Nature发布,斯坦福开源科研 AI4S突破:OpenScholar首超GPT-4o,引文准确率达专家级水平
摘要: 斯坦福团队推出OpenScholar,首个开源科学文献综合AI系统,性能超越GPT-4o,引文准确率媲美专家水平。

Synthesizing Scientific Literature with Retrieval-Augmented Language Models
摘要: 斯坦福团队推出OpenScholar,首个开源科学文献综合AI系统,性能超越GPT-4o,引文准确率媲美专家水平。
阅读原文或https://t.zsxq.com/YgWBF获取原文pdf
引言:科学文献综合的新时代
科学进步依赖于研究人员综合日益增长的文献的能力。然而,随着学术出版物的快速增长,研究人员越来越难以保持信息更新。有效的知识综合需要精确检索、准确归因以及访问最新文献。大型语言模型(LLMs)虽然可以提供帮助,但存在幻觉问题、预训练数据过时以及归因能力有限等缺陷 。
在实验中,当要求引用计算机科学和生物医学等领域的最新文献时,GPT-4o在78-90%的情况下会捏造引用 。这一发现凸显了当前AI系统在科学文献综合任务中的重大局限性。
为了解决准确、全面和透明的科学文献综合挑战,来自华盛顿大学、艾伦人工智能研究所等机构的研究团队推出了OpenScholar——据我们所知,这是首个专为科学研究任务设计的完全开源的检索增强语言模型 。
OpenScholar:开源科学文献综合系统
系统架构与核心组件
OpenScholar集成了领域专业化的数据存储(OpenScholar DataStore,OSDS)、自适应检索模块以及全新的自我反馈引导生成机制,能够实现长文本输出的迭代优化 。
OpenScholar DataStore(OSDS) 是一个完全开放、实时更新的语料库,包含4500万篇科学论文和2.36亿个段落嵌入,为训练和推理提供了可复现的基础 。这一数据规模在开源科学文献系统中处于领先地位。
OpenScholar的工作流程包括:
-
使用训练好的检索器和重排序器从OSDS中检索相关内容
-
生成带有引用的回答
-
通过自我反馈循环迭代优化,以提高事实性、覆盖度和引用准确性
值得注意的是,这一流程同样用于生成高质量的合成数据,使得无需依赖专有LM即可训练紧凑的8B模型(OpenScholar-8B)和检索器 。
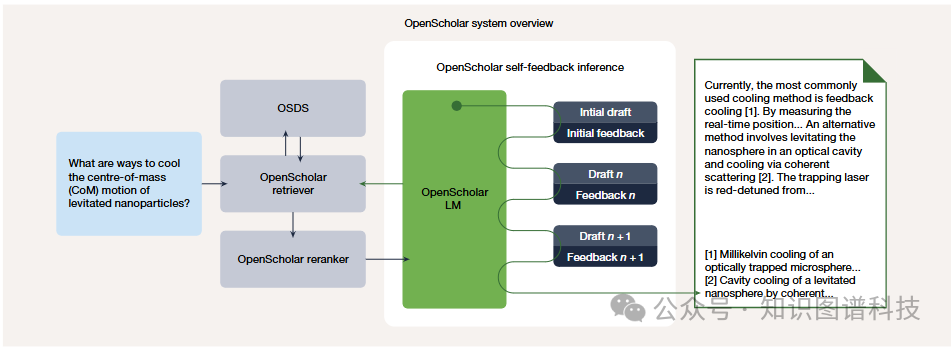
自我反馈机制
OpenScholar的创新之处在于其自我反馈推理循环。系统首先生成初始草稿,然后进行自我评估和反馈,基于反馈进行迭代改进。这一过程可以重复多次,每次迭代都会产生新的草稿和反馈,直到达到满意的质量标准 。
这种机制使OpenScholar能够:
-
识别并修正引用错误
-
增强内容覆盖度
-
提高答案的连贯性和组织性
-
确保事实准确性
ScholarQABench:首个多学科文献综合基准
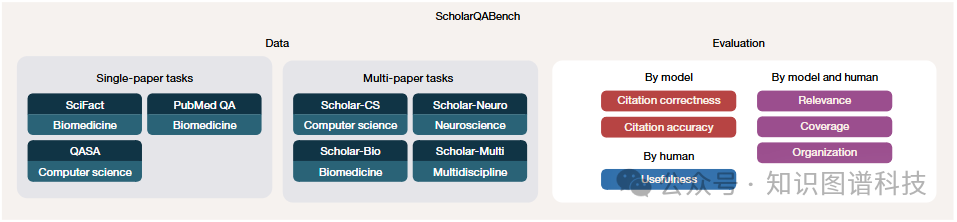
基准设计
为了评估OpenScholar,研究团队开发了ScholarQABench——据我们所知,这是首个用于开放式科学综合的多学科基准 。
与以往专注于短文本输出、多项选择格式或领域推理任务的基准不同,ScholarQABench要求生成基于众多论文最新文献的长文本回答 。该基准包括:
- 3000个研究问题
- 250个专家撰写的答案
-
涵盖计算机科学、物理学、生物医学和神经科学四大领域
-
由经验丰富的博士生和博士后撰写,反映真实世界的文献综述实践
评估协议
为了克服评估长文本、综合性回答的困难,ScholarQABench引入了严格的评估协议,结合了:
- 自动指标
(例如引用准确性)
- 人工基于评分标准的评估
,评估覆盖度、连贯性、写作质量和事实正确性
专家分析表明,所提出的多维评估管道与专家判断达成高度一致,能够可靠地捕捉长文本科学答案中的覆盖度、连贯性、写作质量和事实正确性 。
性能评估:超越GPT-4o和专家水平
自动评估结果
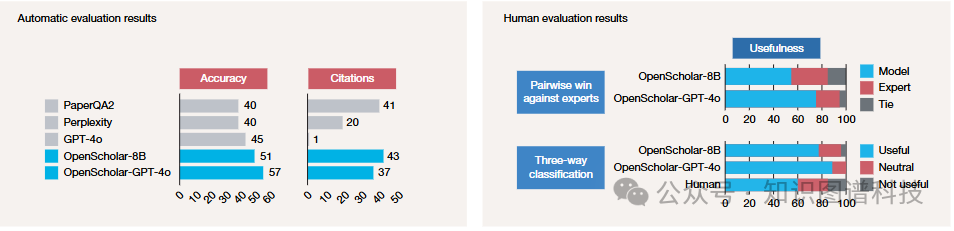
研究团队在ScholarQABench上评估了专有和开源模型(例如GPT-4o、Llama 3.1 8B和70B),以及专门化系统如PaperQA2 。
关键发现:
-
准确性对比(Scholar-CS子集,100个问题):
-
OpenScholar-GPT-4o:57%
-
OpenScholar-8B:51%
-
GPT-4o:45%
-
PaperQA2:40%
-
Perplexity:40%
-
-
引用准确性 :
-
OpenScholar-8B:43%
-
OpenScholar-GPT-4o:37%
-
PaperQA2:41%
-
Perplexity:20%
-
GPT-4o:仅1%
-
尽管GPT-4o展现出强大的整体性能,但在引用准确性和覆盖度方面表现不佳,经常产生不准确或不存在的引用 。
OpenScholar在仅使用LM和检索增强管道方面均优于其他系统。特别值得注意的是,使用完全开源检查点的OpenScholar-8B超越了基于专有LM构建的PaperQA2,以及Perplexity Pro等生产系统,分别实现了6%和10%的改进。
此外,OpenScholar管道可以增强现成的LM。例如,当使用GPT-4o作为底层模型时,OpenScholar-GPT-4o在正确性方面比单独使用GPT-4o提高了12%。
人工评估结果
研究团队进行了大规模人工评估,由16位拥有博士学位的专家对108个问题进行评估 。
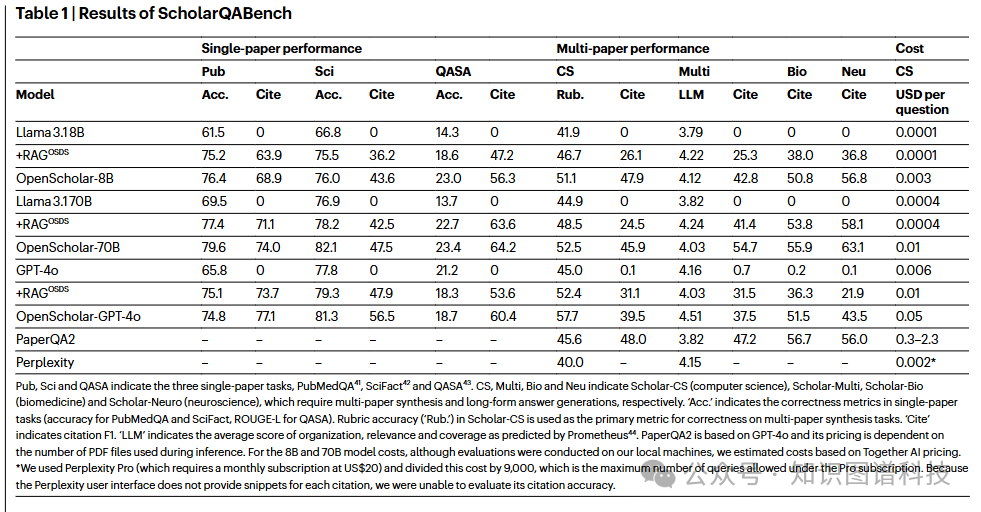
人工评估关键发现:
-
与专家答案的配对比较 :
-
专家更倾向于OpenScholar-GPT-4o:70%
-
专家更倾向于OpenScholar-8B:51%
-
专家更倾向于GPT-4o:仅32%
-
-
有用性三向分类 :
OpenScholar-8B和OpenScholar-GPT-4o在有用性评估中表现优异,与人类专家答案相当。
尽管专家人类表现超过GPT-4o和其他竞争基线,OpenScholar系统在答案正确性和引用准确性方面与专家人类持平或超越 。这一发现表明,AI辅助的科学文献综合已经达到了可以实际应用的水平。
成本效益分析
OpenScholar使用更小、更高效的检索器大幅降低了成本 。这对于需要大规模文献检索和综合的研究机构和企业而言具有重要的实际意义 。
核心技术优势
广泛的评估表明OpenScholar核心组件的重要性,包括:
- 重排序(Reranking)
:提高检索结果的相关性
- 自我反馈(Self-feedback)
:迭代改进答案质量
- 专业化数据存储
:提供领域特定的知识基础
这些组件的协同作用使OpenScholar能够:
-
显著减少引用幻觉
-
提高答案的覆盖度和深度
-
保持引用的准确性和可追溯性
-
生成更加连贯和有组织的长文本回答
实际应用与影响
用户采用情况
OpenScholar的公开演示已吸引了来自不同科学学科的超过30,000名用户。这一广泛的用户基础表明该系统在实际科研工作中具有显著的应用价值。
开源贡献
为了支持和加速未来的研究工作,研究团队开源了:
-
OpenScholar代码
-
数据和模型检查点
-
数据存储(OSDS)
-
ScholarQABench基准
-
公开演示平台
这一全面的开源策略将促进科学文献综合领域的快速发展,使更多研究人员和机构能够基于OpenScholar进行创新 。
局限性与未来方向
当前局限性
研究团队坦诚指出了几个重要的局限性 :
-
不能完全自动化:OpenScholar不能完全自动化科学文献综合。人类专家的判断和批判性思维仍然是科学研究不可或缺的部分 。
-
需要持续改进:尽管性能优异,系统在某些复杂场景下仍有改进空间 。
未来研究方向
未来工作可以通过以下方式进一步改进OpenScholar :
- 整合用户反馈
:利用平台收集的用户反馈增强检索质量
- 提高引用准确性
:进一步减少引用错误
- 优化整体可用性
:改善用户体验和系统响应速度
此外,未来可以探索:
-
扩展到更多科学领域
-
支持多语言文献综合
-
集成实时文献更新机制
-
增强跨学科知识综合能力
结论:科学文献综合的新里程碑
OpenScholar和ScholarQABench的推出代表了LM基础系统在帮助科学家应对科学文献综述这一复杂且不断增长的任务方面的重大进展 。
主要贡献总结:
-
首个完全开源的检索增强系统:使用开放权重LLM和训练的检索模型迭代优化科学输出,解决幻觉和引用准确性等挑战
-
大规模标准化基准:ScholarQABench为多个科学领域的文献综述自动化提供了标准化评估方法
-
超越现有系统:OpenScholar在ScholarQABench评估中表现出色,超越GPT-4o和并行的专有系统PaperQA2
-
超越专家水平:跨三个科学学科的专家评估显示,OpenScholar生成的答案比需要每个注释花费一小时的专家注释者生成的答案更有帮助
OpenScholar为科学研究社区提供了一个强大、透明且可访问的工具,有望显著提高文献综述的效率和质量,加速科学发现的步伐。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)