AI流程管理:从 BPM 到“可治理的智能流程”
本文将从实践角度,分析讲解 AI流程管理到底是什么、系统怎么拆、事件数据怎么建、指标怎么算、护栏怎么做,同时给出一套稳妥的 90 天落地实施路线,助力团队实现 AI 流程管理的落地应用。
本文将面向架构师、流程平台研发、数据工程师、流程 & IT 负责人、CIO等进行诠释解读。
在过往项目辅导、项目实施经历中,我们发现很多团队在做 AI 赋能流程时,容易走入两个极端:
- 一是只做了一个会聊天的助手,能撰写 SOP、绘制流程图,但流程运行效率依旧低下、返工问题频繁出现;
- 二是直接将 AI 接入关键审批或执行环节,导致流程不可控、不可审计、不可回滚,上线即伴随高风险。
因此,本文也将从工程实践视角,分析讲解 AI流程管理到底是什么、系统怎么拆、事件数据怎么建、指标怎么算、护栏怎么做,同时给出一套稳妥的 90 天落地实施路线,助力团队实现 AI 流程管理的落地应用。
什么是AI流程管理?
AI 流程管理 = 流程资产(标准)+ 运行编排(执行)+ 过程智能(洞察)+ 治理审计(可控)+ AI 能力(提效 / 推荐 / 生成 / 预警)。
工程落地核心原则:先夯实数据与治理基础(搭建事件日志 + 部署审计护栏),再逐步将 AI 能力接入流程体系。
AI 流程管理并非 BPM和ChatBot 的简单组合,传统 BPM(业务流程管理)的核心价值是解决 “流程能跑通” 的基础问题,而 AI 流程管理的核心目标是实现 “流程能被精细化运营”,其关键是具备四大特性:
- 可度量:通过事件数据,量化流程全生命周期的周期时长、等待时间、返工次数、流程变体、执行偏差等关键维度;
- 可优化:将过程智能挖掘的洞察转化为实际动作,包括规则配置、流程自动化、智能路由、资源合理调度等;
- 可治理:明确流程权限边界,实现全链路审计追踪,支持流程复核与回滚;
- 可持续:完善流程版本治理,搭建可视化指标面板,形成流程持续改进闭环。
AI 流程管理典型架构之“五层工程化模型”
该模型落地拆分适配性强,五层架构层级与核心能力具体如下:
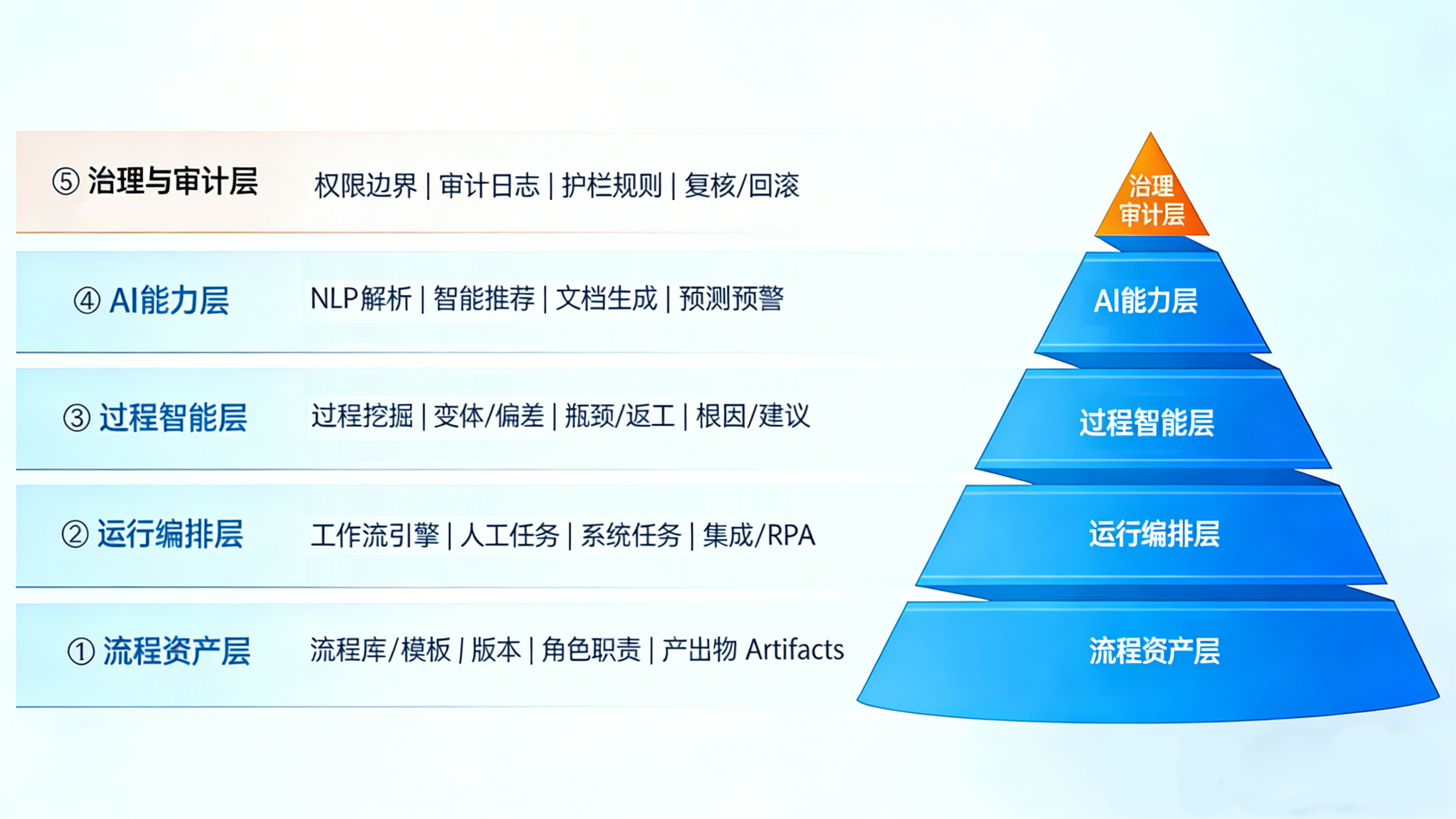
架构落地关键建议:
- 无流程资产层① + 运行编排层②,则流程跑不稳;
- 无过程智能层③,则流程优化只能猜,缺乏数据支撑;
- 无治理与审计层⑤,则AI 难以安全接入财务、采购、合规等关键流程。
数据基础搭建:事件日志(Event Log)怎么设计才不坑
AI 流程管理的洞察挖掘、过程分析、趋势预测均依赖高质量的事件数据,因此需先统一事件契约(Data Contract),才能提升后续工程实施效率。
3.1 最小可用事件模型(MV Event Log)
至少需包含以下核心字段,保障基础分析能力,字段设计如下表:
| 字段 | 含义 | 示例 |
| case_id | 流程实例ID(单据/订单/工单) | PO_202602_000123 |
| process_key | 流程定义Key | P2P_Procurement |
| activity | 节点名 | ManagerApprove |
| lifecycle | start/complete | start |
| event_time | 事件时间(UTC) | 2026-02-25T10:11:12Z |
| actor_id | 执行人/系统 | u_1024 / sys_erp |
| org_unit | 组织/部门 | Finance_SSC |
| channel | 来源系统 | ERP / ITSM |
| outcome | 结果 | approved/rejected |
| attributes | 扩展字段 | JSON |
关键设计要求:同一流程节点必须同时记录 start 和 complete 状态,否则无法准确计算节点等待时间与实际处理时间。
3.2 事件采集:别用“业务表快照”冒充流程日志
最常见错误做法:拿业务表状态字段(如 status=APPROVED)当作流程事件。
这会丢掉:
- 排队等待时间
- 多次返工 / 重复审批记录
- 流程实际执行路径与变体
- 节点开始/完成的时间边界
推荐采集点位:
1.工作流引擎状态机:采集任务创建、领取、完成、撤回、转派等事件;
2.系统集成层:采集 API 调用开始、结束、失败重试等事件;
3.业务关键系统:从 ERP、ITSM 等系统中采集可稳定获取的动作事件(需做标准化处理)。
从事件到洞察:数据管道参考架构(Kafka/Flink/ClickHouse)
4.1 典型数据链路架构
Plain textWorkflow/Apps → Event Producer → Kafka → Stream ETL(Flink) → OLAP(ClickHouse)
└→ Data Lake(optional)
4.2 事件契约(Data Contract)统一规范
- 统一命名:process_key 、 activity 、 lifecycle等核心字段命名全链路一致;
- 统一时间:所有事件时间采用 UTC 时区,精确至毫秒
- 统一枚举:outcome 、 lifecycle 、 channel等枚举类型的取值与释义全链路统一;
- 扩展字段版本化:attributesJSON 字段需增加版本标识 attr_schema_version,便于后续字段迭代管理。
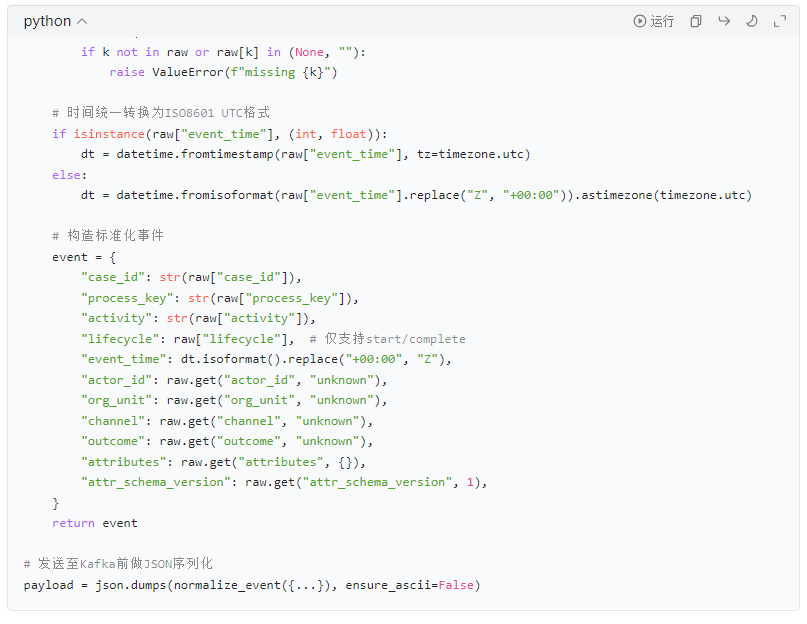
4.3 Python:事件标准化示例(入Kafka前预处理)
指标体系怎么做:一套可复用的 KPI/SQL 模板(ClickHouse示例)
实战核心建议:先搭建可运营的可视化指标面板,再落地 AI 能力;若无明确的指标体系,AI 的价值与 ROI 无法有效验证。以下为 5 类核心流程指标的计算 SQL,以采购流程 P2P_Procurement 为例:
5.1 流程周期(Cycle Time):单实例从开始到结束的总时长

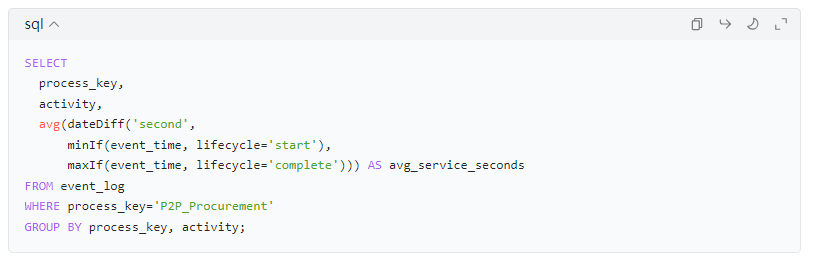
5.2 节点处理时长(Service Time):节点从 start 到 complete 的耗时
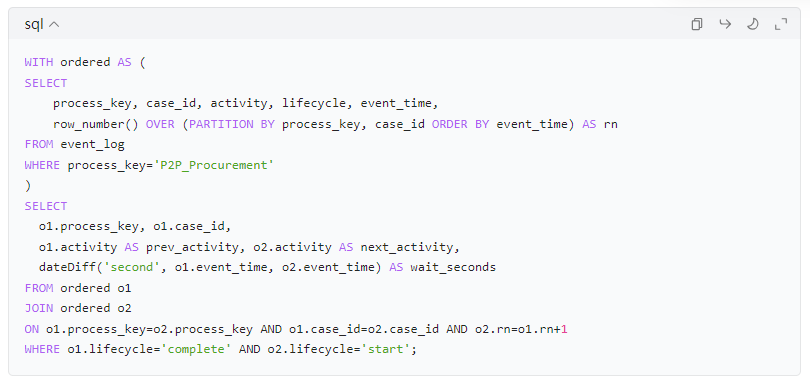
5.3 节点等待时间(Waiting Time):上个节点 complete 到下个节点 start 的耗时(粗略版)
5.4 流程返工率(Rework):同一activity在同一case出现多次
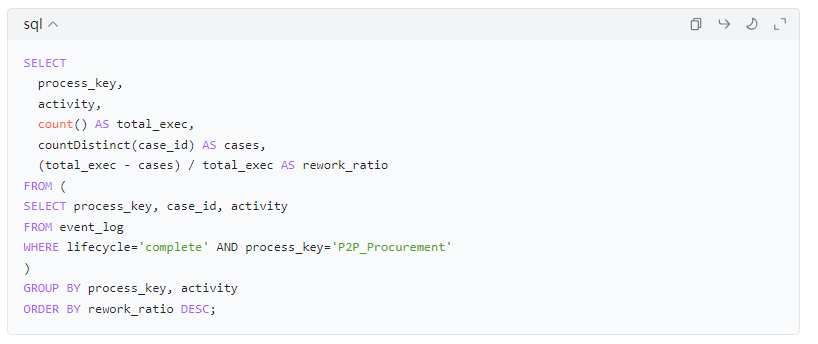
5.5 流程变体(Variant)占比:按活动序列聚合
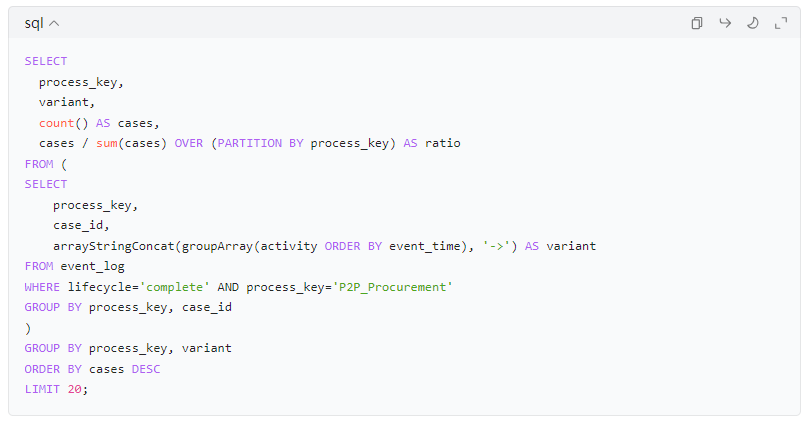
有了这 5 类指标,流程运营基本“能跑起来”。后续AI才有明确抓手:哪类case需要分流、哪个节点需要知识推荐、哪个变体需要治理收敛。
AI 接入流程的正确方式:Guardrails+人类在环+全链路可追溯
工程落地的核心原则:将 AI 作为流程中的 “可控组件”,而非替代人工的 “万能大脑”,通过标准化方案实现 AI 的安全、合规接入。
6.1 AI 接入点优先级(从安全到高风险排序)
1.文档生成:流程变更说明、审计摘要、流程复盘报告等自动化生成;
2.知识推荐:工单处理、异常问题解决的建议推荐(需人工确认后执行);
3.字段补全:票据自动分类、流程摘要生成、风险标签标注(需人工确认后生效);
4.路由建议:流程任务分派、处理优先级推荐(需人工确认后执行);
5.自动决策:仅在强规则约束 + 可回滚的低风险动作中,逐步下放 AI 决策权限。
6.2 AI 审计日志:实现 AI 调用全链路留痕
建议单独创建 ai_audit_log 表,记录 AI 接入流程的所有关键信息,字段设计如下:
| 字段 | 含义 |
| trace_id | 单次 AI 调用的唯一关联标识 |
| case_id / activity | 关联的流程实例 ID 与节点名 |
| model / version | 调用的 AI 模型与版本号 |
| prompt_hash | 提示词哈希(可脱敏存储) |
| input_ref | 输入引用(对象ID/字段) |
| output | AI输出结果(可截断+脱敏) |
| confidence | 置信度(如有) |
| decision | 人工对 AI 输出的处理结果(采纳/修改/拒绝) |
| reviewer | 复核人 |
| timestamp | AI 调用时间 |
6.3 护栏规则(Guardrails)核心三件套
1.硬规则优先:所有可通过规则实现的流程动作,不交给 AI 处理;
2.高风险动作复核:付款、授信、权限开通等高风险操作,必须经过人工复核;
3.可回滚 / 补偿:AI 执行的自动化动作,必须具备撤销机制或事后补偿方案。
平台能力映射示例:五层架构落地产品模块
AI 流程管理的五层架构可落地至不同的产品模块,各平台因定位不同,模块组合方式存在差异(部分平台偏流程建模运行,部分偏过程智能分析,部分偏自动化执行)。
以国内流程平台 AlphaFlow(微宏科技)为例,做五层架构与产品模块的映射参考(仅为实现示例,不涉及平台选型推荐):
- 流程资产层:BPA(流程规划/资产/模板/版本/产出物)
- 运行编排层:BPMA + BPE(流程自动化运行 + 流程引擎)
- 过程智能层:BPI(流程挖掘、变体/偏差、瓶颈/返工分析)
- 治理审计层:权限、审计追踪、规则护栏(结合版本策略)
- AI能力层:制度解析、字段补全、异常解释、复盘摘要等(建议与护栏一起上线)
但各位在实际选型时,还是要结合企业自身的系统边界、数据口径、合规要求与后期维护成本综合判断。
90天落地路线:跑通“洞察—治理—行动”闭环(最稳)
第1–2周:定范围、定指标、定数据
- 选定一个端到端核心流程作为试点(如报销、P2P 采购、O2C 销售、ITSM 工单)
- 确定试点流程的核心 KPI:周期时长、等待时间、返工率、超时率、人工处理时长;
- 梳理试点流程的事件数据现状,明确缺失字段,补充数据采集点位。
第3–6周:挖掘流程洞察,定位核心问题
- 通过过程智能分析,输出流程变体 Top20、运行瓶颈 Top10、节点返工 Top10
- 基于分析结果,输出流程问题清单、问题影响评估、优化优先级排序。
第7–10周:落地优化行动,接入基础 AI 能力(规则+自动化+AI助手)
- 规则化优化:配置流程阈值、审批链规则、数据校验项等;
- 自动化落地:实现系统集成调用、流程字段自动填充、任务自动创建等;
- AI 助手上线:落地流程解释、内容总结、知识推荐等 AI 能力(全程保证可审计、可复核)。
第11–12周:复盘优化效果,复制推广至其他流程
- 对比流程优化上线前后的核心指标,评估周期、返工、超时等问题的改善效果;
- 将试点流程的落地经验,复制推广至企业内相邻的同类型流程。
工程落地常见坑:提前规避,减少返工
- 无统一事件契约:不同系统对同一流程节点的命名不一致,导致后续分析全部混乱;
- 节点日志缺失:仅记录 complete 状态,未记录 start 状态,无法计算等待时间与处理时间;
- 错误的事件采集方式:将业务表快照当作流程事件,无法还原流程返工与变体;
- AI 盲接关键动作:未配置护栏、审计、回滚机制,上线即引发运营风险;
- 无流程版本治理:流程发生变更后,指标统计口径与 AI 建议全部漂移,失去参考价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)