分享一套小巧精致的端到端知识图谱系统
引言
这篇文章介绍一个可快速部署、可演示完整链路的知识图谱系统,后续也准备在数睿通智库系统中集成一下知识图谱功能,所以在这里正好跟大家分享一下。它的目标不是“企业级大而全”,而是把核心体验做成一个容易理解、容易扩展的样板:导入文件 → 解析/抽取 → 图谱可视化 → 基于图谱与文档的问答。
适用场景:快速验证、教学演示、原型开发。
如果要线上长期稳定使用,可按业务需求升级数据库、鉴权、检索与可观测等能力。
1. 系统能力概览
系统目前包含以下能力:
- 图谱管理:多图谱创建、切换、重命名、删除;支持导入历史与按次撤销。
- 导入解析:
- 结构化:JSON / CSV 直接导入节点与关系。
- 非结构化:TXT / Markdown / PDF 文档抽取实体与关系。
- 抽取方式:优先走 LLM 抽取(OpenAI 兼容 / Ollama 等,通过后端代理调用),失败时自动降级到正则抽取。
- 图谱可视化:基于 D3 的交互画布,支持缩放、拖拽、节点悬浮提示;支持力导向/环形/网格/同心圆布局;支持双向边与多重边的分离渲染与箭头。
- RAG 问答:
- 关键词提取 + 文档内容匹配(后端在导入文件内容中做关键词命中与片段截取);
- 图谱结构辅助检索(从关键字命中的实体出发做 BFS 子图扩展);
- 把“文档片段(主)+ 子图结构(辅)”拼成上下文喂给 LLM 生成回答。
- 导出:支持导出两类 JSON:
- 数据 JSON:节点/关系/导入历史(适合备份/迁移)。
- 视图 JSON:直接导出当前渲染所需的视图态数据

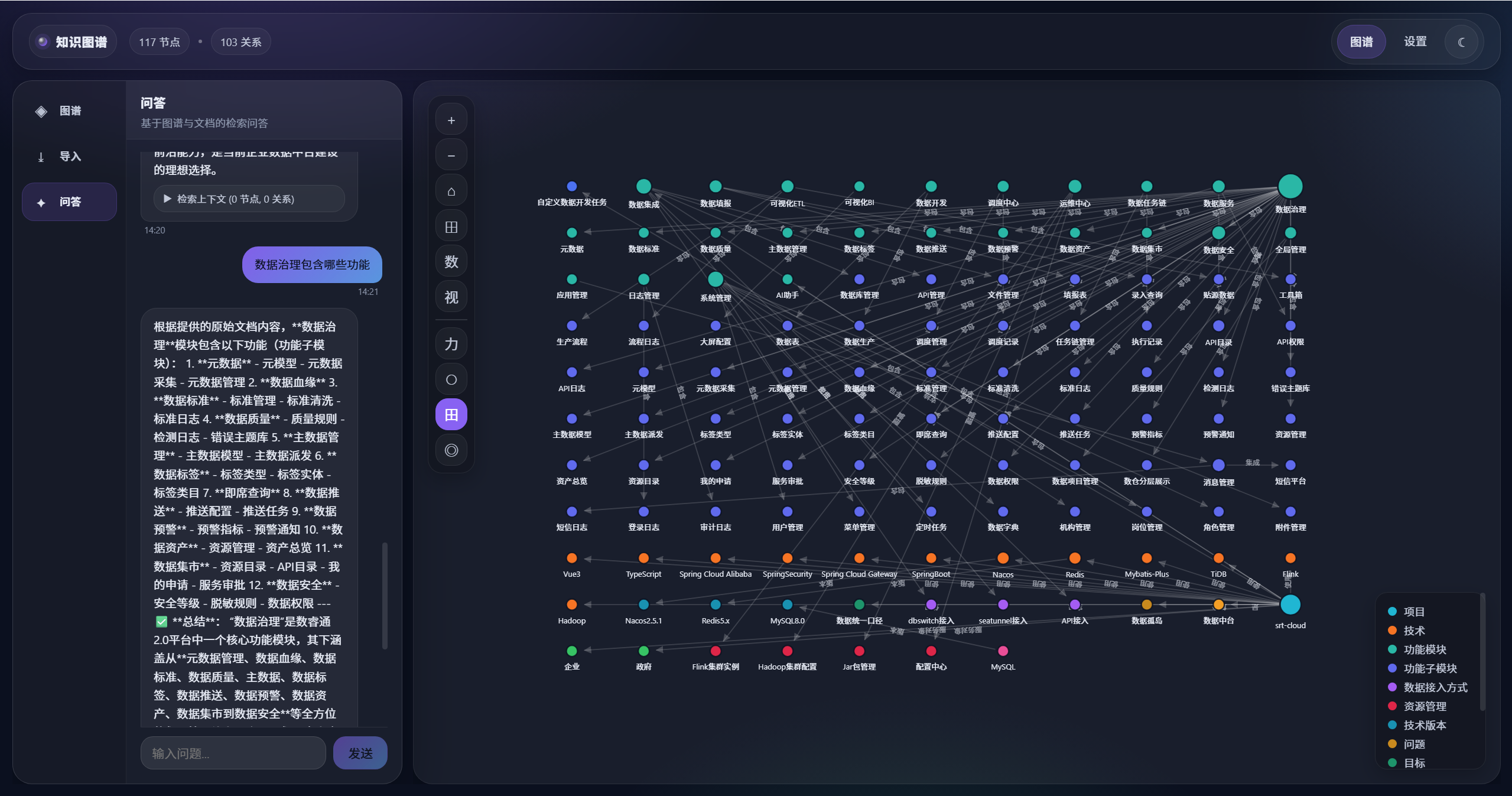
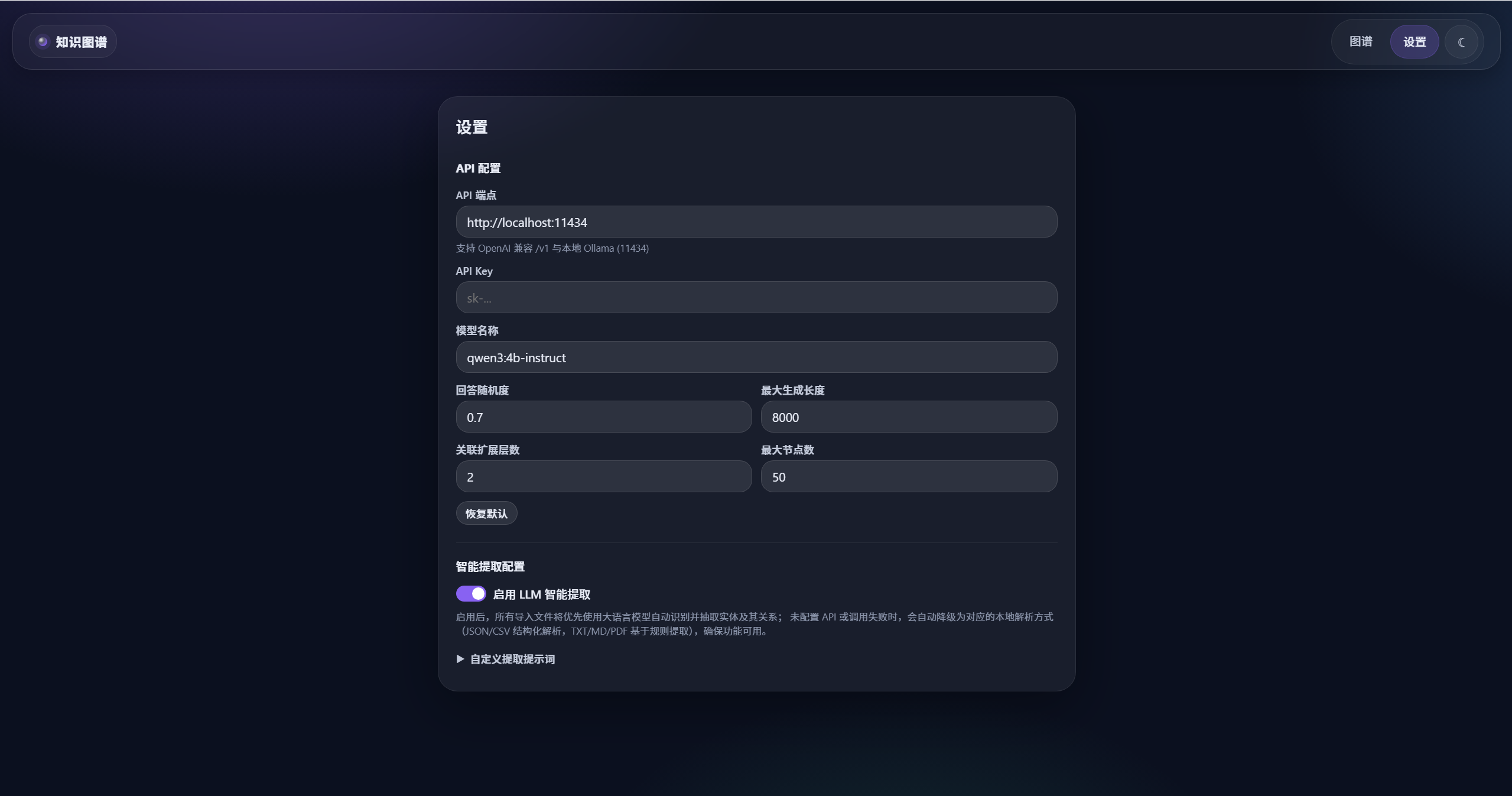
2. 架构设计:前端 + 后端 + 轻量存储
整体结构非常直观:
┌────────────┐ HTTP(/api/*) ┌──────────────┐
│ Vue3/Vite │ ───────────────────────▶ │ Express API │
│ 前端界面 │ │ SQL.js(SQLite)│
└─────┬──────┘ └──────┬───────┘
│ │
│ /api/llm/chat │ 持久化写文件
└────────────────────────────────────────▶ │ server/data/knowledge_graph.db
└───────────────
- 前端负责交互、渲染与轻量业务逻辑(解析流程编排、图谱画布、问答面板)。
- 后端提供图谱 CRUD、导入文件内容存储、消息记录、以及 LLM 代理(避免 CORS/隐藏 Key)。
- 数据库使用 SQL.js(SQLite in-memory + export 写文件)实现“轻量可用”的持久化。
这套架构的优势是“好部署、成本低、方便理解”。
若要线上使用,建议替换为更可靠的数据库(PostgreSQL/MySQL等),并增加鉴权/限流/可观测。
3. 目录结构与模块划分
项目结构(核心部分):
knowledge-graph/
├── src/
│ ├── components/
│ │ ├── graph/ # 画布、控件、图例、节点提示
│ │ ├── import/ # 导入、预览、图谱列表、导入历史
│ │ ├── layout/ # 顶栏、侧边栏
│ │ └── rag/ # 问答面板、消息、上下文查看
│ ├── composables/ # 组合式:文件解析、D3图谱、RAG查询
│ ├── services/ # API 客户端、LLM、解析器、检索器
│ ├── stores/ # Pinia:图谱、问答、设置
│ └── utils/ # 工具:分词、下载、颜色、ID等
└── server/
├── routes/ # graphs/messages/files/llm
├── db.js # SQL.js 初始化与导出到 knowledge_graph.db
└── index.js # Express 入口
4. 数据模型:节点、关系、导入批次
4.1 节点与关系的核心字段
前端图谱状态维护在 Pinia 的 graphStore 中,核心是两个 Map:
nodes: Map<nodeId, Node>edges: Map<edgeId, Edge>
其中 Edge 的 id 是由 sourceId + targetId + label 生成的,这意味着:同一个三元组重复出现会被去重并累加 weight(用于线宽)。
另外,为了解决“同名文件多次导入撤销不准确”的问题,系统引入了 importId(导入批次 ID):
- 每次导入会生成一个唯一的 importId,并写入该批次生成的 nodes/edges。
- 撤销导入时按 importId 精准删除该批次的数据。
4.2 “导入历史”的两个操作:撤销 vs 删记录
导入历史存在两个概念,容易混淆:
- 撤销:撤销本次导入 → 会删除该批次写入的节点与关系(并移除记录)。
- 删记录:只删除导入记录 → 不影响图谱数据(用于清理历史列表)。
系统已经在 UI 上分开了两个按钮,并配了二次确认弹框,避免误操作。
5. 导入链路:从文件到图谱
导入链路是这个系统最核心、也最容易扩展的部分。
5.1 文件类型与解析策略
导入组件支持拖拽/点击上传,文件类型包括:
- 结构化:
json/csv - 文档类:
txt/md/markdown/pdf
解析策略:
- 启用 LLM 智能提取且已配置 API:所有文件格式将优先调用 LLM 抽取知识三元组。
- LLM 不可用或失败:自动降级为本地解析方式:
- JSON/CSV:结构化解析
- TXT/MD/PDF:规则/正则提取
5.2 预览与确认导入
在解析完成后会进入预览状态:
- 预览卡片展示节点/关系数量与示例。
- 右侧画布展示“合并到当前图谱后的预览效果”(可取消回退)。
- 确认导入后,预览直接“提交”,避免预览与最终结果不一致。
5.3 为什么确认导入后数量可能变化
这是知识图谱系统里很常见的现象,系统也明确提示了原因:
- 关系去重:同一个
source + target + label会合并(weight++)。 - 缺失节点补齐:如果解析返回的关系引用了 nodes 列表中不存在的实体,入库时会自动补齐端点节点。
因此“解析数量”和“最终图谱数量”可能存在差异。
6. 图谱画布:交互、布局与边渲染
6.1 交互能力
画布支持:
- 缩放、平移(zoom)
- 节点拖拽(drag)
- 节点悬浮提示(tooltip)
- 相关节点高亮(用于问答命中时的可视化反馈)
6.2 多种布局
支持四种布局并可切换:
- 力导向(force)
- 环形(circular)
- 网格(grid)
- 同心圆(concentric)
非力导向布局会把节点固定在计算出的坐标上(fx/fy),并在切换时做动画过渡。
6.3 双向边/多重边的显示优化
当 A→B 与 B→A 同时存在,或者 A→B 有多条关系时,线与文字容易完全重合。
系统对此做了三点优化:
- 边从直线升级为 曲线 path,同一对节点的多条边自动分配不同曲率(避免重叠)。
- 关系标签改为
textPath沿曲线渲染(避免文字挤在中点)。 - 增加箭头 marker(明确方向)。
7. RAG 问答:关键词检索 + 子图扩展 + LLM 生成
需要特别说明:系统的 RAG 设计是“快速跑通链路”的轻量方案,不是向量检索。
7.1 关键词如何提取
系统对问题做简单分词与去停用词:
- 中文:提取连续中文片段,做 2 字 bigram 切分(或短词保留)。
- 英文:提取单词,过滤停用词。
最终得到关键词列表,用于检索。
7.2 文档检索怎么做(主参考)
导入时会把原始文件内容存到后端(files 表)。
问答时后端对该图谱下的所有文件内容做 indexOf 关键词匹配,并截取上下文片段(snippets)打分返回。高分文件会返回更多内容。
7.3 图谱检索怎么做(辅参考)
根据关键词在图谱里找“种子实体”,再以 BFS 方式扩展一个子图:
- BFS 深度、最大节点数可以在设置里配置。
- 子图的实体与关系会被格式化为结构化文本,作为回答时的辅助参考。
7.4 LLM 调用与 CORS 处理
前端不直接请求三方模型服务,而是通过后端 /api/llm/chat 代理:
- 统一兼容 OpenAI 风格接口
- 支持 Ollama(本地模型)等
这样可以规避浏览器跨域问题,并避免在前端暴露敏感信息。
8. 使用方法:从 0 到可演示
8.1 开发启动
npm install
npm run dev:all
打开:http://localhost:5173
8.2 导入与预览
- 进入左侧“导入”页,拖拽 TXT/MD/PDF 或导入 JSON/CSV。
- 解析完成后可点击“预览”在右侧画布观察合并效果。
- 点击“确认导入”写入图谱并落库。
8.3 问答
- 设置页配置 LLM API 端点与 Key(也可用本地 Ollama)。
- 在“问答”页输入问题,系统会:
- 先检索导入文档片段
- 再拼接子图结构
- 调用模型生成回答,并高亮相关节点
8.4 导出
画布左侧控制栏:
- “数”:导出数据 JSON(备份/迁移)
- “视”:导出视图 JSON(含布局与坐标)
9. 线上部署与扩展建议
9.1 线上部署
- 前端:
npm run build产物用 Nginx 托管静态资源 - 后端:
node server/index.js由 PM2/Systemd/Docker 守护 - Nginx 同域反代
/api/到后端
9.2 生产化建议
- 数据库替换:SQL.js 适合轻量演示;线上建议 PostgreSQL/MySQL并加索引。
- 鉴权与权限:图谱与文件属于资产,建议加登录、租户隔离、权限控制。
- LLM 安全:目前 LLM 端点由前端配置传入,公网场景建议改为服务端固定配置或白名单。
- 检索升级:当前是关键词匹配;可升级为向量检索(embedding + 向量库)+ rerank,并增加可观测日志。
10. 总结
系统的价值在于:把知识图谱系统里最关键的“端到端链路”用快速搭建起来,并保留足够清晰的模块边界,方便你按业务需求继续演进。
感兴趣的朋友可以关注公众号螺旋编程极客加入我的极客AI知识星球,我们一起成长、一起进步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)