MiniMax M2.5 正在重写智能体经济学
MiniMax M2.5 一个数字让我盯着看了很久:1万美元支持4个高能力智能体工作一整年。这不只是 Token 降价,而是 AI 从"昂贵工具"变成"廉价劳动力"的转折点。SWE-Bench 80.2、Multi-SWE 行业第一、工具调用大幅领先 Claude——便宜又好用,才是真的难。
1万美元,能买4个AI员工干一整年
MiniMax M2.5 正在重写智能体经济学
上周我在给 OpenClaw 配默认模型。
随手接了个顶级模型,跑了一天。
晚上打开账单,11 美元。
就这么一天。什么也没做完,只是开着跑了跑。
做智能体的人都知道这道坎——你要让 AI 做一件需要上千次搜索、反复调试代码的复杂任务,Token 费用往往比结果本身还贵。
我立刻打开搜索框,开始查:有没有什么模型,能力别差太多,但烧钱慢一点?
就在这个节点,想起了年前发布的MiniMax M2.5。
1万美元。
支持4个高能力智能体,
不间断地工作整整一年。
这是 MiniMax 创始人闫俊杰说的话,不是广告文案。
我盯着这个数字看了很久。不是因为它便宜,而是因为它把一件事从"理论上可行"变成了"经济上可行"。
这两个词之间,隔着一个产业的距离。
一件事正在悄悄改变
大模型行业有一个很少被讨论的矛盾:能力越强的模型,往往越贵。
GPT-5.2、Claude Opus 4.6 这些顶级选手,每百万 Token 的定价足以让中小团队在成本面前望而却步。对于需要数百轮搜索、成千次代码调试、跨越数天任务规划的智能体场景,传统的 Token 计费模式几乎是在跟开发者说:你用得起模型,但用不起智能体。
M2.5 试图打破这个逻辑。它在快速版(100 TPS)下,输入每百万 Token 仅需 0.3 美元,输出仅需 2.4 美元。对比同梯队的 Claude Opus 4.6,成本差距是数量级的。
但更关键的不是价格本身,而是这个价格背后的思维转变——
在智能体时代,AI 的价值开始用「单位生产力的获取成本」来衡量,而不再是「单次请求的质量」。
这不仅是 Token 价格的下降,而是将 AI 从"昂贵的奢侈品工具"转化为"廉价的规模化劳动力"的关键转折。那些需要极高 Token 消耗的长链路任务——持续的竞争对手情报监控、全自动化软件重构、跨平台电商运营——从"烧不起"变成了"算得过来"。
能力没有缩水,这才是重点
便宜不稀奇。便宜又好用,才值得认真聊。
M2.5 在 108 天内完成了三次重大迭代(M2、M2.1、M2.5),这种迭代频率在全球主流模型梯队中处于领先地位。在衡量真实软件工程能力的 SWE-Bench Verified 测试中,得分从 M2 的 69.4 跑到了 80.2——这个分数,已经杀入了由 Claude Opus 4.6 和 GPT-5.2 统治的"全球最强模型"阵营。
对于我这种写代码的人来说,更直观的感受是:M2.5 在处理复杂工程任务时,不会上来就堆代码——它会先做全局规划,拆任务、定接口、理逻辑,然后再动手。
像一个真正的架构师,而不是一个很快的补全器。
MiniMax 官方把这种行为叫"原生 Spec 行为"——模型在动手之前先写规格说明。这种"先谋后动"的模式大幅减少了大型项目中常见的逻辑漏洞。而且这不是只对 Python 有效:M2.5 在超过 10 种编程语言上做了深度训练,覆盖了从 0-1 的系统设计到 90-100 的 Code Review 全流程。

不只是会写代码,还会"使唤"工具
智能体的本质,是与真实环境交互的能力。光会生成文本还不够,得会调 API、会搜索、会在复杂的工具链路中保持清醒。
M2.5 在 Berkeley 函数调用排行榜(BFCL)的多轮对话任务中拿到了 76.8 分。同一张榜单上,Claude 4.5 得分 68.0,Gemini 3 Pro 是 61.0。
这意味着什么?意味着在处理那种需要多步逻辑、频繁调用不同 API、且必须维持长程上下文记忆的任务时,M2.5 不容易在复杂的调用链路中迷失方向。它能精准理解你的潜在意图,而不是每隔几轮就跑偏一次。
还有一个细节值得注意:M2.5 在搜索决策上也做了优化。相比上一代 M2.1,它用更少的搜索轮次达到更好的信息获取效果——节省了约 20% 的搜索消耗。
不是搜得多就好,而是搜得准才省钱。这种"精准打击"式的搜索能力,直接帮智能体把端到端成本又压低了一截。
它是怎么做到的
架构上有两个关键词。
第一个:Linear Attention(线性注意力)。
传统 Transformer 的注意力机制,计算复杂度随文本长度平方增长——文本变长一倍,算力要涨四倍。M2.5 是全球首个在万亿参数规模上实现线性注意力的模型,把复杂度从 O(n²d) 打到了 O(nd²),推理速度提升 2 到 3 倍,原生支持 128k 上下文。
第二个:MoE(混合专家)。
总参数 2300 亿,但每次推理只激活约 100 亿。万亿底蕴,百亿激活——既保留了深度知识,又控制了运行成本。
💡 简单类比:就像一个全科医院有 2300 名专科医生,但每个病人就诊时,只会同时接诊约 100 位最相关的专家——效率最高,资源不浪费。
但架构只是骨架。真正让 M2.5 跑得又快又准的,是一套叫 Forge 的自研训练框架。
Forge 完全解耦了底层训推引擎与上层 Agent 脚手架,实现了 40 倍训练加速。更有意思的是它的奖励机制:模型不只学"做对",还学"快速且省钱地做对"。通过引入过程奖励(Process Reward),M2.5 对长链路任务的中间轨迹进行精细化评估,并首次把"环境真实耗时"纳入奖励函数。
也就是说,这个模型从出生起就被教育:时间就是金钱,Token 也是。
开源,是另一种姿态
M2.5 把模型权重上线了 ModelScope,直接支持 MLX 本地推理。
开发者可以在本地 Mac 上,通过 3-bit 量化版本实现每秒 60 Token 的流畅代码生成,不需要依赖云端 API,也不用担心数据隐私。对于追求极致并发的企业,M2.5 还提供了针对 SGLang 和 vLLM 的优化方案——在常见的 8 卡显存配置下,可以支持数百万 Token 的 KV Cache 容量。
这不只是技术姿态,也是一种价值判断:好的工具,不应该只属于能负担得起 API 费用的人。
更值得关注的战略选择是:MiniMax 选择了先在海外上线,正面挑战 Claude 和 GPT 系列。这种自信不是凭空的——在 SWE-Bench 这种硬核榜单上,M2.5 已经证明了自己属于第一梯队。
我朋友说,这感觉像"把核武器开源了"。有点夸张,但那种震动是真实的。
它适合谁,不适合谁
公允地说,M2.5 不是一个在所有维度上都最强的模型。
如果你的任务是顶级科学推理、物理奥赛金牌水平的推演,或者极致精美的 3D 图形生成——Gemini 3 Deep Think 仍然是标杆。如果你需要深度本地化的复杂系统工程,GLM-5 也是有力的竞争者。
但如果你的场景是:大规模智能体部署、全栈代码开发、高频次工具调用、长链路自动化任务——M2.5 目前可能是性价比最优解。
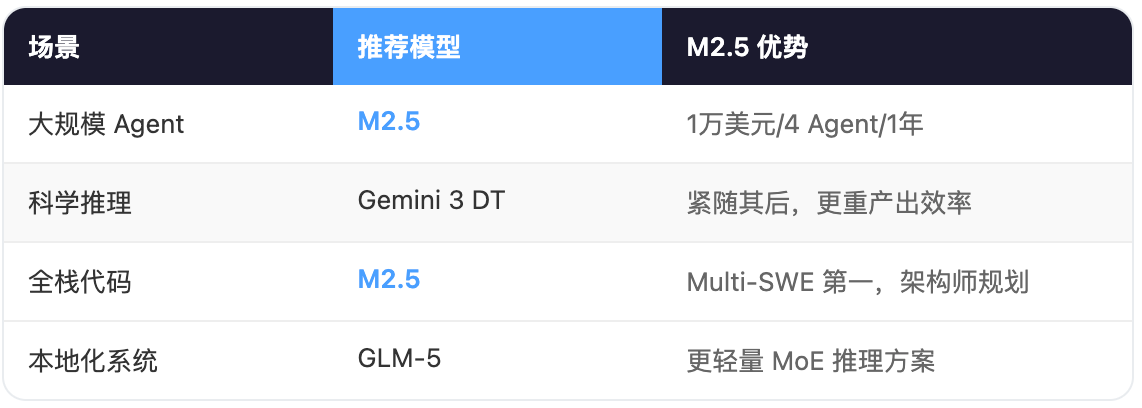
用一句话总结它在天梯中的定位:M2.5 不是为了在某个单一数学竞赛榜单上冲击满分而存在的实验品,而是为了在真实生产负载中优化吞吐量和预算的"生存大师"。
夜猫子时刻
大模型行业有一条暗线,比模型能力本身更重要:
从"大型语言模型"到"大型行动模型"的转变。
LLM 回答问题,LAM 完成任务。
一个是顾问,一个是员工。
M2.5 让我看到的不是某个分数的突破,而是这个转变正在被一个具体的价格标记:
1万美元,4个智能体,1年。
当 AI 从"可以对话的知识库"变成"可以购买的劳动力",最大的变量不再是技术,而是每个组织对这件事的反应速度。
这个数字我记住了。
不知道你记住了没有。
—— 首发wx:夜猫子弦月 ——
白天写代码,晚上写文章,偶尔弹古琴

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)