【AI时代必备】超详细Qdrant向量数据库入门实战:Docker部署 + Node.js接入 + 核心概念解析
本文介绍了如何快速上手开源向量数据库Qdrant,包含Docker部署和Node.js接入的完整流程。首先通过docker-compose配置Qdrant服务,设置API密钥和数据持久化。然后使用Node.js SDK演示了创建集合、插入向量数据和执行相似度搜索的操作步骤。文章还解释了Qdrant的核心概念,包括数据结构、检索索引和分布式架构设计。Qdrant凭借其高性能和轻量级特性,适用于RAG
前言
随着大模型(LLM)和AI应用的爆发,向量数据库成为了当前最火热的技术栈之一。无论是做RAG(检索增强生成)、语义搜索还是推荐系统,都离不开它。
这两天我抽时间研究了开源高性能向量数据库 Qdrant,并跑通了从Docker部署到Node.js代码接入的全流程。这篇文章是我学习过程中的笔记总结,希望能帮到想快速上手向量数据库的同学们!
一、 使用 Docker 快速部署 Qdrant
为了方便环境管理和后续迁移,这里强烈推荐使用 docker-compose 来部署。
1. 创建 docker-compose.yaml 文件
找一个空目录,新建 docker-compose.yaml 文件,并贴入以下内容。我在里面加了详细的注释,关键配置一看就懂:
version: '3.8' # Docker Compose 文件格式版本
services:
qdrant:
image: qdrant/qdrant:latest # 使用官方最新镜像
container_name: qdrant
restart: always # 容器随 Docker 服务启动而自动启动(生产环境必备)
ports:
# HTTP 端口:用于 REST API 调用和浏览器访问 Dashboard
- "6333:6333"
# gRPC 端口:用于高性能数据写入和查询,多数 SDK (如 Python) 会优先使用此端口
- "6334:6334"
environment:
# 【重要安全配置】API 访问密钥。设置后,请求 Header 必须包含 'api-key: your_secret_key'
- QDRANT__SERVICE__API_KEY=your_secret_api_key
# 日志级别。建议生产环境设为 INFO
- QDRANT__LOG_LEVEL=INFO
# 允许通过环境变量修改配置,例如启用静态内容服务
- QDRANT__SERVICE__ENABLE_STATIC_CONTENT=true
volumes:
# 【数据持久化】将数据挂载到宿主机的 ./qdrant_storage 目录,防止容器重启丢失数据
- ./qdrant_storage:/qdrant/storage
ulimits:
# 向量数据库涉及大量文件读写,增加最大文件打开限制,防止 "Too many open files" 报错
nofile:
soft: 65535
hard: 655352. 启动服务
在终端中运行以下命令启动 Qdrant:
docker compose up -d3. 访问可视化控制台 (Dashboard)
打开浏览器,访问:http://localhost:6333/dashboard
进入页面后,会提示输入 API Key,填入我们在 docker-compose 中配置的 your_secret_api_key 即可进入可视化界面!
二、 在 Node.js 中接入 Qdrant
数据库准备好了,接下来我们用 Node.js 写一段脚本,体验一下创建集合 -> 插入向量数据 -> 向量相似度搜索的完整闭环。
1. 初始化项目并安装官方 SDK
npm init -y
npm install @qdrant/js-client-rest2. 编写实战代码 (index.js)
新建 index.js 文件,复制以下代码。注意替换你的服务器 IP 和 API Key:
const { QdrantClient } = require('@qdrant/js-client-rest');
// 1. 初始化客户端连接 (默认 HTTP 运行在 6333 端口)
const client = new QdrantClient({
url: 'http://127.0.0.1:6333', // 如果是远程服务器,替换为你的服务器 IP
apiKey: 'your_secret_api_key' // Docker 部署时设置的密钥
});
async function main() {
const collectionName = 'my_test_collection';
try {
console.log('--- 1. 准备创建集合 (Collection) ---');
// recreateCollection: 集合存在时先删除再创建,方便重复运行测试
await client.recreateCollection(collectionName, {
vectors: {
size: 4, // 向量维度 (此处用4维演示,实际如 OpenAI 模型通常是 1536 维)
distance: 'Cosine', // 距离度量方式:Cosine(余弦相似度)
},
});
console.log(`集合 "${collectionName}" 创建成功!\n`);
console.log('--- 2. 开始插入数据 (Upsert Points) ---');
await client.upsert(collectionName, {
wait: true, // true 表示等待数据写入并建立索引后再继续
points:[
{
id: 1,
vector: [0.05, 0.61, 0.76, 0.74],
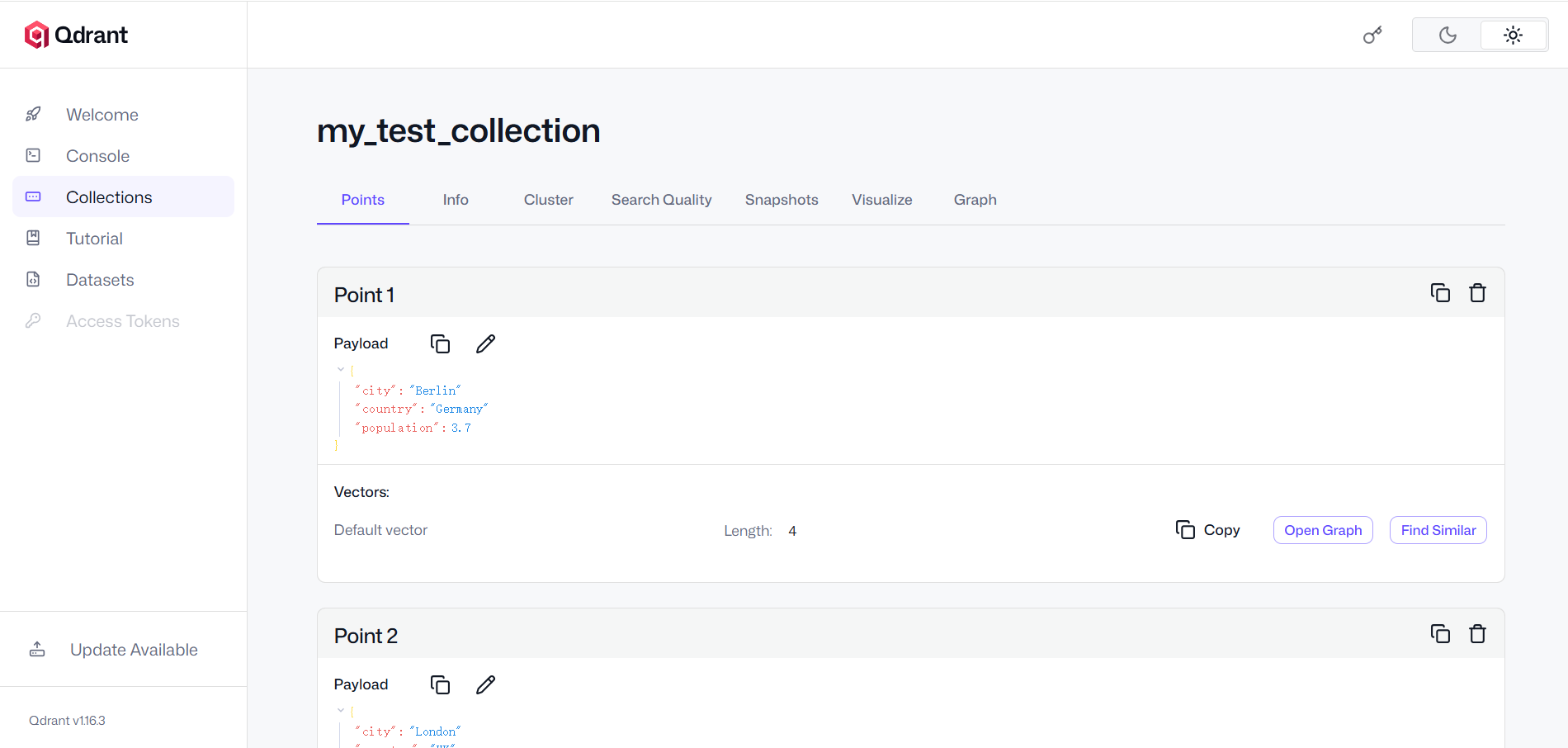
payload: { city: "Berlin", country: "Germany", population: 3.7 }
},
{
id: 2,
vector:[0.19, 0.81, 0.75, 0.11],
payload: { city: "London", country: "UK", population: 8.9 }
},
{
id: 3,
vector:[0.36, 0.55, 0.47, 0.94],
payload: { city: "Beijing", country: "China", population: 21.5 }
}
]
});
console.log('数据插入成功!\n');
console.log('--- 3. 执行向量搜索 (Search) ---');
// 假设这是用户提问经过 AI 模型转换后的查询向量
const queryVector =[0.2, 0.1, 0.9, 0.7];
const searchResults = await client.search(collectionName, {
vector: queryVector,
limit: 2, // 只返回最相似的 2 条结果
});
console.log('搜索结果:');
console.log(JSON.stringify(searchResults, null, 2));
} catch (error) {
console.error('发生错误:', error);
}
}
// 运行主函数
main();3. 运行并查看结果
终端执行 node index.js,你将看到如下输出:
Api key is used with unsecure connection.
--- 1. 准备创建集合 (Collection) ---
集合 "my_test_collection" 创建成功!
--- 2. 开始插入数据 (Upsert Points) ---
数据插入成功!
--- 3. 执行向量搜索 (Search) ---
搜索结果:[
{
"id": 1,
"version": 1,
"score": 0.89463294,
"payload": {
"city": "Berlin",
"country": "Germany",
"population": 3.7
}
},
{
"id": 3,
"version": 1,
"score": 0.83872515,
"payload": {
"city": "Beijing",
"country": "China",
"population": 21.5
}
}
](注:第一行的 unsecure connection 警告是因为本地使用 HTTP 而非 HTTPS,属于正常现象。)
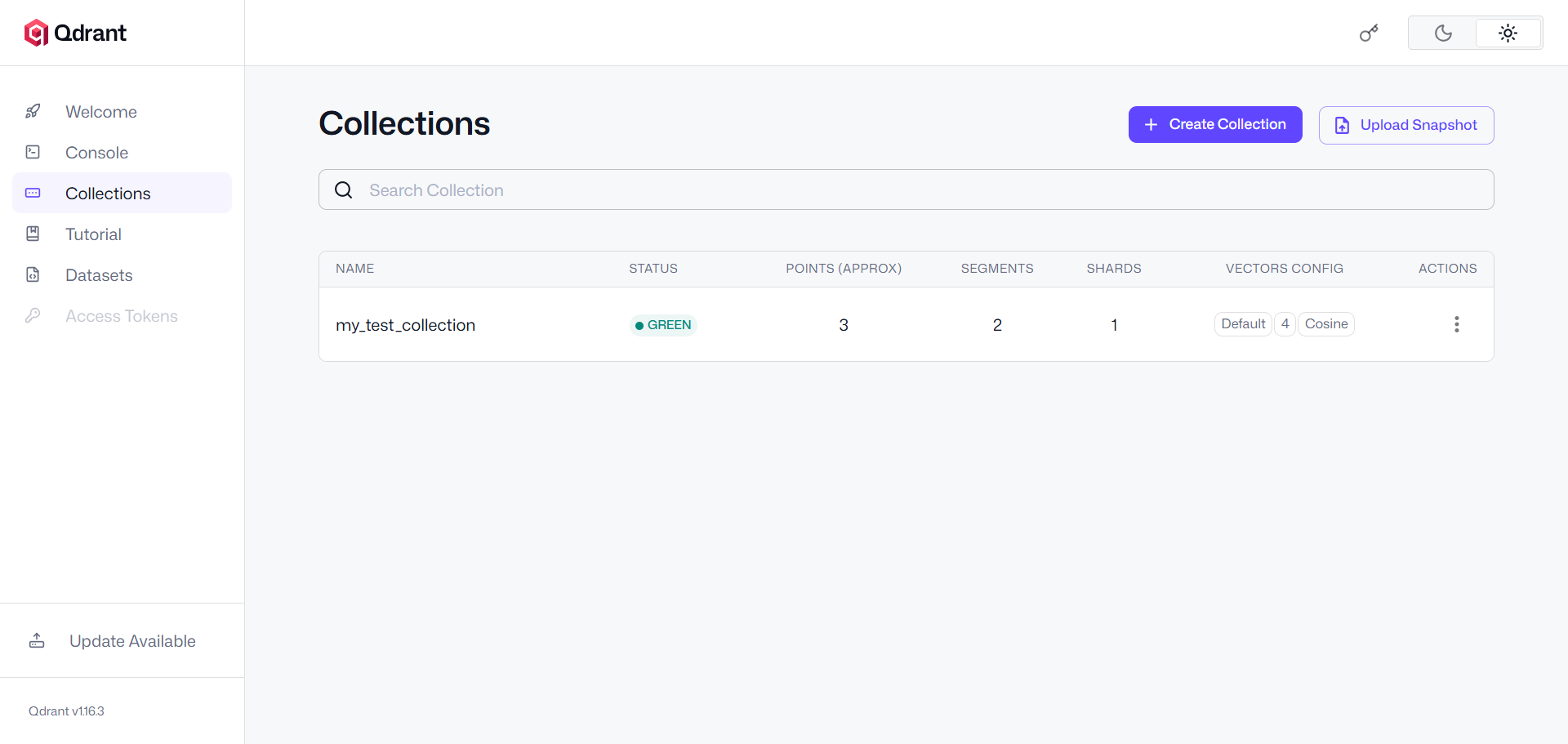
此时,回到你的浏览器打开 Qdrant Dashboard,你会发现 my_test_collection 已经躺在那里了,点进去还能看到我们刚刚插入的数据!
三、 Qdrant 核心概念科普
为了真正掌握 Qdrant,光会写代码还不够,理解背后的概念非常重要。我将它们分为了三大类。
1. 数据结构概念(对比传统数据库)
| Qdrant 概念 | 关系型数据库 | 说明 |
| Collection (集合) | Table (表) | 存储向量及关联数据的容器。创建时需指定向量维度 (size) 和距离度量方式 (distance)。 |
| Point (数据点) | Row (行) | 存储的基本单元。包含三个主要部分:ID (唯一标识符)、Vector (高维浮点数数组)、Payload (元数据)。 |
| Payload (元数据) | Columns (列) | JSON 格式的附加业务数据。可以存入文档内容、作者、商品价格等。 |
2. 检索与索引概念
-
Distance Metric (距离度量):用于判断两个向量“有多相似”的数学计算方法(具体用哪种由你使用的 Embedding 模型决定):
-
Cosine (余弦相似度):最常用于 NLP 和语义搜索,比较向量的夹角方向。
-
Dot (内积):常用于推荐系统。
-
Euclidean (欧几里得距离):即直线距离,常用于图像检索或空间计算。
-
Manhattan (曼哈顿距离):计算各维度绝对差值的总和。
-
-
Vector Index (向量索引 - HNSW):加速向量搜索的底层算法。Qdrant 使用 HNSW(分层可导航小世界网络)算法构建图索引,能在极短时间内找到“近似最近邻”,这是 Qdrant 高性能的核心秘密。
-
Payload Index (负载索引):加速条件过滤的传统索引。如果你常通过 Payload 的某个字段筛选(例如只搜索 price < 100 的记录),为该字段建立索引,Qdrant 在查询时会将向量索引和负载索引结合,极大提升混合检索效率。
3. 存储与分布式架构概念
-
Segment (数据段):单个节点内部的物理存储单元。一个 Collection 的数据会被分成多个 Segment,类似于 Elasticsearch 的设计,便于并行处理、后台优化(Merge)和内存管理。
-
Shard (分片):分布式存储的拆分单元。当数据量极大一台机器装不下时,Qdrant 会把 Collection 拆分为多个 Shard 分布到不同节点,实现水平扩展(Scale-out)。
-
Snapshot (快照):数据的完整备份。将节点或 Collection 的状态打包成文件,方便数据迁移、备份还原或灾难恢复。
结语
Qdrant 以其轻量级、高性能、Rust 编写的优势,在众多向量数据库中脱颖而出。希望这篇笔记能帮大家理清思路,少走弯路!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)