ms-swift框架实现自我认知微调Qwen2.5-7B-Instruct
环境准备
此文章编写于2026年2月26日,采用modelscope提供的免费算力进行实操,显卡:A10
打开modelscope官网:
ModelScope官网
注册登录后,在左侧找到我的Notebook,会发现提供两个算力:CPU算力和GPU算力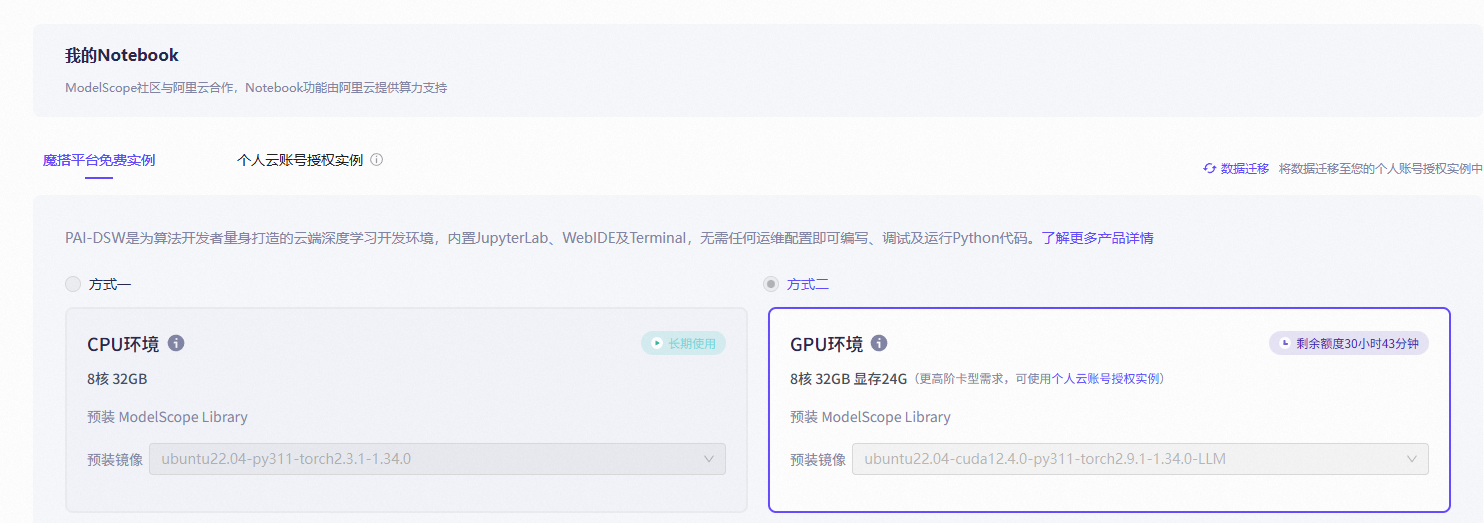
然后选择GPU环境,选择预装镜像版本:ubuntu22.04-cuda12.4.0-py311-torch2.9.1-1.34.0-LLM
该版本基于ubunntu22.04+cuda12.4+python3.11+torch2.9.1版本,能完美运行Qwen2.5-7B-Instruct 大模型。
或者你也可以选择Autodl,官网:
Autodl
手动选择镜像,然后安装ms-swift框架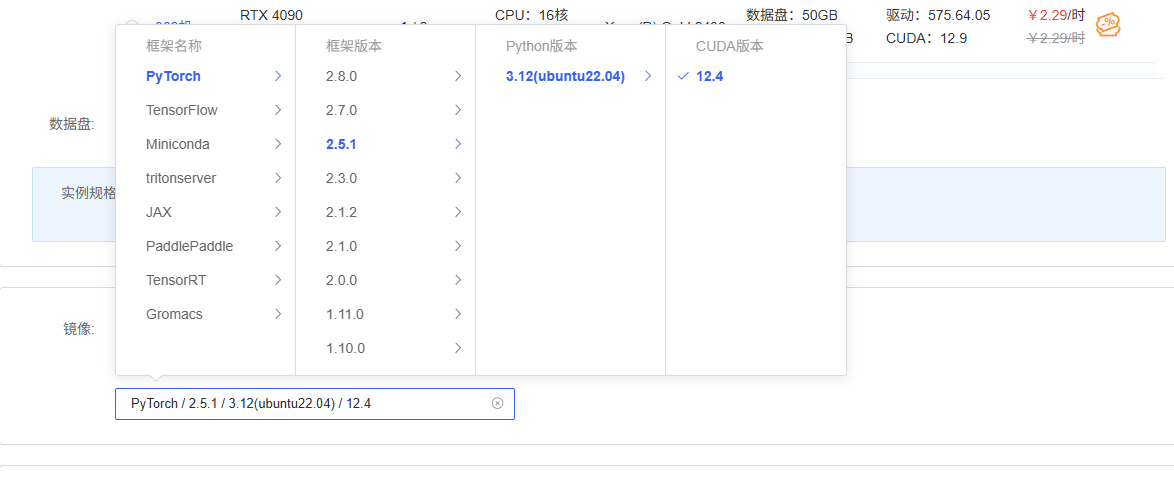
当实例启动后,可以通过终端检查ms-swift版本,输入以下命令:
pip show ms-swift
能看到以下输出就代表ms-swift安装成功:
root@dsw-1676880-84cd6df455-vrfql:/mnt/workspace# pip show ms-swift
Name: ms-swift
Version: 3.11.3
Summary: Swift: Scalable lightWeight Infrastructure for Fine-Tuning
Home-page: https://github.com/modelscope/swift
Author: DAMO ModelScope teams
Author-email: contact@modelscope.cn
License: Apache License 2.0
Location: /usr/local/lib/python3.11/site-packages
Requires: accelerate, addict, aiohttp, attrdict, binpacking, charset-normalizer, cpm-kernels, dacite, datasets, einops, fastapi, gradio, importlib-metadata, jieba, json-repair, matplotlib, modelscope, nltk, numpy, omegaconf, openai, oss2, pandas, peft, pillow, PyYAML, requests, rouge, safetensors, scipy, sentencepiece, simplejson, sortedcontainers, tensorboard, tiktoken, tqdm, transformers, transformers-stream-generator, trl, uvicorn, zstandard
Required-by:
框架介绍
ms-swift框架对比transformer和pytorch等框架,省去了环境部署等麻烦,并且也支持全参微调,Lora,QLora等部分参数微调。
ms-swift是魔搭社区提供的大模型与多模态大模型微调部署框架,现已支持600+纯文本大模型与300+多模态大模型的训练(预训练、微调、人类对齐)、推理、评测、量化与部署。其中大模型包括:Qwen3、Qwen3-Next、InternLM3、GLM4.5、Mistral、DeepSeek-R1、Llama4等模型,多模态大模型包括:Qwen3-VL、Qwen3-Omni、Llava、InternVL3.5、MiniCPM-V-4、Ovis2.5、GLM4.5-V、DeepSeek-VL2等模型。
除此之外,ms-swift汇集了最新的训练技术,包括集成Megatron并行技术,包括TP、PP、CP、EP等为训练提供加速,以及众多GRPO算法族强化学习的算法,包括:GRPO、DAPO、GSPO、SAPO、CISPO、RLOO、Reinforce++等提升模型智能。ms-swift支持广泛的训练任务,包括DPO、KTO、RM、CPO、SimPO、ORPO等偏好学习算法,以及Embedding、Reranker、序列分类任务。ms-swift提供了大模型训练全链路的支持,包括使用vLLM、SGLang和LMDeploy对推理、评测、部署模块提供加速,以及使用GPTQ、AWQ、BNB、FP8技术对大模型进行量化。
此外,如果你更偏向于llama-factory框架也是一样的步骤,框架只是省去了部分环境准备的操作,实际上手还是自己敲命令。
模型与数据集下载
在终端中,通过modelscope下载模型到机器中,命令如下:
modelscope download --model Qwen/Qwen2.5-7B-Instruct
默认下载的路径在当前机器的隐藏目录 .cache下,如果是modelscope启动的实例,则全路径在:/mnt/workspace/.cache/modelscope/models,其他实例类似,貌似新版本都在.cache 下,你也可以通过参数 --local_dir 路径 来指定存储位置
数据集采用swift提供的自我认知数据集与GPT4生成的通用混合中英数据集
自我认知数据集self-cognition ,专注于自我认知领域,为模型提供针对性学习样本,帮助其精准理解相关问题。
通用混合数据集由英文的/alpaca-gpt4-data-en和中文的alpaca-gpt4-data-zh组成,由GPT-4生成。
它涵盖多领域知识、多样语言表达与指令场景,既有助于模型指令精调,提升回复质量,又能强化模型在复杂场景下的决策与生成能力。
通过脚本下载:
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('swift/self-cognition', subset_name='default', split='train')
默认存储位置同样在上述的 .cache/modelscope下的dataset目录中存储
模型微调
ms-swift提供两种方式来进行微调:web ui界面和 命令式 来实现微调训练,通过在终端命令 swift web-ui --lang zh 可以开起web界面调试,web界面也只是封装了这些命令参数。
命令微调如下:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-7B-Instruct \
--tuner_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
各参数详情如下(有点多,选择性的看):
| 参数项 | 原始命令数值 | 详细功能描述 |
|---|---|---|
| GPU设备 | CUDA_VISIBLE_DEVICES=0 |
指定当前训练任务使用的 GPU 编号。 |
| 基础模型 | --model Qwen/Qwen2.5-7B-Instruct |
指定底座模型。此处选用 Qwen2.5 70 亿参数的指令微调版。 |
| 微调类型 | --tuner_type lora |
指定使用 LoRA (Low-Rank Adaptation) 算法,仅更新少量参数以降低显存压力。 |
| 数据集 | --dataset '...#500' |
混合加载中、英指令集及自我认知数据。#500 表示对每个数据集随机采样 500 条进行微调。 |
| 计算精度 | --torch_dtype bfloat16 |
采用 bf16 精度训练。在支持的显卡上比 fp16 更稳定,能有效防止梯度溢出。 |
| 训练轮数 | --num_train_epochs 1 |
数据集完整训练的次数。对于特定任务微调,通常 1 个 Epoch 即可初见成效。 |
| 单卡批次 | --per_device_train_batch_size 1 |
每张显卡单次迭代处理的样本数。设为 1 可最大限度压低峰值显存占用。 |
| 学习率 | --learning_rate 1e-4 |
设定参数更新步长。LoRA 训练通常适配较大的学习率(如 10 − 4 10^{-4} 10−4)。 |
| LoRA 秩 | --lora_rank 8 |
LoRA 矩阵的秩(Rank)。数值越大模型表达能力越强,但显存占用也会上升。 |
| LoRA 缩放 | --lora_alpha 32 |
缩放系数。通常设置为 lora_rank 的 2-4 倍,用于调节 LoRA 权重的比例。 |
| 作用模块 | --target_modules all-linear |
全线性层微调。在 Q, K, V, MLP 等所有 Linear 层注入 LoRA,效果通常优于部分注入。 |
| 梯度累积 | --gradient_accumulation_steps 16 |
每 16 步计算才更新一次参数。等效 Batch Size = 1 * 16 = 16,模拟大批次训练效果。 |
| 保存间隔 | --save_steps 50 |
每训练 50 个 Step 保存一次模型权重(Checkpoint)。 |
| 长度限制 | --max_length 2048 |
最大输入序列长度。超过此长度的文本会被截断,决定了模型处理长文本的能力。 |
| 输出路径 | --output_dir output |
指定训练后的 LoRA 权重、日志记录和配置文件的本地存储目录。 |
| 系统提示 | --system '...' |
设置全局 System Prompt,为模型预设特定的背景人格或语言风格。 |
| 作者名称 | --model_author swift |
自我认知配置:在模型回复“你是谁”等问题时,显示的开发者名称。 |
| 模型命名 | --model_name swift-robot |
自我认知配置:指定模型在对话中赋予它自己的官方名称。 |
启动后,就能看到类似下方的进度条一样的输出,整个过程大约持续十分钟左右输出完毕。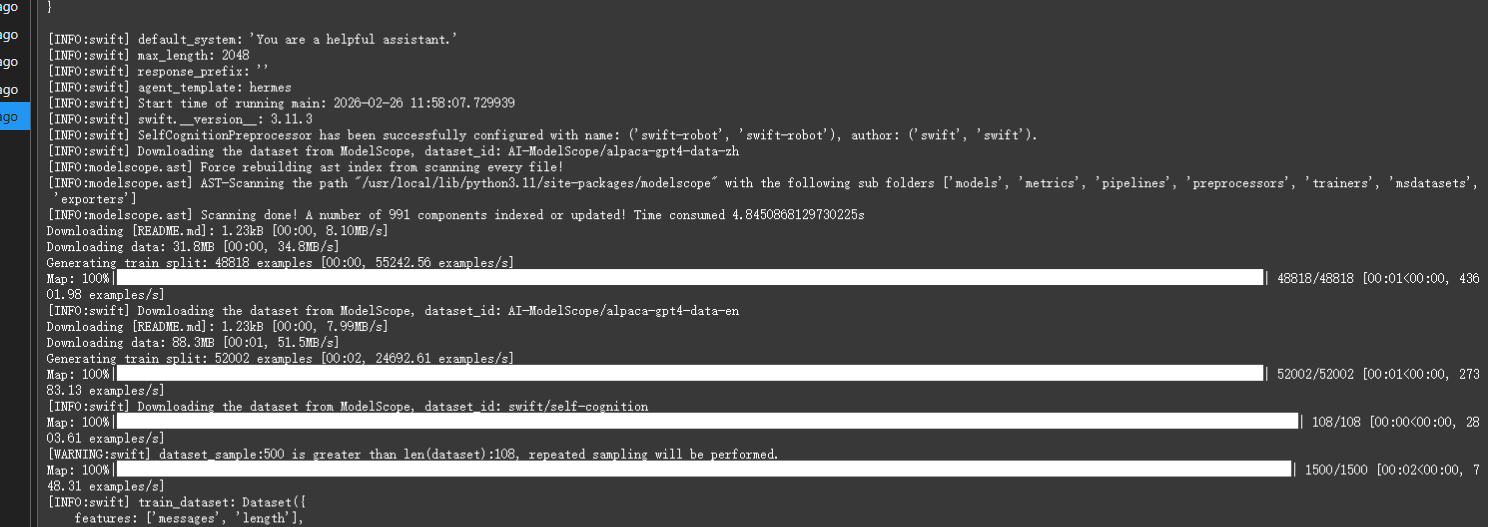
在指定的output路径中,则会生成类似v1-20260226-115522/checkpoint-94这样的目录,里面存放的就是训练完成后的模型权重文件。
到此,我们就得到了一个经过微调训练后的自己的模型,通过以下命令对这个微调模型进行推理:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters /mnt/workspace/output/v1-20260226-115506/checkpoint-94 \
--stream true \
--temperature 0 \
--max_new_tokens 2048
此命令开启交互式输入输出,静待一段时间,就可以在控制台中输入问题与自己微调后的模型进行对话:
同时,可以使用命令将lora与原模型进行合并,然后结合vllm进行推理,命令如下:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters /mnt/workspace/output/v1-20260226-115506/checkpoint-94 \
--stream true \
--merge_lora true \
--infer_backend vllm \
--vllm_max_model_len 8192 \
--temperature 0 \
--max_new_tokens 2048
上传modelscope
我们通过自己微调后的模型就能上传到modelscope上让别人下载或公司内部其他机器下载,操作如下:
首先,在modelscope中,选择创建模型,填写好id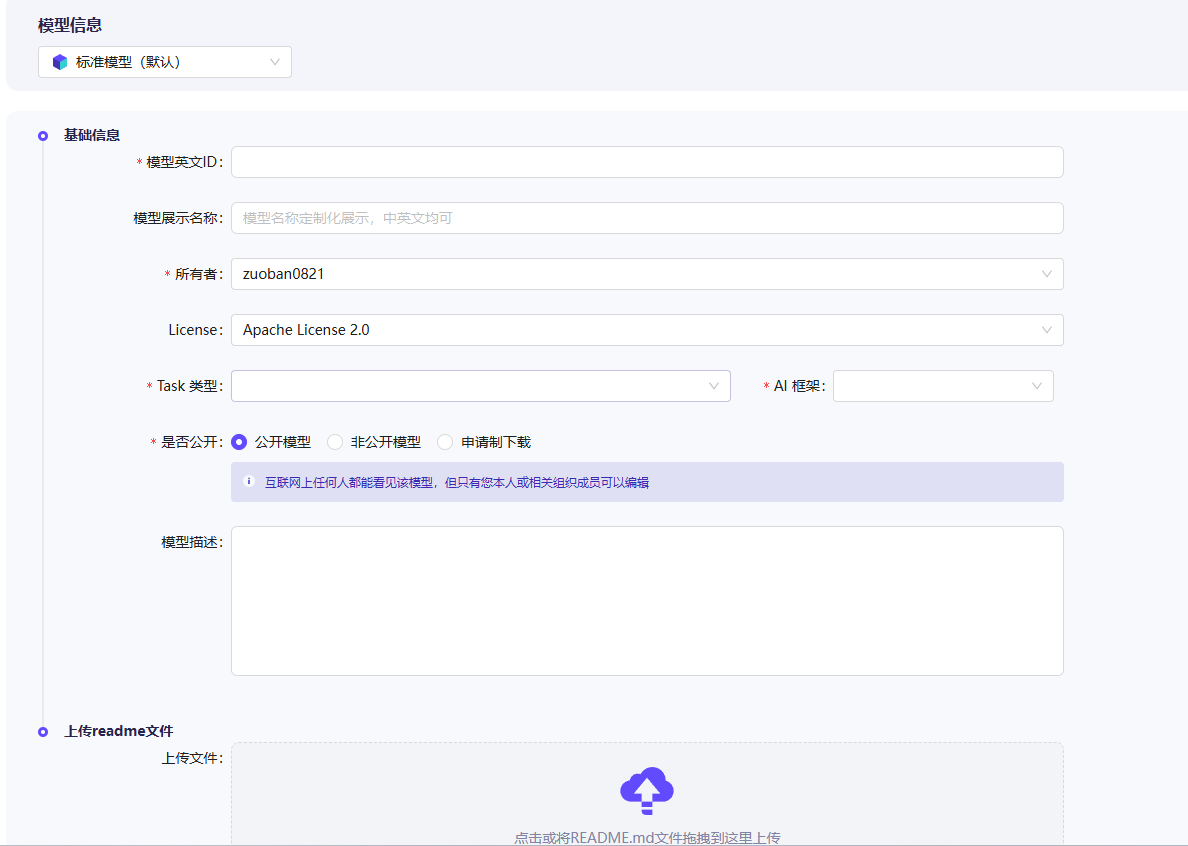
接着获取自己的token,modelscope通过token来与你的账户交互: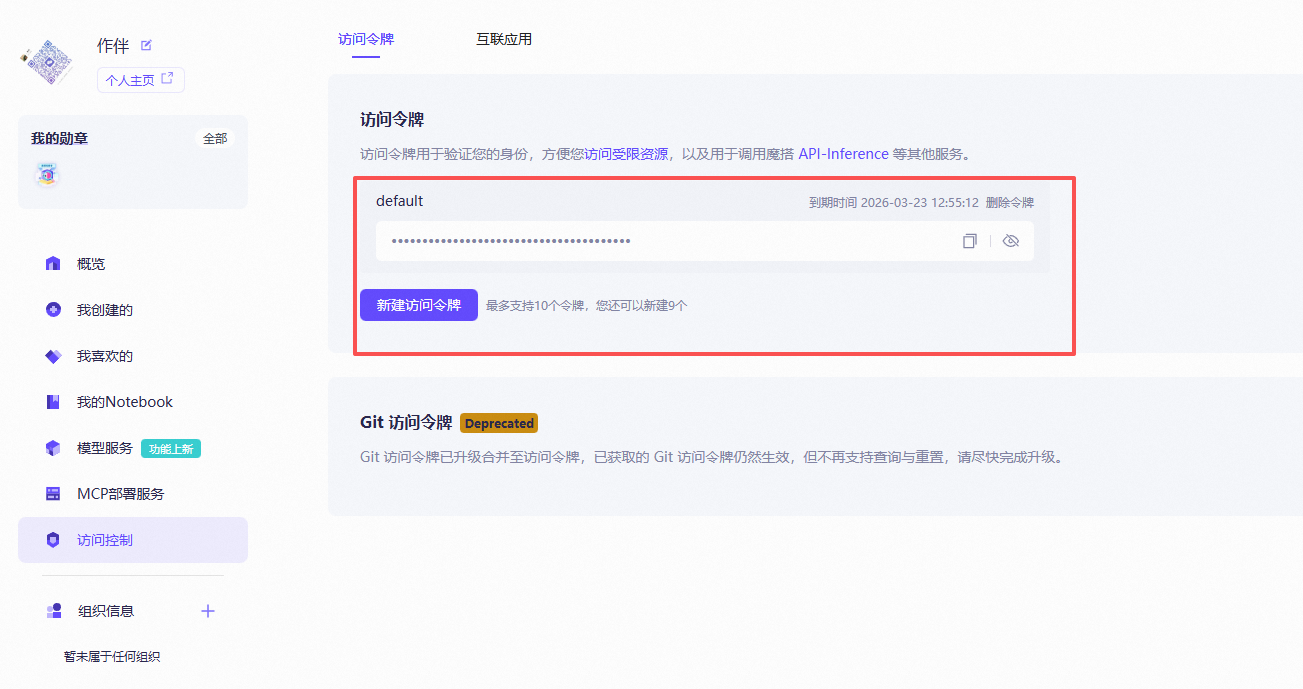
准备好之后,通过命令进行上传:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>' \
--use_hf false
等待上传完成后,刷新你的modelscope就能看到自己的模型文件了: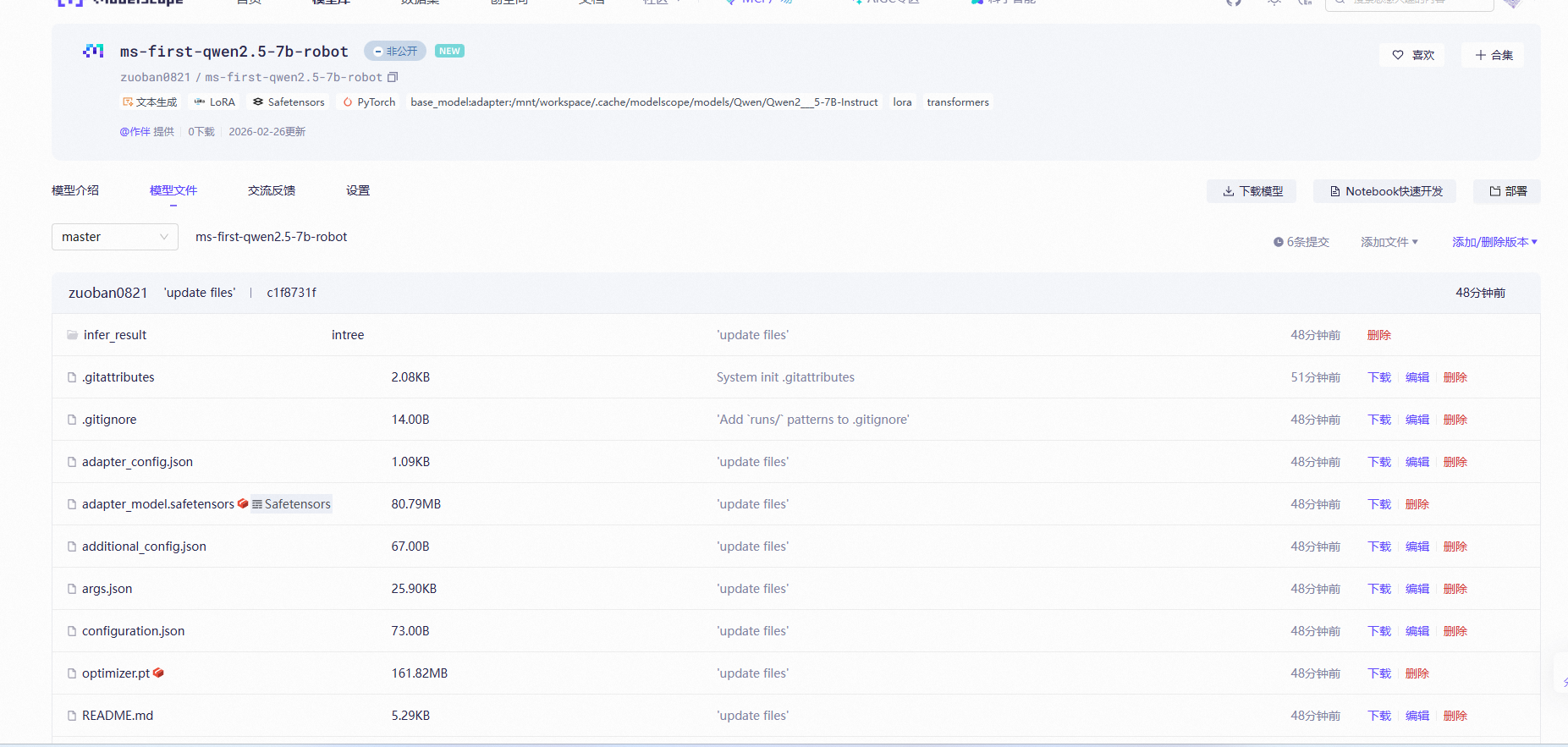

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)