Hypergraph Random Field Model for Multiple Object Tracking in Dense Scenarios
密集场景MOT会因为相互遮挡与冗余检测导致特征丢失、累计误差,出现 ID switch 和误匹配传统轨迹-检测二分图有一对一匹配限制在“频繁出现相似目标”的密集场景容易失败提出 Hypergraph Random Field (HRF),引入两类超节点,分别为trajectory hypernodes和domain hypernodes将 tracking 抽象为图,图中包含三类节点:①当前帧检测
简介:
时间:2026
期刊:Applied Intelligence
作者:Junwen Zhang, Xiaolong Zhang, Ziqi Zhu, Chunhua Deng
摘要:
密集场景MOT会因为相互遮挡与冗余检测导致特征丢失、累计误差,出现 ID switch 和误匹配
传统轨迹-检测二分图有一对一匹配限制在“频繁出现相似目标”的密集场景容易失败
提出 Hypergraph Random Field (HRF),引入两类超节点,分别为trajectory hypernodes和domain hypernodes
创新点:
①HRF:用概率推断在高阶结构上学习“轨迹—候选检测”的复杂依赖
②trajectory/domain hypernode 联合建模
③通过分解成 trajectory HRF 得到闭式解,保证实时性
引言:
现有的跟踪方法大多为二部图模型来将轨迹与检测框进行匹配:
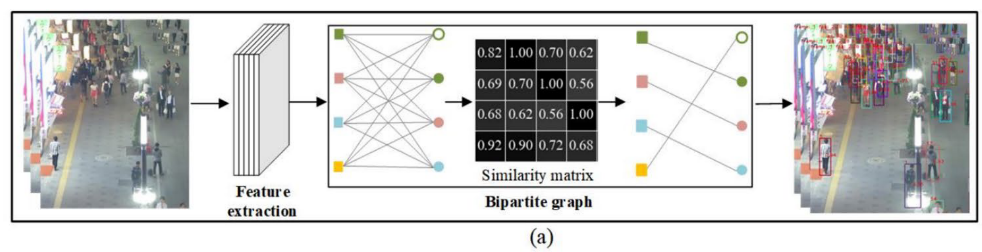
bipartite graph 在密集场景不够:
一对一匹配假设在遮挡/外观变化/形变时无法捕捉更高阶依赖,导致 ID switch、冗余检测匹配错误
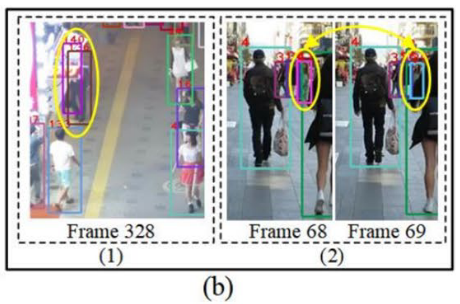
已有改进路线与不足:
①SORT / ByteTrack 等在匹配策略上引入低置信框等
②CRF、能量最小化方法能建模上下文,但复杂度限制实时性
③超图/高阶方法能表达多体关系,但常依赖预定义结构,适应性不足
相关工作:
Joint-detection-and-tracking + 二分图匹配:主流、高效、实时
CRF / 全局优化:增强一致性但计算代价高
深度/Transformer/GNN 等:性能强但依赖大规模标注数据、泛化受限
超图/高阶结构:更强语义表达,但很多方法结构固定或冗余检测累积反而伤性能
由此引出本文的方法,强调 HRF 的“结构适应 + 概率推断”。
方法:
二部图模型通常受到轨迹和检测之间一对一关系的限制,为了克服这一限制,引入超节点来扩展轨迹和检测之间的关联。

通过二部图模型进行多对象跟踪:
建立 baseline tracking 数学模型
三类节点定义:
将 tracking 抽象为图,图中包含三类节点:
①当前帧检测
检测器输出:
每个检测:
其中表示外观特征(ReID embedding),
表示左上角,
表示bbox
②历史观测
历史检测:
保存过去已确认 ID 的观测,是trajectory 的原始组成元素
③轨迹节点
轨迹由历史检测组成:
其中:
代表一个正在跟踪的目标
轨迹外观建模:
采用平均融合,结合历史检测框的外观特征:
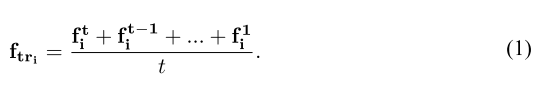
运动预测Kalman Filter:
预测阶段:

其中为运动模型,
为不确定性,
为运动噪声
更新阶段:
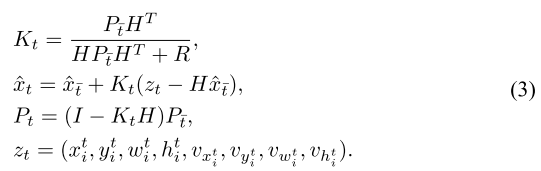
其中为卡尔曼增益,
为测量矩阵,
为测量噪声协方差矩阵,
为第
帧处的测量向量
该公式即预测 + 当前观测融合,得到轨迹下一位置。
相似度矩阵:
建立:
表示轨迹 与检测
是否属于同一目标。
IoU 相似度:
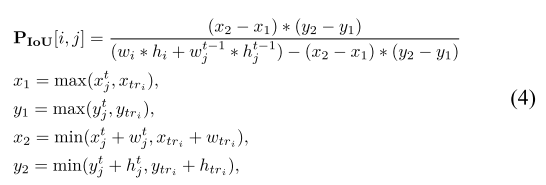
衡量空间重叠,表示位置接近程度。
外观相似度:
为余弦相似度

最终匹配权重:
即位置或外观,任一可信即可
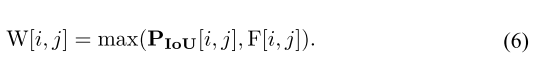
问题:
二分图假设轨迹和检测是一对一的关系,但密集场景一个目标会对应多个检测,且相似的人容易交换ID,因此失败。
建立HRF:
不再做结构匹配,而是做概率推断,这种方法增强了模型的实用性,允许根据不同场景定义不同大小的超图随机场模型。
超图随机模型定义了两种类型的超级节点:由历史检测节点组成的历史检测超级节点和由候选检测节点组成的领域超级节点。
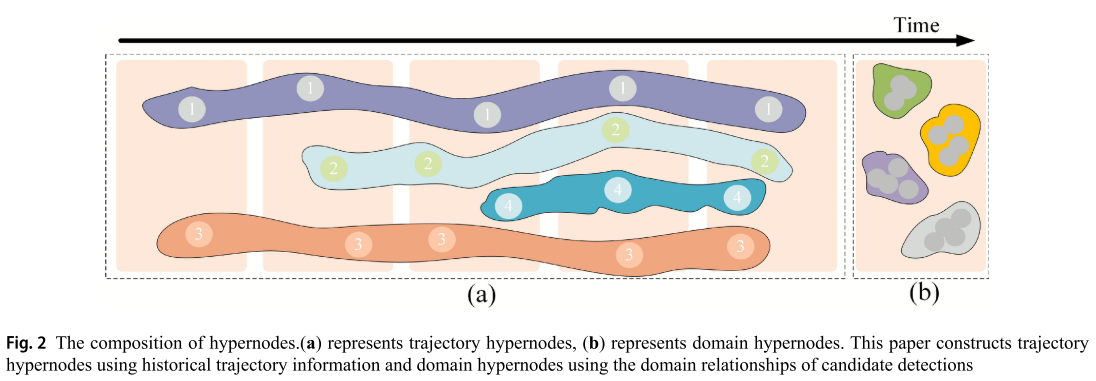
引入 Hypernodes:
普通图是一个T对应一个D,而超图可以将一个T对应多个D,允许一对多关系。
Trajectory Hypernode:
定义:
但区别是只使用最近帧
长期轨迹容易导致累积误差和外观错误,滑动窗口更稳定
改进 Kalman:
为了提高跟踪效率,本文提出了一种改进的卡尔曼滤波算法,以线性方式融合帧的轨迹信息。
考虑到行人运动的有限变化,假设:

避免重复更新
预测改为:
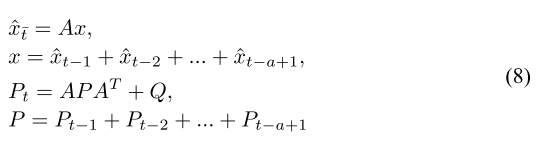
结合了滑动时间窗的记忆机制,对目标运动趋势的建模更加鲁棒,比单帧状态预测更平滑、更抗干扰,尤其是在轨迹轻微抖动的情况下。
更新后:
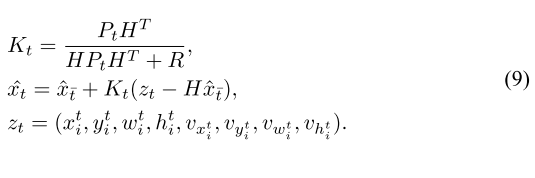
Domain Hypernode:
进一步增强候选检测特征信息并扩大跟踪模型的搜索范围,本文引入域超节点,定义为:
其中,表示域超级节点的总数
每个 domain hypernode包含多个 detection,直观来看是遮挡区域多个检测框合成一个 domain
作用:
聚合局部上下文,处理冗余检测,扩大搜索空间
将 one-to-one association 转为 one-to-many association

Hyperedges:
普通边:
表示候选检测之间的关系:
超边:
是普通边的组合,可分为四种类型包含四类
| 类型 | 具体表示 | 连接 |
| trajectory ↔ domain | ||
| trajectory ↔ detection | ||
| domain ↔ detection | ||
| domain ↔ domain |
能量最小化问题:
将MOT的数据关联转化为超图随机场求解问题。
随机场的能量公式一般定义如下:
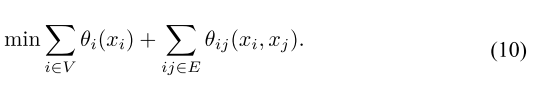
其中,是一个一元公式表示概率的
,
是一个二元公式表示
和
间的关系
HRF能量函数:
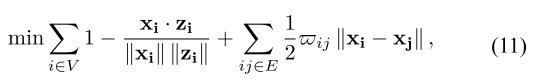
优化目标为找到所有节点与轨迹之间的最优相似关系,再交给 Hungarian 做最终匹配。
每个候选节点只有一个检测和一个特征。
轨迹子随机场:
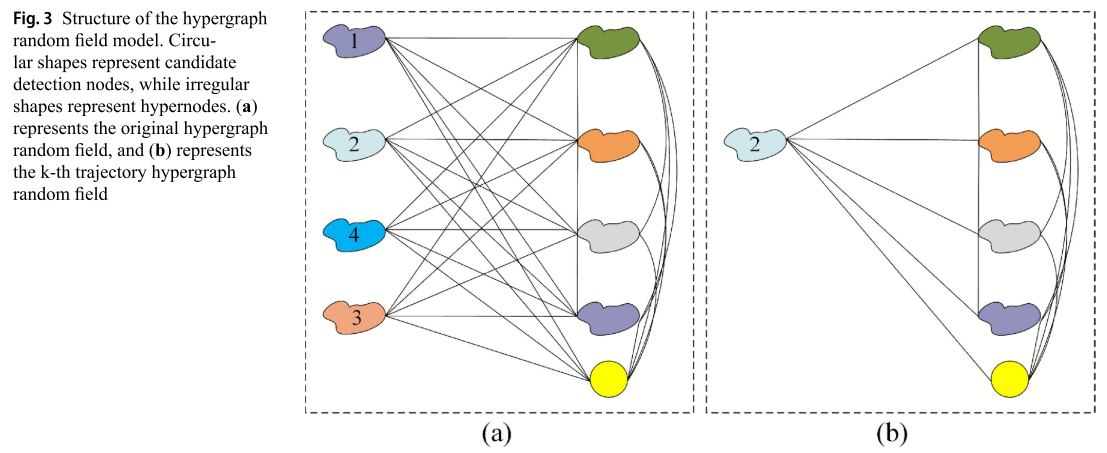
直接迭代求解整个 HRF 的复杂度是,不适合在线跟踪,所以提出一个“按轨迹拆分”的近似解法。
将超图拆分为多个轨迹超图随机场模型,每个模型都具有基于轨迹的闭合部分。
把大 HRF 拆成 n 个“以轨迹为中心”的子图:
按每条轨迹构建一个子随机场
(Fig.3(b)),每个子图包含:
①这条轨迹的轨迹超节点
②所有 domain hypernodes
③所有 candidate detections
形式化定义:
变量从“同时求所有轨迹”变成“只求轨迹 k 的关联概率/相似度”
节点间相似度权重:
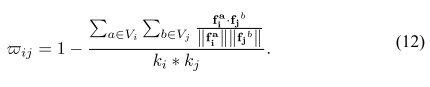
指示量:
轨迹超节点的:one-hot(因为轨迹 ID 已确定)

domain/candidate 节点的 :用其内部检测与轨迹框的 IoU 平均来定义
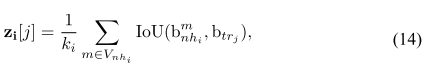
轨迹子模型能量函数:
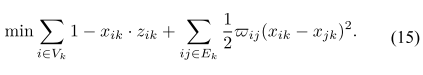
第一项(贴近先验/方向):让与
一致(
大的地方,
倾向更大)
第二项(平滑一致性):如果两个节点 外观/上下文相关,那么它们对轨迹
的得分
不应差太大 —— 这就是典型的“图平滑/label propagation”思想
闭式解把 (15) 写成矩阵形式:
把 (15) 化简为矩阵目标(式16):
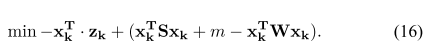
并定义为
组成的矩阵:

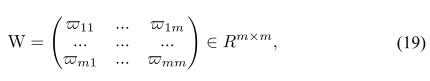
是度矩阵(式18):对角元是行和
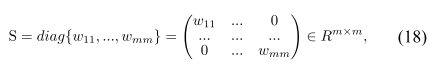
然后进行图拉普拉斯产生“平滑传播”的解,对 (16) 求导置零,得到闭式解(式20):

把所有轨迹的拼成矩阵
,一次性算出所有轨迹的解(式21):

所以复杂度从“对每条轨迹迭代求解 + 相互耦合”变成“一次矩阵运算得到所有轨迹结果”,论文据此说复杂度降到 (在线更友好)
匹配流程:
先解出:
也就是每条轨迹对所有节点的分数向量
。
用 Hungarian algorithm 得到最终 pairing

虽然 HRF 是 one-to-many 建模,但最终输出仍需要“一帧里每条轨迹挑一个结果” → Hungarian 负责把“软分数矩阵”变成“硬匹配”。
在每个 domain hypernode 内,选择阈值最高的 detection 作为最终结果,其余视为冗余检测丢弃。
实验:

结论:
本文提出了一种称为超图随机模型的新型多目标跟踪算法,该算法利用超节点有效解决了由于遮挡而导致的跟踪问题和冗余检测问题。 此外,还提出了一种提高跟踪效率的方法。 为了验证所提算法的有效性,在MOT15、MOT16、MOT17和MOT20数据集上进行了消融实验和对比实验。 结果表明,该算法表现良好,在跟踪性能方面优于许多其他优秀方法

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)