UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
UniWorld-V1 是一篇极具启发性的工作。它证明了在统一视觉生成框架中,高分辨率的对比学习语义特征(SigLIP)比基于重建的局部特征(VAE)能提供更好的泛化指导。结合高效的二阶段训练范式和精巧的 Mask-aware Loss Weighting,用极低的数据成本(2.7M)实现了跨感知、理解、生成的 SOTA 级端到端多模态大模型。模型权重、代码和清洗后的数据集已全部开源。
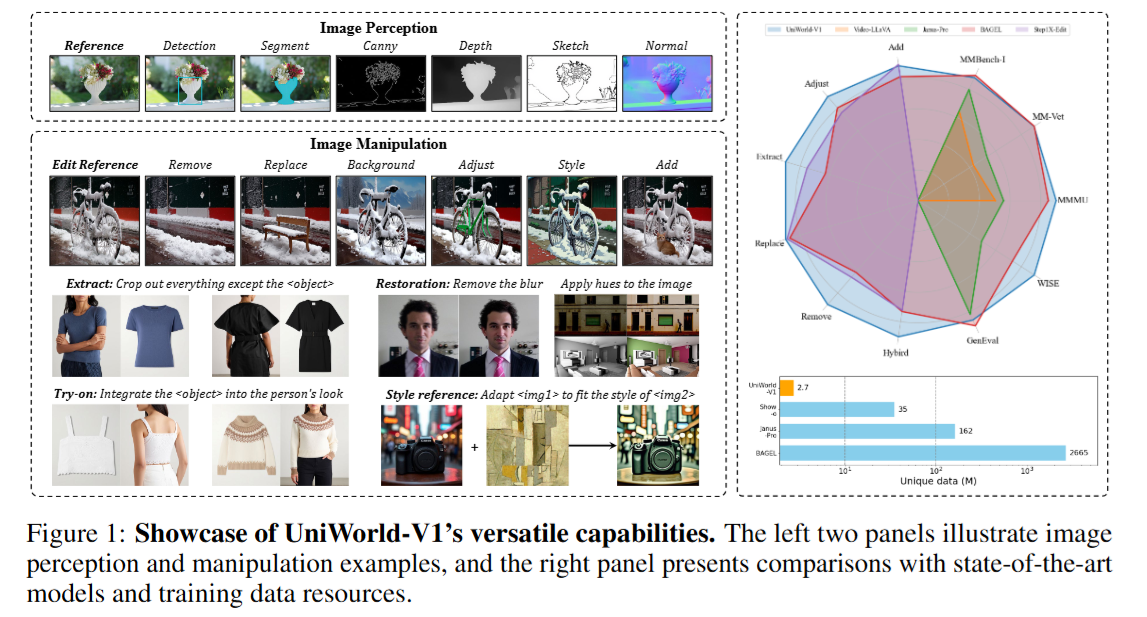

1. 破案:看透 GPT-4o 的“底牌”
目前只有 OpenAI 的 GPT-4o 既能看图说话,又能画画,还能当全能“修图师”(比如精准换背景、改衣服颜色、提取线稿)。
以前学术界以为,AI修图必须靠 VAE(相当于“死板的像素复印机”),死死盯住原图每一个像素。但作者团队对 GPT-4o 做了几个刁钻的测试,发现它居然会“脑补”。
结论得出: GPT-4o 根本没用“复印机”,而是用了 “语义编码器”(相当于“抓神韵的概念画师”)。它不仅看像素,更懂画面的“概念和意境”。
2. 组装:打造我们自己的全能学霸(UniWorld-V1)
摸清了大佬的底牌,作者团队立刻照方抓药,抛弃了传统的“复印机”路线。
他们找来了一个超高清的“概念画师”(SigLIP),外加一个聪明的“AI大脑”(Qwen语言模型),把它们拼在一起,造出了 UniWorld-V1。只要“画师”视力够好(高分辨率),完全能做到精准修图。
3. 开挂:极其高效的“划重点”学习法
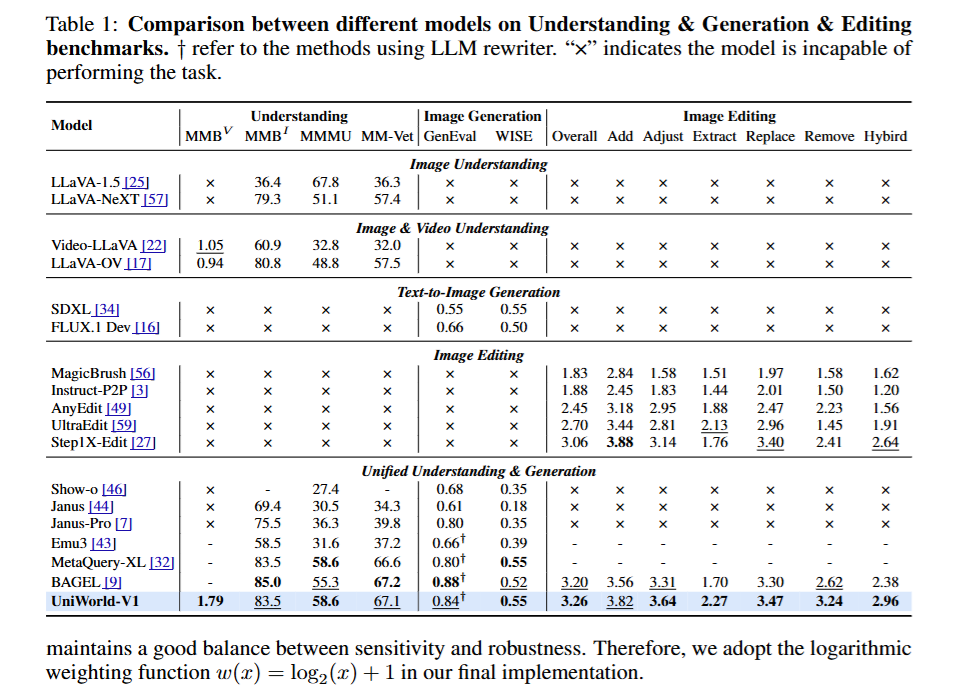
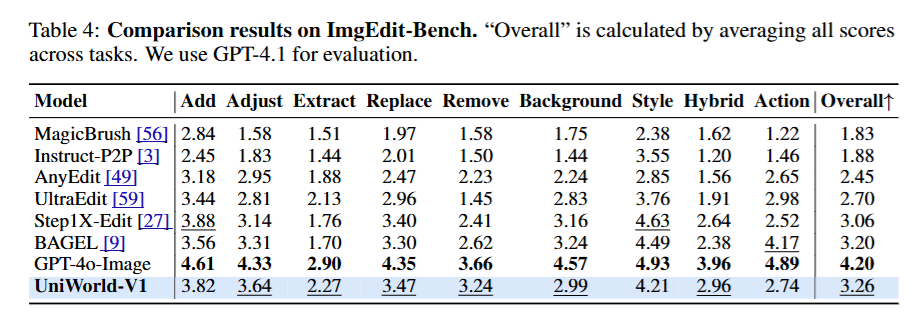
别的AI(比如巨头做的BAGEL模型)为了学会修图,狂看了 26亿张图。
而 UniWorld-V1 只看了区区 270万张(千分之一),成绩却更好!
凭什么? 因为它独创了“自适应权重”算法:如果修图只要求“把桌上的苹果改成橘子”,AI 就会把注意力死死锁定在这个小区域,绝对不被周围没变的背景糊弄。相当于做题时精准**“划重点”**,效率极高。
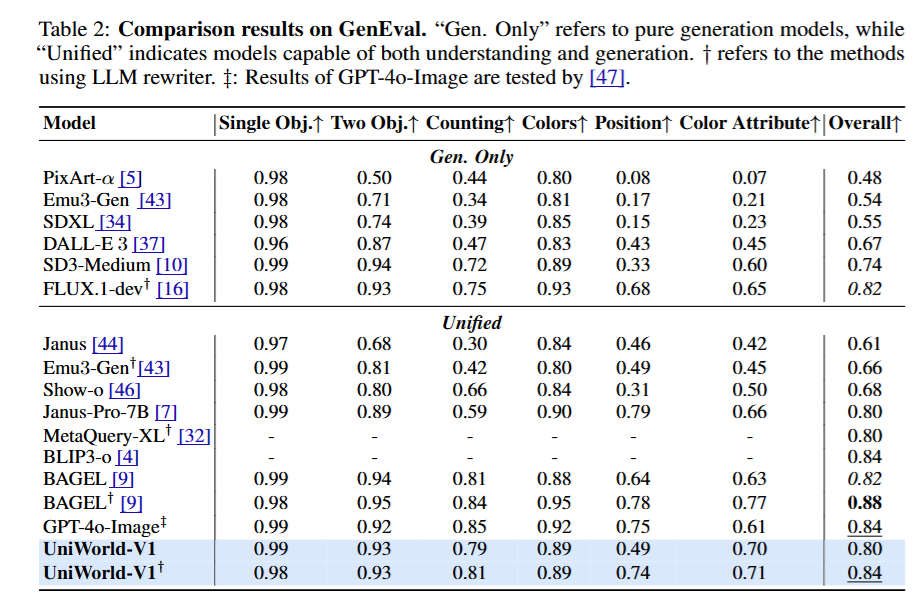
这篇论文《UniWorld-V1》的核心贡献在于:提出了一种摒弃传统 VAE 视觉特征注入,转而依赖高分辨率语义编码器(Semantic Encoders)的统一视觉生成与理解框架。 该模型仅用 2.7M 训练数据,就在图像感知(Perception)和图像操作(Manipulation)任务上,达到了对标甚至超越训练数据量高达 2.6B 的 BAGEL 模型的 SOTA 性能,并逼近闭源的 GPT-4o-Image。
以下是该论文的硬核技术原理解析:
1. 核心动机与 Insight:为什么放弃 VAE?
当前主流的统一图像操作模型(如 Step1X-Edit, FLUX-Kontext)通常引入 VAE 来提取参考图像的视觉特征(Low-level control)。但作者发现,VAE 倾向于保留过多的低频信息(如全局结构和轮廓),这在处理跨域感知和强语义编辑任务时,严重限制了模型的泛化能力和收敛性。
对 GPT-4o-Image 的逆向工程(Empirical Observation):
作者设计了两个探针实验来推测 GPT-4o 的底层特征提取机制:
- 局部编辑实验(文本位置偏移): 让 GPT-4o 修改图中广告牌文字颜色,结果文字位置发生了偏移。如果 GPT-4o 底层使用了强保留低频空间信息的 VAE,文字位置理应严格对齐。
- 重度去噪实验(高斯噪声破坏): 给定 0.6x 噪声的狗图像进行去噪,GPT-4o 将其生成了一只“鹿”。结合 VLM(Qwen/GPT-4o)对该噪声图同样输出“鹿”的 Caption,作者推断:GPT-4o 高度依赖多模态语义先验(Semantic Prior),而非基于像素级的低频重建。
结论: 应该使用**对比学习训练的高分辨率语义编码器(如 SigLIP)**替代 VAE,来提供 Reference Image 的控制信号。
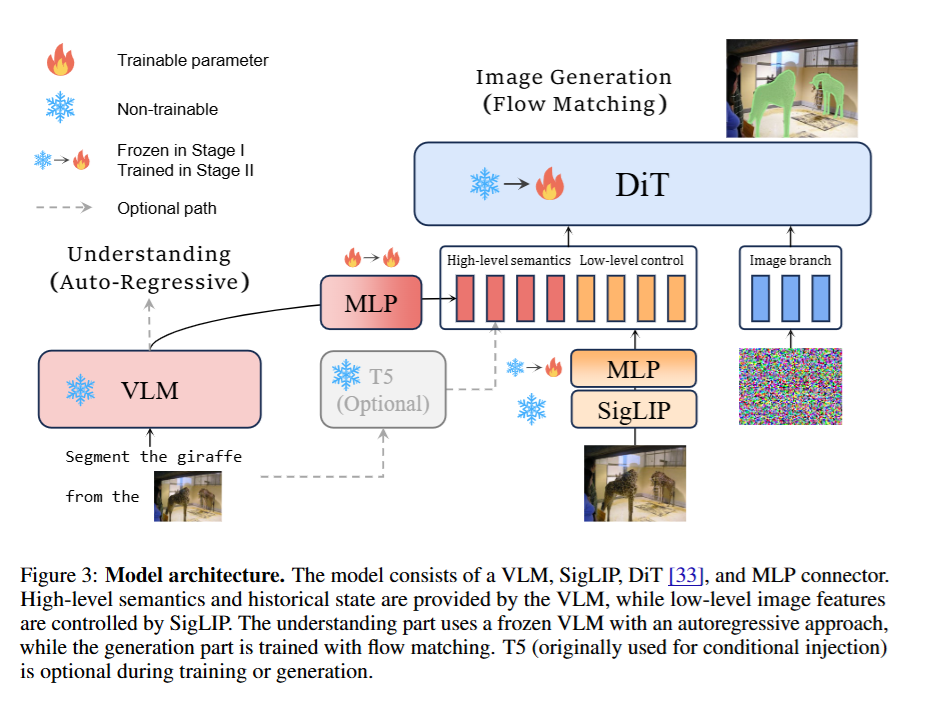
2. 模型架构设计 (Architecture)
UniWorld-V1 是一个解耦了理解与生成的统一架构:
- 理解模块 (Autoregressive VLM): 采用冻结的 Qwen2.5-VL-7B。它负责处理多模态上下文,输出 High-level semantics 和 historical state。冻结 VLM 可以无损继承其原有的强大视觉理解能力(免去了在生成任务中 Fine-tune 导致的灾难性遗忘)。
- 低级视觉控制模块 (Semantic Encoder): 采用高分辨率的 SigLIP2-so400m/14(固定分辨率 512x512)。它同时捕获像素级局部信息和语义级全局概念。
- 生成模块 (Flow Matching DiT): 基于 FLUX.1 Dev 架构。
- 特征融合 (Connector): Reference Image 分别通过 Qwen2.5-VL 和 SigLIP 提取特征,两者的输出通过 MLP 投影后,Concatenate 起来作为 FLUX Text Branch 的条件输入。(注:作者发现早期引入原版 FLUX 的 T5 特征容易导致局部最优,因此训练早期丢弃了 T5)。
3. 核心算法创新:自适应编辑区域权重策略
在 Image Manipulation(如局部编辑)任务中,编辑区域(Edited Region)通常只占全图很小的比例。如果采用全局均匀的 Loss 权重,背景区域的梯度会压倒编辑区域的梯度,导致模型欠拟合(Underfit)用户的编辑意图。
解决方案(Adaptive Editing Region Weighting):
- 伪 Mask 生成 Pipeline: 对于没有开源 Mask 的编辑数据集,作者通过:
像素级作差 (Pixel-wise Differencing) -> 膨胀 (Dilation) -> 连通域过滤 (CC Filtering) -> 最大池化下采样 (Max-pooling)的 CV 传统流程自动生成 Edit Mask,并计算出编辑区域面积 AeditA_{edit}Aedit。 - 动态 Loss 权重函数: 设定权重 w(x)w(x)w(x) 是全图面积 AtotalA_{total}Atotal 与 AeditA_{edit}Aedit 比例 xxx 的函数(x=Atotal/Aeditx = A_{total} / A_{edit}x=Atotal/Aedit)。作者对比了线性、指数、对数等函数,最终采用了平滑且鲁棒的对数函数:
w(x)=log2(x)+1w(x) = \log_2(x) + 1w(x)=log2(x)+1
当全图被编辑(如文生图或风格迁移)时,x=1,w(1)=1x=1, w(1)=1x=1,w(1)=1,退化为标准均匀 Loss。编辑区域越小,该区域像素回传的 Gradient 权重越大。
4. 训练 Recipe 与工程 Trick
模型在极少的数据量(总计约 2.7M,包括 1.4M 感知数据,1M 操作数据,300k 文生图数据)下完成了训练。
- Stage 1 (Semantic Alignment - 语义对齐):
- 目标: 弥合 VLM 表征空间与 FLUX Text Branch 的 Gap。
- 策略: 只训练
VLM -> FLUX的 MLP 连接器,冻结其他所有参数。此阶段不加入 SigLIP 特征。
- Stage 2 (Consistent Generation - 一致性微调):
- 目标: 学习如何利用 SigLIP 特征作为 Reference cues 进行指令编辑。
- 策略: 引入 Stage 1 训练好的 VLM MLP,以及 FLUX-Redux 的 MLP(用于对齐 SigLIP),解冻 FLUX 的 Image Branch 所有参数,保持 Text Branch 冻结。模型在 5k-10k steps 后,会越过“直接重建原图”的捷径,学会遵循指令进行编辑。
- 工程优化 (ZeRO-3 EMA):
为了在有限显存下维持大 Batch Size,主干 DiT 使用 ZeRO-2 训练,而 FP32 的 EMA 模型则采用类似 ZeRO-3 的 Sharding 策略切分到多张 GPU 上。每步更新 EMA 时,每张卡只计算并存储自己分块的参数,极大降低了显存开销(Memory Overhead)。
5. 局限性与 Failed Attempts (排坑指南)
这部分对算法工程师非常有参考价值,作者开源了他们踩过的坑:
- 尝试用 DINO V2 或 RADIO V2.5 替代 SigLIP,失败。
- 尝试直接提取 Qwen2.5-VL 的视觉特征(丢弃文本特征)作为控制信号,失败。
- 原因剖析: 对比学习(如 SigLIP)提取的是全局语义特征,随着分辨率提高趋于饱和;而 VLM 的视觉输出为了做 Token 预测,其特征空间与单纯的低层控制信号存在本质 Gap,导致模型无法保留足够的 Low-level 信息用于图像一致性控制。
总结
UniWorld-V1 是一篇极具启发性的工作。它证明了在统一视觉生成框架中,高分辨率的对比学习语义特征(SigLIP)比基于重建的局部特征(VAE)能提供更好的泛化指导。结合高效的二阶段训练范式和精巧的 Mask-aware Loss Weighting,用极低的数据成本(2.7M)实现了跨感知、理解、生成的 SOTA 级端到端多模态大模型。模型权重、代码和清洗后的数据集已全部开源。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)