告别收藏夹吃灰!我开发了一款基于大模型的 Chrome/Edge 书签自动分类插件
本文介绍了一款基于大语言模型的Chrome插件,它能自动分析网页内容并智能分类书签,解决了手动管理书签的痛点。文章详细分享了其核心功能、技术实现细节(如内容提取、Prompt工程、免费中转通道构建)以及隐私保护设计。
告别收藏夹吃灰!我开发了一款基于大模型的 Chrome/Edge 书签自动分类插件
插件目前是完全开源免费的,有兴趣的小伙伴可以去体验一下,欢迎分析使用感受!
安装地址: edge商店
注:其他浏览器商店会陆续上线。(其他浏览器想体验的暂时可以去下载relese版本压缩包使用! )
GitHub 开源地址:AI书签整理 (AI Bookmark Organizer)
💡 缘起:为什么要做这个插件?

作为一个重度浏览器用户,我的书签栏里总是堆满了各种“稍后阅读”的链接:技术文章、开源工具、设计素材、日常新闻…… 久而久之,书签栏变得像一个深不见底的杂物箱。每次想要找之前收藏的某个工具时,如同大海捞针。
虽然市面上也有一些书签管理工具,但大多需要手动建文件夹、打标签,这完全违背了“稍后阅读”那随性的一键收藏初衷。
既然现在大语言模型(LLM)这么聪明,为什么不让 AI 来帮我做这种繁琐的归类工作呢?于是,AI 书签整理 (AI Bookmark Organizer) 诞生了。
✨ 核心功能亮点
这是一款轻量级的浏览器插件(Manifest V3),主打核心痛点:在你点击收藏的瞬间,利用 AI 自动分析网页内容,并将它移动到最合适的文件夹中。
- 深度分析,告别“标题党”:不只看网页标题,插件会动态提取网页的
description、keywords以及前 1000 个字符的正文内容,让 AI 真正理解网页主旨。 - 灵活的建夹策略:
- 保守:仅归类到你现有的文件夹中,绝不弄乱你的当前结构。
- 平衡/激进:如果当前没有合适的文件夹,允许 AI 根据内容自动为你建立一套科学的知识树。
- 多模型自由切换:支持 OpenAI (ChatGPT)、Google Gemini、DeepSeek,甚至是本地部署的 Ollama。
- 开箱即用的“白嫖”模式:为了降低使用门槛,我内置了一个基于 Cloudflare Worker 搭建的免费默认通道(通过官方代理转发给 DeepSeek),用户甚至不需要配置任何 API Key 就能直接使用。
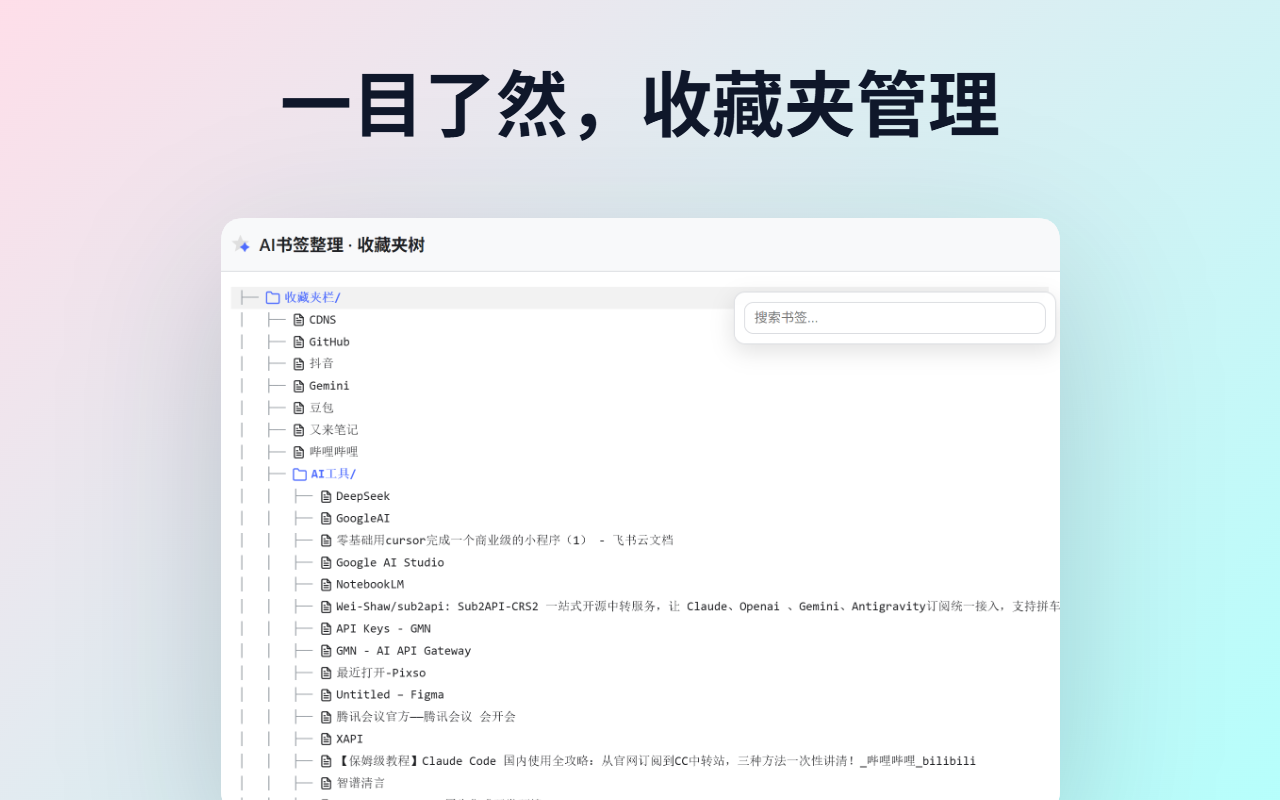
- 极客风的收藏夹管理:内置了一个 CLI 命令行风格的“收藏夹树”页面,让你对成百上千个书签层级一目了然。
🎨 交互设计:把“无感”做到极致
作为一款辅助工具,最好的体验就是“不要打断用户”。在设计这款插件时,我花了很多心思在交互的“做减法”上:
1. 零打扰:舍弃复杂的选择确认,改为后台自动分类
传统的书签整理工具往往会弹出一个巨大的对话框,让你手动选择目录、打标签、点确认,一套流程下来思路全被打断了。
在这个插件中,我追求的是**“阅后即焚式”的收藏体验**。当你点击悬浮按钮或使用快捷键(Alt+Shift+S)时,分析和归类全部交给 background.js 在后台静默完成。当前页面只会在右下角出现一个轻量级的 Toast 提示(“分析中…” -> “已收藏至:技术文档”),你的视线和心流完全不需要离开当前正在阅读的内容。

2. 闭环体验:用“历史记录”解决“找不着”的痛点
全自动分类带来了一个新的体验痛点:“AI 确实帮我收起来了,但我马上想用的时候,它到底被放去哪个文件夹了?”
为了弥补这种自动化带来的“失控感”,我在点击扩展图标弹出的 Popup 面板中,专门设计了一个**“最近记录”**功能。这里一目了然地展示了最近收藏的网页、以及 AI 为它们分配的分类目录。如果你对 AI 的分类不满意,甚至可以在历史记录里一键“取消收藏”。这既保留了自动化的爽快,又给了用户随时兜底的掌控感。
3. 全局掌控:高信息密度的“CLI 风格”收藏夹树
当书签积累到几百上千个时,浏览器原生的书签管理器那冗长的折叠菜单简直是反人类。
为此,我专门开发了一个独立的**“收藏夹树”管理页面**。在视觉上,我摒弃了传统的臃肿卡片或图标,采用了类似 Linux 终端 tree 命令的纯文本高密度排版(CLI 风格)。
- 信息密度极高:一屏可以清晰展示几十甚至上百个节点的关系,连线结构清晰可见。
- 沉浸式查找:配合顶部的全局实时搜索,无需层层点开文件夹,只需上下滚动或搜索,就能在庞大的知识库中瞬间定位目标。
- 快捷操作:支持原生的右键呼出自定义菜单,随时进行重命名、移动或删除。
🛠️ 技术实现细节与踩坑记录
项目使用了纯原生的 HTML/CSS/JS (ES6+) 开发,没有任何沉重的框架,保证了插件的轻量和极速响应。下面分享几个开发过程中的技术难点:
1. 如何优雅地提取网页内容并避免 Token 超限?
早期的想法是把整个 HTML 扔给 AI,但很快发现不仅耗时,还会轻易超过各种 API 的上下文 Token 限制。后来我利用 Chrome 的 scripting API 实现了精准的元数据提取:
// background.js 核心片段
const executionPromise = chrome.scripting.executeScript({
target: { tabId: tabId },
func: () => {
const description = document.querySelector('meta[name="description"]')?.content || '';
const keywords = document.querySelector('meta[name="keywords"]')?.content || '';
// 限制正文字数,替换多余空格
const body = document.body ? document.body.innerText.substring(0, 1000).replace(/\s+/g, ' ') : '';
return { description, keywords, body };
}
});
这种截断前 1000 字符的策略,在保留了网页核心信息的同时,将 Token 消耗控制在了极低的范围内,分析速度飞快。(并且非常省钱,单个网页收藏分类都不超过0.01元)
2. Prompt Engineering:如何让大模型乖乖听话?
为了让 AI 输出的分类精准且符合规范,我设计了一套灵活的 Prompt 系统。不仅要告诉 AI 现有的文件夹列表,还要根据用户的策略设置进行约束:
// 约束条件的动态生成
let strategyZh = '';
switch (folderCreationLevel) {
case 'off': strategyZh = '严格从“现有文件夹”中选择。禁止新建文件夹。'; break;
case 'weak': strategyZh = '优先使用现有文件夹。只有在内容与现有文件夹完全无关时才新建。'; break;
case 'strong': strategyZh = '如果现有文件夹不够精准,请积极新建文件夹。优先保证分类准确性。'; break;
}
// 强制 JSON 输出
const prompt = `请分析网页信息并进行书签分类。
网页标题:${title}
现有文件夹:${foldersStr}
规则:
1. 策略:${strategyZh}
2. 必须返回JSON格式:{"category": "分类名", "title": "简化标题"}`;
在解析时,为了应对大模型偶尔“发疯”加入 Markdown 代码块,我使用了正则匹配 text.match(/\{[\s\S]*\}/) 来安全地提取 JSON。
3. 构建免费的中转通道 (Cloudflare Worker)
为了让小白用户也能零配置用上 AI,我用 Cloudflare Worker 写了一个极简的网关。但直接暴露 API Key 是非常危险的,随时可能被黑客盗用。
因此,我在 Worker 里加入了业务场景校验:
// worker.js 安全校验拦截
const body = await request.json();
const messages = body.messages || [];
const lastMessage = messages[messages.length - 1]?.content || "";
// 只有包含插件特有提示词的请求才会被转发,防止被薅羊毛用作通用聊天
const requiredKeywords = ["书签分类", "现有文件夹"];
const isValidBusinessRequest = requiredKeywords.some(keyword => lastMessage.includes(keyword));
if (!isValidBusinessRequest) {
return new Response(JSON.stringify({ error: "Forbidden: 此接口仅供书签分类插件使用" }), { status: 403 });
}
通过这种方式,加上 Chrome 扩展来源的 Origin 校验,成功保护了后台的 DeepSeek API Key。
4. 网页右下角的丝滑悬浮按钮
为了方便用户,我在 content.js 注入了一个悬浮按钮。但悬浮按钮经常会遮挡网页右下角的客服按钮或返回顶部按钮。
为此,我用原生 JS 实现了一套兼容鼠标和触摸屏的拖拽逻辑 (makeDraggable),判断用户是“点击”还是“拖拽”,并且在检测到拖动时暂时注销点击事件。而且还加入了暗色模式自动检测:
// 简单的暗色模式推断
const bgColor = window.getComputedStyle(document.body).backgroundColor;
const rgb = bgColor.match(/\d+/g);
const brightness = Math.round(((parseInt(rgb[0]) * 299) + (parseInt(rgb[1]) * 587) + (parseInt(rgb[2]) * 114)) / 1000);
if (brightness < 128) btn.classList.add('aibook-dark-mode');
🔒 隐私先行
由于涉及用户的浏览记录和书签,插件从架构设计上就杜绝了隐私泄露:
- 不设独立账户系统:所有的配置(包括你填写的 ChatGPT / DeepSeek API Key)和历史记录,全部通过 Chrome 的
chrome.storage存储在本地,不会上传至任何无关服务器。 - 按需触发:插件仅在你主动点击“智能收藏”时,才会提取当前页面的信息发送给模型,绝不会在后台偷偷爬取你的页面。
🚀 后续规划
目前 V1.0.1 版本已经实现了基础的核心闭环。接下来我计划加入:
- 批量整理现有书签的能力(目前主要侧重于新增时的分类)。
- 支持更多本地化 LLM 推理框架对接。
- 自定义系统 Prompt,让高端用户能自己定制分类逻辑。
欢迎大家去 Edge 扩展商店搜索 “AI Bookmark Organizer” 或 “AI书签整理” 体验(或者直接在开发者模式下加载本项目源码)。
如果您觉得好用,希望能不吝赐教提出宝贵意见!也欢迎技术同好交流插件开发的那些坑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)