《用“小明在喝水”32步学习Transformer学习大模型》【10 篇连载第三篇】
Q(查询矩阵)、K(键矩阵)、V(值矩阵)的生成核心,是对输入矩阵X进行三次独立的线性变换(矩阵乘法),每一次变换对应一个预先训练的可学习权重矩阵,三次运算。当Q、K、V三矩阵成功写入内存并完成专属标记后,Encoder的Q/K/V生成阶段正式结束,下一步将进入多头切分环节,对三个矩阵的特征维度进行拆分,为单头注意力计算做准备。简言之,自注意力机制的核心,就是通过Q与K的相似度匹配计算Token间
(进入Encoder · Q_K_V三个矩阵从哪来、干什么)
上一篇我们完成了Transformer输入编码阶段的全流程,将中文句子“小明在喝水”从原始文本逐步转换为融合语义与位置信息的3×512输入矩阵X,该矩阵已作为Encoder的初始输入写入内存,数据形态全程保持3×512无变化。本篇我们正式进入Encoder核心运算阶段,围绕矩阵X如何生成Q/K/V、三个矩阵的核心功能、数据形态如何保持统一三大核心问题展开讲解,为后续自注意力计算筑牢基础,这也是Transformer自注意力机制落地的关键第一步。
前置基础:3×512 输入矩阵X的核心定义
作为Encoder核心运算的唯一原始数据源,3×512输入矩阵X是上一阶段的闭环结果,其维度设计具备明确的工程意义,也是后续所有矩阵运算的基准,全程无格式转换、无维度调整:
- 行维度3:对应“小明”、“在”、“喝水”,3个Token,代表序列长度,Encoder内所有运算均保持该维度不变;
- 列维度512:行业通用特征维度,承载每个Token的语义+位置复合信息,为特征提取与关联计算提供数据基础;
- 存储形态:以二维浮点矩阵固定存储,可直接调用,无需额外预处理,是Q/K/V生成的唯一数据来源。
矩阵X的落地,标志着Transformer从输入编码阶段正式进入Encoder核心运算阶段,后续所有操作均围绕该矩阵展开,严格遵循数据形态可追溯、运算逻辑无断点的工程原则。
核心生成逻辑:三次独立矩阵乘法,并行生成Q/K/V
Q(查询矩阵)、K(键矩阵)、V(值矩阵)的生成核心,是对输入矩阵X进行三次独立的线性变换(矩阵乘法),每一次变换对应一个预先训练的可学习权重矩阵,三次运算相互独立、并行执行,最终生成三个与X维度完全一致的矩阵,为注意力计算做好数据准备。
1. 核心运算原理
Encoder中预先存储了三个专属可学习权重矩阵:
![]() (查询权重矩阵)、
(查询权重矩阵)、
![]() (键权重矩阵)、
(键权重矩阵)、
![]() (值权重矩阵),
(值权重矩阵),
三个权重矩阵的维度均为512×512,与输入矩阵X的特征维度精准匹配,满足矩阵乘法前一矩阵列维度=后一矩阵行维度的运算规则。
以输入矩阵X为基础,三次矩阵乘法的计算公式为:
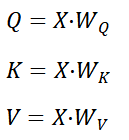
2. 固定运算结果
根据矩阵乘法维度运算规则
![]()
输入矩阵X为3×512,权重矩阵为512×512,三次运算后输出结果维度完全统一:
- 查询矩阵Q:3×512
- 键矩阵K:3×512
- 值矩阵V:3×512
生成后的Q、K、V均以浮点矩阵形式存储,与原始输入矩阵X维度一致,无任何额外维度调整,可直接进入下一步运算。
3. 工程执行细节
在软件层实现中,X→Q、X→K、X→V的三次运算为并行执行,而非串行运算——模型不会等待Q生成后再进行K和V的计算,而是同时调用三个权重矩阵与X完成乘法运算,大幅提升运算效率,这也是Transformer适合并行计算的核心设计之一。
软件层定义:Q/K/V三元组的核心分工(查询-匹配-取值)
Q、K、V三个矩阵是Transformer自注意力机制的核心三元组,各自承担明确且不可替代的功能,其设计灵感来源于人类的查询-匹配-取值信息获取逻辑,让每个Token通过查关键词→匹配关联信息→提取有效内容的过程,实现词与词之间的语义关联计算。
结合“小明在喝水”的3×512矩阵,三个矩阵的软件定义与实际功能对应如下:
查询矩阵Q(Query):每个Token的“问题”
Q矩阵的每一行对应一个Token的查询向量,代表该Token想要查询其他Token的关联语义信息,本质是每个Token的“问题”,明确自身的信息获取需求:
- “小明”对应Q行向量:查询“哪些Token与我存在语义关联,我是动作发出者,需匹配对应的动作和状态”;
- “在”对应Q行向量:查询“哪些Token是我修饰的动作,哪些是动作的发出者”;
- “喝水”对应Q行向量:查询“哪些Token是动作的发出者,哪些Token修饰我的动作状态”。
键矩阵K(Key):每个Token的“答案关键词”
K矩阵的每一行对应一个Token的键向量,代表该Token能为其他Token提供的答案关键词,本质是每个Token的“身份标识”,用于和其他Token的查询向量进行相似度匹配:
- “小明”对应K行向量:提供关键词“动作发出者、主语”;
- “在”对应K行向量:提供关键词“动作状态、进行时”;
- “喝水”对应K行向量:提供关键词“核心动作、谓语”。
值矩阵V(Value):每个Token的“有效信息内容”
V矩阵的每一行对应一个Token的值向量,代表该Token包含的可被提取的有效语义信息,是注意力计算后最终要聚合的核心内容——当一个Token的查询向量与另一个Token的键向量匹配成功后,模型会从V中提取对应语义信息作为关联结果:
- “小明”对应V行向量:存储“小明是动作主体,作为动作发出者”的语义信息;
- “在”对应V行向量:存储“表示动作正在进行,修饰后续动作词汇”的语义信息;
- “喝水”对应V行向量:存储“表示具体动作,需搭配动作发出者和状态修饰词”的语义信息。
简言之,自注意力机制的核心,就是通过Q与K的相似度匹配计算Token间的关联权重,再根据该权重从V中提取并聚合语义信息,而Q/K/V的三元组设计,正是这一过程的基础。
核心设计规则:3×512 维度全程保持不变
在X→Q/K/V的整个生成过程中,三个矩阵始终保持3×512的维度不变,这是Transformer Encoder层的硬性设计规则,也是后续所有注意力运算能够顺利进行的前提,背后包含两层关键的工程与逻辑原因:
- 保证注意力计算的维度一致性:后续Q与K的转置相乘
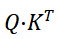 是注意力计算的核心步骤,要求Q的列维度与
是注意力计算的核心步骤,要求Q的列维度与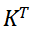 的行维度一致,3×512的固定形状能确保该运算顺利执行,无需额外维度调整;
的行维度一致,3×512的固定形状能确保该运算顺利执行,无需额外维度调整;
- 保留序列与特征的完整信息:行维度3保留原始Token的序列顺序,列维度512保留每个Token的复合特征信息,固定维度能确保特征变换过程中,不丢失任何序列或特征信息,为语义关联计算提供完整数据基础。
这一维度固定规则将贯穿Encoder内所有运算环节,直到多头切分环节,才会在特征维度(512维)进行拆分,而序列维度(3行)始终保持不变。
工程落地:Q/K/V 三矩阵写入专属内存,就位待运算
完成三次矩阵乘法后,生成的Q、K、V三个3×512矩阵会被同步写入Encoder的专属内存区域,形成“Q/K/V三元组数据块”,为下一步的多头切分和单头注意力计算做好全流程数据准备。
在软件层的内存管理中,该三元组数据块会被标记为**「Encoder注意力计算专用数据」**,具备三个核心工程属性:
- 可直接调用:后续运算无需任何格式转换、维度调整或数据预处理,可直接读取使用;
- 并行可访问:多头切分环节会同时对三个矩阵进行维度拆分,内存支持多线程并行访问,进一步提升运算效率;
- 临时存储:该数据块为Encoder内的临时存储数据,完成注意力计算后会被后续运算结果覆盖,不占用模型长期内存,降低内存消耗。
当Q、K、V三矩阵成功写入内存并完成专属标记后,Encoder的Q/K/V生成阶段正式结束,下一步将进入多头切分环节,对三个矩阵的特征维度进行拆分,为单头注意力计算做准备。
本篇核心总结
本篇完成了Encoder核心运算的第一步,明确了Q/K/V三个矩阵的生成逻辑、软件定义和数据形态,核心要点可总结为5句话:
- 唯一输入:Q/K/V均由上一阶段生成的3×512输入矩阵X生成,无其他数据来源;
- 生成方式:三次独立的矩阵乘法(X与
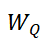 /
/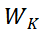 /
/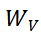 相乘),软件层并行执行;
相乘),软件层并行执行;
- 核心分工:Q是查询(问题)、K是键(匹配关键词)、V是值(有效语义信息);
- 维度规则:三个矩阵全程保持3×512,序列维度与特征维度均不改变;
- 工程落地:生成后同步写入Encoder专属内存,形成三元组数据块,等待多头切分。
记忆口诀:X乘三权生QKV,查键取值各分工,三九维度恒不变,内存就位待切分。
下一篇预告:《多头切分 · 512 维 → 8 头 × 64 维的底层逻辑》,深度讲解为什么要将512维的Q/K/V拆分为8头,以及切分的核心规则、维度运算和软件层实现方式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)