【Agent Skills】基础概念+精通实践(详细版)
Agent Skills的核心理念其实很简单:把「模型会不会」变成「系统能不能稳定交付」,把「靠提示词玄学」变成「可复用、可迭代的工程能力」 。
目录
2.1 第一层:Metadata(元信息)——技能的「身份证+说明书」
2.2 第二层:Instruction(指令)——技能的「操作系统」
2.3 第三层:Resources(资源)——技能的「手脚+资料库」
三、核心设计理念:渐进式披露(Progressive Disclosure)
四、Agent Skills vs MCP:不是替代,是协同

如果说大模型是聪明的大脑,MCP是灵活的手脚,那么Agent Skills就是让大脑能稳定完成专业工作的「肌肉记忆+操作规程」。
引言:为什么我们需要Agent Skills?
2025年以来,AI领域最令人兴奋的进展之一,就是Agent Skills的兴起。它正在改变我们构建AI应用的方式——从过去依赖繁琐的提示词工程,转向模块化、可复用的「技能工程」。
很多人第一次听到Skills,会把它理解成「给模型多接几个API工具」。这只说对了一半。更准确地说:Agent Skills是「可复用的任务完成能力单元」,它把目标、流程、工具、知识、约束与验收标准封装在一起,让智能体能稳定交付专业成果。
【通俗总结——什么是Agent Skills?】
Agent Skills就像是给AI配的“岗位说明书+工具箱”——把干好一项工作需要的所有流程、知识和工具打包成一个独立模块,AI可以像装App一样装上就能直接上岗干活。

一、Agent Skills到底是什么?
1.1 一个直观的比喻
想象你要把一项复杂工作交给新同事。如果不准口口相传,只靠文档交接(而且你想一次性交接完成,以后不被打扰),你会准备什么?
任务的执行SOP与必要背景知识(这件事大致怎么做)
工具的使用说明(用什么软件、怎么操作)
要用到的模板、素材(历史案例、格式规范)
可能遇到的问题、规范、解决方案(细节指引补充)
Agent Skills的设计架构,几乎是这个「交接大礼包」的数字版本。
1.2 官方定义
根据Anthropic的官方说明:Skill是一个包含指令、脚本和资源的组织化文件夹,Agent可以动态发现并按需加载这些内容,从而在特定任务上表现得更好。
每个Skill就是一个文件夹,结构如下:
skill-name/
├── SKILL.md # 必需:技能指令与元数据
├── scripts/ # 可选:辅助脚本(Python/Shell等)
├── templates/ # 可选:文档模板
└── references/ # 可选:参考资料1.3 skills适用场景
【什么场景下适合用Skills?】
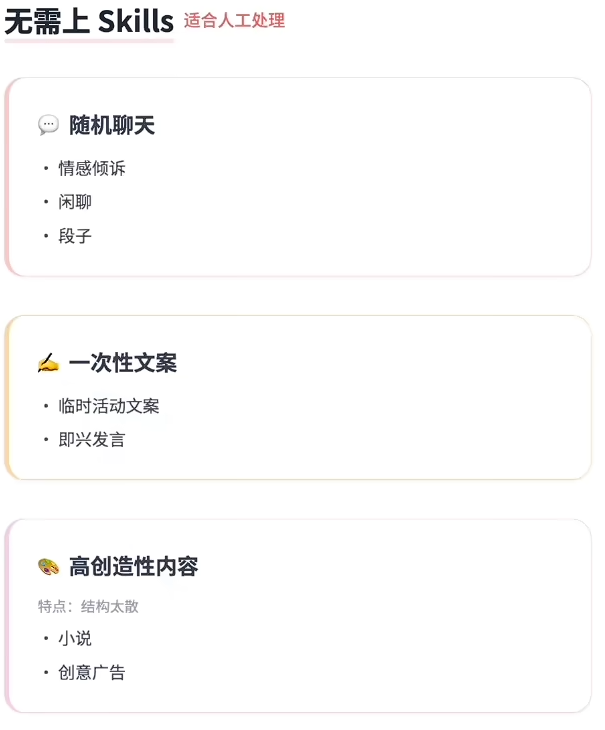
很多人的第一反应是能不能做成skill,但最本质的问题是这个任务值不值得做成skill。
▲适合上skill的场景
固定、高重复、确定性,过程反复,出错代价小的任务;

▲不适合上skill的场景
内容没有一个固定、确定的范式标准答案,创意性高,这种一般需要人工去做校准会更合适;
1.4 skills解决的核心问题(★★★)
1、【上下文爆炸】
为了让智能体能够灵活查询数据库,MCP服务器通常会暴露数十甚至上百个工具(不同的表、不同的查询方法)。这些工具的完整JSON Schema在连接建立时就会被加载到系统提示词中,可能占用数万个token。据社区开发者反馈,仅加载一个Playwright MCP 服务器就会占用200k上下文窗口的8%,这在多轮对话中会迅速累积,导致成本飙升和推理能力下降。
2、【能力鸿沟】
MCP解决了"能够连接”的问题,但没有解决“知道如何使用"的问题。拥有数据库连接能力,不等于智能体知道如何编写高效且安全的SQL;能够访问文件系统,不意味着它理解特定项目的代码结构和开发规范。这就像给一个新手程序员开通了所有系统的访问权限,但没有提供操作手册和最佳实践。
1.5 skill架构组成(★★★)
以下是一个skill工具的完整结构范式

【详细说明】
为了支持复杂的任务,除了核心的SKILL.md,Skill文件夹还可以包含以下可选目录:
·scripts/:包含该技能专属的自动化脚本(如Python、Bash或Node.js)。当某些任务通过纯Prompt难以稳定实现,或者需要进行复杂的数值计算、文件处理时,Agent可以直接运行这些脚本。
·references/:存放该领域的专业文档、API手册、技术标准或常见问题解答(FAQ)。Agent 会在需要时按需读取这些参考资料,这既能保证专业性,又避免了将所有知识硬编码在提示词中。
·assets/:存放各种静态资源,例如配置模板、数据文件、用于对比的示例图像或预定义的JSON Schema。这些资源为Agent提供了执行任务所需的"原材料”。如果说MCP是一个个独立的工具,那么Skill就是一个工具箱--里面不仅装有工具,还附带了详细的使用说明书
(SKILL.md)
二、三层架构:把Skill拆开看明白(★★★★★)
一个设计良好的Skill,可以用三层架构来理解:Metadata(元信息)、Instruction(指令)、Resources(资源)。
2.1 第一层:Metadata(元信息)——技能的「身份证+说明书」
Metadata定义技能的身份、边界与治理规则。它回答:
这个Skill叫什么?解决什么问题?
输入/输出是什么结构?
有哪些风险与边界?
版本信息、作者、兼容性等
在SKILL.md的开头,通常用YAML格式定义:
name: milvus-collection-builder
description: Create Milvus collections using natural language, supporting both RAG and text search scenarios
version: 1.0.0
author: AI TeamAgent在启动时,会预先加载所有已安装技能的Metadata到系统提示中,这是「渐进式披露」的第一层。
2.2 第二层:Instruction(指令)——技能的「操作系统」
Instruction是技能的执行流程与质量标准。它不是一句「请你专业一点」,而是可执行的SOP:
先澄清哪些信息,缺什么就问什么
什么情况下必须检索,什么情况下不该检索
工具如何选择、调用顺序是什么、失败怎么兜底
结果如何验证、冲突证据如何处理
输出格式、引用规范、口吻要求
最终如何自检与验收
如果Agent判断某个技能与当前任务相关,它会进一步读取并加载该技能完整的SKILL.md内容作为上下文。
2.3 第三层:Resources(资源)——技能的「手脚+资料库」
Resources定义技能可调用的工具、可检索的知识与可观测的反馈系统,包括:
-
脚本(Scripts):预先写好的Python/Shell脚本,Agent可以直接调用
-
模板(Templates):可重复使用的文档模板
-
参考资料(References):API文档、技术规格、最佳实践指南
三、核心设计理念:渐进式披露(Progressive Disclosure)
渐进式披露是让Agent Skills灵活可扩展的核心设计原则。就像一本组织良好的手册——先有目录,然后是具体章节,最后是详细附录——技能让Agent只在需要时才加载信息。
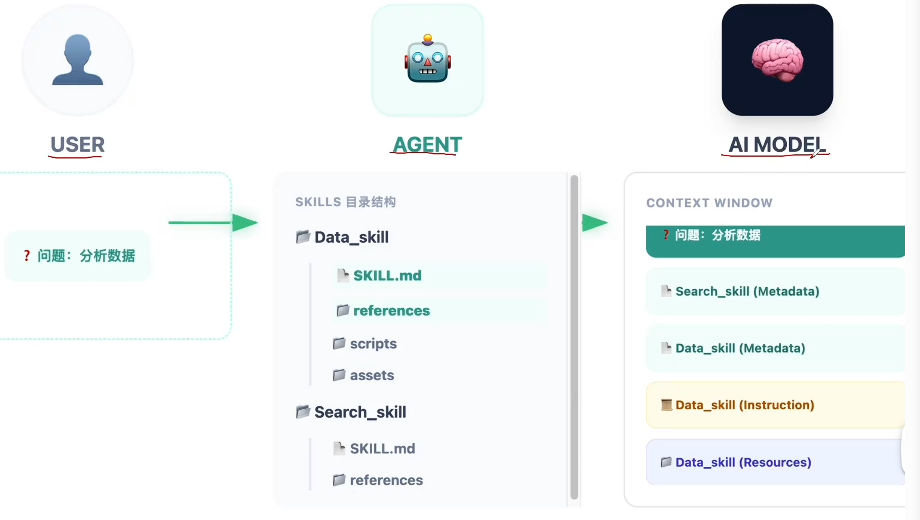
【 Skill 执行流程】
1. 用户提问
用户输入问题,例如:“分析数据”
系统将该问题与所有可用 Skill 的元数据(Metadata)一并发送给大模型
2. 模型分析 & Skill 选择
大模型基于用户问题 + 各 Skill 的描述(Metadata)判断最匹配的 Skill
返回结果示例:
选中的 Skill:
Data_skill理由:用户问题涉及数据分析,符合该 Skill 的功能定位
3. Agent 接收指令
Agent 根据模型选择的 Skill,加载对应的:
Instruction(执行指导)
Resources(脚本、参考、资产等)将完整上下文封装后,再次提交给大模型
4. 大模型执行
大模型根据 Instruction 和 Resources 执行具体任务
输出结果返回给用户或触发后续操作
图示关联说明
图片结构 对应流程环节 SKILLS 目录结构 定义每个 Skill 的组成: SKILL.md(元数据)、references、scripts、assetsCONTEXT WINDOW 表示当前上下文窗口内包含的内容:问题 + 各 Skill 的元数据 + 选定 Skill 的指令与资源 箭头流程 体现“用户 → 模型 → Agent → 模型 → 输出”的闭环逻辑
✅ 总结(一句话版本)
用户问题与技能元数据一起提交给大模型,模型选择最匹配的 Skill,Agent 按需加载该 Skill 的指令与资源后再次提交给大模型执行,最终输出结果。
3.1 三层披露机制(★★★★★)
| 层级 | 组件 | 内容类型 | 加载策略 | 设计目的 |
|---|---|---|---|---|
| L1 | Metadata | 名称、描述、版本 | Always-On(常驻) | 供模型进行路由决策与意图识别 |
| L2 | Instruction | SKILL.md正文规则 | On-Demand(命中后加载) | 定义具体的业务处理逻辑与SOP |
| L3 | Resources | 脚本、参考资料 | Context-Triggered(条件触发) | 提供必要的领域知识,用完即弃 |
Agent Skils 最核心的创新是渐进式披露(Progressive Disclosure)机制。这种机制将技能信息分为三个层次,智能体按需逐步加载,既确保必要时不遗漏细节,又避免一次性将过多内容塞入上下文窗口。
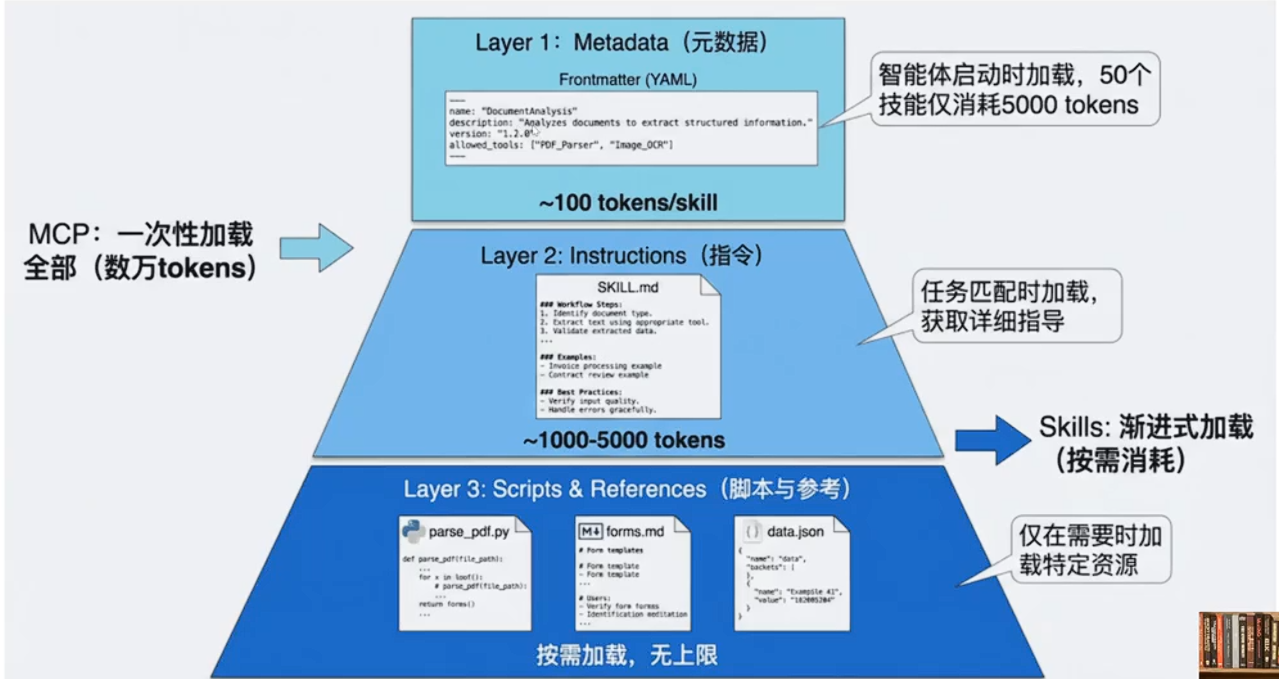
【第一层:元数据(Metadata)】
在Skills的设计中,每个技能都存放在一个独立的文件夹中,核心是一个名为SKILL.md的Markdown文件。这个文件必须以YAML格式的Frontmatter开头,定义技能的基本信息。
--- name: hello-skill description: Anthropic's official brand colons and typography.. ---当智能体启动时,它会扫描所有已安装的技能文件夹,仅读取每个SKILL.md的Frontmatter部分,将这些元数据加载到系统提示词中。根据实测数据,每个技能的元数据仅消耗约100个token。即使你安装了50个技能,初始的上下文消耗也只有约5,000个token。
这与MCP的工作方式形成了鲜明对比。在典型的MCP实现中,当客户端连接到一个服务器时,通常会通过tools/list请求获取所有可用工具的完整JSON Schema,可能立即消耗数万个token。
【第二层:技能主体(Instructions)】
当智能体通过分析用户请求,判断某个技能与当前任务高度相关时,它会进入第二层加载。此时,智能体会读取该技能的完整SKILL.md文件内容,将详细的指令、注意事项、示例等加载到上下文中。
此时,智能体获得了完成任务所需的全部上下文:数据库结构、查询模式、注意事项等。这部分内容的token消耗取决于指令的复杂度,通常在1,000到5,000个token之间。
【第三层:附加资源(Scripts & References)】
对于更复杂的技能,SKILL.md可以引用同一文件夹下的其他文件:脚本、配置文件、参考文档等。智能体仅在需要时才加载这些资源。
例如,一个PDF处理技能的文件结构可能是:

综合来看,新兴的智能体架构呈现出以下组合形态:
1.智能体循环(Agent loop):决定下一步行动的核心推理系统智能体循环是使人工智能智能体持续朝着目标努力的循环过程。首先,智能体从其工具、传感器或记忆中收集最新数据。随后更新内部状态并制定行动方案,通常通过执行规划或推理步骤实现。接着执行选定操作,例如调用APl、写入文件或发送消息。行动后检查结果并存储新信息。循环将基于最新数据重新启动,使智能体能够适应变化并持续进化。这种观察-决策-行动的快速迭代赋予了智能体强大能力。
2.智能体运行时(Agent runtime):执行环境(代码、文件系统)
3.MCP服务器(MCP servers):连接外部工具与数据源的接口
4.技能库(Skills library):领域专业知识与程序化知识的集合
3.2 实际运行流程
当用户发送消息时:
上下文窗口中有核心系统提示、所有已安装技能的Metadata,以及用户的初始消息
Agent判断需要调用某个技能(如PDF处理),通过工具读取该技能的SKILL.md
如果需要,Agent进一步读取技能中引用的附加文件(如forms.md)
最后,Agent带着加载的指令开始执行任务
这种机制让Agent在闲置状态下极其轻量,处理复杂任务时又能瞬间调用庞大的知识储备。
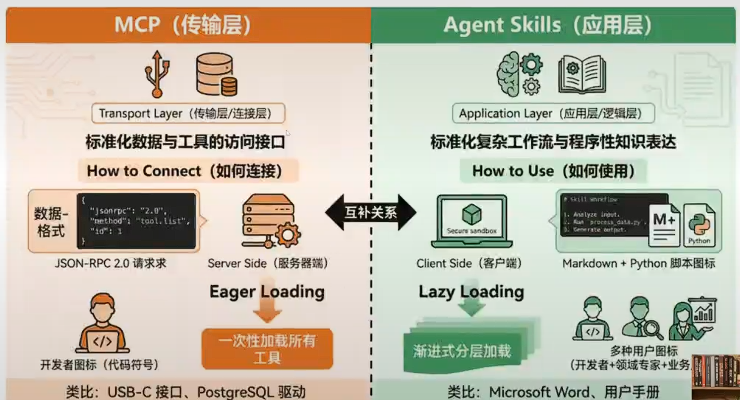
四、Agent Skills vs MCP:不是替代,是协同
在2026年的技术栈中,MCP(Model Context Protocol)与Agent Skills构成了AI应用的「双引擎」。
| 维度 | MCP | Agent Skills |
|---|---|---|
| 本质 | 数据管道(Data Pipeline) | 认知模具(Cognitive Schema) |
| 解决的问题 | 「数据怎么来」 | 「数据怎么用」 |
| 关注点 | 统一方式调用外部工具、数据和服务 | 封装完整的任务处理逻辑与专业知识 |
| 执行方式 | 通过协议调用外部API | 按需加载指令和脚本,客户端执行 |
4.1 协同工作流
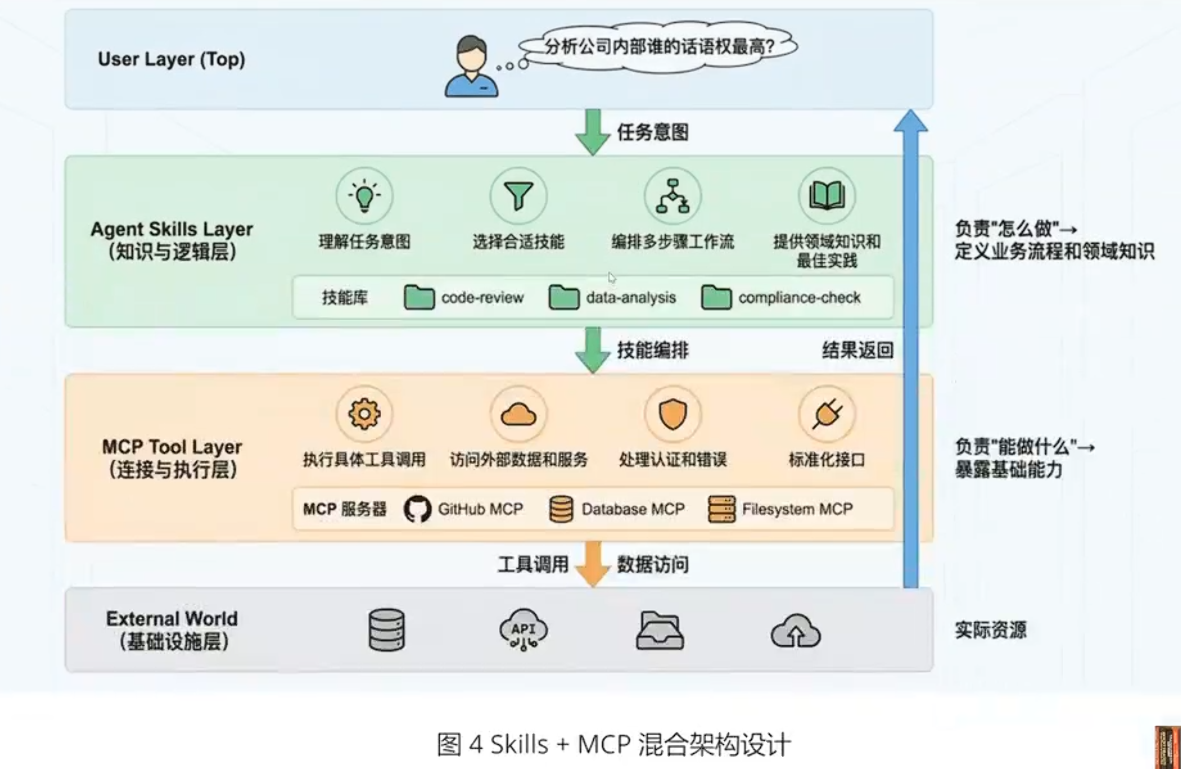
【典型工作流】
1.用户问:"分析公司内部谁的话语权最高”
2.Skills层识别这是一个数据分析任务,加载 mysql-employees-analysis技能
3.Skills层根据技能指令,将任务分解为子步骤:查询管理关系、薪资对比、任职时长等
4.MCP层执行具体的SQL查询,返回结果
5.Skills层根据技能中的领域知识,解读数据并生成综合分析
6.返回结构化的答案给用户
这种架构的优势是:
·关注点分离:MCP专注于”能力",Skills专注于"智慧"
·成本优化:渐进式加载大幅降低token消耗
·可维护性:业务逻辑(Skills)与基础设施(MCP)解耦·复用性:同一个MCP服务器可以被多个Skills使用
股票分析Agent
获取数据(MCP):模型调用Yahoo Finance MCP Server,获取原始JSON数据
处理数据(Skill):模型激活Investment_Analyst Skill,按照技能规则分析数据、生成符合专业格式的报告
最终产出:用户得到一份既包含实时数据(来自MCP),又符合专业研报格式(来自Skill)的分析报告
4.2 Agent Skills 与 MCP本质差异
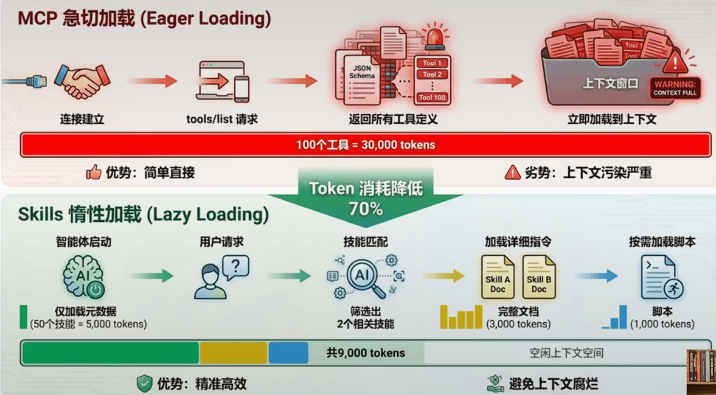
1、mcp急切加载
mcp采用的是动态发现机制:
1.找到mcp所有的工具;
2.然后返回所有工具的定义,再加载到上下文中。如果mcp工具一旦过多,上下文污染就特别严重;
2、Skills惰性加载
1.Agent启动时:仅加载skill描述的元数据文件(50个技能)
2.用户请求——技能匹配:用户发送请求时,会筛选出相关技能
3.加载详细指令:加载md文档主体部分
4.按需加载脚本:如果文档需要脚本处理时,按需加载脚本
五、如何使用Skills(★★★★★)
5.1 操作流程

5.2 安装Agent
平台推荐
国外:claude code(由于限制原因国内用户无法安装,只有国内比较早注册安装过的用户可以使用)
国内:OpenCode
▲为什么选择OpenCode?

▲安装步骤
1、执行OpenCode安装命令
Linux安装指令:
curl -fsSL https://opencode.ai/install | bashWindows安装指令:
npm i -g opencode-ai(说明:npm命令执行前需要先安装好Node.js,版本需≥ 20,Node安装教程:2025最新版Node.js下载安装及环境配置教程【超详图文】-CSDN博客)
2、验证安装是否成功
Linux:
安装好后重新打开命令窗口,输入【opencode】,显示如下界面表示成功;
Windows:
(安装好node环境下)
①win+R打开命令窗口
②输入命令:opencode --version。显示版本号表示安装成功,如下图:
3、启动Opencode
在任意目录打开终端,输入:
opencode你会进入 OpenCode 的交互界面。
4、使用示例(创建个人主页)
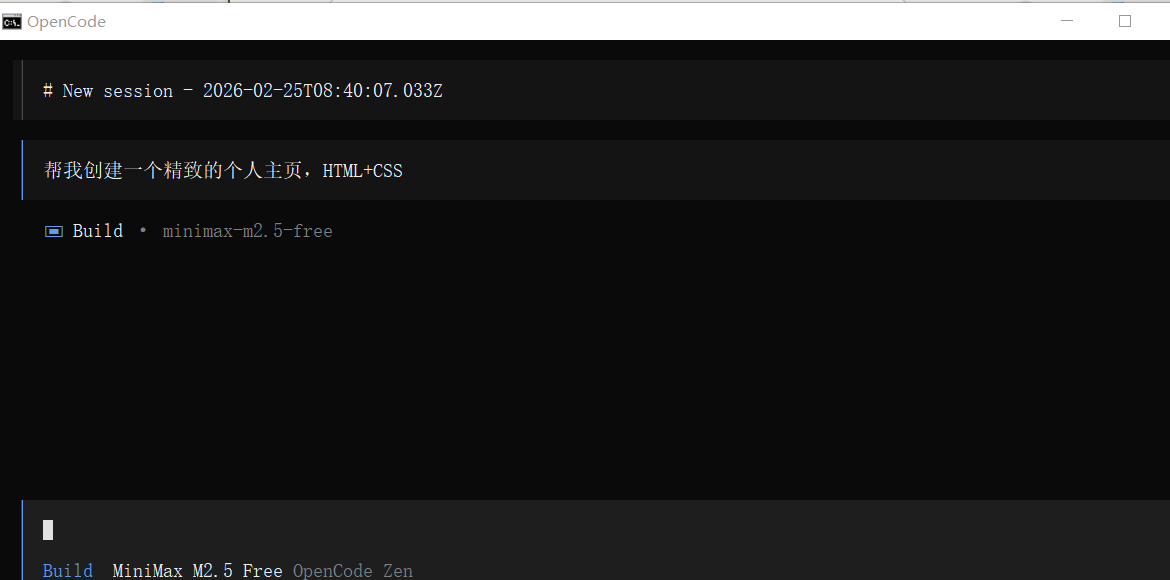
打开项目文件夹并且启动opencode后输入,这里我用的是MiniMax M2.5的模型,项目简单直接使用了Build模式
①输入请求并发送
(点击两下esc就可以打断AI生成)
帮我创建一个精致的个人主页,HTML+CSS②开始执行
执行完可以看到,会自动把文件保存在本地路径中
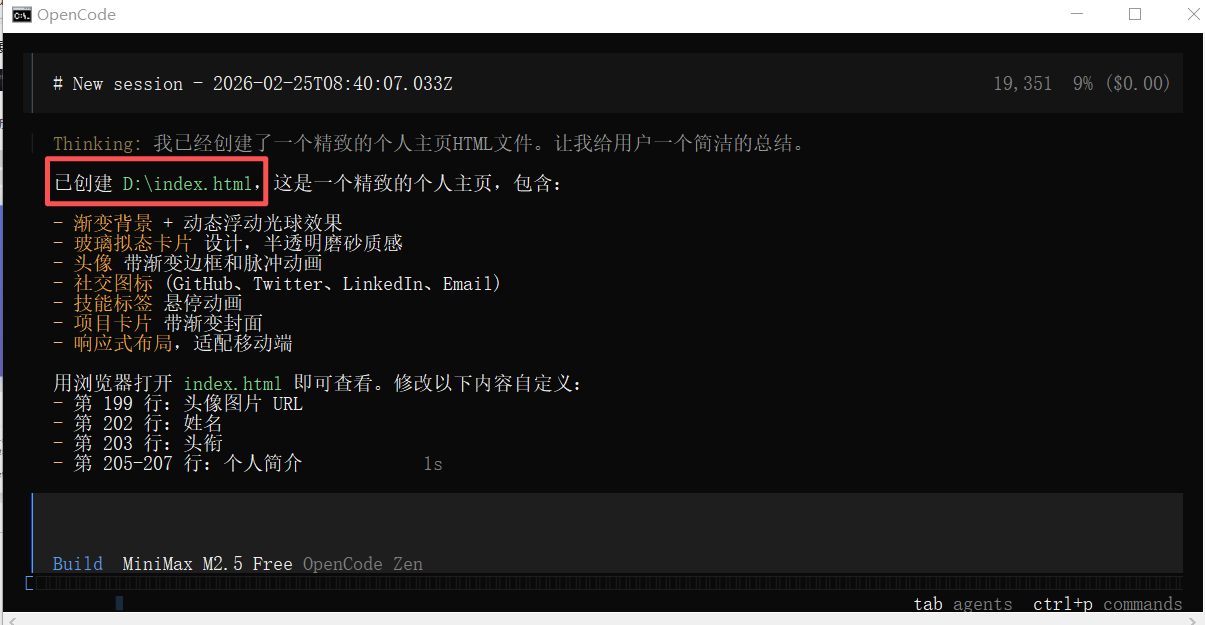
③生成效果
点开“D:\index.html“,可以发现,界面设计整体的观感上没有传统那么重的AI味



5.3 配置模型APIkey
Opencode提供的免费模型虽好,但是也存在速率限制,为了不影响后续我们在执行复杂任务和相关案例的效果,可以通过配置国内不同模型提供商的APIkey,根据需求自行选择:
【国内APIkey申请地址】
智谱:智谱AI开放平台deepseek:DeepSeek 开放平台
qwen:大模型服务平台百炼控制台
下面一智谱为例:
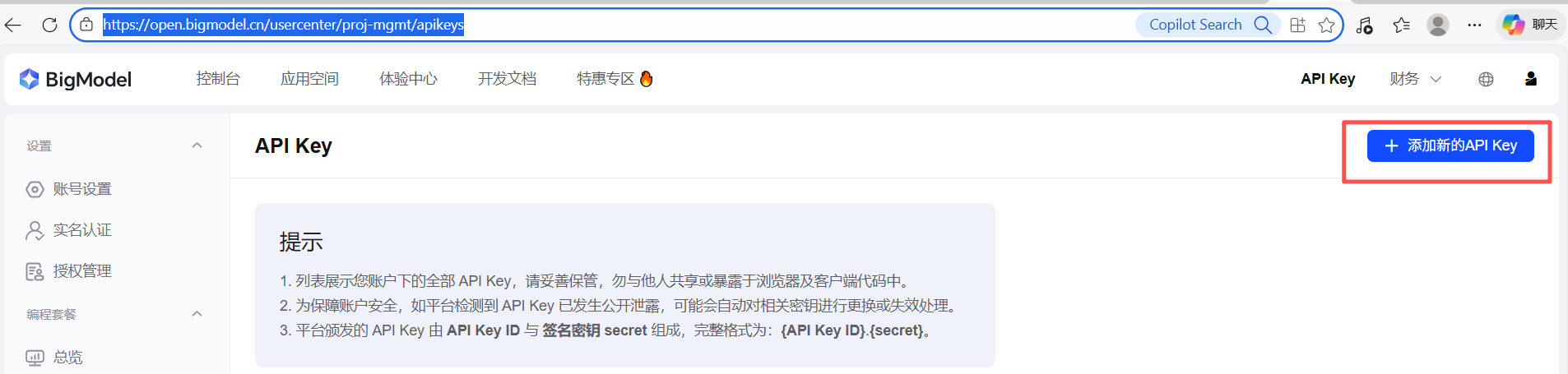
5.3.1 申请APIkey
在智谱官网中点击【添加新的APIkey】
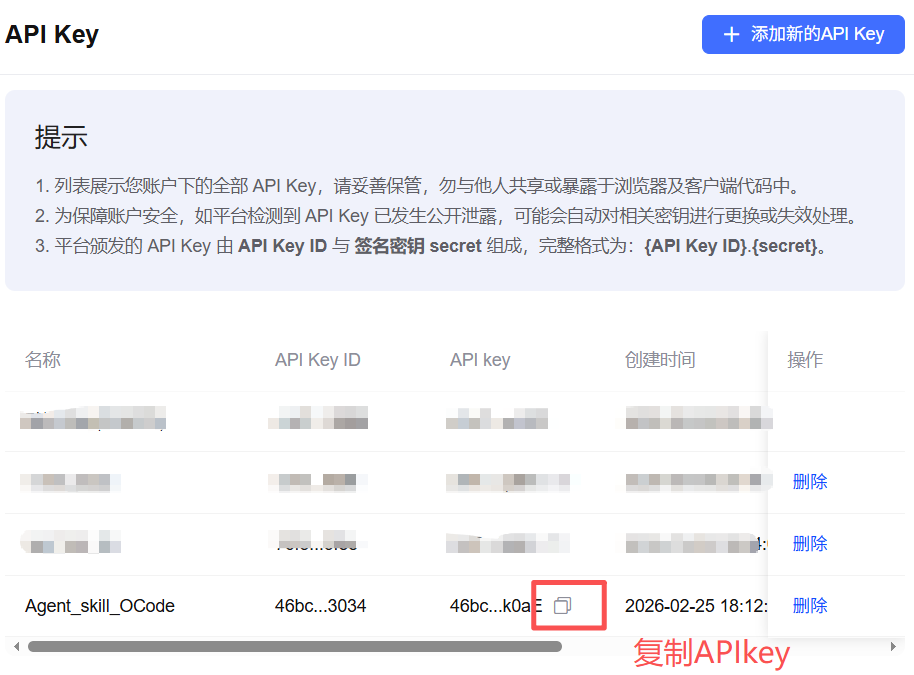
输入APIkey名称,再点击【确定】

5.3.2 智谱模型配置到Opencode
输入并选择【/connect】

填好后,就可以选择智谱提供的模型了(其他厂商的模型一样步骤配置)
5.4 终端中常见用法示例(★★)
5.4.1 Opencode切换模型
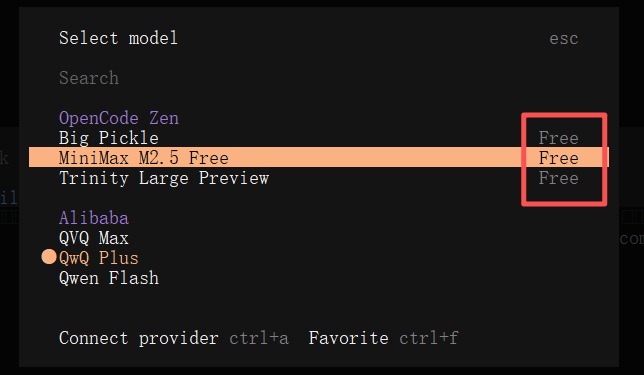
按住ctrl+P,选择Switch model可以进行模型切换
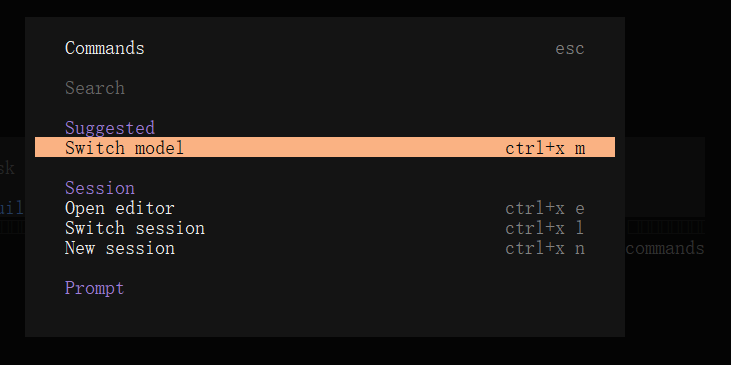
可以看到后面有Free的就是免费模型,其余需要配置APIkey才可使用
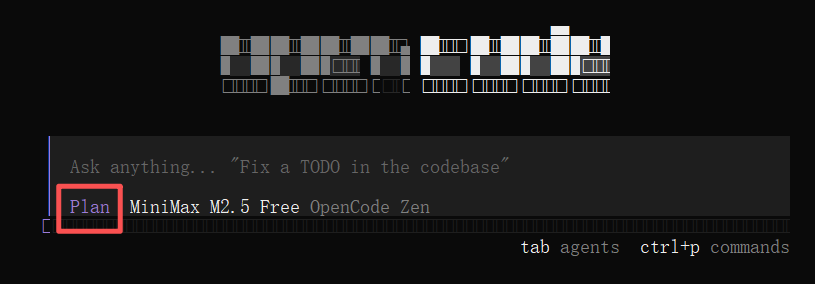
5.4.2 Plan和Build模式的切换
在交互页面,按住tab键就可以切换Plan和Build模式
▲Plan模式:不会修改你的文件和代码,只能阅读你的文件以及给你建议构思等等
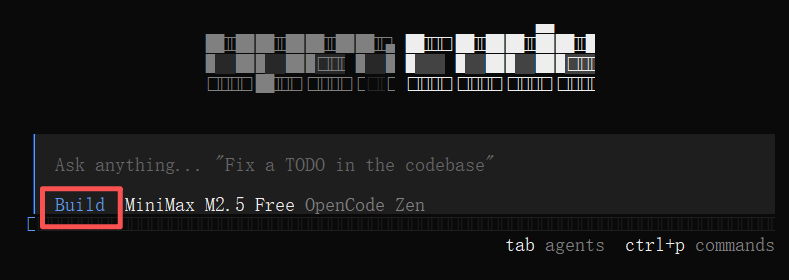
▲Build模式:可以进行文件和代码的修改,建议先用Plan模式构思好,再用Build模式执行
5.4.3 指定skill工具
输入【/skills】,可以找到说有已有的skills列表,我们可以直接指定用哪个工具去完成任务。

选择skill工具
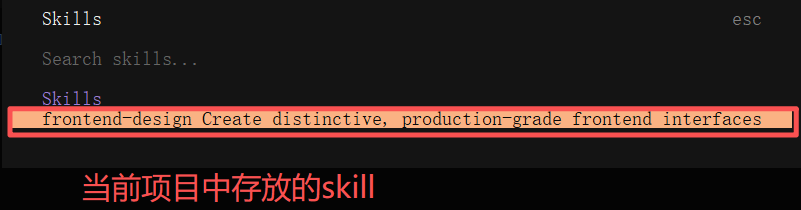
在opencode的输入框中就会出现该skill的前缀

5.4. 退出Opencode
和Claude code 类似输入
/exit输入并选择【/exit】,即可退出opencode操作界面
5.5 下载Skill
5.5.1 Skill下载地址

anthropic官方仓库:GitHub - anthropics/skills: Public repository for Agent Skills
Skills社群网站:Agent Skills 市场 - Claude、Codex 和 ChatGPT Skills | SkillsMP
优秀开源集合:https://github.com/ComposioHQ/awesome-claude-skills
视频制作skill:https://github.com/remotion-dev/skillsyoutube
视频剪辑skill:https://github.com/op7418/Youtube-clipper-skill
大师帮你创建skill的skill:https://github.com/GBSOSS/skill-from-masters
notebookLM skill: https://github.com/PleasePrompto/notebooklm-skill
markdown发布到X skill: https://github.com/wshuyi/x-article-publisher-skill
Al视频产品 Vidu Skills:https://www.vidu.cn/
5.5.2 下载skill
这里演示两个示例,其他工具5.5.1中的地址自行实践下载。
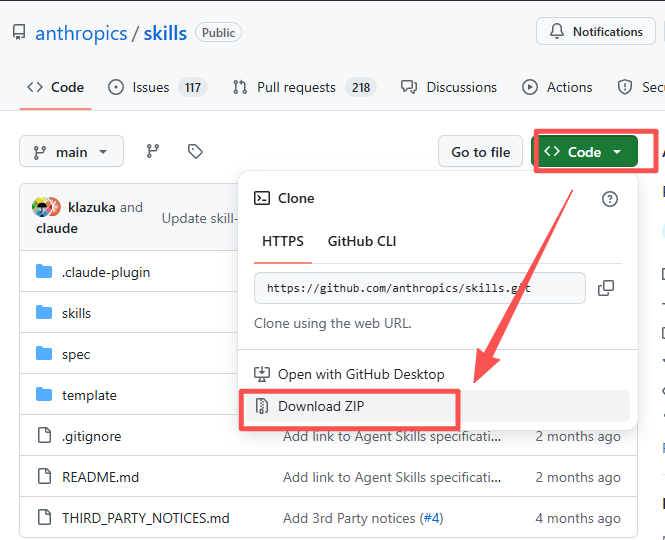
▲方式1:Anthropics官方下载skill
anthropic官方仓库:GitHub - anthropics/skills: Public repository for Agent Skills
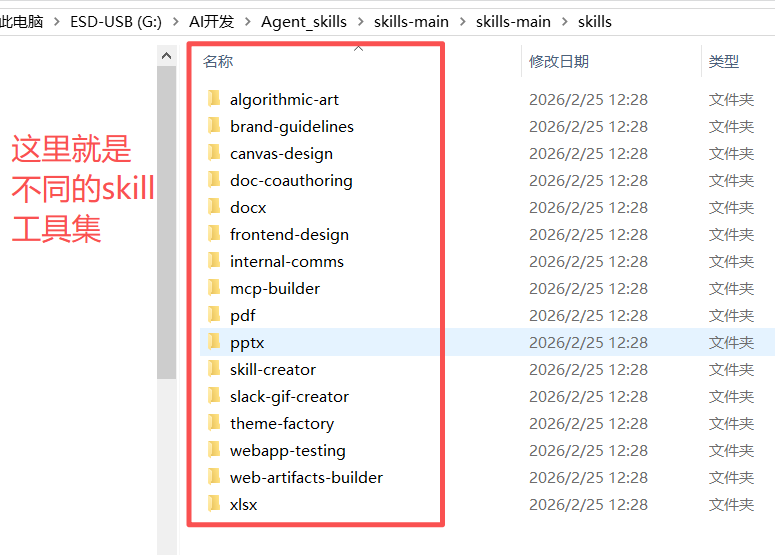
解压文件,找到\skills-main\skills-main\skills路径,每个文件夹都是一个不同的Skills工具
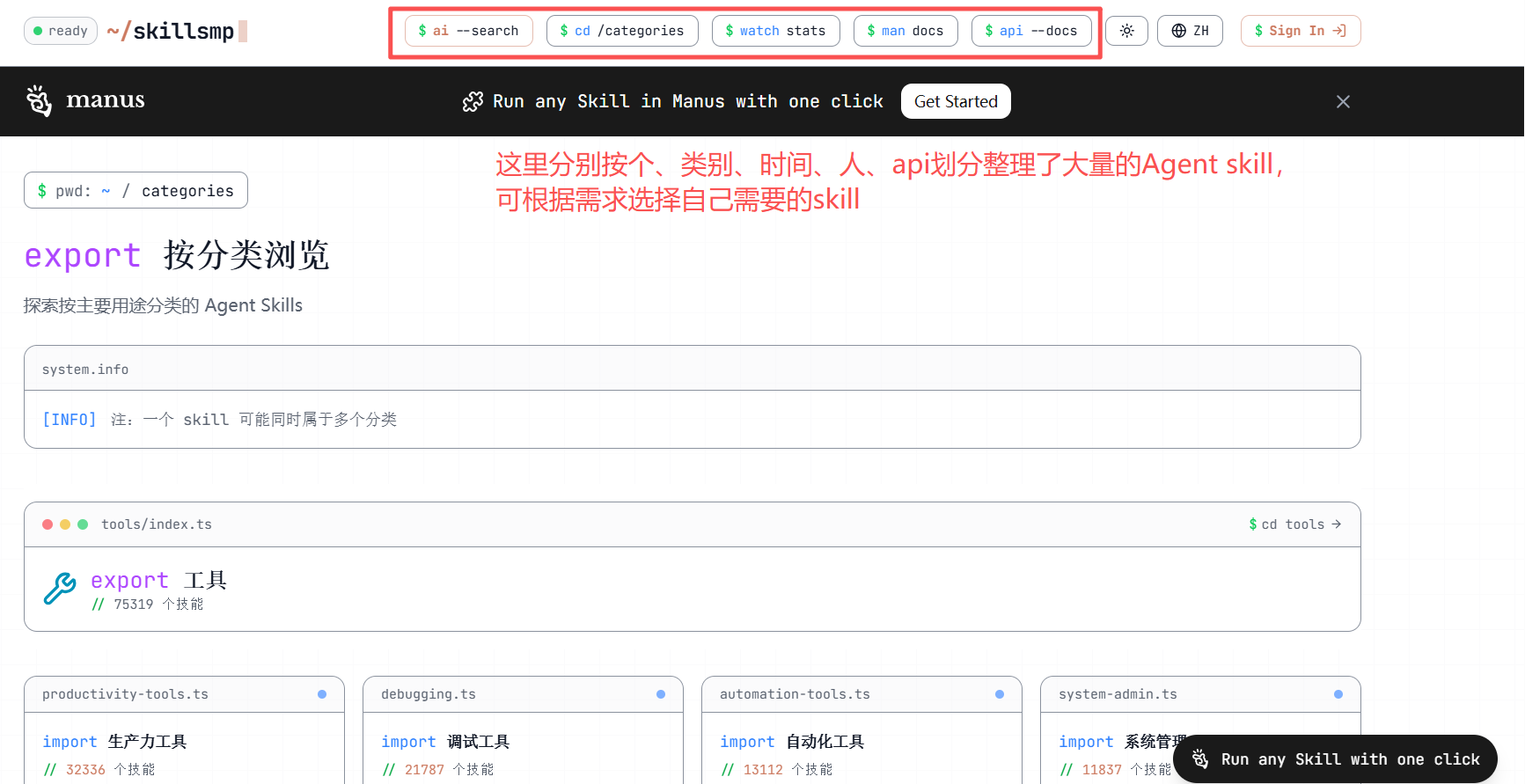
▲方式2:Skills社群网站下载skill
Skills社群网站:Agent Skills 市场 - Claude、Codex 和 ChatGPT Skills | SkillsMP
选择自己想要的skill,点进去
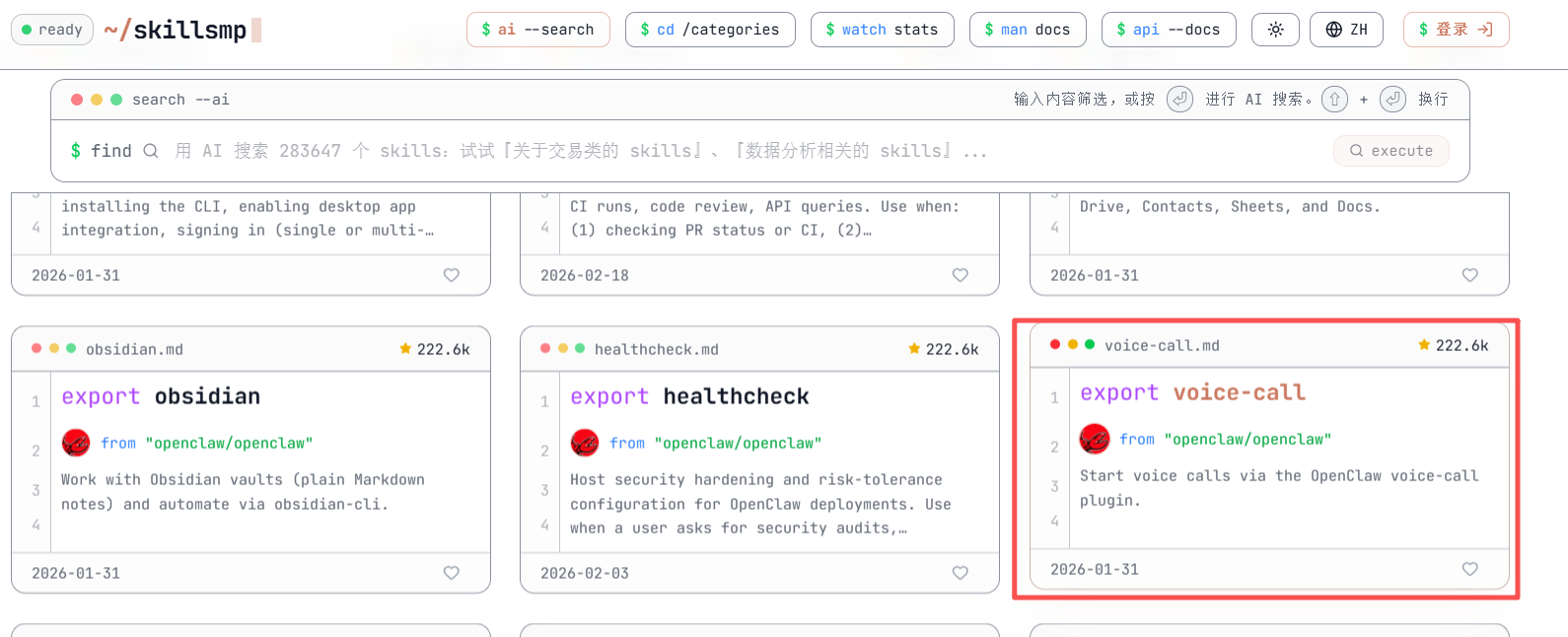
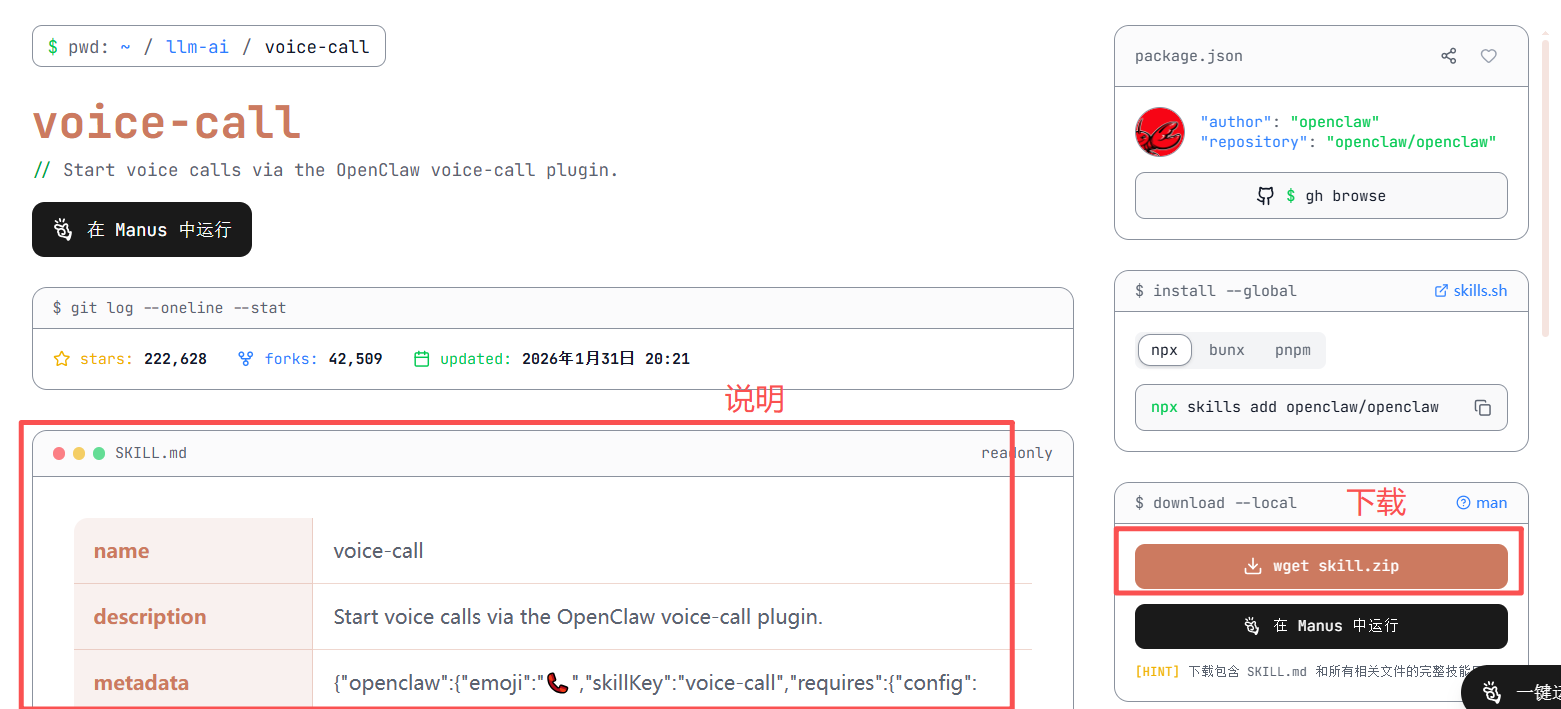
5.6 使用skill
5.6.1 构建文件结构
作为实践演示,先创建:
①项目文件夹:project-base
②skill存放文件夹:./.opencode/skills
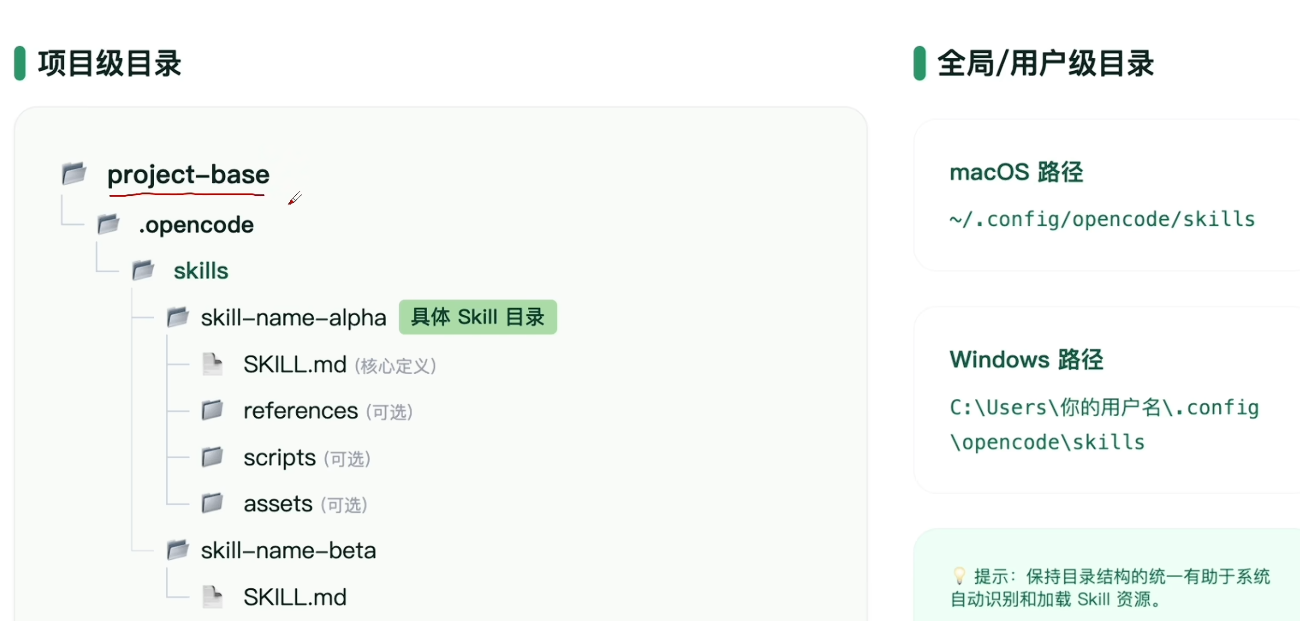
详细说明
project-base:表示当前项目根目录;./.opencode/skills:将所有的skill工具统一放在该路径下;
5.6.2 下载与使用skill工具
接下来我们通过一个专门做前端的skill来完成一个企业级网页设计
①下载地址(下载步骤看5.5.2)
anthropic官方仓库:GitHub - anthropics/skills: Public repository for Agent Skills
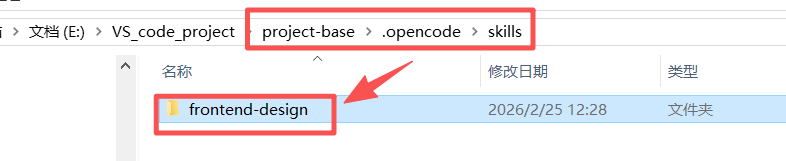
②选择skill工具放进./.opencode/skills目录中,这里选择一个专业的前端制作工具frontend-design
③将skill放在该路径下
④在项目根目录下命令打开窗口
⑤输入【opencode】启动opencode
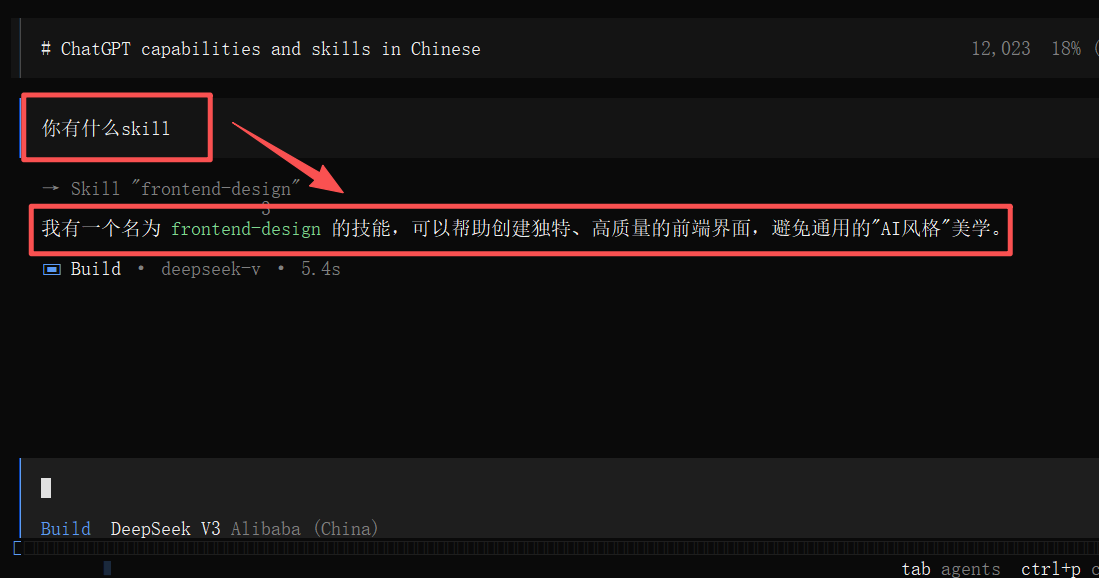
⑥检验skill是否可以被检索到
发送问题请求:
你有什么skill?成功被检索到
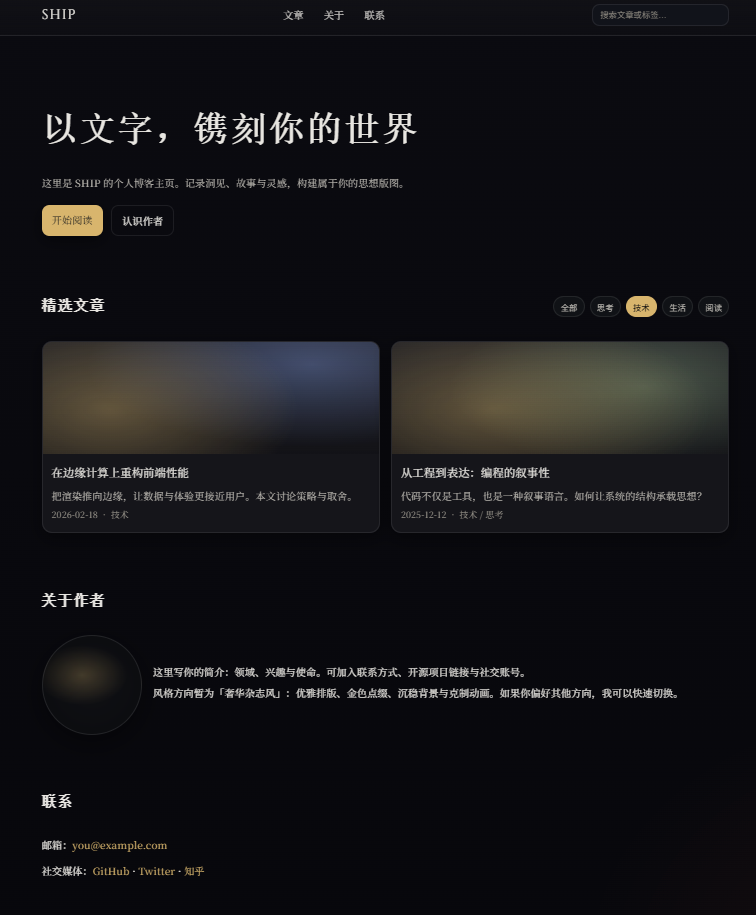
⑦测试效果
给我在当前项目根目录下设计一个高大上档次的个人博客主页,配图布局得好看,不确定的地方需要向我确认在执行的过程中,可以看到,会不断向我们确定需求,我们只需简单回复选项即可
最终的效果如下:


六、在代码编辑器中使用 OpenCode(★★★)
代码编辑器自选,如:VSCode、cursor、kiro、windsurf等,步骤都差不多,这里我用的是Kiro。
6.1 安装opencode插件
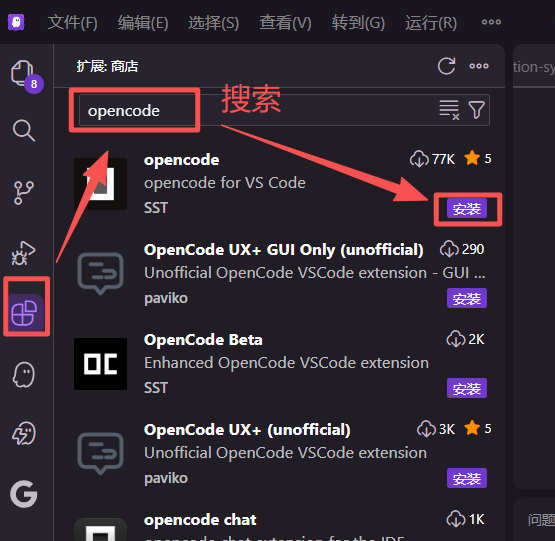
6.2 在代码编辑器中打开opencode
打开你的项目
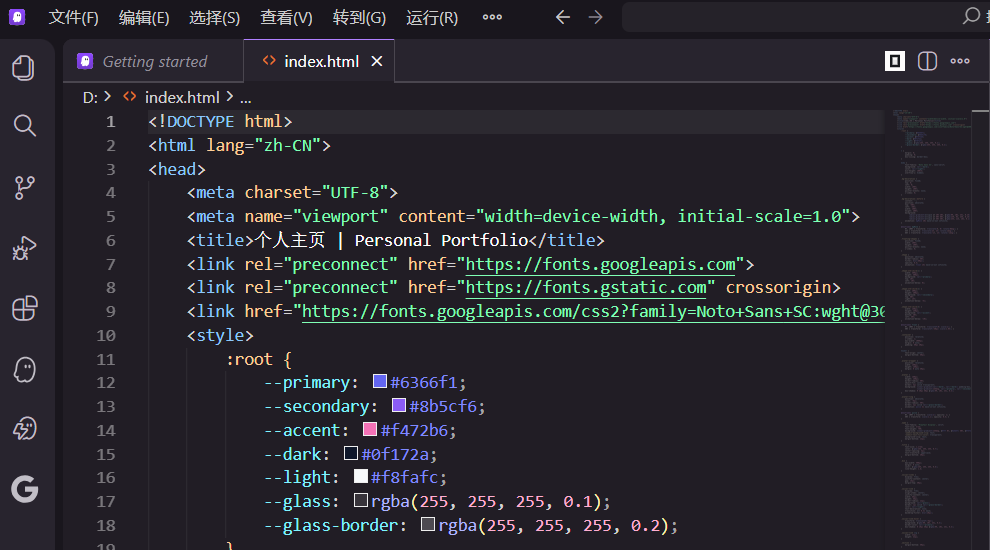
在右上角可以看到opencode的logo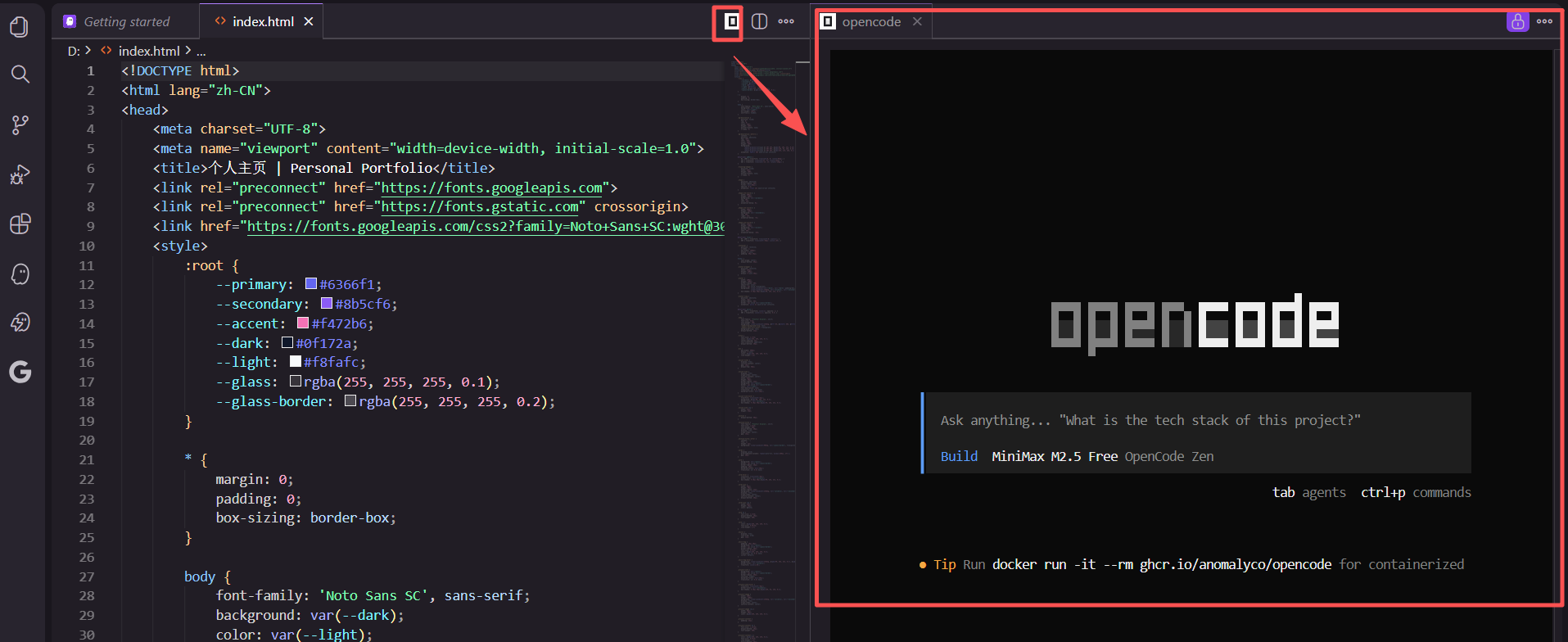
点击就可以启动,测试一下,阅读项目代码
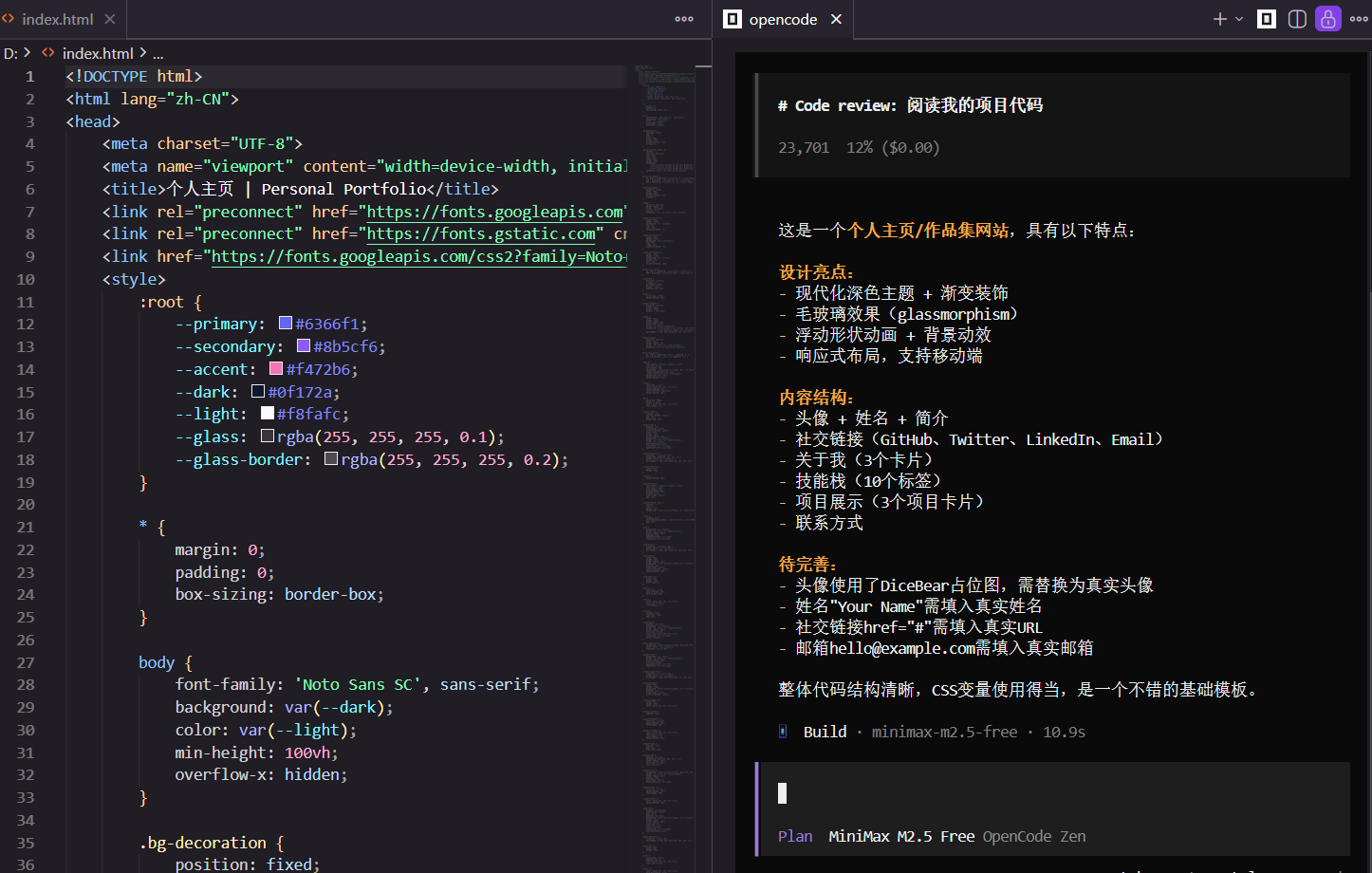
七、如何自己造skill(★★★★★)
想要自己造skill,就得先了解skill的核心架构组成,依照开发范式进行
7.1 skill核心架构
【Agent Skill开发参考书】
1.官方文档:Specification - Agent Skills
2.官方电子书:
The-Complete-Guide-to-Building-Skill-for-Claude.pdf
skill存放的目录下必须要有的文件:SKILL.md
skill包含3层核心架构:元数据层(metadata)、指令层(Instructions)、资源层(resources)
元数据层:描述工具是用来干什么的
指令层:描述工具如何执行,处理异常、参考资料
资源层:参考资料(references)、执行脚本(scripts),模版文件(assets)统称为资源
🟠assets:样式参考模版
🟠references:参考的markdown文档
🟠scripts:处理脚本

7.2 打造skill流程
这里用一个生成周报skill的例子来演示
1.导入项目
将所给的基础项目sample-project.zip解压,然后可用vscode等工具打开,该项目提供了基于git的项目基本结构。
sample-project.zip
2.创建.opencode/skills目录在项目根目录下创建.opencode/skills目录,另外 .opencode/skill目录opencode也是识别的,没有强制要求叫skills还是skill,都能加载到。
3.创建技能文件夹
创建代表自动生成周报的文件夹:weekly-report-generator
4.创建SKILL.md文件
在weekly-report-generator 目录下创建 SKILL.md文件,编写元数据。元数据主要定义名称(格式需符合官方要求)和描述该skill是干嘛用的
--- name: Teekly-report-generator description:自动生成项目周报,从 git提交、issue、todo 文件和用户输入中提取信息,生成专业的 HTML/PDF周报 ---5.编写指令
在SKILL.md中编写指令。指令部分主要定义好:流程、规则、示例说明等相关信息
#指令: 你是一个项目周报生成助手。你的任务是从多种数据源收集本周的项目进展,并生成结构化的周报。 ## 核心流程 1.**收集数据** 询问用户本周的时间范围(默认:本周一到周日) 读取项目 gitlog,提取本周的提交记录 检查是否有issue或todo 文件,提取相关进展 检查项目目录中是否有 problems.md/json、growth.md/json、knowledge.md/json 文件如果项目中没有上述文件,询问用户是否有额外需要添加的内容 2.**处理数据** 使用 scripts/git-analyzer.py 分析 git 提交,提取关键信息 使用 scripts/todo-parser.py 解析 todo/issue,整理完成情况 使用 scripts/user-content-parser.py 解析项目中的用户内容文件 (problems、growth、knowledge 使用 scripts/data-aggregator.py 聚合所有数据,支持 --project-dir 参数指定项目目录参考 references/data-extraction.md了解详细的数据提取方法 3.**组织周报结构** 参考 references/report-structure.md 了解周报的标准结构将数据组织成以下模块: 数据统计(提交数、参与人数、完成事项等) 本周进展(功能开发、问题修复、技术改进) 本周遇到的问题 本周个人成长 相关知识分享 下周计划 风险与问题 ##周报内容说明 用户需要提供以下内容(支持三种方式): **方式一:在项目中提供文件(推荐)** **本周遇到的问题**:在项目根目录创建‘problems.md’或‘problems.json’文件 **本周个人成长**:在项目根目录创建 ‘growth.md’或‘growth.json’文件 **相关知识分享**:在项目根目录创建 ‘knowledge.md或 ‘knowledge.json’文件 JSON 格式需符合 user-input.json~中的结构定义。Markdown 格式需包含相应的标题和内容。 **方式二:通过 user-input.json 文件提供**在 user-input.json 中定义 problems、growth、knowledge 字段 **方式三:对话提供** 如果项目中没有提供文件,按规则询问用户输入 内容说明: **本周遇到的问题**:开发过程中遇到的技术难题、阻塞问题等,包含问题描述、类型、解决方案、经验教训**本周个人成长**:学到的技术、能力提升、经验总结,包含类别、内容、影响 **相关知识分享**:值得记录的技术知识点、最佳实践、学习资源,包含标题、内容、资源链接 ##使用说明 用户可以直接说:"帮我生成本周的周报",或者提供具体的时间范围。 ##注意事项 如果项目不是git 仓库,跳过git log分析 如果没有issue或todo文件,提醒用户手动输入关键进展 需要安装Chrome 或使用浏览器手动生成 PDF 同时输出 HTML和 PDF两种格式6.引入相关资源
从所给资料中,引入相关的资源(如:references、scripts、assets等)到 weekly-report-generator 目录下以上是个完整的skill
7.验证skill
在项目目录下启动opencode窗口,让其生成周报,最终生成效果示例如下:

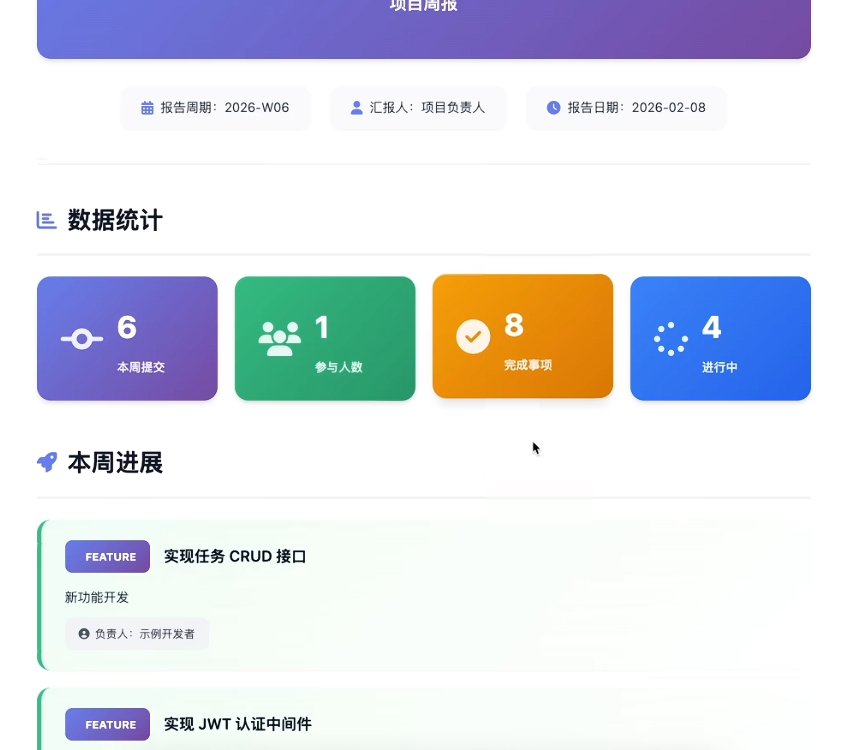
skill整体的构建不会很复杂,关键的难点是如何去定义好SKILLS.md文档的流程、规则,怎么去搭建整体框架。
八、用skill造skill(★★★★★)
简单来说就是:用一个专业写skill的skill,造一个符合我们预期的一个skill。用魔法打败魔法!
当我们刚开始尝试去开发一个skill时,SKILLS.md的规则流程编写只有一个大概的想法,没有一个明确的目标时,可以通过这种方法帮我们快速构建SKILLS.md、执行脚本、参考文档、模版等文件,实现快速开发。
8.1 创建项目文件
1、创建项目文件夹:Agent_skill_create_skill文件夹(自定义名称)
2、在Agent_skill_create_skill里面再创建:.opencode文件夹(统一格式)
3、在.opencode里面再创建:skills文件夹(统一格式)
8.2 下载并选择skills
1、下载skills(参考5.5.2中下载流程)
anthropic官方仓库:GitHub - anthropics/skills: Public repository for Agent Skills
2、下载后解压文件,进入到./skills-main/skills-main/skills路径下,将【skill-creator】文件复制到【./Agent_skill_create_skill/.opencode/skills】路径下
8.3 启动opencode并执行
(说明:以下步骤需提前在代码编辑器中按照opencode,参考【六、在代码编辑器中使用 OpenCode(★★★)】)
1、在代码编辑器中启动opencode;
2、提出问题;
【需求】
我想创建一个skill,场景是这样的,很多开发者即进到一个新的公司,拿到现目之后不知道如何快速了解当前现目,包括:现有架构,用到的技术栈,现有的目录结构是什么样的,有什么重要的配置;如果我要开发一个模块的话,不知道从哪里下手,项目怎么部署,怎么访问等等,我只能想到这些,需要你和我共创这个场果下的skill,应设如何创建,我需要你给我创建好,并且将创建好的skill直接放到当前项目下的.opencode/skills/目录下,开始吧
九、实战案例:从零构建一个Milvus RAG Skill
为了更直观地理解,我们来看一个实际案例——为Milvus向量数据库创建自定义Skill,实现通过自然语言快速搭建RAG系统。
9.1 目录结构
~/.opencode/skills/milvus-skills/
├── SKILL.md # 核心指令
└── scripts/ # 辅助脚本
├── check_env.py # 环境检查
├── intent_parser.py # 意图解析
├── milvus_builder.py # 集合构建器
└── insert_milvus_data.py # 数据插入9.2 SKILL.md核心内容
name: milvus-collection-builder
description: Create Milvus collections using natural language, supporting both RAG and text search scenarios
# Milvus集合构建技能
## 何时使用
当用户需要通过自然语言描述来创建Milvus集合,用于RAG或文本搜索场景时。
## 执行流程
1. **理解用户意图**:判断用户需要RAG场景还是文本搜索场景
2. **调用意图解析**:运行scripts/intent_parser.py,将自然语言转换为结构化意图
3. **构建集合**:根据解析结果,调用milvus_builder.py创建合适的集合模式和索引配置
4. **准备数据插入**:如需插入数据,调用insert_milvus_data.py处理文档分块和向量化
## 环境要求
- Milvus服务已启动(默认端口19530)
- 必要的Python依赖已安装当用户说「我想建一个RAG系统」时,Agent会:
-
通过Metadata识别到milvus-collection-builder技能可能相关
-
加载完整的SKILL.md,了解执行流程
-
依次调用scripts/中的脚本,完成环境检查、意图解析、集合创建和数据插入
十、Skill开发实践流程
10.1 从评估开始
在开发技能前,先在代表性任务上运行你的Agent,观察它在哪些地方挣扎或需要额外上下文。然后增量式地构建技能来解决这些问题。
10.2 为规模化而结构
当SKILL.md变得臃肿时,将其内容拆分到单独的文件中并引用。如果某些上下文互斥或很少一起使用,保持路径分离可以减少Token使用。
10.3 从Agent的视角思考
监控Agent如何在真实场景中使用你的技能,并根据观察迭代:
-
特别注意技能的
name和description,Agent会用它们来决定是否触发技能 -
观察意外的执行路径或对某些上下文的过度依赖
10.4 与Agent协作迭代
在使用Agent完成任务时,让它将成功的做法和常见错误捕获到可重用的上下文和代码中,形成技能。如果它使用技能时偏离轨道,让它自我反思哪里出错了。
10.5 安全注意事项
技能通过指令和代码为Agent提供新能力,这意味着恶意技能可能引入漏洞:
-
只从可信来源安装技能
-
安装前彻底审计技能内容
-
特别注意指示Agent连接到不可信外部网络源的指令或代码
-
遵循最小权限原则,技能仅在需要时临时开放权限
十一、行业趋势:从提示词工程到技能工程
2025年10月,Anthropic首次发布Claude Skills;两个月后,Agent Skills被确立为开放标准,OpenAI、GitHub、VS Code、Cursor等均已跟进。
这一标准的确立,标志着AI开发正在经历从「炼金术」到「工程化」的转型。技能可以被「资产化」、可跨环境迁移,未来可能走向社群共享与技能市集的模式。
对于企业而言,Skills是把领域专业知识编码并使其可重复的简易方式:
-
对新开发者:降低了入门门槛,不需要学习每个细节就能开始
-
对有经验的团队:减少了重复设置的次数,有助于保持项目在不同环境下的一致性
总结
Agent Skills的核心理念其实很简单:把「模型会不会」变成「系统能不能稳定交付」,把「靠提示词玄学」变成「可复用、可迭代的工程能力」 。
从手写脚本到标准化的Agent Skills,再到工程化的MCP协议,AI开发正在经历从作坊式到工业化的转型。掌握Agent Skills的配置与开发,不再是锦上添花的技能,而是构建下一代智能应用的入场券。
未来,谁能更高效地管理和复用这些「数字技能」,谁就能在AI浪潮中占据主动。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 1
1- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)