SkillOrchestra:用“技能手册“取代强化学习,让AI智能体调度又好又省
当下的复合AI系统面临一个核心难题——多步骤任务中如何选对模型、选对工具?主流的强化学习方法训练成本高昂,还容易"偏科"(routing collapse),反复调用同一个最贵的大模型。SkillOrchestra 提出了一种截然不同的思路:不训练路由策略,而是从执行经验中学习一本可复用的"技能手册"(Skill Handbook),让编排器根据手册中记录的细粒度技能需求和各模型的擅长领域来做调度
SkillOrchestra:用"技能手册"取代强化学习,让AI智能体调度又好又省
论文标题:SkillOrchestra: Learning to Route Agents via Skill Transfer
论文链接:https://arxiv.org/abs/2602.19672
机构:University of Wisconsin-Madison, Salesforce AI Research
作者:Jiayu Wang, Yifei Ming, Zixuan Ke, Shafiq Joty, Aws Albarghouthi, Frederic Sala
一句话总结
当下的复合AI系统面临一个核心难题——多步骤任务中如何选对模型、选对工具?主流的强化学习方法训练成本高昂,还容易"偏科"(routing collapse),反复调用同一个最贵的大模型。SkillOrchestra 提出了一种截然不同的思路:不训练路由策略,而是从执行经验中学习一本可复用的"技能手册"(Skill Handbook),让编排器根据手册中记录的细粒度技能需求和各模型的擅长领域来做调度。结果?准确率最高提升22.5个百分点,训练成本降低700倍,而且手册还能跨模型迁移。
问题背景:为什么AI编排这么难?
从单模型到"交响乐团"
过去几年,AI的使用方式经历了一次根本性的转变。我们不再指望一个模型包打天下——GPT-5擅长推理,Qwen3擅长数学,Claude擅长写代码,还有各种专用的搜索、代码执行工具。现代的AI系统越来越像一个交响乐团:有不同的乐手(模型),有不同的乐器(工具),关键在于指挥(编排器)能不能在正确的时刻让正确的乐手上场。
这就是 Agent Orchestration(智能体编排)要解决的问题。
现有方案的两个痛点
痛点一:静态路由太粗糙。 传统的模型路由(Model Routing)方法,比如KNN Router、BERT Router等,本质上是"看一眼题目就选人"。它们基于输入特征做一次性决策,假设一个模型就能搞定整个任务。但在多步骤的智能体工作流中,不同阶段需要不同的能力——搜索阶段需要信息检索能力,编程阶段需要代码生成能力,推理阶段需要逻辑分析能力。一次性选人显然不够。
痛点二:RL路由太贵还会"偏科"。 为了实现多步骤动态路由,Router-R1和ToolOrchestra这样的工作用强化学习(PPO、GRPO)来训练路由策略。思路是对的,但问题也很严重:
- 训练成本极高:Router-R1需要14,000个训练样本做全量RL训练;
- 适应性差:换一批模型或加一个新工具,就得重新训练;
- 路由坍缩(Routing Collapse):RL训练出来的策略会退化成反复选同一个"最强"模型。
路由坍缩这个现象值得展开说。论文中给出了一个令人震惊的数据:Router-R1在9个基准测试中,98.02%的调用都给了LLaMA-3.1-70B这一个模型,其他5个模型加起来才不到2%的调用量。这就好比一个乐团指挥,不管什么曲目都只让首席小提琴一个人演奏——其他乐手形同虚设。类似地,在智能体编排场景下,NVIDIA的ToolOrchestra把99.7%的搜索调用给了GPT-5-mini,97.9%的回答调用给了GPT-5,本质上也是"一个人干所有活"。
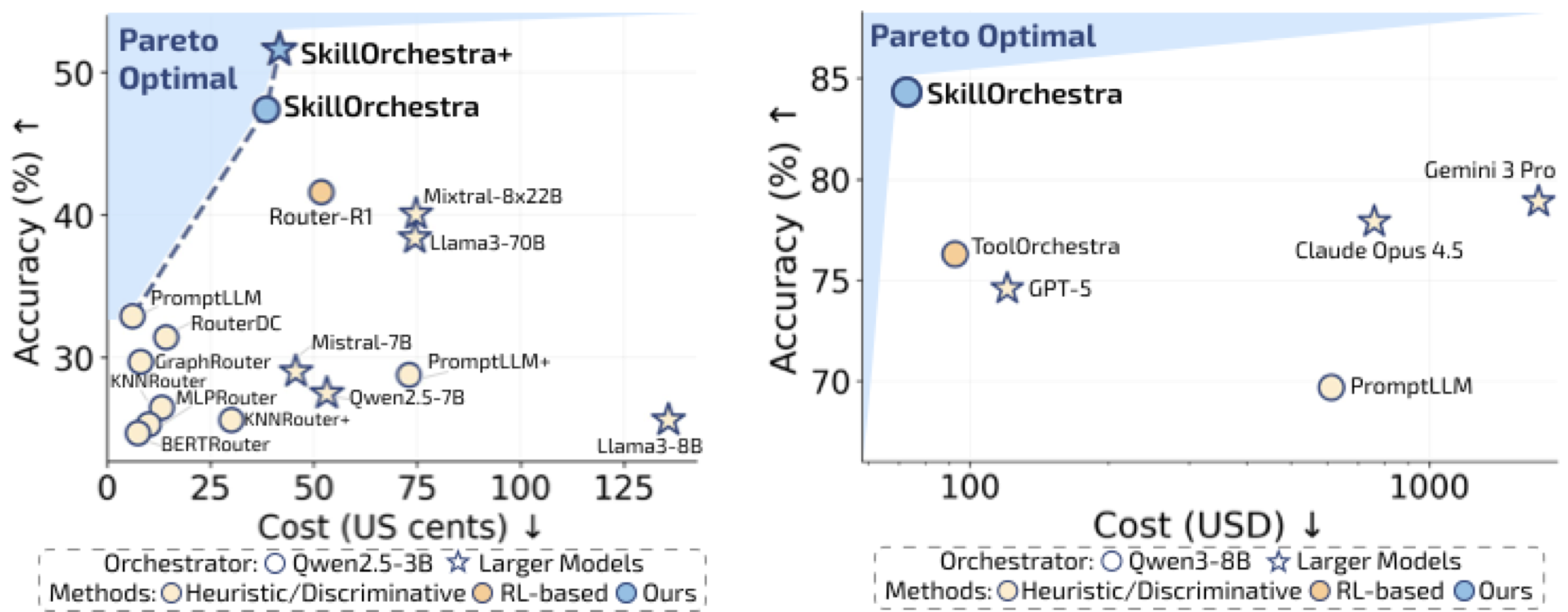
上图展示了各方法在"准确率-成本"坐标系中的位置。左图是模型路由场景,右图是智能体编排场景。可以看到,SkillOrchestra和SkillOrchestra+稳稳地站在了Pareto最优前沿上——在准确率更高的同时成本更低。特别是右图中,使用Qwen3-8B作为编排器的SkillOrchestra,在准确率上超过了GPT-5、Claude Opus 4.5和Gemini 3 Pro这些直接用强模型做编排的方案,而成本只是它们的零头。
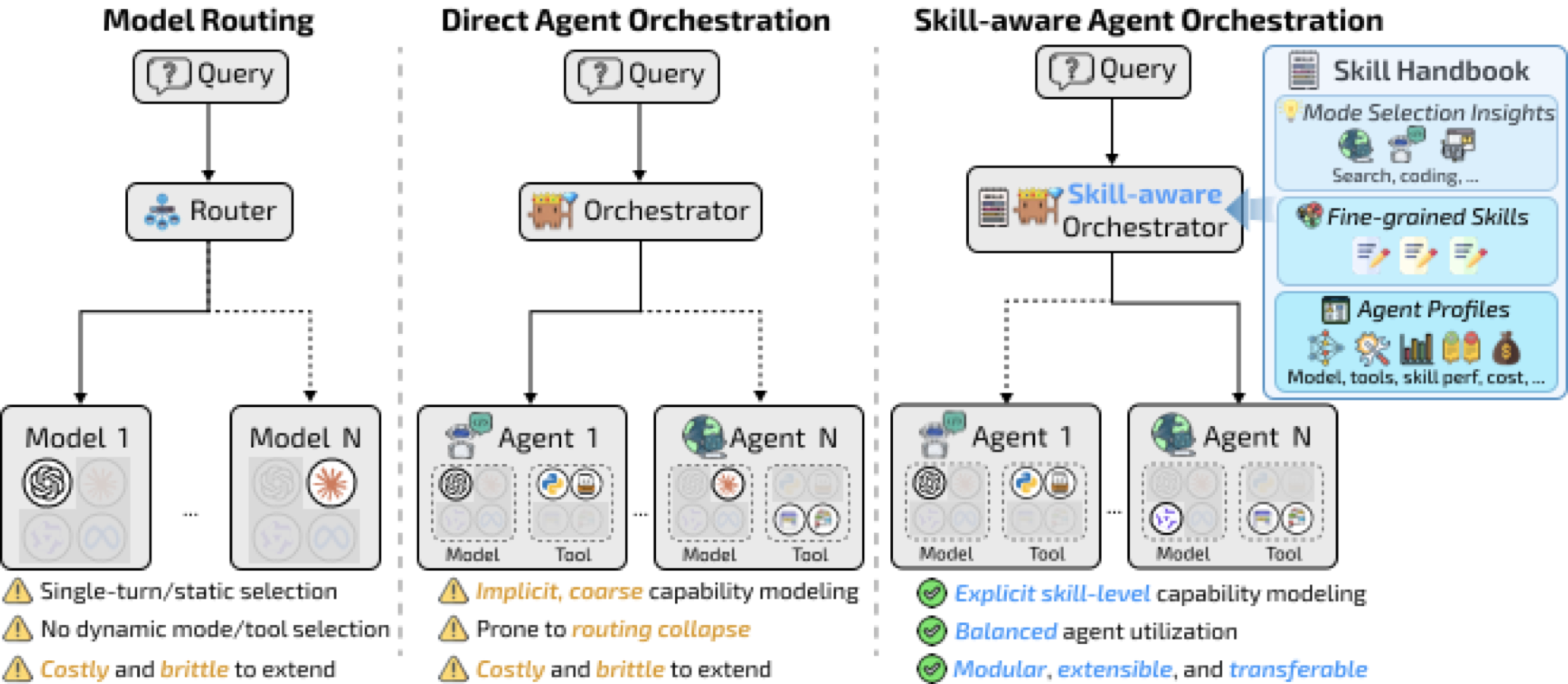
上图清晰地展示了三种范式的区别:(左)传统模型路由是静态的一次性选择;(中)直接智能体编排用RL学端到端策略,但容易路由坍缩;(右)SkillOrchestra的技能感知编排,通过显式的技能建模实现平衡的智能体调度。
SkillOrchestra:核心方法
SkillOrchestra的核心创新在于引入了一个中间抽象层——技能(Skill)。不是直接学"遇到什么问题选什么模型"的映射关系,而是先搞清楚"这个问题需要什么技能",再看"哪个模型擅长这些技能"。
这个思路其实和人类社会的招聘逻辑很像:好的HR不会只看简历上写了哪些项目,而是会先分析岗位需要什么技能,再对照候选人在这些技能上的评估结果来做匹配。
系统全景
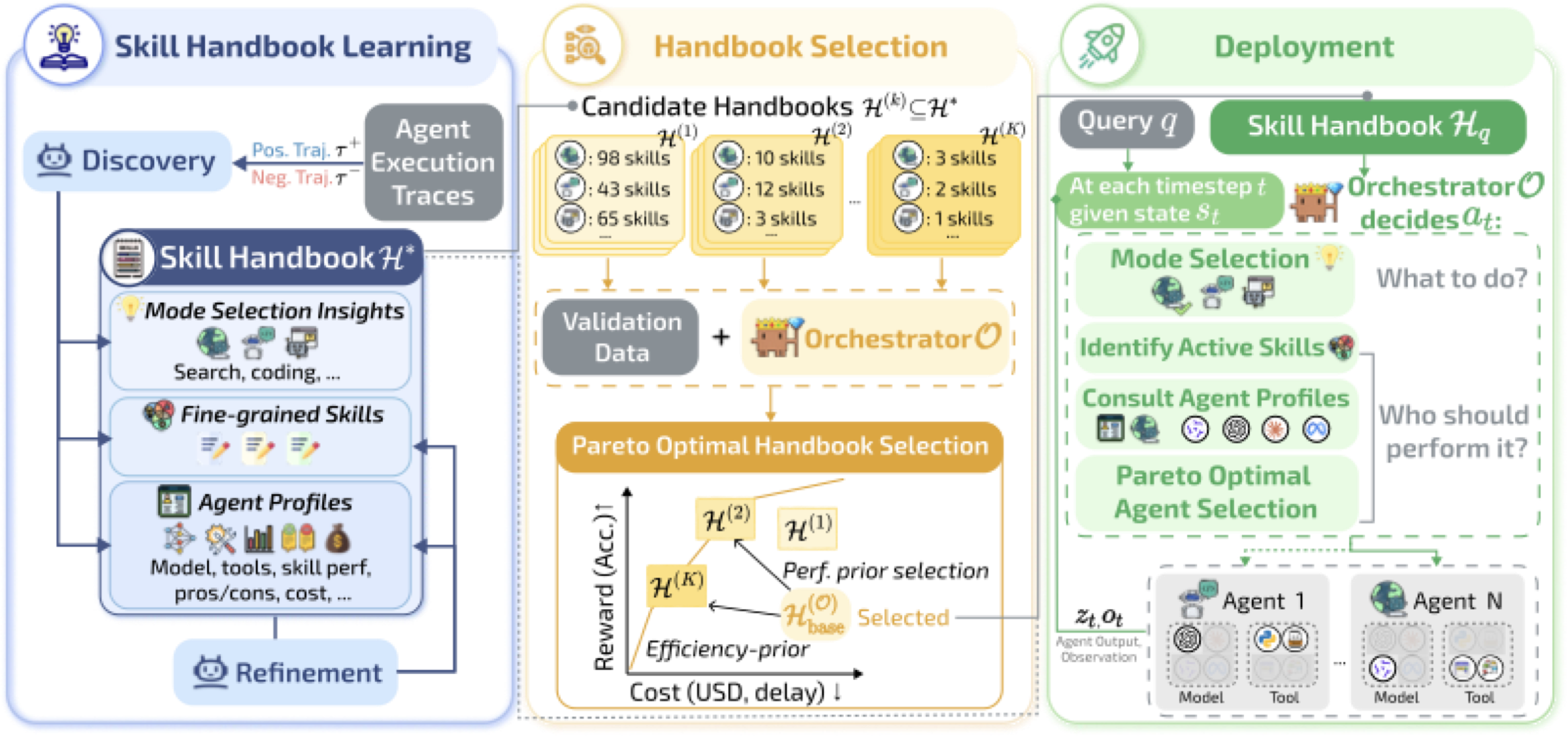
整个系统分为三个阶段:
- 技能手册学习(左):从智能体执行轨迹中发现和提炼可复用的技能,同时估计每个智能体在各技能上的表现和成本
- 手册选择(中):根据编排器的能力选择合适粒度的技能子集,通过Pareto最优验证
- 部署推理(右):编排器在每一步先选操作模式(搜索/编程/回答),再根据当前需要的技能选最合适的智能体
关键概念:技能手册
技能手册可以形式化为一个图结构 GH=(V,E)\mathcal{G}_{\mathcal{H}} = (\mathcal{V}, \mathcal{E})GH=(V,E),包含三类节点:
(一)模式级元数据 VΨ\mathcal{V}_\PsiVΨ:记录每种操作模式(搜索、编程、回答)的路由洞察。比如"如果需要多步算术运算或数据聚合,应该切换到编程模式而不是搜索模式"。这些洞察从执行轨迹中提炼而来。
(二)技能注册表 VΣ\mathcal{V}_\SigmaVΣ:层次化的技能库。每个技能 σ\sigmaσ 定义为:
σ≜⟨D,I⟩\sigma \triangleq \langle \mathcal{D}, \mathcal{I} \rangleσ≜⟨D,I⟩
其中 D\mathcal{D}D 是技能的自然语言描述,I\mathcal{I}I 是上下文指示器(关键词、结构模式、示例查询等),用于判断何时需要该技能。
举个例子:在编程模式下,可能有一个高级技能叫"数据处理"(data_processing),它又细分为子技能"符号逻辑"(symbolic_logic)。这种层级结构让系统能够在不同粒度上进行技能匹配。
(三)智能体档案 VP\mathcal{V}_\mathcal{P}VP:为每个智能体建立详细的能力档案,定义为:
PA,ψ=({ϕA,σ}σ∈Σψ, C^A(ψ), RA,ψ, ΓA)\mathcal{P}_{A,\psi} = \left(\{\phi_{A,\sigma}\}_{\sigma \in \Sigma_\psi},\ \hat{C}_A(\psi),\ \mathcal{R}_{A,\psi},\ \Gamma_A\right)PA,ψ=({ϕA,σ}σ∈Σψ, C^A(ψ), RA,ψ, ΓA)
这个档案包含四个部分:
- ϕA,σ\phi_{A,\sigma}ϕA,σ:智能体A在技能 σ\sigmaσ 上的成功概率估计
- C^A(ψ)\hat{C}_A(\psi)C^A(ψ):在模式 ψ\psiψ 下的执行成本(token数、延迟等)
- RA,ψ\mathcal{R}_{A,\psi}RA,ψ:模式条件下的路由信号(使用约束、系统性失败模式等)
- ΓA\Gamma_AΓA:智能体的优劣势总结
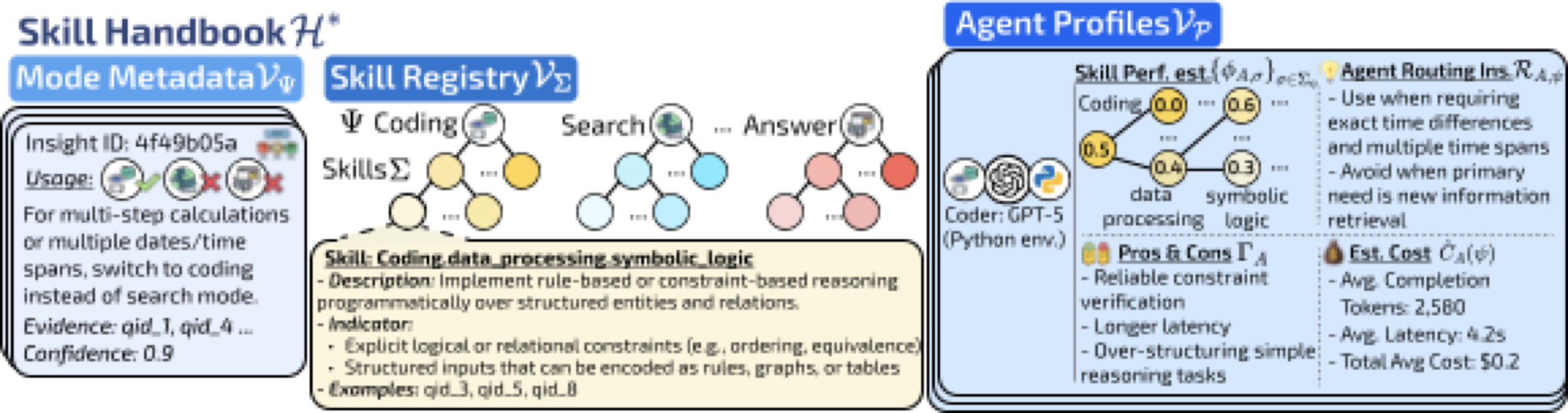
上图展示了一个学习到的技能手册实例。左边是模式级路由洞察(比如"当需要精确时间差计算时使用编程模式"),中间是层次化的技能注册表,右边是某个智能体的档案——包括各技能的能力评分、路由建议、成本统计和优劣势分析。
技能手册的学习过程
手册的学习分为两个阶段。
阶段一:技能发现与档案构建。 给定一个探索数据集 Dtrain={(qi,Bi)}i=1N\mathcal{D}_{\text{train}} = \{(q_i, \mathcal{B}_i)\}_{i=1}^NDtrain={(qi,Bi)}i=1N,其中 Bi\mathcal{B}_iBi 是对同一查询使用不同智能体得到的多条轨迹。
核心操作是对比学习:对于每个查询和操作模式,对比成功轨迹 τ+\tau^+τ+ 和失败轨迹 τ−\tau^-τ−,通过差异分析 Ddiff(τ+∥τ−)\mathcal{D}_{\text{diff}}(\tau^+ \| \tau^-)Ddiff(τ+∥τ−) 来隔离"缺失的能力"。一个LLM(比如GPT-5)充当"发现器",将这个能力差距抽象为一个可复用的技能定义 σnew\sigma_{\text{new}}σnew。
智能体档案的构建用了一个很巧妙的方法——Beta分布建模。对于每个智能体A、模式 ψ\psiψ、技能 σ\sigmaσ,将成功率建模为:
ϕA,σ∼Beta(αA,σ, βA,σ)\phi_{A,\sigma} \sim \text{Beta}(\alpha_{A,\sigma},\ \beta_{A,\sigma})ϕA,σ∼Beta(αA,σ, βA,σ)
更新规则非常直观:
αA,σ(t+1)←αA,σ(t)+∑τ∈BiI[A succeeds on σ in τ]\alpha_{A,\sigma}^{(t+1)} \leftarrow \alpha_{A,\sigma}^{(t)} + \sum_{\tau \in \mathcal{B}_i} \mathbb{I}[A \text{ succeeds on } \sigma \text{ in } \tau]αA,σ(t+1)←αA,σ(t)+τ∈Bi∑I[A succeeds on σ in τ]
βA,σ(t+1)←βA,σ(t)+∑τ∈BiI[A fails on σ in τ]\beta_{A,\sigma}^{(t+1)} \leftarrow \beta_{A,\sigma}^{(t)} + \sum_{\tau \in \mathcal{B}_i} \mathbb{I}[A \text{ fails on } \sigma \text{ in } \tau]βA,σ(t+1)←βA,σ(t)+τ∈Bi∑I[A fails on σ in τ]
成功一次 α\alphaα 加1,失败一次 β\betaβ 加1。Beta分布的后验均值 α/(α+β)\alpha/(\alpha+\beta)α/(α+β) 自然地给出了能力估计,而且天然带有不确定性量化——数据少的时候估计不那么确定,数据多了就越来越准。比起用点估计(比如简单地算个胜率),Beta分布的好处在于它能区分"试了100次赢了50次"和"试了2次赢了1次"——虽然胜率都是50%,但前者的置信度高得多。
阶段二:手册精炼。 为了防止技能过于碎片化或冗余,系统定期对技能集合进行精炼:
- 拆分(Splitting):如果某个技能 σ\sigmaσ 在不同查询上的智能体表现方差很大,说明这个技能可能包含了多个不同的子能力,应该拆开
- 合并(Merging):如果两个技能 (σi,σj)(\sigma_i, \sigma_j)(σi,σj) 在所有智能体上的表现统计不可区分,说明它们对路由决策来说是冗余的,应该合并
一个LLM充当"反思器",审核这些拆分/合并提案,必要时生成修订后的技能定义。
推理时的决策流程
推理时,编排器按以下步骤工作:
第一步:手册选择。 学到的完整手册 H∗\mathcal{H}^*H∗ 可能包含大量细粒度技能,但不是所有编排器都能准确使用这些细粒度信息。一个能力较弱的编排器如果要在"符号逻辑"和"数值近似"之间做选择,很可能搞混——不如直接用更粗粒度的"数据处理"这个技能。
因此,系统为每个编排器选择一个合适的手册子集 Hbase(O)\mathcal{H}_{\text{base}}^{(\mathcal{O})}Hbase(O),通过Pareto最优验证来确定最佳粒度:
Hbase(O)=argmaxH⊆H∗Eq∼Dval[R(τH(q))−λ∑t=0∣τH(q)∣C(ψt,At)]\mathcal{H}_{\text{base}}^{(\mathcal{O})} = \arg\max_{\mathcal{H} \subseteq \mathcal{H}^*} \mathbb{E}_{q \sim \mathcal{D}_{\text{val}}} \left[ R(\tau_{\mathcal{H}}(q)) - \lambda \sum_{t=0}^{|\tau_{\mathcal{H}}(q)|} C(\psi_t, A_t) \right]Hbase(O)=argH⊆H∗maxEq∼Dval R(τH(q))−λt=0∑∣τH(q)∣C(ψt,At)
这个公式直接在验证集上评估完整的轨迹表现,而不是局部的路由准确率。
第二步:技能导向的智能体路由。 在每一个时间步 ttt:
- 模式选择:ψt∼πmode(⋅∣st;Rψ)\psi_t \sim \pi_{\text{mode}}(\cdot | s_t; \mathcal{R}_\psi)ψt∼πmode(⋅∣st;Rψ),根据当前状态和模式级洞察选择操作模式
- 技能匹配:检索当前状态下激活的技能集 Σt⊆Σψt\Sigma_t \subseteq \Sigma_{\psi_t}Σt⊆Σψt
- 能力感知路由:选择最优智能体
At∗=argmaxA∈Aψt[∑σ∈Σtwt,σ⋅αA,σαA,σ+βA,σ−λc⋅C^A(ψt)]A_t^* = \arg\max_{A \in \mathcal{A}_{\psi_t}} \left[ \sum_{\sigma \in \Sigma_t} w_{t,\sigma} \cdot \frac{\alpha_{A,\sigma}}{\alpha_{A,\sigma} + \beta_{A,\sigma}} - \lambda_c \cdot \hat{C}_A(\psi_t) \right]At∗=argA∈Aψtmax[σ∈Σt∑wt,σ⋅αA,σ+βA,σαA,σ−λc⋅C^A(ψt)]
这个选择标准很直观:加权的技能能力估计减去成本惩罚。权重 wt,σw_{t,\sigma}wt,σ 反映了当前查询对各技能的需求程度。
策略分解
从理论角度看,整个编排策略被分解为:
π(at∣st)=πmode(ψt∣st)⋅πroute(At∣st,ψt)\pi(a_t | s_t) = \pi_{\text{mode}}(\psi_t | s_t) \cdot \pi_{\text{route}}(A_t | s_t, \psi_t)π(at∣st)=πmode(ψt∣st)⋅πroute(At∣st,ψt)
传统的模型路由是这个公式的特例——只有一个时间步、一个模式(answer)、没有工具。SkillOrchestra的贡献在于把优化目标从 maxθJ(πθ)\max_\theta J(\pi_\theta)maxθJ(πθ)(学习路由策略的参数 θ\thetaθ)转变为 maxHJ(π(⋅∣H))\max_\mathcal{H} J(\pi(\cdot|\mathcal{H}))maxHJ(π(⋅∣H))(学习最优的技能手册结构 H\mathcal{H}H),从参数适应转变为知识获取。
实验结果
实验分为两大场景:模型路由和智能体编排。
场景一:模型路由
在这个场景下,没有外部工具,性能差异直接反映模型编排的质量。
模型池:Qwen2.5-7B、LLaMA-3.1-8B、LLaMA-3.1-70B、Mistral-7B、Mixtral-8x22B、Gemma-2-27B。编排器:Qwen2.5-3B。
数据集:9个基准测试,涵盖一般QA(NQ、TriviaQA、PopQA)、多跳QA(HotpotQA、2WikiMultiHopQA、Musique、Bamboogle)和数学推理(MATH、AMC23)。
关键数据:SkillOrchestra默认只使用不到50个训练样本来学习技能手册,外加相同数量的验证样本。而Router-R1用了14,000个训练样本做PPO训练。
核心结果表
| 方法类别 | 方法 | NQ | TriviaQA | PopQA | HotpotQA | 2Wiki | Musique | Bamboogle | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| 无路由 | Vanilla | 9.2 | 26.0 | 12.2 | 14.0 | 26.6 | 2.6 | 4.0 | 13.5 |
| 无路由 | RAG | 29.8 | 54.0 | 36.6 | 21.6 | 14.6 | 7.8 | 22.4 | 26.7 |
| 无路由 | Search-R1 | 32.8 | 51.0 | 32.4 | 23.6 | 27.8 | 9.0 | 27.2 | 29.1 |
| 启发式 | Largest LLM | 29.6 | 57.8 | 35.4 | 27.8 | 27.4 | 10.4 | 48.0 | 33.8 |
| 启发式 | RouterDC | 27.8 | 59.2 | 28.2 | 24.4 | 21.8 | 8.0 | 50.4 | 31.4 |
| 启发式 | GraphRouter | 27.6 | 58.6 | 28.0 | 23.4 | 18.0 | 7.6 | 44.8 | 29.7 |
| RL路由 | Router-R1 | 38.8 | 70.6 | 38.4 | 35.2 | 43.4 | 13.8 | 51.2 | 41.6 |
| Ours | SkillOrchestra | 54.2 | 71.6 | 42.6 | 39.0 | 48.0 | 18.2 | 58.4 | 47.4 |
| Ours | SkillOrchestra+ | 54.8 | 80.2 | 48.8 | 44.2 | 49.6 | 20.6 | 63.2 | 51.6 |
几个值得注意的结果:
- SkillOrchestra平均EM 47.4,比Router-R1的41.6高出5.8个百分点
- SkillOrchestra+更是达到51.6,比Router-R1高出10.0个百分点
- 在多跳推理任务上优势更明显:Musique从13.8提升到20.6(+6.8),Bamboogle从51.2提升到63.2(+12.0)
- 这些提升只用了不到50个训练样本,而Router-R1用了14,000个
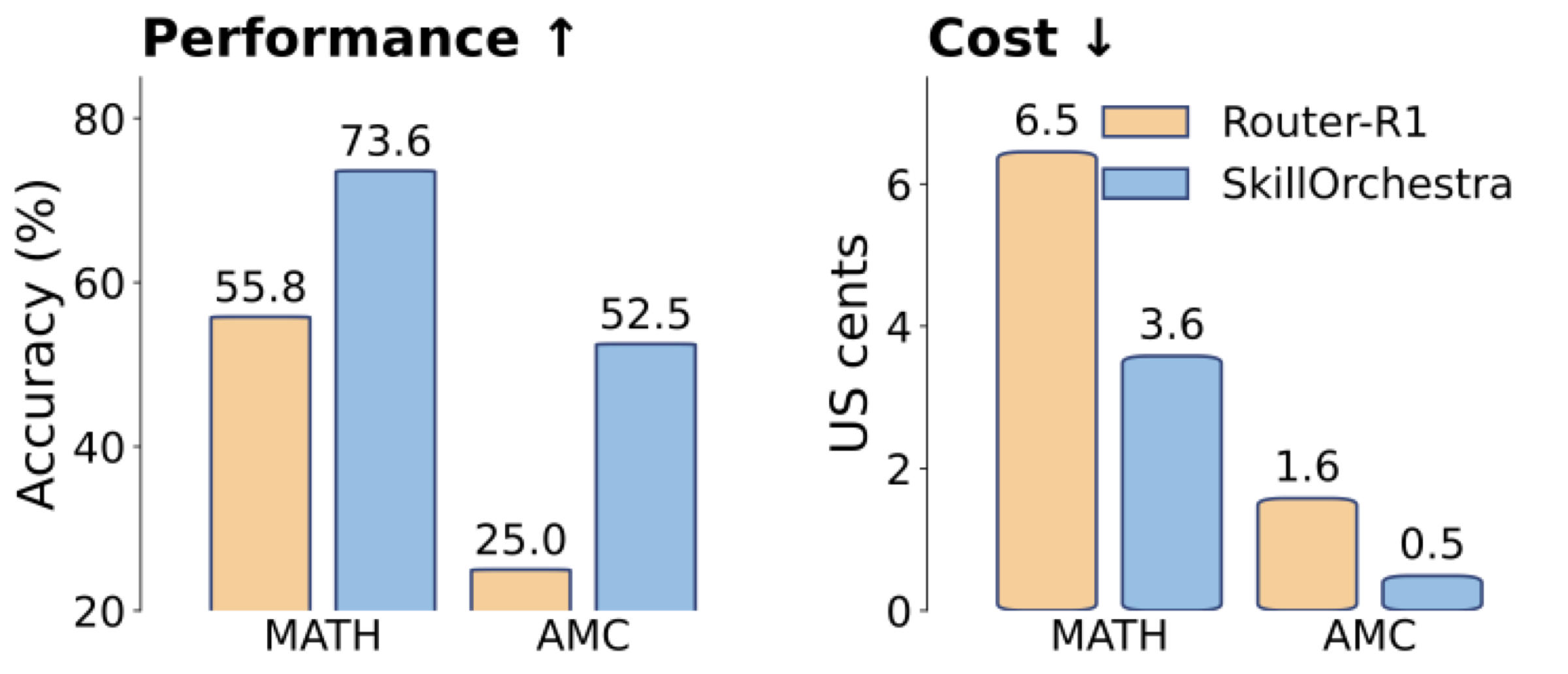
上图展示了在MATH和AMC这两个数学推理数据集上的对比。SkillOrchestra在MATH上达到73.6%的准确率(vs Router-R1的55.8%,提升17.8个百分点),在AMC上达到52.5%(vs 25.0%,提升22.5个百分点),同时推理成本降低约2倍。这个22.5个百分点的提升是论文中报告的最大单项改进。
路由坍缩的缓解

左图的模型选择比例饼图是本文最直观的结果之一:
- Router-R1:LLaMA-3.1-70B占98.02%,其他所有模型加起来不到2%
- SkillOrchestra:Mixtral-8x22B 44.53%,Qwen2.5-7B 25.99%,LLaMA-3.1-70B 15.38%,Qwen2.5-3B 11.50%——分布均衡得多
这种均衡分布反映了真正的能力感知调度:不同的技能需求被路由到不同的擅长模型,强模型只在真正需要时才被调用,简单任务交给轻量模型处理。更有趣的是,某些情况下编排器自己就能回答问题,根本不需要调用外部模型——进一步降低了不必要的调用和成本。
跨模型迁移能力
右图展示了从Qwen2.5-3B学到的技能手册迁移到其他模型的效果:
| 编排器模型 | 无手册 | 有手册 | 提升 |
|---|---|---|---|
| Qwen2.5-3B | 40.7% | 56.1% | +15.4 |
| Qwen2.5-7B | 35.7% | 60.0% | +24.3 |
| LLaMA-3.1-8B | 35.5% | 58.0% | +22.5 |
| Mistral-7B | 36.5% | 59.8% | +23.3 |
| Mixtral-8x22B | 46.5% | 61.3% | +14.8 |
手册完全不需要针对新模型重新训练,直接用就能获得巨大提升。而且更强的基座模型通常能获得更高的绝对性能,说明模型本身的推理能力和技能手册提供的结构化知识是互补的。
场景二:智能体编排
这是更复杂的全量智能体编排场景,在FRAMES基准上测试。系统需要协调三种操作模式(搜索、编程、回答),每种模式有不同的模型池和工具:
- 搜索模式:GPT-5/GPT-5-mini/Qwen3-32B + WebSearch/LocalSearch
- 编程模式:GPT-5/GPT-5-mini/Qwen2.5-Coder-32B + PythonExec
- 回答模式:GPT-5/GPT-5-mini/Llama-3.3-70B/Qwen3-32B/Qwen2.5-Math-72B/Qwen2.5-Math-7B(无外部工具)
编排器为Qwen3-8B,最大交互回合数50。
| 方法 | 准确率 | 总成本(USD) |
|---|---|---|
| ToolOrchestra (RL-based) | 76.3% | $92.7 |
| GPT-5 (直接编排) | 74.6% | $120.4 |
| Claude Opus 4.5 (直接编排) | 77.9% | $758.1 |
| Gemini 3 Pro (直接编排) | 78.9% | $1,729.3 |
| SkillOrchestra | 84.3% | $72.7 |
这组数据含义深远:
- SkillOrchestra准确率最高(84.3%),比用GPT-5做编排高了近10个百分点
- 成本最低($72.7),比GPT-5直接编排便宜39%,比Claude Opus 4.5便宜90%
- 用小模型Qwen3-8B做编排器 + 技能手册,效果全面超过直接用顶级大模型做编排
这说明一个重要道理:编排能力 ≠ 模型能力。一个能力适中但"有经验"(配备了技能手册)的编排器,可以比一个能力超强但"盲目指挥"的大模型做得更好。
ToolOrchestra的路由坍缩问题(来自附录C的详细分析):
- 搜索模式:99.7%调用给了GPT-5-mini
- 回答模式:97.9%调用给了GPT-5
- 而SkillOrchestra在搜索模式100%使用Qwen3-32B(更便宜且同样有效),回答模式则分散调度:GPT-5 58.4%、GPT-5-mini 10.0%、其余给专用模型
消融实验
| 设置 | 手册 | 发现 | 精炼 | 选择 | 细粒度 | 准确率 | 成本 |
|---|---|---|---|---|---|---|---|
| No HB | ✗ | ✗ | ✗ | ✗ | ✗ | 71.0% | $122.9 |
| No Ref+Sel | ✓ | ✓ | ✗ | ✗ | ✓ | 79.0% | $5.5 |
| No Selection | ✓ | ✓ | ✓ | ✗ | ✓ | 79.3% | $3.4 |
| No FG Skills | ✓ | ✓ | ✓ | ✓ | ✗ | 80.4% | $15.1 |
| Full System | ✓ | ✓ | ✓ | ✓ | ✓ | 85.0% | $9.3 |
消融结果清晰地展示了每个组件的贡献:
- 没有手册(No HB):准确率降到71.0%,成本暴增至$122.9——没有技能指导,编排器只能盲目调用,又贵又不准
- 有发现但无精炼和选择(No Ref+Sel):准确率79.0%,成本$5.5——即使是未经精炼的原始技能也已经很有用
- 有精炼但无选择(No Selection):准确率79.3%,成本进一步降到$3.4——精炼减少了冗余,提高了效率
- 无细粒度技能(No FG Skills):准确率80.4%,成本$15.1——只用粗粒度技能(模式级别)导致成本增加和准确率下降
- 完整系统:准确率85.0%,成本$9.3——所有组件协同工作达到最佳平衡
一个有趣的现象:No Selection配置虽然成本最低($3.4),但准确率不是最高的。这是因为完整手册包含了太多细粒度技能,编排器可能在技能识别上犯错。加上手册选择后,虽然成本从$3.4增加到$9.3,但准确率从79.3%跳升到85.0%——技能粒度需要和编排器能力相匹配。
算法伪代码
论文在附录B给出了技能导向智能体路由的完整算法:
算法1: 技能导向的智能体路由
输入: 状态 s_t; 查询手册 H_q; 成本权重 λ_c
输出: 选择的模式 ψ_t, 智能体 A_t, 执行轨迹 z_t, 观察 o_t, 更新后状态 s_{t+1}
1. 模式选择
ψ_t ← π_mode(·|s_t; R_ψ)
2. 检索激活技能
Σ_t ⊆ Σ_{ψ_t} from H_q
3. 能力感知路由
for each A ∈ A_{ψ_t} do:
P̂(A) ← Σ_{σ∈Σ_t} w_{t,σ} · α_{A,σ} / (α_{A,σ} + β_{A,σ}) // 后验均值能力
U(A) ← P̂(A) - λ_c · Ĉ_A(ψ_t) // 效用 = 能力 - 成本
A_t ← argmax_{A∈A_{ψ_t}} U(A)
4. 执行与状态转换
(z_t, o_t) ← Execute(A_t, ψ_t, s_t)
s_{t+1} ← UpdateState(s_t, ψ_t, A_t, z_t, o_t)
算法的简洁性本身就是一个亮点——整个路由过程完全确定性的(给定手册和当前状态),不需要采样或随机策略,也不需要梯度更新。
执行示例分析
论文附录D提供了三个完整的执行轨迹示例,让我们得以窥见技能感知路由的实际工作方式。
示例一:多轮路由纠正(AMC数学题)
编排器首先分析了一道AMC数学题需要的技能(代数方程求解、Vieta定理等),将第一次搜索路由到Mixtral-8x22B(擅长代数操作且成本适中)。如果第一次回答不理想,编排器会在第二次调用中切换到LLaMA-3.1-70B(能力更强但更贵),实现了"先试便宜的,不行再上贵的"的自适应策略。
示例二:编排器自主回答(AMC数学题)
更有趣的是,面对一道关于直角三角形外接圆面积比的问题,Qwen2.5-3B编排器分析技能需求后发现,这个问题可以用基础几何知识(直角三角形的斜边是外接圆直径)直接求解,于是没有调用任何外部模型,自己给出了正确答案194。这展示了技能感知路由的一个重要特性:外部模型调用是可选的而非强制的。
示例三:噪声恢复(PopQA知识问答)
在一道知识问答题上,编排器先路由到Gemma-2-27B,但获得了包含噪声的回答。编排器在第二轮判断需要更强的实体链接和关系推理能力,切换到Mixtral-8x22B获取更准确的信息,最终在第三轮汇总后给出正确答案。三轮调用使用了不同的模型,体现了真正的自适应路由。
深入讨论
为什么"技能"这个中间抽象这么重要?
直觉上理解,技能作为中间抽象层解耦了"需求侧"和"供给侧"。没有技能层的话,路由决策是 query→agent\text{query} \rightarrow \text{agent}query→agent 的直接映射,每换一个模型或加一个新模型,映射关系就要重新学。有了技能层,变成了 query→skills→agent\text{query} \rightarrow \text{skills} \rightarrow \text{agent}query→skills→agent 的两步映射——新加的模型只需要评估它在各技能上的能力即可接入系统,不需要重新学习路由策略。
这和软件工程中"接口与实现分离"的思想如出一辙:技能定义了接口(需要什么能力),智能体档案给出了实现(谁有这个能力),编排器只需要根据接口选实现。
为什么RL路由容易坍缩?
论文虽然没有深入分析RL坍缩的原因,但从结果来推断,这很可能是PPO/GRPO训练中的一个常见问题:在多步骤环境中,强化学习倾向于找到一个"安全"的策略——总是选最强的模型虽然贵,但至少不会出错。这是一种典型的 exploration-exploitation 失衡:训练过程中一旦发现某个模型的胜率最高,就越来越倾向于选它,探索其他模型的机会越来越少,最终形成正反馈循环,导致策略退化。
SkillOrchestra避免了这个问题,因为它不是通过RL学策略,而是通过数据统计来建立能力档案。每个模型在每个技能上都有独立的Beta分布估计,不存在"正反馈导致偏好锁定"的问题。
训练成本的量级差异从何而来?
SkillOrchestra声称比Router-R1和ToolOrchestra分别有700×和300×的训练成本优势。这个差距来源于:
- 样本需求:SkillOrchestra只需要不到50个样本(加上同等数量的验证样本),而Router-R1需要14,000个
- 训练方式:SkillOrchestra不做参数训练(不更新编排器的权重),只做统计估计和LLM调用来构建手册;而RL方法需要多轮梯度更新
- 基础设施需求:RL训练通常需要GPU集群跑几天,手册学习用API调用就够了
Pareto最优手册选择的必要性
消融实验揭示了一个反直觉的现象:更多的技能不一定更好。原始手册可能包含98个技能,但对于Qwen2.5-3B这样的小模型来说,要在这么多技能之间做准确判断太难了。经过Pareto选择后可能只保留10-12个技能,但粒度更匹配编排器的能力,反而取得了更好的效果。
这就像给一个新手司机看一本1000页的驾驶百科全书 vs 给他一本50页的精华手册——信息少但更实用。
局限性与未来方向
尽管SkillOrchestra取得了令人印象深刻的结果,但仍有一些值得思考的方向:
- 手册学习依赖LLM调用:技能发现和精炼需要调用GPT-5这样的强模型做对比分析,如果没有强模型API,手册质量可能受影响
- 冷启动问题:对于全新的任务领域,初始的探索数据仍然需要人工准备或用启发式方法生成
- 技能的动态性:当前手册是离线学习的,如果模型池频繁变化(比如每周都有新模型发布),手册需要增量更新机制
- 单一编排器:目前系统只有一个编排器,在更复杂的场景下可能需要层次化编排
总结
SkillOrchestra的核心贡献在于提出了一种既简洁又有效的编排范式:用知识(技能手册)替代策略(RL参数)来驱动智能体调度。
在我看来,这篇工作抓住了一个很本质的洞察——好的编排不需要端到端地学习一个"神经网络指挥家",而是需要结构化地理解"每个演奏者擅长什么"和"当前曲目需要什么"。RL路由方法试图通过大量试错来隐式学习这些知识,代价是高昂的训练成本和不稳定的策略;SkillOrchestra则选择显式地建模这些知识,用极少的数据就达到了更好的效果。
从更宏观的角度看,这篇工作暗示了复合AI系统设计中的一个趋势:元认知能力(了解自己和同伴的能力边界)可能比端到端优化更重要。毕竟,一个好的团队领导者不需要自己什么都会,但一定要知道团队里每个人擅长什么。
论文信息
- 标题:SkillOrchestra: Learning to Route Agents via Skill Transfer
- 链接:https://arxiv.org/abs/2602.19672
- 代码:https://github.com/jiayuww/SkillOrchestra
- 机构:University of Wisconsin-Madison, Salesforce AI Research

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)