【2026必看】企业RAG技术全景图:从混合检索到Agentic RAG的实战指南
文章详解2024-2025年企业级RAG技术演进,混合检索已成生产标准,召回率提升5-10pp;GraphRAG通过知识图谱实现关系推理,LazyGraphRAG降低99.9%索引成本;Agentic RAG实现自主决策但90%项目生产失败,需谨慎应用。提供了框架选型指南和金融、法律、医疗等行业落地案例,强调企业应优先采用混合检索作为基础设施,根据场景决定技术引入,并建立评估体系贯穿始终。
1、前言:你的RAG还停留在2022年吗?
如果你现在还在用最朴素的"切块 → 向量化 → TopK检索 → 生成"四步RAG,在面试或者和同行交流时大概率会显露出知识断层。
2024-2025年,企业RAG技术经历了真正的代际跃升。不是小改小补,而是从架构、检索策略、工作流协调到基础设施,全面的工程化升级。
几个关键数字先感受一下规模:
- • arXiv上RAG相关论文:2024年超过1,200篇,比2023年的93篇增长13倍
- • 80%以上实施生成式AI的企业正在使用RAG框架
- • 纯向量搜索已被业界视为过时,混合检索成为生产标准
- • LazyGraphRAG将GraphRAG索引成本降低99.9%
- • **90%**的Agentic RAG项目在生产中失败(这个数据很重要,后文专门讲)
- • 法律RAG工具幻觉率仍高达17-33%(Stanford研究,2024)
这篇文章面向已经懂基础RAG的技术人,不再解释什么是RAG。直接讲:2024-2025年企业生产环境里在用什么、为什么用、踩过什么坑、效果怎么样。
2、2025年企业RAG技术全景一览
先用一张图看清楚现在企业RAG的技术分布:
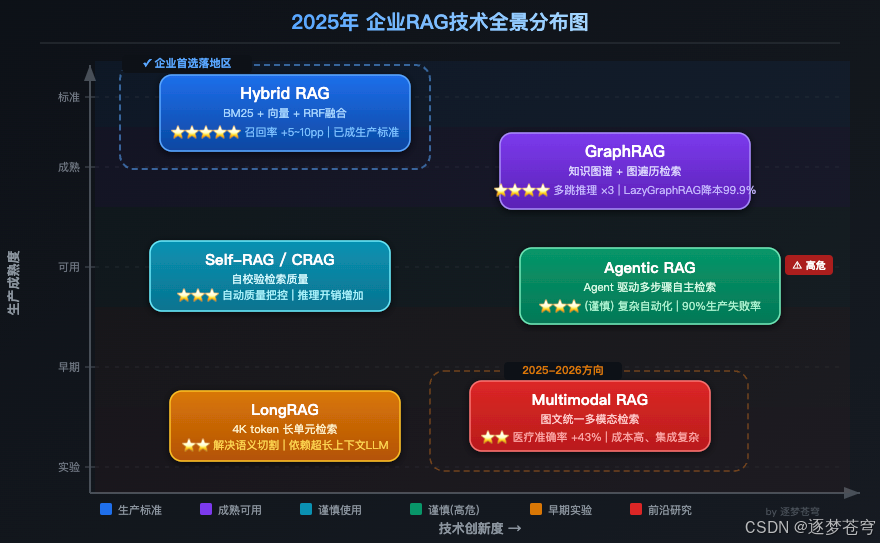
按生产成熟度做一个快速分层:
| 技术 | 生产成熟度 | 核心价值 | 主要风险 |
|---|---|---|---|
| Hybrid RAG | ⭐⭐⭐⭐⭐ | 召回率全面提升5-10pp | 参数调整成本 |
| GraphRAG | ⭐⭐⭐⭐ | 多跳推理准确率×3 | 索引成本高(LazyGraphRAG解决中) |
| Agentic RAG | ⭐⭐⭐(谨慎) | 复杂多步骤自动化 | 90%生产失败率 |
| Self-RAG/CRAG | ⭐⭐⭐ | 自动检索质量把控 | 推理开销增加 |
| Multimodal RAG | ⭐⭐ | 图文统一检索 | 成本高、集成复杂 |
| LongRAG | ⭐⭐ | 解决语义切割问题 | 依赖超长上下文LLM |
从上到下,越往下越新、越实验性。企业级落地优先选择上面三个,后面两个更多是2025-2026年的方向。
3、Hybrid RAG:混合检索已成生产标准
3.1 为什么纯向量搜索被淘汰了
纯向量搜索在通用语义理解上很强,但在企业场景里存在一个致命盲区:关键词精确匹配。
举个典型例子:用户查询"合同编号 SLA-20240315-0089 的服务等级条款",纯向量搜索会找到很多"服务等级协议"相关的文档,但可能就是找不到那份精确合同。原因很简单:向量模型对专有名词、产品编号、法律条款引用这类"精确匹配"信号不敏感。
在法律、金融、监管合规这些企业核心场景里,精确匹配和语义理解同等重要。纯向量搜索在这里的局限性被放大了。
另一个数据也说明了问题:纯向量搜索在基准语料库上约达到75-80%的召回率,理论上限就在这里。而混合检索可以直接提升5-10个百分点。
3.2 BM25 + 向量的黄金组合
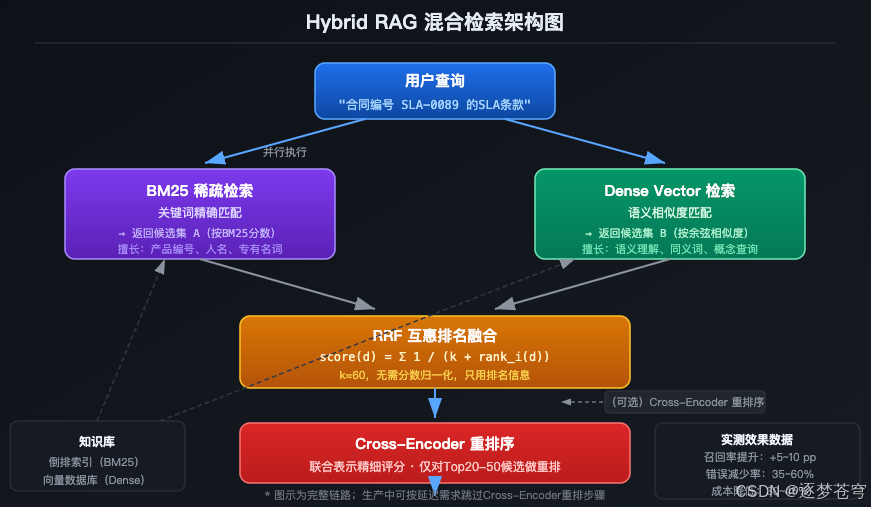
混合检索的核心架构如下:
用户查询 ├── BM25 稀疏检索(关键词精确匹配) │ └── 返回候选集 A(按BM25分数排序) └── Dense Vector 检索(语义相似度) └── 返回候选集 B(按余弦相似度排序) ↓ RRF 互惠排名融合 / 加权分数合并 ↓ Cross-Encoder 重排序(可选) ↓ LLM 生成
**互惠排名融合(RRF)**是最常用的融合策略:
RRF_score(d) = Σ 1 / (k + rank_i(d))# k通常取60,rank_i是文档d在第i个检索器中的排名
这个公式的优雅之处在于:不需要对不同检索器的分数做归一化,只用排名信息,避免了分数量纲不一致的问题。
Cross-Encoder重排序是另一个关键增益点:用一个更精细的模型对TopK候选做二次评分,计算查询和文档的联合表示,准确率更高但延迟也更高(通常仅对Top20-50候选做重排)。
3.3 实际效果数据
用真实数字说话:
- • 混合RAG架构相比单一检索方法:错误减少率35-60%(综合基准)
- • NVIDIA使用Graph+Vector混合架构:金融文件事实忠实度达 96%
- • Azure AI Search研究结论:混合检索+语义重排序是开箱即用的最有效相关性方法
- • LinkedIn集成知识图谱的混合检索:MRR提升77.6%,工单解决时间减少28.6%
- • 智能路由(根据查询类型自动选择检索策略):RAG成本降低30-45%,延迟降低25-40%
什么时候用混合检索:几乎所有企业场景,只要文档里有专有名词、产品编号、日期、人名等精确信息,就应该用混合检索。
什么时候可以不用:纯粹的open-domain问答、知识库文档都是通用知识、对延迟要求极高且精确匹配需求很低的场景。

4、GraphRAG:关系推理的突破
4.1 微软GraphRAG原理
GraphRAG是微软研究院2024年推出的重要创新。传统RAG把文档视为扁平文本,GraphRAG则先把文档中的实体和关系提取出来,构建知识图谱,然后在图谱上做检索。
核心差异:
| 维度 | 传统RAG | GraphRAG |
|---|---|---|
| 数据表示 | 文本块向量 | 实体-关系知识图谱 |
| 检索方式 | 向量相似度 | 图遍历+向量搜索 |
| 查询能力 | 局部相关片段 | 跨文档全局洞察 |
| 代表查询 | “什么是X” | “X与Y的关系”“所有合同的合规风险” |
GraphRAG特别擅长主题级查询:比如"这批500份供应商合同里,哪些存在数据隐私合规风险?"——这类查询需要跨文档汇总,传统RAG很难做好。
性能数据:
- • KG-LM准确率基准:GraphRAG 54.2% vs 纯向量RAG 16.7%,提升3.3倍
- • 模式密集型类别:提升3.4倍
- • Lettria演示:传统RAG答案正确率50% → 混合GraphRAG 80%以上
- • LinkedIn:工单解决时间从40小时降至15小时
4.2 LazyGraphRAG:99.9%成本降低的突破
GraphRAG此前有一个很大的工程障碍:索引成本极高。构建知识图谱需要对全量文档做LLM调用,大型文档库的索引成本可能是普通向量RAG的几十倍,让很多企业望而却步。
2024年11月,微软发布 LazyGraphRAG 解决了这个问题:
核心思路:不在索引阶段预先做LLM摘要和关系提取,而是在查询时按需、迭代地提取概念及共现关系。
效果:
- • 索引成本与向量RAG相同,仅为完整GraphRAG成本的0.1%(降低99.9%)
- • 查询成本比GraphRAG全局搜索降低700倍以上
- • 在所有评估指标上胜过8种竞争方法(具有统计显著性)
这个突破让GraphRAG的工程可行性大幅提升。以前"成本太高,先不考虑",现在没有这个借口了。
4.3 适合哪些场景
适合GraphRAG的场景:
- • 合规审查(供应商合同、监管文件的全局风险评估)
- • 企业知识管理(跨部门、跨文档的关联知识检索)
- • 研究分析(论文、技术报告中的概念关系挖掘)
- • 金融分析(SEC文件、财报的主题分析)
不适合GraphRAG的场景:
- • 简单的单文档问答(2025年2月arXiv:2502.11371系统评估:GraphRAG对简单单文档查询效果不如基线RAG)
- • 对检索延迟要求极高的实时场景
- • 文档更新非常频繁的场景(图谱维护成本)
一句话判断标准:如果你的查询需要"汇总多个文档的共同特征"或者"找出实体间的关联关系",用GraphRAG;如果就是简单的"找这个问题的答案在哪里",用普通Hybrid RAG就够了。
5、Agentic RAG:让RAG自己思考
5.1 架构原理
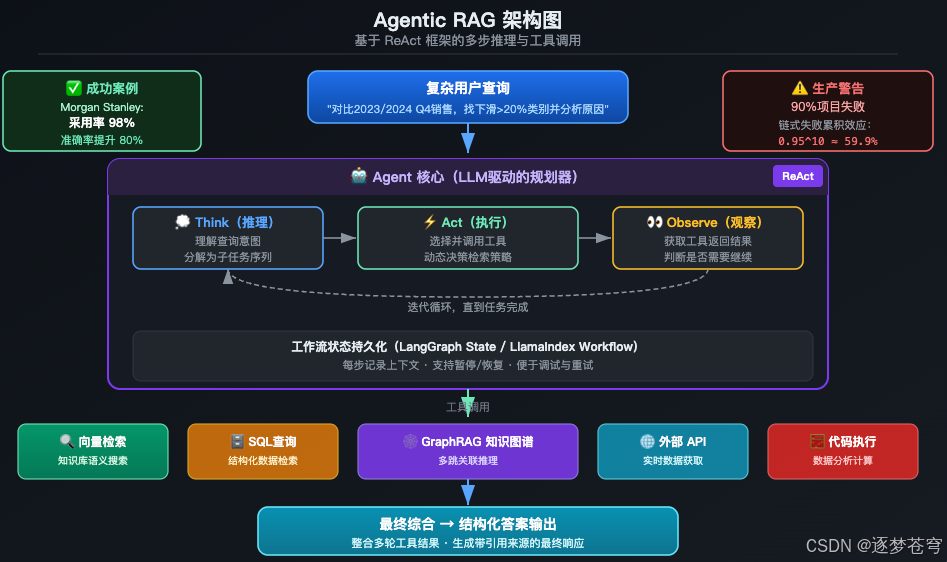
Agentic RAG是把AI Agent嵌入RAG管道,让系统能够自主决策检索策略,而不是固定流程。
核心能力升级:
| 能力 | 传统RAG | Agentic RAG |
|---|---|---|
| 查询处理 | 单次检索 | 多轮迭代检索 |
| 检索策略 | 固定 | Agent动态决策 |
| 工具调用 | 无 | API、SQL、图谱、外部搜索 |
| 复杂查询 | 能力有限 | 分解为子任务 |
| 失败处理 | 无感知 | 自动重试/换策略 |
典型的Agentic RAG工作流(基于ReAct框架):
Query: "对比2023和2024年Q4销售数据,找出下滑超过20%的产品类别并分析原因"→ Agent思考:需要先拿两年的销售数据→ Action: SQL查询 2023 Q4数据→ Observation: [结果...]→ Action: SQL查询 2024 Q4数据→ Observation: [结果...]→ Action: 向量检索 "产品类别下滑原因" 相关文档→ Observation: [市场报告片段...]→ Agent综合分析 → 最终答案
主流实现框架:
- • LangChain LangGraph:图编排、状态持久化、HITL(人在回路)支持
- • LlamaIndex AgentQueryEngine:代理工作流引擎
- • Microsoft AutoGen:多代理协作框架
5.2 为什么90%项目在生产中失败
这是整篇文章最重要的风险提示。
数据来源:2024年行业报告显示,约90%的Agentic RAG项目在生产部署中失败,主要原因是工程团队低估了各层级的累积失败成本。
失败模式分析:
1. 链式失败的累积效应
Agent每调用一个工具,就引入一次失败概率。如果每步成功率95%,10步工作流的整体成功率只有 0.95^10 ≈ 59.9%。在生产环境里,一个40%的失败率是完全不可接受的。
2. 难以调试的不确定性
传统RAG失败了你知道问题在哪(检索结果,生成结果)。Agentic RAG失败了你可能不知道是哪一步、哪个决策出了问题。每次运行的路径可能不一样,复现困难。
3. 成本和延迟爆炸
多步骤工作流 = 多次LLM调用 = 成本线性甚至指数增长。用户等待10秒可以接受,等待60秒几乎不可能。
4. 过度工程化
很多团队在不需要Agent的场景上强行用Agentic架构,为了"炫技"而不是"解决问题"。
5.3 成功落地的关键
那90%失败的,剩下10%是怎么做到的?看几个真实案例:
Morgan Stanley(最成功的Agentic RAG案例之一):
- • 场景:内部金融研究工作流的检索代理
- • 采用率:98%(说明用户认可,不是强制使用)
- • 准确率提升:80%
- • 关键做法:限定在高价值、有边界的金融研究场景,而不是泛用
PwC:
- • 场景:税务和合规用例
- • 成果:自动化**80%**的税务合规流程
- • 关键做法:高度结构化的工作流,减少Agent的自由度
Fisher & Paykel:
- • 场景:客户服务
- • 成果:培训时间减少76%
- • 关键做法:限定领域,高质量知识库
成功落地的几个共同特征:
-
- 限定高价值、有边界的场景,不要做"万能Agent"
-
- 分步骤验证:先验证每个工具调用是否可靠,再组合成工作流
-
- 加入人在回路(HITL):对高风险决策步骤设置人工确认节点
-
- 充分的监控和可观测性:每一步都要记录,方便排查
-
- 渐进式复杂度:从简单的单工具调用开始,逐步增加复杂度
我的判断:Agentic RAG是未来方向,但2025年还需要谨慎对待。如果你的场景用普通RAG能解决80%的问题,先把这80%做好,不要为了Agent而Agent。
6、Multimodal RAG & LongRAG
6.1 Multimodal RAG:多模态统一检索
多模态RAG从2024年开始从实验走向生产化,主要有两条技术路线:
路线一:多模态嵌入
用支持多模态的嵌入模型(如CLIP系列)将文本、图像统一映射到同一向量空间,直接做跨模态语义检索。
路线二:LLM图像摘要
用GPT-4V/GPT-4o将图像内容描述为文字,然后和文本一起存入向量数据库,用统一的文本检索流程处理。这个方案工程实现更简单,目前企业落地更多。
真实效果数据:
- • MMed-RAG(医疗多模态RAG):在5个医疗数据集上平均提升事实准确率43.8%
- • RULE(EMNLP 2024):医疗视觉语言模型,事实准确率平均提升47.4%
- • 医疗合规效率提升:25-30%
- • 实施复杂多模态RAG的企业:生产力提升30-42%
生产挑战要清醒认识:
- • 高计算成本:真正的多模态检索需要大型模型和强力基础设施
- • 跨模态幻觉:图文融合时的幻觉问题比纯文本更难监控
- • 集成复杂度:文本、图像、表格、音频各自的处理管道都不同
我的判断:多模态RAG2025年仍处于"早期采用者"阶段。如果你的核心业务文档包含大量图表(医疗影像、工程图纸、金融图表),值得投入;否则把纯文本RAG先做到足够好更实际。
6.2 LongRAG:解决切块语义割裂问题
LongRAG(Jiang et al., 2024)直指传统RAG的一个根本性缺陷:短块切割导致语义不完整。
传统RAG把文档切割为100词左右的短块,一段完整的论证可能被切得七零八落。每个块单独看都是合理的,但回答需要连贯推理的问题时,拼接出来的答案往往残缺。
LongRAG的解法:将文档处理为4K token的长单元(比传统长约30倍),同时依赖Gemini-1.5-Pro、GPT-4o这类支持超长上下文的LLM作为阅读器。
性能数据:
| 数据集 | 传统RAG | LongRAG |
|---|---|---|
| NQ Answer Recall@1 | 52% | 71% |
| HotpotQA Answer Recall@2 | 47% | 72% |
| NQ EM(精确匹配) | — | 62.7% |
| HotpotQA EM | — | 64.3% |
法律文档分析中,相比传统RAG上下文损失减少35%。
局限性:LongRAG的阅读器必须支持长上下文,目前依赖Gemini-1.5-Pro级别的模型。如果你用的是上下文窗口较小的模型,这个方案不适合。目前仍主要是研究阶段,生产部署相对有限。
7、主流框架选型指南(2025版)
7.1 LlamaIndex vs LangChain/LangGraph 最新对比

两个框架2024-2025年都有重大更新,选型逻辑也更清晰了:
LlamaIndex 2025年核心新特性:
| 功能 | 说明 |
|---|---|
| LlamaParse | 支持90+文件格式,复杂PDF/PPT/图表解析,表格提取为Markdown |
| LlamaCloud | 企业级托管平台,工业级文档解析、索引、检索 |
| Workflows 1.0 | 事件驱动异步工作流,支持暂停/恢复的持久化工作流 |
| 混合检索 | 原生BM25+向量混合+Cross-Encoder重排序 |
| 评估套件 | 内置faithfulness、answer relevancy、context recall,与RAGAS集成 |
| 300+数据连接器 | 覆盖主流数据源 |
LangChain/LangGraph 2025年核心新特性:
| 功能 | 说明 |
|---|---|
| LangGraph | 图编排多代理多步骤工作流;状态持久化;HITL支持;流式输出 |
| Corrective/Adaptive RAG | 原生支持CRAG和自适应RAG工作流 |
| 企业集成 | Salesforce、Microsoft 365、AWS无缝集成 |
| 缓存与内存优化 | 2025年性能增强版,减少内存开销 |
选型建议:
- • RAG应用(数据管道、检索优化) → 选 LlamaIndex,数据处理能力更强,LlamaParse对复杂文档的处理是亮点
- • 多代理复杂工作流(Agentic RAG) → 选 LangGraph,状态管理和图编排更强
- • RAG评估 → 选 RAGAS,目前最广泛使用的RAG评估框架
- • 两者并非非此即彼,复杂项目里LlamaIndex做数据层+LangGraph做工作流层是常见组合
7.2 向量数据库怎么选
向量数据库市场2024年达22亿美元,选型也越来越重要。
各主流向量数据库对比:
| 特性 | Milvus | Weaviate | Pinecone | Qdrant | pgvector |
|---|---|---|---|---|---|
| 类型 | 开源 | 开源+托管 | 完全托管 | 开源 | PG扩展 |
| 规模上限 | 数十亿向量 | 中到大型 | 自动扩展 | 中到大型 | 取决于PG |
| P50延迟 | <10ms | 较高 | 20-50ms | 20-50ms | 竞争力强 |
| 混合搜索 | 有限 | 最强(原生) | 基本 | 良好 | 需扩展 |
| 索引类型 | 11种(最多) | HNSW+倒排 | 专有 | HNSW | HNSW/IVFFlat |
| 成本 | 完全控制 | 灵活 | 按量(偏贵) | 低成本 | 最低(已有PG) |
快速决策矩阵:
- • 无运维需求、严格SLA → Pinecone
- • 需要强混合搜索(向量+关键词+元数据过滤) → Weaviate
- • 十亿级规模、完全控制基础设施 → Milvus(GitHub Star超35,000)
- • 已有PostgreSQL基础设施 → pgvector(pgvectorscale在5000万向量上QPS比Qdrant高11.4倍)
- • 复杂过滤的生产工作负载 → Qdrant
- • 原型和轻量应用 → Chroma
2024-2025年趋势:pgvector因为PostgreSQL生态整合正在加速采用,对于已经有PG的企业,升级成本几乎为零。
8、行业落地案例

8.1 金融:Morgan Stanley的成功范本
Morgan Stanley内部RAG代理:
- • 场景:内部金融研究工作流,分析师查询公司研究报告、市场数据
- • 结果:98%采用率,准确率提升80%
- • 为什么成功:场景高度明确(金融研究),知识库边界清晰,用户群体是专业分析师
Morgan Stanley DevGen.AI(Agentic RAG代码现代化):
- • 基于GPT-4的代码分析代理
- • 已审查:900万行代码
- • 节省:28万开发小时
其他金融案例:
- • 某跨国银行(Squirro合作):AI工单处理跨境支付异常,每年数百万条,节省数百万美元运营成本
- • SEC文件分析:GraphRAG提供比纯向量RAG更具体的市场影响分析
8.2 法律:高准确率背后的幻觉警告
法律AI是RAG落地最热门的场景之一,但也是风险最高的场景。
Stanford重要研究:LexisNexis和Thomson Reuters的法律AI工具(均使用RAG),幻觉率仍在**17-33%**之间。
这意味着什么?每处理100份法律文件,可能有17-33份包含不准确的信息。在法律实践中,这可能导致错误的法律意见、错误的案例引用、甚至误导诉讼策略。
Law援助机构用LongRAG做文档分析,上下文损失减少35%,但这并不意味着幻觉问题解决了——LongRAG解决的是语义完整性,幻觉还需要额外的验证机制。
我的判断:法律RAG必须有人工复核环节,不能端到端自动化。至少在幻觉率降到5%以下之前,法律从业者使用RAG工具时必须保持高度警惕。
8.3 医疗、IT服务等
医疗行业:
- • IBM Watson for Oncology:治疗建议与专家肿瘤医生匹配率96%(《临床肿瘤学杂志》研究)
- • Radbuddy:肺健康AI聊天机器人,基于RAG结合内部诊断协议+实时预约数据
- • 放射科QA:Agentic RAG将准确率从68%提升至73%
- • 多模态医疗RAG(MMed-RAG):事实准确率提升43-47%
IT服务:
- • ServiceNow:多轮RAG IT工作流,缓存检索管道加速重复事件处理
- • Fisher & Paykel:客户服务Agentic RAG,培训时间减少76%
- • LinkedIn:图谱+混合检索,MRR提升77.6%,解决时间减少28.6%
PwC税务:
- • 使用Agentic RAG自动化**80%**的税务合规流程
- • 这是Agentic RAG的成功案例,关键是税务合规流程本身有清晰的规则边界
9、总结:企业RAG技术选型建议
2024-2025年企业RAG的核心变化是从"能用"到"好用",从"单一技术点"到"技术组合"。
技术选型核心建议:
第一步:把混合检索作为基础设施标准
不管用什么上层技术,底层检索层请用Hybrid RAG(BM25+向量+RRF)。这是投入产出比最高的升级,几乎没有理由不做。
第二步:按场景决定是否引入图谱
- • 有大量多跳推理、关联分析需求 → 试用LazyGraphRAG(现在成本已经不再是障碍)
- • 简单问答场景 → 普通Hybrid RAG,GraphRAG得不偿失
第三步:Agentic RAG要小步快走
- • 不要上来就做复杂的多Agent系统
- • 先用单Agent + 少量工具,把可靠性做到90%以上,再增加复杂度
- • 高风险决策必须加人工确认节点
第四步:评估先行
接入RAGAS或LlamaIndex内置评估套件,建立基线指标(faithfulness、answer relevancy、context recall),再做技术改进。没有指标的优化是盲目的。
关键风险提示:
- • 法律、医疗等高风险场景:不能完全信任RAG输出,必须人工复核
- • Agentic RAG:90%生产失败率是真实数字,谨慎评估复杂度
- • 安全威胁:BadRAG/TrojanRAG等文档投毒攻击真实存在,企业RAG需要考虑检索层安全
2025年最值得跟进的方向:
- • LazyGraphRAG的工程化实践(成本降低让GraphRAG可行性大幅提升)
- • LangGraph的Agentic工作流模式(相对成熟的工程实践)
- • RAG安全(被严重低估的方向)
最后用一句话总结:混合检索是现在,GraphRAG是进阶,Agentic RAG是未来但要谨慎,评估体系贯穿始终。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献614条内容
已为社区贡献614条内容

所有评论(0)