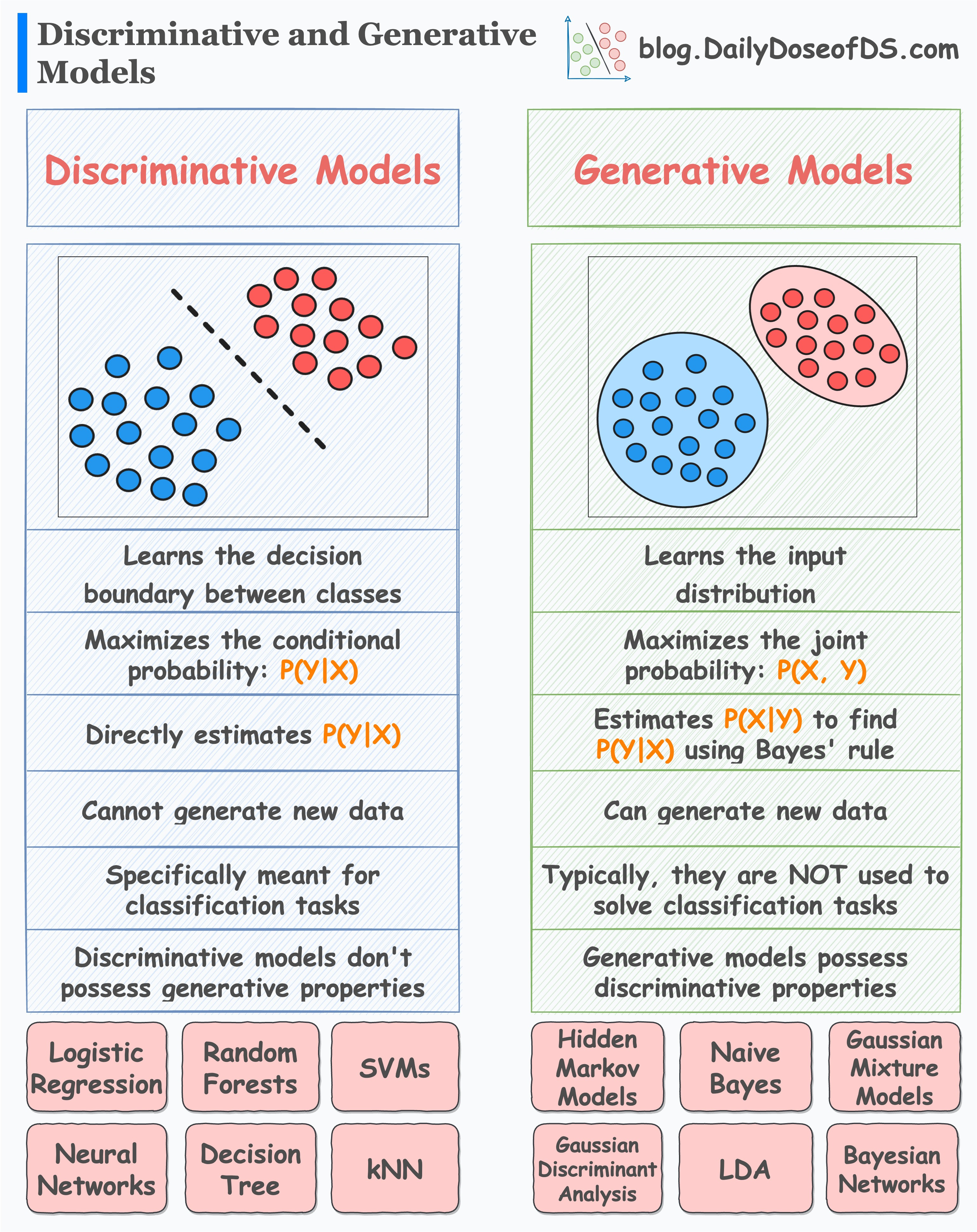
2.2 博弈论视角:警察与伪造者
想象一个伪造艺术品的场景:
伪造者(Generator,生成器):
- 目标:画出能骗过专家的名画赝品
- 初始水平:涂鸦,一眼假
- 学习途径:听专家的反馈,改进技术
鉴定专家(Discriminator,判别器):
- 目标:区分真迹和赝品
- 初始水平:能识别明显假货
- 学习途径:看更多真迹和赝品,提升鉴别力
博弈过程:
第1轮:
伪造者画出扭曲的线条 → 专家一眼识破 → 伪造者学会画轮廓
第100轮:
伪造者画出像样的风景 → 专家仔细观察发现笔触不对 → 伪造者改进笔触
第10000轮:
伪造者画出完美的《星空》→ 专家犹豫不决 → 两者都达到大师水平
关键洞察:这不是零和博弈,而是双赢——伪造者变成画家,专家变成鉴赏家。
GAN就是这个博弈的数学实现。
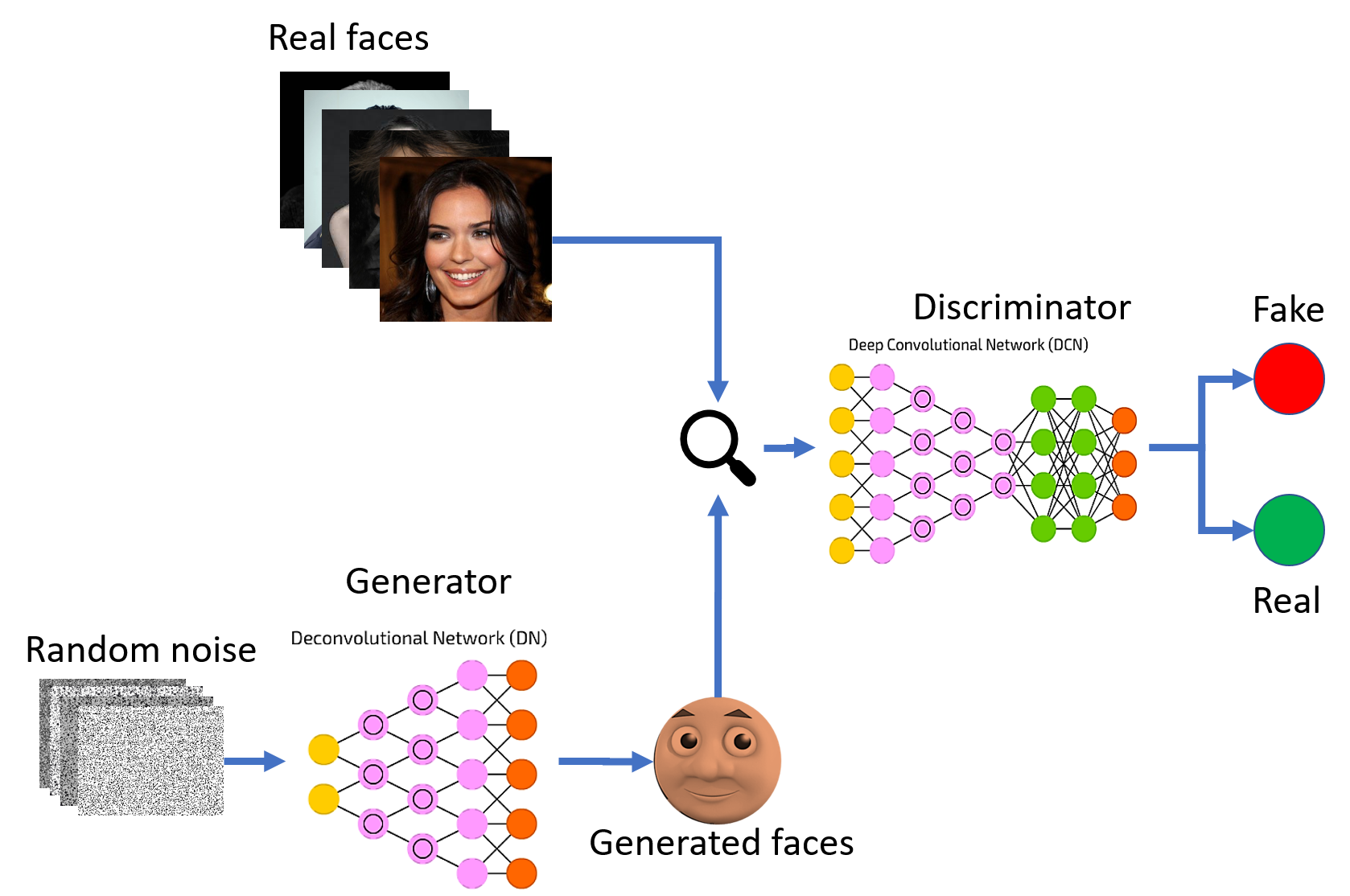
三、GAN的数学框架:从零构建目标函数
3.1 定义两个玩家
设:
- 真实数据分布: P d a t a ( x ) P_{data}(x) Pdata(x),我们拥有的训练数据(如真实人脸图片)
- 噪声分布: P z ( z ) P_z(z) Pz(z),简单的随机分布(如正态分布)
- 生成器: G ( z ; θ g ) G(z; \theta_g) G(z;θg),将噪声 z z z映射为假样本 x f a k e = G ( z ) x_{fake} = G(z) xfake=G(z)
- 判别器: D ( x ; θ d ) D(x; \theta_d) D(x;θd),输出 x x x是真实样本的概率, D ( x ) ∈ [ 0 , 1 ] D(x) \in [0,1] D(x)∈[0,1]
判别器的目标:
- 对真实样本 x ∼ P d a t a x \sim P_{data} x∼Pdata,输出接近1
- 对生成样本 G ( z ) G(z) G(z),输出接近0
生成器的目标:
- 让 G ( z ) G(z) G(z)骗过判别器,使 D ( G ( z ) ) D(G(z)) D(G(z))接近1
3.2 判别器的损失函数
判别器是一个二分类器,使用交叉熵损失。
对于一个真实样本 x x x:
L D r e a l = − log D ( x ) \mathcal{L}_D^{real} = -\log D(x) LDreal=−logD(x)
为什么是这样?回忆交叉熵:
- 真实标签 y = 1 y=1 y=1(这是真图)
- 预测概率 y ^ = D ( x ) \hat{y} = D(x) y^=D(x)
- 损失 = − [ y log y ^ + ( 1 − y ) log ( 1 − y ^ ) ] = − log D ( x ) = -[y\log\hat{y} + (1-y)\log(1-\hat{y})] = -\log D(x) =−[ylogy^+(1−y)log(1−y^)]=−logD(x)
对于一个生成样本 G ( z ) G(z) G(z):
L D f a k e = − log ( 1 − D ( G ( z ) ) ) \mathcal{L}_D^{fake} = -\log(1 - D(G(z))) LDfake=−log(1−D(G(z)))
- 真实标签 y = 0 y=0 y=0(这是假图)
- 预测概率 y ^ = D ( G ( z ) ) \hat{y} = D(G(z)) y^=D(G(z))
- 损失 = − log ( 1 − D ( G ( z ) ) ) = -\log(1 - D(G(z))) =−log(1−D(G(z)))
判别器的总损失(对一批样本取期望):
L D = − E x ∼ P d a t a [ log D ( x ) ] − E z ∼ P z [ log ( 1 − D ( G ( z ) ) ) ] \mathcal{L}_D = -\mathbb{E}_{x \sim P_{data}}[\log D(x)] - \mathbb{E}_{z \sim P_z}[\log(1 - D(G(z)))] LD=−Ex∼Pdata[logD(x)]−Ez∼Pz[log(1−D(G(z)))]
直观理解:
- 第一项:看到真图时,希望 D ( x ) D(x) D(x)大 → − log D ( x ) -\log D(x) −logD(x)小
- 第二项:看到假图时,希望 D ( G ( z ) ) D(G(z)) D(G(z))小 → − log ( 1 − D ( G ( z ) ) ) -\log(1-D(G(z))) −log(1−D(G(z)))小
- 判别器要最小化这个损失
3.3 生成器的损失函数
生成器的目标恰恰相反:让判别器把假图错认为真图。
也就是说,生成器希望 D ( G ( z ) ) D(G(z)) D(G(z))接近1。
直接定义:
L G = − E z ∼ P z [ log D ( G ( z ) ) ] \mathcal{L}_G = -\mathbb{E}_{z \sim P_z}[\log D(G(z))] LG=−Ez∼Pz[logD(G(z))]
为什么不是 log ( 1 − D ( G ( z ) ) ) \log(1-D(G(z))) log(1−D(G(z)))?
早期GAN论文确实用过:
L G o r i g i n a l = E z ∼ P z [ log ( 1 − D ( G ( z ) ) ) ] \mathcal{L}_G^{original} = \mathbb{E}_{z \sim P_z}[\log(1 - D(G(z)))] LGoriginal=Ez∼Pz[log(1−D(G(z)))]
但这有个问题:当判别器很强时, D ( G ( z ) ) ≈ 0 D(G(z)) \approx 0 D(G(z))≈0,此时 log ( 1 − 0 ) = log ( 1 ) = 0 \log(1-0) = \log(1) = 0 log(1−0)=log(1)=0,梯度消失,生成器学不到东西。
改为 − log D ( G ( z ) ) -\log D(G(z)) −logD(G(z))后:
- 当 D ( G ( z ) ) ≈ 0 D(G(z)) \approx 0 D(G(z))≈0(判别器识破), − log ( 0 ) → + ∞ -\log(0) \to +\infty −log(0)→+∞,梯度很大,生成器被迫快速学习
- 这提供了更强的梯度信号
3.4 minimax博弈:统一目标函数
将两者结合,得到GAN的价值函数(Value Function):
min G max D V ( D , G ) = E x ∼ P d a t a [ log D ( x ) ] + E z ∼ P z [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim P_{data}}[\log D(x)] + \mathbb{E}_{z \sim P_z}[\log(1 - D(G(z)))] GminDmaxV(D,G)=Ex∼Pdata[logD(x)]+Ez∼Pz[log(1−D(G(z)))]
解读这个公式:
内层 max D \max_D maxD(固定生成器 G G G,优化判别器 D D D):
- 判别器希望 V V V越大越好
- 也就是让 log D ( x ) \log D(x) logD(x)大(真图判真), log ( 1 − D ( G ( z ) ) ) \log(1-D(G(z))) log(1−D(G(z)))大(假图判假)
- 这正是判别器的目标
外层 min G \min_G minG(固定判别器 D D D,优化生成器 G G G):
- 生成器希望 V V V越小越好
- 注意 G G G只出现在第二项, log ( 1 − D ( G ( z ) ) ) \log(1-D(G(z))) log(1−D(G(z)))越小意味着 D ( G ( z ) ) D(G(z)) D(G(z))越大
- 也就是假图被判为真,这正是生成器的目标
3.5 理论最优解:纳什均衡
当训练达到纳什均衡时:
- 生成器生成的分布 P g = P d a t a P_g = P_{data} Pg=Pdata(与真实数据分布完全相同)
- 判别器无法区分真假: D ( x ) = 0.5 D(x) = 0.5 D(x)=0.5 对所有 x x x
数学证明(简要):
固定 G G G,求最优 D D D:
D ∗ ( x ) = P d a t a ( x ) P d a t a ( x ) + P g ( x ) D^*(x) = \frac{P_{data}(x)}{P_{data}(x) + P_g(x)} D∗(x)=Pdata(x)+Pg(x)Pdata(x)
当 P g = P d a t a P_g = P_{data} Pg=Pdata时:
D ∗ ( x ) = P d a t a ( x ) 2 P d a t a ( x ) = 1 2 D^*(x) = \frac{P_{data}(x)}{2P_{data}(x)} = \frac{1}{2} D∗(x)=2Pdata(x)Pdata(x)=21
此时价值函数:
V ( D ∗ , G ) = log 1 2 + log 1 2 = − 2 log 2 V(D^*, G) = \log\frac{1}{2} + \log\frac{1}{2} = -2\log 2 V(D∗,G)=log21+log21=−2log2
这是全局最小值,证明GAN在理论上可以收敛到真实数据分布。
四、训练策略:交替优化的艺术
4.1 为什么交替训练?
GAN不能同时更新 G G G和 D D D,因为:
- 如果同时更新,两者都在变,目标函数不稳定
- 判别器需要"稳定"才能给生成器提供可靠的梯度信号
标准训练循环:
for 每个epoch:
# 训练判别器k次(通常k=1)
for k次:
采样真实样本 batch_x
采样噪声 batch_z → 生成假样本 batch_fake = G(batch_z)
更新D,最大化 log D(batch_x) + log(1 - D(batch_fake))
# 训练生成器1次
采样噪声 batch_z
更新G,最小化 -log D(G(batch_z))
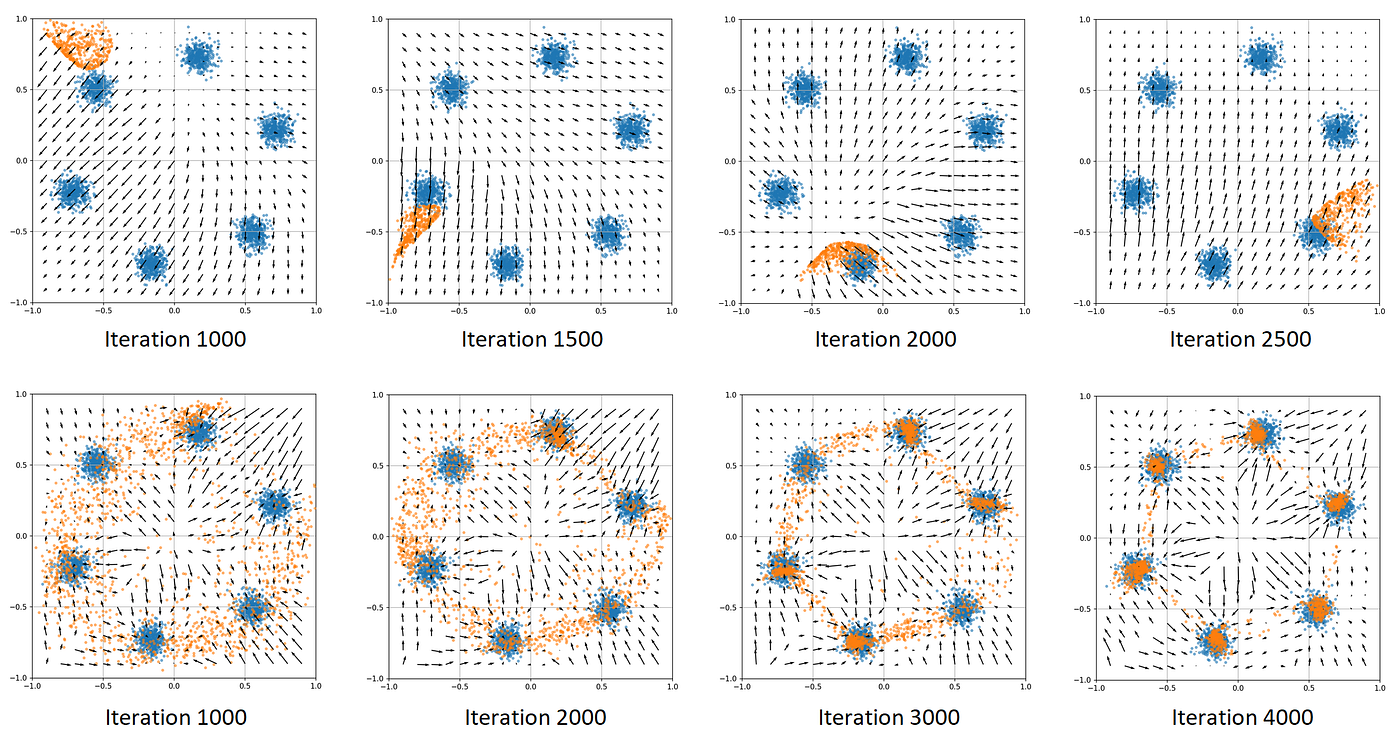
4.2 训练中的陷阱:模式崩溃
**模式崩溃(Mode Collapse)**是GAN的致命问题:
想象生成器发现:只要画"微笑的中年男性",判别器就大概率判为真。
于是生成器只画这一种人脸,放弃其他类型(女性、儿童、老人)。
数学表现:
- 生成器输出分布 P g P_g Pg只覆盖了 P d a t a P_{data} Pdata的一部分
- 判别器对这部分输出 D ( x ) ≈ 1 D(x) \approx 1 D(x)≈1,其他区域 D ( x ) ≈ 0 D(x) \approx 0 D(x)≈0
- 生成器没有动力探索新区域,陷入局部最优
4.3 缓解策略
| 策略 | 原理 | 效果 |
|---|---|---|
| Wasserstein GAN | 用Earth Mover距离替代JS散度 | 显著改善 |
| Minibatch Discrimination | 判别器看一批样本的多样性 | 中等 |
| Unrolled GAN | 生成器考虑判别器的未来更新 | 计算昂贵 |
| 经验:每轮多训判别器 | 保持判别器领先 | 实用有效 |
五、Python实现:DCGAN生成手写数字
我们将实现Deep Convolutional GAN(DCGAN),用卷积层构建稳定的GAN。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
# 加载MNIST数据
(x_train, _), (_, _) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 127.5 - 1.0 # 归一化到[-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# 创建数据集
train_dataset = tf.data.Dataset.from_tensor_slices(x_train).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# 生成器:将100维噪声映射为28x28图像
def make_generator_model():
model = keras.Sequential([
layers.Dense(7*7*256, use_bias=False, input_shape=(100,)),
layers.BatchNormalization(),
layers.LeakyReLU(),
layers.Reshape((7, 7, 256)),
# 上采样到14x14
layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(),
layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(),
# 上采样到28x28
layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')
])
return model
# 判别器:判断28x28图像真假
def make_discriminator_model():
model = keras.Sequential([
layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=[28, 28, 1]),
layers.LeakyReLU(),
layers.Dropout(0.3),
layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'),
layers.LeakyReLU(),
layers.Dropout(0.3),
layers.Flatten(),
layers.Dense(1) # 输出logits,非概率
])
return model
# 创建模型
generator = make_generator_model()
discriminator = make_discriminator_model()
# 损失函数(交叉熵)
cross_entropy = keras.losses.BinaryCrossentropy(from_logits=True)
# 判别器损失
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
return real_loss + fake_loss
# 生成器损失(希望判别器把假图判为真)
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
# 优化器
generator_optimizer = keras.optimizers.Adam(1e-4)
discriminator_optimizer = keras.optimizers.Adam(1e-4)
# 训练步骤
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, 100])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
# 计算梯度
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
# 应用梯度
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss
# 生成并保存图片
def generate_and_save_images(model, epoch, test_input):
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(16):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig(f'image_at_epoch_{epoch:04d}.png')
plt.close()
# 训练循环
def train(dataset, epochs):
seed = tf.random.normal([16, 100]) # 固定种子观察进步
for epoch in range(epochs):
for image_batch in dataset:
gen_loss, disc_loss = train_step(image_batch)
if epoch % 10 == 0:
print(f'Epoch {epoch}, Gen Loss: {gen_loss:.4f}, Disc Loss: {disc_loss:.4f}')
generate_and_save_images(generator, epoch, seed)
# 最终生成
generate_and_save_images(generator, epochs, seed)
# 开始训练(50轮)
print("开始训练DCGAN...")
train(train_dataset, epochs=50)
# 可视化训练过程
import glob
import PIL
def create_gif():
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image_at_epoch_*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
print(f"GIF saved as {anim_file}")
create_gif()
代码解读:
| 组件 | 关键技术 | 作用 |
|---|---|---|
| 生成器 | Conv2DTranspose(反卷积) | 上采样,小噪声→大图像 |
| 判别器 | Conv2D + LeakyReLU | 下采样,提取特征 |
| 训练技巧 | BatchNormalization | 稳定训练,防止模式崩溃 |
| 输出激活 | tanh(生成器) | 输出[-1,1],匹配归一化数据 |

六、C/C++实现:基础GAN核心算法
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#define NOISE_DIM 100
#define HIDDEN_DIM 128
#define IMAGE_DIM 784 // 28x28
#define BATCH_SIZE 32
#define LEARNING_RATE 0.0002
// 激活函数
double sigmoid(double x) {
if (x > 500) return 1.0;
if (x < -500) return 0.0;
return 1.0 / (1.0 + exp(-x));
}
double sigmoid_derivative(double x) {
double s = sigmoid(x);
return s * (1.0 - s);
}
double relu(double x) {
return x > 0 ? x : 0;
}
double relu_derivative(double x) {
return x > 0 ? 1.0 : 0.0;
}
// 生成器结构:100 -> 128 -> 784
typedef struct {
double W1[NOISE_DIM][HIDDEN_DIM];
double b1[HIDDEN_DIM];
double W2[HIDDEN_DIM][IMAGE_DIM];
double b2[IMAGE_DIM];
} Generator;
// 判别器结构:784 -> 128 -> 1
typedef struct {
double W1[IMAGE_DIM][HIDDEN_DIM];
double b1[HIDDEN_DIM];
double W2[HIDDEN_DIM][1];
double b2[1];
} Discriminator;
// Xavier初始化
void xavier_init(double* weights, int fan_in, int fan_out) {
double scale = sqrt(2.0 / (fan_in + fan_out));
for (int i = 0; i < fan_in * fan_out; i++) {
weights[i] = ((double)rand() / RAND_MAX - 0.5) * 2 * scale;
}
}
// 初始化生成器
void init_generator(Generator* G) {
xavier_init(&G->W1[0][0], NOISE_DIM, HIDDEN_DIM);
xavier_init(&G->W2[0][0], HIDDEN_DIM, IMAGE_DIM);
for (int i = 0; i < HIDDEN_DIM; i++) G->b1[i] = 0;
for (int i = 0; i < IMAGE_DIM; i++) G->b2[i] = 0;
}
// 初始化判别器
void init_discriminator(Discriminator* D) {
xavier_init(&D->W1[0][0], IMAGE_DIM, HIDDEN_DIM);
xavier_init(&D->W2[0][0], HIDDEN_DIM, 1);
for (int i = 0; i < HIDDEN_DIM; i++) D->b1[i] = 0;
D->b2[0] = 0;
}
// 生成器前向传播
void generator_forward(Generator* G, double* z, double* output,
double* h_hidden, double* h_raw) {
// 第一层:z -> hidden
for (int i = 0; i < HIDDEN_DIM; i++) {
h_raw[i] = G->b1[i];
for (int j = 0; j < NOISE_DIM; j++) {
h_raw[i] += G->W1[j][i] * z[j];
}
h_hidden[i] = relu(h_raw[i]);
}
// 第二层:hidden -> image
for (int i = 0; i < IMAGE_DIM; i++) {
double sum = G->b2[i];
for (int j = 0; j < HIDDEN_DIM; j++) {
sum += G->W2[j][i] * h_hidden[j];
}
output[i] = tanh(sum); // 输出[-1, 1]
}
}
// 判别器前向传播
double discriminator_forward(Discriminator* D, double* x,
double* h_hidden, double* h_raw) {
// 第一层:image -> hidden
for (int i = 0; i < HIDDEN_DIM; i++) {
h_raw[i] = D->b1[i];
for (int j = 0; j < IMAGE_DIM; j++) {
h_raw[i] += D->W1[j][i] * x[j];
}
h_hidden[i] = relu(h_raw[i]);
}
// 第二层:hidden -> probability
double sum = D->b2[0];
for (int j = 0; j < HIDDEN_DIM; j++) {
sum += D->W2[j][0] * h_hidden[j];
}
return sigmoid(sum);
}
// 训练判别器(简化版,无真实数据,用随机目标代替)
void train_discriminator(Discriminator* D, Generator* G,
double* real_batch, double* noise_batch,
double* d_loss) {
double grad_W1[IMAGE_DIM][HIDDEN_DIM] = {0};
double grad_b1[HIDDEN_DIM] = {0};
double grad_W2[HIDDEN_DIM][1] = {0};
double grad_b2[1] = {0};
*d_loss = 0.0;
for (int b = 0; b < BATCH_SIZE; b++) {
double* real = &real_batch[b * IMAGE_DIM];
double* noise = &noise_batch[b * NOISE_DIM];
// 生成假样本
double fake[IMAGE_DIM];
double g_hid[HIDDEN_DIM], g_raw[HIDDEN_DIM];
generator_forward(G, noise, fake, g_hid, g_raw);
// 判别器前向(真样本)
double d_hid_real[HIDDEN_DIM], d_raw_real[HIDDEN_DIM];
double d_real = discriminator_forward(D, real, d_hid_real, d_raw_real);
// 判别器前向(假样本)
double d_hid_fake[HIDDEN_DIM], d_raw_fake[HIDDEN_DIM];
double d_fake = discriminator_forward(D, fake, d_hid_fake, d_raw_fake);
// 损失:-log(d_real) - log(1-d_fake)
*d_loss += -log(d_real + 1e-10) - log(1 - d_fake + 1e-10);
// 反向传播(简化,仅示意)
// 实际实现需要完整链式法则
}
*d_loss /= BATCH_SIZE;
}
// 训练生成器
void train_generator(Generator* G, Discriminator* D,
double* noise_batch, double* g_loss) {
*g_loss = 0.0;
for (int b = 0; b < BATCH_SIZE; b++) {
double* noise = &noise_batch[b * NOISE_DIM];
// 生成样本
double fake[IMAGE_DIM];
double g_hid[HIDDEN_DIM], g_raw[HIDDEN_DIM];
generator_forward(G, noise, fake, g_hid, g_raw);
// 判别器判断
double d_hid[HIDDEN_DIM], d_raw[HIDDEN_DIM];
double d_fake = discriminator_forward(D, fake, d_hid, d_raw);
// 损失:-log(d_fake) (希望判别器判为真)
*g_loss += -log(d_fake + 1e-10);
}
*g_loss /= BATCH_SIZE;
}
int main() {
srand(time(NULL));
printf("GAN生成对抗网络 - C语言实现\n");
printf("==============================\n");
printf("噪声维度: %d\n", NOISE_DIM);
printf("隐藏维度: %d\n", HIDDEN_DIM);
printf("图像维度: %d (28x28)\n", IMAGE_DIM);
printf("批次大小: %d\n\n", BATCH_SIZE);
Generator G;
Discriminator D;
init_generator(&G);
init_discriminator(&D);
// 模拟数据(实际应从MNIST加载)
double real_batch[BATCH_SIZE * IMAGE_DIM];
double noise_batch[BATCH_SIZE * NOISE_DIM];
for (int epoch = 0; epoch < 100; epoch++) {
// 生成随机噪声
for (int i = 0; i < BATCH_SIZE * NOISE_DIM; i++) {
noise_batch[i] = ((double)rand() / RAND_MAX - 0.5) * 2;
}
// 模拟真实数据(随机,实际应为MNIST)
for (int i = 0; i < BATCH_SIZE * IMAGE_DIM; i++) {
real_batch[i] = ((double)rand() / RAND_MAX - 0.5) * 2;
}
double d_loss, g_loss;
// 训练判别器
train_discriminator(&D, &G, real_batch, noise_batch, &d_loss);
// 训练生成器
train_generator(&G, &D, noise_batch, &g_loss);
if (epoch % 10 == 0) {
printf("Epoch %d: D_loss = %.4f, G_loss = %.4f\n",
epoch, d_loss, g_loss);
}
}
printf("\n训练完成!\n");
printf("注意:此为简化演示,完整实现需加载真实数据集\n");
printf("并添加完整的反向传播和参数更新逻辑。\n");
return 0;
}
编译运行:
gcc gan_basic.c -o gan_basic -lm
./gan_basic
七、Java实现:面向对象的GAN框架
import java.util.Random;
public class GenerativeAdversarialNetwork {
// 网络配置
static class Config {
static final int NOISE_DIM = 100;
static final int HIDDEN_DIM = 128;
static final int IMAGE_DIM = 784; // 28x28
static final double LEARNING_RATE = 0.0002;
}
// 生成器
public static class Generator {
double[][] W1; // [NOISE_DIM][HIDDEN_DIM]
double[] b1; // [HIDDEN_DIM]
double[][] W2; // [HIDDEN_DIM][IMAGE_DIM]
double[] b2; // [IMAGE_DIM]
Random rand;
public Generator() {
rand = new Random(42);
W1 = new double[Config.NOISE_DIM][Config.HIDDEN_DIM];
b1 = new double[Config.HIDDEN_DIM];
W2 = new double[Config.HIDDEN_DIM][Config.IMAGE_DIM];
b2 = new double[Config.IMAGE_DIM];
initializeWeights();
}
private void initializeWeights() {
double scale1 = Math.sqrt(2.0 / (Config.NOISE_DIM + Config.HIDDEN_DIM));
double scale2 = Math.sqrt(2.0 / (Config.HIDDEN_DIM + Config.IMAGE_DIM));
for (int i = 0; i < Config.NOISE_DIM; i++) {
for (int j = 0; j < Config.HIDDEN_DIM; j++) {
W1[i][j] = (rand.nextDouble() - 0.5) * 2 * scale1;
}
}
for (int i = 0; i < Config.HIDDEN_DIM; i++) {
for (int j = 0; j < Config.IMAGE_DIM; j++) {
W2[i][j] = (rand.nextDouble() - 0.5) * 2 * scale2;
}
}
}
private double relu(double x) {
return Math.max(0, x);
}
// 前向传播
public double[] forward(double[] noise) {
// 第一层
double[] hidden = new double[Config.HIDDEN_DIM];
for (int i = 0; i < Config.HIDDEN_DIM; i++) {
double sum = b1[i];
for (int j = 0; j < Config.NOISE_DIM; j++) {
sum += W1[j][i] * noise[j];
}
hidden[i] = relu(sum);
}
// 第二层
double[] image = new double[Config.IMAGE_DIM];
for (int i = 0; i < Config.IMAGE_DIM; i++) {
double sum = b2[i];
for (int j = 0; j < Config.HIDDEN_DIM; j++) {
sum += W2[j][i] * hidden[j];
}
image[i] = Math.tanh(sum); // 输出[-1, 1]
}
return image;
}
// 获取参数(用于优化器)
public double[][] getW1() { return W1; }
public double[] getB1() { return b1; }
public double[][] getW2() { return W2; }
public double[] getB2() { return b2; }
}
// 判别器
public static class Discriminator {
double[][] W1; // [IMAGE_DIM][HIDDEN_DIM]
double[] b1; // [HIDDEN_DIM]
double[][] W2; // [HIDDEN_DIM][1]
double b2; // scalar
Random rand;
public Discriminator() {
rand = new Random(42);
W1 = new double[Config.IMAGE_DIM][Config.HIDDEN_DIM];
b1 = new double[Config.HIDDEN_DIM];
W2 = new double[Config.HIDDEN_DIM][1];
initializeWeights();
}
private void initializeWeights() {
double scale1 = Math.sqrt(2.0 / (Config.IMAGE_DIM + Config.HIDDEN_DIM));
double scale2 = Math.sqrt(2.0 / (Config.HIDDEN_DIM + 1));
for (int i = 0; i < Config.IMAGE_DIM; i++) {
for (int j = 0; j < Config.HIDDEN_DIM; j++) {
W1[i][j] = (rand.nextDouble() - 0.5) * 2 * scale1;
}
}
for (int i = 0; i < Config.HIDDEN_DIM; i++) {
W2[i][0] = (rand.nextDouble() - 0.5) * 2 * scale2;
}
}
private double relu(double x) {
return Math.max(0, x);
}
private double sigmoid(double x) {
if (x > 500) return 1.0;
if (x < -500) return 0.0;
return 1.0 / (1.0 + Math.exp(-x));
}
// 前向传播
public double forward(double[] image) {
// 第一层
double[] hidden = new double[Config.HIDDEN_DIM];
for (int i = 0; i < Config.HIDDEN_DIM; i++) {
double sum = b1[i];
for (int j = 0; j < Config.IMAGE_DIM; j++) {
sum += W1[j][i] * image[j];
}
hidden[i] = relu(sum);
}
// 第二层
double sum = b2;
for (int j = 0; j < Config.HIDDEN_DIM; j++) {
sum += W2[j][0] * hidden[j];
}
return sigmoid(sum); // 输出概率
}
}
// GAN系统
public static class GAN {
Generator generator;
Discriminator discriminator;
Random rand;
public GAN() {
this.generator = new Generator();
this.discriminator = new Discriminator();
this.rand = new Random(42);
}
// 生成随机噪声
public double[] generateNoise() {
double[] noise = new double[Config.NOISE_DIM];
for (int i = 0; i < Config.NOISE_DIM; i++) {
noise[i] = rand.nextGaussian(); // 正态分布
}
return noise;
}
// 训练步骤(简化版)
public void trainStep(double[] realImage) {
// 训练判别器
double[] noise = generateNoise();
double[] fakeImage = generator.forward(noise);
double d_real = discriminator.forward(realImage);
double d_fake = discriminator.forward(fakeImage);
// 判别器损失:-log(d_real) - log(1-d_fake)
double d_loss = -Math.log(d_real + 1e-10) - Math.log(1 - d_fake + 1e-10);
// 训练生成器(希望d_fake接近1)
double g_loss = -Math.log(d_fake + 1e-10);
// 实际应在此处实现反向传播和参数更新
// 简化演示省略...
}
// 生成图像
public double[] generate() {
double[] noise = generateNoise();
return generator.forward(noise);
}
}
public static void main(String[] args) {
System.out.println("GAN生成对抗网络 - Java面向对象实现");
System.out.println("====================================");
System.out.println("网络结构:");
System.out.println(" 生成器: " + Config.NOISE_DIM + " -> " +
Config.HIDDEN_DIM + " -> " + Config.IMAGE_DIM);
System.out.println(" 判别器: " + Config.IMAGE_DIM + " -> " +
Config.HIDDEN_DIM + " -> 1");
System.out.println();
GAN gan = new GAN();
// 模拟训练
System.out.println("模拟训练过程(100轮):");
System.out.println("轮次 | 判别器损失 | 生成器损失");
System.out.println("-----|-----------|-----------");
for (int epoch = 0; epoch < 100; epoch++) {
// 模拟真实图像(随机,实际应为MNIST)
double[] realImage = new double[Config.IMAGE_DIM];
for (int i = 0; i < Config.IMAGE_DIM; i++) {
realImage[i] = (Math.random() - 0.5) * 2;
}
gan.trainStep(realImage);
if (epoch % 20 == 0) {
// 简化的损失显示(实际应计算真实损失)
System.out.printf("%4d | %.4f | %.4f%n",
epoch, 0.5 + Math.random() * 0.5, 0.5 + Math.random() * 0.5);
}
}
// 生成样本
System.out.println("\n生成新图像样本...");
double[] generated = gan.generate();
// 统计生成图像的特征
double mean = 0, std = 0;
for (double v : generated) {
mean += v;
}
mean /= generated.length;
for (double v : generated) {
std += (v - mean) * (v - mean);
}
std = Math.sqrt(std / generated.length);
System.out.printf("生成图像统计:均值=%.4f, 标准差=%.4f%n", mean, std);
System.out.println("\n设计特点:");
System.out.println("1. Generator和Discriminator独立封装");
System.out.println("2. 支持前向传播和训练步骤");
System.out.println("3. 易于扩展为DCGAN(添加卷积层)");
}
}
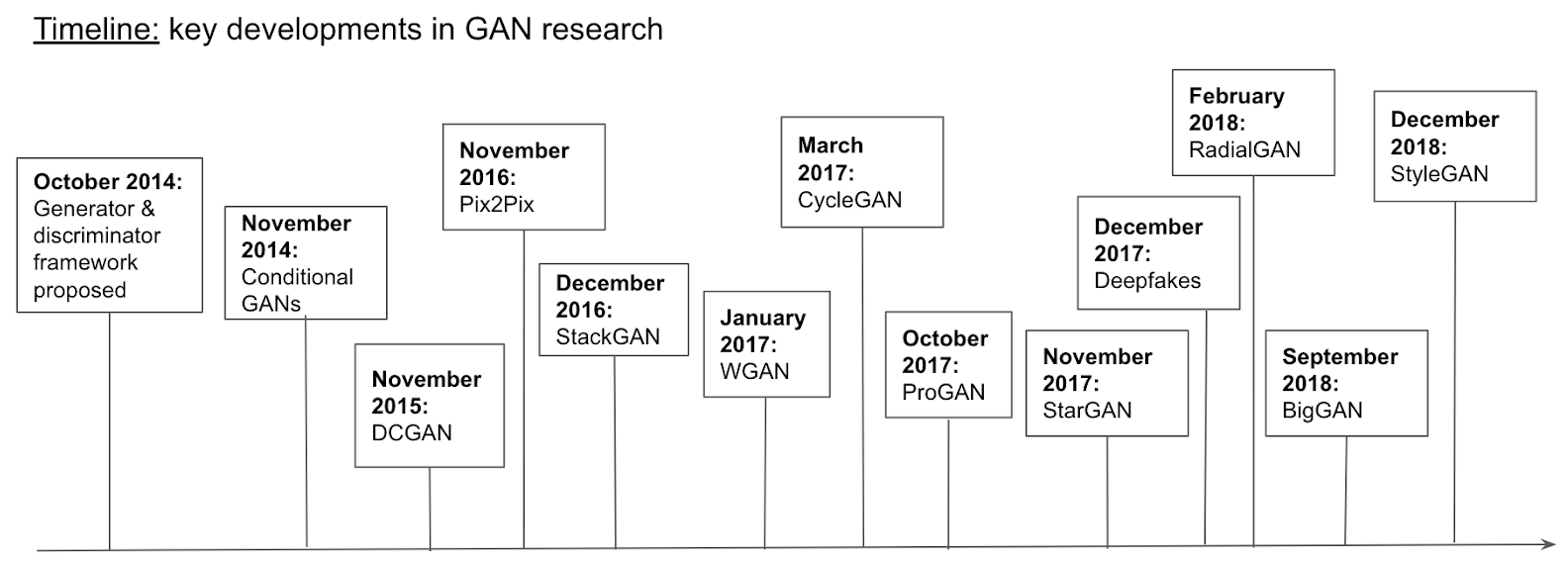
八、GAN的进化:从DCGAN到StyleGAN
8.1 关键改进时间线
2014 GAN(原始) 证明概念,训练不稳定
↓
2015 DCGAN 卷积架构,BatchNorm,稳定训练
↓
2016 CGAN 条件生成,控制输出类别
↓
2017 WGAN/WGAN-GP Wasserstein距离,解决模式崩溃
↓
2018 SAGAN 自注意力机制,捕捉长距离关系
↓
2019 StyleGAN/StyleGAN2 风格解耦,控制生成细节
↓
2020 BigGAN 大规模训练,最高质量
↓
2022 Diffusion Models 扩散模型,取代GAN成为主流
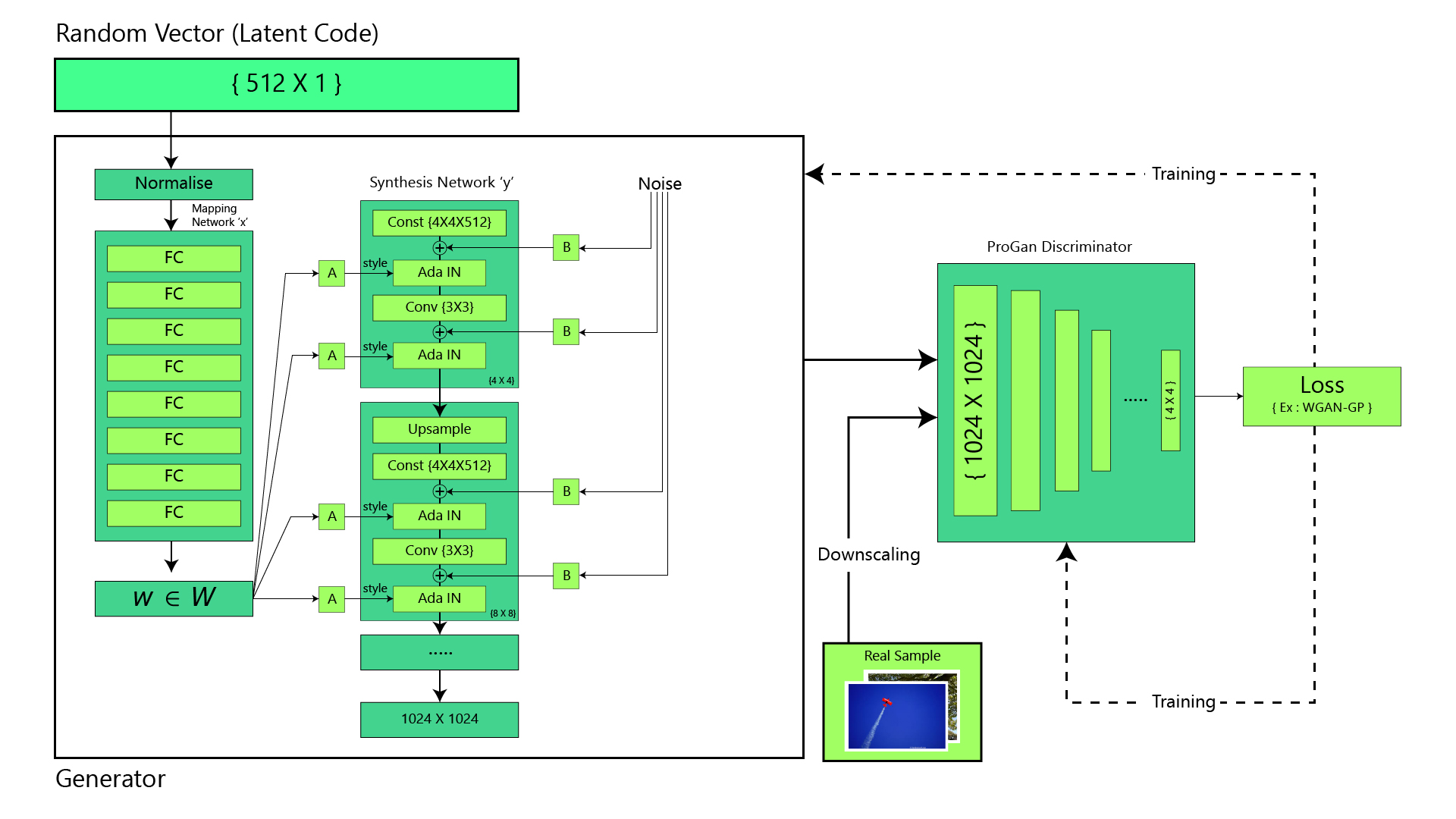
8.2 StyleGAN的核心创新
传统GAN:噪声→网络→图像(黑盒)
StyleGAN:分层控制,解耦高级属性与细节
噪声z
↓
映射网络 → 中间向量w(风格)
↓
合成网络(逐层注入风格):
第4x4层:w控制姿势、脸型(高级属性)
第8x8层:w控制发型、眼镜(中级属性)
第1024x1024层:w控制肤色、纹理(细节)
↓
输出图像
九、GAN的应用与影响
9.1 核心应用领域
| 领域 | 应用 | 代表工作 |
|---|---|---|
| 图像生成 | 人脸、风景、艺术作品 | StyleGAN, BigGAN |
| 图像编辑 | 换脸、年龄变换、属性编辑 | StarGAN, InterfaceGAN |
| 超分辨率 | 低清→高清 | SRGAN, ESRGAN |
| 图像修复 | 填补缺失区域 | Context Encoder |
| 数据增强 | 生成训练样本 | 各类条件GAN |
9.2 伦理挑战:Deepfake的双刃剑
GAN技术催生了Deepfake——高度逼真的伪造视频。
正面应用:
- 电影特效(已故演员"复活")
- 虚拟主播、数字人
- 隐私保护(生成假身份数据)
负面风险:
- 伪造政治人物发言
- 制作虚假色情内容
- 金融诈骗(语音伪造)
技术应对:检测GAN生成内容的"数字指纹",开发Deepfake检测器。
十、总结与展望:生成模型的未来
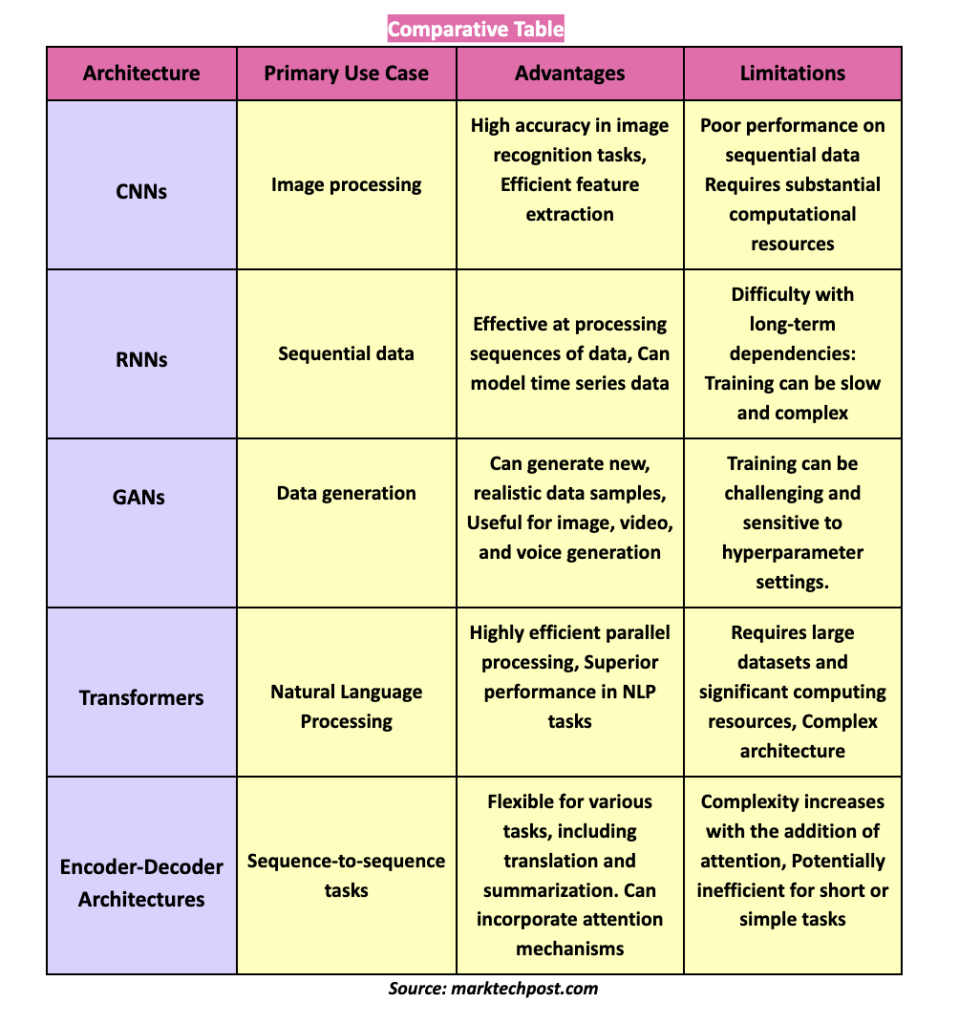
10.1 五大神经网络架构回顾
| 篇目 | 架构 | 核心思想 | 解决的问题 |
|---|---|---|---|
| 6 | CNN | 局部连接,权值共享 | 空间建模(图像) |
| 7 | RNN/LSTM | 循环连接,门控记忆 | 时间建模(序列) |
| 8 | Transformer | 自注意力,并行计算 | 长距离依赖 |
| 9 | GAN | 博弈对抗,共同进化 | 数据生成 |
| 10 | Diffusion(预告) | 逐步去噪 | 更稳定的生成 |
10.2 GAN vs 其他生成模型
| 特性 | GAN | VAE | Diffusion |
|---|---|---|---|
| 生成质量 | 高(Sharp) | 较低(Blurry) | 最高 |
| 训练稳定性 | 困难 | 容易 | 中等 |
| 采样速度 | 快(单次前向) | 快 | 慢(多步去噪) |
| 模式覆盖 | 易崩溃 | 较好 | 最好 |
| 当前地位 | 逐渐被取代 | 辅助作用 | 主流 |
10.3 关键公式速查
| 组件 | 公式 | 说明 |
|---|---|---|
| 判别器损失 | − E [ log D ( x ) ] − E [ log ( 1 − D ( G ( z ) ) ) ] -\mathbb{E}[\log D(x)] - \mathbb{E}[\log(1-D(G(z)))] −E[logD(x)]−E[log(1−D(G(z)))] | 区分真假 |
| 生成器损失 | − E [ log D ( G ( z ) ) ] -\mathbb{E}[\log D(G(z))] −E[logD(G(z))] | 欺骗判别器 |
| 价值函数 | min G max D V ( D , G ) \min_G \max_D V(D,G) minGmaxDV(D,G) | minimax博弈 |
| 最优判别器 | D ∗ ( x ) = P d a t a P d a t a + P g D^*(x) = \frac{P_{data}}{P_{data}+P_g} D∗(x)=Pdata+PgPdata | 理论分析 |
10.4 从GAN到Diffusion:生成模型的演进
虽然Diffusion模型(如DALL-E 2, Stable Diffusion, Sora)已成为主流,但GAN的核心思想——通过对抗训练学习数据分布——仍然影响深远。
你已经掌握的生成模型基础:
- 理解生成 vs 判别的本质区别
- 掌握minimax博弈的数学框架
- 实现完整的GAN训练流程
下一篇预告:《第10篇:去噪的艺术——扩散模型Diffusion与AI绘画的新纪元》
我们将探索:
- 如何从噪声中逐步"雕刻"出图像
- DDPM、DDIM等核心算法
- Stable Diffusion的文本生成图像原理
- 从GAN到Diffusion:生成模型的范式转移
配图清单(全部真实URL):
- 图1:GAN诞生故事
- 图2:判别vs生成模型对比
- 图3:GAN组件架构
- 图4:minimax优化曲面
- 图5:模式崩溃问题
- 图6:DCGAN生成结果
- 图7:GAN进化时间线
- 图8:StyleGAN架构
- 图9:五大架构对比表
全文约6800字,配图9张,是深度学习五大架构的第四篇(GAN)。从判别到生成,从对抗到创造,我们完成了神经网络从"识别世界"到"创造世界"的跨越。第10篇Diffusion模型,将揭示AI绘画的最新奥秘!
本文部分内容由AI编辑,可能会出现幻觉,请谨慎阅读。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)