【与AI+】SAP查询结果不一致之谜:为何DB02与SE16N看到的数据不一样?
为何DB02与SE16N看到的数据不一样
前言:这是我的水水专栏第九篇文章,这个专栏呢,是放一些我向AI提问的问题,以及AI的回答。因为水平实在有限,有时候有些知识点还是不能连成线,所以会有很多奇怪的问题,网站上也是众说纷纭,脑袋锈掉了,只好向AI提问帮忙解答,感觉要被AI统治了~ps:不用动脑想排版的感觉真好~
我不是很确定我的专栏文章内容是否涉及版权,以及也不确定这些整合过的文字是否涉嫌抄袭,所以,如有雷同或是有不小心参考到了您的文章的情况,请立即私聊我,卑微Sesy在线求饶!知识点仅供参考,请酌情查看!!
这个案例是我在最近开发中遇到的真实问题,找不到原因,只好求助了AI,感谢deepseek,真正帮我解决了问题,也帮我解惑了,直接再让deepseek帮我生成一下经验帖,分享给大家!

以下是由deepseek生成的答案:
目录
四、知识点扩展:DB02 SQL 与 ABAP SQL 的本质区别
一、案例描述:一个令人困惑的查询差异
最近在SAP系统中遇到一个有趣的问题:
首先看一下SE16N里面的数据,可以看到MSKUH表里面是有2024年度02月份的数据的:
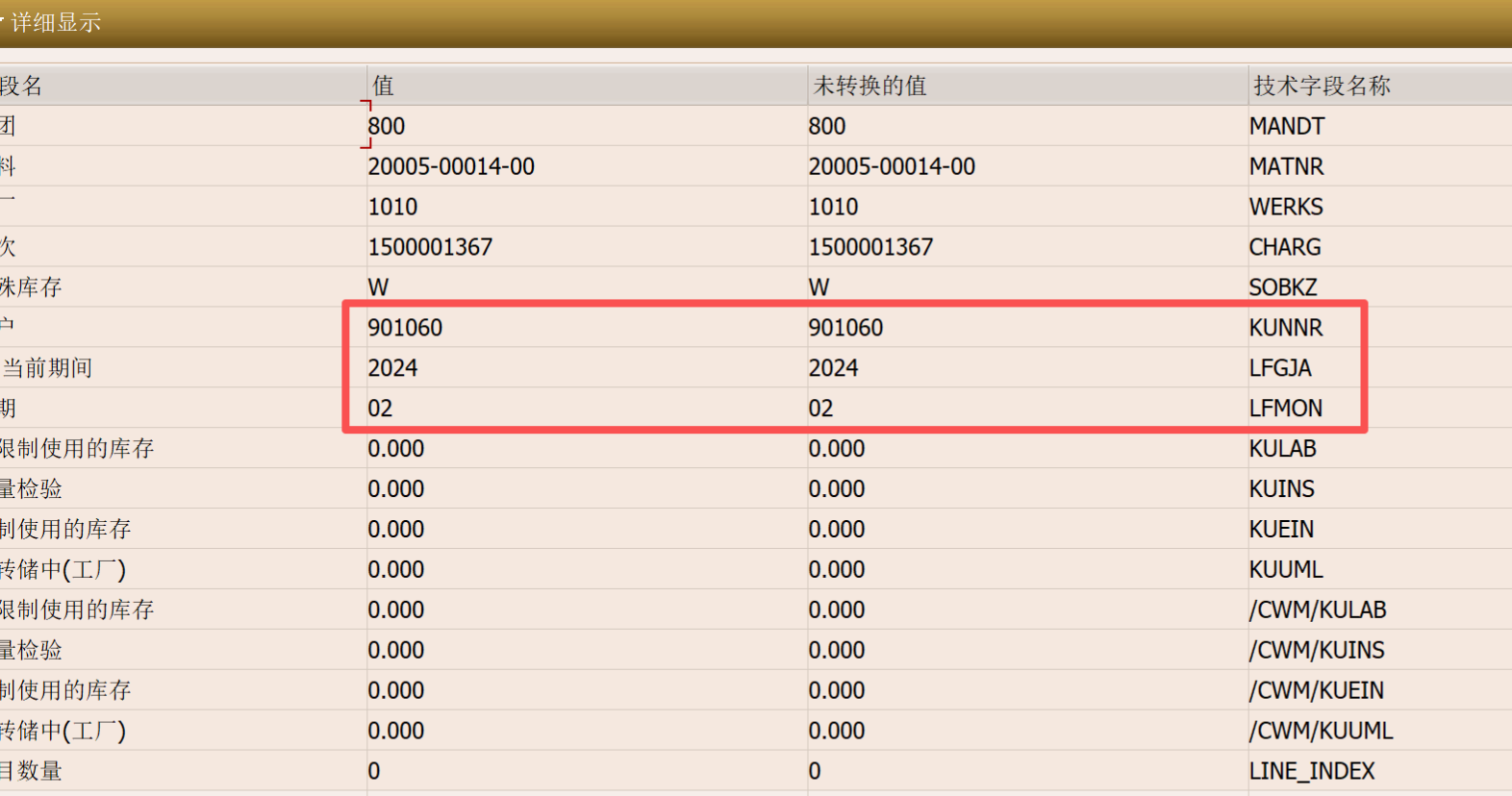
但是当我使用事务代码DB02查询物料凭证表MSKUH时,发现两个SQL语句返回了不同的结果。
语句1(查不到数据):
SELECT A.MATNR
FROM MSKUH A
WHERE A.LFGJA = '2024'
AND A.LFMON = '02'
AND A.WERKS IN ('1010', '1011');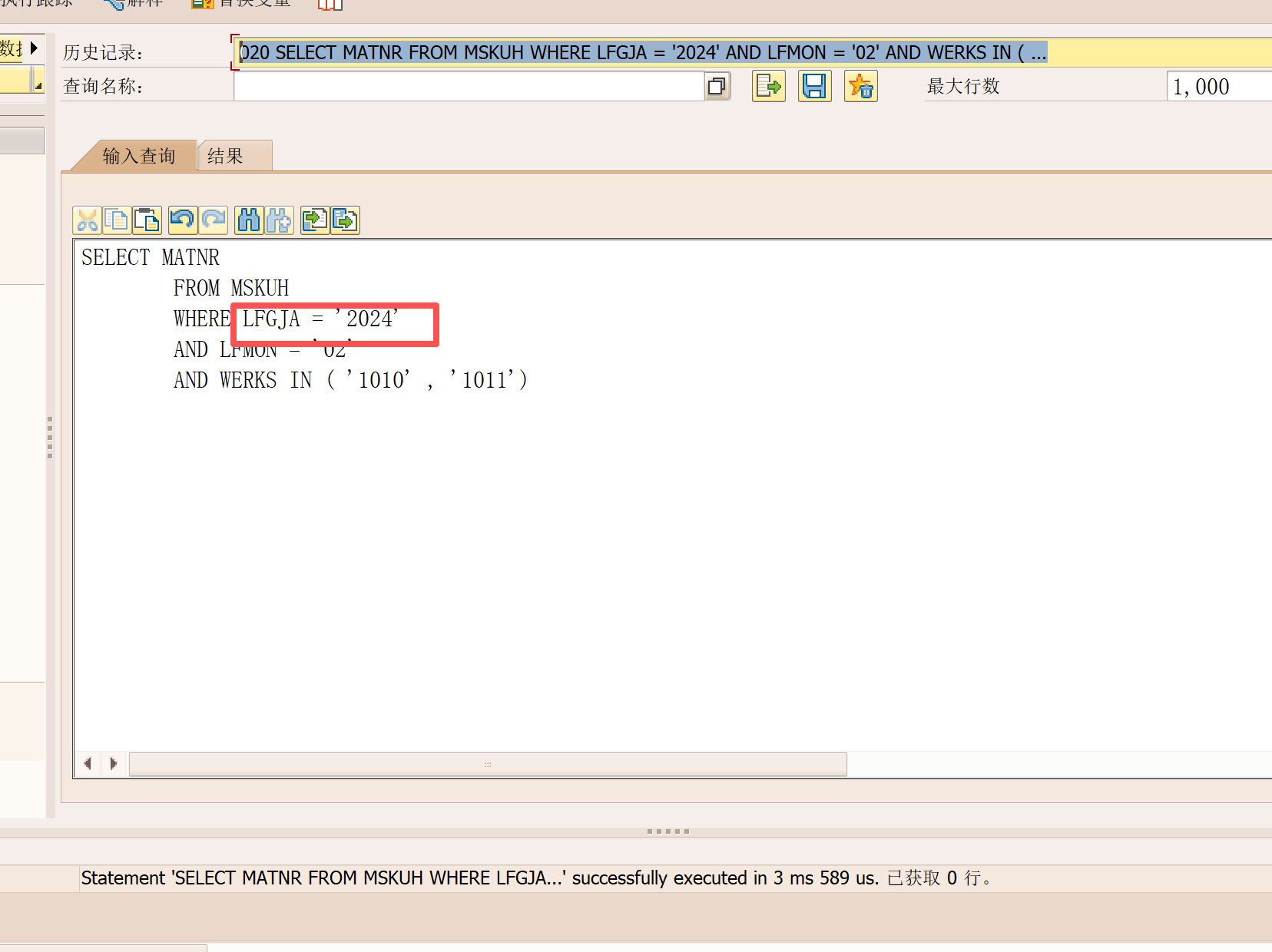
语句2(能查到数据):
SELECT A.MATNR
FROM MSKUH A
WHERE A.LFMON = '02'
AND A.WERKS IN ('1010', '1011');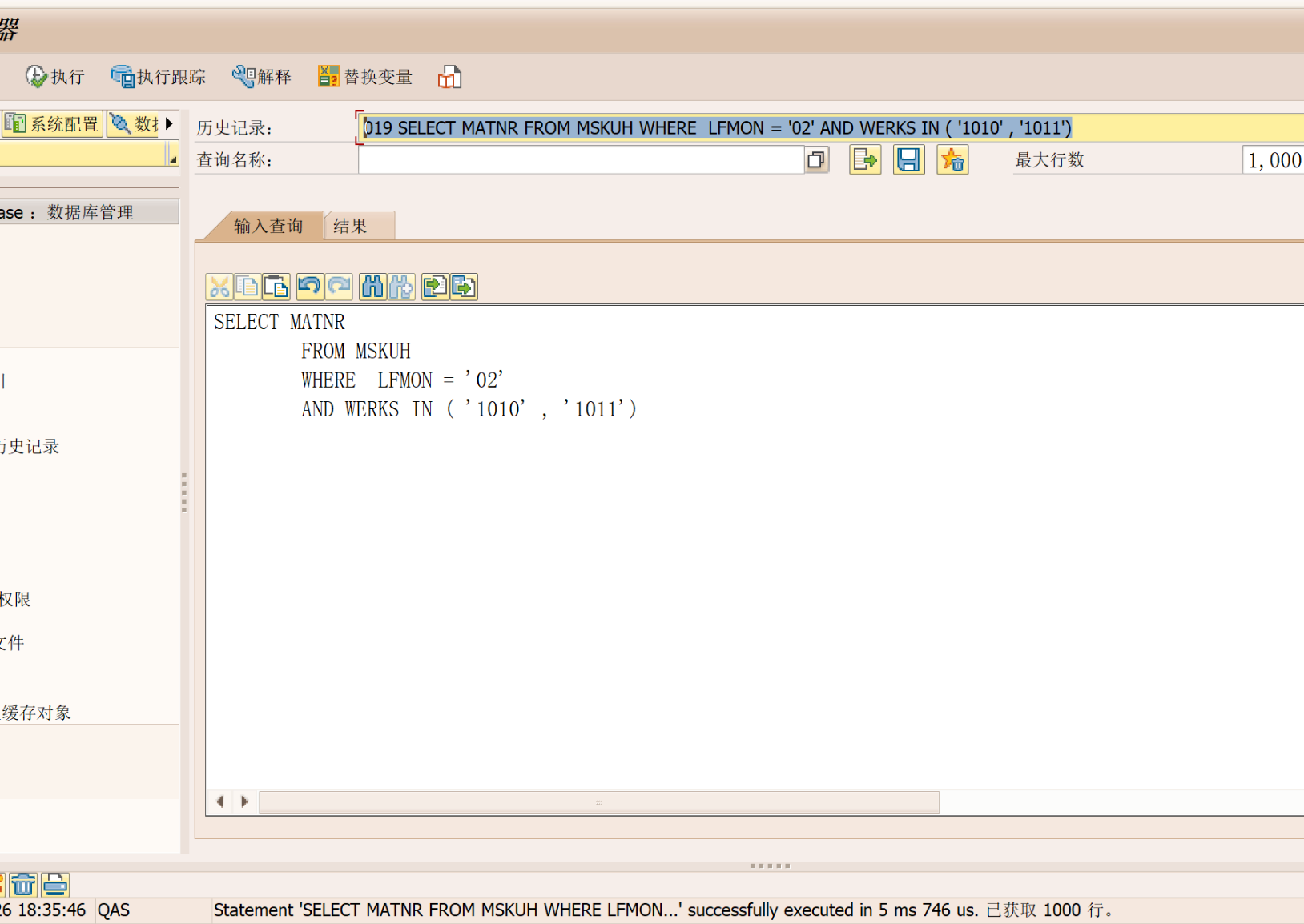
按理说,数据库中应该存在同时满足年份LFGJA = '2024'和月份LFMON = '02'的数据,但加上年份条件后却返回空。更奇怪的是,当我用SELECT DISTINCT LFGJA FROM MSKUH WHERE LFMON = '02'查询时,发现LFGJA只有2015到2022年的值,根本没有2024年。
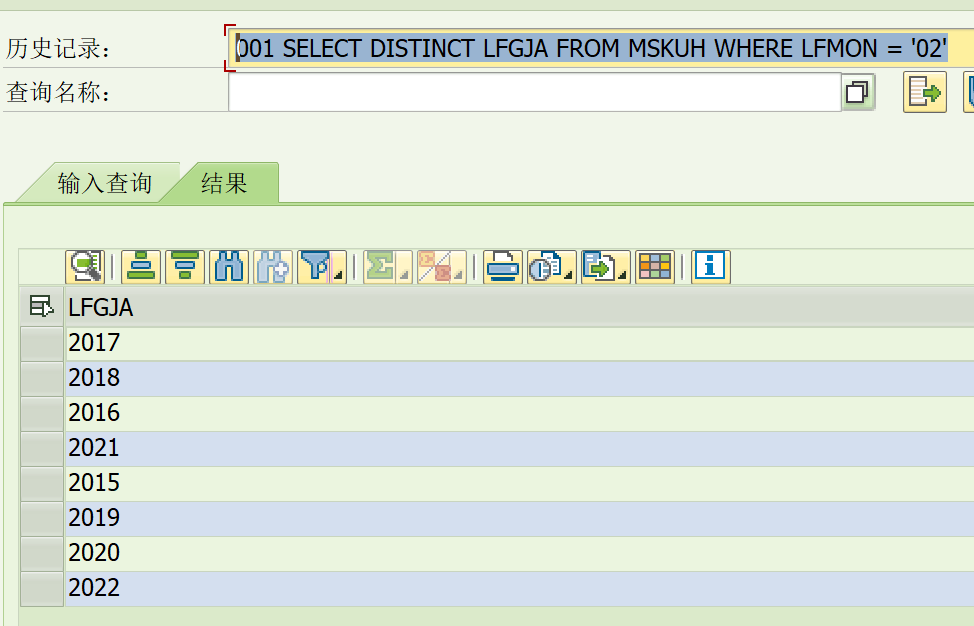
然而,在事务码SE16N中直接查看表MSKUH,却能看到2024年的数据!
这种“SE16N能看到,DB02的SQL编辑器却查不到”的现象,究竟是怎么回事?下面我就来抽丝剥茧,找出背后的原理。
二、原因分析:SAP的双重数据世界
要理解这个现象,首先需要了解SAP系统中数据的两种存在形式:
-
数据库持久层:数据最终存储在硬盘的数据库表中,是物理存在的“冷数据”。
-
SAP应用服务器缓存:为提升性能,SAP会将常用表的数据加载到应用服务器的内存中,形成“热数据”。当通过ABAP程序(如SE16N)查询开启了缓冲的表时,会优先读取缓存。
我的两个查询工具正好对应了这两个层面:
-
DB02的SQL编辑器:直接向底层数据库发送Native SQL,查询的是数据库物理表中的数据,不经过SAP应用层缓存。它看到的是已持久化到硬盘的数据。
-
SE16N:是SAP标准的ABAP报表工具,它通过ABAP SQL(Open SQL)访问数据,会遵循SAP的缓冲策略,优先从应用服务器缓存中读取。
因此,结论逐渐清晰:2024年的数据很可能只存在于应用服务器的缓存中,尚未写回数据库物理表。这解释了为什么DB02查询不到(因为物理表里没有),而SE16N却能查到(因为从缓存中读取)。
三、进一步探索:数据为何只停留在缓存?
那为什么数据会只存在于缓存中?我分析常见的原因有以下几种:
-
事务未提交:可能某个用户(或后台程序)通过事务(如
MIGO、FB01)创建了2024年的物料凭证,但尚未点击“保存”按钮,或者保存后数据仍处于逻辑可见但未物理提交的状态。此时数据存在于该会话的内存中,只有当前会话(或某些特殊读取模式)能看到,其他会话(包括DB02)无法访问。 -
表缓冲机制:表
MSKUH很可能开启了通用缓冲(Generic Buffering)。当数据被加载到缓存后,如果系统尚未触发缓存更新写回数据库(例如由于某些异步更新延迟),新数据就会暂时“滞留”在缓存中。 -
SAP应用层与数据库层的一致性延迟:在某些配置下,SAP应用层可能先更新缓存,而后台数据库的写入操作可能稍有延迟(例如出于性能考虑,将多个更新合并提交)。在这短暂的窗口期内,就会产生数据不一致的假象。
为了验证是否真的是缓存问题,可以尝试让系统管理员(Basis)使用事务码$TAB清除表MSKUH的缓存。如果清除后SE16N也查不到2024年的数据,则确认问题源于缓存。
四、知识点扩展:DB02 SQL 与 ABAP SQL 的本质区别
我遇到的这个问题,也引出了一个更深层次的知识点:DB02中的SQL(Native SQL)与ABAP程序中的SQL(ABAP SQL / Open SQL)到底有什么区别? 理解这一点,对于所有SAP技术人员都至关重要。
1. 定义与架构
-
DB02 SQL(Native SQL):是直接与底层数据库(如HANA、Oracle、MaxDB等)交互的“方言”。我写的语句被原封不动地发送给数据库执行,完全依赖特定数据库的语法和功能。
-
ABAP SQL(Open SQL):是SAP为了屏蔽不同数据库之间的差异而封装的一套标准SQL,是ABAP语言的一部分。当我编写
SELECT ... FROM ... WHERE ...时,SAP内核中的数据库接口会将其翻译成目标数据库能理解的Native SQL,然后再发送执行。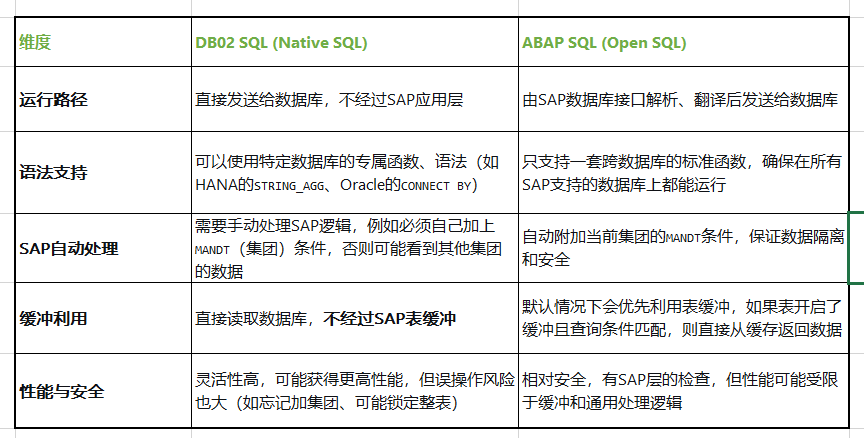
3. 我的案例中的应用
回到我的案例:
-
当我使用DB02(Native SQL)查询时,我看到的是数据库物理表中已提交的数据。由于2024年的数据尚未写回数据库,因此查询不到。
-
当我使用SE16N(通过ABAP SQL)查询时,它首先尝试读取SAP应用服务器的表缓存,而缓存中恰好有2024年的数据(可能是某个未提交事务加载进来的),因此能查到。
这正是“同一个表,不同工具,结果不同”的根本原因。
五、我的经验总结与建议
-
工具选择决定数据视角:在SAP中进行数据查询时,务必明确自己使用的工具是直接访问数据库(如DB02、ST04的SQL编辑器、Native SQL程序),还是通过ABAP层访问(如SE16N、SE11、ABAP报表)。前者反映物理持久化状态,后者可能反映包含缓存和未提交数据的“逻辑”状态。
-
排查数据不一致的思路:
-
当怀疑数据不一致时,先用SE16N等ABAP工具确认数据是否存在。
-
再用DB02或底层数据库工具验证物理表状态。
-
如果两者不符,考虑缓存、未提交事务或更新延迟的可能性。
-
尝试清除表缓存(需谨慎,最好在非生产环境或咨询Basis后进行),观察现象。
-
-
开发注意事项:
-
在编写ABAP程序时,尽量使用Open SQL,让SAP自动处理集团和缓冲,保证代码的健壮性和可移植性。
-
如果需要绕过缓存读取最新数据,可以在Open SQL中使用
BY PASSING BUFFER附加项(谨慎使用)。 -
若必须使用Native SQL(例如调用数据库特有的功能),务必自行处理集团条件,并注意数据一致性问题。
-
-
缓存不是长久之计:数据最终要持久化到数据库。如果发现大量数据长时间滞留在缓存中,可能是系统配置或程序逻辑问题,需要检查提交逻辑、事务隔离级别以及后台作业是否及时将数据写入物理表。
六、结语
SAP系统的复杂性正是由这些精妙的设计层层叠加而成。理解表缓冲、理解不同SQL访问路径的差异,能够帮助我们更准确地定位问题,避免被表象迷惑。希望我今天的案例和分析能成为你SAP技术知识库中的一块拼图,在未来的工作中助你快速破案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)