TTRV:面向视觉-语言模型的测试-时强化学习
25年12月来自印度IIS、JHU、斯坦福、德国Tuebingen AI中心、MIT-IBM联合实验室和MIT- CSAIL的论文“TTRV: Test-Time Reinforcement Learning for Vision Language Models”。现有的强化学习奖励信号提取方法通常依赖于标注数据和专门的训练集划分,这与人类直接从环境中学习的方式截然不同。本文提出一种名为TTRV的
25年12月来自印度IIS、JHU、斯坦福、德国Tuebingen AI中心、MIT-IBM联合实验室和MIT- CSAIL的论文“TTRV: Test-Time Reinforcement Learning for Vision Language Models”。
现有的强化学习奖励信号提取方法通常依赖于标注数据和专门的训练集划分,这与人类直接从环境中学习的方式截然不同。本文提出一种名为TTRV的算法,通过在推理时动态调整模型来增强视觉语言理解能力,而无需任何标注数据。具体而言,改进组相对策略优化(GRPO)框架,在对每个测试样本进行多次推理的同时,根据基础模型输出的频率设计奖励。此外,还提出通过同时奖励模型获得低熵输出经验分布来控制模型输出的多样性。该方法在物体识别和视觉问答(VQA)任务上均取得持续的提升,分别提升高达 52.4% 和 29.8%,在 16 个数据集上的平均提升分别为 24.6% 和 10.0%。值得注意的是,在图像识别任务中,应用于 Intern-VL-8B 的 TTRV 在 8 个基准测试中平均超越 GPT-4o 2.3%,同时在 VQA 任务上也保持很强的竞争力,这表明测试-时强化学习可以达到甚至超越最强大的专有模型。最后,测试-时强化学习在视觉-语言模型(VLM)方面的许多有趣特性:例如,即使在数据极其受限的情况下,仅对一个随机选择的未标记测试样本进行自适应训练,TTRV 在识别任务中仍然能够带来高达 5.5% 的显著提升。
基于强化学习的视觉-语言模型(VLM)微调。强化学习已成为使大语言模型(LLM)与人类偏好和任务目标保持一致的核心范式,诸如RLHF[43]和DPO[47]等方法提高了语言模型和视觉-语言模型的安全性、连贯性和指令遵循能力。最近,诸如GRPO[53]等基于规则的方法证明扩展强化学习以增强推理能力的可行性。在此基础上,基于强化学习的微调(RFT)已被扩展到各种视觉驱动任务的多模态模型。例如,VLM-R1[54]、VisualThinker-R1-Zero[75]和Perception-R1[69]分别将RFT应用于开放词汇物体识别、空间推理和视觉感知;CLS-RL[26]将RFT应用于少样本图像分类; R1-VL [71] 及相关研究进一步完善多模态推理。这些工作表明,强化学习可以显著增强视觉语言模型(VLM)的视觉中心能力,但它们仍然依赖于精心设计的训练集或带标签的反馈。
测试-时训练(TTT)。TTT 方法在推理时调整模型参数,而无需带标签的测试数据,通常是通过优化替代目标,例如最小化熵或自监督辅助损失 [16, 35, 38, 49, 57, 58, 60]。这些技术最初是为单模态架构开发的,但最近已被扩展到多模态系统,其中大部分研究集中在双编码器 VLM 上(例如 CLIP [46])。典型的例子包括 TPT [55],它通过最小化增强视图的熵来调整文本提示,以及其扩展 DiffTPT [15] 和 C-TPT [68],它们分别提高了增强质量和校准精度。RLCF [74] 则利用来自更大模型的反馈来调整图像编码器,而一些黑盒子方法则直接操作嵌入,无需修改内部参数。
然而,许多广泛使用的 TTT 方法都施加架构或目标层面的约束,限制它们在基于解码器的 VLM 中的应用。例如,Norm [49] 和 DUA [35] 需要批归一化层,而 TENT [60] 则依赖于最小化模型输出类别概率分布的熵。基于解码器的 VLM 不会生成此类类别级分布;相反,它们会生成基于完整词汇表的自回归token分布,这使得直接应用 TENT 式目标并非易事。
本文提出一种面向视觉-语言模型的测试-时强化学习框架(TTRV),该框架能够直接从未标记的测试数据中学习,从而朝着上述愿景迈进。TTRV框架能够直接从测试数据中提取用于组相对策略优化(GRPO)[53]的奖励信号。具体而言,提出的奖励机制包含两个不同的部分,分别基于对预训练模型针对每个测试样本输出的频率和多样性控制。其核心思想是鼓励模型频繁地为每个测试样本生成相似的输出,并奖励那些更频繁出现的预测结果;同时,通过奖励输出经验分布中较低的熵值来控制模型输出的多样性。如图概述TTRV,并给出一个优化轨迹。该方法将静态预训练的 VLM 转换为能够在推理时自我改进的动态系统,使多模态模型的 RL 更接近于通过原始经验进行学习的类人范式。
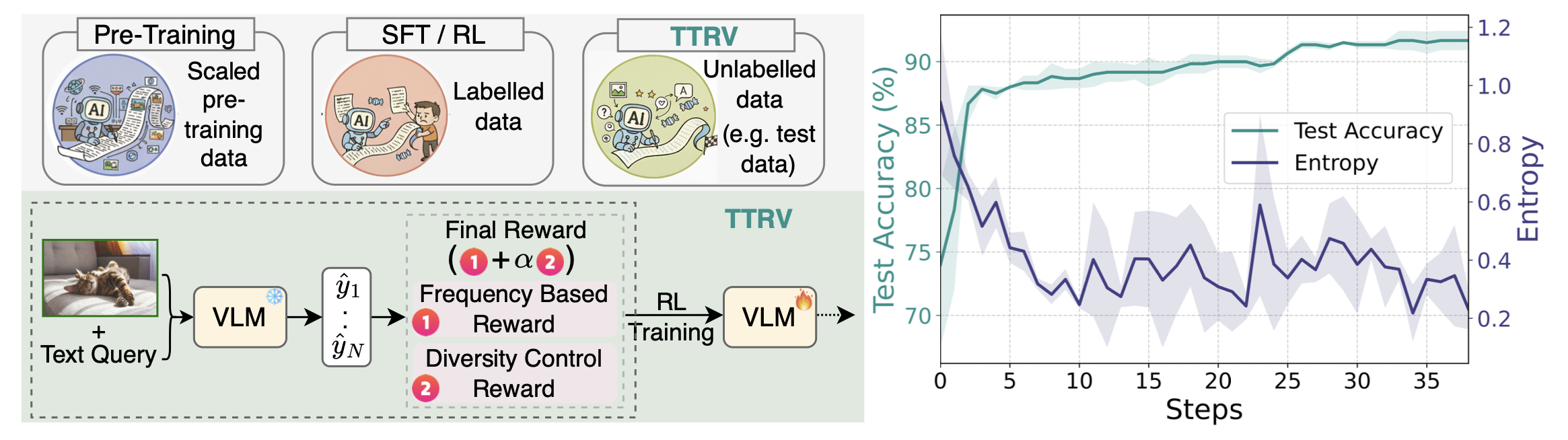
TTRV的目标是通过直接从遇到的未标记测试数据中提取奖励信号来改进下游视觉任务。为此,用组相对策略优化(GRPO)[53]对一个现成的视觉语言模型(例如InternVL [77])进行引导。工作的一个关键贡献在于设计完全无监督的奖励信号。概括来说,引入两种互补的奖励:(i)基于频率的奖励,用于鼓励基础视觉语言模型给出一致的答案;(ii)基于熵的奖励,用于规范响应的多样性。如图概述方法: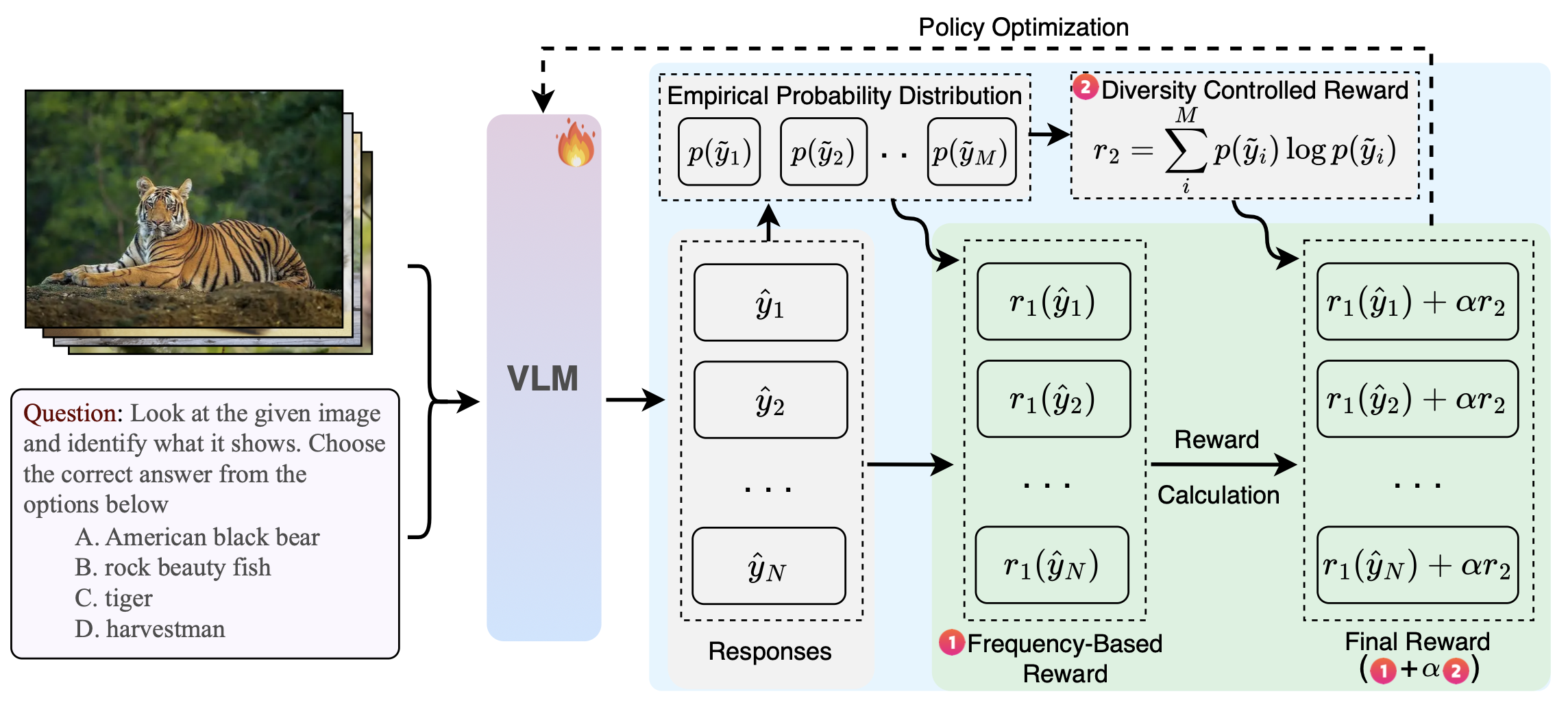
基于分布奖励的测试-时强化学习
TTRV 扩展通常通过标记数据提取奖励的传统 GRPO 框架,引入推理-时强化学习框架。提出在推理时直接从模型输出的经验分布中提取自监督强化信号。与依赖外部监督的设置不同,框架生成自洽奖励,利用展开的变异性来指导推理过程中的收敛。具体而言,从未标记数据中提取两种奖励。
基于频率的奖励。给定测试学习过程中特定时间步的模型副本,目标是多次对测试样本进行推理,并根据预测出现的频率给予奖励。其基本原理是,模型产生的响应越一致,其正确的可能性就越大。形式上,对于每个测试样本 x(由图像和文本提示组成),从当前策略 π_θ(· | x) 中抽取 N 个候选响应 {yˆ_1 , yˆ_2 , . . . , yˆ_N }。令 U = {ỹ_1, ỹ_2, …, ỹ_M} 表示唯一输出的集合。估计 ỹ_m 的经验概率 p(y ̃_m),然后定义单个样本 yˆ_j 的奖励 r_1(yˆ_j),该奖励对频繁出现的响应赋予更高的值,同时仍然对不常见但可能有意义的备选方案分配非零奖励。这种分级结构捕捉重复推广过程中隐含的共识,而不会丢弃少数派推理路径。
重要的是,这与 [78] 中使用的标准 N 选最佳采样方案不同,后者仅选择最频繁出现的响应并丢弃所有其他响应。当模型不确定或最频繁的预测不正确时,这种硬性决策可能会出现问题,因为它提供一个误导性强但可能错误的奖励信号。相比之下,奖励公式产生一个柔和的、概率性的监督信号,反映响应的完整分布。这种视角自然与贝叶斯推理相联系:本方法不是简化为单一的点估计,而是保留假设的不确定性并利用它来指导学习。
多样性控制奖励。为了补充基于频率的奖励 r_1(它为重复的模型响应提供与频率成比例的软性奖励),引入一个基于熵的正则化项来控制收敛性。对于给定的测试样本,计算经验响应分布的香农熵 [51] H(P),并定义辅助奖励 r_2 = −H§,用于惩罚输出分布中过度分散的情况。该机制确保模型在初始阶段探索多种推理模式(如基于频率的奖励所鼓励的那样),并逐渐将概率集中于稳定的高概率答案,而不是将注意力分散到冗余的响应上。
组合奖励。分配给响应 yˆ_j 的总体奖励是概率项和熵项的组合:R(yˆ_j) = r_1(yˆ_j) + αr_2,其中 α 是一个可调超参数,用于控制收敛性和多样性之间的权衡。通过将基于概率的自我奖励与熵正则化相结合,模型在推理过程中自适应地调整其输出,从而在探索多样化的推理路径和收敛到一致的预测之间取得平衡。
优化目标
强化学习的目标是在策略下最大化预期奖励。对于基于解码器的视觉-语言模型(VLM),优化通过标准的自回归语言建模目标来实现,奖励提供预测token的软样本-级加权。参数通过梯度上升法更新。
GRPO [53] 对此过程进行改进,将原始奖励替换为相对优势。这使得优化从绝对奖励转向相对比较,从而更加稳定,并更好地与组-级目标保持一致。
基线:为了进行比较,评估以下双编码器 VLM:CLIP [46]、MetaCLIP [66]、EVA-CLIP [56] 和 SigLIP [70]。作为基于解码器的 VLM 的代表性方法,选择:LLaMA [59]、LLaVA [30] 和 Phi-3.5-vision [1],并提供专有模型 GPT-4o [42] 的结果。在主要实验中,将 TTRV 应用于 InternVL [6] 系列的不同模型尺寸。但是,TTRV 可以应用于任何开源 VLM。
实现细节:独立地将 TTRV 应用于每个基准测试。为了进行优化,采用 AdamW 优化器,并使用余弦学习率调度,将峰值学习率设置为 5 × 10⁻⁷。在展开阶段,生成 32 个候选响应,所有实验的温度均为 1.0。奖励超参数 α 在所有数据集上均固定为 0.75。将最大提示长度限制为 7524 个 token,最大响应长度限制为 1024 个 token。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献223条内容
已为社区贡献223条内容

所有评论(0)