当飞书上发一条消息给OpenClaw,它内部经历了什么?
当飞书上发一条消息给OpenClaw,它内部经历了什么?
1. 第一课:OpenClaw的核心定位与架构设计
李老师:(推了推眼镜)小明,最近GitHub上那只"小龙虾"你应该关注到了吧?22万Star,创始人都被OpenAI挖走了。今天咱们好好聊聊OpenClaw的技术架构。
小明:关注了,但我一直有个疑问——它和普通的LLM应用有什么本质区别?不都是调API吗?
李老师:问到点子上了。OpenClaw的核心定位是"The AI that actually does things"——真正能干活的AI。它不是让LLM生成文字给你看,而是让LLM直接操作你的电脑完成任务。用户通过飞书、Telegram这些IM工具下达指令,OpenClaw自己去执行Shell命令、操作浏览器、发邮件,然后汇报结果。
小明:所以它本质上是一个Agent框架?那它的架构是怎么设计的?
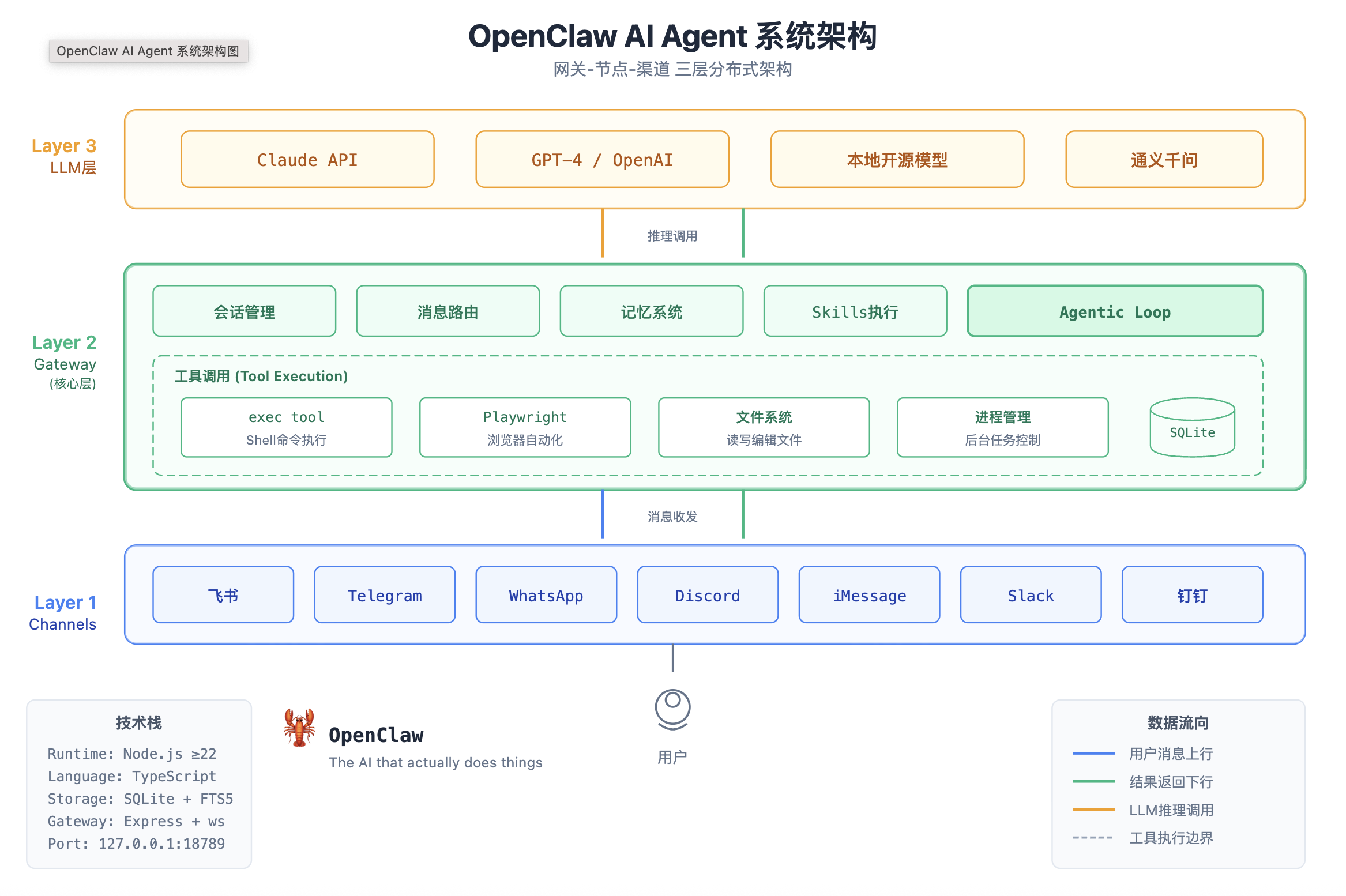
李老师:OpenClaw采用"Gateway-Nodes-Channels"三层架构,核心是单进程Hub-and-spoke模式。
| 架构层级 | 核心组件 | 功能定位 |
|---|---|---|
| Layer 3:LLM层 | Claude/GPT/本地模型 | 智能推理核心 |
| Layer 2:Gateway层 | 会话管理、消息路由、记忆系统 | 神经中枢,默认绑定127.0.0.1:18789 |
| Layer 1:Channels层 | 飞书/Telegram/Discord等 | 用户交互入口 |
小明:等等,单进程?这个设计会不会有性能瓶颈?
李老师:(笑了笑)好问题。这是刻意的设计权衡——在个人自托管场景下,部署简单性远比水平扩展能力重要。一个端口、一个配置文件、一个systemd服务就能跑起来。对于个人助手来说,并发请求量本来就不大,单进程完全够用。
小明:哦,原来是这样设计的。场景决定架构,不追求过度设计。
2. 第二课:当飞书上发一条消息给OpenClaw,它内部经历了什么?
李老师:现在咱们深入看看,当你在飞书上发一条消息给OpenClaw,它内部经历了什么?一共六个环节。
小明:让我理一下…应该是先接收消息,然后调LLM,最后返回结果?
李老师:大方向对,但细节更复杂。我逐个讲——
环节一:渠道适配器。不同IM工具的消息格式不一样,适配器负责标准化。关键设计是细粒度的适配器组合模式——一个channel由十几个可选适配器组成:config、security、outbound、gateway、groups、threading等,按需组合。
小明:这样设计的好处是…接入新平台只需要写适配器,不用动核心逻辑?
李老师:正解。环节二:网关服务是任务协调中心。核心设计是基于通道的命令队列——每个会话有专属执行通道保证操作有序,默认序列化执行,需显式声明才能并行。
小明:为什么默认序列化?
李老师:安全考虑。想象一下,你让AI同时执行"删除文件"和"备份文件",如果并行执行,顺序不确定,可能先删后备份,数据就没了。
小明:明白了,继续。
李老师:环节三:智能体运行器承载AI核心能力——自动匹配大模型、管理API密钥(失效自动冷却换下一个)、主模型失败自动降级、动态拼接系统提示词。环节四:大模型API调用做了抽象封装,对不同Provider统一调用接口,支持流式返回。
小明:前四个环节我理解了。那环节五呢?我猜这是实现Agent能力的关键?
李老师:没错,环节五:Agentic Loop是灵魂所在。流程是这样的——
LLM返回工具调用指令 → OpenClaw本地执行 → 结果添加至会话 → 再次调用LLM
↑ ↓
←←←←←←←← 循环直到LLM返回最终文本 ←←←←←
默认最大循环约20次。你让它"分析CSV并生成PDF报告",它可能要执行十几轮:读文件、跑Python、生成图表、导出PDF…每一步都是一次循环。
小明:所以Agent的"自主性"本质上是这个循环机制!环节六应该就是把最终结果返回给用户?
李老师:对,环节六:回复通路反馈结果,并将会话数据持久化到.jsonl文件,为后续记忆检索提供数据基础。
3. 第三课:记忆管理与工具调用机制
李老师:接下来聊两个核心机制——记忆管理和工具调用。你觉得一个长期运行的Agent,记忆系统该怎么设计?
小明:让我想想…短期记忆用于当前对话上下文,长期记忆存储重要信息供跨会话检索?
李老师:思路正确。OpenClaw的记忆系统分两层:
| 记忆类型 | 存储格式 | 功能描述 | 技术实现 |
|---|---|---|---|
| 会话记忆 | JSONL | 每次对话的全量信息 | 文件持久化 |
| 长期记忆 | Markdown | MEMORY.md或memory/文件夹 | 向量+关键词混合检索 |
小明:Markdown存长期记忆?这个设计挺有意思。
李老师:好处是人类可读、可编辑。检索方案用向量+关键词混合模式——向量检索基于SQLite的sqlite-vec扩展实现,关键词检索用FTS5。不需要额外部署向量数据库,SQLite直接内置一把梭。
小明:记忆同步怎么做?Agent写了新记忆,系统怎么知道要更新索引?
李老师:文件监视器自动触发。Agent通过标准文件写入工具生成记忆文件,无需专属API,系统监测到文件变化就自动重建索引。
小明:那工具调用呢?我看文档说OpenClaw能执行Shell命令、操控浏览器?
李老师:核心是三类内置工具——
exec tool:执行Shell命令,可在沙箱(Docker)、本地主机或远程设备运行。
浏览器工具:基于Playwright开发,亮点是"语义快照"技术——不是截图让LLM看,而是基于页面可访问性树生成文本化表征,LLM理解效率高得多。
进程管理工具:支持后台长期运行命令、终止进程等系统级操作。
小明:语义快照这个设计很聪明,避免了多模态理解的复杂性。
4. 收尾:延伸思考题
李老师:最后两个延伸问题。第一,OpenClaw的Skills插件系统是怎么设计的?
小明:(思考片刻)我看到ClawHub上有5000多个技能…每个Skill应该是一个标准化的描述文件?
李老师:对,每个Skill是一个包含YAML frontmatter的SKILL.md目录。加载优先级是:工作区Skills(最高)→ 本地托管Skills(~/.openclaw/skills)→ 内置Skills(最低)。高优先级可以覆盖低优先级,方便用户自定义。
小明:第二个问题呢?
李老师:安全机制。一个能执行Shell命令的Agent,安全设计必须过硬。OpenClaw的思路是"白名单管控+危险命令拦截"——
- 用户可对命令进行单次允许、永久允许、拒绝的授权
- 基础安全命令(jq、grep等)已预授权
- 系统默认拦截危险Shell语法:命令替换、重定向、链式操作、子shell
小明:所以不是完全信任LLM的输出,而是在执行层做了兜底。
李老师:(点头)这堂课就到这里。OpenClaw的设计哲学很清晰——在个人自托管场景下,追求部署简洁、功能实用、安全可控,而不是盲目追求技术复杂度。
5. 总结
OpenClaw采用Gateway-Nodes-Channels三层架构,通过六环节工作流程实现"指令接收→LLM推理→本地执行→结果反馈"的完整Agent能力,其中Agentic Loop是实现复杂任务自主执行的核心机制。
记忆系统基于SQLite+sqlite-vec实现向量与关键词混合检索
工具调用通过exec tool和Playwright语义快照技术赋予Agent真正的"行动力"
安全设计遵循白名单管控原则,在执行层为LLM输出兜底。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)