【SpringAI】RAG检索流程
检索增强生成(RAG)技术通过结合信息检索与文本生成,有效解决大语言模型的知识陈旧、幻觉等问题。其工作流程分为离线索引和在线检索生成两个阶段:离线阶段将文档切分并转换为向量存储;在线阶段检索相关文档片段,构建增强提示词供模型生成回答。RAG具有降低幻觉、知识可更新、支持专业领域等优势,使AI回答更准确可靠。该技术通过检索外部知识库为模型提供事实依据,显著提升生成质量。
目录
在大语言模型(LLM)快速发展的今天,我们享受着其强大的生成能力,但也面临着知识陈旧、幻觉频发、领域知识不足等挑战。检索增强生成(Retrieval-Augmented Generation, RAG) 正是解决这些问题的关键技术。它通过在生成回答前检索外部知识库,将最相关的信息注入到提示词中,让大模型 “言之有物”,从而大幅提升回答的准确性、可信度和专业性。
本文将结合 RAG 的核心工作流程,从理论到实践,带你全面掌握这项技术。
一、什么是 RAG?
RAG 是一种结合了信息检索与文本生成的混合技术框架。它的核心思想是:
- 检索:当用户提出问题时,系统首先从外部知识库(如文档、数据库、网页)中检索出与问题最相关的信息片段。
- 增强:将这些检索到的信息作为 “上下文”,与用户的原始问题一起,构建成一个增强版的提示词。
- 生成:将这个增强后的提示词输入给大语言模型,使其基于检索到的事实信息生成最终回答。
与纯大模型生成相比,RAG 具有以下显著优势:
- 降低幻觉:回答基于检索到的真实文档,而非模型的 “脑补”。
- 知识更新:无需重新训练模型,只需更新外部知识库即可获得最新知识。
- 领域适配:轻松接入企业内部文档或专业领域知识,快速构建行业应用。
- 可追溯性:回答的依据可以追溯到具体的文档片段,便于审核和验证。
二、检索流程
典型的检索流程如下,这是SpringAI alibaba官方给出的流程图

接下来我们来详细了解一下每一步的过程
二、RAG 核心工作流程详解
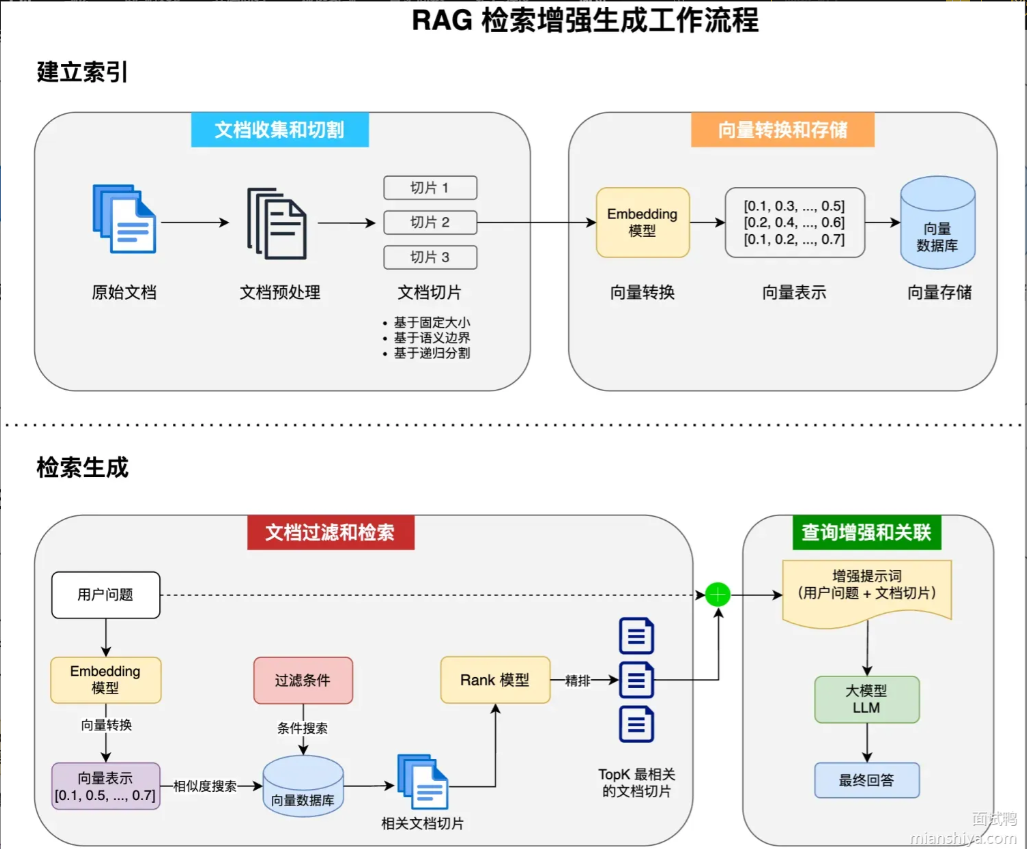
一个完整的 RAG 系统主要分为两大阶段:建立索引(离线阶段) 和 检索生成(在线阶段)。下面我们结合流程图逐一拆解。
(面试鸭流程图)
阶段一:建立索引(离线预处理)
这一阶段的目标是将海量的非结构化文档,转化为可被高效检索的向量数据,并存入向量数据库。
1.文档收集和切割
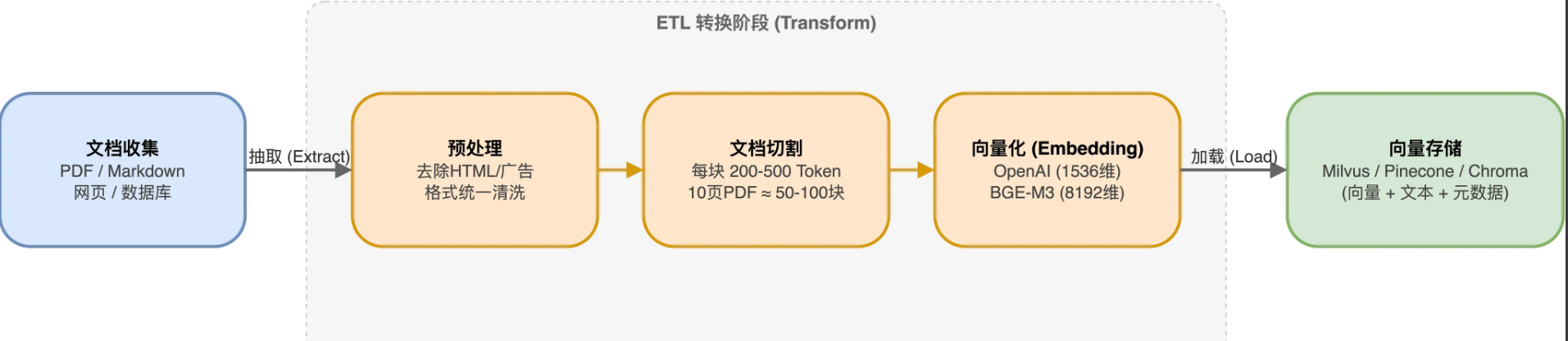
①原始文档:收集企业内部的 PDF、Word、网页等非结构化数据。
②文档预处理:对文档进行清洗,去除无关的页眉页脚、水印、乱码等。
③文档切片:将长文档切分成更小的 “文档切片”(Chunk)。这是关键一步,常见的策略有:
基于固定大小:按字符数或 Token 数简单分割,实现简单但可能破坏语义。
基于语义边界:利用 NLP 技术识别段落、章节等语义边界进行分割,保持信息完整性。
基于递归分割:先按大的分隔符(如\n\n)分割,再对过大的块用小分隔符(如\n)再次分割。
2.向量转换和存储
①向量转换:使用 Embedding 模型(如 OpenAI 的 text-embedding-ada-002、BGE 等),将每个文档切片编码成一个高维的稠密向量。这个向量代表了该切片的语义信息。
②向量存储:将生成的向量与对应的文档切片元数据(如来源、标题)一起,存入专门的向量数据库(如 Milvus、FAISS、Pinecone、Redis),以便后续进行高效的相似性搜索。
阶段二:检索生成(在线推理)
当用户发起查询时,系统进入在线阶段,实时完成检索和生成。
1.文档过滤和检索
- 用户问题:接收用户输入的查询。
- 向量转换:使用与建立索引时相同的 Embedding 模型,将用户问题也转换成一个向量。
- 相似度搜索:在向量数据库中,执行 “最近邻搜索”(KNN),找出与用户问题向量最相似的 Top-K 个文档切片向量。
- 条件搜索(可选):根据元数据(如文档日期、作者)对检索结果进行过滤,缩小范围。
- 精排(Rerank):使用更强大的重排模型(如 Cohere Rerank、BGE Reranker)对初步检索出的 Top-K 结果进行再次排序,进一步提升相关性。
2.查询增强和关联
- 增强提示词:将精排后的 Top-K 文档切片内容,与用户的原始问题,按照预设的模板拼接成一个新的提示词(Prompt)。例如:
"根据以下信息回答问题:\n{文档切片}\n\n问题:{用户问题}"。- 大模型生成:将增强后的提示词输入给大语言模型(LLM)。模型在生成回答时,会严格参考提供的文档信息,避免编造。
- 最终回答:模型输出的结果即为最终答案,它是基于检索到的事实生成的,更加可靠。
感兴趣的宝子可以关注一波,后续会更新更多有用的知识!!!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)